
Chapter 6. Extending search
This chapter covers
- Creating a custom sort
- Using a Collector
- Customizing QueryParser
- Using positional payloads
Just when you thought we were done with searching, here we are again with even more on the topic! Chapter 3 discussed the basics of Lucene’s built-in capabilities, and chapter 5 delved well beyond the basics into Lucene’s more advanced searching features. In those two chapters, we explored only the built-in features. Lucene also has several powerful extension points, which we’ll cover here.
Custom sorting lets you implement arbitrary sorting criteria when the built-in sort by relevance or field isn’t appropriate. We’ll show an example of sorting by geographic proximity to a user’s current location. Custom collection lets you arbitrarily process each matching document yourself, in case you don’t want the top documents according to a sort criterion. We’ll also include examples of two custom collectors. QueryParser has many extension points to customize how each type of query is created, and we provide examples, including how to prevent certain query types and handling numeric and date fields. Custom filters let you arbitrarily restrict the allowed documents for matching. Finally, you can use payloads to separately boost specific occurrences of a given term within the same document. Armed with an understanding of these powerful extension points, you’ll be able to customize Lucene’s behavior in nearly arbitrary ways.
Let’s begin with custom sorting.
6.1. Using a custom sort method
If sorting by score, ID, or field values is insufficient for your needs, Lucene lets you implement a custom sorting mechanism by providing your own subclass of the FieldComparatorSource abstract base class. Custom sorting implementations are most useful in situations when the sort criteria can’t be determined during indexing.
For this section we’ll create a custom sort that orders search results based on geographic distance from a given location.[1] The given location is only known at search time, and could, for example, be the geographic location of the user doing the search if the user is searching from a mobile device with an embedded global positioning service (GPS). First we show the required steps at indexing time. Next we’ll describe how to implement the custom sort during searching. Finally, you’ll learn how to access field values involved in the sorting for presentation purposes.
1 Thanks to Tim Jones (the contributor of Lucene’s sort capabilities) for the inspiration.
6.1.1. Indexing documents for geographic sorting
We’ve created a simplified demonstration of this concept using the important question, “What Mexican food restaurant is nearest to me?” Figure 6.1 shows a sample of restaurants and their fictitious grid coordinates on a sample 10 x 10 grid. Note that Lucene now includes the “spatial” package in the contrib modules, described in section 9.7, for filtering and sorting according to geographic distance in general.
Figure 6.1. Which Mexican restaurant is closest to home (at 0,0) or work (at 10,10)?
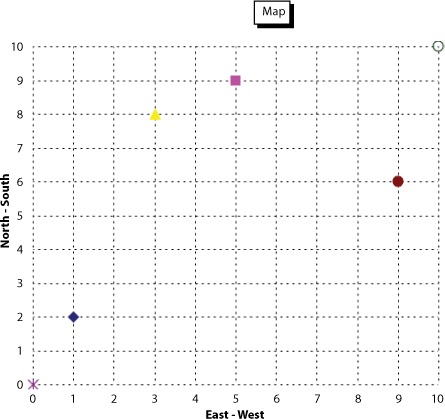
The test data is indexed as shown in listing 6.1, with each place given a name, location in X and Y coordinates, and a type. The type field allows our data to accommodate other types of businesses and could allow us to filter search results to specific types of places.
Listing 6.1. Indexing geographic data
public class DistanceSortingTest extends TestCase {
private RAMDirectory directory;
private IndexSearcher searcher;
private Query query;
protected void setUp() throws Exception {
directory = new RAMDirectory();
IndexWriter writer =
new IndexWriter(directory, new WhitespaceAnalyzer(),
IndexWriter.MaxFieldLength.UNLIMITED);
addPoint(writer, "El Charro", "restaurant", 1, 2);
addPoint(writer, "Cafe Poca Cosa", "restaurant", 5, 9);
addPoint(writer, "Los Betos", "restaurant", 9, 6);
addPoint(writer, "Nico's Taco Shop", "restaurant", 3, 8);
writer.close();
searcher = new IndexSearcher(directory);
query = new TermQuery(new Term("type", "restaurant"));
}
private void addPoint(IndexWriter writer,
String name, String type, int x, int y)
throws IOException {
Document doc = new Document();
doc.add(new Field("name", name, Field.Store.YES,
Field.Index.NOT_ANALYZED));
doc.add(new Field("type", type, Field.Store.YES,
Field.Index.NOT_ANALYZED));
doc.add(new Field("location", x + "," + y, Field.Store.YES,
Field.Index.NOT_ANALYZED));
writer.addDocument(doc);
}
}
The coordinates are indexed into a single location field as a string x, y. The location could be encoded in numerous ways, but we opted for the simplest approach for this example.
6.1.2. Implementing custom geographic sort
Before we delve into the class that performs our custom sort, let’s look at the test case that we’re using to confirm that it’s working correctly:
public void testNearestRestaurantToHome() throws Exception {
Sort sort = new Sort(new SortField("location",
new DistanceComparatorSource(0, 0)));
TopDocs hits = searcher.search(query, null, 10, sort);
assertEquals("closest",
"El Charro",
searcher.doc(hits.scoreDocs[0].doc).get("name"));
assertEquals("furthest",
"Los Betos",
searcher.doc(hits.scoreDocs[3].doc).get("name"));
}
Home is at coordinates (0,0). Our test has shown that the first and last documents in the returned results are the ones closest and furthest from home. Muy bien! Had we not used a sort, the documents would’ve been returned in insertion order, because the score of each hit is equivalent for the restaurant-type query. The distance computation, using the basic distance formula, is done under our custom DistanceComparatorSource, shown in listing 6.2.
Listing 6.2. DistanceComparatorSource


The sorting infrastructure within Lucene interacts with the FieldComparatorSource and FieldComparator ![]() ,
, ![]() API in order to sort matching documents. For performance reasons, this API is more complex than you’d otherwise expect. In
particular, the comparator is made aware of the size of the queue (passed as the numHits argument to newComparator)
API in order to sort matching documents. For performance reasons, this API is more complex than you’d otherwise expect. In
particular, the comparator is made aware of the size of the queue (passed as the numHits argument to newComparator) ![]() being tracked within Lucene. In addition, the comparator is notified every time a new segment is searched (with the setNextReader method).
being tracked within Lucene. In addition, the comparator is notified every time a new segment is searched (with the setNextReader method).
The constructor is provided with the origin location ![]() for computing distances. With each call to setNextReader, we get all x and y values from the field cache
for computing distances. With each call to setNextReader, we get all x and y values from the field cache ![]() ,
, ![]() . Be sure to understand the performance implications when a field cache is used, as described in section 5.1. These values are also used by the getDistance method
. Be sure to understand the performance implications when a field cache is used, as described in section 5.1. These values are also used by the getDistance method ![]() which computes the actual distance for a given document, and in turn the value method
which computes the actual distance for a given document, and in turn the value method ![]() , which Lucene invokes to retrieve the actual value used for sorting.
, which Lucene invokes to retrieve the actual value used for sorting.
While searching, when a document is competitive it’s inserted into the queue at a given slot, as determined by Lucene. Your
comparator is asked to compare hits within the queue (compare ![]() )), set the bottom (worst scoring entry) slot in the queue (setBottom
)), set the bottom (worst scoring entry) slot in the queue (setBottom ![]() ,
, ![]() ), compare a hit to the bottom of the queue (compareBottom
), compare a hit to the bottom of the queue (compareBottom ![]() ), and copy a new hit into the queue (copy
), and copy a new hit into the queue (copy ![]() ). The values array
). The values array ![]() stores the distances for all competitive documents in the queue.
stores the distances for all competitive documents in the queue.
Sorting by runtime information such as a user’s location is an incredibly powerful feature. At this point, though, we still have a missing piece: what’s the distance from each of the restaurants to our current location? When using the TopDocs-returning search methods, we can’t get to the distance computed. But a lower-level API lets us access the values used for sorting.
6.1.3. Accessing values used in custom sorting
The IndexSearcher.search method you use when sorting, covered in section 5.2, returns more information than the top documents:
public TopFieldDocs search(Query query, Filter filter,
int nDocs, Sort sort)
TopFieldDocs is a subclass of TopDocs that adds the values used for sorting each hit. The values are available via each FieldDoc, which subclasses ScoreDoc, contained in the array of returned results. FieldDoc encapsulates the computed raw score, document ID, and an array of Comparables with the value used for each SortField. Rather than concerning ourselves with the details of the API, which you can get from Lucene’s Javadocs or the source code, let’s see how to use it.
Listing 6.3’s test case demonstrates the use of TopFieldDocs and FieldDoc to retrieve the distance computed during sorting, this time sorting from work at location (10,10).
Listing 6.3. Accessing custom sorting values for search results
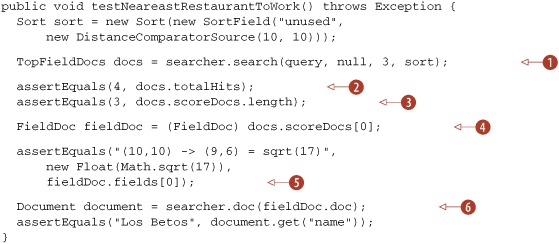
As you can see, Lucene’s custom sorting capabilities empower you to build arbitrary sorting logic for those cases when sorting by relevance or by field value is insufficient. We delved into a basic example, sorting by geographic distance, but that’s just one of many possibilities. We’ll now switch to an even deeper extensions point inside Lucene: custom collection.
6.2. Developing a custom Collector
In most applications with full-text search, users are looking for the top documents when sorting by either relevance or field values. The most common usage pattern is such that only these ScoreDocs are visited. In some scenarios, though, users want more control over precisely which documents should be retained during searching.
Lucene allows full customization of what you do with each matching document if you create your own subclass of the abstract Collector base class. For example, perhaps you wish to gather every single document ID that matched the query. Or perhaps with each matched document you’d like to consult its contents or an external resource to collate additional information. We’ll cover both of these examples in this section.
You might be tempted to run a normal search, with a very large numHits, and then postprocess the results. This strategy will work, but it’s an exceptionally inefficient approach because these methods are spending sizable CPU computing scores, which you may not need, and performing sorting, which you also may not need. Using a custom Collector class avoids these costs.
We begin by delving into the methods that make up the custom Collector API (see table 6.1).
Table 6.1. Methods to implement for a custom Collector
6.2.1. The Collector base class
Collector is an abstract base class that defines the API that Lucene interacts with while doing searching. As with the FieldComparator API for custom sorting, Collector’s API is more complex than you’d expect, in order to enable high-performance hit collection. Table 6.1 shows the four methods with a brief summary.
All of Lucene’s core search methods use a Collector subclass under the hood to do their collection. For example, when sorting by relevance, TopScoreDocCollector is used. When sorting by field, it’s TopFieldCollector. Both of these are public classes in the org.apache.lucene.search package, and you can instantiate them yourself if needed.
During searching, when Lucene finds a matching document, it calls the Collector’s collect(int docID) method. Lucene couldn’t care less what’s done with the document; it’s up to the Collector to record the match, if it wants. This is the hot spot of searching, so make sure your collect method does only the bare minimum work required.
Lucene drives searching one segment at a time, for higher performance, and notifies you of each segment transition by calling the setNextReader(IndexReader reader, int docBase). The provided IndexReader is specific to the segment. It will be a different instance for each segment. It’s important for the Collector to record the docBase at this point, because the docID provided to the collect method is relative within each segment. To get the absolute or global docID, you must add docBase to it. This method is also the place to do any segment-specific initialization required by your collector. For example, you could use the FieldCache API, described in section 5.1, to retrieve values corresponding to the provided IndexReader.
Note that the relevance score isn’t passed to the collect method. This saves wasted CPU for Collectors that don’t require it. Instead, Lucene calls the setScorer(Scorer) method on the Collector, once per segment in the index, to provide a Scorer instance. You should hold onto this Scorer, if needed, and then retrieve the relevance score of the currently matched document by calling Scorer.score(). That method must be called from within the collect method because it holds volatile data specific to the current docID being collected. Note that Scorer.score() will recompute the score every time, so if your collect method may invoke score multiple times, you should call it once internally and simply reuse the returned result. Alternatively, Lucene provides the ScoreCachingWrapperScorer, which is a Scorer implementation that caches the score per document. Note also that Scorer is a rich and advanced API in and of itself, but in this context you should only use the score method.
The final method, acceptsDocsOutOfOrder(), which returns a Boolean, is invoked by Lucene to see whether your Collector can tolerate docIDs that arrive out of sorted order. Many collectors can, but some collectors either can’t accept docIDs out or order, or would have to do too much extra work. If possible, you should return true, because certain BooleanQuery instances can use a faster scorer under the hood if given this freedom.
Let’s look at two example custom Collectors: BookLinkCollector and AllDocCollector.
6.2.2. Custom collector: BookLinkCollector
We’ve developed a custom Collector, called BookLinkCollector, which builds a map of all unique URLs and the corresponding book titles matching a query. BookLinkCollector is shown in listing 6.4.
Listing 6.4. Custom Collector: collects all book links

The collector differs from Lucene’s normal search result collection in that it does not retain the matching document IDs. Instead, for each matching document, it adds a mapping of URL to title into its private map, then makes that map available after the search completes. For this reason, even though we are passed the docBase in setNextReader, there’s no need to save it, as the url s and titles that we retrieve from the FieldCache are based on the per-segment document ID. Using our custom Collector requires the use of IndexSearcher’s search method variant, as shown in listing 6.5.
Listing 6.5. Testing the BookLinkCollector
public void testCollecting() throws Exception {
Directory dir = TestUtil.getBookIndexDirectory();
TermQuery query = new TermQuery(new Term("contents", "junit"));
IndexSearcher searcher = new IndexSearcher(dir);
BookLinkCollector collector = new BookLinkCollector(searcher);
searcher.search(query, collector);
Map<String,String> linkMap = collector.getLinks();
assertEquals("ant in action",
linkMap.get("http://www.manning.com/loughran"));;
searcher.close();
dir.close();
}
During the search, Lucene delivers each matching docID to our collector; after the search finishes, we confirm that the link map created by the collector contains the right mapping for “ant in action.”
Let’s look at a simple custom Collector, next.
6.2.3. AllDocCollector
Sometimes you’d like to simply record every single matching document for a search, and you know the number of matches won’t be very large. Listing 6.6 shows a simple class, AllDocCollector, to do just that.
Listing 6.6. A collector that gathers all matching documents and scores into a List

You simply instantiate it, pass it to the search, and use the getHits() method to retrieve all hits. But note that the resulting docIDs might be out of sorted order because acceptsDocsOutOfOrder() returns true. Just change that to false, if this is a problem.
As you’ve seen, creating a custom Collector is quite simple. Lucene passes you the docIDs that match and you’re free to do what you want with them. We created one collector that populates a map, discarding the documents that match, and another that gathers all matching documents. The possibilities are endless!
Next we discuss useful ways to extend QueryParser.
6.3. Extending QueryParser
In section 3.5, we introduced QueryParser and showed that it has a few settings to control its behavior, such as setting the locale for date parsing and controlling the default phrase slop. QueryParser is also extensible, allowing subclassing to override parts of the query-creation process. In this section, we demonstrate subclassing QueryParser to disallow inefficient wildcard and fuzzy queries, custom date-range handling, and morphing phrase queries into SpanNearQuerys instead of PhraseQuerys.
6.3.1. Customizing QueryParser’s behavior
Although QueryParser has some quirks, such as the interactions with an analyzer, it does have extensibility points that allow for customization. Table 6.2 details the methods designed for overriding and why you may want to do so.
Table 6.2. QueryParser’s extensibility points
|
Method |
Why override? |
|---|---|
| getFieldQuery(String field, Analyzer analyzer, String queryText) or getFieldQuery(String field, Analyzer analyzer, String queryText, int slop) | These methods are responsible for the construction of either a TermQuery or a PhraseQuery. If special analysis is needed, or a unique type of query is desired, override this method. For example, a SpanNearQuery can replace PhraseQuery to force ordered phrase matches. |
| getFuzzyQuery(String field, String termStr, float minSimilarity) | Fuzzy queries can adversely affect performance. Override and throw a ParseException to disallow fuzzy queries. |
| getPrefixQuery(String field, String termStr) | This method is used to construct a query when the term ends with an asterisk. The term string handed to this method doesn’t include the trailing asterisk and isn’t analyzed. Override this method to perform any desired analysis. |
| getRangeQuery(String field, String start, String end, boolean inclusive) | Default range-query behavior has several noted quirks (see section 3.5.3). Overriding could lowercase the start and end terms, use a different date format, or handle number ranges by converting to a NumericRangeQuery (see section 6.3.3). |
| getBooleanQuery(List clauses) or getBooleanQuery(List clauses, boolean disableCoord) | Constructs a BooleanQuery given the clauses. |
| getWildcardQuery(String field, String termStr) | Wildcard queries can adversely affect performance, so overridden methods could throw a ParseException to disallow them. Alternatively, because the term string isn’t analyzed, special handling may be desired. |
All of the methods listed return a Query, making it possible to construct something other than the current subclass type used by the original implementations of these methods. Also, each of these methods may throw a ParseException, allowing for error handling.
QueryParser also has extensibility points for instantiating each query type. These differ from the points listed in table 6.2 in that they create the requested query type and return it. Overriding them is useful if you only want to change which Query class is used for each type of query without altering the logic of what query is constructed. These methods are newBooleanQuery, newTermQuery, newPhraseQuery, newMultiPhraseQuery, newPrefixQuery, newFuzzyQuery, newRangeQuery, newMatchAllDocsQuery and newWildcardQuery. For example, if whenever a TermQuery is created by QueryParser you’d like to instantiate your own subclass of TermQuery, simply override newTermQuery.
6.3.2. Prohibiting fuzzy and wildcard queries
The subclass in listing 6.7 demonstrates a custom query parser subclass that disables fuzzy and wildcard queries by taking advantage of the ParseException option.
Listing 6.7. Disallowing wildcard and fuzzy queries
public class CustomQueryParser extends QueryParser {
public CustomQueryParser(Version matchVersion,
String field, Analyzer analyzer) {
super(matchVersion, field, analyzer);
}
protected final Query getWildcardQuery(String field, String termStr)
throws ParseException {
throw new ParseException("Wildcard not allowed");
}
protected Query getFuzzyQuery(String field, String term,
float minSimilarity)
throws ParseException {
throw new ParseException("Fuzzy queries not allowed");
}
}
To use this custom parser and prevent users from executing wildcard and fuzzy queries, construct an instance of CustomQueryParser and use it exactly as you would QueryParser, as shown in listing 6.8.
Listing 6.8. Using a custom QueryParser

With this implementation, both of these expensive query types are forbidden, giving you peace of mind in terms of performance and errors that may arise from these queries expanding into too many terms. Our next QueryParser extension enables creation of NumericRangeQuery.
6.3.3. Handling numeric field-range queries
As you learned in chapter 2, Lucene can handily index numeric and date values. Unfortunately, QueryParser is unable to produce the corresponding NumericRangeQuery instances at search time. Fortunately, it’s simple to subclass QueryParser to do so, as shown in listing 6.9.
Listing 6.9. Extending QueryParser to properly handle numeric fields

Using this approach, you rely on QueryParser to first create the TermRangeQuery, and from that you construct the NumericRangeQuery as needed. Testing our NumericQueryParser, like this:
public void testNumericRangeQuery() throws Exception {
String expression = "price:[10 TO 20]";
QueryParser parser = new NumericRangeQueryParser(Version.LUCENE_30,
"subject", analyzer);
Query query = parser.parse(expression);
System.out.println(expression + " parsed to " + query);
}
yields the expected output (note that the 10 and 20 have been turned into floating point values):
price:[10 TO 20] parsed to price:[10.0 TO 20.0]
As you’ve seen, extending QueryParser to handle numeric fields was straightforward. Let’s do the same for date fields next.
6.3.4. Handling date ranges
QueryParser has built-in logic to detect date ranges: if the terms are valid dates, according to DateFormat.SHORT and lenient parsing within the default or specified locale, the dates are converted to their internal textual representation. By default, this conversion will use the older DateField.dateToString method, which renders each date with millisecond precision; this is likely not what you want. If you invoke QueryParser’s setDateResolution methods to state which DateTools.Resolution your field(s) were indexed with, then QueryParser will use the newer DateTools.dateToString method to translate the dates into strings with the appropriate resolution. If either term fails to parse as a valid date, they’re both used as is for a textual range.
But despite these two built-in approaches for handling dates, QueryParsers’s date handling hasn’t been updated to handle date fields indexed as NumericField, which is the recommended approach for dates, as described in section 2.6.2. Let’s see how we can once again override newRangeQuery, this time to translate our date-based range searches into the corresponding NumericRangeQuery, shown in listing 6.10.
Listing 6.10. Extending QueryParser to handle date fields
class NumericDateRangeQueryParser extends QueryParser {
public NumericDateRangeQueryParser(Version matchVersion,
String field, Analyzer a) {
super(matchVersion, field, a);
}
public Query getRangeQuery(String field,
String part1,
String part2,
boolean inclusive)
throws ParseException {
TermRangeQuery query = (TermRangeQuery)
super.getRangeQuery(field, part1, part2, inclusive);
if ("pubmonth".equals(field)) {
return NumericRangeQuery.newIntRange(
"pubmonth",
Integer.parseInt(query.getLowerTerm()),
Integer.parseInt(query.getUpperTerm()),
query.includesLower(),
query.includesUpper());
} else {
return query;
}
}
}
In this case it’s still helpful to use QueryParser’s built-in logic for detecting and parsing dates. You simply build on that logic in your subclass by taking the further step to convert the query into a NumericRangeQuery. Note that in order to use this subclass you must call QueryParser.setDateResolution, so that the resulting text terms are created with DateTools, as shown in listing 6.11.
Listing 6.11. Testing date range parsing
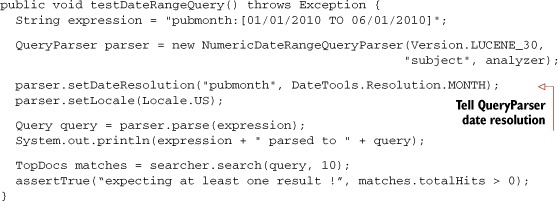
This test produces the following output:
pubmonth:[05/01/1988 TO 10/01/1988] parsed to pubmonth:[198805 TO 198810]
As you can see, QueryParser first parsed our textual date expressions (05/01/1988) into normalized form (198805), and then our NumericDateRangeQueryParser subclass translated those normalized forms into the equivalent NumericRangeQuery.
Controlling the Date-Parsing Locale
To change the locale used for date parsing, construct a QueryParser instance and call setLocale(). Typically the client’s locale would be determined and used instead of the default locale. For example, in a web application the HttpServletRequest object contains the locale set by the client browser. You can use this locale to control the locale used by date parsing in QueryParser, as shown in listing 6.12.
Listing 6.12. Using the client locale in a web application

QueryParser’s setLocale is one way in which Lucene facilitates internationalization (often abbreviated as I18N) concerns. Text analysis is another, more important, place where such concerns are handled. Further I18N issues are discussed in section 4.8.
Our final QueryParser customization shows how to replace the default PhraseQuery with SpanNearQuery.
6.3.5. Allowing ordered phrase queries
When QueryParser parses a single term, or terms within double quotes, it delegates the construction of the Query to a getFieldQuery method. Parsing an unquoted term calls the getFieldQuery method without the slop signature (slop makes sense only on multiterm phrase query); parsing a quoted phrase calls the getFieldQuery signature with the slop factor, which internally delegates to the nonslop signature to build the query and then sets the slop appropriately. The Query returned is either a TermQuery or a PhraseQuery, by default, depending on whether one or more tokens are returned from the analyzer.[2] Given enough slop, PhraseQuery will match terms out of order in the original text. There’s no way to force a PhraseQuery to match in order (except with slop of 0 or 1). However, SpanNearQuery does allow in-order matching. A straightforward override of getFieldQuery allows us to replace a PhraseQuery with an ordered SpanNearQuery, shown in listing 6.13.
2 A PhraseQuery could be created from a single term if the analyzer created more than one token for it.
Listing 6.13. Translating PhraseQuery to SpanNearQuery

Our test case shows that our custom getFieldQuery is effective in creating a SpanNearQuery:
public void testPhraseQuery() throws Exception {
CustomQueryParser parser =
new CustomQueryParser(Version.LUCENE_30,
"field", analyzer);
Query query = parser.parse("singleTerm");
assertTrue("TermQuery", query instanceof TermQuery);
query = parser.parse(""a phrase"");
assertTrue("SpanNearQuery", query instanceof SpanNearQuery);
}
Another possible enhancement would be to add a toggle switch to the custom query parser, allowing the in-order flag to be controlled by the user of the API.
As you can see, QueryParser is easily extended to alter its logic in producing queries from text. We’ll switch now to an important extensions point for Lucene: custom filters.
6.4. Custom filters
If all the information needed to perform filtering is in the index, there’s no need to write your own filter because the QueryWrapperFilter can handle it, as described in section 5.6.5.
But there are good reasons to factor external information into a custom filter. In this section we tackle the following example: using our book example data and pretending we’re running an online bookstore, we want users to be able to search within our special hot deals of the day.
You might be tempted to simply store the specials flag as an indexed field, but keeping this up-to-date might prove too costly. Rather than reindex entire documents when specials change, we’ll implement a custom filter that keeps the specials flagged in our (hypothetical) relational database. Then we’ll see how to apply our filter during searching, and finally we’ll explore an alternative option for applying the filter.
6.4.1. Implementing a custom filter
We start with abstracting away the source of our specials by defining this interface:
public interface SpecialsAccessor {
String[] isbns();
}
The isbns() method returns those books that are currently specials. Because we won’t have an enormous amount of specials at one time, returning all the ISBNs of the books on special will suffice.
Now that we have a retrieval interface, we can create our custom filter, SpecialsFilter. Filters extend from the org.apache.lucene.search.Filter class and must implement the getDocIdSet(IndexReader reader) method, returning a DocIdSet. Bit positions match the document numbers. Enabled bits mean the document for that position is available to be searched against the query, and unset bits mean the document won’t be considered in the search. Figure 6.2 illustrates an example SpecialsFilter that sets bits for books on special (see listing 6.14).
Figure 6.2. A filter provides a bit for every document in the index. Only documents with 1 are accepted.
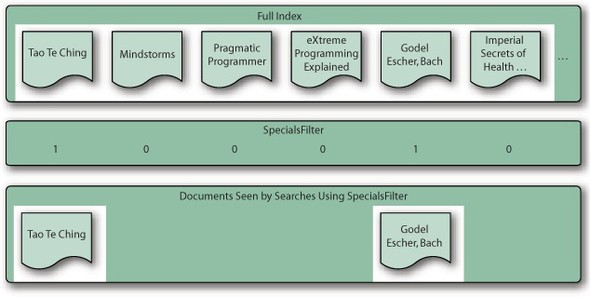
Listing 6.14. Retrieving filter information from external source with SpecialsFilter

The filter is quite straightforward. First we fetch the ISBNs ![]() of the current specials. Next, we interact with the IndexReader API to iterate over all documents matching each ISBN
of the current specials. Next, we interact with the IndexReader API to iterate over all documents matching each ISBN ![]() ; in each case it should be a single document per ISBN because this is a unique field. The document was indexed with Field.Index.NOT_ANALYZED, so we can retrieve it directly with the ISBN. Finally, we record each matching document in an OpenBitSet
; in each case it should be a single document per ISBN because this is a unique field. The document was indexed with Field.Index.NOT_ANALYZED, so we can retrieve it directly with the ISBN. Finally, we record each matching document in an OpenBitSet ![]() , which we return to Lucene. Let’s test our filter during searching.
, which we return to Lucene. Let’s test our filter during searching.
6.4.2. Using our custom filter during searching
To test that our filter is working, we created a simple TestSpecialsAccessor to return a specified set of ISBNs, giving our test case control over the set of specials:
public class TestSpecialsAccessor implements SpecialsAccessor {
private String[] isbns;
public TestSpecialsAccessor(String[] isbns) {
this.isbns = isbns;
}
public String[] isbns() {
return isbns;
}
}
Here’s how we test our SpecialsFilter, using the same setUp() that the other filter tests used:
public void testCustomFilter() throws Exception {
String[] isbns = new String[] {"9780061142666", "9780394756820"};
SpecialsAccessor accessor = new TestSpecialsAccessor(isbns);
Filter filter = new SpecialsFilter(accessor);
TopDocs hits = searcher.search(allBooks, filter, 10);
assertEquals("the specials", isbns.length, hits.totalHits);
}
We use a generic query that is broad enough to retrieve all the books, making assertions easier to craft. But because our filter trimmed the search space, only the specials are returned. With this infrastructure in place, implementing a SpecialsAccessor to retrieve a list of ISBNs from a database should be easy; doing so is left as an exercise for the savvy reader.
Note that we made an important implementation decision not to cache the DocIdSet in SpecialsFilter. Decorating SpecialsFilter with a CachingWrapperFilter frees us from that aspect. Let’s see an alternative means of applying a filter during searching.
6.4.3. An alternative: FilteredQuery
To add to the filter terminology overload, one final option is FilteredQuery.[3]FilteredQuery inverts the situation that searching with a filter presents. Using a filter, an IndexSearcher’s search method applies a single filter during querying. Using the FilteredQuery, though, you can turn any filter into a query, which opens up neat possibilities, such as adding a filter as a clause to a BooleanQuery.
3 We’re sorry! We know that Filter, QueryWrapperFilter, FilteredQuery, and the completely unrelated TokenFilter names can be confusing.
Let’s take the SpecialsFilter as an example again. This time, we want a more sophisticated query: books in an education category on special, or books on Logo.[4] We couldn’t accomplish this with a direct query using the techniques shown thus far, but FilteredQuery makes this possible. Had our search been only for books in the education category on special, we could’ve used the technique shown in the previous code snippet instead.
4 Erik began his programming adventures with Logo on an Apple IIe.
Our test case, in listing 6.15, demonstrates the described query using a BooleanQuery with a nested TermQuery and FilteredQuery.
Listing 6.15. Using a FilteredQuery

| This is the ISBN number for Rudolf Steiner’s A Modern Art of Education. | |
| We construct a query for education books on special, which only includes Steiner’s book in this example. | |
| We construct a query for all books with logo in the subject, which only includes Mindstorms in our sample data. | |
| The two queries are combined in an OR fashion. |
The getDocIdSet() method of the nested Filter is called each time a FilteredQuery is used in a search, so we recommend that you use a caching filter if the query is to be used repeatedly and the results of a filter don’t change.
Filtering is a powerful means of overriding which documents a query may match, and in this section you’ve seen how to create custom filters and use them during searching, as well as how to wrap a filter as a query so that it may be used wherever a query may be used. Filters give you a lot of flexibility for advanced searching.
6.5. Payloads
Payloads, an advanced feature in Lucene, enable an application to store an arbitrary byte array for every occurrence of a term during indexing. This byte array is entirely opaque to Lucene: it’s simply stored at each term position, during indexing, and then can be retrieved during searching. Otherwise the core Lucene functionality doesn’t do anything with the payload or make any assumptions about its contents. This means you can store arbitrary encoded data that’s important to your application, and then use it during searching, either to decide which documents are included in the search results or to alter how matched documents are scored or sorted.
All sorts of uses cases are enabled with payloads. One example, which we delve into in this section, is boosting the same term differently depending on where it occurred in the document. Another example is storing part-of-speech information for each term in the index, and altering how filtering, scoring, or sorting is done based on that. By creating a single-term field, you can store document-level metadata, such as an application-specific unique identifier. Yet another example is storing formatting information that was lost during analysis, such as whether a term was bold or italic, or what font or font size was used.
Position-specific boosting allows you to alter the score of matched documents when the specific occurrences of each term were “important.” Imagine we’re indexing mixed documents, where some of them are bulletins (weather warnings) and others are more ordinary documents. You’d like a search for “warning” to give extra boost when it occurs in a bulletin document. Another example is boosting terms that were bolded or italicized in the original text, or that were contained within a title or header tag for HTML documents. Although you could use field boosting to achieve this, that’d require you to separate all the important terms into entirely separate fields, which is often not feasible or desired. The payloads feature lets you solve this by boosting on a term-by-term basis within a single field.
Let’s see how to boost specific term occurrences using payloads. We’ll start with the steps required to add payloads to tokens during analysis. Then, we’ll perform searches that take our custom payloads into account. Finally, we’ll explore two other ways to interact with payloads in Lucene: first via SpanQuery and second by directly accessing Lucene’s TermPositions API.
Let’s begin with augmenting analysis to produce payloads.
6.5.1. Producing payloads during analysis
The first step is to create an analyzer that detects which tokens are important and attaches the appropriate payloads. The TokenStream for such an analyzer should define the PayloadAttribute, and then create a Payload instance when appropriate and set the payload using PayloadAttribute.setPayload inside the incrementToken method. Payloads are created with the following constructors:
Payload(byte[] data) Payload(byte[] data, int offset, int length)
It’s perfectly fine to set a null payload for some tokens. In fact, for applications where there’s a common default value, it’s best to represent that default value as a null payload, instead of a payload with the default value encoded into it, to save space in your index. Lucene simply records that there’s no payload available at that position.
The analyzers contrib module includes several useful TokenFilters, as shown in table 6.3. These classes translate certain existing attributes of a Token, such as type and start/end offset, into a corresponding payload. The PayloadHelper class, which we’ll use shortly in our use case, exposes useful functions to encode and decode numeric values to and from a byte[].
Table 6.3. TokenFilter in contrib/analyzers that encode certain TokenAttributes as payloads
|
Name |
Purpose |
|---|---|
| NumericPayloadTokenFilter | Encodes a float payload for those tokens matching the specified token type |
| TypeAsPayloadTokenFilter | Encodes the token’s type as a payload on every token |
| TokenOffsetPayloadTokenFilter | Encodes the start and end offset of each token into its payload |
| PayloadHelper | Static methods to encode and decode ints and floats into byte array payloads |
Quite often, as is the case in our example, the logic you need to create a payload requires more customization. In our case, we want to create a payload for those term occurrences that should be boosted, containing the boost score, and set no payload for all other terms. Fortunately, it’s straightforward to create your own TokenFilter to implement such logic. Listing 6.16 shows our own BulletinPayloadsAnalyzer and BulletinPayloadsFilter.
Our logic is quite simple: if the document is a bulletin, which is determined by checking whether the contents start with the prefix Bulletin:, we attach a payload that encodes a float boost to any occurrence of the term warning. We use PayloadHelper to encode the float into an equivalent byte array.
Listing 6.16. Custom filter to add payloads to warning terms inside bulletin documents
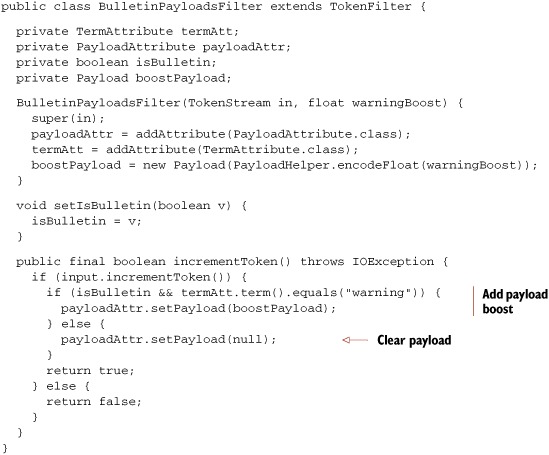
Using this analyzer, we can get our payloads into the index. But how do we use the payloads during searching to boost scores for certain matches?
6.5.2. Using payloads during searching
Fortunately, Lucene provides a built-in query PayloadTermQuery, in the package org.apache.lucene.search.payloads, for precisely this purpose. This query is just like SpanTermQuery in that it matches all documents containing the specified term and keeps track of the actual occurrences (spans) of the matches. But then it goes further by enabling you to contribute a scoring factor based on the payloads that appear at each term’s occurrence. To do this, you’ll have to create your own Similarity class that defines the scorePayload method, like this:
public class BoostingSimilarity extends DefaultSimilarity {
public float scorePayload(int docID, String fieldName,
int start, int end, byte[] payload,
int offset, int length) {
if (payload != null) {
return PayloadHelper.decodeFloat(payload, offset);
} else {
return 1.0F;
}
}
}
We again use PayloadHelper, this time to decode the byte array back into a float. For every term occurrence, PayloadTermQuery invokes scorePayload to determine its payload score. Then, it aggregates these scores across all term matches for each matching document using a PayloadFunction instance that you provide. Lucene 2.9 offers three functions—MinPayloadFunction, AveragePayloadFunction, and MaxPayloadFunction—but you can easily create your own subclass if necessary. Finally, by default the aggregated payload score is multiplied by the normal score that SpanTermQuery would otherwise provide, thus “boosting” the score for that document. If you’d rather entirely replace the score for the matching document with your payload score, use this constructor:
PayloadTermQuery(Term term, PayloadFunction function,
boolean includeSpanScore)
If you pass false for includeSpanScore, the score for each match will be the aggregated payload score. Now that we have all the pieces, let’s pull it together into a test case, as shown in listing 6.17.
Listing 6.17. Using payloads to boost certain term occurrences


We index three documents, two of which are bulletins. Next, we do two searches, printing the results. The first search is a normal TermQuery, which should return the second document as the top result, because it contains two occurrences of the term warning. The second query is a PayloadTermQuery that boosts the occurrence of warning in each bulletin by 5.0 boost (passed as the single argument to BulletinPayloadsAnalyzer). Running this test produces this output:
TermQuery results: 0.2518424:Warning label maker 0.22259936:Hurricane warning 0.22259936:Tornado warning BoostingTermQuery results: 0.7870075:Hurricane warning 0.7870075:Tornado warning 0.17807949:Warning label maker
Indeed, PayloadTermQuery caused the two bulletins (Hurricane warning and Tornado warning) to get much higher scores, bringing them to the top of the results!
Note that the payloads package also includes PayloadNearQuery, which is just like SpanNearQuery except it invokes Similarity.scorePayload just like PayloadTermQuery. In fact, all of the SpanQuery classes have access to payloads, which we describe next.
6.5.3. Payloads and SpanQuery
Although using PayloadTermQuery and PayloadNearQuery is the simplest way to use payloads to alter scoring of documents, all of the SpanQuery classes allow expert access to the payloads that occur within each matching span returned by the getSpans method. At this point, none of the SpanQuery classes, besides SpanTermQuery and SpanNearQuery, have subclasses that make use of the payloads. It’s up to you to subclass a SpanQuery class and override the getSpans method if you’d like to filter documents that match based on payload, or override the SpanScorer class to provide custom scoring based on the payloads contained within each matched span. These are advanced use cases, and only a few users have ventured into this territory, so your best bet for inspiration is to spend some quality time on Lucene’s users list.
The final exposure of payloads in Lucene’s APIs is TermPositions.
6.5.4. Retrieving payloads via TermPositions
The final Lucene API that has been extended with payloads is the TermPositions iterator. This is an advanced internal API that allows you to step through the documents containing a specific term, retrieving each document that matched along with all positions, as well as their payload, of that term’s occurrences in the document. TermPositions has these added methods:
boolean isPayloadAvailable() int getPayloadLength() byte[] getPayload(byte[] data, int offset)
Note that once you’ve called getPayload() you can’t call it again until you’ve advanced to the next position by calling nextPosition(). Each payload can be retrieved only once.
Payloads are still under active development and exploration, in order to provide more core support to make use of payloads for either result filtering or custom scoring. Until the core support is fully fleshed out, you’ll need to use the extension points described here to take advantage of this powerful feature. And stay tuned on the user’s list!
6.6. Summary
Lucene offers developers extreme flexibility in searching capabilities, so much so that this is our third (and final!) chapter covering search. Custom sorting is useful when the built-in sorting by relevance or field values isn’t sufficient. Custom Collector implementations let you efficiently do what you want with each matched document as it’s found, while custom Filters allow you to pull in any external information to construct a filter.
In this chapter, you saw that by extending QueryParser, you can refine how it constructs queries, in order to prevent certain kinds of queries or alter how each Query is constructed. We also showed you how the advanced payloads functionality can be used for refined control over which terms in a document are more important than others, based on their positions.
Equipped with the searching features from this chapter and chapters 3 and 5, you have more than enough power and flexibility to integrate Lucene searching into your applications. Our next chapter explains how to extract text from diverse document formats using the Apache Tika project.