

Remediation Introduction
Effective incident response requires a two-pronged approach: incident investigation and incident remediation. So far, however, much of this book has focused on investigation-related topics such as incident preparation, data collection, and analysis. However, remediation is just as important as the investigation, and deserves its fair share of coverage. In this edition of the book, we’ve dedicated two full chapters to remediation topics. This chapter will be the “classroom,” where we discuss remediation fundamentals, and the next chapter will be the “field,” where we apply those fundamentals to the scenarios that were presented back in Chapter 1.
Our goal in this chapter is to familiarize you with how to create a comprehensive remediation plan. A comprehensive plan requires substantial effort to create and will address all aspects of even the most challenging incidents. Not every incident requires a comprehensive plan, but if you understand how to create a comprehensive plan, you should be able to handle any scenario. In the beginning of this chapter, we introduce basic remediation concepts. We then examine each of those concepts in detail and conclude the chapter by connecting the concepts to a sample scenario.
BASIC CONCEPTS
Remediating large incidents is a complicated process. To help explain all the relevant aspects, we’re going to introduce some basic concepts in this section. Those concepts include high-level remediation steps, remediation action types, and common factors critical to a remediation. A remediation plan is commonly organized into two parts—the first part concentrates on remediating the current incident (posturing, containment, and eradication actions) and the second part concentrates on improving the organization’s security posture (strategic actions). As with any complex endeavor, the more planning that goes into the remediation effort, the smoother the remediation process will be.
The draft remediation plan reflects all actions the remediation team believes the organization can realistically complete prior to an eradication event. We’ve found that the plan is revised many times during an investigation, because action items that are initially believed to be easy to implement turn out to be more difficult than anticipated. We usually shift these items into the strategic recommendation list, unless they are absolutely necessary for success.
When an item on the initial remediation plan turns out to be too much effort for an eradication event, you should decompose the item, select the parts with the greatest impact for the eradication event, and move the remainder to a strategic plan. An example is the recommendation to implement two-factor authentication globally. A number of our clients have been unable to support this on an enterprise scale before an eradication event, so a subset of users can be selected. The two groups of users selected for the tactical process change might be executives of the company and all system administrators. Then, the rollout to everyone else can be pushed into the long-term plans. This helps to contain the attackers, if they return. |
Although it may be tempting, making wide, sweeping changes to improve your security posture during an incident is not advisable—wait until after the incident is over. An easy way to develop the initial remediation plan is for the team to brainstorm actions based on each area of the Remediation Planning Matrix, which we present later in this chapter.
The level of detail necessary in a remediation plan varies from incident to incident. Some organizations choose to create a very detailed plan including Microsoft Project workflows, Excel spreadsheets, and other documents. Others rely on a minimum level of detail at the highest levels while trusting their people to handle the details. The correct level of detail for the remediation plan is whatever the remediation owner needs it to be in order to ensure the plan is comprehensive and, most importantly, implementable. We are not going to cover specific ways of documenting the various parts of the remediation plan in this chapter. The next chapter will contain a sample remediation spreadsheet and plan.
Figure 17-1 depicts the remediation process as a flowchart. Each step of the flowchart is explained in more detail throughout this chapter. If you find the remediation process difficult to follow, you should continue to refer to the flowchart. Because the remediation process is complex, you will need to read the entire chapter in order to fully understand the process and how to properly implement it.

The remediation process consists of the following eight high-level steps:
1. Form the remediation team. Remediation teams are formed only when an incident is declared and incident ownership is assigned. We presented the formation of an investigation team in Chapter 2. The remediation team is similarly structured, with representatives from legal, IT (both infrastructure and helpdesk), security, and business line managers.
2. Determine the timing of the remediation actions. Business leaders, in coordination with the legal, remediation, and investigation teams, must decide what actions begin immediately and what is delayed until the investigation is over. In our experience, this varies widely depending on the incident, the rate of the investigation, and the type of information that could be in jeopardy.
3. Develop and implement remediation posturing actions. Posturing actions are implemented while the incident is ongoing and often include enhancements to system and network monitoring, mitigating critical vulnerabilities, and preparing support teams for enterprise-wide changes, such as password resets or two-factor deployments. Most posturing actions are nearly indiscernible from normal maintenance by an attacker.
4. Develop and implement incident containment actions. Containment actions are designed to deny the attacker access to specific environments or sensitive data during an investigation. Containment actions are often disruptive short-term solutions that are implemented in a very short amount of time.
5. Develop the eradication action plan. The goal of the eradication plan is to remove the attacker’s access to the environment and to mitigate the vulnerabilities the attacker used to gain and maintain access. These actions are clearly documented, and the team should spend time rehearsing them in a way that does not disrupt the investigation. This step of the remediation process is typically executed at or near the conclusion of the investigation, once the attacker’s tools, tactics, and procedures are well understood.
6. Determine eradication event timing and implement the eradication plan. There is a point in the investigation where a “steady state” is reached. At this point, while additional system compromises may be discovered, after analysis, no new tools or techniques are discovered. It is important to understand that the eradication event must be well planned and executed at the right time in order to be successful. When the investigative team has a good grasp of the tools, techniques, and processes being used, the eradication step is executed. This step also includes the post-monitoring and verification of eradication activities.
7. Develop strategic recommendations. Throughout the investigation and remediation process, you should document areas for improvement. These notes are the basis for strategic recommendations, which will help improve the security of your environment. Strategic recommendations often consist of remedial actions that cannot be implemented prior to, or during, the investigation. Quite often, strategic recommendations align directly with well-documented information security best practices. Furthermore, strategic recommendations typically require significant cross-functional working groups to implement. These activities may disrupt business and are often expensive to implement. Strategic actions typically occur months to years following an eradication event.
8. Document the lessons learned from the investigation. Documentation that is generated as a result of an investigation should be stored in a central location. This location should be restricted to incident responders only, given the potential sensitivity of the documentation. This information will be invaluable to help your organization improve over time. Examples of the expected documentation are reports developed and notes about the environment,
The remediation effort should be concise and effective. If your remediation team attempts to enact significant changes in a tactical situation, there is a real risk that the result will be rushed and incomplete. Understand what your team (and the organization) is capable of acting on quickly, and push other tasks into the strategic recommendations documentation Implementing a small number of effective changes is usually more effective than trying to implement a large number of actions that are less relevant to the incident.
There is no single strategy to a successful remediation effort—the right remediation strategy depends on a number of factors specific to each incident. Based on our experience, the seven most common factors critical to the remediation effort are as follows:
• Incident severity The incident severity will dictate the type of remediation implemented. The severity of an incident is something each organization needs to decide for itself. For example, a bank experiencing real-time loss is more likely take immediate containment and eradication actions than a defense contractor that is breached by an unknown attacker. The type of incident can also change the severity. Remediation of a breached external web server that only contains public information is much less severe than remediation of an incident where an attacker obtained domain administrator credentials An organization with a mature incident response process will have documented various incident severity levels so an incident responders can determine the proper severity and approach quickly.
• Remediation timing Stakeholders should agree on the tentative timing of the remediation actions at the beginning of the planning process. Some efforts are designed to immediately remove the attacker’s access to sensitive systems or data, whereas others are designed to allow the investigative team time to gather enough information to comprehensively remove the attacker from the environment while simultaneously strengthening defenses. Although it is not possible (or even advisable) to strictly adhere to a timeline developed before the incident was well understood, it is important to have aggressive timelines to ensure the incident response is performed in a timely manner.
• The remediation team There are three primary concerns with incident remediation teams—the size of the team, the skill level, and management support. The size of the team may affect the team’s ability to coordinate and ensure proper execution of simultaneous actions. The team’s skill level will dictate how thorough the remediation effort can be. An experienced remediation team will be more comfortable taking customized approaches, whereas a less skilled team may want to keep the remediation effort within their comfort zone. Management support will ensure the remediation team has the authorization and financial resources to properly implement remediation actions to secure the environment.
• Technology The type of technology in place will affect how you implement remediation actions. This includes security technology as well as enterprise management technology. For example, your organization may have software to assist with changing local administrator account passwords throughout an enterprise. An organization that does not have this software may have to develop a script to change the local administrator account password on every system.
Implementing new technology during an ongoing incident will usually cause more problems than it is worth. Every resource (people, time, and money) spent on the new technology is a resource not spent on the investigation or remediation. There are exceptions to this statement, of course, such as an organization with very skilled and mature IT and security teams or situations where the new security technology is critical to the successful remediation of the incident. |
• Budget An organization with a large IT and security budget can purchase and implement best-of-breed technology, whereas an organization without a large budget may have to implement less expensive compensating controls. Additionally, the remediation effort must make sense in the context of the incident and data being protected. Spending more money protecting assets than the assets are worth usually does not make business sense.
• Management support Most comprehensive remediation efforts require an organization to implement changes that affect day-to-day operations. For example, implementing a unique local administrator or root account password on all systems may require system administrators to change how they interact with systems. Securing management support will help ensure that even the most painful remediation actions are implemented and supported throughout the organization.
• Public scrutiny Your legal or PR team may be required to disclose information about an incident due to regulatory requirements. In some cases, information is made public due to an information leak or third-party discovery. In other cases, the attacker may try to extort the victim company by threatening to make the compromise or stolen information public. In any of these cases, your organization should carefully review any statements it intends to make about an incident. Some organizations rush to release information, in an attempt to show they are “doing something.” However, as the investigation team discovers more information about the incident, you may have to revise information previously released. Amending publicly disclosed information can be embarrassing and may force the organization to perform damage control against public backlash. Incidents that include significant public commentary or scrutiny may cause the remediation effort to be driven by public perception rather than fact.
An example of a regulatory requirement that forces an organization to disclose an incident is the Health Insurance Portability and Accountability Act (HIPAA). Under HIPAA, any loss of data that constitutes Protected Health Information (PHI) or Personally Identifiable Information (PII) triggers various notifications. It is often advantageous for a company that must disclose that it lost PHI or PII to include the containment steps taken or being implemented. This lets the public know that action is being taken to stop the loss of data and to further protect it. This also forces the remediation team to focus on immediate containment. An example of third-party involvement that may cause public scrutiny is when a reporter breaks a story about the compromise of an organization without informing the organization first.
Notification requirements for the loss of PII data vary greatly between the U.S. federal government, individual state governments, and foreign governments. If you are involved in an incident that includes the loss of PHI or PII data, you should ensure that legal counsel and your PR department are involved from the beginning of the incident. |
Now that we’ve introduced the eight high-level remediation steps, we’re nearly ready to go into greater detail. Before we do, however, a couple pre-checks should be performed before forming the remediation team. Let’s talk about those pre-checks first, and then we’ll dive into the details of each remediation step.
We recommend you perform two pre-checks prior to forming the remediation team. The first is to ensure your organization has committed to a formal response to an incident. A response will consume many man-hours of time and may redirect key individuals and teams to deal with the incident before their other projects. This may sound unnecessary, but it is important that senior management communicate the decision to declare the incident response, and all team members should only begin response procedures once they’ve received that communication.
The second pre-check is to verify that an incident owner has been assigned. The incident owner provides leadership for key stakeholders within the organization, the incident investigation team, and the incident remediation team. All incident teams must coordinate and communicate with the incident leader to ensure a cohesive incident response. That will be difficult if you don’t know who was assigned—or worse—one isn’t assigned.
Now, with your pre-checks complete, it’s time to look at the details of the first step—forming the remediation team.
FORM THE REMEDIATION TEAM
We discuss three areas related to forming the remediation team. The first is understanding when you should create the remediation team, the second is understanding the role of the remediation owner, and the third is understanding who should be part of the remediation team.
When to Create the Remediation Team
Based on our experience, the remediation team should be established as soon as an investigation is initiated. This allows the remediation team to start working on planning the remediation effort immediately. Once the incident owner decides on the timing of the remediation actions, the team should be able to start developing the posturing and containment actions and planning for the eradication event.
Running the incident investigation and remediation teams in parallel will help reduce the amount of time from discovery of the incident to the eradication event. The time from incident discovery to eradication is known as the “time to remediate.” One goal of information security organizations is to strive for a low mean time to remediate (MTTR). Some organizations have even defined metrics around the acceptable MTTR-specific types of incidents. For example, if a piece of malware is discovered on January 25, the investigation determines that the system was compromised on January 15, and the system is rebuilt on January 26, then the mean time to remediate is 24 hours (incident detection occurred on January 25 and eradication occurred on January 26, which is 24 hours). Even though the compromise was not detected for 10 days, having a low mean time to remediate is important. Given that many organizations do not detect the compromise themselves, but have to be notified by a third party, ensuring a low mean time to remediate is as important as detecting an incident as quickly as possible.
Next, let’s talk about assigning a remediation owner.
Assigning a Remediation Owner
The most important aspect of forming the remediation team is assigning a remediation owner. The remediation owner accepts responsibility for the overall remediation effort and interacts with both technical and nontechnical personnel. In addition to the technical areas traditionally associated with incident response, the remediation owner needs to understand nontechnical areas such as data flows, business operations, company strategy, public relations, human resources, and legal. Because the team will consist of both technical and nontechnical personnel, a senior technical person is likely the best remediation owner. There are situations where a good project manager may be able to effectively lead a remediation effort if they are surrounded by an effective team; however, a strong senior technical person will usually be more effective. The senior technical person should be someone who has solid technical experience as well as experience dealing with the other aspects of the business. This experience will allow them to provide better direction to their team and to better advise the business on the ramifications of implementing certain actions. The victim organization must also ensure that the remediation owner has full management support to make decisions and act accordingly.
Many aspects of the remediation effort are difficult to implement and cause some amount of disruption to the business. A strong remediation owner must motivate the team and push difficult remediation action items to completion. This requires an individual with a lot of energy, who can effectively resolve disagreements. An example of a difficult remediation action is forcing a coordinated login account password change throughout an environment. It is generally easy to change standard user account passwords; but local administrator accounts, service accounts, and credentials built into applications and scripts are often challenging to change. In addition, many remediation efforts require that all of these account passwords be changed within a short, defined period (such as 24 to 48 hours). This type of action is generally not well received by the staff who must implement it—there will be pushback and questions as to why such a demanding task must be done. Unfortunately, a single missed account could render the remediation processes invalid.
Sometimes a single person has responsibility for the investigations and the remediation, especially with less complex incidents. However, if the incident is complex and/or pervasive throughout a large environment, the incident, investigation, and remediation owners should be separate people. This will ensure that the respective owners will focus appropriately on their area of responsibility.
When assigning ownership of the remediation effort, you should look for five key qualities in an individual. These qualities are essential, even though each incident and remediation is different. The five qualities are listed next, followed by a more detailed discussion of each one:
• In-depth understanding of IT and security
• Focus on execution
• Understanding of internal politics
• Ability to communicate with technical and nontechnical personnel
An understanding of IT and security is critical for the remediation owner because they must work directly with the technicians responsible for developing remediation actions and determine the feasibility of those actions. They will also have to be able to understand the incident and the investigation well enough to be able to provide the team with appropriate technical direction. We have experienced many situations where laziness and complacency would have prevailed if the remediation owner had not understood IT well enough to override certain technical objections. An understanding of IT and security may be the most overlooked quality of a good remediation owner—many companies assume good project managers make good remediation leads because of their background in efficiency and planning (both of which are important, but not as much as technical understanding).
The remediation owner must execute. Some people refer to this quality as “operations focused.” Whatever you may call it, the remediation owner needs to understand how to develop, gauge, and produce results. They need to be good at assigning tasks, enforcing accountability, following up on assigned tasks, and ensuring completion of tasks. Developing a comprehensive remediation plan is meaningless unless it is implemented appropriately and in a timely manner. The ability to make quick decisions based on limited information, though not always necessary, can be important. Most remediation efforts run into unexpected complications, budget overruns, and exceeded timelines. For example, if the remediation effort accidentally alerts the attacker that you are aware of their presence, the remediation owner needs to be able to act quickly to counter any offensive actions taken by the attacker. The remediation owner must make quick decisions based on a fluctuating situation and project confidence.
An understanding of internal politics is critical for the remediation owner to ensure the right remediation actions are implemented with minimal business impact. Understanding internal politics can mean the difference between approval and disapproval for a difficult remediation action. For example, if the remediation team owner knows that the CIO is typically reluctant to implement sweeping changes, that person should spend time with the CIO and discuss the processes that may be required during an investigation. If expectations are set before the organization is under the pressure of an incident response, actions deemed necessary to remediate are far easier to implement.
The remediation owner must also be able to build support for the remediation plan. Many difficult decisions will be made, such as causing an outage of business systems that will cost the organization money. The remediation owner needs to be able to gain support from key stakeholders (typically executives, business line owners, and senior engineers) to ensure an effective remediation. Oftentimes, garnering support for various initiatives means being able to successfully convey an understanding of the risk and reward to business leaders. Successfully conveying complex technical concepts to nontechnical personnel is an essential skill in these circumstances. No executive wants to hear how implementing a security measure will protect the business if that measure impedes the business from functioning. Rather, they want to understand how the security measure will enhance the security of the business and protect its interests. Even difficult remedial actions that require the business to operate in a different manner moving forward may gain support and be implemented when properly conveyed to senior management.
The ability to communicate with both technical and nontechnical personnel is critical for the remediation owner. He needs to be able to work with his technical personnel to understand the recommendations and ensure they are in the best interest of both the remediation and the organization’s security posture. The remediation owner also needs to be able to speak intelligently to executives, in their language, to properly explain the risks and benefits from the various remediation actions. For example, the remediation owner needs to be able to properly convey the risk to the business of shutting down Internet access for all systems as the first step in a comprehensive eradication event. Executives cannot afford to misunderstand a drastic step such as disconnecting from the Internet, which will obviously affect the business for a day or two.
Members of the Remediation Team
In Chapter 2, we spent time describing the composition of the investigation, remediation, and ancillary teams. As a refresher, the remediation team should consist of at least the following types of individuals: someone from the investigative team; system, network, and application representatives; and various other subject matter experts (if applicable). The remediation team needs to have the expertise and authority to implement changes as necessary. Chapter 2 also discusses ancillary team members that can be critical to the remediation, but are more task oriented. Some examples of these ancillary team members are representatives from internal and external legal counsel, compliance officers, business line managers, human resources, public relations, and executive management.
Here are some reasons these team members are so important:
• An investigative team member will be able to offer valuable insight about the attacker’s activities and what mitigation steps can be taken. They will also know what immediate remediation actions would alert the attacker (if the delayed remediation approach is taken).
• System, network, and application owners will best understand the feasibility of recommended actions and their effects on the organization. Their understanding of systems and applications will allow them to offer alternative suggestions if the initial recommendation is not feasible.
• Various subject matter experts (SMEs) will be crucial when a nonstandard system, such as a classified system or Industrial Control System (ICS), is involved in the remediation.
• Representatives from the ancillary functions will be able to provide valuable insight and support to the nontechnical issues the remediation team is expected to encounter.
Many incident response teams include a representative from legal (either internal or external counsel, or both) from the beginning of the incident response. This helps ensure that all parties are appropriately advised from a legal perspective from the beginning. In some cases, especially when an outside firm is brought in to assist with the incident response, having external counsel involved can help protect privilege in the case of a lawsuit. |
One of the first tasks the remediation team must do is to select a remediation approach. In the next section, we’ll talk about the different types of remediation approaches and some of the considerations associated with each one.
DETERMINE THE TIMING OF THE REMEDIATION
There are three approaches to remediation action: immediate, delayed, and combined. The incident owner, in conjunction with the investigation and remediation team owners, should decide on the remediation approach before any remediation work is started. The correct approach will depend on the seven most common incident factors critical to the remediation effort that we discussed earlier in this chapter. Sometimes it’s difficult to determine the proper remediation approach at the onset of an incident response. Based on our experience, the “delayed action” remediation approach should be used as the default approach taken until evidence from the investigation proves that another approach is warranted. Details about the three types of remediation approaches are listed next:
• Immediate action This approach is used to stop the incident from continuing (incident containment). This remediation approach should be implemented when it is considered more important to immediately stop the attacker’s activities than to continue the investigation. The immediate action remediation approach often alerts an active attacker that the organization is aware of their malicious activities. This is the appropriate remediation approach for many incidents with an active attacker.
Some examples of when this remediation approach is likely appropriate are when an organization is losing money in real time, such as through Automated Clearing House (ACH) or credit/debit card fraud; when a malicious insider is copying data to an external USB drive and is about to sell the information to a competitor; and when the incident is small, such as a single compromised system. This remediation approach is likely not appropriate if the attacker has compromised hundreds of systems and implanted multiple backdoor families—immediate action in this case would only cause the attacker to change their tools and techniques, which will cause the investigation team to re-scope the compromise.
• Delayed action This approach allows the investigation to conclude before any direct actions are taken against the attacker. Throughout the investigation, care is taken not to alert the attacker. This remedial approach should be implemented when the investigation is at least as important as the remediation. This is the most common remediation approach for incidents involving intellectual property (IP) theft or where the intelligence gained from monitoring the attacker’s activities outweighs the need to contain the activity. Some examples of when this remediation approach is more appropriate are corporate espionage and when an attacker compromises hundreds of systems, requiring an investigation to fully scope the compromise.
In some cases, law enforcement may ask you to delay remediation in order to allow their investigation to continue, so they may learn more about the attacker, or to provide time to make an arrest. This situation can work to your benefit because you may be able to delay public notifications, if they are necessary.
• Combined action This approach implements containment on only a specific aspect of the incident, while letting the rest of the incident continue. This remediation approach is often used when incident containment is more important than the investigation; however, a full investigation and remediation effort is still warranted. This remediation approach is most common in large environments that are able to remediate only part of their environment quickly. For example, an organization may choose to remediate a compromised business unit as quickly as possible to immediately protect the rest of the organization, but choose to remediate the remaining business units over a longer period. This remediation approach is also most common in incidents involving the near real-time theft of money or critical business data. For example, if an attacker has gained access to credentials used to create and authorize ACH transactions, the victim organization needs to immediately remove the attacker’s access to the system. However, the organization also needs to fully scope the compromise and implement a comprehensive remediation effort to ensure the attacker does not still have access to the environment. In this case, immediately preventing the attacker from accessing certain systems is more important than removing their access to the environment, although the attacker’s access to the environment still needs to be removed.
With the team formed and the remediation approach determined, the team needs to step into action. In the next section, we discuss the team’s first task—to create posturing and containment plans that are consistent with the selected remediation approach.
Let’s discuss posturing actions first. Posturing actions are taken during an ongoing incident and are designed to be implemented while having little impact on the attacker. The actions are designed to enhance the investigation team’s visibility by implementing additional logging and monitoring. Posturing actions can be critical to an incident response because they enhance the investigation by adding additional sources of evidence and decrease the amount of time spent on the later phases of the remediation effort. Here are some high-level examples of typical posturing actions:
• Enhance logging, including the following logs:
• System-specific logs
• Application-specific logs
• Networking logs
• Central authentication logs
• Centralize log files and management (security information and event management [SIEM] implementation)
• Enhance alerting
• Patch third-party applications
• Implement multifactor authentication for access to critical environments
• Reduce locations where critical data is stored
• Enhance the security of native authentication
Many of these actions can be addressed by improving the type of data retained by endpoints. Enabling command history and process auditing, as well as ensuring all authentications are being properly logged, are some common and easy posturing actions to implement on Linux systems. For Windows systems, ensure that Microsoft Windows auditing is configured to log Success and Failure events. The specific audit events that are logged will depend on the goal; however, here are some of the more common events to enable:
• Audit account logon events
• Audit account management
• Audit logon events
• Audit object access
• Audit privilege use
• Audit process tracking
• Audit system events
Enabling Microsoft Windows “Success” events for audit policies “Audit object access” and “Audit process tracking” may quickly fill the local Security event log file. If that happens, your event logs will contain entries for only a very short period. This drastically reduces the effectiveness of the logs. You should closely monitor the effects of your changes to logging policies. The maximum size of the log files may need to be increased or the events may need to be sent to a centralized logging system. |
One common security misconception is that logging only denied (Failure) activity will help catch malicious activity. We’ve seen many organizations focus on looking for failed activity, thinking that’s where malicious activity will be logged (the thinking is that if it’s bad, it will be disallowed and will therefore be categorized as failed activity). Although there are certainly situations where this is true, if you’re investigating an active attacker, you need to see what the attacker is being allowed to do (hence the active attacker). In order to gain full visibility into an incident, you need to log and monitor allowed (Success) activity in addition to Failure activity. For example, if an attacker is able to gain access to legitimate credentials, all malicious activity will show as “allowed” by the “legitimate” user. Monitoring only for denied or failed activity would miss this set of activity. |
Another common posturing goal is to increase the security of an application, system without alerting the attacker. Prior to implementing these changes, you should present your plan to the investigation team—they will have an opinion on whether or not the attacker will notice the changes. Here are some examples of posturing actions:
• Remove LANMAN hashing throughout a Windows environment.
• Strengthen password security requirements.
• Patch commonly targeted third-party applications.
• Implement multifactor authentication to a critical environment the attacker has not yet compromised or discovered.
• Fix an application flaw the attacker used to gain initial access into the environment.
In some instances, it’s acceptable to remove a compromised system from the environment; systems are rebuilt, reclaimed, or left offline while the user goes on vacation all the time. Attackers expect to encounter some amount of flux in a large environment. However, if 25 of 30 infected systems suddenly go offline and remain offline for a couple of days, the attacker will most likely think they’ve been discovered. If that happens, the attacker may change their tools or techniques, and the investigative team will have trouble identifying the scope of the attack again.
Another posturing action that may benefit the investigative team is to stop all legitimate use of known compromised credentials, issue new user accounts to the users whose accounts were compromised, and implement monitoring and alerting for the known compromised user accounts. This approach ensures that, as of a specific date, all activity from known compromised accounts should be considered malicious. This increases the investigation team’s ability to discern malicious user account activity from legitimate activity. This can be especially difficult to accomplish when system administrator accounts are involved.
Implications of Alerting the Attacker
Taking actions that alerts an attacker they’ve been discovered is usually considered detrimental to an investigation. An attacker who becomes aware that they are detected will likely react. In some cases, the attacker’s reaction is benign—such as when the attacker feels confident with their ability to maintain their presence in the environment or if the attacker has accomplished their mission and does not have a reason to remain in the environment any longer. However, here are some of the more common reactions we’ve seen:
• Change in tools, tactics, and procedures This will cause the incident responders to focus on reacting to the changing attacker activity rather than on investigating the past activity. This also causes the investigation team extra work—they must track all the changed tools, tactics, and procedures (TTPs) while continuing to investigate the past activity to make sure nothing is missed. Other times the investigation team may lose visibility into the attacker’s activities entirely. In some cases, the change in TTPs may be so severe that your organization is forced to remediate activity immediately, which causes the incident response teams to focus on eradication instead of the investigation. This may allow the attacker to install new mechanisms for maintaining access to the environment without the incident response teams noticing, thus compromising the entire effort.
• Become dormant If the attacker becomes dormant, it may cause the incident responders to miss evidence of malicious activity and allow the attacker to remain hidden in the environment during the eradication event, only to become active afterward. Some common techniques attackers use to go dormant are to implant malware that communicates to its command-and-control (C2) server every couple of months, to remove all malware and only access the environment through remote access means (such as a business peer connection or VPN), to implement webshells in the demilitarized zone (DMZ) that are not used until the attacker believes the incident response team is finished, and to park all malicious domain names in innocuous-looking IP addresses (such as an IP address owned by Google).
Some attackers like to “park” their domains by resolving them to IP addresses such as the localhost (127.0.0.1), broadcast address (255.255.255.255), multicast addresses (224.0.0.0–239.255.255.255), or Class E (IANA reserved) IP addresses (240.0.0.0–254.255.255.255). However, some of this activity is easily detected by any IDS/IPS and is not considered stealthy. More skilled attackers will resolve their domains to IP addresses that do not stand out. |
• Become destructive Although rare, some attackers will go on the offensive in order to change the incident response focus from responding to past activities to spending time recovering from damages. Some examples of destructive behavior are deleting files from systems, defacing web pages, and crashing systems. In one case we worked, a system administrator discovered that an attacker was remotely connected to a server and was performing malicious activity. The system administrator disconnected the attacker from the server. The attacker ultimately responded by disconnecting the system administrator’s RDP connection to the server. The attacker then disabled the system administrator’s user account and finished their malicious activity.
• Attempt to overwhelm the organization with compromised systems In one incident we worked, every night the attacker used scripts to implant multiple families of backdoors on each of the 40 domain controllers in the environment. This caused the investigation team to focus on the new infections before anything else, and the organization remediated on a nightly basis. This level of work was unsustainable and the organization ultimately rebuilt all servers and implemented application whitelisting in strict blocking mode on all domain controllers and all critical servers (for example, e-mail servers, web servers, file share servers, and SharePoint servers).
DEVELOP AND IMPLEMENT INCIDENT CONTAINMENT ACTIONS
Now let’s discuss containment actions. Containment actions prevent the attacker from performing a specific action that the organization cannot allow to continue. Containment actions are commonly extreme measures, and are not designed to be implemented long term. Implementing a containment plan often does not remove the attacker’s access from the environment; rather, it just prevents the attacker from performing the activity that cannot be allowed to continue. For example, if an attacker is actively stealing a large amount of PII data from a file server, it is more advisable to immediately stop the activity, and thus prevent further theft of PII data, than to attempt to fully scope the compromise before taking any action. A sample containment plan in this scenario could be to take the PII database offline until the incident has been resolved or to prevent any system from communicating with the PII database server except for a single jump host. It may not be a long term solution, but it will contain the incident temporarily until you can fully remediate.
A containment plan should never be treated as an eradication event because a containment plan is meant to be a temporary and often drastic solution to prevent malicious activity that is considered too unacceptable to be allowed to continue. A comprehensive investigation and remediation are still required to fully remove the attacker from the compromised environment. |
To develop a comprehensive containment plan, the teams need to understand the data or resources that need to be protected. The exercise is quite similar to the large, enterprise-level discussions that occur when an organization drafts a corporate security plan, albeit far more focused. During the drafting of the action plan, the investigation team should work with IT as well as security to ensure that every reasonable means to protect the data is on the table. Even if the investigation team believes they understand exactly how the attacker is operating, containment plans need to be as comprehensive as possible, which means accounting for all reasonable activity and not just the known activity. Many environments are large and complex enough that IT personnel simply do not understand every facet of the environment, whereas a good attacker will spend the time performing reconnaissance to ensure they have multiple avenues to conduct their malicious activity. Most attackers expect to be discovered at some point in time—the more advanced attackers simply ensure they have continued access even if discovered and their primary means of access is removed.
Let’s use a scenario to further explain containment strategies and how to properly implement one. A company recently discovered that an attacker breached its restricted financial environment. The attacker created unauthorized Automated Clearing House (ACH) transfers for large sums of money to an overseas bank account. The attacker breached the organization’s internally developed financial application, which provided the capability to create, authorize, and process ACH transactions.
In this situation, the remediation team should implement an immediate action containment plan, with the goal of preventing the attacker from creating additional unauthorized ACH transfers. Multiple approaches could be used to prevent the attacker from continuing to process unauthorized ACH transfers. The team was constrained by the following factors:
• The company could not tolerate a loss in business functionality.
• The attacker would still have access to the environment, so the containment plan must address alternate methods the attacker could initiate ACH transfers or access financial applications.
Many compromises of this nature become public, so the company will need to be able to provide the exact date when they removed the attacker’s access to the restricted financial environment. Typically, this will be the date the comprehensive containment plan was fully implemented. In some cases, an organization will provide this date to give customers confidence to do business again.
Given these considerations and the description of the scenario, let’s discuss a possible containment plan. The following four actions immediately come to mind:
1. Remove the attacker’s network access to the server hosting the financial application. One approach is to implement Access Control Lists (ACLs) to prevent all systems, except one, from interacting with the server. That one system is established as a “jump” system that requires two-factor authentication and only allows logins from local accounts. Local accounts are created for a small number of users who absolutely must interact with the financial application.
2. Remove the attacker’s ability to authenticate to the financial application. This means changing all passwords for all user accounts that have access to the financial application.
3. Require two-person integrity to create and authorize ACH transactions. This means that certain user accounts are able to create an ACH transaction and other user accounts can authorize the ACH transaction, but no account will be able to do both.
4. Implement notifications for all ACH transactions. The financial application will send an e-mail to a defined set of users notifying them of each major step in the process required to create and authorize an ACH transfer.
The containment plan just discussed provides reasonable measures to remove the attacker’s access to the server hosting the financial application. This was achieved by implementing the network ACLs and the jump system with two-factor authentication and local account access only. However, just in case the company overlooked a method the attacker could use to continue accessing the server, other controls were established. This is the same concept as defense in depth (or layered protection). By changing all user account passwords to the financial application, you force the attacker to re-compromise credentials. In addition, by requiring two unique user accounts in order to create and approve an ACH transaction, you force the attacker to learn which accounts can perform each action, and then compromise at least one of each type of account. Finally, by implementing monitoring on the financial application, the company’s financial team has the ability to detect anomalous ACH transaction activity.
One critical control was not discussed. Did you catch it? If the attacker installed a backdoor on a system in the restricted financial environment that has direct Internet access, then the attacker could continue to access the financial application and potentially regain access to the accounts necessary to continue their malicious activities. To combat this possibility, ACLs should be implemented to allow the financial application server network traffic to communicate only with systems that are explicitly required for business. This will prevent a backdoor the attacker may have installed from communicating with its C2 server. Remember, a containment plan needs to be as comprehensive as possible so that the attacker cannot continue their malicious activity and so that the company has a concrete date they can claim the specific malicious activity stopped.
Containment plans are often developed and implemented prior to understanding the full scope of a compromise. This often means you take an overly cautious approach by implementing temporary stringent measures that are relaxed after a full remediation is performed. The rest of the remediation effort, implemented later, should focus on removing the attacker’s access to the environment and better securing the environment from future compromise. The comprehensive remediation effort will implement more sustainable security measures to enhance the security of the environment on which the containment plan was implemented.
Once a containment plan has been implemented, the incident response team should expect a reaction from the attacker. The remediation team should work on implementing appropriate logging, monitoring, and alerting in parallel to implementing the containment plan in order to detect and react to the additional malicious activity outside of the contained environment. |
Because we are talking about real-life scenarios and operational issues, we should address what happens when something goes wrong. Let’s say that five days after the containment plan was implemented, the investigation team discovers that the attacker still has access to the financial application. This means that the remediation team may have overlooked a method the attacker could use to access the financial application. To properly deal with this situation, the investigation and remediation teams should work together and investigate how the attacker maintained or regained access to the financial application. Once that is determined, the remediation team will immediately implement new containment actions. If the company made a public statement that their environment was contained as of a certain date, they may need to revise that information.
Once the team has developed and implemented the appropriate posturing or containment plans, the next step is to develop the eradication plan. This plan, discussed in the next section, is designed to remove the threat from your environment.
DEVELOP THE ERADICATION ACTION PLAN
Eradication actions are implemented during a short period to remove the attacker from the environment. The eradication event, or the short defined period during which the eradication actions are implemented, should be designed such that the victim organization is fully recovered from the compromise at the end of the event. Unlike an immediate containment plan, which is designed to remove the attacker’s access to a specific network segment, application, or data, the eradication plan is designed to remove all of the attacker’s access to the environment. A comprehensive eradication event relies heavily on the investigation team’s ability to fully scope the environment but also on the organization’s ability to fully implement the eradication plan. The goals of an eradication event are as follows:
• Remove the attacker’s ability to access to the environment.
• Deny the attacker access to compromised systems, accounts, and data.
• Remove the attack vector the attacker used to gain access to the environment.
• Restore the organization’s trust in its computer systems and user accounts.
Eradication plans should be designed with the expectation that the attacker will try to regain access to the environment. The plan should account for attempts the attacker could make both during and after the eradication event. It should also consider that the attacker may do more than just attempt to access the environment with previously used methods—the attacker may search for and exploit other vulnerabilities. The plan should also account for any aggressive actions the attacker may make in retribution for losing access to the environment. |
Examples of common eradication actions are listed next; however, because each incident is different, other actions may be taken:
• Disconnecting the victim organization from the Internet during the eradication event
• Blocking malicious IP addresses
• Blackholing (or sinkholing) domain names
• Changing all user account passwords
• Implementing network segmentation
• Mitigating the original vulnerability that allowed the attacker initial access to the environment
• Rebuilding compromised systems
In most organizations, weekends are a good time to conduct an eradication event because the disruption to the business is minimal. Another factor to consider when selecting the time frame for an eradication event is the attacker’s standard working hours, if known. Implementing eradication hours during a time period of expected low attacker activity increases the chances of the eradication plan succeeding before the attacker is aware he has lost access to the environment.
The longer the duration of the eradication event, the greater the chance that the attacker will regain access to the environment during the event. The incident severity will dictate how in-depth the eradication actions are, but it is common for organizations to disconnect Internet connectivity during the eradication event in order to ensure that the attacker cannot access the environment and disrupt the eradication event. Imagine the waste of time and resources if you spend a month planning for a large eradication event only for the attacker to undermine the effort by using an undiscovered backdoor during the eradication event to compromise additional systems.
The remediation team can take a couple potential responses if the attacker is able to regain access to the environment during the eradication event. One response is to quickly investigate and contain the re-compromise. The investigation team should work in parallel to determine the method the attacker used to regain access in order to mitigate it. Once the attacker’s access has been mitigated, the eradication event can continue. Another response is to delay the eradication event and start the incident response process over. This response is more appropriate when the attacker gains access for a significant period and compromises more systems than could be realistically remediated during the planned eradication event.
Eradication plans are often the easiest part of the remediation effort to design, because a limited number of actions can be implemented to comprehensively remove an attacker from an environment. For example, in order to remediate a compromised system, the eradication plan would include either 1) rebuilding the systems from known good media or 2) implementing detailed cleaning instructions to clean the malware from the system. In addition, in order to recover from compromised credentials, the eradication plan would include either 1) changing the user account password or 2) disabling/deleting the user account and issuing a new one. Unfortunately, just because eradications plans are easy to design does not mean they are easy to implement—just the opposite in fact.
Improper planning is the biggest contributor to an incomplete or failed eradication event. In general, the more time spent upfront planning for the eradication event, the less time it takes to implement the eradication actions and fewer things go wrong. For example, your organization may decide it wants to disconnect from the Internet during the event. However, most organizations cannot tolerate completely disconnecting from the Internet—there are business applications that need to remain operational 24/7 in order for business to continue (imagine a large international bank going offline for an entire weekend). The reality is that Internet connectivity will need to be allowed to and from certain systems residing in one or more DMZs. Because of that, the remediation team will need to take extra measures:
• Ensure that those business-critical systems do not have access to systems outside of their specific DMZ.
• Network connectivity between various geographical sites will need to remain intact to allow the various IT teams to implement the eradication actions.
• Business-to-business connections will have to be evaluated to see which connections can be disconnected and which need to remain operational. For those business-to-business connections that need to remain operational, the remediation team needs to ensure that Internet-bound traffic cannot traverse the link.
• Remote VPN connectivity will likely need to remain operational in order to allow IT staff to work from remote locations and yet still implement the eradication event action items. However, the number of user accounts allowed to connect to the VPN during the eradication event should be limited to necessary IT personnel, investigation, and remediation team members only. In addition, split-tunneling through the VPN should be disabled to provide an additional layer of caution.
• Before any system is allowed to connect (remotely or in-office) to the compromised environment to work on the eradication event, it should be verified to be clean.
Based on that list, you can see that an action that sounds simple, such as disconnecting from the Internet, may actually be quite difficult to implement in an operational environment.
Another eradication event action item that is often difficult to implement is changing all user account passwords. This includes all operating systems, such as Windows, Linux, and Mac user accounts; user accounts hard-coded into applications; database accounts; and any accounts for networking gear targeted by the attacker (such as firewalls, IDS/IPS, routers, and switches). Remember, the intent is to prevent the attacker from using all stolen credentials, not just the credentials the investigation team discovered being used. In addition, performing an audit of all user accounts and matching them to physical user accounts is a good idea if the remediation team has time. All user accounts include, at a minimum, the following accounts:
• Standard Windows, Linux, and Mac user accounts
• Service accounts
• Local administrator or root accounts
• Any other accounts integrated with the local credential database (whether Microsoft Active Directory, other LDAP solution, or NIS)
• Application accounts
• Networking gear accounts
• Database accounts
The last three types of accounts—application, networking gear, and database accounts—may not need to be changed during an eradication event. The amount of effort spent changing “all” user account passwords should be directly related to the ability of the remediation team to implement all recommendations and based on the attacker’s focus of activity. Forcing password changes on user accounts is generally a simple task. The biggest concern is how you deal with the possibility that an attacker might be the person who logs in and makes the password change. This is a difficult problem to solve, and there are different ways to approach it. Though we don’t recommend this, you could simply accept the risk. The appeal of this approach is that it’s easy to implement, because you are just assuming the other eradication actions should ensure the attacker does not have continued access to the environment. You could also generate random passwords for all accounts and use an appropriate method to provide the new passwords to the users. Another option is to require users to call into the helpdesk to grant them VPN access to change their passwords.
Changing service account passwords is also straightforward; however, planning is required in order to understand the effects of changing those passwords. Before you change service account passwords, you will need to determine which applications use a service account, and then identify all systems where that application is installed. This is because service account passwords need to be changed on every system that uses that service account as well as in the central directory. There will almost certainly be systems or applications that are missed during the planning process. A contingency plan should be in place for dealing with systems and applications that start experiencing issues from a changed service account password. Many times, these issues are not discovered until after the eradication event is completed and the application is operational again.
Changing the local administrator password to something unique on all systems in the environment is also a very challenging task. Some organizations decide to accept the risk these accounts pose and either leave the passwords unchanged or implement a single password for all local administrator accounts. Some organizations develop their own scripts to set (and track) unique passwords for all local administrator accounts whereas other organizations implement credential vaults and management software that randomizes the passwords on all systems and requires administrators to check out and check in passwords for the local administrator account. Still other organizations disable remote network and RDP logons from the local administrator account or disable the account entirely. The best method to protect the local administrator accounts in your organization will depend on the environment and what your organization will tolerate.
A final point to consider when developing an eradication plan is how to properly back up user and critical data from the compromised systems being rebuilt. Most users will have data on their systems that they absolutely must have backed up and restored to their new system. System administrators will have data on their servers that will need to be backed up and restored as part of the eradication event. In all cases where data needs to be backed up from compromised systems and restored to the new system, a member of the remediation team should sign off on the directories and files being backed up to ensure that malware is not accidentally transferred to the new system. We have performed enough eradication events to see more than one company almost re-compromise itself by accidentally restoring malware to a user’s system. However, because all known malicious IP addresses were blocked and domain names were blackholed, the user accidentally executing malware didn’t actually re-compromise the environment. If the preparation steps are completed successfully, when the malware attempts to establish a C2 connection, it should be blocked by the security mechanisms put in place.
As we discussed earlier, planning is critical to a successful eradication event. However, even the best planning cannot guarantee that everything goes smoothly. You should develop contingencies to address common complications, such as the following:
• A user is on vacation or traveling and does not change their password within a timely manner.
• A user account is no longer active but was never disabled, so the password is never changed.
• Systems that do not belong to the domain will not be affected by most types of automated password changes.
• Local user accounts that have administrative rights assigned, but are not the standard local administrator account.
After the remediation team develops the eradication plan, they will need to coordinate with leadership to determine when the best time is to execute that plan. In the next section, we discuss timing considerations and execution strategies.
DETERMINE ERADICATION EVENT TIMING AND EXECUTE ERADICATION PLAN
The timing of the eradication event is critical to a successful remediation. If the eradication event is executed too early, the investigation team may not have time to adequately scope the compromise. This may cause the remediation to fail because the attacker’s access to the environment may not have been completely removed (for example, if a backdoor was missed). If the eradication event is executed too late, the attacker may change their tools, tactics, and procedures (TTPs) or accomplish their mission. If the attacker changes their TTPs, the investigation team must investigate those new activities. If the attacker accomplishes their mission, then the business suffers a loss (although the damage might not be immediately felt, as in the case of intellectual property theft). An ideal time to execute the eradication event is when the investigative team has properly scoped the compromise and the remediation team has implemented all or most of the posturing/containment actions and is prepared for the event. Properly scoping the compromise means that the investigation team understands the majority of the attacker’s TTPs and can reliably detect malicious activity. At Mandiant, we refer to the ideal timing of the eradication event as the “strike zone.” The strike zone is the middle ground between knowledge and time. Figure 17-2 depicts this concept.
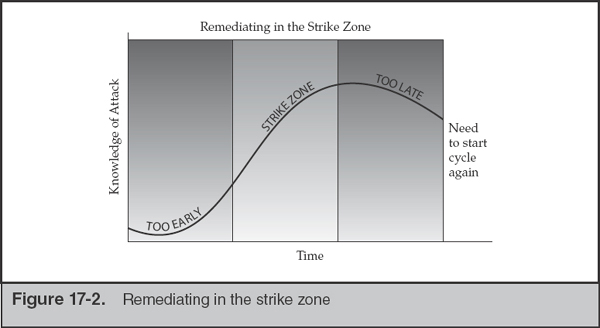
Determining when you’re in the “strike zone” can be difficult—it is more of an art than a science. We generally look for the following conditions as good indicators that we’re approaching or are in the strike zone:
• The investigation team believes they have good visibility into the breached environment and they understand the attacker’s TTPs.
• The number of compromised systems discovered per day (or other time period) has decreased significantly.
• Most of the compromised systems detected contain known indicators of compromise.
• The remediation effort has been thoroughly planned.
As you can see, if you do not have good visibility into the environment, or good detection mechanisms, it will be difficult to know when you’re in the strike zone because you’re missing the first part of the equation, which is knowledge of the attacker’s TTPs.
Some organizations choose to wait until the investigation team is close to finishing their work before they start planning for the eradication event. That approach is not ideal and often leads to rushed planning or missing the strike zone. The planning process for the eradication event should start as soon as the incident owner has decided upon a remediation approach (immediate, delayed, or combined). The eradication plan should be considered a work in progress while the investigation is ongoing and should be revised accordingly as new information is discovered. This might seem like extra work with little or no gain; however, experience has shown us that early planning leads to more effective eradication.
The timing of the eradication event should not be decided when the incident owner believes the organization is in the strike zone. Rather, a tentative execution date should be agreed upon between the incident owner, the investigation owner, and the remediation owner while the investigation and remediation efforts are ongoing. The intent is to try to pick a date that ultimately falls within the strike zone, although you won’t know when you’re in the strike zone until you are very close or you are there (hence why we refer to this concept as an art and not a science). Some organizations set a date far enough in the future that they can guarantee they are well prepared, but this may lead them to fall outside of the strike zone because too much time has passed. The most effective way to select an eradication event execution date is to select a date that is considered a little difficult to achieve and then forcing the various teams to work hard to achieve the date.
If possible, do not let the eradication event date slip. In our experience, once an organization pushes back the eradication event date, the eradication event starts to lose its sense of urgency, which can have other side effects. We’ve seen companies postpone the eradication event indefinitely until they are “better prepared” to implement the recommended actions. The problem with this type of thinking is that an organization is never as prepared as they would like to be to deal with an incident (both the investigation and remediation). It is better to perform some type of remediation than none at all. In addition, once the eradication event date has slipped, it becomes easier for the victim organization to start removing difficult-to-implement eradication actions in order to execute an eradication event. In our experience, this occurs most frequently with the changing of user account passwords. Once you push the eradication event execution date back once, you are more likely to let the date slip again.
Execution of the eradication event is usually process driven—execution of the eradication event consists of implementing the previously developed eradication actions in a specific sequence and verifying that they were implemented properly. The more planning that was performed in anticipation of the eradication event, the more straightforward the event will be. A sample eradication event could consist of the following five activities:
• Disconnect from the Internet.
• Block known malicious IPs and blackhole malicious domain names.
• Remove compromised systems from the network and rebuild.
• Change all user account passwords.
• Verify all eradication event activities.
The eradication event action items are designed to be executed in order. This means that the first action taken once the eradication event starts will be the network team disconnecting the organization from the Internet, followed by the implementation of IP address blocks at all border routers and DNS blackholing at all external DNS servers. Note that it is very important for the network administrators to test that the Internet is properly disconnected and that the IP address blocks and DNS blackholing are working properly at all locations. One common method for testing to ensure these two activities were properly implemented is to attempt to browse to legitimate websites, attempt to ftp (or use some other common protocol) to legitimate FTP sites, and attempt to access a handful of the known malicious IP addresses from all locations that have their own Internet egress points. It is important that all major geographical or logical sites perform this testing to ensure that a mistake does cause the eradication event to fail. Note that attempting to “ping” the legitimate and malicious domains/IPs is not considered acceptable testing because ICMP packets may be treated differently than TCP/UDP traffic, thus a false positive/negative condition could occur. One suggestion is to use the netcat and nmap networking tools to test that Internet connectivity has been properly severed, that ACLs are blocking known malicious IP addresses, and that DNS blackholing is working as expected. Most organizations implement alerts to indicate when known malicious IP addresses or domain names are accessed, in addition to just blocking IP addresses and blackholing domain names. This is a prudent step because these alerts will notify the organization if any compromised systems with known malware were missed (although the malware should be rendered useless by the IP address blocks and DNS blackholing).
Once the networking action items have been completed, your system and application administrators can start remediating compromised systems. This usually entails either rebuilding the compromised systems or carefully removing the malware based on instructions provided by the incident investigative team. If systems are rebuilt, you should be very careful when restoring data to the new system to ensure that malware is not accidentally reintroduced. Even though the network blocks put in place in the previous steps should prevent the malware from communicating with its command-and-control server, there is still a risk that something was missed. This is one of the reasons that the eradication event action items are implemented in a specific order and why it is important to execute them all—when eradicating an attacker, you want every advantage on your side.
We are often asked if “cleaning” a compromised system is sufficient. Cleaning, or removing known malware, is not recommended because it is difficult to be certain that all malware has been discovered and thus removed from the compromised system. Rebuilding compromised systems from known-good media is the most trusted way to ensure a clean environment post-remediation. However, there are circumstances where cleaning the malware from the system rather than rebuilding the system will be required. An example is when production servers are involved and downtime means lost revenue for the business, or when the attacker has compromised hundreds or thousands of systems. |
Once the compromised systems are taken offline, your administrators can start working on changing all user account passwords. We mentioned earlier that the eradication event actions are executed in a strict order to ensure the event is as effective as possible. However, once the previous steps are complete and all compromised systems have been powered down or unplugged from the network, the attacker should no longer have access to your environment. At that point, it is appropriate to start working on the next action item. In other words, all compromised systems do not need to be rebuilt before starting to change user account passwords—the compromised systems simply need to be removed from the network (and wireless connectivity disabled, if applicable). This will help reduce the amount of time required to execute the eradication event. As was mentioned earlier in the chapter, the user account password change is likely the hardest part of the eradication event and will take the most amount of time. This action frequently causes the most number of unanticipated issues, so you should start on this action as soon as you can without hindering the eradication effort.
The last eradication event action in this example is to verify remedial activities were accomplished appropriately—after which the Internet can be reconnected. Verifying that malware has been removed from all compromised systems is a simple as looking for the indicators of compromise via whatever method was used throughout the investigation. Oftentimes, verifying that systems were properly remediated will identify a small number of systems that were accidentally overlooked, improperly rebuilt, or not rebuilt at all. In our experience, some administrators will try to save time by cleaning the malware from the compromised system rather than rebuilding the system (regardless as to the specific instructions). Trace evidence of the malware may still exist, such as entries in the registry or configuration files on the file system, which are easy to discover when searching for indicators of compromise. Finally, verifying that all user account passwords were changed is straightforward. If the victim organization is using Microsoft Active Directory, the remediation team can easily verify that all passwords either were set to expire or changed using native Microsoft Active Directory tools. In order to determine whether local administrator, database, and application (if applicable) user account passwords were changed, administrators should take a sampling approach to verification.
Communication will be critical throughout the eradication event. Effective communication will be required to let each group of administrators know when they can start the next action item and when previous action items have been completed. Proper communication is also required to address issues the administrators are running into and to help administrators who are experiencing difficulty. No matter how well prepared, you will most likely encounter unexpected challenges during your eradication event. Effective communication will ensure that these unexpected challenges are addressed quickly before they can disrupt the entire eradication event.
The remediation owner should ensure that a communication medium is established prior to the eradication event. This communication medium should be available throughout the duration of the eradication event. One strategy is to establish set times periodically throughout the day for all administrators and members of the remediation team to call into to discuss progress. Another strategy is to keep a conference bridge open throughout the duration of the entire eradication event so that all members of the team can give and receive updates in real time.
The eradication team normally includes more people than just the remediation team. Usually, all network, system, and application administrators are required to participate in the eradication event, under the guidance of the remediation team. Not all members of the remediation team need to work through the eradication event (such as the public relations, human resource, and legal members), but all technical personnel should participate or remain available throughout the event. In the days following an eradication event, ensure that your helpdesk personnel have the ability to contact the remediation team, in the event suspicious activity or failed applications are reported.
DEVELOP STRATEGIC RECOMMENDATIONS
Strategic recommendations are actions that are critical to your organization’s overall security posture, but that cannot be implemented prior to, or during, the eradication event. Some high-level examples of strategic recommendations are upgrading to a more secure OS throughout the environment, reducing user privileges across the organization, implementing strict network segmentation, and implementing egress traffic filtering. Strategic recommendations are, by design, difficult to implement because they are disruptive in nature but offer significant security enhancements.
The strategic recommendations are often developed during the course of the first two phases of the remediation. For example, a member of the remediation team may develop a comprehensive network segmentation plan to deny attackers access to a restricted segment of the environment. This plan may require you to move critical data to a series of servers and then place the servers in the restricted environment. In addition, the plan may call for credentials to be established and two-factor authentication deployed for the users who need to interact with that data. More than likely this project will require more time, planning, and resources than can be spared during the incident. This action is a perfect recommendation; the action is beneficial to the security of the organization but is not feasible to implement in a short timeframe. Note that the remediation team should not spend significant time developing strategic recommendations until after the eradication event. When developing strategic recommendations, the remediation team should focus on describing the action items from a high level only. The specific details for the strategic actions should be worked on by cross-functional teams formed by the organization specifically to plan the implementation of the strategic recommendations. These teams will be more specialized and knowledgeable in the disciplines necessary to plan and implement each strategic action.
It is important that the remediation team document all recommended strategic actions, even if they do not believe the organization is willing to implement the recommendation. The organization may decide at a later date that difficult-to-implement strategic recommendations are important to implement. Other times, executive management may ask to be briefed on the strategic recommendations and may allocate funding and resources for the actions with the most benefit. Because of this, strategic recommendations should always be documented in order of priority, with recommendations that reduce the organization’s risk the most listed first.
After the team completes all of the remediation actions, there’s one final step to the remediation process—develop lessons learned. In the next section, we discuss why this is such an important part of the process.
DOCUMENT THE LESSONS LEARNED
You should capture lessons learned after each major remediation effort. Your organization will define what constitutes a “major remediation effort,” but in general you should create lessons learned for any remediation effort that requires significant participation, planning, and implementation. Simple remediation efforts, such as a rebuilding one system due to a virus, likely do not require lessons learned documentation.
You should capture lessons learned in a standard, structured, format document that’s stored in an easily accessible and centralized location. Establishing structure—essentially a template—will ensure content is captured in a consistent manner. Additionally, the lessons learned should be easily searchable and browsable, with tags, categories, or other appropriate methods to organize the documentation. This will also help to prevent duplicate lessons learned. Wikis and document management systems make great locations for centrally storing and indexing lessons learned.
An example of when creating lessons learned will be useful is after implementing an enterprise-wide password change for all user accounts (including directory, system, and application accounts). Your remediation team will have to solve numerous technical and nontechnical issues to implement this remediation action. Some technical challenges that need to be solved are how to change all Unix passwords if a directory is not being used, how to create unique passwords for the local administrator account on all Microsoft Windows systems, how to determine all scripts and applications that have hardcoded usernames and passwords, and how to determine all service accounts using specific service accounts, among others. Some nontechnical issues include the identification of all systems, applications, and scripts in the environment where user accounts are used, winning executive and business-level support for this remediation action, and getting standard users to comply to the fullest extent possible with this action item.
Creating a lessons learned document, and storing all documentation and custom scripts created in support of this remediation action item, will greatly reduce the amount of time and effort necessary if the remediation team has to plan another enterprise-wide password change. You should create lessons learned as soon as possible after the remediation effort has concluded, in order to ensure that all lessons are accurately captured. We’ve seen some remediation teams wait days, or even weeks, after the remediation effort has concluded to develop their lessons learned. By that time, the remediation team may either forget to include information or have trouble compiling the necessary information from the other members of the remediation team. Your remediation owner should ensure the remediation team understands that creating lessons learned is a mandatory part of the remediation effort. That usually encourages team members to make notes along the way so the lessons learned process is less painful.
This may be an obvious point, but avoid storing information on prior investigations on systems connected to corporate domains or directories. This type of information, essentially blueprints for how your incident response (IR) team operates, would be incredibly useful to future attackers. If you must store it online, stand up independent servers and storage that is managed by the IR team. |
Now that we’ve covered all eight steps of the remediation process, let’s look at a generic example of how you might apply them. In the following section, we’ll combine the remediation steps with a planning matrix to illustrate how a remediation might progress.
The remediation process is challenging because there are so many situational-dependent issues that you will have no control of. At Mandiant, we use the concepts of the Attack Lifecycle and Remediation Planning Matrix as the basis for developing comprehensive remediation plans. You should already be familiar with the concept of the Attack Lifecycle, because we introduced it in the Chapter 1 of this book. The concept of the Remediation Planning Matrix may be new, so we’ll cover it here. We developed these concepts to better describe the various phases of an attack and to ensure a remediation plan was comprehensive and addressed all areas of the attack. To recap, the Attack Lifecycle consists of seven functional areas common to most intrusions. Note that all seven areas are not always part of an attack; however, this lifecycle can be adapted to fit any incident. The Attack Lifecycle is depicted here:
Constructing a comprehensive remediation plan that is designed to combat an attacker at some or all of the areas discussed in the Attack Lifecycle is easier to visualize by breaking up an incident into the seven functional areas. At, Mandiant we use the Remediation Planning Matrix, shown next, to plan comprehensive remediation efforts:

The Remediation Planning Matrix was created to help design a plan to protect against threats (prevention), detect attacker activities (detection), and eradicate the threat from the environment (responding). By focusing on each of the three rows (Prevent, Detect, and Respond) for each phase of the Attack Lifecycle (represented as columns in the figure), and understanding the goals of the incident response, your remediation team can develop a comprehensive plan that addresses the most critical security vulnerabilities of your organization. The Remediation Planning Matrix also helps brainstorm possible remediation actions, which can be reworked later when designing the remediation plan.
Understanding what constitutes a critical asset—what you are trying to protect—is vital. There are three types of critical assets: data, people, and systems. This understanding will increase the likelihood of a successful remediation effort and more targeted strategic actions. |
Let’s walk through an example that uses the Attack Lifecycle and the Remediation Planning Matrix concepts. Suppose an attacker has exploited a Remote File Include (RFI) vulnerability on a publicly accessible web server running a LAMP stack (Linux, Apache, MySQL, and PHP). The attacker has uploaded a webshell that grants access to the compromised web server with the privileges of the Apache user account. The Apache user account is in the wheel group and therefore has root privileges. The attacker has stolen the /etc/shadow file, cracked the root user’s weak password, and then used the root account and Secure Shell to compromise other systems in the DMZ, starting with the backend database system. The attacker has also installed a backdoor that communicates with a command-and-control server at ftp.evilattacker.net over TCP port 53. However, the attacker is not able to gain access to the internal environment because proper segmentation is in place. Figure 17-3 is a graphical depiction of this sample RFI compromise.
Now let’s apply the Remediation Planning Matrix to the scenario just described. Here, we list each phase of the attack lifecycle, including a summary of what happened in that phase, and then list ideas for each matrix category (prevent, detect, and respond):
• Phase 1: Initial compromise The attacker exploits an RFI vulnerability.
• Prevent Perform a thorough code review, fix insecure code, and obfuscate the web server version.
• Detect Implement a web application firewall (WAF) or other intrusion detection system (IDS) tuned to look for web application-based malicious activity.
• Respond Perform thorough code reviews.
• Phase 2: Establish foothold The attacker creates a webshell on the server.
• Prevent Restrict the Apache user to creating files only in specific directories and configure the server to disallow all server-side scripting in those directories.
• Detect Implement a host-based intrusion detection system, such as Tripwire, to monitor file system changes.
• Respond Remove malicious file(s) from the system.
• Phase 3: Escalate privileges The attacker uses the Apache user account’s privileges to gain access to the /etc/shadow file and then cracks the root user account’s weak password.
• Prevent Remove root privileges from the Apache user, run Apache in a jailed environment, implement a strong password for the root user, and implement unique root passwords on all DMZ systems.
• Detect Implement a host-based intrusion detection system, such as Tripwire, to monitor file system changes.
• Respond Change user account passwords for all users on all systems in the DMZ, and change the root password on all systems in the DMZ.
• Phase 4: Internal reconnaissance The attacker has likely port scanned or performed ping sweeps of the local subnet to discover other systems.
• Prevent Implement ACLs to restrict systems from communicating with one another, except over ports required for business functionality.
• Detect Implement IDS with rules tuned to monitor for nonbusiness traffic from one system to another.
• Respond N/A
• Phase 5: Move laterally The attacker uses the root account to log in to remote systems with secure shell (SSH).
• Prevent Disallow remote root logins, implement ACLs to restrict systems from communicating with each other (except over ports required for business functionality), implement a strong password for the root user, and implement unique root passwords on all DMZ systems.
• Detect Implement IDS with rules tuned to monitor for nonbusiness traffic from one system to another.
• Respond Investigate every system in the subnet if no trace of internal reconnaissance is discovered.
• Phase 6: Maintain presence The attacker installs a backdoor on a system.
• Prevent Implement grsecurity/PAX to prevent code injection, SELinux to enhance security restrictions, and disallow outbound connections from systems in the DMZ.
• Detect Implement a host-based intrusion detection system, such as Tripwire, to detect changes to the file system, and implement network IDS tuned to look for outbound traffic connections from DMZ systems.
• Respond Remove malicious file(s) from the system and block outbound access to the malicious domain.
• Phase 7: Complete mission In this example, we do not know what the attacker’s mission is.
• Prevent N/A
• Detect N/A
• Respond N/A
To summarize, the following unique list captures all the potential remediation actions that were developed as part of this brainstorming session:
• Obfuscate the web server version.
• Fix insecure code.
• Perform thorough code review.
• Implement WAF or other IDS tuned to look for web application-based malicious activity.
• Disallow the Apache user from creating files in specific directories.
• Implement a host-based intrusion detection system (such as Tripwire to detect changes to the file system) to monitor file system changes.
• Remove malicious file(s) from the system.
• Remove root privileges from the Apache user.
• Run the Apache web server in a jailed environment.
• Implement strong passwords for privileged users.
• Implement unique root passwords on all DMZ systems.
• Change user account passwords for all users on all systems in the DMZ.
• Implement ACLs to restrict systems from communicating with each other except over ports required for business functionality.
• Implement IDS with rules tuned to monitor for nonbusiness traffic from one system to another.
• Implement IDS tuned to look for outbound traffic connections from DMZ systems.
• Disallow remote root login.
• Investigate every system in the subnet if no trace of internal reconnaissance is discovered.
• Disallow outbound connections from systems in the DMZ.
• Block outbound access to the malicious domain.
At this point, the team needs to decide which action items will be implemented and where they fit in the overall remediation strategy. Given this scenario, the incident owner would likely choose a delayed action remediation direction. Remember that the incident owner typically does not have all the facts of the compromise at the time he needs to determine the remediation approach. A delayed action remediation approach is usually the safest approach, especially if the incident owner thinks the compromise is significant. A delayed action remediation approach will consist of three phases: posturing actions, eradication actions, and strategic recommendations. Considering this scenario, let’s take a look at what you might do during each phase:
• Posturing actions The following remediation actions (from the brainstorming session) could be implemented as posturing action items:
• Obfuscate the web server version.
• Fix insecure code.
• Implement a host-based intrusion detection system (such as Tripwire) to detect changes to the file system.
• Monitor critical system file accesses.
Other posturing action items you should consider, even though they were not mentioned in the brainstorming session because they were not directly relevant to the current incident, are:
• Redirect all syslog data to a SIEM.
• Install missing patches on all systems.
• Remove unnecessary programs from all servers in the DMZ.
In most situations, the actions listed here will not tip off the attacker that they have been detected and are being investigated. Each posturing action item appears more like a normal IT action than a measure taken in direct response to the attacker.
1. Disconnect DMZ systems from the Internet.
2. Block outbound access to the malicious domain (ftp.evilattacker.net) by performing DNS blackholing of the domain.
3. Rebuild the compromised web server:
a. Remove malicious files from the system (note that this is accomplished by rebuilding the compromised web server).
b. Run Apache in a jailed environment.
4. Disallow remote root logins to all servers.
5. Implement strong password for all user accounts:
a. Change root and Apache user account passwords.
b. Implement unique passwords per account per system.
c. Remove root privileges from the Apache user.
d. Disallow the Apache user from creating files in specific directories.
e. Implement a web application firewall (WAF) or other intrusion detection system (IDS) tuned to look for web application-based malicious activity.
f. Verify successful implementation of all eradication actions.
Note that this list also includes some items that were not mentioned in the brainstorming session. This is because some of the eradication actions are necessary in order to properly remediate the compromise, but did not directly relate to the known attacker activity. An example of this is the first eradication action listed: Disconnect DMZ systems from the Internet. This eradication action is necessary to ensure the attacker does not disrupt the eradication event, but does not directly address any part of the Attack Lifecycle or Remediation Planning Matrix. Also, note that the order in which the actions are intended to be implemented. The order is designed to deny the attacker access to the environment, prevent the attacker from using a compromised user account (in case an avenue into the environment was missed), and implement enhanced security measures where feasible (such as rebuilding the web server with Apache running in a jailed environment).
• Strategic actions The following actions are more suited as strategic recommendations:
• Perform thorough code review.
• Implement ACLs to restrict systems from communicating with one another, except over ports required for business functionality.
• Implement IDS with rules tuned to monitor for nonbusiness traffic from one system to another.
Other strategic recommendations that should be considered, even though they were not mentioned in the brainstorming session because they were not directly relevant to the current incident, could be:
• Implement SIEM for centralized logging in the DMZ.
• Outsource security monitoring of the DMZ to a managed security services provider.
• Disallow remote management from the Internet to the DMZ except through multifactor authentication.
In the next chapter, we’ll look at specific scenarios and go into more detail as we present remediation case studies. Before that, we’d like to wrap up this chapter with a brief discussion about common remediation challenges that can lead to failure.
COMMON MISTAKES THAT LEAD TO REMEDIATION FAILURE
In our experience, there are some common mistakes that organizations make during the remediation process that cause them to fail or be less successful. Here are the most common pitfalls you should look out for:
• Lack of ownership
• Lack of executive support
• Poor planning
• Remediation plan is too ambitious
• Poor timing
We’ve already covered lack of incident and remediation ownership, lack of executive support, poor planning, and poor timing in other sections of this chapter. However, we have not discussed how an overly ambitious remediation plan can lead to failure. Organizations sometimes use the remediation effort as a time to overhaul their security posture. This is usually because the security team suddenly finds themselves with executive-level interest, support, and funding. This causes the organization to overlook the immediate problem (remediating the current incident) in favor of more strategic and long-term actions. The remediation team needs to avoid this trap and stay focused on remediating the current incident.
Ignoring future security planning may sound counterintuitive to seasoned security professionals. They must protect countless systems and applications, whereas an attacker only has to exploit a single vulnerability in a single application or system to circumvent security controls. Therefore, it seems to make sense to take advantage of the increased support for security initiatives, and strike while you have management’s support. However, in our experience, organizations fail at the security posture overhaul because it is too much additional work. That failure normally affects the investigation and the remediation effort, because their resources are frequently used to implement the attempted security improvements.
SO WHAT?
The remediation process can be very complex and challenging. Coordinating with multiple teams, determining the impact of remediation actions, dealing with legal issues, encountering last-minute changes, worrying about missing something, and attending countless meetings will test your patience and drain you of energy. A process that includes thoughtful planning, focus, attention to detail, and well-coordinated execution will help you to stay sane and perform a successful remediation. That process includes the eight steps we introduced at the beginning of this chapter:
• Form the remediation team.
• Determine the timing of the remediation actions.
• Develop and implement remediation posturing actions.
• Develop and implement incident containment actions.
• Develop the eradication action plan.
• Determine the eradication event timing and execute the eradication plan.
• Develop strategic recommendations.
• Document the lessons learned from the investigation.
QUESTIONS
1. List at least five of the factors critical to remediation efforts.
2. List at least three of the five qualities essential for a strong remediation lead.
3. Should the remediation team include members from the investigation team? Why or why not?
4. Give at least five examples of personnel who should be members of the remediation team (including ancillary personnel).
5. Define posturing actions. Define containment actions. What are some differences between the two types of actions?
6. What are some common reasons eradication events fail?
8. Give an example of a remediation effort where a combined action approach would be more valuable to the incident response effort than either an immediate or delayed action approach.
9. Pick a recent public breach disclosure and create a containment plan based on the known information. What actions would you implement as part of the eradication effort that you would not implement as part of the containment plan. Explain your choices.
10. Create a complete remediation plan, including posturing/containment, eradication, and strategic recommendations, for one of the two case studies presented in Chapter 1.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.