
Chapter 24. Test Flexibility
Living plants are flexible and tender;
the dead are brittle and dry.
[...]
The rigid and stiff will be broken.
The soft and yielding will overcome.
—Lao Tzu (c.604—531 B.C.)
Introduction
As the system and its associated test suite grows, maintaining the tests can become a burden if they have not been written carefully. We’ve described how we can reduce the ongoing cost of tests by making them easy to read and generating helpful diagnostics on failure. We also want to make sure that each test fails only when its relevant code is broken. Otherwise, we end up with brittle tests that slow down development and inhibit refactoring. Common causes of test brittleness include:
• The tests are too tightly coupled to unrelated parts of the system or unrelated behavior of the object(s) they’re testing;
• The tests overspecify the expected behavior of the target code, constraining it more than necessary; and,
• There is duplication when multiple tests exercise the same production code behavior.
Test brittleness is not just an attribute of how the tests are written; it’s also related to the design of the system. If an object is difficult to decouple from its environment because it has many dependencies or its dependencies are hidden, its tests will fail when distant parts of the system change. It will be hard to judge the knock-on effects of altering the code. So, we can use test brittleness as a valuable source of feedback about design quality.
There’s a virtuous relationship with test readability and resilience. A test that is focused, has clean set-up, and has minimal duplication is easier to name and is more obvious about its purpose. This chapter expands on some of the techniques we discussed in Chapter 21. Actually, the whole chapter can be collapsed into a single rule:
JUnit, Hamcrest, and jMock allow us to specify just what we want from the target code (there are equivalents in other languages). The more precise we are, the more the code can flex in other unrelated dimensions without breaking tests misleadingly. Our experience is that the other benefit of keeping tests flexible is that they’re easier for us to understand because they are clearer about what they’re testing—about what is and is not important in the tested code.
Test for Information, Not Representation
A test might need to pass a value to trigger the behavior it’s supposed to exercise in its target object. The value could either be passed in as a parameter to a method on the object, or returned as a result from a query the object makes on one of its neighbors stubbed by the test. If the test is structured in terms of how the value is represented by other parts of the system, then it has a dependency on those parts and will break when they change.
For example, imagine we have a system that uses a CustomerBase to store and find information about our customers. One of its features is to look up a Customer given an email address; it returns null if there’s no customer with the given address.

When we test the parts of the code that search for customers by email address, we stub CustomerBase as a collaborating object. In some of those tests, no customer will be found so we return null:
![]()
There are two problems with this use of null in a test. First, we have to remember what null means here, and when it’s appropriate; the test is not self-explanatory. The second concern is the cost of maintenance.
Some time later, we experience a NullPointerException in production and track the source of the null reference down to the CustomerBase. We realize we’ve broken one of our design rules: “Never Pass Null between Objects.” Ashamed, we change the CustomerBase’s search methods to return a Maybe type, which implements an iterable collection of at most one result.

We still, however, have the tests that stub CustomerBase to return null, to represent missing customers. The compiler cannot warn us of the mismatch because null is a valid value of type Maybe<Customer> too, so the best we can do is to watch all these tests fail and change each one to the new design.
If, instead, we’d given the tests their own representation of “no customer found” as a single well-named constant instead of the literal null, we could have avoided this drudgery. We would have changed one line:
public static final Customer NO_CUSTOMER_FOUND = null;
to
public static final Maybe<Customer> NO_CUSTOMER_FOUND = Maybe.nothing();
without changing the tests themselves.
Tests should be written in terms of the information passed between objects, not of how that information is represented. Doing so will both make the tests more self-explanatory and shield them from changes in implementation controlled elsewhere in the system. Significant values, like NO_CUSTOMER_FOUND, should be defined in one place as a constant. There’s another example in Chapter 12 when we introduce UNUSED_CHAT. For more complex structures, we can hide the details of the representation in test data builders (Chapter 22).
Precise Assertions
In a test, focus the assertions on just what’s relevant to the scenario being tested. Avoid asserting values that aren’t driven by the test inputs, and avoid reasserting behavior that is covered in other tests.
We find that these heuristics guide us towards writing tests where each method exercises a unique aspect of the target code’s behavior. This makes the tests more robust because they’re not dependent on unrelated results, and there’s less duplication.
Most test assertions are simple checks for equality; for example, we assert the number of rows in a table model in “Extending the Table Model” (page 180). Testing for equality doesn’t scale well as the value being returned becomes more complex. Different test scenarios may make the tested code return results that differ only in specific attributes, so comparing the entire result each time is misleading and introduces an implicit dependency on the behavior of the whole tested object.
There are a couple of ways in which a result can be more complex. First, it can be defined as a structured value type. This is straightforward since we can just reference directly any attributes we want to assert. For example, if we take the financial instrument from “Use Structure to Explain” (page 253), we might need to assert only its strike price:
assertEquals("strike price", 92, instrument.getStrikePrice());
without comparing the whole instrument.
We can use Hamcrest matchers to make the assertions more expressive and more finely tuned. For example, if we want to assert that a transaction identifier is larger than its predecessor, we can write:
assertThat(instrument.getTransactionId(), largerThan(PREVIOUS_TRANSACTION_ID));
This tells the programmer that the only thing we really care about is that the new identifier is larger than the previous one—its actual value is not important in this test. The assertion also generates a helpful message when it fails.
The second source of complexity is implicit, but very common. We often have to make assertions about a text string. Sometimes we know exactly what the text should be, for example when we have the FakeAuctionServer look for specific messages in “Extending the Fake Auction” (page 107). Sometimes, however, all we need to check is that certain values are included in the text.
A frequent example is when generating a failure message. We don’t want all our unit tests to be locked to its current formatting, so that they fail when we add whitespace, and we don’t want to have to do anything clever to cope with timestamps. We just want to know that the critical information is included, so we write:

which asserts that all these strings occur somewhere in failureMessage. That’s enough reassurance for us, and we can write other tests to check that a message is formatted correctly if we think it’s significant.
One interesting effect of trying to write precise assertions against text strings is that the effort often suggests that we’re missing an intermediate structure object—in this case perhaps an InstrumentFailure. Most of the code would be written in terms of an InstrumentFailure, a structured value that carries all the relevant fields. The failure would be converted to a string only at the last possible moment, and that string conversion can be tested in isolation.
Precise Expectations
We can extend the concept of being precise about assertions to being precise about expectations. Each mock object test should specify just the relevant details of the interactions between the object under test and its neighbors. The combined unit tests for an object describe its protocol for communicating with the rest of the system.
We’ve built a lot of support into jMock for specifying this communication between objects as precisely as it should be. The API is designed to produce tests that clearly express how objects relate to each other and that are flexible because they’re not too restrictive. This may require a little more test code than some of the alternatives, but we find that the extra rigor keeps the tests clear.
Precise Parameter Matching
We want to be as precise about the values passed in to a method as we are about the value it returns. For example, in “Assertions and Expectations” (page 254) we showed an expectation where one of the accepted arguments was any type of RuntimeException; the specific class doesn’t matter. Similarly, in “Extracting the SnipersTableModel” (page 197), we have this expectation:
oneOf(auction).addAuctionEventListener(with(sniperForItem(itemId)));
The method sniperForItem() returns a Matcher that checks only the item identifier when given an AuctionSniper. This test doesn’t care about anything else in the sniper’s state, such as its current bid or last price, so we don’t make it more brittle by checking those values.
The same precision can be applied to expecting input strings. If, for example, we have an auditTrail object to accept the failure message we described above, we can write a precise expectation for that auditing:
![]()
Allowances and Expectations
We introduced the concept of allowances in “The Sniper Acquires Some State” (page 144). jMock insists that all expectations are met during a test, but allowances may be matched or not. The point of the distinction is to highlight what matters in a particular test. Expectations describe the interactions that are essential to the protocol we’re testing: if we send this message to the object, we expect to see it send this other message to this neighbor.
Allowances support the interaction we’re testing. We often use them as stubs to feed values into the object, to get the object into the right state for the behavior we want to test. We also use them to ignore other interactions that aren’t relevant to the current test. For example, in “Repurposing sniperBidding()” we have a test that includes:
![]()
The ignoring() clause says that, in this test, we don’t care about messages sent to the auction; they will be covered in other tests. The allowing() clause matches any call to sniperStateChanged() with a Sniper that is currently bidding, but doesn’t insist that such a call happens. In this test, we use the allowance to record what the Sniper has told us about its state. The method aSniperThatIs() returns a Matcher that checks only the SniperState when given a SniperSnapshot.
In other tests we attach “action” clauses to allowances, so that the call will return a value or throw an exception. For example, we might have an allowance that stubs the catalog to return a price that will be returned for use later in the test:
allowing(catalog).getPriceForItem(item); will(returnValue(74));
The distinction between allowances and expectations isn’t rigid, but we’ve found that this simple rule helps:
Allow Queries; Expect Commands
![]()
Commands are calls that are likely to have side effects, to change the world outside the target object. When we tell the auditTrail above to record a failure, we expect that to change the contents of some kind of log. The state of the system will be different if we call the method a different number of times.
Queries don’t change the world, so they can be called any number of times, including none. In our example above, it doesn’t make any difference to the system how many times we ask the catalog for a price.
The rule helps to decouple the test from the tested object. If the implementation changes, for example to introduce caching or use a different algorithm, the test is still valid. On the other hand, if we were writing a test for a cache, we would want to know exactly how often the query was made.
jMock supports more varied checking of how often a call is made than just allowing() and oneOf(). The number of times a call is expected is defined by the “cardinality” clause that starts the expectation. In “The AuctionSniper Bids,” we saw the example:
atLeast(1).of(sniperListener).sniperBidding();
which says that we care that this call is made, but not how many times. There are other clauses which allow fine-tuning of the number of times a call is expected, listed in Appendix A.
Ignoring Irrelevant Objects
As you’ve seen, we can simplify a test by “ignoring” collaborators that are not relevant to the functionality being exercised. jMock will not check any calls to ignored objects. This keeps the test simple and focused, so we can immediately see what’s important and changes to one aspect of the code do not break unrelated tests.
As a convenience, jMock will provide “zero” results for ignored methods that return a value, depending on the return type:
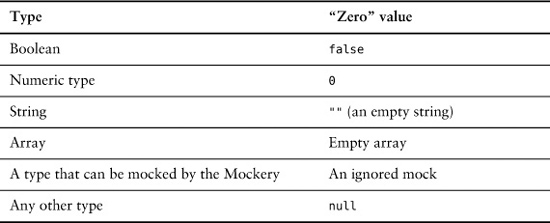
The ability to dynamically mock returned types can be a powerful tool for narrowing the scope of a test. For example, for code that uses the Java Persistence API (JPA), a test can ignore the EntityManagerFactory. The factory will return an ignored EntityManager, which will return an ignored EntityTransaction on which we can ignore commit() or rollback(). With one ignore clause, the test can focus on the code’s domain behavior by disabling everything to do with transactions.
Like all “power tools,” ignoring() should be used with care. A chain of ignored objects might suggest that the functionality ought to be pulled out into a new collaborator. As programmers, we must also make sure that ignored features are tested somewhere, and that there are higher-level tests to make sure everything works together. In practice, we usually introduce ignoring() only when writing specialized tests after the basics are in place, as for example in “The Sniper Acquires Some State” (page 144).
Invocation Order
jMock allows invocations on a mock object to be called in any order; the expectations don’t have to be declared in the same sequence.1 The less we say in the tests about the order of interactions, the more flexibility we have with the implementation of the code. We also gain flexibility in how we structure the tests; for example, we can make test methods more readable by packaging up expectations in helper methods.
1. Some early mock frameworks were strictly “record/playback”: the actual calls had to match the sequence of the expected calls. No frameworks enforce this any more, but the misconception is still common.
Only Enforce Invocation Order When It Matters
![]()
Sometimes the order in which calls are made is significant, in which case we add explicit constraints to the test. Keeping such constraints to a minimum avoids locking down the production code. It also helps us see whether each case is necessary—ordered constraints are so uncommon that each use stands out.
jMock has two mechanisms for constraining invocation order: sequences, which define an ordered list of invocations, and state machines, which can describe more sophisticated ordering constraints. Sequences are simpler to understand than state machines, but their restrictiveness can make tests brittle if used inappropriately.
Sequences are most useful for confirming that an object sends notifications to its neighbors in the right order. For example, we need an AuctionSearcher object that will search its collection of Auctions to find which ones match anything from a given set of keywords. Whenever it finds a match, the searcher will notify its AuctionSearchListener by calling searchMatched() with the matching auction. The searcher will tell the listener that it’s tried all of its available auctions by calling searchFinished().
Our first attempt at a test looks like this:
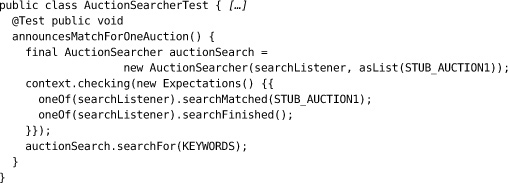
where searchListener is a mock AuctionSearchListener, KEYWORDS is a set of keyword strings, and STUB_AUCTION1 is a stub implementation of Auction that will match one of the strings in KEYWORDS.
The problem with this test is that there’s nothing to stop searchFinished() being called before searchMatched(), which doesn’t make sense. We have an interface for AuctionSearchListener, but we haven’t described its protocol. We can fix this by adding a Sequence to describe the relationship between the calls to the listener. The test will fail if searchFinished() is called first.
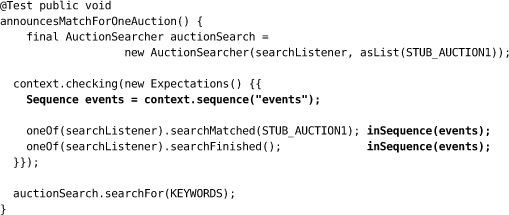
We continue using this sequence as we add more auctions to match:

But is this overconstraining the protocol? Do we have to match auctions in the same order that they’re initialized? Perhaps all we care about is that the right matches are made before the search is closed. We can relax the ordering constraint with a States object (which we first saw in “The Sniper Acquires Some State” on page 144).
A States implements an abstract state machine with named states. We can trigger state transitions by attaching a then() clause to an expectation. We can enforce that an invocation only happens when object is (or is not) in a particular state with a when() clause. We rewrite our test:

When the test opens, searching is in an undefined (default) state. The searcher can report matches as long as searching is not finished. When the searcher reports that it has finished, the then() clause switches searching to finished, which blocks any further matches.
States and sequences can be used in combination. For example, if our requirements change so that auctions have to be matched in order, we can add a sequence for just the matches, in addition to the existing searching states. The new sequence would confirm the order of search results and the existing states would confirm that the results arrived before the search is finished. An expectation can belong to multiple states and sequences, if that’s what the protocol requires. We rarely need such complexity—it’s most common when responding to external feeds of events where we don’t own the protocol—and we always take it as a hint that something should be broken up into smaller, simpler pieces.
When Expectation Order Matters
![]()
Actually, the order in which jMock expectations are declared is sometimes significant, but not because they have to shadow the order of invocation. Expectations are appended to a list, and invocations are matched by searching this list in order. If there are two expectations that can match an invocation, the one declared first will win. If that first expectation is actually an allowance, the second expectation will never see a match and the test will fail.
The Power of jMock States
jMock States has turned out to be a useful construct. We can use it to model each of the three types of participants in a test: the object being tested, its peers, and the test itself.
We can represent our understanding of the state of the object being tested, as in the example above. The test listens for the events the object sends out to its peers and uses them to trigger state transitions and to reject events that would break the object’s protocol.
As we wrote in “Representing Object State” (page 146), this is a logical representation of the state of the tested object. A States describes what the test finds relevant about the object, not its internal structure. We don’t want to constrain the object’s implementation.
We can represent how a peer changes state as it’s called by the tested object. For instance, in the example above, we might want to insist that the listener must be ready before it can receive any results, so the searcher must query its state. We could add a new States, listenerState:

Finally, we can represent the state of the test itself. For example, we could enforce that some interactions are ignored while the test is being set up:
![]()
Even More Liberal Expectations
Finally, jMock has plug-in points to support the definition of arbitrary expectations. For example, we could write an expectation to accept any getter method:
allowing(aPeerObject).method(startsWith("get")).withNoArguments();
or to accept a call to one of a set of objects:
oneOf (anyOf(same(o1),same(o2),same(o3))).method("doSomething");
Such expectations move us from a statically typed to a dynamically typed world, which brings both power and risk. These are our strongest “power tool” features—sometimes just what we need but always to be used with care. There’s more detail in the jMock documentation.
“Guinea Pig” Objects
In the “ports and adapters” architecture we described in “Designing for Maintainability” (page 47), the adapters map application domain objects onto the system’s technical infrastructure. Most of the adapter implementations we see are generic; for example, they often use reflection to move values between domains. We can apply such mappings to any type of object, which means we can change our domain model without touching the mapping code.
The easiest approach when writing tests for the adapter code is to use types from the application domain model, but this makes the test brittle because it binds together the application and adapter domains. It introduces a risk of misleadingly breaking tests when we change the application model, because we haven’t separated the concerns.
Here’s an example. A system uses an XmlMarshaller to marshal objects to and from XML so they can be sent across a network. This test exercises XmlMarshaller by round-tripping an AuctionClosedEvent object: a type that the production system really does send across the network.
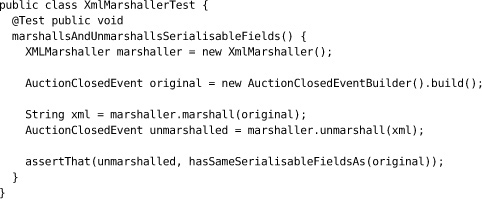
Later we decide that our system won’t send an AuctionClosedEvent after all, so we should be able to delete the class. Our refactoring attempt will fail because AuctionClosedEvent is still being used by the XmlMarshallerTest. The irrelevant coupling will force us to rework the test unnecessarily.
There’s a more significant (and subtle) problem when we couple tests to domain types: it’s harder to see when test assumptions have been broken. For example, our XmlMarshallerTest also checks how the marshaller handles transient and non-transient fields. When we wrote the tests, AuctionClosedEvent included both kind of fields, so we were exercising all the paths through the marshaller. Later, we removed the transient fields from AuctionClosedEvent, which means that we have tests that are no longer meaningful but do not fail. Nothing is alerting us that we have tests that have stopped working and that important features are not being covered.
We should test the XmlMarshaller with specific types that are clear about the features that they represent, unrelated to the real system. For example, we can introduce helper classes in the test:

The WithTransient class acts as a “guinea pig,” allowing us to exhaustively exercise the behavior of our XmlMarshaller before we let it loose on our production domain model. WithTransient also makes our test more readable because the class and its fields are examples of “Self-Describing Value” (page 269), with names that reflect their roles in the test.