
The crux of our effort will be the training, which is shown in the second file we encountered earlier—translate.py. The prepare_wmt_dataset function we reviewed earlier is, of course, the starting point as it creates our two datasets and tokenizes them into nice clean numbers.
The training starts as follows:
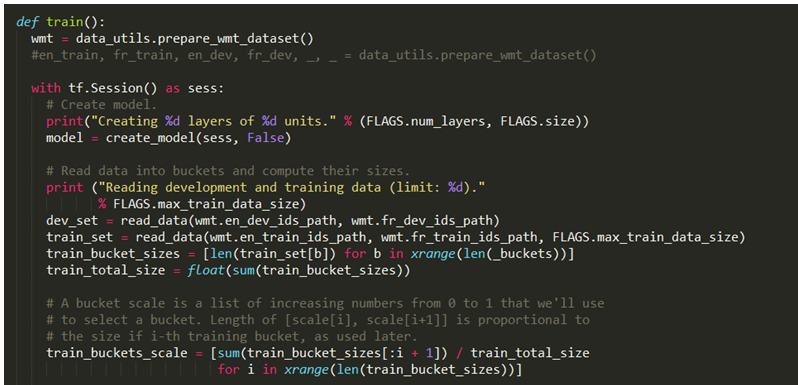
After preparing the data, we will create a TensorFlow session, as usual, and construct our model. We'll get to the model later; for now, let's look at our preparation and training loop.
We will define a dev set and a training set later, but for now, we will define a scale that is a floating point score ranging from 0 to 1. Nothing complex here; the real work comes in the following training loop. This is very different from what we've done in previous chapters, so close attention is required.
Our main training loop is seeking to minimize our error. There are two key statements. Here's the first one:
encoder_inputs, decoder_inputs, target_weights =
model.get_batch(train_set, bucket_id)
And, the second key is as follows:
_, step_loss, _ = model.step(sess, encoder_inputs, decoder_inputs,
target_weights, bucket_id, False)
The get_batch function is essentially used to convert the two sequences into batch-major vectors and associated weights. These are then used on the model step, which returns our loss.
We don't deal with the loss though, we will use perplexity, which is e raised to the power of the loss:

At every X steps, we will save our progress using previous_losses.append(loss), which is important because we will compare our current batch's loss to previous losses. When losses start going up, we will reduce our learning rate using:
sess.run(model.learning_rate_decay_op), and evaluate the loss on our dev_set, much like we used our validation set in earlier chapters:

We will get the following output when we run it:
put_count=2530 evicted_count=2000 eviction_rate=0.790514 and
unsatisfied allocation rate=0 global step 200 learning rate 0.5000 step-time 0.94 perplexity
1625.06 eval: bucket 0 perplexity 700.69 eval: bucket 1 perplexity 433.03 eval: bucket 2 perplexity 401.39 eval: bucket 3 perplexity 312.34 global step 400 learning rate 0.5000 step-time 0.91 perplexity
384.01 eval: bucket 0 perplexity 124.89 eval: bucket 1 perplexity 176.36 eval: bucket 2 perplexity 207.67 eval: bucket 3 perplexity 239.19 global step 600 learning rate 0.5000 step-time 0.87 perplexity
266.71 eval: bucket 0 perplexity 75.80 eval: bucket 1 perplexity 135.31 eval: bucket 2 perplexity 167.71 eval: bucket 3 perplexity 188.42 global step 800 learning rate 0.5000 step-time 0.92 perplexity
235.76 eval: bucket 0 perplexity 107.33 eval: bucket 1 perplexity 159.91 eval: bucket 2 perplexity 177.93 eval: bucket 3 perplexity 263.84
We will see outputs at every 200 steps. This is one of about a dozen settings we're using, which we defined at the top of the file:
tf.app.flags.DEFINE_float("learning_rate"", 0.5, ""Learning
rate."")
tf.app.flags.DEFINE_float("learning_rate_decay_factor"", 0.99,
"Learning rate decays by this much."")
tf.app.flags.DEFINE_float("max_gradient_norm"", 5.0,
"Clip gradients to this norm."")
tf.app.flags.DEFINE_integer("batch_size"", 64,
"Batch size to use during training."")
tf.app.flags.DEFINE_integer("en_vocab_size"", 40000, ""Size ...."")
tf.app.flags.DEFINE_integer("fr_vocab_size"", 40000, ""Size
of...."")
tf.app.flags.DEFINE_integer("size"", 1024, ""Size of each
model..."")
tf.app.flags.DEFINE_integer("num_layers"", 3, ""#layers in the
model."")tf.app.flags.DEFINE_string("train_dir"",
os.path.realpath(''../../datasets/WMT''), ""Training directory."")
tf.app.flags.DEFINE_integer("max_train_data_size"", 0,
"Limit size of training data "")
tf.app.flags.DEFINE_integer("steps_per_checkpoint"", 200,
"Training steps to do per
checkpoint."")
We will use most of these settings when constructing the model object. That is, the final piece of the puzzle is the model itself, so let's look at that. We'll return to the third and final of the three files in our project—seq2seq_model.py.
Recall how we created the model at the start of the training process after creating the TensorFlow session? Most of the parameters we've defined are used to initialize the following model:
model = seq2seq_model.Seq2SeqModel(
FLAGS.en_vocab_size, FLAGS.fr_vocab_size, _buckets,
FLAGS.size, FLAGS.num_layers, FLAGS.max_gradient_norm,
FLAGS.batch_size,
FLAGS.learning_rate, FLAGS.learning_rate_decay_factor,
forward_only=forward_only)
However, what the initialize is accomplishing is inside seq2seq_model.py, so let's jump to that.
You will find that the model is enormous, which is why we won't explain line by line but instead chunk by chunk.
The first section is the initialization of the model, demonstrated by the following two figures:

The model starts with an initialization, which sets off the required parameters. We'll skip the setting of these parameters as we're already familiar with them—we initialized these parameters ourselves before the training, by just passing the values into the model construction statement, and they are finally passed into internal variables via self.xyz assignments.
Recall how we passed in the size of each model layer (size=1024) and the number of layers (3). These are pretty important as we construct the weights and biases (proj_w and proj_b). The weights are A x B where A is the layer size and B is the vocabulary size of the target language. The biases are just passed based on the size of the target vocabulary.
Finally, the weights and biases from our output_project tuple - output_projection = (w, b)- and use the transposed weights and biases to form our softmax_loss_function, which we'll use over and over to gauge performance:

The next section is the step function, which is shown in the following figure. The first half is just error checking, so we'll skip through it. Most interesting is the construction of the output feed using stochastic gradient descent:

The final section of the model is the get_batch function, which is shown in the following figure. We will explain the individual parts with inline comments:

When we run this, we can get a perfect training run, as follows:
global step 200 learning rate 0.5000 step-time 0.94 perplexity
1625.06 eval: bucket 0 perplexity 700.69 eval: bucket 1 perplexity 433.03 eval: bucket 2 perplexity 401.39 eval: bucket 3 perplexity 312.34 ...
Alternatively, we may find steps where we have reduced our learning rate after consistent increases in losses. Either way, we will keep testing on our development set until our accuracy increases.