

Investigating Applications
While examining forensic evidence, it’s common to find artifacts that are not part of the operating system. User applications, such as Internet browsers, e-mail clients, office suites, and chat programs, store data on nearly every computer. There are also service applications, such as web servers, database servers, and e-mail servers, that support both user applications and the IT infrastructure. These data sources are often a critical source of evidence for an investigation. Therefore, it’s important to understand how to identify and analyze application data.
Because there are many ways an application creator can choose to store data, you will encounter many different data formats. Sometimes an application uses only a single format whereas other applications use multiple formats. The creator will normally choose formats that are well suited for the requirements of the application. Those formats can range from standard open source data structures to closed proprietary formats. Some application artifacts are independent of the operating system. For example, certain web browser history files are the same for any operating system that you use the browser on. You can take advantage of this during an investigation by using similar tools or techniques to review application data from many different operating systems.
Application data is important because it is a layer of potential evidence in addition to operating system artifacts. Some of the most common application categories that are relevant to an intrusion investigation are e-mail clients, web browsers, and instant messaging clients. Of course, there are many more categories—there are entire books dedicated to the forensic analysis of just a single application. The details you uncover though investigating applications could make or break a case. In this chapter we cover generic methods for investigating applications, as well as specific information about popular application categories and solutions. Like other chapters in this book, our intent is not to discuss all the fine details of an application. Rather, we intend to cover information that, in our experience, you are likely to find most useful.
WHAT IS APPLICATION DATA?
Data that is created, stored, or maintained by an application is considered application data. There are many different ways application data is stored and represented. Those storage methods, and the available data, regularly change over time. Some applications remain fairly stable, whereas others can change dramatically from month to month. Because of this, the tools and methods for investigating applications can also change dramatically over time. Because we cannot predict what applications will look like in the future, this chapter covers generic application investigation methods in addition to details about specific applications. Let’s take a quick look at where application data is stored, and then we will cover general methods.
As you begin to examine a system to look for application data, you may find yourself wondering where to start. More to the point, how do you know what applications are installed on the system and where related application data is located? Although applications can store data in custom locations, most operating systems have a convention. Knowing these conventions can help you quickly discover useful application data. In the following sections, we’ll provide some tips that should help you quickly locate application data on Windows, Linux, and OS X. Let’s cover Windows first.
Windows
There are a number of very good places to look on a Microsoft Windows system that help you compile a list of possible leads. Applications can always attempt to use custom locations to store data, but these are a list of the common locations we find most useful. Even if an application is no longer installed on the system, these default locations usually have some artifacts left behind. Most applications frequently use one, some, or all of these locations:
• Default application installation directory This is where the executable code for an application is typically placed during the application installation process. Most commonly, this is C:Program Files. It’s useful to sort the directory listing by date modified or date created, which gives you a quick-and-dirty indication of what applications have been installed or changed recently. On 64-bit systems, be sure to check C:Program Files (x86), the location where 32-bit applications are installed by default.
• Default application data directories Windows applications tend to use a common directory to store application-specific data, such as configuration files, or to use as a temporary working space. In Windows XP and older versions, check all directories one level under C:Documents and Settings{username} Application Data. In Windows Vista and newer versions, check all directories one level under C:ProgramData and C:Users{username}AppData.
• Registry uninstall information Windows has a common location in the registry where applications list themselves for uninstallation. Examine the registry keys under HKLMSOFTWAREMicrosoftWindowsCurrentVersionUninstall. Most keys will have a value named InstallLocation that lists the path to which the application was installed. On 64-bit versions of Windows, be sure to check HKLMSOFTWAREWow6432NodeMicrosoftWindowsCurrentVersionUninstall, which holds information on any 32-bit applications installed.
• Default registry configuration data locations Windows applications often use a common registry key to store application-specific configuration information. Check all sub-keys one level down from HKLMSOFTWARE. On 64-bit systems, be sure to check HKLMSOFTWAREWow6432Node, because that is where you will find information for 32-bit applications.
Apple OS X has two main locations you should inspect if you are searching for applications or related data:
• Default application installation directory The default installation directory for applications in OS X is /Applications. Just as with Windows, users can also place applications in custom locations.
• Application user data directory OS X applications generally place user-specific data within directories under the user’s profile. The default location is /Users/{profile}/Library/Application Support. In this directory, an application will typically create a directory named the same as the application and store all related user data under it.
Linux
In Linux, the locations of application-related data will vary based on the distribution you are investigating and any customizations that may be in place. We use two categories of methods to locate application data. The first is to manually inspect the file system, and the second is to query the package manager. Let’s look at each of these in a little more detail.
Manually inspecting the file system can take a lot of time and become very tedious if you don’t have something to point you in the right direction. To help, there is a convention that most Linux distributions follow called the Filesystem Hierarchy Standard (FHS). The FHS defines the directory structure that Linux distributions should follow. The full document is available on the FHS website.
GO GET IT ON THE WEB
Most distributions conform to some portion of the standard, so inspecting the following locations should provide you with good leads:
• Systemwide configuration data In most Linux distributions, the /etc and /usr/local/etc/directories are the primary locations where systemwide application configuration data is stored.
• User application data User-specific application data is typically found in subdirectories under the user’s home directory, by default /home/{username}.
• Executable locations The standard directories where you will find executables are /bin, /sbin, /usr/bin, /usr/sbin, /usr/local/bin, and /usr/local/sbin.
• Add-on software A location where some third-party applications and application data are installed to is /opt.
Sometimes a faster way to get the answers you are looking for is to simply query the package manager. Most modern versions of Linux use a package manager that maintains a database of all installed packages. Two common package managers and the corresponding commands to obtain a list of installed packages are:
• RPM-based distributions The RPM Package Manager (RPM) is used by a number of popular Linux distributions, with the most well-known being Red Hat Enterprise Linux (RHEL), CentOS, OpenSUSE, and Fedora. RPM packages have an .rpm extension by default, and the RPM command-line tool is named “rpm.” A basic command to see all installed packages and the date installed is:
Some distributions use Yellowdog Updater, Modified (yum), in conjunction with rpm. Systems with yum typically maintain a log in /var/log/yum.log, where you can see the history of packages installed, updated, and erased.
• Debian-based distributions Debian-based distributions use the dpkg package manager, and by default its packages are named with a .deb extension. Ubuntu and Knoppix are two popular Debian-based Linux distributions. To obtain a basic list of installed packages, run this command:
Dpkg also maintains a log in /var/log/dpkg.log. However, most distributions have this log rotated, so the history is limited. If it’s present, you will find additional details, including the date and time an action was taken, as well as the version number of the package. Ubuntu distributions also use the Advanced Packaging Tool (apt) in conjunction with dpkg, and apt log files may be present in /var/log/apt directory.
When you are dealing with a forensic image, you can use virtualization software, such as VMware Workstation or Oracle’s VirtualBox, to boot a copy of the image. Just be sure not to connect the virtual machine to your network in case there is malware on the system!
GENERAL INVESTIGATION METHODS
Before this chapter dives into specific applications, we’d like to discuss some general methods you can use to investigate an application and discover what artifacts it creates. This is a useful skill because applications change over time, and we don’t plan on covering the details of every application that’s out there. There are also many custom applications, some of which may only exist in your organization. So a little bit of “teaching a person to fish” is in order.
So what do we mean by “investigate an application”? In this case, we mean to determine what artifacts an application creates that might be beneficial to your investigation. If an application is not well documented, you may need to perform your own research to determine what artifacts might be useful and how to interpret them. When little or no documentation exists, there is a greater chance you might come to an incorrect conclusion. If the seriousness of your investigation is high, such as a case involving a criminal complaint, you may want to consider hiring computer forensic experts to assist. In less serious matters, performing your own research may be acceptable.
We suggest you first use resources in the forensics community to determine what may already be known. Forensic Focus, the Forensics Wiki, and support or message boards maintained by the application developers can be very useful. If you own commercial forensic software, their private message boards can also be a very useful resource.
GO GET IT ON THE WEB
Forensics Wiki www.forensicswiki.org
Forensic Focus www.forensicfocus.com
Popular forensic suites have the capability to parse and present data from many different applications. Before going off into the deep end, you should check to see if your preferred forensic suite supports processing the application data you are interested in. Two popular suites are Guidance Software’s EnCase and AccessData’s FTK.
GO GET IT ON THE WEB
If those resources don’t have the information on the application you are interested in, you may have no option but to perform your own research and testing. Again, be sure you have carefully considered the type of case you are working on and the implications if your research is found faulty.
The research you perform for investigating an application has some overlap in the skills necessary for malware triage. This should not be surprising, as one of the primary goals of malware triage is to determine what the malware does. However, in this case, the software is a legitimate application instead of malware. Many of the techniques we discuss in the “Triage Environment” and “Dynamic Analysis” sections of Chapter 15 also apply here. If you find this section of the chapter a bit short on details, we recommend you take a look at Chapter 15 for more information.
• Configure an environment Similar to what is covered in the “Triage Environment” section of Chapter 15, you will need to configure an environment that is conducive to performing your research. Much like when you’re examining malware, it is likely that you will need to frequently re-run tests. A virtual machine with snapshot capability makes this very easy to perform.
• Obtain the application If you do not already have a copy of the application, you will need to obtain one. If the software is freely available, you can simply download a copy. If the software is commercial, you may need to purchase it. However, in some cases, the manufacturers provide trial or demo versions of their software.
• Configure instrumentation Instrumentation is software or tools that allow you to monitor the execution of the application and identify potential artifacts of interest. The instrumentation you can use varies by operating system. The most common operating system we encounter is Microsoft Windows, and one of the best tools is Microsoft’s Process Monitor. The Apple OS X command “dtruss” and the Linux (and other Unix variant) command “strace” display all syscalls that a process makes.
• Perform installation Perform the application installation while your instrumentation is active. You may find useful artifacts during the installation process. Those artifacts may help answer if an application is currently, or was ever, installed on a system under investigation. After the installation is complete, you may want to stop your instrumentation and save the output.
• Execute the application You should try to execute the application consistent with how it is used in the environment that is part of the investigation. You should perform appropriate configuration and execute functionality that is of interest. This will help to produce relevant artifacts.
• Review instrumentation data Once execution is complete, stop the instrumentation and review the output. Output from monitoring program execution often contains thousands of events. You will need to search through the output for events of interest, such as file creation or modification.
• Adjust instrumentation and re-perform testing as needed If needed, you may need to refine your instrumentation to only monitor the paths that the application executables reside in. For example, if you are using Microsoft’s Process Monitor, you may want to add filters to restrict file monitoring. You may need to execute the application multiple times and refine filters until the data collected is easy to analyze.
If the versions of both the application and the operating system do not match your target environment, you may either miss valuable artifacts or send yourself on a wild goose chase for artifacts that do not apply to your situation. As you already know, application artifacts can change between different versions of software. You must take special care to perform your research on the same, or closest, version of the application that is involved in your investigation. In addition, the version of the operating system that you perform your research on may also affect what artifacts the application generates. You should use the same operating system version, including the patch level, that is part of the investigation. |
Now let’s walk through a simple example scenario to help illustrate the process.
In this scenario, you find that an attacker used a Windows GUI application named PuTTY. You found a Windows prefetch entry for the binary, but the application was no longer on the system. PuTTY is a secure shell (SSH) client application you suspect the attacker used to connect to a number of Linux servers. Your investigative question is, “What servers have the attacker connected to?” So let’s see if there is an artifact that’s normally left behind that could help answer that question. Let’s step through the process:
• A Windows XP virtual machine and Process Monitor is ready to go.
• Place a copy of PuTTY in the VM and configure Process Monitor to begin capturing events with an include filter of “Process Name is putty.exe.”
• Double-click the PuTTY executable, and log in to a secure shell server in your environment.
• Wait a few seconds and then disconnect.
• After disconnecting, stop Process Monitor and review the results.
In our test of this procedure, a total of 463 events were captured over 16 seconds. Because there were so few events in this example, it was reasonable to just review them all. As with most applications, interesting events include file creation or modification. However, a review of the events revealed no file-related activity. Under Windows, another common source of evidence is the registry. A review of the events showed a number of RegCreateValue and RegSetValue operations. Of particular note was a RegSetValue operation on a key path of HKCUSoftwareSimonTathamPuTTYSshHostKeys
sa2@22:10.18.0.42. The name of the registry key suggests that is where PuTTY stores the public key for a host that it connects to. In this case, the key value contains the IP address of the host (10.18.0.42).
When you find interesting artifacts like this registry key, it’s best to do some research before jumping to conclusions. In the registry key just mentioned, the name “Simon Tatham” is part of the key path. Because it might be easy to associate the name to the activity on the system, we thought we’d point out that Simon is simply the author of the PuTTY software. Popular search engines are usually very helpful in these situations. |
Based on this information, it seems possible you could compile a list of hosts the attacker connected to by examining the HKCUSoftwareSimonTathamPuTTYSshHostKeys registry key for the user account on the system you were investigating. However, we’d also like to mention a couple ways this information could mislead you in this scenario.
The first potential issue is when there are multiple values under the SshHostKeys registry key. In that case, there is no clear way to determine when each value was created. This is because the Windows registry assigns modification timestamps (not creation), and registry timestamps are assigned to keys, not values. A list of five values could have been created over weeks, months, or even years. You could incorrectly assume the attacker connected to all five, when they may have only connected to the most recent. Also, if PuTTY is a tool normally used in your environment, you may not be able to tell which entries are associated with the attacker and with legitimate use.
The second potential issue is to recognize this registry key is user specific. Be sure to review the registry hive of the user the attacker was logged in as. If the attacker logged in as “Bob,” but you check the “Administrator” user hive, you will not find the registry key and may incorrectly conclude that the attacker did not connect to any hosts. There are certainly other ways to misinterpret the findings; the point is, be careful about the conclusions you draw from limited information.
Now that we’ve discussed general methods to determine what data an application might store, let’s look at some specific categories of applications in detail. We’ve chosen four categories based on our experience that are the most likely to provide you with evidence during an incident response. We cover web browsers, e-mail clients, instant messaging applications, and encryption software. As we go through each category, we cover specific applications that we’ve encountered frequently during investigations. For each application, we discuss where application data is stored, what format the data is in, and what tools you can use to perform analysis. Let’s start with web browsers.
WEB BROWSERS
Web browsers are among the most popular computer applications today. Web browsers are applications that retrieve, process, and present data. Today, that data is most commonly Hypertext Markup Language (HTML) and numerous multimedia formats. When rendered by the browser, the HTML and multimedia are combined to present useful information that is commonly called a “web page.” Your web browser can retrieve data from your local computer or from another computer, commonly called a server or a site, that can be on your local network, in a nearby city, or halfway around the world. Web browsers can also send data back to those servers as part of an interactive process, such as e-commerce, collaboration environments, or a computer game. As the capabilities of web browsers increase, more and more traditional applications, such as word processors and e-mail clients, are becoming “web apps”—interactive sessions within a web browser that closely resemble a traditional application. This trend makes it very important for incident responders to understand how web browsers work.
Throughout the process of sending, receiving, processing, and presenting data, the browser creates many artifacts on a system. Nearly all web browsers maintain the following:
• History As you visit websites, a browser will normally record the Uniform Resource Locator (URL) you accessed, as well as the date and time. This makes it convenient for you to revisit a site you recently browsed to.
• Cache As you access sites, the browser will store local copies of data that is retrieved. This is used to speed up the browsing process, because some items are used repeatedly on a single site or across multiple sites. The default amount of cache saved varies by browser, and can be modified by the user.
• Cookies Cookies are small bits of information that a site may instruct your browser to store. They are commonly used to save site preferences and maintain session information. Most browsers can be configured to restrict (deny) cookies for specific sites or for all sites.
During an investigation, these artifacts can provide critical evidence that allows you to explain what happened. Whether you are investigating the victim of social engineering, or an attacker who logged in to a system and performed malicious actions, web browser artifacts can provide you with useful leads.
Several tools are able to process artifacts from all major web browsers, including the browsers we cover in this chapter. Rather than list them repeatedly in each browser section, we’re listing them once here. Commercial forensic suites, including EnCase and FTK, have the ability to parse most browser artifacts, although support for the most recent versions of browsers tends to lag. The best commercial options for analyzing browser artifacts are tools that focus specifically on browser artifacts. Two tools we’ve found particularly good are Digital Detective NetAnalysis and Magnet Forensics Internet Evidence Finder.
GO GET IT ON THE WEB
Digital Detective NetAnalysis www.digital-detective.co.uk/netanalysis.asp
Internet Evidence Finder www.magnetforensics.com/software/internet-evidence-finder
These commercial tools provide comprehensive browser artifacts analysis. They do not cost as much as a full forensic suite, so they may be a good option for some organizations. There are also many free tools you can use. Free tools tend to focus on a single browser, so we will mention those in each browser section in this chapter. There are at least two exceptions to that—NirSoft’s BrowsingHistoryViewer and Mandiant’s RedLine—both of which can display the browsing history for Internet Explorer, Mozilla Firefox, Google Chrome, and Safari, all in a single view.
GO GET IT ON THE WEB
We’re going to cover the top three web browsers in use today—Microsoft Internet Explorer (IE), Google Chrome, and Mozilla Firefox. According to major sites that track browser use, such as StatCounter, these three browsers account for more than 80 percent of all web browsing activity. In our experience investigating mid-to-large-size corporate environments, Internet Explorer is usually the standard browser. We will start there, and then cover Chrome and Firefox.
Internet Explorer
Internet Explorer (IE) is a closed source web browser maintained by Microsoft. IE is installed by default on the Windows OS and is typically the browser most supported in large-scale enterprises. IE version 1.0 was released in 1995 and was included in the OEM version of Windows 95. Microsoft purchased the underlying technology from Spyglass—the developers of the Mosaic web browser. Internet Explorer for Mac also included versions of IE for Mac OS X. However, Mac OS support has been discontinued for almost 10 years now, so we will not cover Internet Explorer for Mac in this book.
Data Format and Locations
Internet Explorer stores data in a combination of files and registry keys. In this section, we go over the locations of autocomplete, typed URLs, preferences, cache, bookmarks, and cookies first. Then we discuss history, which can be a little more complicated depending on what version of IE you are investigating.
Autocomplete, typed URLs, and preference settings data are all stored in the Windows registry. Autocomplete, sometimes referred to as “form data,” saves inputs that a user has provided in a form. The data is stored in one of two registry keys, listed in the following table. Because the autocomplete data may contain sensitive information, including passwords, IE obfuscates the data. However, there are tools that can “decrypt” this data for some versions of IE—we’ll touch on this later. Typed URLs is a limited history of sites that a user manually types in the address bar and browses to. A corresponding 64-bit Win32 FILETIME timestamp is saved in a second registry key. Preferences are saved in normal registry keys and values, most of which have descriptive names and values, such as “Privacy.” The following table lists the registry locations where IE stores autocomplete, typed URLs, and preferences data:
Artifact |
Location |
Autocomplete |
HKEY_CURRENT_USERSoftwareMicrosoftInternet ExplorerIntelliFormsStorage1
HKEY_CURRENT_USERSoftwareMicrosoftInternet ExplorerIntelliFormsStorage2 |
Typed URLs |
HKEY_CURRENT_USERSoftwareMicrosoftInternet ExplorerTypedURLs
HKEY_CURRENT_USERSoftwareMicrosoftInternet ExplorerTypedURLsTime |
Preferences |
HKEY_CURRENT_USERSoftwareMicrosoftInternet Explorer |
Now let’s go over the cache, bookmarks, and cookies locations. All three of these artifacts are saved as files in the file system. Bookmarks and cookies are individual files within the locations listed in the following tables. Bookmarks are standard Windows shortcut files, and cookies are just plain text files. Temporary Internet files is a cache that contains many files, so its structure is maintained by IE and consists of a number of subdirectories where data is stored. The cached files are unmodified copies of the data that IE retrieves from servers, so the files are viewable with an appropriate viewer for the specific file type. The location of cache, browsers, and cookies depends on the version of Windows. We’ve listed the default locations in the following two tables. The first table lists locations for Windows Vista and newer:
Artifact |
Location |
Cache |
C:Users{username}AppDataLocalMicrosoftWindowsTemporary Internet Files |
Bookmarks |
C:Users{username}Favorites |
Cookies |
C:Users{username}AppDataRoamingMicrosoftWindowsCookies
C:Users{username}AppDataRoamingMicrosoftWindowsCookiesLow |
The second table lists locations for Windows XP and older:
Artifact |
Location |
Cache |
C:Documents and Settings{username}Local SettingsTemporary Internet Files |
Bookmarks |
C:Documents and Settings{username}Favorites |
Cookies |
C:Documents and Settings{username}Cookies |
Now let’s take a look at how IE stores history. Versions 9 and older of Internet Explorer store history in proprietary database files named index.dat. A number of index.dat files will exist per user, for different time ranges of the user’s browsing history. As of IE version 10, Microsoft has dropped the use of index.dat files for history storage and now uses the Extensible Storage Engine (ESE) database format. If you are interested in additional detail on the internal structure of these formats, you can find PDF documents in the Downloads sections of the following websites:
GO GET IT ON THE WEB
Index.dat detail code.google.com/p/libmsiecf
ESE detail code.google.com/p/libesedb
Index.dat The database containing Internet history for IE versions 1–9 is called index. dat. This database file’s contents vary depending on the type of record being stored. If the record is for Internet history, for example, the record stored includes the requested URL, last accessed date, file modified date, and expiration date of the URL. The location of index.dat files on a system depending on their function and the OS used. The following table summarizes the most common locations where you may find index.dat files.
OS |
Locations |
Windows 95 – Windows 98 |
{systemdrive}Temporary Internet FilesContent.ie5index.dat |
{systemdrive}Cookiesindex.dat |
|
{systemdrive}HistoryHistory.ie5index.dat |
|
{systemdrive}WindowsCookiesindex.dat |
|
{systemdrive}WindowsHistoryindex.dat |
|
• MSHist{digits}index.dat |
|
• History.IE5index.dat |
|
• History.IE5MSHist{digits}index.dat |
|
{systemdrive}WindowsTemporary Internet Filesindex.dat |
|
(IE4 only) |
|
{systemdrive}WindowsTemporary Internet FilesContent |
|
.IE5index.dat |
|
{systemdrive}WindowsUserDataindex.dat |
|
{systemdrive}WindowsProfiles{username} |
|
• Cookiesindex.dat |
|
• Historyindex.dat |
|
• HistoryMSHist{digits}index.dat |
|
• HistoryHistory.IE5index.dat |
|
• HistoryHistory.IE5MSHist{digits}index.dat |
|
• Temporary Internet Filesindex.dat (IE only) |
|
• Temporary Internet FilesContent.IE5index.dat |
|
• UserDataindex.dat |
|
Windows XP |
{systemdrive}Documents and Settings{username} |
• Local SettingsTemporary Internet FilesContent.ie5index.dat |
|
• Cookiesindex.dat |
|
• Local SettingsHistoryhistory.ie5index.dat |
|
• Local SettingsHistoryhistory.ie5MSHist{digits}index.dat |
|
• UserDataindex.dat |
|
{systemdrive}Users{username} |
|
• RoamingMicrosoftWindowsCookiesindex.dat |
|
• RoamingMicrosoftWindowsCookiesLowindex.dat |
|
• LocalMicrosoftWindowsHistoryHistory.IE5index.dat |
|
• Lowindex.dat |
|
• index.datMSHist{digits}index.dat |
|
• Lowindex.datMSHist{digits}index.dat |
|
• LocalMicrosoftWindowsTemporary Internet Files Content.IE5index.dat |
|
• LocalMicrosoftWindowsTemporary Internet FilesLowContent.IE5index.dat |
|
• RoamingMicrosoftInternet ExplorerUserDataindex.dat |
|
• RoamingMicrosoftInternet ExplorerUserDataLowindex.dat |
ESE The ESE (Extensible Storage Engine) database replaced the index.dat file functionality beginning with IE version 10. Internet browsing history is stored in a single database file per user. Microsoft has used ESE in the past for LDAP, Exchange, and the Windows Search Index. There are tools on the market that can read and interpret this data, which we cover shortly. The following table lists the location and file names for IE ESE databases:
OS |
Location |
Windows 7 – 8.1 |
{systemdrive}Users{username}AppDataLocalMicrosoftWindowsWebCache |
• WebCacheV01.dat |
|
• WebCacheV16.dat |
|
• WebCacheV24.dat |
The ESE database will have a number of tables in it; each is assigned a purpose on an as-needed basis. To find relevant tables, look within the ESE database for a table named Containers. This table, shown next, lists information about all the other tables in the ESE database and, where relevant, the local directory that stores corresponding data.

For example, the tables associated with history all have a Name value that begins with MSHist. The following article provides more detail on examining the ESE database:
GO GET IT ON THE WEB
History
IE browsing history maintains the URLs visited by the user. These include typed URLs, links followed, and bookmarks clicked. The IE interface provides options for the user to set the maximum history life, to clear browsing history on exit, or to clear the history manually. See the “Preferences” section, later in this chapter, for more information on determining the life of the browsing history. As mentioned in the previous section, the storage of the data varies based on the IE version. In versions prior to IE 10, index.dat files are used. Beginning with IE 10, history is stored in the WebCache ESE database.
Cache
To increase the performance of the web browser, IE caches files in the Temporary Internet locations described previously. However, keep in mind that the user can change the path of the cache in the Website Data Settings dialog under the “Browsing History” Internet options. When revisiting a page, the browser will read the data in Temporary Internet before downloading new content based on the user’s settings. Files in the cache include images, HTML, text, SWF, and other web content. IE allows a user to set the behavior of the cache to check for new content using the following options:
• Never
• Always
• Automatically
These settings allow the user to determine when the browser should check for new content on a page. The “automatic” setting is done by the browser to determine the frequency of visits and number of changes a page has between visits before it checks for new content.
The user can manually clear the cache or set the browser to clear the cache on exit. The cache will maintain files for a number of days, as set by the user (20 by default in Windows 7 running IE 10). In addition, the cache settings limit the amount of disk space to use based on user settings and typically will be between 50MB and 250MB. These actions will delete files from the Temporary Internet location.
Cookies
Cookie settings in the various versions of IE enable a user to accept all, block all, or to accept cookies based on criteria such as the website visited, first- or third-party cookies, and cookies designed to save certain types of information. IE saves cookies in the locations described earlier as plain text files. These files contain arbitrary data as set by the web server the user visited. Cookies can contain data such as form data, the user’s public IP address, timestamps, geolocation, and more.
Bookmarks
Internet Explorer calls bookmarks “Favorites” and saves them as Windows Internet shortcut files. The files are saved in a folder named Favorites under the user’s profile directory. The file extension is .url, and the content is in plain text and viewable with any text editor. Because the bookmarks are actually files, they have the usual timestamps associated with whatever file system is in use.
Tools
Internet Explorer has been around for a long time, and so there are many tools to analyze IE artifacts. In addition to the generic commercial and free tools mentioned earlier in this section, a number of specialized free tools are available that focus on IE artifacts. We’ve found the free tools at NirSoft to be some of the better maintained and accurate tools for IE browser artifact analysis. Although these tools may not provide the robust features of some of the commercial tools, they are still very good.
GO GET IT ON THE WEB
Cache Viewer www.nirsoft.net/utils/ie_cache_viewer.html
History Viewer for IE 4-9 www.nirsoft.net/utils/iehv.html
Cookie Viewer for IE 4-9 www.nirsoft.net/utils/iecookies.html
History and Cookie Viewer for IE 10+ www.nirsoft.net/utils/ese_database_view.html
AutoComplete for IE4-9 www.nirsoft.net/utils/pspv.html
AutoComplete for IE10+ www.nirsoft.net/utils/internet_explorer_password.html
There are some cases when an ESE database is marked “dirty,” causing a problem with some tools. You may need to scan the file to correct this condition. There is a tool called “esentutl” that is built into Windows and can attempt repairs on an ESE database. To use it, run
where <filename> is the path to your ESE database file. Be sure to make a backup copy first!
Google Chrome
Google’s Chrome web browser is a relative newcomer to the browser market. It arrived in 2008 and has steadily grown in popularity to become one of the top three most widely used browsers. Google first released Chrome for Windows in late 2008, then stable versions for OS X and Linux in 2010. Versions for Android and iOS followed in 2012. Google published much of the browser’s source code as part of the open source Chromium project. Google uses Chromium as the base source code and adds in branding and a few features, including a Flash player, PDF viewer, and an auto-updater, before releasing it as Chrome. Chrome versions 27 and older are based on the WebKit engine, whereas 28 and newer are based on a fork of WebKit called Blink. Chrome features a rapid release cycle; Google’s goal is to put out a new version of Chrome every six weeks.
Data Formats and Locations
In the “Chrome” folder is “User Data,” which contains the directory “Default,” which has the bulk of the data about user activities. Chrome stores an incredible amount of information about what a user does, but we limit our discussion here to the artifacts likely to be the most interesting to an incident responder. On currently supported operating systems, the Chrome directory is stored in the user’s profile by default. The following table summarizes those locations across popular operating systems.
Operating System |
Chrome User Data Directory |
Windows XP |
C:Documents and Settings{username}Local SettingsApplication DataGoogleChrome |
Windows Vista/7/8 |
C:Users{username}AppDataLocalGoogleChrome |
Linux |
/home/{username}/.config/google-chrome/ |
OS X |
/Users/{username}/Library/Application Support/Google/Chrome/ |
Within the Default directory are a number of files and folders; the amount has grown steadily as new versions of Chrome added additional features. Chrome stores most of its data in SQLite databases and JavaScript Object Notation (JSON) files, and most of these files have no extension. You can examine both of these file types easily using a number of different tools, both free and commercial. Tools will be covered in more depth a little later. Within these files, you will encounter a number of different timestamp formats. Chrome uses both a millisecond version of Unix (epoch) timestamps as well as the WebKit time format. The following blog article has more information about the different time formats that Chrome uses:
GO GET IT ON THE WEB
History
The “urls” and “visits” tables in the file “History” combine to provide the typical browser history data: what websites were visited and when. Chrome saves a few extras in addition, such as typed_count, visit_count, and transition (how the user arrived at that page). Because the History file is just a SQLite database, you can retrieve this data in a number of ways. One of the simplest methods would be to query the database with a command-line tool, such as sqlite3. The following query would produce a very simple view of a user’s browsing history:

The file Archived History is a stripped-down version of History that tracks activity older than three months. It drops a few of the ancillary tables Chrome uses and keeps the core “urls” and “visits” tables, both of which have the same structure and columns as in History.
The History Index files are artifacts than have the potential to be a goldmine. The “omnibox” (address/search bar combination) is a key feature of Chrome that other browsers have moved to emulate. Users can start typing into the omnibox, and Chrome will provide suggestions from many sources; one source is the user’s past browsing activity. The “History Index” SQLite files contain text elements from web pages the user has visited, stored in a way that allows Chrome to very quickly search all that text for keywords. The end result for investigators is that in addition to the URLs of visited websites, we also potentially have access to text content of what the user was looking at stored in these files. Multiple history index records can exist for the same web page at different times, so we even have the potential to view “snapshots” of changing content.
Cache
Like other modern browsers, Chrome uses a cache to store downloaded files that may be used again to speed web page load times and reduce the need to go out and re-download every page element every time. The cache can hold valuable information that can often be used to reconstruct visited websites as the user saw them, allow investigators to view the source code of the websites, and review images or other supporting files. Chrome’s cache is located at User DataDefaultCache and always contains a minimum of five files: index, data_0, data_1, data_2, and data_3. The index file contains a hash table detailing where each file in the cache is stored. The other files are called “block” files, because each data_x file stores data in fixed sized blocks. If a file that is to be cached exceeds the maximum size one of these block files can handle (16KB), it is stored in the cache folder as its own file. When this happens, the file is renamed to “f_” followed by a number of hex digits. Although these f_files have no extension, if all you want is a quick triage of the cached files, you could use signature analysis to reveal their format without having to parse the block files (although text-based files, like HTML pages, are compressed). The block files contain any metadata that was saved, such as HTTP headers and the file’s name and address.
Cookies
The file Cookies contains all cookies the browser saves; Chrome uses a database rather than many individual text files. The host_key column stores the domain that set the cookie. The other fields likely to be of interest to an incident responder all have fairly descriptive names: name, value, creation_utc, and last_accessed_utc. The timestamps are stored in WebKit format. Cookies may also contain interesting bits of identifying information, such as hints to the user’s geographical location (ZIP or area codes, latitude/longitude coordinates) or identity (usernames or e-mail addresses).
Downloads
The History file also contains details about files that a user saves using Chrome. Old versions of Chrome have all this data in the “downloads” table; newer versions (v26 or later) split it between downloads and downloads_url_chains. All versions of Chrome retain the downloaded files’ URL, total size, how many bytes were actually downloaded, and the time the download started. More recent Chrome versions also track when the download finished, if the file was opened, and if Chrome thought the file was malicious; these last two new features may provide easy wins for incident responders in some investigations.
Autofill
Chrome’s autofill feature is designed to aid users by remembering what they typed into a text field on a website and automatically filling (“autofilling”) the value in if the user encounters a similar form on a different site or visits the same site again. In order to do this, Chrome records what a user enters into each text field, the name of the text field, and the timestamp. The website the user typed the text into is not explicitly saved, but can be inferred by correlating timestamps with other Chrome artifacts. Chrome stores the autofill data in a number of different tables in a SQLite database in the file Web Data. The autofill feature is enabled by default, so unless the user turned it off, this file should contain some interesting data.
Chrome stores a user’s bookmarks in a JSON object in the file Bookmarks (a duplicate copy is stored in Bookmarks.bak). The bookmark file is easily readable in a text editor or a JSON viewer. Chrome saves the date the bookmark was added, its URL, the bookmark title, and the folder structure of the bookmarks.
Preferences
User preferences are stored in the file Preferences as a JSON object (User DataDefaultPreferences). There are a number of tidbits that may be of interest in the Preferences file, including a list of what extensions and plugins are installed. If a user is using Google Sync for Chrome, the Preferences file details what items are synced, when the last sync was, and the associated Google account. Some settings reveal a little about directory structure of the host file system; for example, savefile.default_directory, selectfile.last_directory, and download.default_directory may contain paths that reveal locations of interest on the file system. Other preferences of potential interest include autofill.enabled, browser.clear_data, and browser.clear_lso_data_enabled.
One last preference that may be of interest to an incident responder is profile. per_host_zoom_levels. This preference tracks when a user zooms in or out on a website so Chrome can remember that setting for the next visit. One quirk of this particular preference that makes it interesting from a forensic perspective is that as of the current version of Chrome (v27), the domains listed here will persist despite all browser history being cleared. Because this only gives the top-level domain (not the full URL) and the user must have changed zoom settings to create the artifact, it is of limited use, but it is still worth checking out.
Tools
Because Chrome is the youngest of the major browsers, fewer forensic tools support Chrome compared to the other browsers. Chrome’s rapid release cycle and the sheer number of versions of Chrome also present a challenge for tool developers; changes between versions sometimes alter artifacts, and forensic tools are slow to catch up. Chrome’s auto-update feature works in the background to keep Chrome up to the latest version with any user interaction. This results in fewer older, less secure versions of the browser in use; however, the downside is that some forensic tools won’t work as well with the more prevalent newer versions of Chrome.
Because most Chrome artifacts reside in either SQLite databases or JSON files, you can retrieve them in a number of ways. One way is to directly access the data. A great number of free tools are available to read SQLite and JSON formats. SQLite Database Browser and the Firefox extension SQLite Manager are popular GUI tools to access SQLite databases, and sqlite3 is a free command-line browser. If you have coding experience, popular scripting languages Python and Perl also offer the ability to easily access both formats.
GO GET IT ON THE WEB
SQLite Database Browser sourceforge.net/projects/sqlitebrowser
Firefox SQLite Manager extension addons.mozilla.org/en-us/firefox/addon/sqlite-manager
sqlite3 www.sqlite.org/download.html
Perl www.perl.org
Python www.python.org
In most cases, though, you will probably want a more comprehensive tool that parses Chrome artifacts and provides you with a useful display of the data. Even though Chrome is a relatively new browser, because of its rapidly growing popularity, there are many free and commercial tools from which to choose. In addition to the commercial tools mentioned at the beginning of this section, the following free tools are available that can parse and present Chrome artifacts:
GO GET IT ON THE WEB
NirSoft ChromeHistoryView www.nirsoft.net/utils/chrome_history_view.html
NirSoft ChromeCacheView www.nirsoft.net/utils/chrome_cache_view.html
Woanware ChromeForensics www.woanware.co.uk/forensics/chromeforensics.html
All of these tools support analyzing a live system—which should rarely be needed—as well as choosing a specific directory where your evidence is located. Next we will look at the Mozilla Firefox browser.
Mozilla Firefox
Firefox is an open source multiplatform web browser. Beta versions were initially released in 2002, under the name “Phoenix.” Due to trademark issues, the name was changed to Firebird, and then finally to Firefox in 2004. Firefox was forked from the Mozilla application project, which was based on work done in the 1990s by Netscape Communications Corporation. Firefox quickly rose in popularity, but leveled off during 2010. Starting with Firefox version 5 in June 2011, the Firefox development team changed their release strategy. They began what was called “rapid release”—their intent was to release a new version, or branch, every six weeks. The stated reason for this change was to more quickly bring new features to users. However, as of December 2013, Firefox was at version 26 and its use was in slow decline, mostly due to Google Chrome’s increasing popularity.
Data Formats and Locations
Mozilla and Chrome have a number of similarities in the way they store data. Mozilla, like Chrome, stores nearly all of its data in files, and Mozilla uses SQLite and JSON formats for most of its data storage. The data is stored in directories under the user’s profile, according to the following table:
OS |
Location |
Windows Vista and newer |
C:Users{username}AppDataRoamingMozillaFirefox
C:Users{username}AppDataLocalMozillaFirefox (Cache) |
Windows XP and older |
C:Documents and Settings{username}Application DataMozilla
C:Documents and Settings{username}Local SettingsApplication DataMozilla (Cache) |
Linux |
/home/{username}/.mozilla/firefox /home/{username}/.cache/.mozilla/firefox (Cache) |
OS X |
/Users/{username}/Library/Application Support/Firefox /Users/{username}/Library/Caches/Firefox (Cache) |
For a given operating system user, Firefox can maintain multiple profiles—although most users generally have only one. The data for each Firefox profile is stored in an eight-character randomly named directory with an extension of “.default” under the Profiles directory—for example, e91fmfjw.default. In Windows and OS X, Firefox places these profile directories in a sub-directory named “Profiles.” Under Linux, the Firefox profile directories are in the “firefox” directory—there is no additional Profiles directory layer. One nice thing about Firefox data is that, in general, a given version of Firefox uses the same file names across all operating systems. In addition, the file names have been the same since around the time Firefox version 5 was released. The naming convention we’ve seen Firefox follow is detailed in the following table:
Some of the Firefox SQLite databases make use of newer or optional SQLite features, which prevents some versions of sqlite tools from opening them. If your SQLite tool is failing to open one of these databases, be sure you have the latest version of the tool. Even if you are using the sqlite3 command-line tool, you may need to use the most recent version from the SQLite website.
Firefox cache is stored in a series of folders that are managed by Firefox. Just like other browser data, Firefox maintains cache in separate directories for each Firefox profile. Firefox creates 16 directories, 0–9 and A–F, in a directory named “Cache.” The Cache directory is found in the location path for cache we listed in an earlier table, under the corresponding Firefox profile directory. In this book, we will not cover the internal details of Firefox cache storage, but you can find good documentation on the Internet, including these locations:
GO GET IT ON THE WEB
Firefox has user-configurable settings to “clear history,” which includes all of the previously mentioned artifacts. Firefox can clear history on demand, and can also be configured to clear history on exit. We’ll touch on where you can see these settings shortly.
In the following sections, we talk a little bit more about each Firefox artifact. With most of these artifacts, you will want to use a tool designed for this task instead of manually attempting to query the SQLite databases. We’re only adding some extra detail so you understand a little most about where the data resides, so if you have trouble with a tool you can investigate. A number of useful tools are listed at the end of the Firefox browser section.
History
Firefox stores a user’s browsing history in the SQLite database places.sqlite. Two tables store the basic browsing history data: moz_places and moz_historyvisits. The records in these tables are linked between the id field in moz_places and the places_id field in moz_historyvisits. A SQL query very similar to the one we used with Chrome history will also provide you with a basic display of the user’s browsing history.
Downloads
Each time a file is downloaded, Firefox stores information about the download in addition to standard history entries. Firefox download information was originally stored in its own SQLite database named downloads.sqlite. The schema was quite simple, with data in a single table named moz_downloads. Beginning with version 20 of Firefox, changes that came with a new download manager moved download tracking into a table named moz_annos in the places.sqlite database. The older downloads.sqlite database is no longer used.
Bookmarks
In Firefox version 2 and older, user bookmarks were stored in an HTML file. You can view the file with any web browser or text editor. Version 3 of Firefox came out in 2008, and bookmarks were moved into the moz_bookmarks table of the places.sqlite database. The entries in moz_bookmarks are linked to an entry in moz_places using the bookmarks field “fk” to link to the places “id” field. This link is important because the moz_bookmarks table does not contain the URL of the bookmark—it’s in moz_places.
Autofill
Autofill, or form history data, is stored in the formhistory.sqlite SQLite database. A tabled named moz_formhistory contains form history data records. The records are simple key/value pairs, with additional metadata such as the first time the value was used, the last time, and the total number of times. Form data is typically not useful during most intrusion investigations, but can be very useful in other types of investigations.
Cookies
Firefox stores website cookie data in the cookies.sqlite database. A single table, moz_cookies, contains all the data for each cookie saved. In some investigations, the cookie itself is useful, but during most incident response scenarios you’ll be mainly interested in the domain names and timestamps associated with any cookies.
Preferences
Firefox has many user-configurable settings. They are all saved in a file named prefs.js. The file is plain text and can be viewed with any text editor. Some of the preferences have a large impact on the availability of browser artifacts. Specifically, Firefox can be configured to clear browser artifacts on exit, or to never save history at all. Users can also clear artifacts on demand through the user menu. The following table lists the Firefox settings that affect creation of browser artifacts:
Setting |
Effect |
user_pref(“browser.privatebrowsing.autostart”, true); |
When true, Firefox will not save any history. |
user_pref(“privacy.sanitize.sanitizeOnShutdown”, true);
user_pref(“privacy.clearOnShutdown.offlineApps”, true);
user_pref(“privacy.clearOnShutdown.passwords”, true);
user_pref(“privacy.clearOnShutdown.siteSettings”, true); |
When true, Firefox will clear history, including the specified artifacts, on exit. |
user_pref(“browser.cache.disk.capacity”, 358400); |
This setting limits the size (in KB) of the Firefox browser cache. If it’s set to a low number, Firefox will not have as many cache artifacts. |
The Firefox cache stores local copies of content that is retrieved from websites and other servers a user visits. By default, the Firefox cache is limited to 350MB of data. Older, infrequently used data will be cycled out as needed. As with any other cache, the primary reason is to speed up the user experience—many downloaded items are reused. During an incident, the cache may store copies of data from malicious sites a user visited, or perhaps even save data from websites an attacker viewed while in control of a computer. The user can clear the Firefox cache and other artifacts (such as cookies) manually through the Firefox user menu.
Tools
As you may have already guessed, a SQLite database browser is one tool you can use to examine many of the browser artifacts Firefox creates. Although using SQLite is a manual and often tedious method, it is sometimes necessary due to bugs or unsupported features in the more full-featured tools. A number of SQLite database browsers were mentioned earlier in this section.
As with Internet Explorer and Chrome, the commercial and free tools we mentioned at the beginning of the “Web Browsers” section are good options for performing analysis of Firefox artifacts. There are additional free tools that are specific to Firefox, and some of the best we’ve seen are authored by NirSoft:
GO GET IT ON THE WEB
History Viewer www.nirsoft.net/utils/mozilla_history_view.html
Cookie Viewer www.nirsoft.net/utils/mzcv.html
Cache Viewer www.nirsoft.net/utils/mozilla_cache_viewer.html
Downloads Viewer www.nirsoft.net/utils/firefox_downloads_view.html
E-MAIL CLIENTS
There are many types of investigations where e-mail is a key source of evidence. In intrusion investigations, a common initial attack vector is spear phishing—this is when an attacker targets victims with social engineering e-mails. In scareware scams, attackers sometimes send e-mail from faked or stolen e-mail accounts. In other criminal activity, miscreants may use e-mail to coordinate activity or transfer data. And finally, don’t forget that e-mail accounts are also a direct target—some attackers are interested in stealing e-mail. In all these cases, it is important to know what common e-mail applications are in use and understand where data is stored, what is stored, and how to analyze it.
The most basic piece of data is the e-mail it itself. E-mail content contains two main sections—one called the “body” and one called “headers.” The body is the actual content of the e-mail, such as text or attachments. It is common for the body to be encoded in the Multipurpose Internet Mail Extensions (MIME) format. This encoding standard was created so newer multimedia contents are handled correctly as the e-mail passes through different types e-mail systems. The headers consist of handling information, such as the sender’s e-mail address, the recipient’s e-mail address, a sent date, a subject, a list of servers the e-mail was passed through, and many other possible fields.
E-mail headers can be extremely complex to decode. If you are looking for some extra help, the following Internet resources should be of assistance. Be careful with the Google Apps link, though, because you probably don’t want to paste sensitive data into the site.
GO GET IT ON THE WEB
In this section, we look at artifacts related to four of the most popular e-mail clients we encounter: Microsoft Outlook for Windows, Microsoft Outlook for OS X, Apple Mail, and Web Mail. Before we look at each one in detail, we’d like to talk briefly about dealing with e-mail formats. There are many different e-mail clients beyond what we cover in this section. Using the general leads from the “Where Is Application Data Stored?” section, you should be able to locate artifacts related to any e-mail client. The next challenge will be analyzing that data. We’ve found the tools Aid4Mail and Emailchemy are able to convert data from many different e-mail clients into more common formats. Many other e-mail conversion tools are available, which you can easily locate with any major Internet search engine.
GO GET IT ON THE WEB
Following this general process should enable you to review data from nearly any e-mail client you come across. For example, you could convert Eudora Mail into standard mbox format and open the resulting output with the free Mozilla Thunderbird e-mail client. Now let’s move on and talk about Web Mail.
Web E-Mail
According to numerous surveys in 2012 and early 2013, use of traditional computer-based e-mail clients, such as Microsoft Outlook, has become a small portion of the overall market share. The surveys indicate that web and mobile-based e-mail now accounts for more than 50 percent of all e-mail clients, although our experience suggests there is still heavy use of “thick” clients, such as Microsoft Outlook, within many corporate environments. Examples of web mail services include Gmail, Hotmail/Outlook.com/Live.com, AOL, and Yahoo!, as well as mobile e-mail on Apple iPhones and Android devices. Most of these services also provide contact, calendar, and chat capabilities.
Web-based e-mail services present a significant challenge for an incident responder. Most services do not store e-mail content on a local system. Because a user accesses services through a web browser, or an application that emulates one, there are few artifacts other than browser artifacts. You can read more about the challenges associated with web-based e-mail, and some tips how to deal with them, in the following articles:
GO GET IT ON THE WEB
We’ve found that some users configure a “thick client,” such as Microsoft Outlook, to download e-mail from their web-based services. In those cases, it’s likely there is a local copy of the web-based e-mail. You can use the procedures we outline later in this section to locate and analyze the e-mail. |
Because web-based e-mail systems continuously change, the best approach to discovering artifacts is to use a well-maintained specialized tool. Traditional forensic analysis suites (commercial and free) will normally find some artifacts, but are usually not as comprehensive as specialty tools. To get the best results, we recommend using a tool such as Magnet Forensics Internet Evidence Finder, Digital Detective’s NetAnalysis, or Siquest Internet Examiner Toolkit (formerly CacheBack). These tools are relatively expensive, but they will be well worth your money if you frequently need to examine web-based e-mail.
GO GET IT ON THE WEB
Internet Evidence Finder www.magnetforensics.com/software/internet-evidence-finder
NetAnalysis www.digital-detective.co.uk/netanalysis.asp
Internet Examiner Toolkit www.siquest.com
If those tools don’t help in your situation, you can perform a comprehensive timeline around the times in question. Include all aspects of the system, such as browser history, file system, registry, logs, and other sources of evidence. Be sure to look at the browser section in this chapter for the browser type involved for additional ideas and pointers. In some cases, these steps may provide enough findings—or at least some leads—to be useful.
If the situation merits, you may be able to gain access to the e-mail account through user consent, search warrant, or other appropriate legal procedures. Given the challenges to discovering useful artifacts, it should come as no surprise that these types of requests are increasing over time. But be sure to follow local policy and laws, consult with legal counsel, and fully document any attempts to gain access to an e-mail account. It’s easy to get yourself into legal hot water when dealing with e-mail, so involve your legal counsel early and consult with them throughout the process.
Microsoft Outlook for Windows
One of the most common e-mail clients we encounter is Microsoft Outlook. Although versions for both Windows and Apple operating systems exist, the most common we encounter is Windows. Outlook has been around since the late 1990s, and supports a number of different e-mail server protocols. For example, Outlook can connect to Post Office Protocol (POP), Internet Message Access Protocol (IMAP), Microsoft Exchange, and a number of web (or HTTP) based services. There are many third-party add-ins that extend Outlook’s capabilities to support other e-mail protocols, encryption methods, integration with mobile devices, social networks, and other capabilities. Microsoft uses proprietary data storage techniques to store not only e-mail, but also data such as calendars, tasks, and contacts.
Data Storage Locations
Outlook stores data in different directories and with different file names, depending on the operating system version and the e-mail server protocol. The following table lists the default locations of Outlook data files for common Windows operating systems:
Operating System |
Path |
Windows Vista/7 |
C:Users{Windows_profile}AppDataLocalMicrosoftOutlook{login_name}.ost
C:Users{Windows_profile}DocumentsOutlook FilesOutlook.pst |
Windows 2000/XP |
C:Documents and Settings{Windows_profile}Local SettingsApplication DataMicrosoftOutlook{E-mail_account_name}.pst
C:Documents and Settings{Windows_profile}DocumentsOutlook FilesOutlook.pst |
Of course, those directories are where the files should be. Outlook allows you to configure alternate locations or additional data storage files. A reliable place to check for data files that are configured in Outlook is the Windows registry key HKEY_CURRENT_USERSoftwareMicrosoftOffice{version}OutlookSearchCatalog, where {version} is the “short” Office version number. The following table contains a list of the most common versions of Office and the corresponding short version number:
“Friendly” Version Name |
Short Version |
Microsoft Office XP |
10.0 |
Microsoft Office 2003 |
11.0 |
Microsoft Office 2007 |
12.0 |
Microsoft Office 2010 |
14.0 |
Microsoft Office 2013 |
15.0 |
Outlook also has the ability to configure multiple “profiles.” Each profile has its own settings, including e-mail servers, e-mail addresses, signatures, and data files. All of the Outlook data files for all profiles will be listed in the registry key we mentioned, but for investigative purposes, sometimes it’s good to know that there are multiple profiles and what their names are. Outlook profiles are listed as keys under HKEY_CURRENT_USERSoftwareMicrosoftWindows NTCurrentVersionWindows Messaging SubsystemProfiles. When multiple profiles are on the same system, it may be important to know which profile is the default profile. You can examine the registry key HKEY_CURRENT_USERSoftwareMicrosoftWindows NTCurrentVersionWindows Messaging SubsystemProfilesDefaultProfile to determine which profile is configured as the default Outlook profile. Also, with multiple profiles on the system, the Outlook data files will have “ - {profile name}” appended to their name when new data files are created. This is done to create a unique name for each data file that belongs to a specific profile. Deleting a profile using the Windows Control Panel | Mail administrative feature does not delete the associated data files.
Data Format
Outlook uses a file format called the Personal Folder File (PFF). In a Microsoft Exchange–based environment, Outlook will store a copy of e-mail offline in a file called the Offline Storage Table (OST), which is a form of PFF. In non-Exchange environments, such as Post Office Protocol (POP), or in Outlook archives, the file format used is the Personal Storage Table (PST), also a form of PFF. These files will also contain additional data such as calendar appointments and contacts. Because both of these forms are based on the PFF format, most tools that parse OST will also parse PST, and vice versa.
GO GET IT ON THE WEB
Libpff Project code.google.com/p/libpff
Even though the PFF format is proprietary, there is good documentation from third parties. The Downloads section of the Libpff project website contains several very good documents on the PFF format. If you are interested in learning all the gory details of the PFF format, we recommend you take a look at those documents.
Tools
There are two categories of tools you can use to analyze OST and PST files:
• Commercial forensics tools Guidance Software’s EnCase and AccessData’s FTK can parse and analyze OST and PST files natively. For example, within EnCase, you can simply right-click the file and select View File Structure. EnCase displays the e-mail data file contents as a tree that you can browse and search just like a file system.
• Open source tools The best maintained and documented open source project we know of for OST and PST parsing is “libpff.” This project provides the code to compile an executable called “pffexport,” which can export items from an OST or PST file. In Windows, you can compile the libpff tools using an environment such as Cygwin.
Because not everyone has access to a commercial solution, let’s take a closer look at how to use the open source libpff tools.
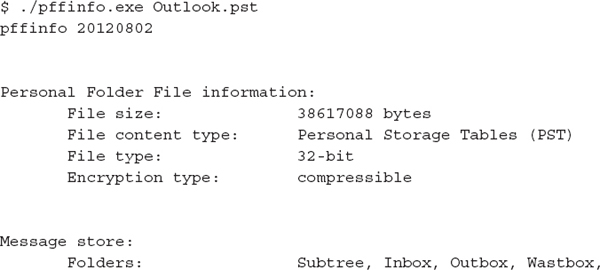
The libpff tools are distributed from the tool’s author as source code only. This means you must compile, or build, the source code into an executable file before you can use it. The libpff website has a good wiki article on how to build the libpff tools on a number of operating systems, and with a number of build toolsets. Once you have the tools built, you can use pffinfo.exe to display basic information about the file. Here’s an example:
To extract the data from this PST file, you will use pffexport.exe. The following command tells pffexport to extract all available item types from the source file Outlook. pst and create a log file named outlook.pst.log:
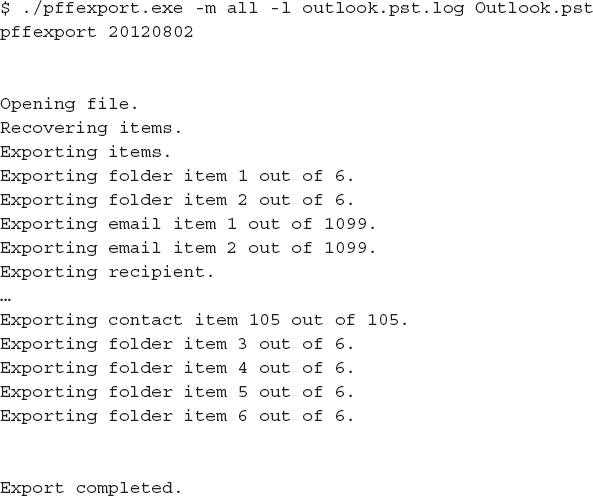
By default, pffexport places all extracted data in a directory that is named after the source file with “.export” appended to it. In that directory will be a number of other directories. Depending on the mail protocol used and user configuration options, the mail data may be in one of several folders. The quickest way to find mail is to search for folders named “Inbox” or files named Message.txt or Message.rtf, as shown next. Pffexport creates a sequentially named folder for each item, such as an e-mail, and places all related data in it, including the message body, headers, and attachments.

Apple Mail
Apple Mail is a built-in e-mail client that comes with Apple’s OS X operating systems. Apple Mail supports the POP, IMAP, and Microsoft Exchange e-mail protocols. Apple Mail is a popular OS X e-mail client because it is built in and has support for all major e-mail protocols. We see it used heavily by individuals and small to mid-size organizations. Larger environments also use Apple Mail, although Microsoft Outlook for Mac tends to be more popular in that setting—which we’ll cover in the next section.
Data Storage Locations
Apple Mail stores all user data under a single directory: /Users/{profile}/Library/Mail. Recent versions of Mail will create a directory for each account configured under the directory V2. For example, data for an IMAP account named [email protected] would be placed under /Users/{profile}/Library/Mail/V2/[email protected]. The folder structure under this directory will correspond to the structure in Bob’s IMAP account. If you dive into this structure, you will notice that each folder contains additional layers before you get to actual e-mail message files. An example of a full path to an e-mail message file is /Users/{profile}/Library/Mail/V2/[email protected]/INBOX.mbox/25892e17-80f6-415f-9c65-7395632f0223/Data/Messages/1.emlx.
Data Format
E-mail messages in Apple Mail versions 2 and newer use the “emlx” format, which is in plain text. Therefore, you can view and search the e-mail message files using any test-based tool.
Tools
Because Apple Mail e-mail messages are stored in plain text, you can use many tools to examine them. Basic command-line tools, such as grep or strings, may be all you need to locate messages of interest. More robust GUI-based search tools, such as PowerGREP, are also very effective. You can also convert the emlx format into standard mbox, and use a free e-mail client such as Mozilla Thunderbird to view the e-mail.
GO GET IT ON THE WEB
PowerGREP www.powergrep.com
Emlx to Mbox Converter www.cosmicsoft.net/emlxconvert.html
Mozilla Thunderbird www.mozilla.org/en-US/thunderbird
Commercial tools such as EnCase have a built-in combination of capabilities that present the e-mail data in a more familiar tree-based format that is easier to review.
Microsoft Outlook for Mac
Microsoft Outlook comes as part of the Office for Mac Home & Business edition. Most of features and layout that Microsoft implemented in Outlook for Windows are the present in the Office for Mac version of Outlook. Outlook’s features are also similar to Apple Mail; however, Outlook for Mac allows users to set up Exchange server-side rules and integrate with other Exchange and Microsoft enterprise features, such as Lync. Therefore, Outlook for Mac is more popular in larger environments—we do not often see Outlook for Mac in small organizations or personal use.
Data Storage Location and Format
Microsoft Outlook for Mac 2011 stores user data under the directory /Users/{profile}/Documents/Microsoft User Data/Office 2011 Identities. By default, there will be a single identity, named “Main Identity,” under the Identities directory. Users can manage identities using the Microsoft Database Utility, which is installed with Office for Mac Home & Business. Each identity can have one or more e-mail accounts associated with it. All settings and data for an identity are stored in a series of directories under the corresponding identity directory.
Microsoft uses a proprietary database to track Identities and all related data. The database file is named “Database,” and is maintained in the Identities directory. In Entourage, the older Microsoft e-mail client for Mac, most user data was in the Database file, including messages and other content. This caused performance issues, and resulted in a new storage scheme for content.
There is a new directory under Identities named “Data Records,” and Outlook content is kept in a series of files and directories under it. Data Records contains a number of subdirectories, one for each major content type, such as Message Source, Contacts, and Categories. Within each content directory, data is stored in directories with no more than 1,000 files per directory. Microsoft names the folders using the convention nT/nB/nM/nK, where n is a sequential number and T/B/M/K are trillion/billion/million/thousand, respectively. With this scheme, content files only exist in the nK directories. The files are named with an extension of “olk14{content type},” where {content type} is a string such as “Schedule,” “Message,” “MsgSource,” or “Recent.”
E-mail message content is found in the Message Source directory under Data Records. The files have an extension of “olk14MsgSource” and are in a proprietary format that usually includes the message content as plain text ASCII, Unicode, or both.
Tools
The Outlook for Mac 2011 storage methods make it somewhat difficult to effectively analyze without a more comprehensive tool. You can attempt to use standard text-processing tools such as grep and strings, but be careful because of possible Unicode characters. A tool that specifically supports Outlook for Mac 2011, such as Aid4Mail or Emailchemy, is recommended. Not all tools support properly handling Unicode, and even though it may just be standard ASCII characters in Unicode format, they may not handle them properly.
INSTANT MESSAGE CLIENTS
Instant message (IM) clients provide a way for individuals to communicate with each other in near real time. The communication can be two way, or can involve multiple parties in a group chat session. IM clients have evolved to include technologies such as file transfers, voice chat capabilities, videoconferencing capabilities, voice-to-telephone chats, and can even record and save voicemail. Unlike with e-mail communications, chat participants have the ability to see if their chat partners are online, offline, away, and more, depending on the client.
Numerous IM clients have been developed over time, and there are many options for IM users. Most users have preferences based on the capabilities of the client, ease of use, familiarity, security, or just general personal preference. Because of user demands for additional features, security, and bug patches, chat clients continue to evolve. Most IM clients are updated frequently, and it’s impossible for us to cover all versions in a book. Therefore, we discuss general methodology and test environments in addition to examples of some of the more popular clients and their capabilities.
Methodology
The frequent updates of IM clients will require you to be able to properly test each client to ensure that the results returned from any tool or method used are accurate. We recommend that you use a documented methodology for testing. This can help ensure you are not embarrassed or wrong in any conclusions you draw based on an analysis of an IM client.
1. Test environment The best test environment would include using the same operating system version and client version that is part of the investigation. This may not always be possible, in which case you will need to consider how confident you can be with the results. As covered in previous sections, we recommend a clean installation of an operating system or a clean VM (virtual machine) so that cross-contamination is eliminated or kept to a minimum.
2. Common Instant Message technology IM clients are commonly based on similar technology. These technologies define how a client transmits or stores data. Knowledge of these protocols and languages will help you understand the changes in the test environment. Knowledge of the technologies behind an IM client can also help you locate messages in the page file, memory, or unallocated space on a device. Some examples of commonly used technologies are:
• HTML The HTML (hypertext markup) language is commonly used to create simple web pages. HTML text can be formatted with elements defined in the language, including fonts, colors, embedding pictures, and more. AIM (AOL Instant Messenger) message logs are saved as HTML files when logging is enabled.
• XML The Extensible Markup Language (XML) is a language designed to be both human readable and machine readable by the use of arbitrary tags designated by the application designer. Windows Messenger creates IM logs stored as XML documents.
• SQLite SQLite is an open source relational database format used to store plain text and binary data. Many Mozilla-based applications store data in a SQL or SQLite database.
• SOAP The Simple Object Access Protocol (SOAP) is a method of transmitting data using various protocols and XML while maintaining an ordered structure. Yahoo! and Gmail artifacts are often XML documents embedded in a SOAP wrapper.
Instant Message
As mentioned previously, many different IM clients are currently available, and we cannot cover them all. In this section, we intend to provide an overview of some of the common protocols and clients available. IM clients vary in the way they store and transmit information and in their capabilities. Where practical, we specify the version of the IM client the information presented applies to. This is necessary because IM clients change frequently.
Skype
Skype was originally developed as an independent Voice over IP (VoIP) client by the same Estonian developers who worked on Kazaa—a peer-to-peer file sharing utility. Microsoft purchased the technology in 2011 and is transitioning from Windows Live Messenger to Skype. Skype uses a hybrid of client-server and peer-to-peer protocols for communication.
Skype’s features include VoIP, video calling and teleconferencing, file sharing, and private and group chat sessions. The basic chat functionality and voice calls to other Skype users are free. Calls to landlines or cellular phones are charged a fee based on region of origin and destination.
GO GET IT ON THE WEB
Log Storage Log files for Skype are located in a user’s profile. Logging is enabled by default, and the default history setting is “forever.” Specific log paths are determined by operating system as listed in the following table:
Operating System |
Path |
Windows Vista/7 |
C:Users{Windows_profile}AppDataRoamingSkype{Skype_profile} |
Windows 2000/XP |
C:Documents and SettingsApplication DataLocalSkype{Skype_profile} |
Linux |
/home/{Linux_profile}/.Skype/{Skype_profile}/ |
OS X |
/Users/{user}/Library/Application Support/Skype/{Skype_profile}/ |
Log Format Chat logs are maintained as a SQLite3 database file named main.db. This file contains database tables that include chat conversations. You can open the database with a SQLite browser. Instant messages are in the Messages table in the database. The format of a message in the database begins with the Skype profile name on the system, followed by a separator (/$), and then the dialog partner’s Skype name. Here’s an example:
When both chat partners are known, you can use this to search for additional messages in the page file, memory, and unallocated areas on a device.
Using a SQLite browser, such as SQLiteSpy, you can load main.db and query the data with SQL statements. You can run this simple query to display all messages stored in the database:
GO GET IT ON THE WEB
The fields in the table include body_xml, author, and timestamps. Timestamps are stored as Unix Epoch time in UTC.
Artifacts Skype maintains additional artifacts in the main.db database. These can be viewed using a SQLite3 browser. Additional data includes calls, groups, contacts, and voicemails. A SQLite3 browser listed the following tables in Skype version 6.3.60.105:
Voicemail artifacts in the main.db file list a path to the voicemail stored as a DAT file. The DAT file is an audio file that uses a proprietary codec from Skype. You can use your own installation of Skype to play voicemails from other systems using the following procedure:
1. Create a voicemail in Skype on your analysis system and locate the DAT file in the profile path.
2. Overwrite the DAT file you created with the voicemail DAT file from your investigation.
3. Play the voicemail in Skype by choosing the voicemail you replaced.
Preferences Skype preferences are stored primarily in an XML file named config.xml in the user’s profile directory. Be sure to consider that each user profile directory can contain a Skype preference file—a single computer may have many preference files. A number of XML fields have “plain English” labels. The contacts for a Skype profile are stored in the config.xml file under:

Each contact will have a tag of its own. For example, if the contact’s profile name is skype.user, you would see data within the following tags:
If chat history is configured to be logged, the number of days kept will be in the tag:

Be aware that the history days will have a value, even when history is disabled. Look for the following tag to see if history is disabled:
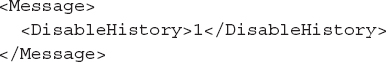
If the value is 1, history is disabled and the HistoryDays tag is ignored. Additional tags of interest include the following:

Tools Many commercial tools are available for parsing Skype history. You can also examine the main.db file using a SQLite3 browser, and you can run native SQL commands on the database to search for Skype history and artifacts. The XML configuration document can be viewed with any standard text editor or web browser. Several popular commercial tools to examine Skype history are listed next:
GO GET IT ON THE WEB
SkypeAlyzer www.sandersonforensics.com
Skype Analyzer home.belkasoft.com/en/bsa/en/Skype_Analyzer.asp
Skype Log View www.nirsoft.net/utils/skype_log_view.html
Facebook Chat
The popular social media site Facebook provides a built-in web-based text and video chat client. Facebook users can use the client to communicate with anyone in their “friends” list that has chat enabled. The client logs data by default to the user’s Facebook profile as “messages” on the server. If the recipient is not available at the time a chat is sent, Facebook servers will place the message in their inbox—similar to sending an offline message to the user. All chats therefore take place through the web-based client—there is not a local install of software. This presents a challenge if you don’t have access to the user’s account on Facebook through a search warrant or other legal process.
Log Storage Facebook logs are not stored on a user’s system. Because the system is web based, Facebook chat messages are stored on Facebook servers. While the web client is active, the messages may be manually copied out of the message window using normal copy/paste commands. Otherwise, it is possible that artifacts of the chat sessions are present in memory, page files, hibernation files, unallocated space, or in Internet browser cache files. Those artifacts are present through indirect processes and are not stored by design. Therefore, the presence of artifacts is unpredictable, and, even when present, may be incomplete or inaccurate.
Log Format Facebook chat messages in memory are formatted in JavaScript Object Notation (JSON). When sent as a chat message, the message is stored with the tag “msg” with the following fields:
• “text” (includes the body of the message)
• “messageID”
• “time” (message time in UTC as a Unix millisecond timestamp)
• “from” (the Facebook ID of the sender)
• “to” (the Facebook ID of the recipient)
• “from_name” (in plain text)
• “to_name” (in plain text)
• “sender_offline” (false if the chat partner was online at the time the message was sent)
Here is an example of a message (the full Facebook IDs were sanitized with xxxx):

It’s unlikely you will find Facebook chat messages in Internet browser cache files. Main memory is the most common place to find messages. At least one tool, Internet Evidence Finder (IEF), can carve memory images for chat fragments. Additionally, you can try keyword searches for portions of the JSON message format, such as the following:
• {“msg”:
• {“text”:
• “from”:
• “id”:
The last two can be particularly useful if you know the Facebook ID of the sender and recipient. Each individual message sent or received will have a tagged wrapper, making the process tedious if the image contains a large number of messages.
Artifacts Facebook artifacts can remain in Internet browser cache files, the page file, memory, or unallocated locations. Facebook running natively in a browser does not store logs or preferences offline intentionally.
Tools Partly because Facebook does not store logs on a user’s local system, very few commercial tools have been created to parse Facebook chats. A tool that can parse Facebook chat messages, along with many other evidence items, is Internet Evidence Finder (IEF). IEF can analyze a memory image for Facebook chat items, including all of the JSON fields we outlined in the Facebook “Log Format” section.
GO GET IT ON THE WEB
America Online Instant Messenger (AIM)
AOL Instant Messenger (AIM) has been available as a standalone chat client since 1997. The client uses an AOL proprietary protocol named Open System for Communication in Real-time (OSCAR). Although the number of users actively installing AIM has dropped in recent years, it is still widely used for communication. Features in AIM include chat, group chat, video chat, file sharing, and SMS since version 8.0.1.5. The client also allows for direct communication to Facebook, Twitter, Google Talk, and Instagram.
GO GET IT ON THE WEB
Log Storage Beginning with AIM version 8.0.1.5, message logs are not stored locally by default. You will have to follow the proper legal procedures to obtain AIM message logs for a user. However, the user may enable local logging using the “Save a copy of my chats on this computer” option under AIM Preferences | Privacy shown here:

If the user configures AIM to store logs locally, they are stored in the Documents folder under the profile of the user. For example, in Windows 7, the profile folder will be C:Users{Windows_Profile}DocumentsAIM Logs{AIM_Profile}. Within this folder, the logs are stored in a subfolder for the AIM login name used. The log files are stored as a file with the chat partner and service used as the log name. Here are two examples:
Log Format AIM logs are stored as HTML. Messages are contained in the <tr> tag. Each message has a separate line that includes a Unix timestamp in UTC, a local field that includes the message timestamp as the local time of the system, and a message field that includes the message body. Here is an example of a message:
The fields in this message are as follows:
• ts Unix timestamp in UTC
• “local” Local or remote author who sent the message, along with a local system timestamp
• “msg” Includes the message body
Artifacts As of AIM version 8.0.1.5, the software is no longer installed in the program files directory. The new default installation directory is the user’s profile directory. The installation path is typically C:Users{Windows_profile}AppDataLocalAIM. To verify this, you can examine the registry key HKCUSoftwareMicrosoftWindowsCurrentVersionUninstallAIMInstallLocation to determine the AIM installation directory, as shown here:
Preferences The majority of user preferences for version 8 of AIM are stored on the server. The settings are inherited from local installation to local installation and cached in a local SQLite database in the path listed:
Operating System |
Path |
Windows Vista |
C:Users{profile}AppDataAOLAIMcacheLocal Storagehttp_www.aim.com_0.localstorage |
Windows 2000/XP |
C:Documents and Settings{Windows_Profile}Local SettingsApplication DataAOLAIMcacheLocal Storagehttp_www.aim.com_0.localstorage |
OS X |
/Users/{profile}/Library/Application Support/AOL/AIM/cache/Local Storage |
The SQLite database contains a single table named ItemTable, with a simple key/value pair scheme that is used to store locally cached preferences. If local logging is turned on, this database will also store chat message history as key/value pairs. Here is an example of a session where we use the “sqlite3” command under Cygwin to display the database schema (the “.schema” command) and display all records (the “select * from ItemTable” command):

Tools Because AIM logs are formatted as HTML, any text viewer or web browser can be used to view the message logs. Carving for message tags (such as --><td class=”local”>) can be used to locate messages in memory images, the page file, and unallocated space. The preferences SQLite database can be viewed by any popular SQLite database tool. Also, a free Windows-based time conversion tool named DCode is very useful when dealing with non-human-formatted dates and times:
GO GET IT ON THE WEB
During an investigation, operating system artifacts are only part of the picture. Application-related artifacts will add to your understanding of an incident, and sometimes may be your only source of evidence. Keep in mind, however, that the operating system may leave application artifacts in unexpected places—like free space or the Windows page file—that are beyond the control of the application.
In this chapter, we covered three major application areas where we find evidence—Internet browsers, e-mail clients, and instant messaging clients. We also touched on a few other applications that have provided us with useful evidence on more than one occasion. Because there is no way for us to cover all common applications, you should take the time to become familiar with the applications used in your organization. Compile information similar to the format of the sections in this chapter—data storage locations, data format, and tools. Coupled with the techniques and information we’ve gone over, you will be well armed to investigate applications and solve the case!
QUESTIONS
1. During an investigation, a database administrator discovers that hundreds of SQL queries with a long execution time were run from a single workstation. The database did not record the specific query—just the date, time, source, and query execution time. You are tasked to determine what queries were executed. How would you proceed?
2. You begin investigating a Windows 7 computer, and quickly notice that there is no C:Users directory. Assume the data was not deleted. Provide a realistic explanation of why there is no C:Users directory, and how you can get access to the user data.
3. As you are investigating a Windows XP system, you find operating system artifacts that indicate the attacker ran heidisql.exe multiple times. Assuming the file name is the original name of the program, what do you suspect the application was? What registry key or keys would you examine to determine additional information about what the attacker did?
4. You are investigating what artifacts an application creates on a Windows 8 system. You notice that under the AppData directory, the application is storing information in multiple directories: Local, LocalLow, and Roaming. Why would the application do that? What is the purpose of the different AppData directories (Local, LocalLow, and Roaming)?
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.