
Introduction to Theory in Medicine
1.1 Introduction
On September 5, 1976, a man named MabaloLokela was admitted to the Yambuku Mission Hospital in what is now the Democratic Republic of the Congo [8, Ch. 5]. Gravely ill, Lokela was suffering an intense fever, headache, chest pain and nausea. He vomited blood and had bloody diarrhea. Medical personnel recognized the signs of a hemorrhagic fever, but they were still largely in the dark. A variety of pathogens cause hemorrhagic fever, and there was no time to determine which one was causing this particular case. Lokela was clearly in serious trouble. Unfortunately, his health care workers failed to recognize that they were also in serious trouble.
Roughly speaking, Lokela’s tissues, including his skin, were melting away, causing massive internal bleeding. After a few days he had exhausted the clotting factors in his blood, and he began “bleeding out.” By then, the hospital staff could do little more than watch him die.
Ominously, just after Lokela’s burial, a number of his friends and family began experiencing similar symptoms. Eventually, 20 of them contracted the same disease. Two survived. While these 20 people suffered, the hospital in Yambuku started admitting patient after patient with the same sickness. Eventually, hospital staff, too, began to fall ill. The epidemic spread like wildfire. Within weeks of the outbreak, astonished, and frankly terrified, scientists and medical professionals around the world scrambled to understand what was happening in Yambuku. Initially they focused on two questions: what was the pathogen, and how did it pass from person to person? Surprisingly quickly they discovered that the pathogen was unknown to science (at that time) and that it jumped between hosts via body fluids. Unaware of this latter point early in the outbreak, many Yambuku medical workers contracted the disease because they failed to protect themselves from their patients’ blood. The hospital became an amplifier of the epidemic as the pathogen spread from patient to patient, carried at times by the medical workers themselves. Quickly, however, hospitals throughout Sub-Saharan Africa were made aware of the disease and taught how to handle it. The epidemic died out nearly as rapidly as it flared.
In this way the world learned of Ebola hemorrhagic fever, also called Ebolavirus disease (EVD). Since then the world has seen a number of other Ebola outbreaks. In 2014 an Ebola epidemic spread more extensively to West Africa, specifically to Sierra Leone, Liberia and Guinea. This extremely long lasting outbreak was probably started by a 2-year-old boy died in December 2013 in the village of Meliandou, Guinea. It caught the world off guard because, unlike previous outbreaks, this one did not flare and rapidly die out on its own, largely due to the poor health infrastructure and the lack of standard practices to prevent the outbreak in the affected countries. As of November 1, 2015, over 28,607 cases have been reported, of which over 11,314 patients have died, making it the deadliest Ebola epidemic thus far according to WHO Ebola situation reports [19]. Despite this tragic human suffering and loss, the dynamics of this epidemic can be reasonably predicted by simple mathematical models correctly modeling the human behavior change dynamics after some initial period of time [2].
Against the background of the tragedies in Yambuku and West Africa we see the functioning of modern medicine. Here we use the word medicine in its most general sense—it means “the art of preventing or curing disease” and “the science concerned with disease in all its relations” [15].1 In Yambuku, the two “arms” of medicine, curative and public health care, complemented each other beautifully. As its name implies, curative medicine focuses on cures or treatments for diseases—the Yambuku Mission Hospital staff trying to keep MabaloLokela alive, for example. In contrast, the goal of public health is to prevent disease. In Yambuku, public health professionals (perhaps) slowed the epidemic by identifying the pathogen and recommending techniques to prevent infection among hospitals in the region. When these two arms of medicine work together, the effectiveness of medical intervention is maximized. Although popular culture tends to focus on curative medicine— nearly all health-related movies and shows are set in hospitals with physicians and surgeons treating individual patients, and our experience tends to suggest that most young students entering so-called “pre-med” undergraduate studies are unaware of the existence of public health as an arm of medicine—a strong argument can be made that public health is primary. As the developing world shows us daily, inadequate public health care makes curative medicine superfluous. Without clean water, for example, the number of cases of infectious disease simply swamps curative efforts (see Section 1.3 below).
The definition above also suggests that medicine is both art and science. The art of medicine typically refers to clinical practice.2 In the clinic, medical professionals work with individual patients out of necessity—each patient presents a unique case. In contrast, medical science seeks broad patterns andcausative relationships within the chaos of individual cases. These patterns exist both within and among patients.
As the tragedies of Yambuku and West Africa show, medical science informs, or should inform, the practice of the medical art. Health professionals in the clinic rely on discoveries made by their scientific colleagues. At least, they should. When they do, we refer to the practice as evidence-based medicine. Our goal in this book is to explore how mathematics, dynamical models in particular, have in the past and can in the future advance the practice of evidence-based medicine, specifically as it applies to oncology, the science and art of studying and treating tumors.
1.2 Disease
Central to all of medicine, and its founding scientific discipline of physiology (see below), is the concept of homeostasis, a concept that includes both equilibrium and disequilibrium. For example, we say that mammals homeo-statically regulate body temperature because they maintain a constant body temperature in disequilibrium with the environment. A dead mammal in a thermally invariant environment will maintain a constant body temperature, but not homeostasis.
Antithetical to homeostasis is the concept of disease. By the standard definition [15], disease is “an interruption, cessation, or disorder of body function, system or organ.” A more modern outlook would take this down to the level of cells and even molecules. Since almost all organs, systems, cells and molecules work to maintain homeostasis, it might be tempting to define disease as a threat to homeostasis. However, this definition would not apply to diseases of the reproductive system, which functions not to maintain homeostasis but to perpetuate the genes. Nevertheless, homeostatic mechanisms exist, ultimately, in support of the reproductive system in metazoans (multicellular animals).
Like the word medicine, “disease” can be used with subtly different meanings. The word also applies to a sickness with “at least two of these criteria: recognized [causative] agent(s), identifiable group of signs and symptoms, or consistent anatomic alterations” [15]. A symptom is something a patient feels that indicates disease, whereas a sign is an outward, objective manifestation of disease. According to these definitions, sore throat is a common symptom of a cold, whereas fever is a common sign of bacterial infection. A collection of signs and symptoms characteristic of disease is called a syndrome. For example, HIV infection is a disease characterized by acquired immunodeficiency syndrome (AIDS), signs of which include loss of certain types of immune cells and the presence of various opportunistic infections and cancers, like Pneumocystis carinii pneumonia and lymphoma, among others.
1.3 A brief survey of trends in health and disease
We adopt the view that any mathematical model of disease dynamics must connect in some way to the clinic. Otherwise the exercise is either pure mathematics, in which case its origin as a model of disease is hardly relevant, or it reduces to a triviality. This viewpoint justifies our decision to start with a survey of biomedical science and not mathematical techniques. Our goal is to help both mathematics and science students interested in theory to develop the skills and understanding necessary to contribute in a meaningful way to pathology—literally, the study of suffering—with the ultimate goal of alleviating some of that suffering. It is a daunting task that no one should enter without a clear understanding of what they are up against. Therefore, we include here a survey of the patterns of disease around the world.
About half the people on the planet will die from infection, cancer, coronary artery disease or cerebrovascular disease (primarily strokes).3 However, simple lists like this are misleading because patterns of disease are strongly influenced by socioeconomics at all levels, from individuals to nations (Fig. 1.1). Speaking generally, poor countries contend primarily with infectious diseases, particularly pulmonary (including tuberculosis), diarrheal, HIV, malaria and neonatal (among infants) infections. Infectious diseases are less significant in wealthier countries, where chronic diseases mostly associated with senescence—cancer, CAD, cerebrovascular disease, chronic obstructive pulmonary disease (COPD) and dementia—are the major killers. This pattern is reflected in life expectancy; in countries the WHO classifies as “high income,” > 2/3 of the inhabitants reach the age of 70, compared to “low income” countries, where < 1/4 do, largely due to high death rates among children.
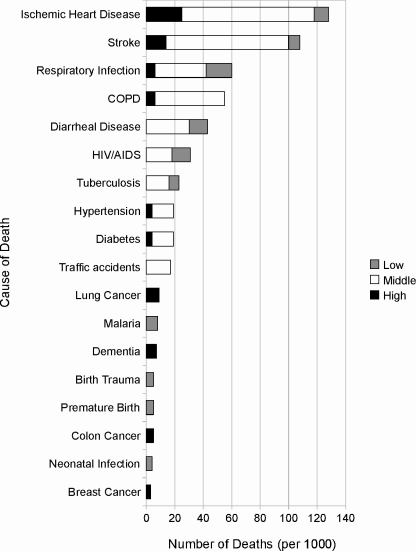
Main causes of death in the world in 2004, broken down by general income class (high income countries = black, middle income countries = white, low income countries = grey). Data from the World Health Organization (WHO) Top 10 Causes of Death Fact Sheet. NOTE: Data do not reflect all causes of death; it is a sum of the top 10 causes of death in each economic class.
That infectious disease is the leading killer tells a somewhat misleading story because the concept “infectious disease” includes many more disease entities than a simpler concept like “CAD” does. To microorganisms our bodies represent a vast reservoir of natural resources. Not surprisingly, an enormous diversity of microbes in all but two of the standard kingdoms have evolved to exploit those resources.4 Humans are particularly susceptible to infections in the lungs. Tuberculosis, a disease caused by the bacterial pathogen Mycobacterium tuberculosis, commonly, but not exclusively, resides in the lungs, as does an astonishing variety of bacterial, fungal and viral agents. For this reason, respiratory infection is a major killer in all nations, regardless of income status. Next most vulnerable to infection is the gut, especially the lower intestine. Here, however, diarrheal disease is a major killer only among the poorer nations. Poor and middle-income countries also suffer disproportionately from HIV, Mycobacterium, neonatal, and Plasmodium infections. This last agent is a class of eukaryotic (nucleated) parasites that cause malaria, which is a particularly devastating disease. Even though it ranks sixth in the world list of infectious killers, its impact is perhaps greater than all the others combined. The disease itself is very common—WHO estimates approximately 173 million cases occurred in 2008, compared to 2.7 million tuberculosis and the same number of new HIV cases.5 Although largely survivable, malaria causes debilitating, sometimes recurring fevers that limit an individual’s ability to work and provide for the family. There is a strong negative correlation between national wealth and malaria incidence, and some have suggested thatthe relationship is causal.
Neoplasia, literally “new growth,” includes all tumors, both benign and malignant. This latter class is synonymous with cancer. As the names imply, most deaths from neoplasia occur from malignant tumors, but not all. “Benign” tumors are not always benign; pheochromocytomas, for example, are rarely malignant but can still kill by secreting hormones that generate hypertension (high blood pressure). Like infectious disease, neoplasia comprises a vast array of distinct disease entities, and patterns of both incidence and mortality vary with economic status. In most high-income countries like the United States, deadly cancers arise primarily in the lung, breast, colon/rectum and prostate. However, middle and low income countries bear a much greater burden of stomach and liver cancer. So the global cancer mortality pattern as shown in Figure 1.2 represents only the total cancer death rates for some major cancers in the world, which may not resemble cancer mortality pattern of any actual countries.
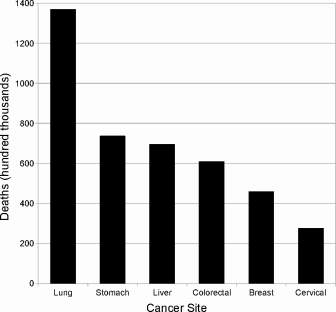
Worldwide mortality from the five leading causes of death from neoplasia. Height of each bar represents total number of deaths (in 100,000s) in the world in 2004. Data from WHO cancer fact sheet, February 2009.
In the last century, wealthy countries like the United States have made tremendous strides in combating infectious disease. In the last few decades, effective prevention strategies and drugs combating CAD and cerebrovascular disease have significantly decreased the number of deaths from these causes as well, although they remain leading killers. On the other hand, deaths from diabetes mellitus and chronic lower respiratory diseases (CLRD) are moving in the opposite direction. Cancer still kills essentially the same number as always over the same time period (Fig. 1.3).
![Figure showing trends in age-adjusted mortality rate in the United States, 1980-2007, all races and both sexes combined. Data from National Center for Health Statistics 2009 report [13].](http://imgdetail.ebookreading.net/math_science_engineering/24/9781498785532/9781498785532__introduction-to-mathematical__9781498785532__image__fig1-3.png)
Trends in age-adjusted mortality rate in the United States, 1980-2007, all races and both sexes combined. Data from National Center for Health Statistics 2009 report [13].
This observation and the fact that a higher proportion of people die from neoplasia than ever before suggests that we are losing the “war on cancer.” In fact, a subtle relationship among leading causes of death obscures the fact that we are clearly winning. By 2007, cancer death “rates” (essentially the proportion of individuals killed by cancer in a fixed time interval) have fallen to 70% of their 1975 value among Americans younger than 65 at time of death (Fig. 1.4). While the number dying from cancer in older age groups is essentially unchanged over the same time period, deaths from CAD, the leading killer, have dropped tremendously (Fig. 1.4). In fact, the drop in CAD deaths among all age groups should result in an increase in cancer deaths as those who before would have died from heart attacks (and strokes) survive and become increasingly susceptible to cancer as they age. But, in fact, cancer death rates have decreased slightly, which itself is significant.
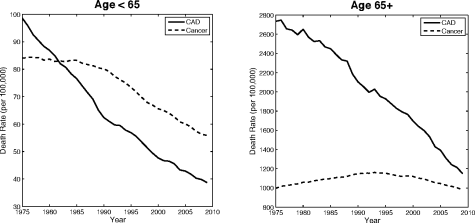
Trends in age-adjusted mortality rate from heart disease and neoplasia (all sites) in the United States, 1975-2007 for deaths among individuals < 65 vs. ≥ 65 years of age, all races and both sexes combined. Figure reprinted from the Surveillance, Epidemiology and End Results (SEER) Cancer Statistics Review, 1975-2007 with the kind permission of the National Cancer Institute.
Trends in 5-year survival statistics also support the notion that, generally speaking, we are treating cancer patients increasingly effectively. As shown in Figure 1.5, 5-year survival is improving for all four leading killers: lung, colorectal, breast and prostate cancers, particularly the latter two. Colorectal cancer, while still very deadly with generally poor prognosis, is now considerably more survivable than in 1975; so is lung cancer, but its prognosis remains extremely poor.
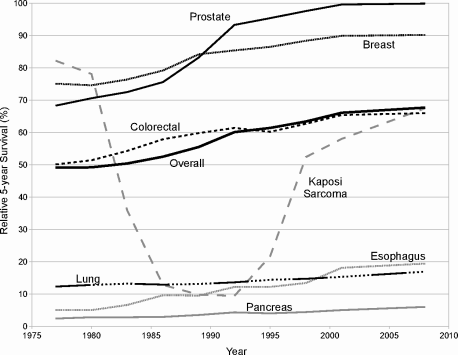
Relative 5-year cancer survival in the United States, all cancer types, all races, both sexes combined. Data represent average survival for patients diagnosed within the period between data points, with the data plotted on the right-hand endpoint of the period. Data from the National Cancer Institute’s SEER Cancer Statistics Review, 1975-2007.
Lung cancer warns us that, despite recent successes, we still have far to go. Pancreatic and esophageal cancers, along with lung, are in the list of extremely difficult cancers to treat successfully, despite recent modest improvement. In some cases the story is more complex; the odd pattern of survivability in Ka-posi sarcoma, for example (Fig. 1.5), is explained largely by its relationshipto HIV/AIDS. Kaposi sarcoma is extremely rare, arising only in individuals who are already immune-compromised. Therefore, it is a common opportunistic disease characterizing AIDS. When the HIV epidemic flaired in the early 1980s, Kaposi sarcoma rode along. Then in the late 1990s, fairly effective treatments for HIV became widely available, which consequently diminished mortality from Kaposi sarcoma because the disease is rarely fatal in immune-competent individuals.
1.4 The scientific basis of medicine
Modern curative medicine is founded on the scientific disciplines of anatomy and physiology, the studies of form and function, respectively, of living sys-tems.6 However, emphases are shifting. As a direct result of the molecular biology revolution, the scale of focus continues to become finer and finer. Traditionally, disease processes were understood at the organ system level. With the advance of microscopy, including improved instruments and staining techniques, tissue- and cell-level processes were added to our descriptions and explanations of disease. Now, new medical insights arise mostly from molecular biology and so-called “-omics” technologies. Modern medical practice requires competence at all levels of biological organization from organ systems to DNA.
For example, consider coronary artery disease (CAD), a leading cause of death in the world (see Section 1.3). At the organ system level we think of the disease as being confined largely to the cardiovascular system—the heart, blood and blood vessels. We describe its most common cause as atherosclerosis, a narrowing of coronary (heart) arteries caused by plaque development within the vessels. Eventually, blood flow to the heart becomes blocked, most often by coronary thrombosis (a blood clot blocking an artery of the heart), causing infarction (tissue death caused by lack of blood flow) of a portion of the myocardium (muscular wall of the heart)—hence, myocardial infarction, or MI. At the tissue level, the arterial plaques, deposits of lipid and calcium carbonate mixed with smooth muscle cells, originate from inflammation of the artery wall, roughly speaking. These basic research discoveries led directly to the application of antiinflammatory drugs as preventative treatments for CAD. At the molecular level, it appears that low density lipoproteins (LDLs) somehow cause the inflammation. Not only does that observation explain why high blood LDL levels correlate positively with CAD, it led to lifestylerecommendations and new drugs, primarily statins, that have helped people in developed nations avoid premature deaths. How the body handles LDLs is in part determined genetically, so we recognize DNA as another potential target for therapy.
This CAD example, although greatly abbreviated, already exhibits many of the basic biology disciplines related to curative medicine—anatomy, physiology, histology (study of tissues), cell biology,7 molecular biology and ge-nomics (roughly, the study of all genes and DNA sequences in an organism and their variations among organisms). In addition, a competent biomedical scientist must have proficiency in basic chemistry, biochemistry, biophysics and classical physics. (Hemodynamics, the study of blood flow dynamics, requires plenty of fluid physics, for example). In mathematical medicine, we add the powerful tools of dynamical systems and stochastic processes to the mix, among other mathematical tools.
1.5 Aspects of the medical art
On its clinical side, medicine’s primary concerns include diagnosis, prognosis and treatment. Diagnosis refers to the identification of disease processes and their causes. For example, in MabaloLokela’s case, the disease process was hemorrhagic fever and the cause was Ebola Ebola virus infection. Prognosis, one of the most difficult aspects of medicine, involves estimation of the likely course of a disease and its threat to health or survival. A person infected with the same strain of Ebola virus that killed MabaloLokela faces a grim prognosis, for example—the probability of survival is less than 10%, and death usually occurs within two weeks of the onset of symptoms.
Treatment, of course, means an attempt to alleviate symptoms. One way to do that is to effect a cure, or permanent reversal of the disease process, usually by eliminating its cause. However, the goal of treatment is not always a cure. In many cases, a disease cannot be cured. In such situations, treatment may simply manage the disease so that it no longer progresses or presents a threat. The Highly Active Antiretroviral Treatment (HAART) applied to HIV patients works in this way. Although it cannot cure HIV disease, in most cases HAART allows HIV patients to live, if not a normal life, one close to it. In extreme cases, like terminal cancer, for example, it is not even possible to manage the disease. In these cases, standard practice calls forpalliative treatment—an attempt to alleviate symptoms to make the patient as comfortable as possible.
1.6 Key scientific concepts in mathematical medicine
In 1973, Theodosius Dobzhansky, a very highly respected Russian émigré geneticist from Rockefeller University and the University of California, Davis published an article in The American Biology Teacher with the deliberately provocative title, “Nothing in Biology Makes Sense Except in the Light of Evolution” [5]. Although Dobzhansky’s argument in that paper may not support the claim’s universality as it is now interpreted, the subsequent three decades of research in biology and medicine largely have. Certainly, evolutionary concepts, especially the theory of natural selection, have become a founding pillar of biomedical research and the medical practice, even if its practitioners are not always aware of the fact. Antibiotic and cytotoxic treatment regimens for infectious agents and cancer, respectively, are now routinely framed around evolutionary principles, either implicitly or explicitly. If natural selection is ignored, such treatments fail at an unacceptably high rate due to the evolution of resistance. At a more mechanistic level, molecular data generated by the “genomics revolution” show clearly that the genome is not a collection of carefully crafted genes constructing a perfectly adapted organism. Rather, genes are typically copies of existing genes jury-rigged to generate novel, often imperfectly functioning proteins. This commonly results in unnecessarily extravagant genetic regulatory systems with potential failure modes that a human engineer designing a genetic system from the ground up could eliminate. Evolutionary theory helps make sense of this otherwise confusing design philosophy, and more excitingly is beginning to be used to explain diseases, predict their course and rationally search for treatments.
If evolution is one supporting pillar of biomedical science, genetics is an equally important second. Here we use the term “genetics” in its most general sense—the study of heredity and variation in organisms. Under this definition, essentially all diseases have a genetic component because a person’s response to disease is unique and largely explained by heredity. Also, as we will see, if “nothing in biology makes sense except in the light of evolution,” nothing in evolution makes sense except in the light of genetics. That is not to imply that genetics is the queen of biology because, as we have seen, genetics makes no sense without evolution. Instead, the two are so deeply entwined that appeal to one without the other either makes no sense or is unnecessarily trivialized.
1.6.1 Genetics
In 1865, an obscure paper entitled Versucheüber Pflanzen-Hybriden [Experiments in Plant Hybridization] was read at two meetings of the equally obscure Brünn Natural Science Society in the city of Brünn, Moravia (now Brno, Czech Republic). Its author was a monk and teacher from the Augustinian Order of St. Thomas, a local monastery dedicated to teaching science. He was an amateur without an advanced science degree, and the results disagreed with what was already known about how traits were passed from parent to offspring. So after the paper was published in the society’s proceedings the following year, it was roundly ignored. One of the leading authorities on heredity at the time, Carl von Nägeli, dismissed the results out of hand, despite a series of explanatory letters sent to him by the paper’s author. So the paper died of neglect, and its author never published again on heredity.
In 1900, three biologists—Hugo de Vries, Carl Correns, and Erick von Tshermak—discovered the basic rules of heredity independently of each other. Everlasting fame would certainly have been theirs, except that these same rules had already been worked out completely some 35 years earlier by an obscure monk who published his results in the equally obscure Proceedings of the Brünn Natural Science Society. The author was by then nearly 20 years in his grave, but it took that long for the scientific culture to mature sufficiently to allow his work’s significance to be recognized. Today no one but specialists remember who Carl von Nägeli, Hugo de Vries, Carl Correns or Erick von Tshermak were, although they also made significant contributions. But literally millions around the world know the name of the Augustinian monk from Brünn—Johann Mendel, given the name Gregor when he took his monastic vows.
Mendel discovered a special class of traits determined by a very simple genetic system. Although traits of this type are generally uncommon across all organisms, Mendel found seven examples in his experimental species, the garden pea (Pisumsativum). He discovered that each of these seven traits were determined in a given individual by two immiscible “factors,” one inherited from each parent. These factors come in two possible forms, which today we call alleles. In modern terminology, we say that each of these simple traits is determined by a single gene that has two allelic variants. A list of the precise alleles an individual carries is called its genotype, and the expression of the trait is called the phenotype. Individuals carrying two copies of the same allele are homozygous for the trait, whereas those with two different alleles are referred to as heterozygous. The transmission properties of these seven traits are further simplified because all exhibit dominance and recessiveness. A dominant allele, by definition, is expressed in the heterozygote, while a recessive allele is not. We call the phenotype associated with each allele the dominant and recessive phenotypes, respectively. All seven traits on which Mendel focused show one dominant and one recessive phenotype.
Mendel’s stature and the importance of his discoveries can easily lead one to the false conclusion that Mendel is the architect of our modern theory of genetics. He is not. He correctly interpreted the laws of transmission of only the simplest class of inherited traits, which are rare. Mendel never claimed that these patterns hold for all traits. In fact, toward the end of his paper he identifies a number of exceptions. For example, Mendel found that flower and seed color in beans (Phaseolus) does not follow the same pattern as he saw in peas. Since Mendel, we have found a number of patterns that nearly conform to his “laws,” but not quite. For example, snapdragons (Antirrhinum magus) with red flowers crossed with white-flowered plants have pink-flowered offspring. This type of blending in heterozygotes is now called incomplete dominance. Mendel also pointed out that flower color in a variety of species is wildly variable, and then came remarkably close to the modern notion of poly-genic inheritance—that is, traits determined by multiple genes—to explain it. Another common pattern not explained entirely by Mendel’s hypotheses are codominant traits, in which two alleles are dominant at the same time. The classic example is ABO blood type in humans. Individuals with blood type AB are heterozygous and are blood type A as well as blood type B; therefore, by definition both phenotypes are dominant, a pattern Mendel never addressed. In fact, so few traits exhibit Mendel’s patterns that they must be considered the exception rather than the rule, a fact most biologists at the time, including Mendel himself, recognized.
So, if Mendel’s patterns are so rare, why do we revere him—and we do revere him—as the “father of modern genetics?” Mendel’s hypotheses were initially considered flawed in part because all competent biologists at the time knew obvious counterexamples to Mendel’s observations, but also because they completely disagreed with widely accepted contemporary theories based on the incorrect idea that the genetic material was a sort of fluid. In contrast, Mendel suggested that the material of heredity acted like particles passed from each parent to the child. This—the particulate nature of inheritance— was Mendel’s great contribution, and it opened the door to the modern genetic theory. The rules he discovered for the seven simple traits in peas represent the threshold separating ancient and modern ideas of heredity. We therefore codify these rules today as the following two principles:
Principle 1 (Segregation) For the seven traits Mendel studied, each parent passes exactly one of its two copies of the gene for that trait to its offspring. The copy chosen is a random draw, with equal probability of either copy being chosen. In other words, the gene copies segregate randomly among gametes.
Principle 2 (Independent Assortment) The Principle of Segregation acts independently on the seven traits Mendel studied.
Even though here we limit these statements to the traits Mendel studied in peas, the principles extend to some other traits in many other species. Traits and their controlling genes that obey the Principles of Segregation and Independent Assortment are called Mendelian. Let Ai and ai be distinct alleles of a gene indexed by i. Suppose two individuals heterozygous for n traits breed. If these traits are all Mendelian, then this breeding can be represented symbolically as
(Here the symbol × represents a breeding cross.) All possible combinations of genotypes in the offspring and their respective expected proportions are given by
By convention we would write AiAi or aiai for homozygotes instead of or . (Here the letters represent alleles and act like units; they are not quantities.) Since allele order does not matter in the genotype, the probability mass function for a single offspring to be homozygous for k (and heterozygous for n − k) traits is binomial:
As we have already seen, not all traits are Mendelian. Among the exceptions that Mendel noted are polygenic traits which are determined by the interaction of multiple distinct genes. In some cases, polygenic traits are expressed as continuous variables—human height, for example—in which case we call them quantitative. In others, the genes modify expression of a qualitative trait, in which the trait is given a non-numerical value—like fur color in mice. Even among relatively simple traits determined largely by a single gene, the Mendelian pattern is rare. For example, distinct traits determined by genes on the same chromosome, called linked traits, often fail to assort independently. Sex-linked traits are a special case; the genes are carried on only one of the sex chromosomes. Another example is meiotic drive, in which gametes carrying a particular allele for a particular gene are favored over other gametes carrying another allele for that gene. Meiotic drive represents only one mechanism disrupting Mendel’s Principle of Segregation. In general, any mechanism interfering with either of Mendel’s principles generates transmission distortion.
Two years after De Vries, Correns and von Tshermak rediscovered Mendel, Walter Sutton of Columbia University discovered “the physical basis of the Mendelian law of heredity” [16, pg. 39]. By carefully examining cells from the plains lubber grasshopper, Brachystola magna, Sutton discovered that every chromosome (in this species, and it turns out in many other organisms including humans) has a twin with the same size and location of the centromere, the structure holding the two halves of the chromosome together. Twin chromosomes are called homologous, which is a general term for structures orgenes that descend from a single common ancestor. Homologous chromosomes therefore carry copies of the same genes. Any cell with two complete sets of chromosomes is called diploid, as are organisms in which the majority of cells are diploid. Cells with only one set are referred to as haploid. Cells in which the number of copies varies, like many cancer cells, are called aneuploid.
Sutton also discovered that during meiosis—the process by which animals produce gametes (sex cells: egg and sperm)—homologous chromosomes segregate independently, one into each gamete. As a result, gametes from a diploid organism are haploid. Sutton therefore referred to meiosis as reduction division because it reduced the number of chromosomes by half. When the gametes fuse to form a zygote, the offspring must get one copy of each homologous chromosome from each parent, thereby reconstituting diploidy of the offpsring. So, chromosomes come in pairs, one inherited from each parent, and they segregate randomly and independently into gametes. It was obvious to Sutton that chromosomes are physical objects that obey Mendel’s two principles; therefore, equation (1.1) describes their behavior during meiosis and subsequent fertilization. Here was a physical manifestation of Mendel’s abstract “factors.”
Fifty-one years after Sutton’s paper appeared, two researchers from the University of Cambridge’s Cavendish Laboratory—an American named James Watson and a Brit named Francis Crick—published a tiny paper in the journal Nature8 that finally provided the physical foundation for Mendel’s mechanism of hereditary [17]. Although Sutton’s chromosomes behaved like Mendel’s factors, the number of chromosomes in any cell was always small, on the order of tens, compared to the number of traits apparently requiring genes, numbering at least thousands. Viewed naïvely, Watson and Crick’s paper does nothing obvious to resolve this problem; it simply provides a structure for deoxyribonucleic acid (DNA). However, DNA was known at that time to be the material of heredity, and every competent biologist in the world immediately recognized that Watson and Crick found the mechanical connection between physics and chemistry on one hand and phenotype on the other.
A gene, as understood today, is a “packet” of information coded in the DNA. The most well-known genes are structural genes, so called because they determine the structure of a specific biological molecule, usually a protein or RNA molecule. But they also contain control elements that govern when and how many copies of the molecule are to be constructed at any given time. In general, genes are abstract concepts, not objects. In eukaryotes—cells with atrue nucleus and membrane-bound organelles—an entire gene cannot be accurately described as existing at a specific locus (location on a chromosome), as was once thought and still often taught. For example, a single protein coding gene comprises both localized structural and regulatory sequences along with dispersed regulatory regions. The primary structure (amino acid sequence) of the gene’s protein product is determined by a coding region adjacent to a set of regulatory sequences collectively called the promoter that in part controls the gene’s activity. Other regulatory sequences controlling the gene’s activity, called enhancers, are dispersed on the same chromosome hundreds or thousands of base pairs away from the coding region and sometimes found even on other chromosomes. Together, all these elements determine both structure and intracellular concentrations of their protein products.
Speaking tersely, a protein coding eukaryotic gene “turns on” when a molecule called a transcription factor binds to the promoter and assembles a protein complex that constructs a ribonucleic acid (RNA) copy of the DNA. The key element of this complex is a molecule called RNA polymerase. The poly-merase copies the coding region along with “leader” and “trailer” sequences called untranslated regions (UTRs). This copy process is called transcription and yields a physical copy of the gene called messenger RNA (mRNA). The mRNA copy contains the information carried in the coding region along with regulatory sequences in the UTRs that control how many proteins are made.
After the copy process is complete, the mRNA is modified and ushered out of the nucleus into the cytosol. There, an enormous molecular complex made of protein and other RNA molecules called a ribosome assembles itself around the mRNA. The ribosome then builds a protein to the precise specifications encoded in the mRNA coding region. The ribosome works its way along the mRNA molecule, reading the information stored there while it catalyzes the construction of the protein in a process called translation. Afterwards, the protein typically undergoes further processing and folding into its functional form. Inasmuch as proteins are the major molecular machines performing and regulating cell functions, as well as forming a nontrivial component of cell structure, a newly minted protein assumes a role in determining its cell’s anatomy and physiology—in short, its phenotype. The cell’s interaction with other cells and noncellular elements in its immediate environment is determined by its phenotype and that of the cells with which it interacts. These interactions then determine the phenotypes of tissues, which determine the phenotypes of organs, organ systems and finally the organism itself. Our understanding of this entire process, and much else besides, traces its intellectual ancestry back to Watson and Crick’s paper of 1953.
1.6.2 Evolution
Consider a collection of self-replicating entities—concretely, think of organisms or cells. If these entities (i) vary in their characteristics, (ii) that variation is heritable, and (iii) some variants have, by virtue of their heritable characteristics, consistently higher reproductive success than do others, then evolution by natural selection follows as a necessary consequence. This argument traces its historical roots back to Charles Darwin, although it was articulated in this clean way by Richard Lewontin [11] and John Endler [7] (see [9] for a historical treatment). Although the argument, as stated this way, is elegant, it has some technical ambiguities that need clarification. In particular, “consistently higher reproductive success,” also called fitness, seems clearer than it actually is. In reality, reproductive success is at least partially random. Therefore, by chance some “less fit” individuals could out-reproduce more fit individuals even though “on average” that won’t happen. So Lewontin’s and Endler’s conditions apply only in a “mean field” sense. Nevertheless, if reproducing entities vary, that variation is heritable and consistently associated with differential fitness, then natural selection can be expected to produce evolutionary change. Randomness and other evolutionary forces may swamp or negate its effects, but natural selection is still the rule.
Why does evolution and natural selection matter to someone interested in medicine? First of all, replicating entities are ubiquitous in disease systems. Cancer cells, pathogens and parasites all reproduce. So do the human beings who suffer from disease. These replicating entities vary, and that variation is heritable. Cancer cells within a single tumor are often genomically unstable and therefore quite genetically diverse. Replicating cancer cells cannot help but pass these genetic alterations on to their daughters. Pathogens and parasites also vary genetically, both among and within hosts. Again, replicating microbes pass their genetic characteristics to their “offspring.” Certainly humans vary, and just as certainly that variation is largely heritable. So, reproduction with heritable variation is without doubt a ubiquitous property of entities of interest to medicine.
If any of this heritable variation correlates with a fitness advantage vis-á-vis disease, then natural selection almost certainly plays a role in the disease process. Consider tumor progression, for example. Tumor development is largely explained by a mapping between genetic alterations and differential reproductive advantage among tumor cells. In addition, some tumor cell variants resist cytotoxic (cell killing) chemo- and radiotherapy, and therefore have a selective advantage over other variants under treatment. Precisely analogous statements can be made for every known pathogen—certain variants can outcompete others within and between hosts, and we always find some strains that resist treatment. As for humans, much of our variation is associated with our immune systems, which has obvious fitness implications in the face of infectious disease and cancer. Heritable diseases like Duchenne muscular dystrophy or ataxia telangiectasia, which typically kill before the age of 25, have equally obvious fitness consequences. Some inherited disorders, like sickle-cell anemia and thalassemia, have both fitness costs and benefits. Both are examples of inherited anemias exhibiting major and minor syndromes. The major syndromes kill the very young from severe anemia and other complications. The minor form also exacts a fitness cost, either from direct morbidity (a milder form of anemia) or dangerous complications arising from comorbidity (another disease that arises in someone who already has one of these anemias). But there is also a fitness benefit—individuals with the minor form resist complications from malaria. These are just a few examples of how heritable variation in fitness affects disease, and we find it extremely challenging to find a single counter-example, a disease in which heritable variation has no effect on fitness in any organism (or virus) in the disease system in any way. Therefore, we conclude that evolution by natural selection is a common, probably ubiquitous, aspect of human disease.
Here we adopt the somewhat narrow view that organic evolution, or just evolution, is change in allele frequencies in a population over time. The frequency of a given allele, say A, is simply the fraction of all alleles in a given population that are A. Suppose a single gene has exactly m different alleles, A1, A2, ... Am, and the organisms carrying these genes are diploid. Denote the proportion of individuals in the population with genotype AiAj as Pij ∊ [0, 1], where the alleles’ order is considered. Biologists would therefore say the genotype frequency of AiAj is Pij (Actually, geneticists typically disregard allele order, so the conventional genotype frequencies would be Pii for homozygotes and for heterozygotes with the understanding that Pij = Pji.) Then the allele frequency of the ith allele is
If we view pi as a function of time, either discrete or continuous, then by definition no evolution occurs in a time interval [t0, t1] if and only if
Condition 1.3 is expected to fail if different genotypes confer different (mean) fitnesses. As an illustration that introduces the main mathematical ideas, consider a closed population (no immigration or emigration) with non-overlapping generations. We view time, therefore, as discrete; that is, t ∊ {0, 1, 2, ...}. Suppose that every individual with genotype AiAj contributes wij offspring to the next generation’s breeding population. We assume that wij is an invariant property of the genotype, which is typically justified by arguing that the population is infinitely large so that statistical fluctuations in the number of offspring born to a single individual are “averaged out.” If the effects of all other genes are evolutionarily neutral, then we can equate wij with fitness. This definition makes no assumptions about the source of fitness variation— the gene could affect juvenile survival, reproductive success or both. Finally we assume that in every reproductive bout, an offspring’s genotype is determined by two independent random draws from the population of alleles, with a single draw choosing allele Ai with probability pi. Biologically, this assumption means that mating is random with respect to gene A, and again the population is large enough that statistical fluctuations are expected to beaveraged out. Under these assumptions the number of individuals that carry genotype AiAj in the breeding population at time t + 1 will be
We define the mean fitness of this population as
which is also the total number of breeding adults contributed to the next generation. Furthermore,
Now suppose there is no differential fitness; that is, set wij = ŵ for all i, j ∊ {1, 2, ... , m}, where ŵ is a constant. Then
because . By condition 1.3, no evolution has occurred. An inductive argument based on these observations leads to the following celebrated result:
Theorem 1.1 (Hardy-Weinberg-Pearson)
Consider a reproductive population with non-overlapping generations. Suppose (i) wij is constant for all i, j ∊ {1, 2, ... , m} (no differential fitness; i.e., no natural selection); (ii) the proportion of genotype AiAj among offspring after any breeding bout is pipj where allele order is maintained, and pi is the frequency of allele Ai in the breeding population (mating is random); (iii) there is no immigration or emigration; (iv) no mutations occur in the gene A; and (v) fitness is invariant over time (the population is infinitely large). Then in a population with non-overlapping generations, (no evolution will occur).
Condition (ii) is equivalent to assuming that the genotype frequencies (with allele order considered) are given by each term in the expansion of
If we are biologists and disregard allele order in genotypes, then AiAj is the same genotype as AiAj, i ≠ j. With this convention, the results of Theorem 1.1 and the corollary above imply that the equilibrium genotype frequencies in a population as described in the theorem are
These results (and more) were first obtained by Karl Pearson in 1904 [14], and less general versions were formulated independently by Godfrey Hardy [10] and Wilhelm Weinberg [18] in 1908. For some reason tradition ignores Pearson—Theorem 1.1 is traditionally called the “Hardy-Weinberg” theorem, and the equilibrium frequencies are called the Hardy-Weinberg equilibrium. In fact, Hardy only focused on the special case in which m = 2, which reduces the expected equilibrium frequencies of genotypes AA, Aa and aa to , and (1 − p1)2, respectively, where here we use the convention that A1 = A and A2 = a. This simplification is how the topic is usually introduced in general biology textbooks.
To a biologist, the usefulness of the Hardy-Weinberg theorem comes from its hypotheses (assumptions). Relaxation of any introduces the possibility that pi(t) ≠ pi(t0) at some time t > t0, implying evolution would be possible. The random mating assumption (hypothesis ii), for example, can be violated in a number of different ways, a notorious one occurring when organisms choose mates differentially based on phenotypes conferred by the gene in question. This situation is called sexual selection, and most biologists view it as a special case of natural selection. Inbreeding is another violation, although alone inbreeding is not a mechanism of evolution. Evolution by gene flow occurs when hypothesis iii fails, mutational drive arises by relaxation of hypothesis iv, and finally genetic drift results from failure of hypothesis v. In the diseases we study in this book, natural selection, mutational drive and genetic drift are the dominant evolutionary mechanisms.
As a practical matter, biologists often use the Hardy-Weinberg theorem to determine if a particular gene is evolving in a natural population. If the population is not evolving (the Hardy-Weinberg theorem applies), then Pij(t) = pi(t)pj(t) since allele frequencies would be constant. If, on the other hand, Pij(t) ≠ pi(t)pj(t), then at least one of the mechanisms of evolution must be operating.
1.7 Pathology—where science and art meet
The goal of biomedical science is to develop a correct theory of disease. It can be approached, and is by many practitioners, as pure science. Ultimately, however, all biomedical theory must apply to health and disease in some way. The point of transition from medical science to medical art is typically the discipline of pathology, which according to a very influential text [3] is “a bridging discipline involving both basic science and clinical practice and is devoted to the study of the structural and functional changes in cells, tissues, and organs that underlie disease.” Note the scales in the biological hierarchy on which pathology focuses: from cells to organs. Taking a reductionist view, as we did earlier, organ function and malfunction can often be understood at the tissue level, which itself derives from interacting phenotypes among cells and so on down to the genes. So, by necessity pathology involves genetics. As genetics and evolution are deeply intertwined, evolutionary principles can also inform our understanding of pathology.
At its most general level, pathology attempts to define and explain the association between disease processes and their anatomical and physiological manifestations. Diseases by definition are deviations from normal function of the body at some level. That deviation is caused by some set of agents—for example, mutant genes, infectious agents, toxins, allergens and other environmental irritants, congenital malformations, and autoimmune responses. How these agents cause disease is the pathology subdiscipline of etiology, and the process by which the etiological agent and host physiology interact to produce disease is referred to as pathogenesis. The derangement of cells and tissues characteristic of disease generate changes in morphology, and the study of these changes, their cause and effects are the subdisciplines of histopathol-ogy and cytopathology, respectively. The clinical impact describes a disease’s presentations, prognosis and (sometimes) susceptibility to treatment. The physiological derangements generating the signs and symptoms of a disease is referred to as pathophysiology. As a practical matter, the mechanisms by which a disease threatens health are so tightly intertwined with the process generating the disease that pathophysiology often subsumes much of pathogenesis. These disease expressions, addressed from a scientific standpoint, are used by clinicians to both diagnose and plan treatment. Here, in the realm of pathology, theory built on mathematical modeling can and is having a great impact on our attempts to understand and treat disease.
References
[1] Brauer F, Castillo-Chávez C: Mathematical models in population biology and epidemiology. New York: Springer, 2001.
[2] Chowell G, Simonsen L, Viboud C, and Kuang Y: Is west africa approaching a catastrophic phase or is the 2014 ebola epidemic slowing down? different models yield different answers for Liberia. PLoS Currents 2014, 6.
[3] Cotran RS, Kumar V, Collins T: Pathologic Basis of Disease. St. Louis: Sanders, 1999.
[4] Diekmann O, Heesterbeek JAP: Mathematical epidemiology of infectious diseases: Model building, analysis and interpretation. New York: Wiley, 2000.
[5] Dobzhansky T: Nothing in biology makes sense except in the light of evolution. AmerBiol Teacher 1973, 35:125-129.
[6] Dunn LC: Mendel, his work and his place in history. ProcAmer Phil Soc 1965, 109:189-198.
[7] Endler J: Natural Selection in the Wild. Princeton: Princeton University Press, 1986.
[8] Garrett L: The Coming Plague: Newly Emerging Diseases in a World out of Balance. Chapter 5. New York: Penguin, 1994.
[9] Godfrey-Smith P: Conditions for evolution by natural selection. J Phil 2007, 104:489-516.
[10] Hardy GH: Mendelian proportions in a mixed population. Science 1908, 28:4950.
[11] Lewontin R: The units of selection. Ann Rev EcolSyst 1970, 1:1-18.
[12] Mendel G: Versucheüber Pflanzen-Hybriden. J Brünn Nat HistSoc 1866, 4:3-47.
[13] National Center for Health Statistics: Health, United States, 2009: With Special Feature on Medical Technology. 2010. Hyattsville, MD.
[14] Pearson K: Mathematical contributions to the theory of evolution. XII. On a generalized theory of alternative inheritance, with special reference to Mendel’s laws. Phil Trans Royal Soc London A 1904, 203:53-86.
[15] Pugh MB: Steadman’s Medical Dictionary. [27th ed.]. Philadelphia: Lippincott Williams and Wilkins, 2000.
[16] Sutton WS: On the morphology of the chromosome group in Brachystola magna. Biol Bull 1902, 4:24-39.
[17] Watson JD, Crick FHC: Molecular structure of nucleic acids: A structure for deoxyribose nucleic acid. Nature 1953, 171:737-738.
[18] Weinberg W: Über den Nachweis der Vererbungbeim Menschen. Jahresh Wuertt Ver varerl Natkd 1908, 64:369-382.
[19] World Health Organization: Ebola Situation Reports. http://apps.who.int/ebola/ebola-situation-reports, accessed on November 5, 2015.
[20] Wilkins MHF, Stokes AR, Wilson HR: Molecular structure of nucleic acids: Molecular structure of deoxypentose nucleic acids. Nature 1953, 171: 738-740.
1In addition to the meaning used here, “medicine” can also mean “a drug,” or health care not associated with surgery.
2The word “clinic” here refers generally to areas where medical doctors work—hospitals, private offices, and actual clinics, among others.
3This statement is based on data from the World Health Organization’s statistics service. For example, in 2004, infectious disease killed approximately 11 million people worldwide (about 19% of total deaths that year), cancer 7.4 million (12.5%), CAD 7.2 million (12.2%) and cerebrovascular disease 5.7 million (about 10%).
4We know of no plants or archaeans that act as human pathogens.
5In 2008, WHO estimates that 33.4 million people were living with HIV, which unlike most malaria infections is chronic. Therefore, there are about 5 times more new malaria cases in a single year than there are existing HIV cases.
6Despite the argument in the introduction section, in this course we largely ignore public health, founded on the science of epidemiology. Although fascinating, this topic is well treated in numerous other texts. See [1] and [4] for introductions to this field.
7Here we avoid the outdated term “cytology,” which seems to focus primarily on cell anatomy. The Medline Plus online medical dictionary defines cytology as “a branch of biology dealing with the structure, function, multiplication, pathology and life history of cells,” but most modern biologists studying cell function call themselves cell or molecular biologists.
8A companion paper by Maurice Wilkins, Alec Stokes and Herbert Wilson [20] provided support for Watson and Crick’s hypothesis using what turned out to be controversial x-ray crystalography. In essence, the molecule’s structure is worked out in part by studying how it defracts x-rays. An outstanding biochemist, Rosaline Franklin, provided much of the spark, including a key x-ray crystalograph, that led Wilkins’ team to their discoveries. Wilkins received the Nobel Prize with Watson and Crick. Franklin died of ovarian cancer before the prize was conferred; however, she was never nominated before she died, although Watson and Crick were.