
NULLs—Missing Data in SQL
A discussion of how to handle missing data enters a sensitive area in relational database circles. Dr. E. F. Codd, creator of the relational model, favored two types of missing-value tokens in his book on the second version of the relational model, one for “unknown” (the eye color of a man wearing sunglasses) and one for “not applicable” (the eye color of an automobile). Chris Date, leading author on relational databases, advocates not using any general-purpose tokens for missing values at all. Standard SQL uses one token, based on Dr. Codd’s original relational model.
Perhaps Dr. Codd was right—again. In Standard SQL, adding ROLLUP and CUBE created a need for a function to test NULLs to see if they were in fact “real NULLs” (i.e., present in the data and therefore assumed to model a missing value) or “created NULLs” (i.e., created as place holders for summary rows in the result set).
In their book A Guide to Sybase And SQL Server, David McGoveran and C. J. Date (ISBN 978-0201557107, 1992) said: “It is this writer’s opinion that NULLs, at least as currently defined and implemented in SQL, are far more trouble than they are worth and should be avoided; they display very strange and inconsistent behavior and can be a rich source of error and confusion. (Please note that these comments and criticisms apply to any system that supports SQL-style NULLs, not just to SQL Server specifically.)”
SQL takes the middle ground and has a single general-purpose NULL for missing values. Rules for NULLs in particular statements appear in the appropriate sections of this book. This section will discuss NULLs and missing values in general.
People have trouble with things that “are not there” in some sense. There is no concept of zero in Egyptian, Mayan, Chinese, Roman numerals, and virtually all other traditional numeral systems. It was centuries before Hindu-Arabic numerals and a true zero became popular in Europe. In fact, many early Renaissance accounting firms advertised that they did not use the fancy, newfangled notation and kept records in well-understood Roman numerals instead.
Many of the conceptual problems with zero arose from not knowing the difference between ordinal and cardinal numbers. Ordinal numbers measure position (an ordering); cardinal numbers measure quantity or magnitude. The argument against the zero was this: If there is no quantity or magnitude there, how can you count or measure it? What does it mean to multiply or divide a number by zero? There was considerable linguistic confusion over words that deal with the lack of something.
There is a Greek paradox that goes like this:
2. A cat has one more tail than no cat.
3. Therefore, a cat has 13 tails.
See how “no” is used two different ways? This was part of the Greek language. A blank as a character had to wait for typesetting to replace manuscripts. Likewise, it was a long time before the idea of an empty set found its way into mathematics. The argument was that if there are no elements, how could you have a set of them? Is the empty set a subset of itself? Is the empty set a subset of all other sets? Is there only one universal empty set or one empty set for each type of set?
Computer science now has its own problem with missing data. The Interim Report 75-02-08 to the ANSI X3 (SPARC Study Group 1975) had 14 different kinds of incomplete data that could appear as the result of queries or as attribute values. These types included overflows, underflows, errors, and other problems in trying to represent the real world within the limits of a computer.
Instead of discussing the theory for the different models and approaches to missing data, I would rather explain why and how to use NULLs in SQL. In the rest of this book, I will be urging you not to use them, which may seem contradictory, but it is not. Think of a NULL as a drug; use it properly and it works for you, but abuse it and it can ruin everything. Your best policy is to avoid them when you can use them properly when you have to.
14.1 Empty and Missing Tables
An empty table or view is a different concept from a missing table. An empty table is one that is defined with columns and constraints, but that has zero rows in it. This can happen when a table or view is created for the first time, or when all the rows are deleted from the table. It is a perfectly good table. By definition, all of its constraints are TRUE.
A missing table has been removed from the database schema with a DROP TABLE statement, or it never existed at all (you probably typed the name wrong). A missing view is a bit different. It can be absent because of a DROP VIEW statement or a typing error, too. But it can also be absent because a table or view from which it was built has been removed. This means that the view cannot be constructed at run time and the database reports a failure. If you used CASCADE behavior when you dropped a table, the view would also be gone, but more on that later.
The behavior of an empty TABLE or VIEW will vary with the way it is used. The reader should look at sections of this book that deal with predicates that use a subquery. In general, an empty table can be treated either as a NULL or as an empty set, depending on context.
14.2 Missing Values in Columns
The usual description of NULLs is that they represent currently unknown values that may be replaced later with real values when we know something. Actually, the NULL covers a lot more territory, as it is the only way of showing any missing values. Going back to basics for a minute, we can define a row in a database as an entity, which has one or more attributes (columns), each of which is drawn from some domain. Let us use the notation E(A) = V to represent the idea that an entity, E, has an attribute, A, which has a value, V. For example, I could write “John(hair) = black” to say that John has black hair.
SQL’s general-purpose NULLs do not quite fit this model. If you have defined a domain for hair color and one for car color, then a hair color should not be comparable to a car color, because they are drawn from two different domains. You would need to make their domains comparable with an implicit or explicit casting function. This is done in Standard SQL, which has a CREATE DOMAIN statement. Trying to find out which employees drive cars that match their hair is a bit weird outside of Los Angeles, but in the case of NULLs, do we have a hit when a bald-headed man walks to work? Are no hair and no car somehow equal in color? In SQL-89 and higher, we would get an UNKNOWN result, rather than an error, if we compared these two NULLs directly. The domain-specific NULLs are conceptually different from the general NULL because we know what kind of thing is UNKNOWN. This could be shown in our notation as E(A) = NULL to mean that we know the entity, we know the attribute, but we do not know the value.
Another flavor of NULL is “Not Applicable,” shown as N/A on forms and spreadsheets and called “I-marks” by Dr. E. F. Codd in his second version of the Relational Model. To pick an example near to my heart, a bald man’s hair-color attribute is a missing-value NULL drawn from the hair-color domain, but his feather-color attribute is a “Not Applicable” NULL. The attribute itself is missing, not just the value. This missing-attribute NULL could be written as E(NULL) = NULL in the formula notation.
How could an attribute not belonging to an entity show up in a table? Consolidate medical records and put everyone together for statistical purposes. You should not find any male pregnancies in the result table. The programmer has a choice as to how to handle pregnancies. He can have a column in the consolidated table for “number of pregnancies” and put a zero or a NULL in the rows where sex_code = 1 (‘male’ in the ISO Standards) and then add some CHECK() clauses to make sure that this integrity rule is enforced.
The other way is to have a column for “medical condition” and one for “number of occurrences” beside it. Another CHECK() clause would make sure male pregnancies do not appear. But what happens when the sex is known to be person rather than a lawful entity like a corporation and all we have is a name like ‘Alex Morgan,’ who could be either sex? Can we use the presence of one or more pregnancies to determine that Alex is a woman? What if Alex is a woman who never had children? The case where we have NULL(A) = V is a bit strange. It means that we do not know the entity, but we are looking for a known attribute, A, which has a value of V. This is like asking “What things are colored red?,” which is a perfectly good, though insanely vague, question that is very hard to ask in an SQL database. It is possible to ask in some columnar databases, however.
If you want to try writing such a query in SQL, you have to get to the system tables to get the table and column names, then JOIN them to the rows in the tables and come back with the PRIMARY KEY of that row.
For completeness, we could play with all eight possible combinations of known and unknown values in the basic E(A) = V formula. But such combinations are of little use or meaning. The “total ignorance” NULL, shown as NULL(NULL) = NULL, means that we have no information about the entity, even about its existence, its attributes, or their values. But NULL(NULL) = V would mean that we know a value, but not the entity or the attribute. This is like the running joke from Douglas Adam’s HITCHHIKER’S GUIDE TO THE GALAXY, in which the answer to the question, “What is the meaning of life, the universe, and everything?” is 42. I found that interesting since I also teach a domino game named Forty-two that is only played in Texas.
14.3 Context and Missing Values
Create a domain called Tricolor that is limited to the values ‘Red,’ ‘White,’ and ‘Blue’ and a column in a table drawn from that domain with a UNIQUE constraint on it. If my table has a ‘Red’ and two NULL values in that column, I have some information about the two NULLs. I know they will be either (‘White,’ ‘Blue’) or (‘Blue,’ ‘White’) when their rows are resolved. This is what Chris Date calls a “distinguished NULL,” which means we have some information in it.
If my table has a ‘Red,’ a ‘White,’ and a NULL value in that column, can I change the last NULL to ‘Blue’ because it can only be ‘Blue’ under the rule? Or do I have to wait until I see an actual value for that row? There is no clear way to handle this situation. Multiple values cannot be put in a column, nor can the database automatically change values as part of the column declaration.
This idea can be carried farther with marked NULL values. For example, we are given a table of hotel rooms that has columns for check-in date and check-out date. We know the check-in date for each visitor, but we do not know his or her check-out dates. Instead, we know relationships among the NULLs. We can put them into groups—Mr. and Mrs. X will check out on the same day, members of tour group Y will check out on the same day, and so forth. We can also add conditions on them: Nobody checks out before his check-in date, tour group Y will leave after 2025-01-07, and so forth. Such rules can be put into SQL database schemas, but it is very hard to do. The usual method is to use procedural code in a host language to handle such things.
Another context is statistical and probabilistic. Using my previous example of “Alex Morgan” as an ambiguous sex_code, I can take the birth date and make a guess. In the 1940-1950 time period, Alex was almost exclusively a male first name; in the 1990-2000 time period, Alex was more than half female. This gets into fuzzy logic and probabilistic data; I do not want to deal with it in this book.
David McGoveran has proposed that each column that can have missing data should be paired with a column that encodes the reason for the absence of a value (McGoveran, 1993, 1994a,b,c). The cost is a bit of extra logic, but the extra column makes it easy to write queries that include or exclude values based on the semantics of the situation.
You might want to look at solutions statisticians have used for missing data. In many kinds of computations, the missing values are replaced by an average, median, or other value constructed from the data set.
14.4 Comparing NULLs
A NULL cannot be compared to another NULL (equal, not equal, less than, greater than, and so forth). This is where we get SQL’s three-valued logic instead of two-valued logic. Most programmers do not easily think in three values. But think about it for a minute. Imagine that you are looking at brown paper bags and are asked to compare them without seeing inside of either of them. What can you say about the predicate “Bag A has more tuna fish than Bag B”—TRUE or FALSE? You cannot say one way or the other, so you use a third logical value, UNKNOWN.
If I execute “SELECT * FROM SomeTable WHERE SomeColumn = 2”; and then execute “SELECT * FROM SomeTable WHERE SomeColumn < > 2”; I expect to see all the rows of SomeTable between these two queries in a world of two-valued logic. However, I also need to execute “SELECT * FROM SomeTable WHERE SomeColumn IS NULL”; to do that. The IS [NOT] NULL predicate will return only TRUE or FALSE.
A special predicate was introduced in the SQL:2003 Standard with the syntax:
< expression 1 > IS DISTINCT FROM < expression 2 >
Which is logically equivalent to:
(< expression 1 > = < expression 2 > OR (< expression 1>IS NULL AND < expression 2 > IS NULL))
Likewise the infixed comparison operator
< expression 1 > IS NOT DISTINCT FROM < expression 2 > NOT (< expression 1 > IS DISTINCT FROM < expression 2 >)
or equivalent to:
(< expression 1 > <> < expression 2 > OR (< expression 1> IS NULL AND < expression 2 > IS NOT NULL) OR (< expression 1> IS NOT NULL AND < expression 2 > IS NULL))
Besides being simpler and lending itself to better optimization, the IS [NOT] DISTINCT FROM operator gives you traditional two-valued logic. It is based on another concept in SQL—the difference between equality and grouping. Grouping, the equivalence relation used in the GROUP BY clause and other places in the language, treats all NULLs as one equivalence class.
14.5 NULLs and Logic
George Boole developed two-valued logic and attached his name to Boolean algebra forever (An Investigation of the Laws of Thought by George Boole, 1854; there several reprints in paper and e-formats). This is not the only possible logical system. Do a Google search on “Multi-valued logics” and you will come up with lots of material. SQL’s search conditions look a lot like a proposal from Jan Łukasiewicz, the inventor of Polish Notation, for a three-valued logic.
Two-valued logic is the one that works best with a binary (two-state) computer and with a lot of mathematics. But SQL has three-valued logic: TRUE, FALSE, and UNKNOWN. The UNKNOWN value results from using NULLs in comparisons and other predicates, but UNKNOWN is a logical value and not the same as a NULL, which is a data value marker. That is why you have to say (x IS [NOT] NULL) in SQL and not use (x = NULL) instead.
Here are the tables for the three logical operators that come with SQL.
| NOT | |||
| TRUE | FALSE | ||
| UNKNOWN | UNKNOWN | ||
| FALSE | TRUE | ||
| AND | TRUE | UNKNOWN | FALSE |
| TRUE | TRUE | UNKNOWN | FALSE |
| UNKNOWN | UNKNOWN | UNKNOWN | FALSE |
| FALSE | FALSE | FALSE | FALSE |
| OR | TRUE | UNKNOWN | FALSE |
| TRUE | TRUE | TRUE | TRUE |
| UNKNOWN | TRUE | UNKNOWN | UNKNOWN |
| FALSE | TRUE | UNKNOWN | FALSE |
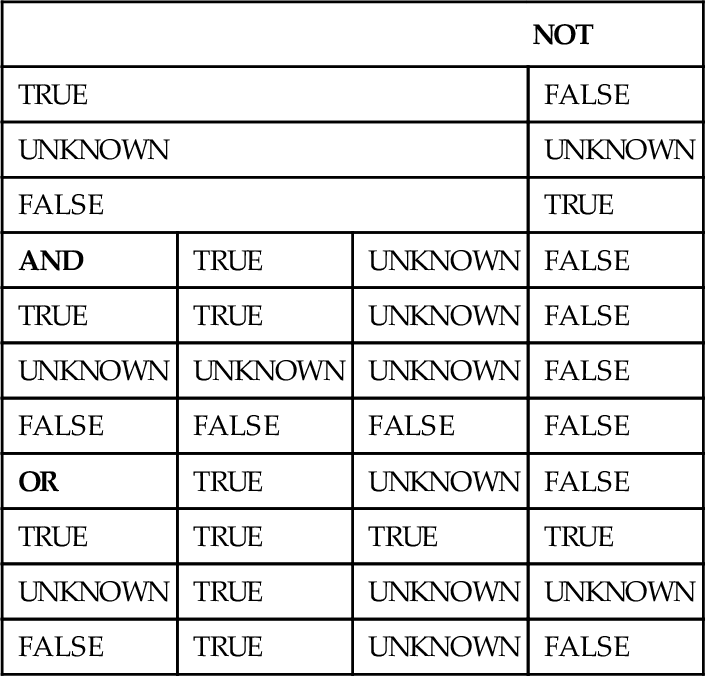
A comparison between known values gives you a result of TRUE or FALSE. This is Boolean logic, embedded in the SQL operators.
This is where we invented the logical value UNKNOWN. Well, rediscovered it. There were already a lot of multivalued logics in the mathematical literature. Some of them are based on discrete values and some on continuous values (i.e., fuzzy logic). SQL first looks like the system developed by Polish logician Jan Łukasiewicz (the L-bar is a “W” sound in English). Programmers know him as the guy who invented Polish Notation which inspired Reverse Polish Notation for HP calculators and stack architecture (aka zero address machines) computers like the old Burroughs computers.
In the Łukasiewicz multivalued logic systems, the AND, OR, and NOT are almost the same as in SQL’s three-valued logic. The general case is based on the following Polish notation formulas in which 1 is TRUE, 0 is FALSE, and fractions are the other values.
◆ Cab = 1 − a + b for (a > b)
◆ Na = 1 − a
N is the negation operator, and C is the implication operator. What is important about this system is that implication cannot be built from the AND, OR, and NOT operators. From the N and C pair, we define all other operators:
Maybe is defined as “not false” in this system. Then Tarski and Łukasiewicz had rules of inference to prove theorems. David McGoveran pointed out that SQL is not really a logic system because it lacks inference rules for deductions and proofs. The idea is that the UNKNOWN might be resolved to {TRUE, FALSE}, so we can sometimes determine the result regardless of how one value resolves. If we cannot determine a result, then return UNKNOWN.
Let me sum up. SQL is not a formal logical system. We have no inference rules and what we informally call “predicates” are actually “search conditions” in the ANSI/ISO Standards. What we have is a collection of look-up tables to compute a value of {TRUE, FALSE, UNKNOWN} to control ON and WHERE clauses in SQL statements.
The symbol for material implication in Boolean logic is a two-tailed right arrow defined by this table. It is often read as “a true premise cannot imply a false conclusion” in English.
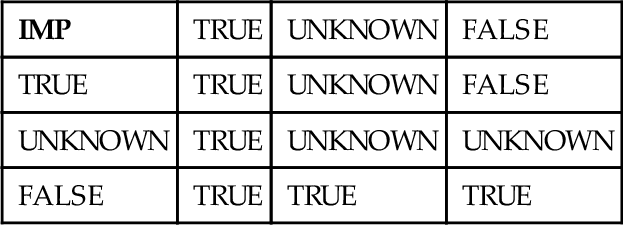
This is properly called “material implication” and it can be read as “a true premise cannot imply a false conclusion” in English. But implication can also be written as (a ⇒ b) = ⇒(a ⇒ ⇒b). There is also the “Smisteru rule” that rewrites material implication as (a ⇒ b) = (⇒a ⇒ b), which is the same in two valued logic. If we use then old Algol operator IMP for three valued implication, things do not work well. Let’s write some look-up tables.
Traditional implication
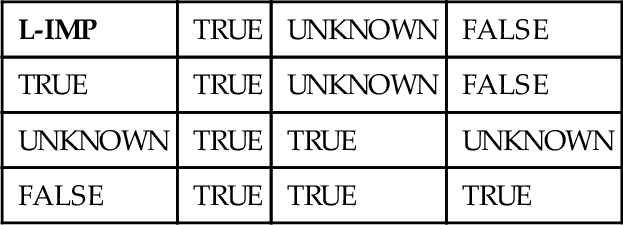
Compare this with Łukasiewicz implication
The tables are not the same. In the first version, we have (UNKNOWN IMP FALSE) expanding out to:
⇒ (UNKNOWN ⇒ ⇒ UNKNOWN)
⇒ (UNKNOWN ⇒ UNKNOWN)
⇒ (UNKNOWN)
UNKNOWN
But the second version, Łukasiewicz, gives us:
L-IMP (½, ½) = CASE WHEN ½ <= ½ THEN 1 ELSE (1- ½ + ½) END
= 1 = TRUE
This is why we call the search logic in the SQL Standards is called a “search condition” and not a predicate. It will not actually hurt too much to make this error in practice.
14.5.1 NULLS in Subquery Predicates
People forget that a subquery often hides a comparison with a NULL. Consider these two tables:
CREATE TABLE Table1 (col1 INTEGER); INSERT INTO Table1 (col1) VALUES (1), (2); CREATE TABLE Table2 (col1 INTEGER); INSERT INTO Table2 (col1) VALUES (1), (2), (3), (4), (5);
Notice that the columns are NULL-able. Execute this query:
SELECT col1 FROM Table2 WHERE col1 NOT IN (SELECT col1 FROM Table1);
Result
Now insert a NULL and reexecute the same query:
INSERT INTO Table1 (col1) VALUES (NULL); SELECT col1 FROM Table2 WHERE col1 NOT IN (SELECT col1 FROM Table1);
The result will be empty. This is counter-intuitive, but correct. The NOT IN predicate is defined as:
SELECT col1 FROM Table2 WHERE NOT (col1 IN (SELECT col1 FROM Table1));
The IN predicate is defined as:
SELECT col1 FROM Table2 WHERE NOT (col1 = ANY (SELECT col1 FROM Table1));
which becomes:
SELECT col1 FROM Table2 WHERE NOT ((col1 = 1) OR (col1 = 2) OR (col1 = 3) OR (col1 = 4) OR (col1 = 5) OR (col1 = NULL));
The last expression is always UNKNOWN, so by applying DeMorgan’s laws, the query is really:
SELECT col1 FROM Table2 WHERE ((col1 <> 1) AND (col1 <> 2) AND (col1 <> 3) AND (col1 <> 4) AND (col1 <> 5) AND UNKNOWN);
Look at the truth tables and you will see this always reduces to UNKNOWN and an UNKNOWN is always rejected in a search condition in a WHERE clause.
14.5.2 Logical Value Predicate
Standard SQL solved some of the 3VL (Three-Valued Logic) problems by adding this predicate:
< search condition > IS [NOT] TRUE | FALSE | UNKNOWN
which will let you map any combination of three-valued logic to two values. For example, ((credit_score < 750) OR (eye_color = ‘Blue’)) IS NOT FALSE will return TRUE if (credit_score IS NULL) or (eye_color IS NULL) and the remaining condition does not matter.
14.6 Math and NULLs
NULLs propagate when they appear in arithmetic expressions (+, −, *, /) and return NULL results. See the chapter on numeric data types for more details. The principle of NULL propagation appears throughout SQL.
Aggregate functions (SUM, AVG, MIN, MAX, COUNT, COUNT(*)) drop the NULLs before doing their computation. This means that an all-NULL table will be empty. Now special rules apply to the results, and the aggregate of an empty set is NULL and COUNT(*) and COUNT are zero. Chris Date and other people do not like this convention. They are willing to agree to MIN, MAX, AVG, and COUNT sold be NULL, but they freak out on SUM.
The reason is that there is a convention in mathematics that when you do the summation of a series with the Σi notation, if the summation has one summand, then it returns that value, just like SQL. Technically, this makes addition (a binary operator) and summation different. If the summation has no summands, then it returns zero because zero is the identity element for addition. This is known as the empty sum. This convention makes formal manipulations easier.
Likewise, for the same reasons of formal convenience, when you do products of a series with the Πi notation, if the product has one factor, then it returns that value. If the product has no factors, then it returns one, because one is the identity element for multiplication. This is known as the empty product.
14.7 Functions for NULLs
All standard computational functions propagate NULLs; that means a NULL argument gives NULL result of the appropriate data type. Most vendors propagate NULLs in the functions they offer as extensions of the standard ones required in SQL. For example, the cosine of a NULL will be NULL. There are two functions that convert NULLs into values.
1. NULLIF (V1, V2) returns a NULL when the first parameter equals the second parameter. The function is equivalent to the following case specification:
CASE WHEN (V1 = V2) THEN NULL ELSE V1 END
2. COALESCE (V1, V2, V3, …, Vn) processes the list from left to right and returns the first parameter that is not NULL. If all the values are NULL, it returns a NULL.
14.8 NULLs and Host Languages
This book does not discuss using SQL statements embedded in any particular host language. You will need to pick up a book for your particular language. However, you should know how NULLs are handled when they have to be passed to a host program. No standard host language for which an embedding is defined supports NULLs, which is another good reason to avoid using NULLs in your database schema.
Roughly speaking, the programmer mixes SQL statements bracketed by EXEC SQL and a language-specific terminator (the semicolon in Pascal and C, END-EXEC in COBOL, and so on) into the host program. This mixed-language program is run through an SQL preprocessor that converts the SQL into procedure calls the host language can compile; then the host program is compiled in the usual way.
There is an EXEC SQL BEGIN DECLARE SECTION, EXEC SQL END DECLARE SECTION pair that brackets declarations for the host parameter variables that will get values from the database via CURSORs. This is the “neutral territory” where the host and the database pass information. SQL knows that it is dealing with a host variable because these have a colon prefix added to them when they appear in an SQL statement. A CURSOR is an SQL query statement that executes and creates a structure that looks like a sequential file. The records in the CURSOR are returned, one at a time, to the host program in the BEGIN DECLARE section with the FETCH statement. This avoids the impedance mismatch between record processing in the host language and SQL’s set orientation.
NULLs are handled by declaring INDICATOR variables in the host language BEGIN DECLARE section, which are paired with the host variables. An INDICATOR is an exact numeric data type with a scale of zero—that is, some kind of integer in the host language.
The FETCH statement takes one row from the cursor, and then converts each SQL data type into a host-language data type and puts that result into the appropriate host variable. If the SQL value was a NULL, the INDICATOR is set to minus one; if no indicator was specified, an exception condition is raised. As you can see, the host program must be sure to check the INDICATORs, because otherwise the value of the parameter will be garbage. If the parameter is passed to the host language without any problems, the INDICATOR is set to zero. If the value being passed to the host program is a non-NULL character string and it has an indicator, the indicator is set to the length of the SQL string and can be used to detect string overflows or to set the length of the parameter.
Other SQL interfaces such as ODBC, JDBC, etc., have similar mechanisms for telling the host program about NULLs even though they might not use cursors.
14.9 Design Advice for NULLs
“If you’re that concerned with NULLs, then use the ISNULL function, that’s what it’s there for.”
-- Jay, 2009-12-20 in a posting on the Microsoft SQL Server Programming Newsgroup
I wish this quotation was a fake. First of all, Jay did not know that MS SQL Server has had COALESCE() for years, so he was writing SQL in a Hillbilly dialect with the proprietary ISNULL() syntax. And then the content of the sentence is just wrong. Yet, I fear that he is not alone. A competent SQL programmer has a simple process for handling NULLs in his DDL.
First, declare all your base tables with NOT NULL constraints on all columns and then justify using NULLs in them. NULLs still confuse people who do not know SQL and NULLs are expensive. NULLs are usually implemented with an extra bit somewhere in the row where the column appears, rather than in the column itself. They adversely affect storage requirements, indexing, and searching.
NULLs are not permitted in PRIMARY KEY columns. Think about what a PRIMARY KEY that was NULL (or even partially NULL) would mean. A NULL in a key means that the data model does not know what makes the entities in that table unique from each other. That in turn says that the RDBMS cannot decide whether the PRIMARY KEY does or does not duplicate a key that is already in the table.
NULLs should be avoided in FOREIGN KEYs. SQL allows this “benefit of the doubt” relationship, but it can cause a loss of information in queries that involve joins. For example, given a part number code in Inventory that is referenced as a FOREIGN KEY by an Orders table, you will have problems getting a listing of the parts that have a NULL. This is a mandatory relationship; you cannot order a part that does not exist.
An example of an optional foreign key is a relationship between a Personnel table, a Jobs table and a Job_Assignments table. The new hire has all of his personnel information and we have a bunch of open jobs, but we have not assigned him a job yet. We might want to show his job as a NULL in Job_Assignments.
NULLs should not be allowed in encoding schemes that are known to be complete. For example, employees are people and people are either male or female. On the other hand, if you are recording lawful persons (corporations and other legal entities), you need the ISO sex codes, which use 0 = unknown, 1 = male, 2 = female, and 9 = legal persons, such as corporations.
The use of all zeros and all nines for “Unknown” and “N/A” is quite common in numeric encoding schemes. This convention is a leftover from the old punch card days, when a missing value was left as a field of blanks that could punched into the card later. Early versions of FORTRAN read blanks in numeric fields as zeroes.
Likewise, a field of all nines would sort to the end of the file, and it was easy to hold the “nine” key down when the keypunch machine was in numeric shift. This was a COBOL programmer convention.
However, you have to use NULLs in date columns when a DEFAULT date does not make sense. For example, if you do not know someone’s birth date, a default date does not make sense; if a warranty has no expiration date, then a NULL can act as an “eternity” symbol. Unfortunately, you often know relative times, but it is difficult to express them in a database. For example, you cannot get a pay raise before you are hired, you cannot die before you are born, etc. A convict serving on death row should expect a release date resolved by an event: his execution or death by natural causes. This leads to extra columns to hold the status and to control the transition constraints.
There is a proprietary extension to date values in MySQL. If you know the year but not the month, you may enter ‘2017-00-00.’ If you know the year and month but not the day, you may enter ‘2017-09-00.’ You cannot reliably use date arithmetic on these values, but they do help in some instances, such as sorting people’s birth dates or calculating their (approximate) age.
For people’s names, you are probably better off using a special dummy string for unknown values rather than the general NULL. In particular, you can build a list of ‘John Doe #1,’ ‘John Doe #2,’ and so forth to differentiate them; and you cannot do that with a NULL. Quantities have to use a NULL in some cases. There is a difference between an unknown quantity and a zero quantity; it is the difference between an empty gas tank and not having a car at all. Using negative numbers to represent missing quantities does not work because it makes accurate calculations too complex.
When the host programming languages had no DATE data type, this could have been handled with a character string of ‘9999-99-99’ for ‘eternity’ or ‘the end of time’; it is actually the last date in the ISO-8601 Standard. When 4GL products with a DATE data type came onto the market, programmers usually inserted the maximum possible date for ‘eternity.’ But again, this will show up in calculations and in summary statistics. The best trick was to use two columns, one for the date and one for a flag. But this made for fairly complex code in the 4GL. For example, if there are a lot of flags that signal “this birthdate is approximated ± 3 years,” then you have to do special statistics to computer the average age of a population.
14.9.1 Avoiding NULLs from the Host Programs
You can avoid putting NULLs into the database from the Host Programs with some programming discipline.
1. Initialization in the host program: initialize all the data elements and displays on the input screen of a client program before inserting data into the database. Exactly how you can make sure that all the programs use the same default values is another problem.
2. Automatic Defaults: The database is the final authority on the default values.
3. Deducing Values: infer the missing data from the given values. For example, patients reporting a pregnancy are female; patients reporting prostate cancer are male. This technique can also be used to limit choices to valid values for the user.
4. Tracking missing data: data is tagged as missing, unknown, in error, out of date, or whatever other condition makes it missing. This will involve a companion column with special codes. Most commercial applications do not need this, but a data quality audit could use this kind of detail.
5. Determine impact of missing data on programming and reporting. Numeric columns with NULLs are a problem because queries using aggregate functions can provide misleading results. Aggregate functions drop out the NULLs before doing the math and the programmer has to trap the SQLSTATE 01003 for this to make corrections. It is a Warning and will not create a ROLLBACK.
6. Prevent missing data: use batch process to scan and validate data elements before it goes into the database. In the early 2000’s, there was a sudden concern for data quality when CEOs started going to jail for failing audits. This has lead to a niche in the software trade for data quality tools.
7. The data types and their NULL-ability constraints have to be consistent across databases (e.g., the chart of account should be defined the same way in both the desktop spreadsheets and enterprise level databases).
14.10 A Note on Multiple NULL Values
In a discussion on CompuServe in 1996 July, Carl C. Federl came up with an interesting idea for multiple missing value tokens in a database.
If you program in embedded SQL, you are used to having to work with an INDICATOR column. This is used to pass information to the host program, mostly about the NULL or NOT NULL status of the SQL column in the database. What the host program does with the information is up to the programmer. So why not extend this concept a bit and provide an indicator column? Let’s work out a simply example:
CREATE TABLE Bob (keycol INTEGER NOT NULL PRIMARY KEY, val_col INTEGER NOT NULL, multi_indicator INTEGER NOT NULL CHECK (multi_indicator IN (0, -- Known value 1, -- Not applicable value 2, -- Missing value 3 -- Approximate value));
Let’s set up the rules: When all values are known, we do a regular total. If a value is “not applicable,” then the whole total is “not applicable.” If we have no “not applicable” values, then “missing value” dominates the total; if we have no “not applicable” and no “Missing” values, then we give a warning about approximate values. The general form of the queries will be:
SELECT SUM (val_col), (CASE WHEN NOT EXISTS (SELECT multi_indicator FROM Bob WHERE multi_indicator > 0) THEN 0 WHEN EXISTS (SELECT * FROM Bob WHERE multi_indicator = 1) THEN 1 WHEN EXISTS (SELECT * FROM Bob WHERE multi_indicator = 2) THEN 2 WHEN EXISTS (SELECT * FROM Bob WHERE multi_indicator = 3) THEN 3 ELSE NULL END) AS totals_multi_indicator FROM Bob;
Why would I muck with the val_col total at all? The status is over in the multi_indicator column, just like it was in the original table. Here is an exercise for the reader:
1. Make up a set of rules for multiple missing values and write a query for the SUM(), AVG(), MAX(), MIN() and COUNT() functions.
2. Set degrees of approximation (plus or minus five, plus or minus ten, etc.) in the multi_indicator. Assume the val_col is always in the middle. Make the multi_indicator handle the fuzziness of the situation.
CREATE TABLE MultiNull (groupcol INTEGER NOT NULL, keycol INTEGER NOT NULL, val_col INTEGER NOT NULL CHECK (val_col >= 0), val_col_null INTEGER NOT NULL DEFAULT 0, CHECK(val_col_null IN (0, -- Known Value 1, -- Not applicable 2, -- Missing but applicable 3, -- Approximate within 1% 4, -- Approximate within 5% 5, -- Approximate within 25% 6 -- Approximate over 25% range)), PRIMARY KEY (groupcol, keycol), CHECK (val_col = 0 OR val_col_null NOT IN (1,2)); CREATE VIEW Group_MultiNull (groupcol, val_col_sum, val_col_avg, val_col_max, val_col_min, row_cnt, notnull_cnt, na_cnt, missing_cnt, approximate_cnt, appr_1_cnt, approx_5_cnt, approx_25_cnt, approx_big_cnt) AS SELECT groupcol, SUM(val_col), AVG(val_col), MAX(val_col), MIN(val_col), COUNT(*), SUM (CASE WHEN val_col_null = 0 THEN 1 ELSE 0 END) AS notnull_cnt, SUM (CASE WHEN val_col_null = 1 THEN 1 ELSE 0 END) AS na_cnt, SUM (CASE WHEN val_col_null = 2 THEN 1 ELSE 0 END) AS missing_cnt, SUM (CASE WHEN val_col_null IN (3,4,5,6) THEN 1 ELSE 0 END) AS approximate_cnt, SUM (CASE WHEN val_col_null = 3 THEN 1 ELSE 0 END) AS appr_1_cnt, SUM (CASE WHEN val_col_null = 4 THEN 1 ELSE 0 END) AS approx_5_cnt, SUM (CASE WHEN val_col_null = 5 THEN 1 ELSE 0 END) AS approx_25_cnt, SUM (CASE WHEN val_col_null = 6 THEN 1 ELSE 0 END) AS approx_big_cnt FROM MultiNull GROUP BY groupcol; SELECT groupcol, val_col_sum, val_col_avg, val_col_max, val_col_min, (CASE WHEN row_cnt = notnull_cnt THEN 'All are known' ELSE 'Not all are known' END) AS warning_message, row_cnt, notnull_cnt, na_cnt, missing_cnt, approximate_cnt, appr_1_cnt, approx_5_cnt, approx_25_cnt, approx_big_cnt FROM Group_MultiNull;
While this is a bit complex for the typical application, it is not a bad idea for a “staging area” database that attempts to scrub the data before it goes to a data warehouse.