
CHAPTER 16
Leveraging and Governing Emerging Technologies
This chapter covers some key emerging and advanced information technologies that can be leveraged in information governance (IG) programs: data analytics, artificial intelligence (AI), blockchain, and the Internet of Things (IoT).
Data Analytics
Analytics are playing an increasing role in IG programs. File analytics software, also referred to as content analytics, is used to discover duplicates, ownership, content classifications, the age of unstructured information, when it was last accessed, and other characteristics. Predictive analytics are used to help search and classify e-documents during litigation. Security analytics are used to monitor and respond to cybersecurity attacks. Analytics are also used to find new value in information by combining various internal and often external data points. The use of analytics is key to the success of IG programs.
Big Data analytics has a lot of uses (real-time fraud detection, complex competitive analysis, call-center optimization, consumer sentiment analysis, intelligent traffic management, etc.). Big Data has three defining characteristics, the “three Vs” as Doug Laney of Gartner proposed: high volume, high velocity, and high variety of data. Analysis of the appropriately named Big Data can provide the kind of insight into relationships and business patterns that can improve a business’ bottom line.
There are several classes of analytics tools that can be applied to render insights into large data collections and can help organizations find new value in information.
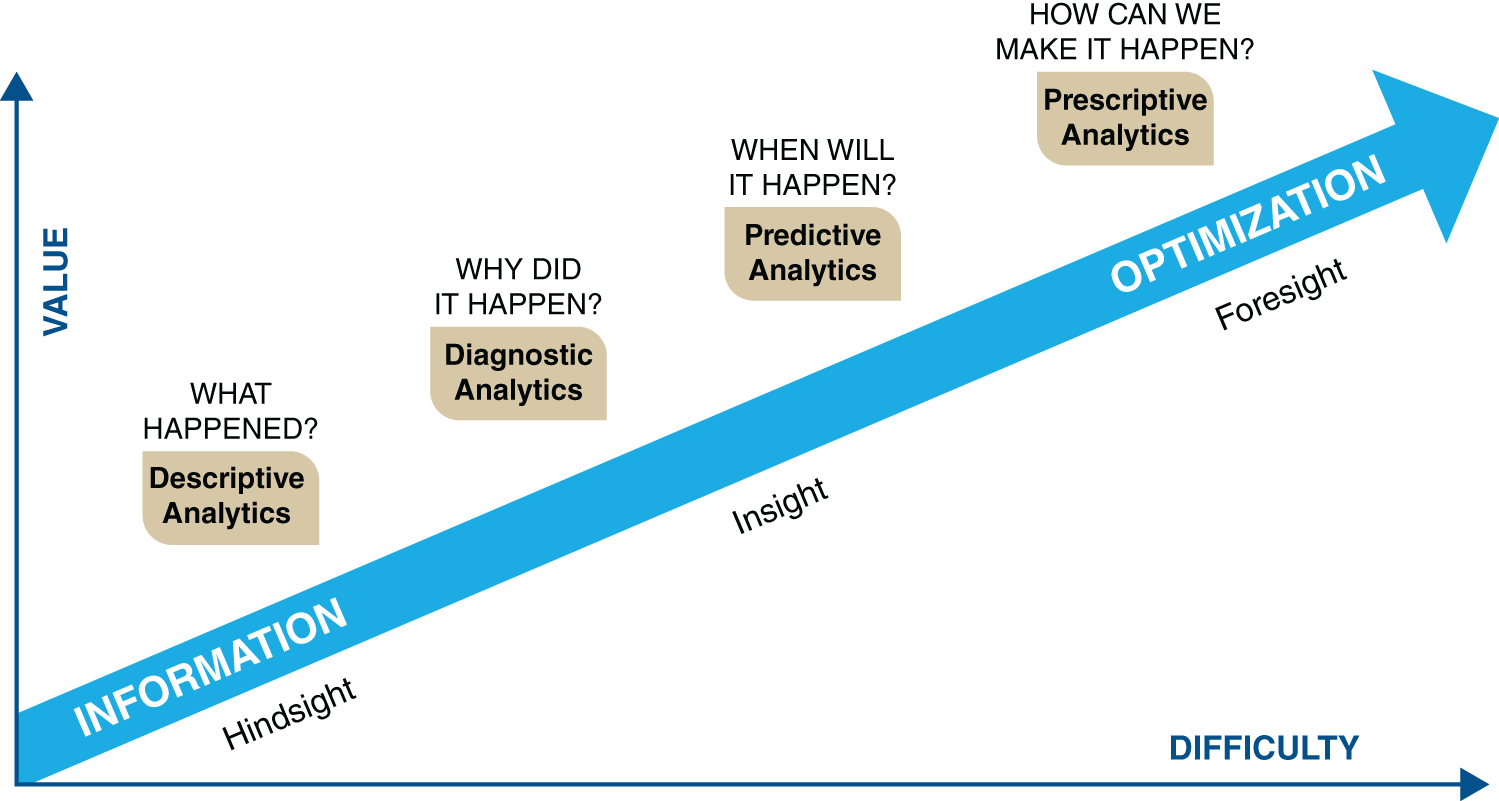
The four main types of analytics are:
- Descriptive: Real-time analysis of incoming data
- Diagnostic: Understanding past performance
- Predictive: Forecast of what might happen
- Prescriptive: Formation of rules and recommendations
Descriptive analytics tells you about information as it enters the system. Diagnostic analytics investigates larger data sets to understand past performance and tell you what has happened. Predictive analytics is used to compare year-over-year, or month-to-month, to determine what might happen in the future. Prescriptive analytics helps companies to determine what actions to take on these predictions based on a variety of potential futures.1
In order of increasing complexity, and value added, the sequence is: descriptive, diagnostic, predictive, and prescriptive. These analytics tools will become more important—and more difficult—as we continue to produce unprecedented amounts of data every year.
Descriptive Analytics
In many ways, descriptive analytics (or data mining) is the least sophisticated type of analytics. This doesn't mean that it can't help provide valuable insight into patterns. With descriptive analytics, we are trying to answer the question: what happened? Not nearly as exciting as predictive or prescriptive analytics, but useful nevertheless. Just as with other types of analytics, raw data is collated from multiple sources in order to provide insight into past behavior. However, the difference here is that the output is binary: Was it wrong or right? There is little depth to the data; it provides no explanation. Most data-driven companies go well beyond descriptive analytics, utilizing others to understand the data in order to effect change within their business.
Diagnostic Analytics
Diagnostic analytics might be the most familiar to the modern marketer. Often, social media managers track success or failure based on number of posts, new followers (or unfollows), page-views, likes, shares, and so on. Using this methodology, we are trying to discover why something happened. Comparative statistics are what drives diagnostic analytics, as we are comparing historical data with another set, in order to understand why data looks the way it does. This is why people love Google Analytics so much: it lets them drill down and identify patterns in how visitors interact with their site.
Predictive Analytics
Predictive analytics utilizes Big Data to illustrate how patterns in the past can be used to predict the future. Sales is usually a beneficiary of predictive analytics, as lead generation and scoring, along with the sales process itself, is built out of a series of patterns and data points over time. Predictive analytics tells us what is likely to happen, based on tendencies and trends, which makes this forecasting tool so valuable. Bear in mind that statistical models are just estimates. Accuracy is achieved through the continued accruement of clean, accurate data and the refinement of the model based on new information.
Source: Information Governance World magazine (infogovworld.com).
Prescriptive Analytics
Despite its clear value and sophistication, prescriptive analytics are not used as often and as widely as it should be, although that is changing. Perhaps it is an insistence on larger, systemwide analytics that makes this narrowly focused body of data overlooked so often. Its purpose is quite simple: What action should be taken in the future to correct a problem or take advantage of a trend? By looking at historical data and external information, a statistical algorithm is created that adds value to a company regardless of its industry.
Which Type of Analytics Is Best?
There is no easy conclusion about which one to use. It is dependent on your business scenario. Deploying a combination of analytics types is best to fit the needs of your company. Given the options, companies should choose that blend that provides the greatest return on their investment. Descriptive and diagnostic approaches are reactive; predictive and prescriptive are proactive. The real take-home message is to utilize data-driven analytics to first learn what is happening using descriptive and diagnostic analytics, and to move toward and understanding of what might happen, using predictive and prescriptive analytics. Leveraging analytics can provide dividends (pun intended) for companies by giving context to their business story and arming decision makers with better information, helping to provide a sustainable competitive advantage.
The Role of Analytics in IG Programs
For nearly four decades, data analytics has been used by leading organizations to gain new insights and track emerging market trends. Today, in the era of Big Data, increasingly sophisticated analytics capabilities are being used to help guide and monitor IG programs.
Structured Data Versus Unstructured Information
Data analytics relies on structured data, which is stored in relational databases. When computers are fed data, it fits into a defined model. All the data within the model is structured. Unstructured information, on the other hand, is basically everything else—e-mail messages, word processing and spreadsheet files, presentation files, scanned images, PDFs, and so on. Unstructured information lacks detailed and organized metadata. Structured data is more easily managed, analyzed, and monetized because it has rich and easily processed metadata. For example, a column titled “Name” will correspond to the name of the person linked to the rest of the data in the row.
It may be rather surprising, but unstructured information is stored rather haphazardly. Every day, knowledge workers create documents and send e-mails to communicate with other knowledge workers. Our personally unique and inconsistent preferences for what we name our everyday office e-documents and where we save them makes for a labyrinth of data. Even the nature of the information within them is rather chaotic. Free-flowing sentences do not make sense to computers like databases full of 1s and 0s. As a result, analysis is more difficult, at least until the proper metadata fields are created and leveraged—then the benefits can be quite significant.
Structured data is very useful for determining what is happening in the market or within your organization. However, relying on it will leave you missing the most important piece of the puzzle: why. Clearly, it is advantageous to know what is happening, but without the why it is impossible to act on.
Historically, data analytics has been an imperfect science of observation. Systems produce massive amounts of data, and data scientists correlate data points to determine trends. Unfortunately, correlation does not imply or translate to causation. Think about all the information that isn't included. Behind every one of these data points are e-mails and instant messages formulating ideas, as well as documents describing the thoughts and processes involved. There is a treasure trove of information to be found in the crucial unstructured data.
Take, for example, a typical enterprise of 10,000 employees. On average, this organization will generate over one million e-mail messages and nearly 250,000 IM chats every single day. During that same time, they will also create or update 100,000 e-documents. The problem is simply being able to corral and cull massive amounts of information into a useable data set. This is not an easy task, especially at scale. The challenge only increases with the production of more data. Not only are established technologies not designed to cope with this type of information, they're also unable to function at such high volumes.
IG Is Key
Without an active IG program, all this relevant information remains opaque in desktop computers, file shares, content management systems, and mailboxes. This underutilized or unknown information is referred to as dark data. Not only does understanding and controlling this information add value to your analytics program, it also reduces risk across the enterprise.
To control your information, you must own your information; when you own your information, you can utilize your information. This is much harder with unstructured information because most organizations have environments full of stand-alone, siloed solutions that each solve their own designated issue. This is fine from a business perspective, but a nightmare to manage for RIM and IG professionals.
A single document sent as an e-mail attachment could be saved in a different location by every person included in the chain. Multiple copies of the same document make it difficult, if not impossible, to apply universal classification and retention policies. The same file may be stored and classified separately by legal, compliance, HR, and records––and no one would know! When this happens, organizations lose control and expose themselves to undue risks.
Large organizations have petabytes of dark data haphazardly stored throughout their file shares and collaboration software. Much of this information is ROT (redundant, obsolete, or trivial). ROT data hogs storage and can slow down systems and search capabilities—thus hindering business function. ROT may also be stored in retired legacy systems. These legacy systems can be a thorn in the side of IG professionals because of the amount of dark data and ROT intermingled with important business records. Mass deletion is not possible, but neither is the status quo. Implementing modern, proactive IG strategies can be a daunting task that requires input from a number of sources.
So Where Do We Begin?
IG is not something to jump into all at once, but rather to ease into step by step. Often, the best place to start is with file analysis classification and remediation (FACR) software. In short, file analysis performs a series of system scans across file shares and other disk storage to index this dark data and bring it to light. A deep content inspection is conducted and standardized metadata tags are inserted (the classification and remediation part), based on a predefined metadata design plan. File analysis can be performed on the metadata or the content of files, depending on the intricacy and accuracy needed. Metadata is information about the topic, who created the file, as well as where and when, and how often it has been accessed. Think about the information on the outside of an envelope being metadata, while the actual letter enclosed is the content. Performing file analysis helps determine what information is ROT and can be deleted, what can be utilized, and what needs to be preserved.
Leveraging Newfound Knowledge
Analytics can help improve compliance functions by tracking and mapping information flows and communications. A communication heat map allows an administrator to view “who is communicating with whom about what” at a high level, while also having the granularity to drill down into any of the conversations that may set off compliance triggers. Beyond monitoring communications, tools are able to determine if there are sensitive or potentially illegal communications being shared or stored in documents and files. Doing so proactively is an additional safeguard to keep an organization safe.
These communication maps are also valuable to Human Resources. Knowing who communicates with whom, and about what, helps determine who the big impact players are within an organization. Understanding who knows and owns important information and tracking communication trends can help assess leadership potential and award promotions based on merit. It can also alert management about potential negative sentiments and potential insider threats to an organization. It can also provide insights to a potential acquiring organization in an M&A scenario.
For legal teams, the data insight can drastically improve Early Case Assessment (ECA) abilities during litigation. Since the legal team knows what information the organization has and where it is stored, there's no mad scramble to find information when litigation is initiated. Being able to analyze what information the organization holds saves time and effort in collection, while also providing a more accurate data set. It is not necessary to send massive amounts of information to outside counsel to be analyzed, which is very costly and time consuming. When litigation does arise, the legal team can quickly and accurately determine what, if any, liability the organization faces and can make informed decisions on how to proceed. A process that used to take weeks or months can now be completed in hours or days.
The benefits for records management teams are substantial as well. The insights gained from analysis provide important information about which documents are business records and which are unnecessary to retain. This goes beyond typical records, too. Items that are historically not considered records, such as private information discussed in an e-mail, now may be discoverable for litigation. This means record managers need to be able to identify this information and apply retention to it.
File analysis also makes compliance with new regulations (like the European Union's privacy law, GDPR) much easier. Many vendors have promised one-stop GDPR solutions, but the truth is there really is no such thing. GDPR is not something you can solve with a single-point solution, but rather something that requires the implementation of proper IG tools, techniques, and policies. Having in-depth knowledge of the information within an organization makes GDPR dSAR (digital subject access requests) a breeze.
Summing It Up
It is crucial to focus on the cross-functional benefits of IG in order to spur executives into action. The knowledge gained from analytics within IG helps create new value and possibly revenue, while minimizing risk. It is a competitive advantage that will shape the next few decades in the corporate world.
Artificial Intelligence
Artificial intelligence (AI) is simulation of human intelligence by computers: the ability of software to “learn” and make decisions based on inputs and conditions. This creates intelligent computers that can reason (using pre-set rules) and make adjustments or corrections on a fundamental level like humans, only much more rapidly and efficiently. The use of AI has drastically increased and is used for applications like robotics, the Internet of Things (IoT), speech recognition, complex classification, expert systems like medical and maintenance diagnostics, advertising and pricing, and even compliance.
AI tools can significantly assist in business functions, but AI systems can be expensive to develop and maintain, so they are increasingly being embedded into software applications as well as AI as a service (AIaaS), which allows experimentation and testing prior to making a major investment in AI.
Leading AI platforms include Amazon Machine Learning, IBM Watson, Microsoft Cognitive Services, and Google's Cloud Machine Learning.
There are deep ethical issues that arise with AI, worth considering, but more complex than the scope of this book.
Deep Learning
Deep learning is a type of AI, where the software continuously “learns” based on results it creates, without continual human input. David Naylor noted the “term deep learning was adopted to differentiate” between a “new generation of neural net technology” from previous machine-reading technology.2 In 2012, the University of Toronto used deep learning to “significantly improve speech recognition on Android devices and the prediction of drug activity in a Merck competition.” The key is prediction. AI thinks by using deep learning to predict things and make insights.
The Role of Artificial Intelligence in IG
AI solutions, if pundits are to be believed, will solve everything from data storage to transportation. The use of AI to assist in IG program tasks and activities is steadily rising.
Fostering GDPR Compliance
The European Union's new GDPR has left companies across the globe scrambling to gain control over the consumer data they have housed. Some software companies are offering AI tools to assist in this effort. One example is using machine learning technology (to automate analytical model building) to simplify compliance tasks. The software can give enterprises a holistic, comprehensive view of consumer data, regardless of where it is stored. It uses machine learning to identify relationships among data in different databases and data stores, including e-mail, instant messages, social media, transactional data, and other sources.
The goal is to ensure compliance with GDPR by gathering technical, business, operational and usage metadata, and providing more accurate compliance analytics and reporting.
AI in Health Care
Investment in healthcare-related AI is “expected to reach $6.6 billion by 2021,” resulting “in annual savings of $150 billion by 2026.”3 Organizations that participate in this growth will conceptually utilize an IG program leveraged with state-of-the-art technology infrastructure. This approach allows AI to do what humans cannot do, that is, structuring massive sets of big data. Facilitating these partnerships requires cooperation and close support for the end user to ensure that regulatory concerns about information sharing are adequately addressed.
While all business sectors will benefit from AI, the healthcare industry will see widespread adoption as administrators and CEOs realize its potential. This is an emerging technology, and, as such, businesses operating within the healthcare industry that begin using AI will gain a competitive advantage. The following five key steps help define how to leverage AI in healthcare:
- Users must understand what AI is and what it does. AI applications use the same data other systems use. Although the common perception is that AI simply replaces human ability, the key point is that it does some things “better” or “faster” or “more accurately” and/or some things humans want to do but cannot. For instance, Finnish company Fimmic Oy developed a deep learning AI application that helps pathologists identify abnormalities the human eye cannot see.4 The key is to remember AI's ability to leverage data and information at levels humans cannot. It is not a magic robot, but it does have powerful information-processing capabilities. With baseline training, existing healthcare workers should be able to manage and control new AI applications.
- AI can use sophisticated algorithms to “learn” features from a large volume of health-care data, and then use the obtained insights to assist clinical practice.5 Much of today's AI literature uses the term deep learning to describe what AI does behind the scenes.
- The long-identified issues of injury and death caused by medical errors (the third leading cause of death in the United States) can be addressed at a micro level. Given AI's learning capacity, the resulting data then becomes a point of leverage for funding elements such as Medicare reimbursements. Deep learning promotes “self-correcting abilities to improve system accuracy based on feedback.”6
- AI can assist with evidence-based practice (EBP) protocols. By monitoring the hundreds of accessible information databases, AI can enable real-time EBP. This physician/AI partnership adds to the benefits of meaningful use and other U.S. federal healthcare requirements.
- AI will contribute to public health initiatives. By linking preventive medicine routines with elements such as diabetes risk factors, healthcare organizations can begin to project “healthy communities” that ultimately contribute to public health initiatives that are equitable. It certainly costs less money to provide preventive healthcare services than to perform surgeries or to administer extreme treatments in an acute care setting.
Auto-Classification and File Remediation
AI is also being applied to large collections of unstructured information. Unstructured generally information lacks detailed and organized metadata and must be classified and mapped to an organization's information taxonomy so it can be managed. AI can be used to inspect the contents of e-documents and e-mails to make a “best guess” at how they should be categorized. Some of the more sophisticated FACR software can actually insert basic metadata tags to help organize (remediate) content. This is an essential task for executing defensible disposition, that is, following an established records retention schedule (RRS) and dispositioning (usually destroying) information that has met its life cycle retention requirements.
E-Discovery Collection and Review
AI is also used commonly to locate information that is responsive in a particular legal matter. Using predictive coding software (which uses AI and analytics), a human expert, usually an attorney working on a case, feeds the software examples of content (e.g. documents and e-mails) that are relevant. Then the software goes out into information stores and looks for similar content. It serves up the content and the expert reviewer goes through a sample and teaches the software “more like this” and “not like this” so the AI software gets better and better at narrowing its searches. After a few iterations, the software becomes quite efficient at finding the relevant information. But it doesn't have to be perfect. Courts in the United States have ruled that if the predictive coding software locates 70 percent or more of the responsive information, then that is acceptable, since that is about the accuracy rate of humans, due to fatigue and error.
AI has proven to be a good tool for IG programs to utilize to accomplish key tasks, and the use of AI in IG programs will continue to grow.
Blockchain: A New Approach with Clear Advantages
By Darra Hoffman
This article first appeared in Information Governance World, Fall 2018. Used with permission.
By now, we've all heard about blockchain technology—or at least its famous progenitor, Bitcoin. According to its evangelists, blockchain technology will secure our records, protect our privacy, democratize our technology, and probably fix us a cup of tea in the process. Blockchain's detractors tend to agree with John Oliver's takedown of Bitcoin and other cryptocurrencies as, “Everything you don't understand about money combined with everything you don't understand about computers.” So, what's the real deal? Is blockchain technology the miracle cure that will soothe the aches and pains of digital information governance? Or is it just so much snake oil?
What Is Blockchain?
That one guy who wears only T-shirts with memes told you that blockchain is the future. So why is it so hard to find out what blockchain actually is? In part, it's because there's no agreed-upon definition as to what constitutes a “blockchain,” and in part because there are actually a number of different kinds of “blockchains.” While academics can debate the nuances of exactly which technologies are and aren't “blockchain,” a blockchain can be understood as:
- A distributed ledger with a decentralized architecture
- Where transactions are:
- Immutable
- Secured through cryptography
“There's no agreed-upon definition as to what constitutes a “blockchain,” and in part because there are actually a number of different kinds of “blockchains.”
Breaking Down the Definition of Blockchain
A distributed ledger, or distributed ledger technology (DLT), is its own technology—of which blockchain is a form. A distributed ledger is a database of transactions. The “distributed” part comes in from the fact that every computer or server running the ledger (every “node”) runs that ledger in its entirety; there is no master-slave or master-copy setup. With a decentralized architecture, there is no centralized control over who can participate in the ledger. Instead of a centralized authority—say, Janice in accounting—maintaining the ledger, each node can construct and record its own updates to the ledger. The nodes then all vote on whether each update is valid and what order they occurred in through a consensus mechanism. While different consensus mechanisms operate differently, they all trust math (instead of Janice in accounting). This is why blockchain is considered a “trust-less” technology: there is no human or institutional intervention necessary to verify transactions. If the nodes reach consensus that a transaction is valid, it stays. If the nodes find a transaction invalid, it must sashay away.
Transactions on the blockchain are made immutable and secured to the blockchain through a clever bit of math. With a blockchain, each transaction is cryptographically hashed—a cryptographic hashing algorithm makes an alphanumeric “fingerprint” of the transaction based on its exact content, down to the bit. A block of 10 transactions will have 10 hashes. Those hashes are then all hashed together to make the block hash. That block hash becomes the first hash of the next block, “chaining” all of the blocks together to make … a chain of blocks (or a “blockchain”).
See What We Did There?
In the above illustration (which uses simple addition, as opposed to the incredibly complex math of a real hashing algorithm), Block 2's hash value is dependent on Block 1's value; Block 3, in turn, depends on both Block 1 and 2. Changing the hash of any transaction—which, remember, happens when any bit of that transaction is changed—destroys the entire chain of hashes going forward. Because every block is unbreakably chained to the previous block, the blockchain is considered immutable. Furthermore, the cryptographic hash function works in such a way that it is virtually impossible to reconstruct the original transaction from its hash (much like you can't build a person from a fingerprint). This means that it's impossible to tamper and then go back and hide the tampering.
So What Can Blockchain Do for Your Organization?
Blockchain is a new technology that uses math to secure transactions on a ledger that anyone can read or write to without permission from a central authority. So why do you—a busy information professional—care? Blockchain is way up in the hype cycle; your team might well be asking whether a blockchain makes sense for your organization. A few benefits of the blockchain get touted pretty often: a blockchain will make our records more secure; a blockchain is more private; or a blockchain is auditable. To evaluate whether a blockchain makes sense for your organization, you need to know how true each of those claims is.

Claims that blockchains are secure (or at least, more secure than other databases) rely on a few things. The first is the distributed nature of the blockchain ledger; being able to falsify records on the blockchain typically requires a “51% attack”—or gaining control of 51% of the nodes running the ledger. However, each user controls his/her/their own account through use of a private key; if that key is comprised, just like when a password is compromised, an attacker can then do anything the user could do. This is a real threat when considering the complexity of private keys and the elevated privileges in designs where a trusted body holds users’ keys in escrow. People are always a security threat; blockchains are no exception to that rule.
The second element of the blockchain that leads people to claim it is secure is its usage of cryptography (such as the cryptographic hashing). People sometimes think this means data on the blockchain is natively encrypted. It's not. In a public blockchain, like Bitcoin, transaction data cannot be encrypted; if it were, nodes couldn't validate the transaction without decrypting the data. If every node in a private blockchain is going to decrypt in order to validate transactions, then you have to ask why you're spending the time and money to encrypt in the first place. So, even though blockchains use public key infrastructure (PKI) and cryptographic hashing, there's a whole lot of unencrypted data (which, remember, anyone running a node can read) running around on a blockchain. Since encryption is pointed to as a reason that the blockchain is both more secure and more private, it's difficult to overstate how important it is to understand exactly what data is, and isn't, encrypted when considering a blockchain solution.
Finally, claims that the blockchain will make records more secure often point to the immutability of transactions secured to the blockchain. It's true: this is an excellent tool for ensuring the integrity of records. It also makes auditability a native feature of the blockchain. However, for records to be trustworthy—for information assets to retain their strategic or, in the case of litigation, evidentiary value—they must be accurate, reliable, and authentic.
Integrity Is Only Half of Authenticity
Blockchain cannot ensure the accuracy of a record; it's entirely possible for a user to enter a false or incorrect record onto a blockchain. Reliability is a condition of how a record is created; if Bob enters, say, an employee record into the blockchain without complying with the company's record's procedures, then that will be an unreliable record. Nothing that happens after a record's creation can make it reliable.
Lastly, authenticity—of which integrity is part—requires that a record is what it purports to be. There is nothing in the blockchain that instantiates the archival bond, which means a blockchain doesn't ensure a record's authenticity. Creating, managing, and preserving trustworthy records in a blockchain solution requires a lot of thought to build and integrate features that are not native to the blockchain.
When Is a Blockchain a Good Solution?
Are blockchains a complete write-off? A fad, doomed to the dustbin of history with Betamax and MySpace? No! Blockchains are still a technology in development, but they offer an excellent solution when you need a database with shared read/write permissions, have low trust between parties, need disintermediation, and have relationships between the transactions in the database.
The threshold question, then, is why do you need a blockchain (as opposed to simply a secure database)? The best answer is that you have parties who don't particularly trust one another, and you have some reason not to use a trusted third-party intermediary: cost, time, or simply the struggle finding someone all the parties can agree to trust. Like IG itself, blockchain technology integrates social considerations of trust with data and technical considerations.
As such, blockchains are rarely a good solution for information assets within an organization; the problems of trust and disintermediation (theoretically) shouldn't be an intra-organizational problem. However, they can be very useful for inter-organizational IG. Some of the problem spaces in which blockchain are being explored include land registries, supply chain management, food provenance, healthcare, and financial services. Examples include:
- The Linux Foundation's open-source collaborative blockchain, Hyperledger, being used by IBM to develop a banking application;
- Oracle developing preassembled, cloud-based, enterprise blockchain networks and applications;
- The National Association of Realtors developing a member-engagement data blockchain that allows permission-based access.

For those cases where a blockchain makes sense, design matters.
Implementing a successful blockchain requires asking in-depth technical questions:
- What consensus mechanisms?
- Permissioned or permission-less?
- What data will be encrypted?
- What kind of transaction speeds do we need?
- How scalable does this system need to be?
But it also requires asking a lot of people- and organization-oriented questions.
- Why do we need a trustless, disintermediated system?
- What are we trying to fix by implementing a blockchain?
- How do we make this accessible and useable to the end users, so that they trust the system where they didn't trust the previous processes?
- What regulatory challenges arise from using such a new technology?
- What makes the blockchain worth the extra investment, and how do we leverage that investment to maximize our return?
Implementing a blockchain should be a strategic choice.
Conclusion
Blockchains are new and sexy. They combine distributed ledger technology and cryptography in a way that lets transactions be processed without human intervention—and thus no need to trust human fallibility. But new and sexy is often the wrong strategic choice, especially if old and dependable is sufficient to meet organizational needs. Before implementing a blockchain, an organization should ask itself: Why?
Blockchain is fundamentally a technology that addresses a social problem—trust. For those cases where low trust and intermediation are problems, blockchain can offer a real solution to serious data management problems, bringing efficiency and transparency to processes that have long challenged interorganizational IG. However, in cases where trust is not the fundamental problem, blockchain technology is not the best solution. The key is asking what organizational needs a blockchain can meet that can't be met by its plainer ancestor, the relational database. Blockchain probably won't get us a cup of tea (though who knows where the Internet of Things will go), but it is a very useful tool to have in the toolbox, as long as one remembers that a hammer does not make every problem into a nail.
The Internet of Things: IG Challenges
First came the Industrial Revolution. Then the Internet Revolution. And today we have made a firm step into the dawn of a third revolution called the Internet of Things or IoT.7 Or at least this is how IoT's arrival was characterized by the head of the Industrial Internet Consortium—founded in March 2014 by household name companies like AT&T, Cisco, GE, Intel, and IBM to advance and coordinate the rapid rise of IoT. This is no hyperbole. Indeed, Cisco forecasts that IoT will have an economic impact of over $14 trillion by 2022, while per GE's prognosis, IoT could add $15 trillion to the world economy over the next 20 years.8
Stated simply, the IoT is the concept of connecting any device with an “on and off switch” to the Internet (and/or to each other). This includes everything from smartphones, lights and light switches, security doors, refrigerators, cars, washing machines, headphones, wearable devices, and almost anything else you can think of. The IoT also includes components of devices and machines, such as the engine in a car or truck, the sprayers on crop duster planes, vital signs monitors in hospitals, and much more.
The IoT is a clear example of the Big Data trend. With the massive amounts of data that will be created—from such a wide variety of devices, at unheralded speeds—new strategies and methods will be required in order to capitalize on the upside of IoT opportunities while minimizing its inherent risks and planning for e-discovery collection and review.
What created this emerging revolution in the IoT? Faster, cheaper Internet connections make it possible to transmit large amounts of data. WiFi connectivity is being built into devices and sensors, and mobile device use is exploding. New developments in nanotechnology have created micro-electromechanical systems (MEMS), and new software engineering approaches have created microservices, which are a suite of modular software services, each supporting a specific goal.
The onslaught of the IoT is undeniable and the changes in technology and the business environment make it difficult for organizations to develop successful, practical IG policies and practices.
As the IoT becomes a reality, the deluge of data discoverable in legal actions will dwarf the data tsunami that is seemingly engulfing litigation teams today. With the imminent influx of connections in the future, the number of devices and objects that e-discovery professionals will be called upon to collect data from will be infinite. The IoT will lead to the discovery of everything electronic.9
In layman’s terms, IoT represents the exciting and, for some, terrifying ecosystem of interconnected sensory devices performing coordinated, preprogrammed—or even learned—tasks without the need for continuous human input. Think thermostats, which “know” when to expect you to come home, so they automatically cool or warm your home just before you arrive. Now imagine your fitness activity tracker telling your thermostat that it needs to turn the A/C down a bit lower than usual before you come home because you have had an exhausting run. And maybe your auto insurance premiums will be determined in part by your driving habits as transmitted by embedded sensors.”10
The IoT is a growing area of interest for business and technology professionals. It “is a system of interrelated computing devices, mechanical and digital machines, objects, animals or people that are provided with unique identifiers and the ability to transfer data over a network without requiring human-to-human or human-to-computer interaction.”11
Some basic definitions of IoT:
- TechTarget defines IoT12 as: a system of interrelated computing devices, mechanical and digital machines, objects, animals or people that are provided with unique identifiers and the ability to transfer data over a network without requiring human-to-human or human-to-computer interaction.
- The IoT European Research Cluster (IERC) states that IoT13 is —A dynamic global network infrastructure with self-configuring capabilities based on standard and interoperable communication protocols where physical and virtual … things have identities, physical attributes, and virtual personalities and use intelligent interfaces, and are seamlessly integrated into the information network.
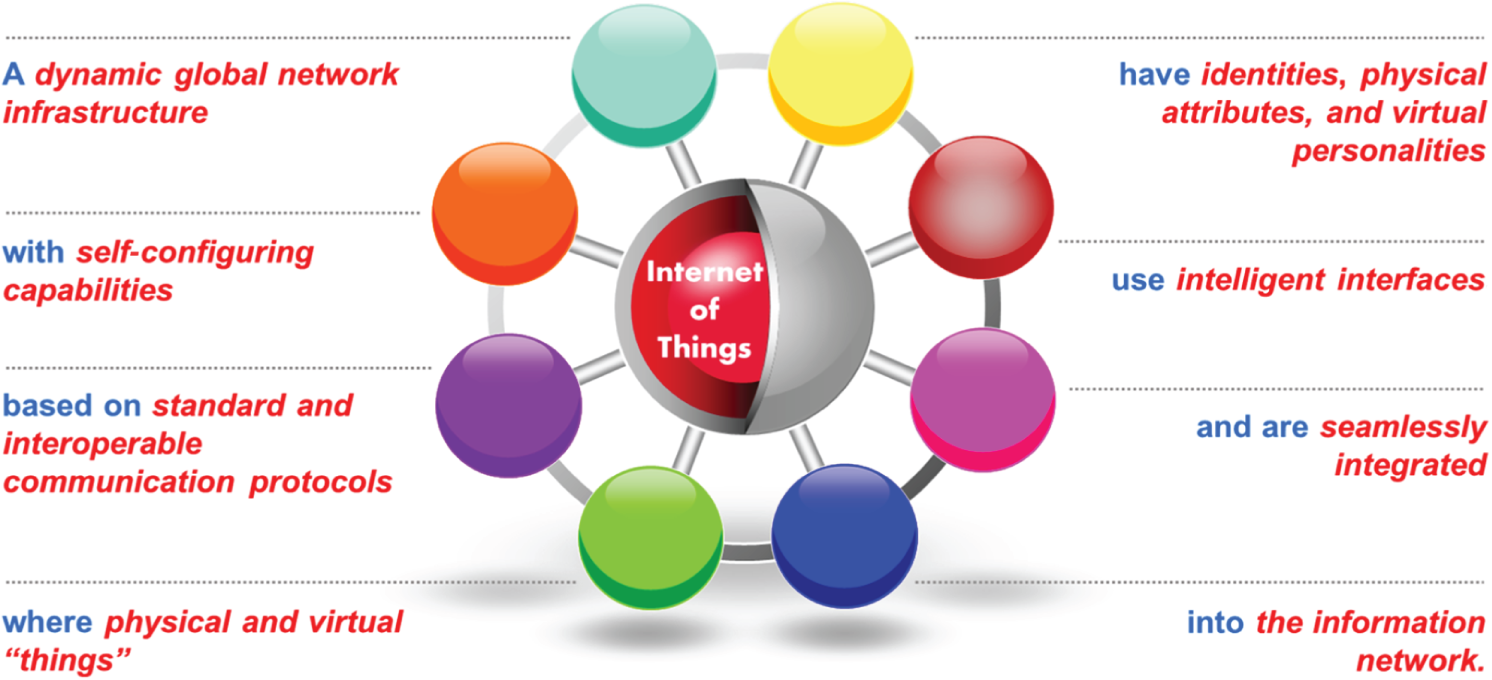
Source: European Research Cluster on the Internet of Things.
Stated simply, the IoT is the concept of connecting any device with an “on and off switch” to the Internet (and/or to each other). This includes everything from smartphones, lights and light switches, security doors, refrigerators, cars, drones, washing machines, headphones, wearable devices, and “almost anything else you can think of.” The IoT also includes components of devices and machines, such as the engine in a car or truck, the sprayers on crop duster planes, vital signs monitors in hospitals, and much more.
The IoT is a massive network of connected devices, which includes people. The interconnections will be “between people-people, people-things, and things-things.”14 The IoT has evolved from the convergence of wireless technologies, microelectromechanical systems (MEMS), microservices, and the Internet. The convergence has helped tear down the silo walls between operational technology (OT) and information technology (IT), allowing unstructured machine-generated data to be analyzed for insights that will drive improvements.15
The IoT, fully implemented and exploited, could radically change the way humans function in their everyday lives, including significant changes at work.16 But is also presets tremendous challenges in cybersecurity, e-discovery during litigation, and IG.
Some may cast off the IoT as a somewhat frivolous development that reminds you to buy more milk or automatically adjusts the heat in your home. However, its implications are much more far-reachng than that, and its impact will affect nearly all industries.17
The IoT extends the end node far beyond the human-centric world to encompass specialized devices with human-accessible interfaces, such as smart home thermostats and blood pressure monitors. And even those without human interfaces, including industrial sensors, network-connected cameras, and traditional embedded systems.
As IoT grows, the need for real-time scalability to handle dynamic traffic bursts also increases. There also may be the need to handle very low bandwidth small data streams, such as a sensor identifier or a status bit on a door sensor or large high-bandwidth streams such as high-def video from a security camera.
Homes and Offices
Utility companies will receive constant updates from meters and sensors in the field to monitor systems in real time and to proactively detect and remediate problems such as blackouts, water leaks and circuit overloads. Efficiency is optimized through continual analysis of trends, demand, and outages. In one instance, the city of Oslo was able to reduce energy costs by over 60 percent using IoT technology.”
“A thing, in the Internet of Things, can be a person with a heart monitor implant, a farm animal with a biochip transponder, an automobile that has built-in sensors to alert the driver when tire pressure is low—or any other natural or man-made object that can be assigned an IP address and provided with the ability to transfer data over a network.”18
The IoT is a massive network of connected devices, which includes people. The interconnections will be “between people-people, people-things, and things-things.”19
Gartner predicts that by 2020 there will be over 26 billion connected devices. These trends have created the ideal environment for IoT to take off and radically change work and life through technology assistance and augmentation.20 There will be big changes in healthcare, smart agriculture, precision manufacturing, building management, energy and transportation, and more.21
By 2025, the global Internet of Things market will be worth $3 trillion, up four times from $750 billion in 2015.22 In 2025, smart city services will reach 1.2 billion, more than 10 times the 115.4 million devices in 2015 worldwide.23
IoT as a System of Contracts
Contracts are an everyday tool used in business. But with the IoT, a digital contract can contain the terms and conditions to be carried out based on various scenarios.24
A digital contract is an explicit and machine-executable process between several business-entities, primarily, things and people. (Italics added for emphasis).
For instance, a new IoT-enabled refrigerator could have four types of contracts simultaneously: (1) with household members, (2) with the original manufacturer and service provider, (3) with e-commerce connections to grocery and food delivery providers, and (4) with the smart TV, cell phones, thermostat, and other things within a particular household.
Digital contracts are standardized, machine-executable processes that already know how to handle all these complexities. Each digital contract may be executed and records/audit trails would be kept by a blockchain.
IoT Basic Risks and IG Issues
Rachel Teisch succinctly stated the risks of IoT in a post on Lexology.com, grouping them into three main categories: cybersecurity, privacy, and Information Governance:25
Last year [in 2015], there were an estimated 16 billion devices connected to the Internet, and predictions say that the number will rise as high as 30 billion devices by 2020. The Internet of Things (IoT) has gained publicity (or notoriety) as yet another data source that may be subject to litigation or investigations in an e-discovery context, and there have been a few cases already (e.g. a Fitbit device has already played a prominent role in a criminal case) involving IoT data. There's likely more to come, presenting yet another major headache for corporate counsel and their legal teams, given the wealth of data stored in IoT devices.
Yet, so many devices collecting data on every aspect of our lives gives rise to a number of critical issues—so many so that to call it merely the Internet of Things trivializes its importance. Rather, it can also be coined the Cybersecurity, Privacy, Information Governance, and eDiscovery of Things.
Cybersecurity for IoT
If a cybercriminal hacks into a firewall and delves into a company's benefits database, there are risks of data loss and privacy breaches. But when an Internet of Things device is breached, the ramifications can be even more dire. If a hacker intercepts an unmanned vehicle's Internet connection and sends it malicious directions, it could lead to property damage as well as severe injuries or even death. Or, if a hospital is the subject of a denial of service attack, it could compromise medical records or even allow outsiders to manipulate medicine dosage through Internet-controlled pumps.
Privacy for IoT
Who owns the data that these devices create? Is it the exerciser tracking steps with a fitness device, the homeowner adjusting a thermostat, or the driver of a car? In general, no. The companies collecting this data often reserve the right to access, use, and even sell their data within their terms of service agreements. And sometimes, devices are collecting data without users consenting or being aware: for example, connected streetlights and beacons in retail outlets. Depending on where the data is collected, processed, and stored, it could also implicate cross-border data protection laws.
Information Governance for IoT
With the Internet of Things, companies have access to a number of new data streams that may be relevant for regulatory matters or lawsuits. But because most of these devices simply gather data and send it to the cloud, it creates complicated issues relating to identifying where the data is located and then negotiating with a third-party provider regarding its retention, control, and custody.
Each of these issues has the potential to spawn litigation and regulatory actions. Recognizing the risks, legal counsel at the forefront of these challenges are taking several steps:
- They are embracing their ethical duty to remain technologically competent by understanding the implications of these devices.
- They are considering what technologies their organizations are deploying and what data they are collecting and storing.
- They are ensuring the impact of the Internet of Things is contemplated in policies and procedures that address privacy, security, records management, and litigation readiness.
- They are working with eDiscovery specialists to devise ways to preserve and collect the relevant data for litigation and investigations.
Information governance is going to be an essential element to include in planning as the IoT develops. “The sheer volume of information from Internet enabled devices is enough to bog down even the most robust systems. The ‘keep everything’ approach cannot work with the oceans of data generated by Internet enabled devices. Everything from data maps to back-up procedures is impacted. Deciding what to keep and what to eliminate is critical. Data of sufficient importance must be protected while records of low value must be disposed of intelligently. Automated classification can help sift essential data from the chaff. Additionally, policy and procedures should regularly eliminate redundant, outdated, or trivial (ROT) records. Because the amount of data is so much greater from IoT sources, defensible deletion becomes a governance priority.”26
IoT E-Discovery Issues
The amount of discoverable data will drastically escalate as the IoT matures. The “IoT will lead to the discovery of everything electronic.”27
In today's litigation environment, data stewards and litigation attorneys search for electronically stored information (ESI) from traditional sources, like computers, phones, disk drives, and USB drives to find e-mail and data relevant to a pending legal matter. But new devices and data types are constantly being introduced so litigation professionals are seemingly always developing new ways to locate and preserve data. “For example, e-discovery professionals today are working to develop collection protocols for data contained in social media platforms, SnapChat applications, and text messages. When IoT devices become the norm, legal and IT professionals will need to quickly address some of the following concerns: who is in control of the IoT device, the format of the data being generated from relevant IoT devices, and how IoT data can be cost-effectively gathered for litigation processing and review.”28
Once all the sources of this new ESI are located, that data must be added to the pool of discoverable information, which may include e-mails, spreadsheets, word processing documents, and presentation files. Today, this information is typically housed in some type of online litigation repository and document review tool. In the last decade, these online repositories and review technologies have advanced quickly to help with the increasingly daunting discovery process. For example, some of these platforms even possess cutting-edge “predictive coding” features that use artificial intelligence to weigh the responsiveness of a document in a legal matter. Although e-discovery innovations are keeping pace, document review databases and e-discovery technology platforms will have to kick it into ludicrous warp-speed to deal with the immense volume of new and diverse discoverable data coming from the IoT revolution.
“Determining whether IoT data is relevant to a suit and if any privilege or privacy concerns exist will present an additional challenge. The first step will be to efficiently remove superfluous data in the growing sea of information from IoT devices. An added complexity for businesses will be to draw the line between personal data and data that is relevant to the legal matter, while sufficiently protecting private data, such as personally identifiable information or financial and health information. This will be especially challenging as the line between personal use and corporate use is blurred by IoT devices.”29
E-Discovery Dangers
“Beyond IoT issues like data privacy and information security, there are eDiscovery dangers lurking beneath the surface of companies’ IG programs.”30 These dangers, which are particularly acute in the context of litigation holds and data preservation, are becoming better known through industry education efforts. For example, a highly publicized session from the 2014 Georgetown Law Advanced E-Discovery Institute brought much-needed attention to the issues. During that session, speakers representing various constituencies observed that the IoT could raise any number of preservation and production challenges in the discovery phase of civil litigation. Ignatius Grande from the law firm of Hughes, Hubbard & Reed explained that the IoT was not designed to accommodate eDiscovery demands:
“Many products in the IoT sphere are not created with litigation hold, preservation, and collection in mind,” he said. “In terms of liability … companies will most likely be responsible to preserve data produced by the capabilities of their products and services in the event of a litigation hold.”
This is the case: unless appropriate measures are adopted to ensure that IoT data is preserved for litigation or regulatory matters, relevant IoT materials could be lost, setting the stage for expensive and time-consuming satellite litigation.31
Security
Security is also a major issue. Organizations will have to develop new policies and processes to manage and govern IoT data. And sometimes real-time analytics will need to take place. New data processing capacities will need to be developed for this massive amount of data flowing from the IoT.
In addition to data storage concerns, the IoT explosion is driving backup and retention difficulties. With limited storage space on current IoT devices, most IoT technologies integrate with existing technologies. As such, it is likely that any IoT data also resides on another device such as a smartphone, tablet, or server, meaning that the data is probably already backed up and governed by existing corporate policies and practices. For example, smart watches need to be connected to a smartphone to access e-mail, text messages, and social media accounts. However, as IoT devices become more stand-alone, with greater capacities to store data without the assistance of another device, corporate information governance and “bring your own device” policies will need to expand to include considerations for these hypermobile IoT devices.
Lastly, IoT innovations will create a multitude of security issues, including cyberattacks, data breaches, and hacking. A recent study from HP Security Research found that 70% of Internet-connected devices are vulnerable to some form of hacking. As IoT continues to expand, there are rising concerns about the increased number of entry points for hackers into the smart home or office. The challenge will be to make IoT devices tamper-proof to ensure their physical connections cannot be modified, their operating system or firmware is unalterable, and any data they contain is void of extraction in an unencrypted form. In addition, no matter how secure the IoT infrastructure, companies will still have to pay extra attention to the security of the data center that stores and processes data that comes in from IoT equipment.”32
Challenges Ahead
It should be abundantly clear now that organizations need to have an actionable plan to prepare for the data privacy, information security, and e-discovery implications of the IoT. As an initial phase in this preparation, companies should determine the extent to which the IoT affects or will affect their consumers and employees. Understanding the range of potential IoT issues will provide clarity on the next steps that should be taken.
One of those steps likely will involve the development of an IG strategy that accounts for the massive data generated from the IoT. “Such a strategy should include a plan for identifying information that must be kept for business or legal purposes while isolating other data (particularly PII) for eventual deletion. It also should encompass steps to ensure compliance with the privacy expectations of domestic and international data protection authorities. Enterprises also will need to ensure that their litigation readiness programs are updated to include a process for preserving and producing relevant IoT data.”33
Taking a proactive approach that addresses these issues will help companies avoid many of the treacherous problems associated with the IoT. While it may not lead to smooth sailing all of the time, it will establish a process that can enable the successful disposition of IoT issues.
As your organization deploys various devices connected to the Internet, bear in mind that any and all of the data these devices generate and exchange is discoverable in litigation and must be considered in compliance planning.
The Federal Rules of Civil Procedure (FRCP), since the landmark 2006 changes to accommodate electronically stored information (ESI), and its update in 2015, have made it clear that “all data within the enterprise is discoverable. As businesses expand their network of connected devices and collect more and more data, there will increasingly be an expectation that the data is discoverable.”34
Due to the variety and velocity of data from multiple device types, the collection and preservation of IoT data will be challenging.35
That is why you must have an IG strategy and Information Governance Framework (IGF) in place to drive and guide your IG program. Your IGF will present the guardrails or guidelines within which your organization will manage the collection and preservation of IoT data.
Why IoT Trustworthiness Is a Journey and Not a Project
By Bassam Zarkout
Overview
We have seen several iterations of the “Internet of X” mantra over the years: The Internet of Content, the Internet of Commerce, and the Internet of People.
The most recent iteration and arguably the most significant one is the Internet of Things. Recognized as one of the key enablers for Digital Transformation, IoT is the ability to configure sensors on things36 in order to capture operational data, exploit that data, gain insight about the operation of these things, control them, alter their behavior, and ultimately produce “better outcomes.”37
Although IoT systems tend to be architecturally complex, the overall principle of their operation is fairly consistent: you Detect, you Derive, you Decide, and then you Do.
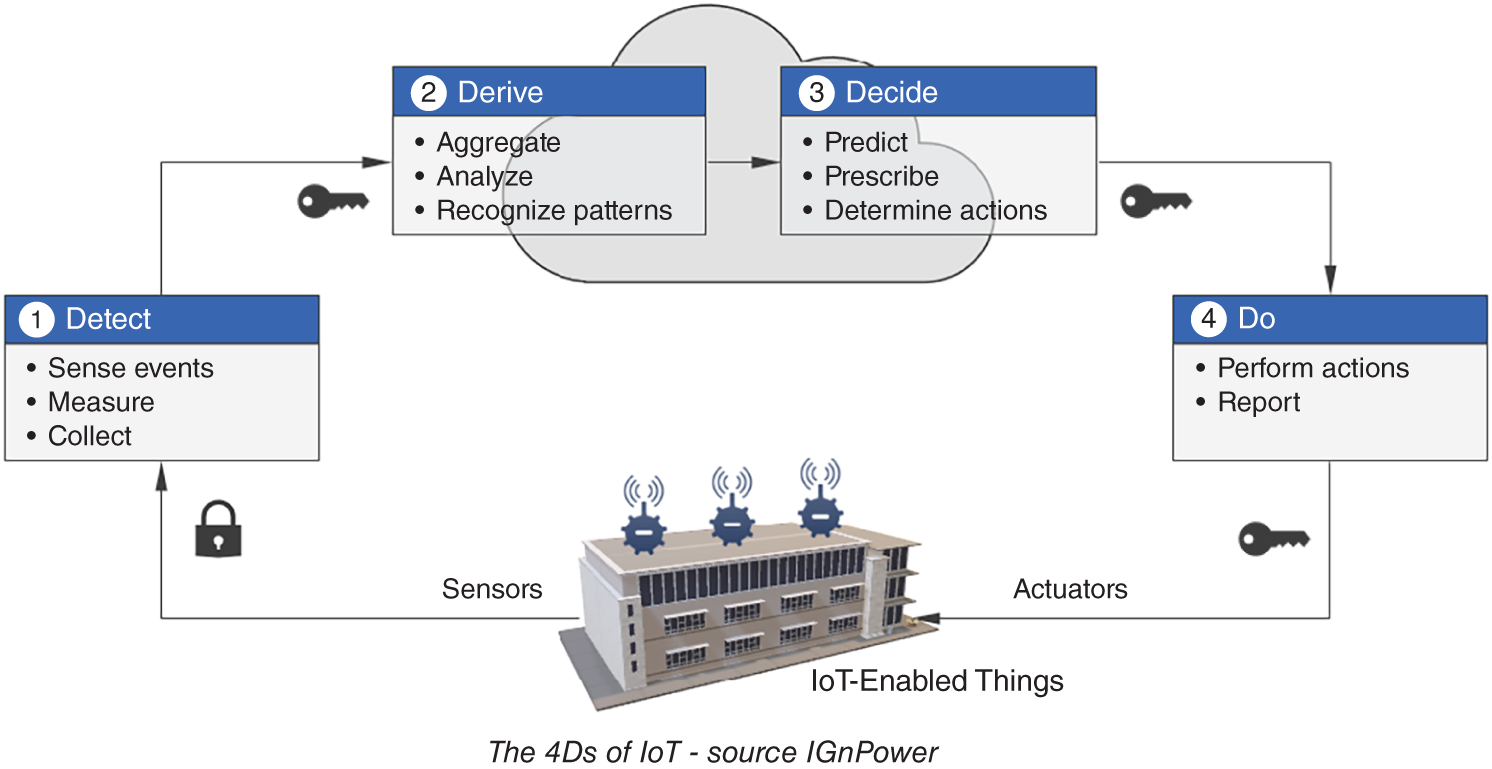
Most people associate the term IoT with consumer-oriented devices like home thermostats. But it is in various industries38 that IoT applications have the most impact. In the last few years the number of IoT sensors39 has grown exponentially. By 2020 that number is expected to exceed 20 billion. This means that IoT systems are destined to generate volumes of data that will dwarf the volumes of data and information generated by business systems.
As an information covernance professional, I consider that IoT data is corporate data that must be governed in accordance with legal and regulatory obligations and internal corporate policies.
As an IoT professional, I would say … yes, but not so fast.
This article will introduce the term IoT Trustworthiness, an emerging domain that overlaps with IG in some areas, but is potentially much more significant to the organization.
This article is thus a call to action to both IoT practitioners and IG professionals:
- IoT practitioners should heed the growing governance debt that will inevitably result from the exponential growth of IoT data volumes.
- IG professionals should watch out for that incoming train called IoT and recognize the important role they are destined to play in IoT Trustworthiness.
Governing the IoT Data
As already stated, data produced and consumed by IoT systems should be considered as corporate data that is subject to governance controls mandated by laws, regulations, standards, and eDiscovery rules, as well as rules defined by internal policies.
Adopters of IoT solutions are facing a wide range of technical and organizational challenges: how to cope with fast-evolving technology and architecture, how to deal with the challenges of integration, and above all how to reconcile IT with OT40 issues and manage their convergence.
As IoT solutions continue to expand and mature, the volume of IoT data generated by the sensors will witness exponential growth, and organizations will have to address several fundamental questions:
- What is the IoT data and who owns it?
- What are the rights of the IoT solution adopters?
- What are the obligations of the IoT solution providers41 toward this data?
- What are the Data Protection best practices for this data?
- How long should this data be retained?
- How to deal with issues like data lineage and data residency?
Throughout my years in the IG space, I have always been struck by the years of inaction of organizations vis-à-vis their mounting IG debt and the uphill battles IG practitioners continue to face in getting their initiatives off the ground.
There is no question in my mind that the governance of IoT data will face similar challenges. But these challenges will be more complex here, however, due to the physical nature of these systems.
I will get into these challenges in the next section, but let me first get the “good news” out of the way:
- Governance debt for IoT data is still very low: Most IoT systems have been in production for a relatively short period of time. This means that the volume of IoT data is relatively low at the moment and the governance debt for the IoT data is still low. No time to waste here, however, since the volume of IoT data is about to explode.
- IoT data is structured and well organized: it should not be difficult to identify this data, classify it, and define governance rules for it. Adding governance frameworks to existing IoT systems to actually enforce the governance controls will require engineering efforts, but it is doable.
IoT Trustworthiness
The discussion about governing IoT data cannot be limited to data only. This is due to a very simple fact about IoT: IoT is much more than IT for Things.
By definition, IoT systems have a digital side and a physical side. The governance of the IT aspects of these IoT systems (security and privacy) cannot be separated from the governance of the OT aspects of these systems (safety, reliability, and resilience).
Enter the term: IoT Trustworthiness.
The Boston-based Industrial Internet Consortium or IIC42,43 defines IoT Trustworthiness as follows:

Source: Industrial Internet Consortium.
It is the degree of confidence one has that the system performs as expected with characteristics including safety, security, privacy, reliability, and resilience in the face of environmental disturbances, human errors, system faults, and attacks.
Establishing and maintaining the trustworthiness objectives in an IoT system leads to better outcomes, such as a better alignment with the corporate business objectives, a better visibility of operational risks, and so on. On the other hand, failure to achieve and maintain the trustworthiness objectives can lead to significant negative consequences, such as serious accidents, equipment failures, data breaches, and operational interruptions to name a few.
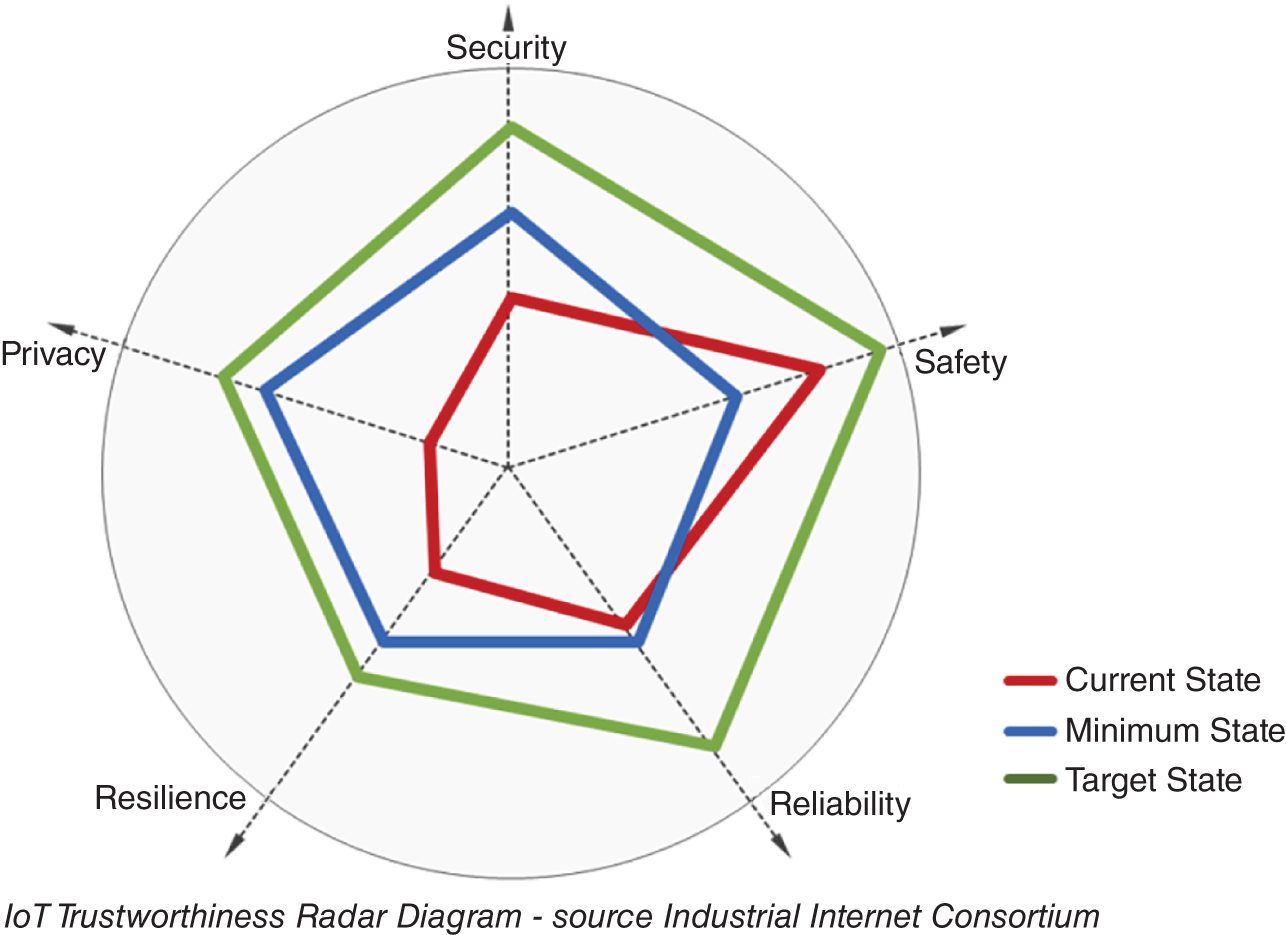
In order to assess the overall trustworthiness state of an IoT system, one must look at the state of each of the IoT Trustworthiness characteristics: Security, Safety, Reliability, Resilience, and Privacy.
For example, the current state of one characteristic may fall short of the minimum level mandated by laws and regulations for that characteristic. On the other hand, the current state of another characteristic may meet the minimum level but fall short of the target level set at a corporate level.
Below is a description of these current, minimum, and target states:
- Current state (red): This is the “trustworthiness” status of the IoT system, based on how it is currently designed, implemented, and operating.
- Minimum state (blue): This is a non-negotiable trustworthiness level mandated by external authorities and parties, for example, legal, regulatory, standards, and industry best practices.
- Target state (green): This trustworthiness level exceeds the minimum state, and is based on internally defined and self-imposed drivers and objectives (business and technical).
The “radar map” in the diagram below provides an example of the IoT Trustworthiness states of a system. In this example, Safety exceeds the mandated minimum legal requirements while the other characteristics (Security, Reliability, Resilience, and Privacy) fall short of their respective mandated minimums and thus require efforts to become compliant.
Source: Industrial Internet Consortium.
This visual view of IoT Trustworthiness will help the organization understand its current situation vis-à-vis the trustworthiness of IoT systems and prioritize the work needed to become compliant.
Information Governance Versus IoT Trustworthiness
Readers who have been trained in the art of information governance should have recognized by now that IG and IoT Trustworthiness share some similarities:
- IoT Trustworthiness may be complex as a topic, but at the end of the day IoT data is corporate data that must be governed. This data must be classified, its life cycle managed, and its e-discovery properly handled in case of litigation.
- Like IG, IoT Trustworthiness is a multifaceted discipline that requires a collaboration between multiple groups in the organization.
- Just like IG, IoT Trustworthiness needs a leader45 who is empowered46 to drive the trustworthiness efforts throughout the life cycle of the IoT system.
IoT Trustworthiness is also different from IG. Its scope is much wider, covering several well-established functions that have their own teams, long traditions, and mandates. Safety plays a very prominent role in IoT, and cybersecurity plays a central and enabling role in IoT and beyond (safety, privacy, etc.).
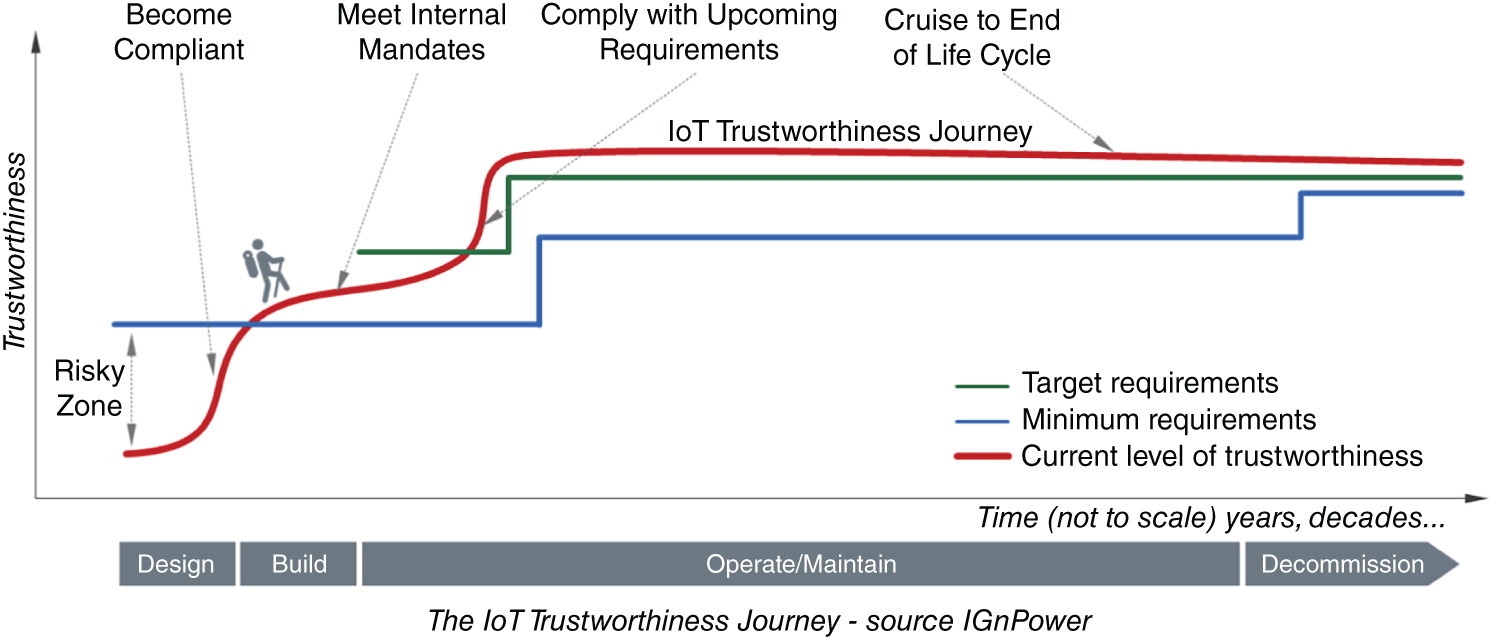
IoT Trustworthiness Journey
IoT systems tend to have long life cycles. For example, the life cycle of a manufacturing plant and its systems may be decades long:
- During this long life cycle, some of the plant's internal systems and subsystems may be upgraded, IoT-enabled, or totally replaced.
- IoT data produced and consumed by the plant's systems may have long life cycles.
- Trustworthiness requirements for the system may change over time due to changes in laws and regulations or changes in the architecture of the system itself.
What all this means is that establishing and maintaining the system's trustworthiness is not a project. It is an effort that must be sustained throughout the life cycle journey of the system (diagram below):
The IoT Trustworthiness journey must be piloted by a program that acts as a framework for organizing, directing, implementing, and maintaining trustworthiness of an IoT system throughout its life cycle, and in accordance with established Corporate Business Objectives.
Similar to the Information Governance program within the organization, the IoT Trustworthiness program must have a corporate sponsor to set the mandate and empower the organization to achieve that mandate, a program tsar to lead and manage the program, and a steering committee for the stakeholders who will coordinate the cross-functional implementation of the various facets of trustworthiness.
The program must also deliver real value to the organization in the form of “better outcomes.” This value must be communicated to the various groups and stakeholders in the organization in terms they relate to and understand.
A lot to unpack here and perhaps I should dedicate a chapter in the future to the subject of the IoT Trustworthiness Program, its structure and its activities.
Suffice it to say that a core component of the initial stages of this program is an assessment of the current state of the IoT system and a determination of the minimum state based on external drivers like laws and regulations, and the desired arget state based on internal drivers like corporate strategy.
Source: IgN Power.

Source: IgN Power.
IG professionals have an important role to play in this regard.
Conclusion
The trustworthiness of IoT systems and the governance of their IoT data are key to ensuring that these systems can deliver on their intended objectives. Both efforts should be maintained throughout the full life cycle journey of the IoT systems and their IoT data.
There is little time to waste here as IoT technologies and architectures are evolving fast. AI and distributed ledger technologies like blockchain are starting to play central roles within IoT systems. Issues like AI ethics (why did the AI make this versus that decision) and the seemingly irreconcilable conflicts between blockchain and privacy (for example, GDPR's right-to-forget) are coming to the forefront.
Terms like safety-by-design, security-by-design, and privacy-by-design are not mere catchy buzzwords. They have a significant impact on the success of IoT systems and ultimately on the Digital Transformation strategies of organizations. These terms must be understood and the principles behind them weaved into the fabric of the IoT systems.
To close, I think it is safe to say that the need to govern IoT data is real and looming … it is also inescapable. But it is part of a wider conversation in which issues related to the trustworthiness of IoT systems will dominate the conversation.
Again, IG professionals will have an important role to play in all this.
Notes
- 1. Sam Fossett, “The Role of Analytics in IG Programs,” Information Governance World (Fall 2018), 47.
- 2. C. David Naylor, “On the Prospects for a (Deep) Learning Health Care System,” JAMA 320, no. 11 (2018): 1099–1100. doi:10.1001/jama.2018.11103.
- 3. “AI And Healthcare: A Giant Opportunity,” Forbes, February 11, 2019, https://www.forbes.com/sites/insights-intelai/2019/02/11/ai-and-healthcare-a-giant-opportunity/#599177fd4c68.
- 4. J. H. Tibbetts, “The Frontiers of Artificial Intelligence,” BioScience 68, no. 1 (2018): 5–10, https://doi-org.wgu.idm.oclc.org/10.1093/biosci/bix136.
- 5. Fei Jiang et al., 2017. “Artificial Intelligence in Healthcare: Past, Present and Future.” Stroke and Vascular Neurology 2, no. 4 (2017): 230–243.
- 6. Ibid.
- 7. Reproduced with permission from Electronic Commerce & Law Report, 20 ECLR 562, April 15, 2015. Copyright © 2015 by The Bureau of National Affairs, Inc. (800-372-1033), www.bna.com.
- 8. Ibid.
- 9. Michele C. S. Lange, “E-discovery and the Security Implications of the Internet of Things,” April 13, 2015, https://sm.asisonline.org/Pages/Ediscovery-and-the-Security-Implications-of-the-Internet-of-Things.aspx.
- 10. Reproduced with permission from Electronic Commerce & Law Report, 20 ECLR 562, April 15, 2015. Copyright © 2015 by The Bureau of National Affairs, Inc. (800-372-1033) www.bna.com.
- 11. http://internetofthingsagenda.techtarget.com/definition/Internet-of-Things-IoT (accessed September 16, 2016).
- 12. Ibid.
- 13. European Research Cluster and the Internet of Things, www.internet-of-things-research.eu/about_iot.htm (accessed December 24, 2018).
- 14. Jacob Morgan, “A Simple Explanation of ‘The Internet of Things,’” Forbes, May 13, 2014, www.forbes.com/sites/jacobmorgan/2014/05/13/simple-explanation-internet-things-that-anyone-can-understand/#2440d0e86828.
- 15. http://internetofthingsagenda.techtarget.com/definition/Internet-of-Things-IoT (accessed August 23, 2016).
- 16. Morgan, “A Simple Explanation of ‘The Internet of Things.’”
- 17. Ben Rossi, “Why the Internet of Things Is More than Just a Smart Fridge,” InformationAge, September 22, 2014, http://www.information-age.com/technology/mobile-and-networking/123458485/why-internet-things-more-just-smart-fridge.
- 18. http://internetofthingsagenda.techtarget.com/definition/Internet-of-Things-IoT (accessed August 23, 2016).
- 19. Morgan, “A Simple Explanation of ‘The Internet of Things.’”
- 20. Ibid.
- 21. http://internetofthingsagenda.techtarget.com/definition/Internet-of-Things-IoT (accessed August 23, 2016).
- 22. Machina Research, IoT Global Forecast & Analysis 2015–25, August 5, 2016, https://machinaresearch.com/report/iot-global-forecast-analysis-2015-25/.
- 23. IHS Markit, “Smart City Devices to Top 1 Billion Units in 2025, IHS Says,” May 24, 2016, http://press.ihs.com/press-release/technology/smart-city-devices-top-1-billion-units-2025-ihs-says.
- 24. Alexander Samarin, “The IoT as a System of Contracts,” August 6, 2015, https://www.linkedin.com/pulse/iot-system-digital-contracts-thanks-blockchain-bpm-ecm-samarin.
- 25. http://www.lexology.com/library/detail.aspx?g=594bb08c-e31d-4570-a4e7-bc2517d93e83 (accessed April 15, 2016).
- 26. http://www.sherpasoftware.com/blog/information-governance-and-the-internet-of-things/ (accessed August 23, 2016).
- 27. Michele C. S. Lange, “E-discovery and the Security Implications of the Internet of Things,” April 13, 2015. https://sm.asisonline.org/Pages/Ediscovery-and-the-Security-Implications-of-the-Internet-of-Things.aspx.
- 28. Ibid.
- 29. Ibid.
- 30. Philip Favro, “IoT Data Collection Raises Legal Ediscovery Questions, Data Informed.com, May 21, 2015, http://data-informed.com/iot-data-collection-raises-legal-ediscovery-questions/.
- 31. Ibid.
- 32. Ibid.
- 33. Ibid.
- 34. www.insidecounsel.com/2016/04/28/will-the-iot-become-the-ediscovery-of-things.
- 35. Ibid.
- 36. Automotive, aerospace, machines in plants, agricultural equipment, city lights, elevators, and so on.
- 37. New business models, enhanced productivity, and so on.
- 38. Manufacturing, cities, transportation, retail, agriculture, healthcare, and so on.
- 39. IR sensors, image sensors, motion sensors, accelerometer sensors, temperature sensors, and so on.
- 40. Operational Technology such as SCADA systems and ICS.
- 41. The Data Controllers and Processors in the GDPR terminology.
- 42. https://www.iiconsortium.org/.
- 43. https://www.iiconsortium.org/news/joi-articles/2018-Sept-IoT-Trustworthiness-is-a-Journey_IGnPower.pdf.
- 44. Removal of redundant, obsolete, and trivial content from corporate shared drives.
- 45. Gartner recommends the appointment of a Chief Data Officer to own the Information Governance function.
- 46. Empowered with authority and budgets.