
Investigating Websites and Webpages
This chapter is intended to reveal to the investigator how websites work, how they can be useful in an investigation and how to properly document website evidence. This chapter introduces the reader to the concepts of HTML, and its use in an investigation. It also discusses what can be found on a website and how to identify metadata in embedded images, documents, and videos.
Keywords
webpages; HTML; XML; Java; HTML5; website structure; domain registration; Babel Fish; Google translation; spider; metadata; Exif
All they need to do is to set up some website somewhere selling some bogus product at 20% of the normal market prices and people are going to be tricked into providing their credit card numbers.
Kevin Mitnick, reformed hacker
Webpages and websites
Webpages are the Internet’s heart as we know it. We described earlier in Chapter 3 how the Internet works and how Internet protocol (IP) addresses are the basis for most Internet connections. Webpages are the graphical representations of the data stored on a webserver as viewed through a browser on our local computer or computing device (tablet or cell phones). The main protocol used for communication between a web browser and a webserver is Hypertext Transfer Protocol. This protocol was designed to enable document, images, and other types of data to be transferred between a website and a user’s browser. The data resides on the webserver in folders, just like other data resides on your local computer. You enter a domain name into your browser, which is translated to an IP address, and the browser sends a request to the webserver asking for the page at the requested address. The webserver that resides at the IP address responds, providing access to the requested data if authorized (Figure 13.1).

How webpages work
Webpages “live” on what we refer to as the World Wide Web (WWW). WWW is a collection of servers around the world that host pages of information that are connected to each other using hypertext. We regularly click on hypertext links, identified as blue colored text on a webpage. These pages are historically written in HTML, a common IP language. There are more languages being used on webpages now than just HTML. Modern browsers also use Java, ActiveX, and other scripting languages to show image files, video, and animation.
Website structure
There are several basic structures that can be used to design a website. The first page is called the home page and other pages are organized in one of three possible structure types: tree, linear, and random. The tree structure is laid out in a hierarchical manner with the information presented on each page going from general to more defined or specific information. A linear structure is one where each page follows the home page one after the other. The random structure is one without any structure where the pages are connected to each other in a random fashion (Figures 13.2 and 13.3).

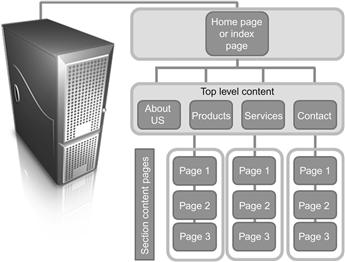
These structures help the website designer lay out the website and organize the design. From an investigative point of view, it can give the investigator an understanding of how the data is laid out on the website. The investigator has to remember that the data stored on the hosting website server is located in folders and files that link to the data laid out in the webpage.
How markup languages work
We have previously discussed how browsers connect to a webpage and the communication protocol is sent between the two when the connection is made. What we have not discussed is the data that the browser interprets as the page. HTML is the common language used to build a webpage and is the data interpreted by the browser which is ultimately displayed on the investigator’s monitor. The markup languages contain two things, content and instructions on how to format the content, which are called tags. Markup languages are NOT programming languages themselves and they do not execute a program on the investigator’s computer. There are programming and scripting languages that execute on the investigator’s computer if allowed, but the HTML itself does not execute any code. The common types of markup languages include HTML, XHTML, DHTML, and XML. The tags provide the browser with instructions on how to display the data on the screen, from font and size to color and even the display and location within the page of images. Table 13.1 presents some of the common HTML tags found in a webpage. A complete list of HTML tags can be found at http://www.web-source.net/html_codes_chart.htm from which this table was compiled.


Figure 13.4 reflects a very basic HTML website on the left side. On the right side is the same code as displayed by a browser.

The basic HTML page format is the Header and the Body. Before the Header, the investigator may encounter the tag for the document type as <DOCTYPE> which is an instruction to the browser telling it what HTML version the page is written in and how to correctly display the page. For example:
<!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML 4.01//EN” “http://www.w3.org/TR/html4/strict.dtd”>
The <head> tag contains information about how the document describes itself like the document type, the title, and other meta information. For example:
The <body> tag in the page contains the contents of the HTML document.
Website reconnaissance
Before you actually visit a website, there is a significant amount of information that can be obtained about the site prior to actually connecting a browser to a web address. Investigators can scout and collect valuable information on the site’s ownership, other sites associated with the target site, and possibly other victims of similar crimes. The section will introduce a process that can reveal more data about the website before it is actually accessed online by the investigator.
URL traits
We have already looked at what makes up a domain in Chapter 8. We know that the web address gives us the domain's name and the Top Level Domain (TLD) suffix, such as .com, .gov, or .xxx, provide information about the entity behind the site. Even a site ending with a country code, such as “.dk” (Denmark) or “.se” (Sweden), can provide clues about the site’s location. The question the investigator needs to ask “Is the domain extension appropriate for the content of the material you are looking for?” If you are looking at a government site, the extension should be .gov or .mil, educational sites should be .edu, and a nonprofit organization should be .org. Check the area of the URL between “http://www.” and first “/”. This is the domain. Have you heard of the domain name before? If not, open your favorite search engine and do a search of the domain name. Besides the domain returns itself, what sites reference the targeted domain? Do these links reflect anything additional about the target’s website? The investigator needs to be aware though that a TLD such as .tv or .co can be registered by anyone anywhere in the world. So location of the domain may not originate with the TLD’s registered country.
Another technique the investigator can use to discover information prior to accessing the site is to use the “link:” operator in a search engine like Google. This can provide you with what other sites consider your target site relevant enough to link to it. Go to Google.com type in “link:”, type or cut and paste the URL of the site immediately following “link:”, click on “Google Search” or press the Enter Key. This will provide a list of sites linked to the targeted site. What do the results tell the investigator? How many links are there? Many links can mean that this site is of value to others. Only a few can mean it is either new, unknown or not relevant to other sites. The investigator should then check the domain extensions of the linking sites. What types of sites link to the target page? Review the information about the sites that link to the page. Is the linked site pertinent to the target site or to the target website’s topic? Maybe the linked site complains about the target site and identifies negative information that can lead to additional victims.
Domain registration
Previously, we discussed tools to determine basic information and ownership of a website or an IP address by accessing its domain registration. Prior to going to a page, the investigator should do a lookup of the domain and identify site ownership information. Any of the previously mentioned references such DNS Stuff (http://www.dnsstuff.com/) or Network Tools (http://network-tools.com/) are good resources to conduct the lookup. The domain registration provides the investigator with useful information which can include the company the domain was registered through, the registrant, their address, and email and telephone contacts for the owner. As previously stated, this information is an input by the user during domain registration and can be falsified. However, this step can provide the investigator with information to further the webpage investigation. The investigator should begin by doing a search on the registration information details. If the company name is listed, search the name for an additional information on the company. Do the same with the registrant’s name, the telephone numbers listed, and the email address. Record and document this information using the tools we have previously described.
Website ranking and search engine optimization (SEO) sites
Another way to find information about a website is based on the site's Internet traffic. A website with the most traffic is ranked 1. Determining website rank is dependent upon the service used. Ranking sites collect a variety of information about individual sites, which can also be a good investigative source. Data collected frequently has a marketing focus, such as demographic information. However, these sites also collect linked sites as well as mentions by other websites and blogs. Notable website ranking sites include Alexa Traffic Ranking (http://www.alexa.com); Quantcast (http://www.quantcast.com/); and Website Outlook (http://www.websiteoutlook.com).
Search engine spiders also parse data similarly when they crawl a website and identify certain information from the site including the title, metadata, and keywords. A spider is a program that visits websites and reads their pages and other information in order to create entries for a search engine index. This is the general process that Google and other search engines use to build their databases of websites crawled. Search Engine Spider Simulator (http://www.webconfs.com/search-engine-spider-simulator.php) and Spider Simulator Tool SEO Chat (http://www.seochat.com/seo-tools/spider-simulator/) are two free search engine spider simulators for investigators to remotely view a website. Simply input the target URL and the spider simulator displays such items as content, meta descriptions, keywords, and internal and external links. Ranking and SEO sites can provide the investigator with webpage information prior to actually connecting to the site.
Website history research
In Chapter 12, we discussed using the Google and Bing’s cache feature. This provides a snapshot of a website created the last time a search engine crawled the website. Again, it can provide clues to the investigator about any changes that might have been made to the website since the last search engine crawl. As the created cache is subject to replacement, it must be documented and preserved at the time it is collected. These website caches are only a short-term snapshot, which is replaced as soon as the search engine crawls the site again.
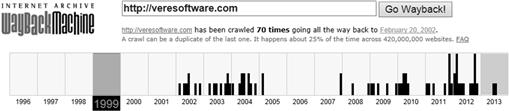
However, there exists a more long-term website archival system on the Internet. Since 1996, the Internet Achieve (http://archive.org) has been collecting and cataloging websites, which to date exceeds 240 billion webpages or almost 2 petabytes of data. It is currently growing at a rate of 20 terabytes per month (archive.org). It is a US 501(c)(3) nonprofit organization, which is supported by donations but collaborates with institutions such as the Library of Congress and the Smithsonian. The Internet Archive’s website, the “Wayback Machine”,1 has an easy-to-use interface to search for website information. The site provides the date and times of when the site has been crawled, as well as a capture of the site, so the investigator can see how the site has changed over time. These achieved webpages may provide the investigator with additional useful information. This could include ownership information in the archived “About Us” section that may have been deleted or later changed to prevent the current webpage from disclosing website ownership.
Just like any other webpage, the investigator can also look through the HTML source code of the achieved page to look for possible usable information. Investigators should be aware that the site does not crawl and record everything found on a website or webpage. It does not record every page if the Robot.txt file is set to tell search engines not to crawl the page. Additionally, certain Java code and other newer active content scripting are not collected. The Internet Actives FAQ page lists circumstances when the site does not collect information on a particular website or page. Regardless of some limitations, this is still a hugely valuable tool for the investigator to identify past website information (Figure 13.5).
Checking for malicious code on a site
In today’s Internet, the inclusion of malicious code on a website is becoming more common. Redirected or malicious websites can compromise the investigation or the investigator’s machine, if they are not identified as hazardous. Prior to going to a website, the investigator should check the site for malicious code.
One sign that a web address might be problematic is if it is shorted. Websites like bitly (https://bitly.com/), Google URL Shortener (http://goo.gl/), and TinyURL!™ (http://tinyurl.com/) allow users to input a long URL and shorten it. These redirect services are designed to condense long URLs because of the limits imposed on some social media services such as Twitter. However, online criminals use this technique to obfuscate the address and hide the actual intent and location of the website. A typical shortened website URL using tinyulr.com can look like:
The original URL has a length of 48 characters, and using TinyURL!™ to shorten the URL resulted in a URL of 26 characters. The investigator can use several different websites to decipher shortened websites. Sites like Unshorten.com (http://www.unshorten.com/) and Unshorten.It! (http://unshorten.it/) expand an address to identify its real location. Once the URL is expanded, the investigator can use other Internet tools to identify if the site has malicious code or other possible threats, such as web bugs, which will be discussed shortly.
Sites like Zulu URL Risk Analyzer (http://zulu.zscaler.com/) (Figure 13.6), Web Inspector (http://www.webinspector.com/), and VirusTotal (https://www.virustotal.com/) provide a look into the URL. These sites check the URL for malicious activity by connecting to the URL with a virtual machine and downloading the page. The downloaded data is scanned for malicious activity. The sites also pass the URL through various “Black Lists” that record known and potentially malicious sites. These sites can provide other information about the site’s activity, potential malicious content, and past known history of malicious activity. The investigator should be aware that scanning sites are not always a complete review of a website’s code. Scanning sites review the page input only and also may not be able to review all types of active content or other code found at the URL.

Webpage examination
So we finally point our browser at the website, what exactly can we find on a website? After collecting the website, we can review the website’s various pages for useful investigative information. We can also review the HTML itself and the underlying code for comments by the web tool used to make the page and any comments or references in the page to other sites (redirects) or images linked or other pages. We can then review the pages themselves as how the browser produces the pages. The investigator can look for who wrote the page, look for links that reflect “About Us,” “Philosophy,” or “Background.” Look for names of people, organizations, or groups that claim responsibility of the website or its design. If you have a long page with forward slashes separating the pages, truncate back the URL trying to find the main page and additional information on the site (e.g., http://www.weather.com/newscenter/stormwatch/index.html). Is there an email address for the person, company, or organization for further contact? The investigator can research this address through a search engine to see if it is used elsewhere on the Internet. Is the text grammatically correct and free of typos? From an investigative point of view, this might indicate the level of understanding of the language used. The website might be built by someone that does not speak that language natively. This could be a possible indication of a fraudulent site. The investigator should look for words like “Links,” “Additional Sites,” “Related Links.”. These could be references to unknown investigative details such as additional victims and/or suspects. The investigator should check the links to determine if the links work and/or are relevant to the investigation.
Foreign language websites
So what happens when we encounter a website in a foreign language? The Internet and its many resources provide us with the assistance we need. There are many sites that the investigator can enlist to translate a word or an entire webpage. The sites can assist the investigator understand the website and give a general idea of what the site says in the investigator’s language. However, these sites are not perfect and should not be relied on as providing a complete and/or accurate translation. If the site becomes evidence and the investigator needs to have an accurate representation of the language for the investigation, a translator should be enlisted to provide a proper translation of the text. The investigator should also be aware that these sites only translate the text found in the HTML on the site and not any text found in images or other nonhtml-coded areas of the webpage. The following sites can aid the investigator who is examining websites in a foreign language:
• Babel Fish, http://www.babelfish.com/
• Google’s Language Tools, http://www.google.com/language_tools
• Online Translation Tools, http://www.emailaddresses.com/online_translation.htm
• Yahoo’s Transliteration, http://transliteration.yahoo.com/
Reviewing source code
The code written by a programmer in HTML to form a webpage is readable by people. The investigator can take advantage of this as there can sometimes be information in the source code of the page that could be of use to the investigation. We have mentioned before that the browser interprets this language as the webpage we see. In Microsoft’s Internet Explorer, you can view the source code by going to “View” and select “Source” or holding the “Control” button down and selecting the “U” key. Opened in notepad will be the HTML source code for that individual page. Web-Source (http://www.web-source.net/html_codes_chart.htm) provides a good guide for translating a webpage’s source code. Figure 13.7 provides an example of a webpage’s source code.

Webpage tracking bugs
Buried in webpages can be code that identifies the browser and information about the computer connecting to the webpage. From a marketing point of view, this is a popular way of identifying information about people and their surfing habits. A page’s code can vary from legitimate marketing tools like Google Analytics to web bugs that track IP address of people going to a page. Looking through the source code can identify the presence of such tracking devices. MySpace trackers still exist to allow the page owner to identify the IP addresses of persons looking at their page. Most other social media sites don’t allow this because you don’t have access directly to the HTML of the user page. Facebook and other social media sites lock this access down and prevent users from making changes to their pages. General websites though can add whatever data they want to the page and tracking software can easily be implemented that identified through the browser or other software such as Flash or Java the IP address and other information about the user connecting with a webpage.
Documenting a website’s multimedia and images
Often overlooked places for evidence are images and videos on a website. Obviously, pictures or videos may show images that are important for what they show or reflect. Images or videos may identify suspects or evidence of illegal activity. They may provide clues to a suspect’s location, a missing victim, or where some questionable activity took place. However, many times pictures and videos can provide additional information that is not shown in their images. This unseen information is called metadata. Digital forensic investigators understand that within the image and video files exists metadata that further describes the file. Internet investigators need to understand that there is the potential for valuable information within the image file. Image files and video files can have embedded information contained in the file that can give you potentially valuable leads in the case. Exif Data or Exchangeable image file format (Exif) is a specification for the image file format used by digital cameras. This Exif Data holds camera settings used to take the picture. Most digital cameras support Exif and save the data in the file’s header information. Examples of metadata that can be found include a camera’s model and serial number, creation time/date, and even global positioning coordinates. However, when an image is edited, the Exif data may be automatically removed by the software. This requires investigators to obtain images and videos and preserve them without making any changes that may obliterate Exif data.
To examine an image from a website, right click on the image on the page and save the file to a folder on the investigator’s local machine. Examining the Exif Data can easily be done in Microsoft operating systems. A subset of the Exif information may be viewed by right clicking on the image file and clicking “Properties.” In the Properties dialog, click the “Summary” or “Details” tab. The investigator needs to be aware that damage can occur to Exif headers if changes are applied and that this method does not reveal all the potentially available Exif data. There are many tools available to review the entire Exif data such as Stuffware’s Photostudio (http://www.stuffware.co.uk/photostudio/). This small, free program can review images and their Exif data. Also there are online resources that include Jeffrey’s Exif Viewer (http://regex.info/exif.cgi) or online photo Exif metadata reader (http://www.findexif.com/) that can assist in identifying Exif data. The investigator should remember when using these services that they are uploading the images from their investigation to an unknown server.
Capturing website videos
Videos are now often not embedded on the page that you view the video from. Youtube.com presents many videos that it streams from another location to the viewer’s browser. To download certain streaming web videos, you need to track the video to its source. Several tools exist to assist the investigator with grabbing video files from the web. Tools like YouRipper grabs videos from YouTube (http://www.remlapsoftware.com/youripper.htm) and URLSnopper grabs Streaming Video (http://www.donationcoder.com/Software/Mouser/urlsnooper/index.html) which can assist the investigator collect videos from their websites. Another good tool for this purpose is Replay Media Catcher located at http://www.applian.com. These tools are intended to aid the investigator in downloading files in their native format. There are sites on the web that will allow for downloading a copy of a video, but they may convert the file into a different format and delete any possible metadata.
If metadata is important in other investigations, can video metadata be a similar potential treasure trove? Todd in his classes has extolled the examination of metadata during Internet investigations because finding metadata in online documents or images can be incredibly damaging evidence. For example, Todd recently was asked to examine a website setup on a “free” domain to find out who the owner might be. Examination of the website failed to ascertain anything until Todd downloaded the files embedded in the site. A quick look at the files’ metadata ascertained their author—who was well known to the plaintiff.
Two video metadata types
Video metadata does exist and it is clearly important. To deal with video metadata, we have to understand where it comes from. Good (2008) notes that there are two metadata sources, operational information and human-authored metadata. He describes them as:
(a) “Operational, automatically gathered video metadata, which is typically a set of information about the content you produce, such as the equipment you used, the software you employed, the date you created your video, and GPS coordinates of shooting location.
(b) Human-authored video metadata, which can be created to provide more search engine visibility, audience engagement, and better advertising opportunities for online video publishers.”
Most of what we are currently dealing with in metadata examination is the “operational” metadata. However, human-authored metadata may become more important. Interestingly enough, video metadata is getting some heavy discussion from a marketing point of view. Online video providers are looking at the use of video metadata to describe the video better for two reasons: first, better coverage in the search engines, and second, end users have more descriptive information about the video. Additionally, video-sharing sites seek to make videos more “social” by enabling users to add metadata to the videos they host. For instance, Metacafe’s Wikicafe section allows all its users to add “human-authored” comments to video metadata.
Although few standards currently exist for video metadata, this is changing as video delivery becomes more important. Acceptance of standards such as the Dublin Core Metadata Element Set is becoming common. With standards in the metadata, investigators will have an ability to look for common items of information in the file. Standard metadata also makes it easier to build tools to extract this data. The continuing conversation, and the acceptance of “human-authored” metadata, will undoubtedly provide investigators with additional information regarding videos they find on the Internet during investigations.
File formats and what they contain
Search Google for “video metadata forensics,” and you won’t find much of anything useful. It is mentioned in some places that video has metadata, but little describes the metadata in depth. However, search for Resource Interchange File Format (RIFF) and you will find a lot more. RIFF, the term similar in usage to Exif data, is the format that describes the usage of metadata in many video and audio files.
The amount of RIFF data available depends on the file format. RIFF data is a proprietary format originally developed by Microsoft and IBM for Windows 3.1. The format was released in the 1991 in the Windows Multimedia Programmer’s Reference. RIFF was never adopted as a standard and few new video formats have adopted the file format since 1990s. Common file formats still in use that use RIFF include .wav and .avi. Microsoft has been using the Advanced Systems Format (ASF) since 2004 in its .wma files. From the Microsoft ASF specifications, we can find that the ASF file can contain potentially valuable information. However, as images have the Exif standard, there is no real standard for maintaining metadata in video files. There are other standards in the field including the newer MPEG-7 standard and the XMP Dynamic Media Schema developed by Adobe. What this all means is there is an underlying structure for the metadata present in video files. The question now becomes, how do we look at that data if it is there? There are a few free tools out there to assist you. Let’s talk about three.
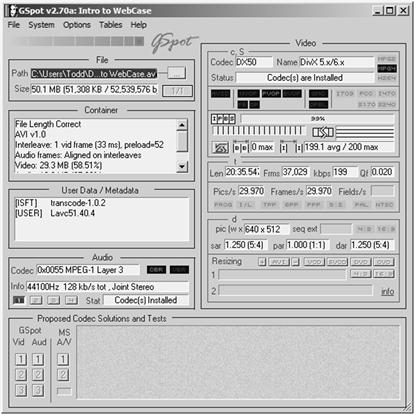
Gspot
Gspot has been the heavy lifter for most investigators looking at metadata in video files. It provides a single screen view of the available data in a video file (of the files it can translate). Most of the data is “operational” data found in the file, but it does provide you with the “human-authored” data if it is present. Gspot has an export function to allow the user to save the metadata information for inclusion in a report or to add to WebCase. Another good part of GSpot is that the investigator can export a report of its findings that can be included in the investigator's report. Gspot’s failing is that it has had no recent updates since 2007 (Figure 13.8).
Mediainfo
MediaInfo is a newer tool. Its basic presentation is much simpler than Gspot’s, but it offers several different views of the data that allow you to determine what metadata is present. The “tree” view lays out all of the metadata present in an easy-to-view screen. The export options for reporting also allow the user to quickly make reports in a text or html format for inclusion in their reports or to add to a tool like WebCase. MediaInfo also adds during installation a right click function to Windows Explorer to easily access the tool. Finally, the program can also export a report of its findings in a txt, html, or CSV format that can be included in the investigator’s report (Figure 13.9).

Video inspector
This program is a very basic tool and provides the user with the basic metadata present in the video file. The export function allows for exporting a text document with the metadata it finds, but it is limited. The tool was designed to assist the user in identifying missing codecs required to play the video, so reading all the available metadata is not its main function. Video Inspector also has a report that can be included in the investigator’s report (Figure 13.10).

There is some usefulness in reviewing video files for metadata. Something to remember is that some sites may strip the metadata when posted online. Also, other tools used to download videos from the Internet, like savevid.com, save the video in flash and not the original file format containing the original metadata. Investigators need to find the original video uploaded to get to the metadata. Investigators may encounter challenges when they review images from social media sites. One example is Metacafe’s attempt to add metadata to videos it hosts. Its Wikicafe section allows all its users to add “human-authored” comments to video metadata. Other sites simply strip the Exif metadata from the image or video prior to posting on the site.
The legal process of identifying a website
Internet Service providers (ISPs) hosting webpages have no requirements to store data about its users or their action when online. However, they most often store a significant amount of usable data for the investigator. This data can include the site’s owner, address and credit card information, dates and times logged on to the ISP. The proper legal service required for obtaining information from an ISP varies by jurisdiction. Contact your legal counsel for advice on serving an ISP. A great resource for information on the legal contacts for ISPs is maintained by SEARCH, a federally funded nonprofit organization, we have previously mentioned. You can find most ISP legal contacts at: www.search.org/programs/hightech/isp/.
Monitoring websites over time
If the website has an RSS Feed, tools like Netvibes (www.netvibes.com) or NewsBlur (www.newsblur.com) let you subscribe to the websites so that new content comes to you when it’s posted. This can give the investigator an alert on up-to-date changes on the target site. Google Alerts (http://www.google.com/alerts) can also easily provide the investigator with updated information without having to regularly check the website or webpage. This service, available only with a Gmail account, provides updates of the latest relevant Google results (web, news, etc.) based on the investigator’s choice of query or topics. Google Alerts will send an email to the investigator while they are crawling the Internet and when the investigator’s query name or topic is found, the system sends an email. These alerts can be configured to be sent as they are found, on a daily basis or once a week. This can also allow the investigator to monitor developing news stories on the target. Some great investigative uses of Google Alerts include monitoring a company name or individual target. Civilian investigators can keep current on a competitor or industry concept and get the latest on the queries referenced on a site Google crawls. Corporate investigators may also find it helpful to detect individuals posting questionable or threatening comments about the company and/or key officers.
Conclusion
This chapter has provided the reader with the understanding of how a website is built and the programming languages used to design websites. The reader was provided an outline of how to look at a website and the information that can be provided by examining a website. There is a significant amount of data that can be found on a website and should not be overlooked by the investigator. With a little understanding the investigator can identify who owns the site, information about the contents, and potentially useful metadata from the source code as well as images and other items embedded on the site.
Further reading
1. Alexa—The Web Information Company. (n.d.). Alexa—The Web Information Company. Retrieved from <http://www.alexa.com>.
2. Applian Technologies: Video Downloaders, Media Converters, Audio Recorders and more. (n.d.). Applian Technologies. Retrieved from <http://www.applian.com>.
3. ASF (Advanced Systems Format). (n.d.). Digital preservation (Library of Congress). Retrieved from <http://www.digitalpreservation.gov/formats/fdd/fdd000067.shtml>.
4. BabelFish—Free Online Translator. (n.d.). BabelFish. Retrieved from <www.babelfish.com/>.
5. Bing. (n.d.). Bing. Retrieved from <http://www.bing.com>.
6. Bitly. (n.d.). Bitly. Retrieved from <https://bitly.com/>.
7. DNS Tools: Manage Monitor Analyze, DNSstuff. (n.d.). DNS Tools. Retrieved from <http://www.dnsstuff.com/>.
8. Download Online Videos Save Direct Easily—Savevid.com. (n.d.). Savevid.com. Retrieved from <http://www.savevid.com/>.
9. Dublin Core Metadata Element Set, Version 1.1. (n.d.). DCMI Home: Dublin Core® Metadata Initiative (DCMI). Retrieved from <http://dublincore.org/documents/dces/>.
10. English to Hindi. (n.d.). English to Hindi. Retrieved from <http://transliteration.yahoo.com/>.
11. Extracting and preparing metadata to make video files searchable meeting the unique file format and delivery requirements of content aggregators and distributors. (2008). Nevada City, CA: Telestream, Inc.
12. Find Exif Data—Online exif/metadata photo viewer. (n.d.). Find Exif Data—Online Exif/metadata photo viewer. Retrieved from <http://www.findexif.com/>.
13. Free Online Translation Tools. (n.d.). Free email address directory: Guide to free email and other services. Retrieved from <http://www.emailaddresses.com/online_translation.htm>.
14. Google. (n.d.). Google. Retrieved from <http://www.google.com>.
15. Google Alerts—Monitor the Web for Interesting New Content. (n.d.). Google. Retrieved from <http://www.google.com/alerts>.
16. Google Translate. (n.d.). Google. Retrieved from <http://www.google.com/language_tools>.
17. Google URL Shortener. (n.d.). Google URL Shortener. Retrieved from <goo.gl/>.
18. GSpot Codec Information Appliance. (n.d.). GSpot Codec Information Appliance. Retrieved from <http://gspot.headbands.com/>.
19. HTML Cheatsheet: Webmonkey, Wired.com. (n.d.). Webmonkey—The web developer’s resource, Wired.com. Retrieved from <http://www.webmonkey.com/2010/02/html_cheatsheet/>.
20. HTML Codes Chart. (n.d.). Web page design and development. Retrieved from <http://www.web-source.net/html_codes_chart.htm>.
21. International School of Information Science (ISIS). (n.d.). Home—Bibliotheca Alexandrina. Retrieved from <http://www.bibalex.org/isis/frontend/archive/archive_web.aspx>.
22. Internet Archive: Digital Library of Free Books, Movies, Music & Wayback Machine. (n.d.). Internet Archive: Digital Library of Free Books, Movies, Music & Wayback Machine. Retrieved from <http://archive.org>.
23. Internet Archive: Legal: Requests. (n.d.). Internet Archive: Digital Library of Free Books, Movies, Music & Wayback Machine. Retrieved from <http://archive.org/legal/>.
24. Jeffrey’s Exif Viewer. (n.d.). Jeffrey’s Exif Viewer. Retrieved from <regex.info/exif.cgi>.
25. KC Softwares. (n.d.). KC Softwares. Retrieved from <http://www.kcsoftwares.com/?vtb>.
26. Kevin Mitnick Quotes—BrainyQuote. (n.d.). Famous quotes at Brainyquote. Retrieved from <http://www.brainyquote.com/quotes/authors/k/kevin_mitnick.html>.
27. MediaInfo. (n.d.). MediaInfo. Retrieved from <http://mediainfo.sourceforge.net/en>.
28. Metacafe—Wikicafe. (n.d.). Metacafe—Online video entertainment—Free video clips for your enjoyment. Retrieved from <http://www.metacafe.com/wikicafe/>.
29. Netvibes: Social Media Monitoring, Analytics and Alerts Dashboard. (n.d.). Netvibes Social Media Monitoring, Analytics and Alerts Dashboard. Retrieved from <http://www.netvibes.com>.
30. NewsBlur. (n.d.). NewsBlur. Retrieved from <www.newsblur.com>.
31. Photo Studio. (n.d.). StuffWare. Retrieved from <http://www.stuffware.co.uk/photostudio>.
32. Quantcast Measure. (n.d.). Quantcast. Retrieved from <https://www.quantcast.com/>.
33. Search Engine Spider Simulator. (n.d.). SEO tools—Search engine optimization tools. Retrieved from <http://www.webconfs.com/search-engine-spider-simulator.php>.
34. Spider Simulator—SEO Chat. (n.d.). Spider Simulator—SEO Chat. Retrieved from <www.seochat.com/seo-tools/spider-simulator/>.
35. The Official Blitz Website. (n.d.). The Official Blitz Website. Retrieved from <http://www.blitzbasic.com/codearcs/codearcs.php?code=2582>.
36. TinEye Reverse Image Search. (n.d.). TinEye Reverse Image Search. Retrieved from <http://tineye.com/>.
37. TinyURL.com—Shorten that Long URL into a Tiny URL. (n.d.). TinyURL.com. Retrieved from <http://tinyurl.com/>.
38. Traceroute, Ping, Domain Name Server (DNS) Lookup, WHOIS. (n.d.). Traceroute. Retrieved from <http://network-tools.com/>.
39. Unshorten—Get the Real Location of a Short URL. (n.d.). Unshorten—Get the real location of a short URL. Retrieved from <http://www.unshorten.com>.
40. Unshorten that URL!—Unshorten.It!. (n.d.). Unshorten.It!. Retrieved from <http://unshorten.it/>.
41. URL Snooper—Mouser—Software—DonationCoder.com. (n.d.). URL Snooper—Mouser—Software—DonationCoder.com. Retrieved from <www.donationcoder.com/Software/Mouser/urlsnooper/index.html>.
42. Video Metadata Key Strategic Importance For Online Video Publishers—Part 1. (n.d.). Professional online publishing: New media trends, communication skills, online marketing—Robin Good’s MasterNewMedia. Retrieved from <http://www.masternewmedia.org/video-metadata-key-strategic-importance-for-online-video-publishers-part-1/>.
43. VirusTotal—Free Online Virus, Malware and URL Scanner. (n.d.). VirusTotal—Free Online Virus, Malware and URL Scanner. Retrieved from <https://www.virustotal.com/en/>.
44. WebP Container Specification—WebP Google Developers. (n.d.). WebP Container Specification—Webp Google Developers. Retrieved from <code.google.com/speed/webp/docs/riff_container.html>.
45. Website Security with Malware Scan and PCI Compliance: Web Inspector. (n.d.). Web Inspector. Retrieved from <http://www.webinspector.com/>.
46. Website Value Calculator and Web Information. (n.d.). Website Value Calculator and Web Information. Retrieved from <http://www.websiteoutlook.com/>.
47. Whitney, S. (2012, July 29). How to understand Google safe browsing diagnostic page. Retrieved from <25yearsofprogramming.com/blog/2009/20091124.htm>.
48. World Wide Web Consortium (W3C). (n.d.). World Wide Web Consortium (W3C). Retrieved from <http://www.w3.org/>.
49. Yahoo!. (n.d.). Yahoo!. Retrieved from <http://www.yahoo.com>.
50. YouRipper. (n.d.). Remlapsoftware.com. Retrieved from <http://www.remlapsoftware.com/youripper.htm>.
51. Zscaler Zulu URL Risk Analyzer—Zulu.(n.d.). Zscaler Zulu URL Risk Analyzer—Zulu. Retrieved from <http://zulu.zscaler.com/>.
1The Wayback Machine is named in reference to the famous Mr. Peabody’s WABAC (pronounced way-back) machine from the Rocky and Bullwinkle Cartoon Show (archive.org).