
Big data is composed of massive databases, and millions or even billions of document files. One of the possible ways to generate insights from these datasets is by batch processing. One of the classical approaches of batch processing is called Hadoop's MapReduce paradigm. The processing time can take anywhere from minutes to hours, or even more—it all depends on the size of the job. But if we are thinking about insights in real time, we are more concerned about streaming data.
Streaming data can be defined as a sequence of digitally-encoded coherent signals that are used to send or receive information that is in the process of being transmitted.
Formally, it can be defined as any ordered pair (S, Δ) (S, Δ), where S is a sequence of tuples and Δ is a sequence of positive real-time intervals.
In order to humanize the definition, let's consider the following diagram:
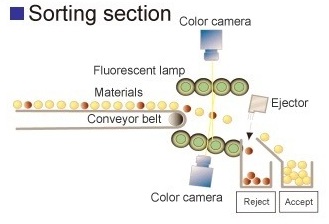
To understand this definition, we can think of data streaming as a conveyor belt, as demonstrated in the preceding diagram. We can assume the items on the belt are data packets that are being transmitted. If we have a sorting machine at the end of the belt that accepts or rejects items based on certain conditions, we can take this as a real-time streaming analytics scenario. If we replace the color camera with machine learning algorithms, it would show what a real-time streaming-analytics scenario would look like in a big dataset.