
In our experiment, we will use our custom machine instead of Amazon EC2. However, you can achieve the same result on any server with GPUs. In this section, we will use two Titan X GPUs with a batch size of 32 on each GPU. That way, we can compute up to 64 videos in one step, instead of 32 videos in a single GPU configuration.
Now, let's create a new Python file named train_multi.py in the scripts package. In this file, add the following code to define some parameters:
import tensorflow as tf import os import sys from datetime import datetime from tensorflow.python.ops import data_flow_ops import nets import models from utils import lines_from_file from datasets import sample_videos, input_pipeline # Dataset num_frames = 10 train_folder = "/home/aiteam/quan/datasets/ucf101/train/" train_txt = "/home/aiteam/quan/datasets/ucf101/train.txt" # Learning rate initial_learning_rate = 0.001 decay_steps = 1000 decay_rate = 0.7 # Training num_gpu = 2 image_size = 112 batch_size = 32 * num_gpu num_epochs = 20 epoch_size = 28747 train_enqueue_steps = 50 save_steps = 200 # Number of steps to perform saving checkpoints test_steps = 20 # Number of times to test for test accuracy start_test_step = 50 max_checkpoints_to_keep = 2 save_dir = "/home/aiteam/quan/checkpoints/ucf101"
These parameters are the same as in the previous train.py file, except batch_size. In this experiment, we will use the data parallelism strategy to train with multiple GPUs. Therefore, instead of using 32 for the batch size, we will use a batch size of 64. Then, we will split the batch into two parts; each will be processed by a GPU. After that, we will combine the gradients from the two GPUs to update the weights and biases of the network.
Next, we will use the same operations as before, as follows:
train_data_reader = lines_from_file(train_txt, repeat=True) image_paths_placeholder = tf.placeholder(tf.string, shape=(None,
num_frames), name='image_paths') labels_placeholder = tf.placeholder(tf.int64, shape=(None,),
name='labels') train_input_queue =
data_flow_ops.RandomShuffleQueue(capacity=10000,
min_after_dequeue=batch_size, dtypes= [tf.string, tf.int64], shapes= [(num_frames,), ()]) train_enqueue_op =
train_input_queue.enqueue_many([image_paths_placeholder,
labels_placeholder]) frames_batch, labels_batch = input_pipeline(train_input_queue,
batch_size=batch_size, image_size=image_size) global_step = tf.Variable(0, trainable=False) learning_rate = models.get_learning_rate(global_step,
initial_learning_rate, decay_steps, decay_rate) ``` Now, instead of creating a training operation with `models.train`,
we will create a optimizer and compute gradients in each GPU. ``` optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate) total_gradients = [] frames_batch_split = tf.split(frames_batch, num_gpu) labels_batch_split = tf.split(labels_batch, num_gpu) for i in range(num_gpu): with tf.device('/gpu:%d' % i): with tf.variable_scope(tf.get_variable_scope(), reuse=(i >
0)): logits_split, _ = nets.inference(frames_batch_split[i],
is_training=True) labels_split = labels_batch_split[i] total_loss, cross_entropy_loss, reg_loss =
models.compute_loss(logits_split, labels_split) grads = optimizer.compute_gradients(total_loss) total_gradients.append(grads) tf.get_variable_scope().reuse_variables() with tf.device('/cpu:0'): gradients = models.average_gradients(total_gradients) train_op = optimizer.apply_gradients(gradients, global_step) train_accuracy = models.compute_accuracy(logits_split,
labels_split)
The gradients will be computed on each GPU and added to a list named total_gradients. The final gradients will be computed on the CPU using average_gradients, which we will create shortly. Then, the training operation will be created by calling apply_gradients on the optimizer.
Now, let's add the following function to the models.py file in the root folder to compute the average_gradient:
def average_gradients(gradients):
average_grads = []
for grad_and_vars in zip(*gradients):
grads = []
for g, _ in grad_and_vars:
grads.append(tf.expand_dims(g, 0))
grad = tf.concat(grads, 0)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
Now, back in the train_multi.py file, we will create the saver and summaries operation to save the checkpoints and summaries, like before:
tf.summary.scalar("learning_rate", learning_rate)
tf.summary.scalar("train/accuracy", train_accuracy)
tf.summary.scalar("train/total_loss", total_loss)
tf.summary.scalar("train/cross_entropy_loss", cross_entropy_loss)
tf.summary.scalar("train/regularization_loss", reg_loss)
summary_op = tf.summary.merge_all()
saver = tf.train.Saver(max_to_keep=max_checkpoints_to_keep)
time_stamp = datetime.now().strftime("multi_%Y-%m-%d_%H-%M-%S")
checkpoints_dir = os.path.join(save_dir, time_stamp)
summary_dir = os.path.join(checkpoints_dir, "summaries")
train_writer = tf.summary.FileWriter(summary_dir, flush_secs=10)
if not os.path.exists(save_dir):
os.mkdir(save_dir)
if not os.path.exists(checkpoints_dir):
os.mkdir(checkpoints_dir)
if not os.path.exists(summary_dir):
os.mkdir(summary_dir)
Finally, let's add the training loop to train the network:
config = tf.ConfigProto(allow_soft_placement=True)
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
coords = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coords)
sess.run(tf.global_variables_initializer())
num_batches = int(epoch_size / batch_size)
for i_epoch in range(num_epochs):
for i_batch in range(num_batches):
# Prefetch some data into queue
if i_batch % train_enqueue_steps == 0:
num_samples = batch_size * (train_enqueue_steps + 1)
image_paths, labels = sample_videos(train_data_reader,
root_folder=train_folder,
num_samples=num_samples, num_frames=num_frames)
print("
Epoch {} Batch {} Enqueue {}
videos".format(i_epoch, i_batch, num_samples))
sess.run(train_enqueue_op, feed_dict={
image_paths_placeholder: image_paths,
labels_placeholder: labels
})
if (i_batch + 1) >= start_test_step and (i_batch + 1) %
test_steps == 0:
_, lr_val, loss_val, ce_loss_val, reg_loss_val,
summary_val, global_step_val, train_acc_val = sess.run([
train_op, learning_rate, total_loss,
cross_entropy_loss, reg_loss,
summary_op, global_step, train_accuracy
])
train_writer.add_summary(summary_val,
global_step=global_step_val)
print("
Epochs {}, Batch {} Step {}: Learning Rate {}
Loss {} CE Loss {} Reg Loss {} Train Accuracy {}".format(
i_epoch, i_batch, global_step_val, lr_val, loss_val,
ce_loss_val, reg_loss_val, train_acc_val
))
else:
_ = sess.run([train_op])
sys.stdout.write(".")
sys.stdout.flush()
if (i_batch + 1) > 0 and (i_batch + 1) % save_steps == 0:
saved_file = saver.save(sess,
os.path.join(checkpoints_dir,
'model.ckpt'),
global_step=global_step)
print("Save steps: Save to file %s " % saved_file)
coords.request_stop()
coords.join(threads)
The training loop is similar to the previous, except that we have added the allow_soft_placement=True option to the session configuration. This option will allow TensorFlow to change the placement of variables, if necessary.
Now we can run the training scripts like before:
python scripts/train_multi.py
After a few hours of training, we can look at the TensorBoard to compare the results:
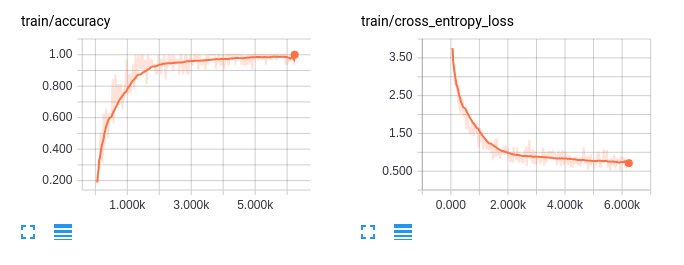
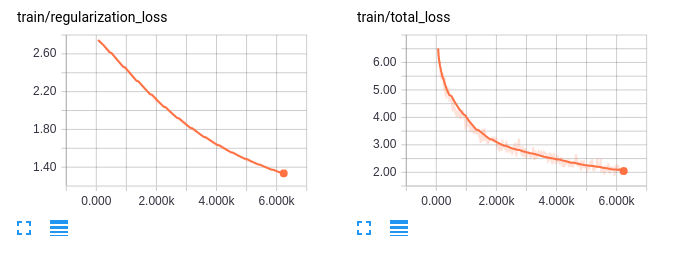
Figure 04—Plot on Tensorboard of multiple GPUs training process
As you can see, the training on multiple GPUs achieves 100% accuracy after about 6,000 steps in about four hours on our computer. This almost reduces the training time by half.
Now, let's see how the two training strategies compare:
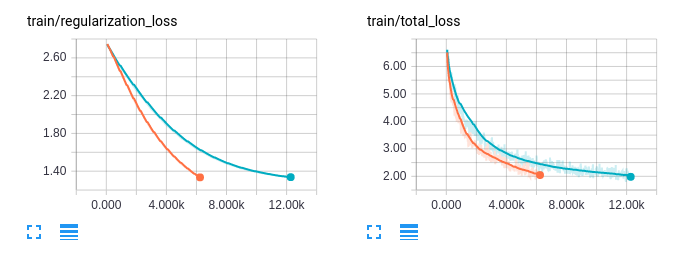

Figure 05—Plot on TensorBoard with single and multiple GPUs compared side by side
The orange line is the multiple GPUs result and the blue line is the single GPU result. We can see that the multiple GPUs setup can achieve better results sooner than the single GPU. The different is not very large. However, we can achieve faster training with more and more GPUs. On the P1 instance on Amazon EC2, there are even eight and 16 GPUs. However, the benefit of training on multiple GPUs will be better if we train on large-scale datasets such as ActivityNet or Sports 1M, as the single GPU will take a very long time to converge.
In the next section, we will take a quick look at another Amazon Service, Mechanical Turk.