
Ideally, we will want the entire process automated. This way, we can easily run the process end to end on any computer we use without having to carry around ancillary assets. This will be important later, as we will often develop on one computer (our development machine) and deploy on a different machine (our production server).
I have already written the code for this chapter, as well as all the other chapters; it is available at https://github.com/mlwithtf/MLwithTF. Our approach will be to rewrite it together while understanding it. Some straightforward parts, such as this, may be skipped. I recommend forking the repository and cloning a local copy for your projects:
cd ~/workdir git clone https://github.com/mlwithtf/MLwithTF cd chapter_02
The code for this specific section is available at— https://github.com/mlwithtf/mlwithtf/blob/master/chapter_02/download.py.
Preparing the dataset is an important part of the training process. Before we go deeper into the code, we will run download.py to automatically download and prepare the dataset:
python download.py
The result will look like this:
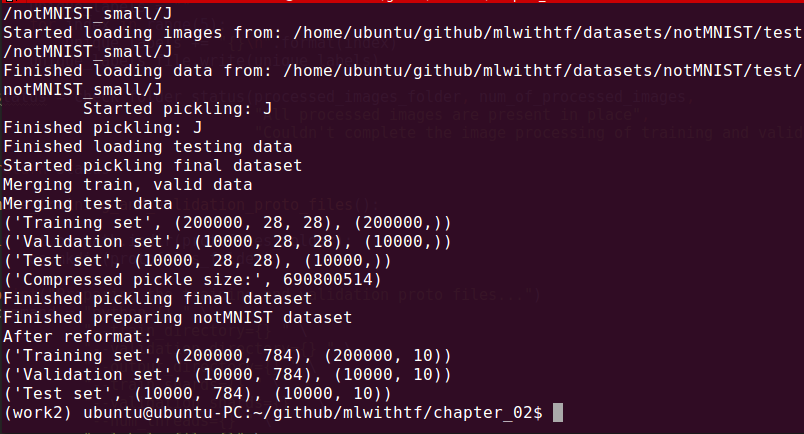
Now, we will take a look at several functions that are used in download.py. You can find the code in this file:
https://github.com/mlwithtf/mlwithtf/blob/master/data_utils.py
The following downloadFile function will automatically download the file and validate it against an expected file size:
from __future__ import print_function
import os
from six.moves.urllib.request import urlretrieve
import datetime
def downloadFile(fileURL, expected_size):
timeStampedDir=datetime.datetime.now()
.strftime("%Y.%m.%d_%I.%M.%S")
os.makedirs(timeStampedDir)
fileNameLocal = timeStampedDir + "/" +
fileURL.split('/')[-1]
print ('Attempting to download ' + fileURL)
print ('File will be stored in ' + fileNameLocal)
filename, _ = urlretrieve(fileURL, fileNameLocal)
statinfo = os.stat(filename)
if statinfo.st_size == expected_size:
print('Found and verified', filename)
else:
raise Exception('Could not get ' + filename)
return filename
The function can be called as follows:
tst_set =
downloadFile('http://yaroslavvb.com/upload/notMNIST/notMNIST_small
.tar.gz', 8458043)
The code to extract the contents is as follows (note that the additional import is required):
import os, sys, tarfile
from os.path import basename
def extractFile(filename):
timeStampedDir=datetime.datetime.now()
.strftime("%Y.%m.%d_%I.%M.%S")
tar = tarfile.open(filename)
sys.stdout.flush()
tar.extractall(timeStampedDir)
tar.close()
return timeStampedDir + "/" + os.listdir(timeStampedDir)[0]
We call the download and extract methods in sequence as follows:
tst_src='http://yaroslavvb.com/upload/notMNIST/notMNIST_small.tar.
gz' tst_set = downloadFile(tst_src, 8458043) print ('Test set stored in: ' + tst_set) tst_files = extractFile(tst_set) print ('Test file set stored in: ' + tst_files)