
Chapter 6. Object-Oriented Style
Always design a thing by considering it in its next larger context—a chair in a room, a room in a house, a house in an environment, an environment in a city plan.
—Eliel Saarinen
Introduction
So far in Part II, we’ve talked about how to get started with the development process and how to keep going. Now we want to take a more detailed look at our design goals and our use of TDD, and in particular mock objects, to guide the structure of our code.
We value code that is easy to maintain over code that is easy to write.1 Implementing a feature in the most direct way can damage the maintainability of the system, for example by making the code difficult to understand or by introducing hidden dependencies between components. Balancing immediate and longer-term concerns is often tricky, but we’ve seen too many teams that can no longer deliver because their system is too brittle.
1. As the Agile Manifesto might have put it.
In this chapter, we want to show something of what we’re trying to achieve when we design software, and how that looks in an object-oriented language; this is the “opinionated” part of our approach to software. In the next chapter, we’ll look at the mechanics of how to guide code in this direction with TDD.
Designing for Maintainability
Following the process we described in Chapter 5, we grow our systems a slice of functionality at a time. As the code scales up, the only way we can continue to understand and maintain it is by structuring the functionality into objects, objects into packages,2 packages into programs, and programs into systems. We use two principal heuristics to guide this structuring:
2. We’re being vague about the meaning of “package” here since we want it to include concepts such as modules, libraries, and namespaces, which tend to be confounded in the Java world—but you know what we mean.
When we have to change the behavior of a system, we want to change as little code as possible. If all the relevant changes are in one area of code, we don’t have to hunt around the system to get the job done. Because we cannot predict when we will have to change any particular part of the system, we gather together code that will change for the same reason. For example, code to unpack messages from an Internet standard protocol will not change for the same reasons as business code that interprets those messages, so we partition the two concepts into different packages.
Higher levels of abstraction
The only way for humans to deal with complexity is to avoid it, by working at higher levels of abstraction. We can get more done if we program by combining components of useful functionality rather than manipulating variables and control flow; that’s why most people order food from a menu in terms of dishes, rather than detail the recipes used to create them.
Applied consistently, these two forces will push the structure of an application towards something like Cockburn’s “ports and adapters” architecture [Cockburn08], in which the code for the business domain is isolated from its dependencies on technical infrastructure, such as databases and user interfaces. We don’t want technical concepts to leak into the application model, so we write interfaces to describe its relationships with the outside world in its terminology (Cockburn’s ports). Then we write bridges between the application core and each technical domain (Cockburn’s adapters). This is related to what Eric Evans calls an “anticorruption layer” [Evans03].
The bridges implement the interfaces defined by the application model and map between application-level and technical-level objects (Figure 6.1). For example, a bridge might map an order book object to SQL statements so that orders are persisted in a database. To do so, it might query values from the application object or use an object-relational tool like Hibernate3 to pull values out of objects using Java reflection. We’ll show an example of refactoring to this architecture in Chapter 17.
Figure 6.1 An application’s core domain model is mapped onto technical infrastructure
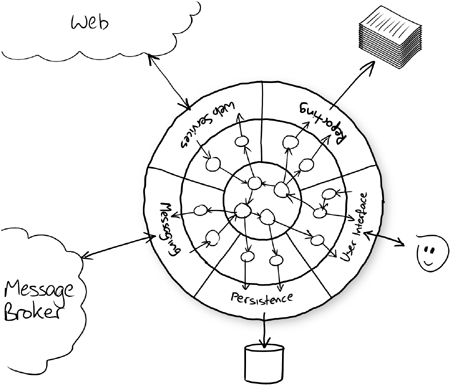
The next question is how to find the facets in the behavior where the interfaces should be, so that we can divide up the code cleanly. We have some second-level heuristics to help us think about that.
Internals vs. Peers
As we organize our system, we must decide what is inside and outside each object, so that the object provides a coherent abstraction with a clear API. Much of the point of an object, as we discussed above, is to encapsulate access to its internals through its API and to hide these details from the rest of the system. An object communicates with other objects in the system by sending and receiving messages, as in Figure 6.2; the objects it communicates with directly are its peers.
Figure 6.2 Objects communicate by sending and receiving messages
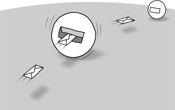
This decision matters because it affects how easy an object is to use, and so contributes to the internal quality of the system. If we expose too much of an object’s internals through its API, its clients will end up doing some of its work. We’ll have distributed behavior across too many objects (they’ll be coupled together), increasing the cost of maintenance because any changes will now ripple across the code. This is the effect of the “train wreck” example on page 17:

Every getter in this example exposes a structural detail. If we wanted to change, say, the way customizations on the master are enabled, we’d have to change all the intermediate relationships.
So how do we choose the right features for an object?
No And’s, Or’s, or But’s
Every object should have a single, clearly defined responsibility; this is the “single responsibility” principle [Martin02]. When we’re adding behavior to a system, this principle helps us decide whether to extend an existing object or create a new service for an object to call.
Our heuristic is that we should be able to describe what an object does without using any conjunctions (“and,” “or”). If we find ourselves adding clauses to the description, then the object probably should be broken up into collaborating objects, usually one for each clause.
This principle also applies when we’re combining objects into new abstractions. If we’re packaging up behavior implemented across several objects into a single construct, we should be able to describe its responsibility clearly; there are some related ideas below in the “Composite Simpler Than the Sum of Its Parts” and “Context Independence” sections.
Object Peer Stereotypes
We have objects with single responsibilities, communicating with their peers through messages in clean APIs, but what do they say to each other?
We categorize an object’s peers (loosely) into three types of relationship. An object might have:
Dependencies
Services that the object requires from its peers so it can perform its responsibilities. The object cannot function without these services. It should not be possible to create the object without them. For example, a graphics package will need something like a screen or canvas to draw on—it doesn’t make sense without one.
Notifications
Peers that need to be kept up to date with the object’s activity. The object will notify interested peers whenever it changes state or performs a significant action. Notifications are “fire and forget”; the object neither knows nor cares which peers are listening. Notifications are so useful because they decouple objects from each other. For example, in a user interface system, a button component promises to notify any registered listeners when it’s clicked, but does not know what those listeners will do. Similarly, the listeners expect to be called but know nothing of the way the user interface dispatches its events.
Adjustments
Peers that adjust the object’s behavior to the wider needs of the system. This includes policy objects that make decisions on the object’s behalf (the Strategy pattern in [Gamma94]) and component parts of the object if it’s a composite. For example, a Swing JTable will ask a TableCellRenderer to draw a cell’s value, perhaps as RGB (Red, Green, Blue) values for a color. If we change the renderer, the table will change its presentation, now displaying the HSB (Hue, Saturation, Brightness) values.
These stereotypes are only heuristics to help us think about the design, not hard rules, so we don’t obsess about finding just the right classification of an object’s peers. What matters most is the context in which the collaborating objects are used. For example, in one application an auditing log could be a dependency, because auditing is a legal requirement for the business and no object should be created without an audit trail. Elsewhere, it could be a notification, because auditing is a user choice and objects will function perfectly well without it.
Another way to look at it is that notifications are one-way: A notification listener may not return a value, call back the caller, or throw an exception, since there may be other listeners further down the chain. A dependency or adjustment, on the other hand, may do any of these, since there’s a direct relationship.
Composite Simpler Than the Sum of Its Parts
All objects in a system, except for primitive types built into the language, are composed of other objects. When composing objects into a new type, we want the new type to exhibit simpler behavior than all of its component parts considered together. The composite object’s API must hide the existence of its component parts and the interactions between them, and expose a simpler abstraction to its peers. Think of a mechanical clock: It has two or three hands for output and one pull-out wheel for input but packages up dozens of moving parts.
In software, a user interface component for editing money values might have two subcomponents: one for the amount and one for the currency. For the component to be useful, its API should manage both values together, otherwise the client code could just control it subcomponents directly.
moneyEditor.getAmountField().setText(String.valueOf(money.amount());
moneyEditor.getCurrencyField().setText(money.currencyCode());
The “Tell, Don’t Ask” convention can start to hide an object’s structure from its clients but is not a strong enough rule by itself. For example, we could replace the getters in the first version with setters:
moneyEditor.setAmountField(money.amount());
moneyEditor.setCurrencyField(money.currencyCode());
This still exposes the internal structure of the component, which its client still has to manage explicitly.
We can make the API much simpler by hiding within the component everything about the way money values are displayed and edited, which in turn simplifies the client code:
moneyEditor.setValue(money);
This suggests a rule of thumb:
Composite Simpler Than the Sum of Its Parts
![]()
The API of a composite object should not be more complicated than that of any of its components.
Composite objects can, of course, be used as components in larger-scale, more sophisticated composite objects. As we grow the code, the “composite simpler than the sum of its parts” rule contributes to raising the level of abstraction.
Context Independence
While the “composite simpler than the sum of its parts” rule helps us decide whether an object hides enough information, the “context independence” rule helps us decide whether an object hides too much or hides the wrong information.
A system is easier to change if its objects are context-independent; that is, if each object has no built-in knowledge about the system in which it executes. This allows us to take units of behavior (objects) and apply them in new situations. To be context-independent, whatever an object needs to know about the larger environment it’s running in must be passed in. Those relationships might be “permanent” (passed in on construction) or “transient” (passed in to the method that needs them).
In this “paternalistic” approach, each object is told just enough to do its job and wrapped up in an abstraction that matches its vocabulary. Eventually, the chain of objects reaches a process boundary, which is where the system will find external details such as host names, ports, and user interface events.
One Domain Vocabulary
![]()
A class that uses terms from multiple domains might be violating context independence, unless it’s part of a bridging layer.
The effect of the “context independence” rule on a system of objects is to make their relationships explicit, defined separately from the objects themselves. First, this simplifies the objects, since they don’t need to manage their own relationships. Second, this simplifies managing the relationships, since objects at the same scale are often created and composed together in the same places, usually in mapping-layer factory objects.
Context independence guides us towards coherent objects that can be applied in different contexts, and towards systems that we can change by reconfiguring how their objects are composed.
Hiding the Right Information
Encapsulation is almost always a good thing to do, but sometimes information can be hidden in the wrong place. This makes the code difficult to understand, to integrate, or to build behavior from by composing objects. The best defense is to be clear about the difference between the two concepts when discussing a design. For example, we might say:
• “Encapsulate the data structure for the cache in the CachingAuctionLoader class.”
• “Encapsulate the name of the application’s log file in the PricingPolicy class.”
These sound reasonable until we recast them in terms of information hiding:
• “Hide the data structure used for the cache in the CachingAuctionLoader class.”
• “Hide the name of the application’s log file in the PricingPolicy class.”
Context independence tells us that we have no business hiding details of the log file in the PricingPolicy class—they’re concepts from different levels in the “Russian doll” structure of nested domains. If the log file name is necessary, it should be packaged up and passed in from a level that understands external configuration.
An Opinionated View
We’ve taken the time to describe what we think of as “good” object-oriented design because it underlies our approach to development and we find that it helps us write code that we can easily grow and adapt to meet the changing needs of its users. Now we want to show how our approach to test-driven development supports these principles.