
Chapter 19. Handling Failure
In which we address the reality of programming in an imperfect world, and add failure reporting. We add a new auction event that reports failure. We attach a new event listener that will turn off the Sniper if it fails. We also write a message to a log and write a unit test that mocks a class, for which we’re very sorry.
To avoid trying your patience any further, we close our example here.
So far, we’ve been prepared to assume that everything just works. This might be reasonable if the application is not supposed to last—perhaps it’s acceptable if it just crashes and we restart it or, as in this case, we’ve been mainly concerned with demonstrating and exploring the domain. Now it’s time to start being explicit about how we deal with failures.
What If It Doesn’t Work?
Our product people are concerned that Southabee’s On-Line has a reputation for occasionally failing and sending incorrectly structured messages, so they want us to show that we can cope. It turns out that the system we talk to is actually an aggregator for multiple auction feeds, so the failure of an individual auction does not imply that the whole system is unsafe. Our policy will be that when we receive a message that we cannot interpret, we will mark that auction as Failed and ignore any further updates, since it means we can no longer be sure what’s happening. Once an auction has failed, we make no attempt to recover.1
1. We admit that it’s unlikely that an auction site that regularly garbles its messages will survive for long, but it’s a simple example to work through. We also doubt that any serious bidder will be happy to let their bid lie hanging, not knowing whether they’ve bought something or lost to a rival. On the other hand, we’ve seen less plausible systems succeed in the world, propped up by an army of special handling, so perhaps you can let us get away with this one.
In practice, reporting a message failure means that we flush the price and bid values, and show the status as Failed for the offending item. We also record the event somewhere so that we can deal with it later. We could make the display of the failure more obvious, for example by coloring the row, but we’ll keep this version simple and leave any extras as an exercise for the reader.
The end-to-end test shows that a working Sniper receives a bad message, displays and records the failure, and then ignores further updates from this auction:

where sendInvalidMessageContaining() sends the given invalid string via a chat to the Sniper, and showsSniperHasFailed() checks that the status for the item is Failed and that the price values have been zeroed. We park the implementation of reportsInvalidMessage() for the moment; we’ll come back to it later in this chapter.
Testing That Something Doesn’t Happen
![]()
You’ll have noticed the waitForAnotherAuctionEvent() method which forces an unrelated Sniper event and then waits for it to work through the system. Without this call, it would be possible for the final showSniperHasFailed() check to pass incorrectly because it would pick up the previous Sniper state—before the system has had time to process the relevant price event. The additional event holds back the test just long enough to make sure that the system has caught up. See Chapter 27 for more on testing with asynchrony.
To get this test to fail appropriately, we add a FAILED value to the SniperState enumeration, with an associated text mapping in SnipersTabelModel. The test fails:

It shows that there are two rows in the table: the second is for the other auction, and the first is showing that the current price is 500 when it should have been flushed to 0. This failure is our marker for what we need to build next.
Detecting the Failure
The failure will actually occur in the AuctionMessageTranslator (last shown in Chapter 14) which will throw a runtime exception when it tries to parse the message. The Smack library drops exceptions thrown by MessageHandlers, so we have to make sure that our handler catches everything. As we write a unit test for a failure in the translator, we realize that we need to report a new type of auction event, so we add an auctionFailed() method to the AuctionEventListener interface.

This fails with an ArrayIndexOutOfBoundsException when it tries to unpack a name/value pair from the string. We could be precise about which exceptions to catch but in practice it doesn’t really matter here: we either parse the message or we don’t, so to make the test pass we extract the bulk of processMessage() into a translate() method and wrap a try/catch block around it.

While we’re here, there’s another failure mode we’d like to check. It’s possible that a message is well-formed but incomplete: it might be missing one of its fields such as the event type or current price. We write a couple of tests to confirm that we can catch these, for example:
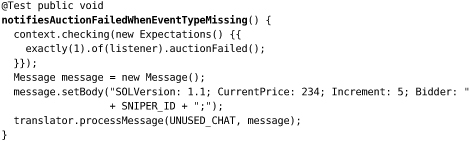
Our fix is to throw an exception whenever we try to get a value that has not been set, and we define MissingValueException for this purpose.
Displaying the Failure
We added an auctionFailed() method to AuctionEventListener while unit-testing AuctionMessageTranslator. This triggers a compiler warning in AuctionSniper, so we added an empty implementation to keep going. Now it’s time to make it work, which turns out to be easy. We write some tests in

We’ve added a couple more helper methods: ignoringAuction() says that we don’t care what happens to auction, allowing events to pass through so we can get to the failure; and, expectSniperToFailWhenItIs() describes what a failure should look like, including the previous state of the Sniper.
All we have to do is add a failed() transition to SniperSnapshot and use it in the new method.

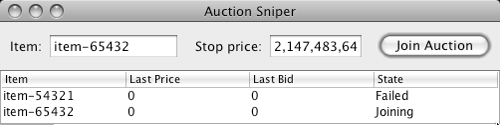
This displays the failure, as we can see in Figure 19.1.
Figure 19.1 The Sniper shows a failed auction
The end-to-end test, however, still fails. The synchronization hook we added reveals that we haven’t disconnected the Sniper from receiving further events from the auction.
Disconnecting the Sniper
We turn off a Sniper by removing its AuctionMessageTranslator from its Chat’s set of MessageListeners. We can do this safely while processing a message because Chat stores its listeners in a thread-safe “copy on write” collection. One obvious place to do this is within processMessage() in AuctionMessageTranslator, which receives the Chat as an argument, but we have two doubts about this. First, as we pointed out in Chapter 12, constructing a real Chat is painful. Most of the mocking frameworks support creating a mock class, but it makes us uncomfortable because then we’re defining a relationship with an implementation, not a role—we’re being too precise about our dependencies. Second, we might be assigning too many responsibilities to AuctionMessageTranslator; it would have to translate the message and decide what to do when it fails.
Our alternative approach is to attach another object to the translator that implements this disconnection policy, using the infrastructure we already have for notifying AuctionEventListeners.
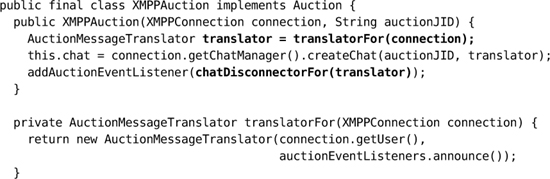
z

The end-to-end test, as far as it goes, passes.
The Composition Shell Game
![]()
The issue in this design episode is not the fundamental complexity of the feature, which is constant, but how we divide it up. The design we chose (attaching a disconnection listener) could be argued to be more complicated than its alternative (detaching the chat within the translator). It certainly takes more lines of code, but that’s not the only metric. Instead, we’re emphasizing the “single responsibility” principle, which means each object does just one thing well and the system behavior comes from how we assemble those objects.
Sometimes this feels as if the behavior we’re looking for is always somewhere else (as Gertrude Stein said, “There is no there there”), which can be frustrating for developers not used to the style. Our experience, on the other hand, is that focused responsibilities make the code more maintainable because we don’t have to cut through unrelated functionality to get to the piece we need. See Chapter 6 for a longer discussion.
Recording the Failure
Now we want to return to the end-to-end test and the reportsInvalidMessage() method that we parked. Our requirement is that the Sniper application must log a message about these failures so that the user’s organization can recover the situation. This means that our test should look for a log file and check its contents.
Filling In the Test
We implement the missing check and flush the log before each test, delegating the management of the log file to an AuctionLogDriver class which uses the Apache Commons IO library. It also cheats slightly by resetting the log manager (we’re not really supposed to be in the same address space), since deleting the log file can confuse a cached logger.

This new check only reassures us that we’ve fed a message through the system and into some kind of log record—it tells us that the pieces fit together. We’ll write a more thorough test of the contents of a log record later. The end-to-end test now fails because, of course, there’s no log file to read.
Failure Reporting in the Translator
Once again, the first change is in the AuctionMessageTranslator. We’d like the record to include the auction identifier, the received message, and the thrown exception. The “single responsibility” principle suggests that the AuctionMessageTranslator should not be responsible for deciding how to report the event, so we invent a new collaborator to handle this task. We call it XMPPFailureReporter:

We amend our existing failure tests, wrapping up message creation and common expectations in helper methods, for example:
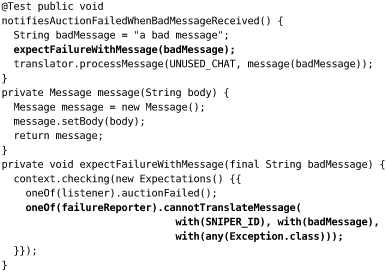
The new reporter is a dependency for the translator, so we feed it in through the constructor and call it just before notifying any listeners. We know that message.getBody() will not throw an exception, it’s just a simple bean, so we can leave it outside the catch block.

The unit test passes.
Generating the Log Message
The next stage is to implement the XMPPFailureReporter with something that generates a log file. This is where we actually check the format and contents of a log entry. We start a class LoggingXMPPFailureReporter and decide to use Java’s built-in logging framework. We could make the tests for this new class write and read from a real file. Instead, we decide that file access is sufficiently covered by the end-to-end test we’ve just set up, so we’ll run everything in memory to reduce the test’s dependencies. We’re confident we can take this shortcut, because the example is so simple; for more complex behavior we would write some integration tests.
The Java logging framework has no interfaces, so we have to be more concrete than we’d like. Exceptionally, we decide to use a class-based mock to override the relevant method in Logger; in jMock we turn on class-based mocking with the setImposteriser() call. The AfterClass annotation tells JUnit to call resetLogging() after all the tests have run to flush any changes we might have made to the logging environment.

We pass this test with an implementation that just calls the logger with a string formatted from the inputs to cannotTranslateMessage().
Breaking Our Own Rules?
![]()
We already wrote that we don’t like to mock classes, and we go on about it further in Chapter 20. So, how come we’re doing it here?
What we care about in this test is the rendering of the values into a failure message with a severity level. The class is very limited, just a shim above the logging layer, so we don’t think it’s worth introducing another level of indirection to define the logging role. As we wrote before, we also don’t think it worth running against a real file since that introduces dependencies (and, even worse, asynchrony) not really relevant to the functionality we’re developing. We also believe that, as part of the Java runtime, the logging API is unlikely to change.
So, just this once, as a special favor, setting no precedents, making no promises, we mock the Logger class. There are a couple more points worth making before we move on. First, we would not do this for a class that is internal to our code, because then we would be able write an interface to describe the role it’s playing. Second, if the LoggingXMPPFailureReporter were to grow in complexity, we would probably find ourselves discovering a supporting message formatter class that could be tested directly.
Closing the Loop
Now we have the pieces in place to make the whole end-to-end test pass. We plug an instance of the LoggingXMPPFailureReporter into the XMPPAuctionHouse so that, via its XMPPAuctions, every AuctionMessageTranslator is constructed with the reporter. We also move the constant that defines the log file name there from AuctionLogDriver, and define a new XMPPAuctionException to gather up any failures within the package.

The end-to-end test passes completely and we can cross another item off our list: Figure 19.2.
Figure 19.2 The Sniper reports failed messages from an auction

Observations
“Inverse Salami” Development
We hope that by now you’re getting a sense of the rhythm of incrementally growing software, adding functionality in thin but coherent slices. For each new feature, write some tests that show what it should do, work through each of those tests changing just enough code to make it pass, restructure the code as needed either to open up space for new functionality or to reveal new concepts—then ship it. We discuss how this fits into the larger development picture in Chapter 5. In static languages, such as Java and C#, we can often use the compiler to help us navigate the chain of implementation dependencies: change the code to accept the new triggering event, see what breaks, fix that breakage, see what that change breaks in turn, and repeat the process until the functionality works.
The skill is in learning how to divide requirements up into incremental slices, always having something working, always adding just one more feature. The process should feel relentless—it just keeps moving. To make this work, we have to understand how to change the code incrementally and, critically, keep the code well structured so that we can take it wherever we need to go (and we don’t know where that is yet). This is why the refactoring part of a test-driven development cycle is so critical—we always get into trouble when we don’t keep up that side of the bargain.
Small Methods to Express Intent
We have a habit of writing helper methods to wrap up small amounts of code—for two reasons. First, this reduces the amount of syntactic noise in the calling code that languages like Java force upon us. For example, when we disconnect the Sniper, the translatorFor() method means we don’t have to type "AuctionMessageTranslator" twice in the same line. Second, this gives a meaningful name to a structure that would not otherwise be obvious. For example, chatDisconnectorFor() describes what its anonymous class does and is less intrusive than defining a named inner class.
Our aim is to do what we can to make each level of code as readable and self-explanatory as possible, repeating the process all the way down until we actually have to use a Java construct.
Logging Is Also a Feature
We defined XMPPFailureReporter to package up failure reporting for the AuctionMessageTranslator. Many teams would regard this as overdesign and just write the log message in place. We think this would weaken the design by mixing levels (message translation and logging) in the same code.
We’ve seen many systems where logging has been added ad hoc by developers wherever they find a need. However, production logging is an external interface that should be driven by the requirements of those who will depend on it, not by the structure of the current implementation. We find that when we take the trouble to describe runtime reporting in the caller’s terms, as we did with the XMPPFailureReporter, we end up with more useful logs. We also find that we end up with the logging infrastructure clearly isolated, rather than scattered throughout the code, which makes it easier to work with.
This topic is such a bugbear (for Steve at least) that we devote a whole section to it in Chapter 20.