
Perhaps the simplest way to get started with understanding programming for Hadoop is a simple word count functionality on a fairly large electronic book. The map program will read in every line of the text separated by a space or tab and return a key-value pair, which is by default assigned to a count of 1. The reduce program will read in all key-value pairs from the map program and sum up the number of similar words. Hadoop will produce an output file that contains a list of words in the book and the number of times the words have appeared.
Project Gutenberg hosts over 100,000 free e-books in HTML, EPUB, Kindle, and plain-text UTF-8 formats. For our testing with a sample e-book, let's use Ulysses by James Joyce. The link for the plain text UTF-8 file is http://www.gutenberg.org/ebooks/4300.txt.utf-8. Using Firefox or any other web browser available in the CentOS virtual machine, you can download the file from the URL, and save it as pg4300.txt in the Downloads folder of our home directory, at /home/cloudera/Downloads.
Once we have our target e-book downloaded onto our local drive, it is time to copy the e-book data in the Hadoop HDFS file store for processing. In the Terminal, run the following command:
[cloudera@quickstart ~]$ hadoop fs -copyFromLocal /home/cloudera/Downloads/pg4300.txt pg4300.txt
This will copy the e-book to the Hadoop HDFS store with the same filename pg4300.txt.
To ensure that our copy operation is successful, use the hadoop fs –ls command to give us the following output:
[cloudera@quickstart ~]$ hadoop fs -ls Found 1 items -rw-r--r-- 1 cloudera cloudera 1573150 2014-12-05 22:26 pg4300.txt
The Hadoop file store shows that our file has been copied successfully.
We will run the map program in Python on Hadoop. Insert the following code in a file named mapper.py so that we can use this later:
#!/usr/bin/python
import sys
for line in sys.stdin:
for word in line.strip().split():
print "%s %d" % (word, 1)When mapper.py is executed, the interpreter will read in the input buffer that consists of text. All the text will be broken down by empty whitespace characters, and each word will be assigned to a count of 1, separated by a tab character.
A user-friendly text editor in CentOS is gedit. Create a new folder named word_count in your home directory and save the file in /home/cloudera/word_count/mapper.py.
The mapper.py file needs to be recognized as an executable file in Linux. From the Terminal, run the following command:
chmod +x /home/cloudera/word_count/mapper.py
This will ensure that our map program can run without restrictions.
To create our reduce program, paste the following Python code into a text file named reduce.py, and place it in the same folder at /home/cloudera/word_count/ so that we can use this later:
#!/usr/bin/python
import sys
current_word = None
current_count = 1
for line in sys.stdin:
word, count = line.strip().split(' ')
if current_word:
if word == current_word:
current_count += int(count)
else:
print "%s %d" % (current_word, current_count)
current_count = 1
current_word = word
if current_count > 1:
print "%s %d" % (current_word, current_count)The reduce program will read in all the key-value pairs from the map program. The current word and word count from the key-value pair is obtained by stripping off the tab character and comparing it with the previous occurrence of the word. Every similar occurrence increases the word count by one with the end result: printing the word itself and its count separated by the tab character.
Again, the reduce.py file needs to be recognized as an executable file in Linux. From the Terminal, run the following command:
chmod +x /home/cloudera/word_count/reduce.py
This will ensure that our reduce program can run without restrictions.
Before running our map and reduce program on Hadoop, we can run the scripts locally on our machine first to make sure everything works as intended. If we navigate to our word_count folder, we should see the following files:
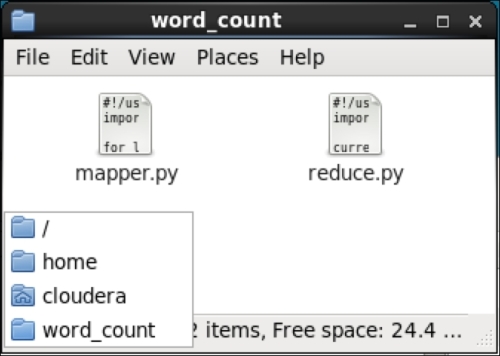
In the Terminal, run the following command on our mapper.py Python file:
[cloudera@quickstart ~]$ echo "foo foo quux labs foo bar quux" | /home/cloudera/word_count/mapper.py
This will produce the following output:
foo 1 foo 1 quux 1 labs 1 foo 1 bar 1 quux 1
As expected, our map program will issue a count of one to every word read into its input buffer, and print the results on each line.
In the Terminal, run the following command on our reduce.py Python file:
[cloudera@quickstart ~]$ echo "foo foo quux labs foo bar quux" | /home/cloudera/word_count/mapper.py | sort -k1,1 | /home/cloudera/word_count/reduce.py
This will produce the following output:
bar 1 foo 3 labs 1 quux 2
Our reduce program sums up the number of similar words encountered by the map program, prints the results on each line, and sorts them in ascending order. It works as intended.
We are now ready to run our MapReduce operation on Hadoop. In the Terminal, type the following command:
hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming- 2.5.0-mr1-cdh5.3.0.jar -file /home/cloudera/word_count/mapper.py -mapper /home/cloudera/word_count/mapper.py -file /home/cloudera/word_count/reduce.py -reducer /home/cloudera/word_count/reduce.py -input pg4300.txt -output pg4300-output
We will use the Hadoop Streaming utility to enable the use of Python scripts as the map and reduce operation. The Java JAR file for the Hadoop Streaming operation is assumed to be hadoop-streaming-2.5.0-mr1-cdh5.3.0.jar and is located in the folder at /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/. On other systems, the Hadoop Streaming utility JAR file may be placed in a different folder or may use a different filename. The provided additional arguments will specify our input files, and the output directory that is required by the Hadoop operation.
Once the Hadoop operation starts, we should get an output similar to the following:
14/12/06 09:39:37 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 14/12/06 09:39:38 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 14/12/06 09:39:38 INFO mapred.FileInputFormat: Total input paths to process : 1 14/12/06 09:39:38 INFO mapreduce.JobSubmitter: number of splits:2 14/12/06 09:39:39 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1417846146061_0002 14/12/06 09:39:39 INFO impl.YarnClientImpl: Submitted application application_1417846146061_0002 14/12/06 09:39:39 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1417846146061_0002/ 14/12/06 09:39:39 INFO mapreduce.Job: Running job: job_1417846146061_0002 14/12/06 09:39:46 INFO mapreduce.Job: Job job_1417846146061_0002 running in uber mode : false 14/12/06 09:39:46 INFO mapreduce.Job: map 0% reduce 0% 14/12/06 09:39:53 INFO mapreduce.Job: map 50% reduce 0%
A number of interesting things begin to happen in Hadoop. It tells us that the MapReduce operation can be tracked at http://quickstart.cloudera:8088/proxy/application_1417846146061_0002/. It also tells us about the progress of the operation, which is currently at 50 percent, since it could take some time to process the whole book.
When the operation is completed, the last few lines of the output contain more information of interest:
File Input Format Counters Bytes Read=1577103 File Output Format Counters Bytes Written=527716 14/12/06 09:40:03 INFO streaming.StreamJob: Output directory: pg4300- output
It tells us that the MapReduce operation has completed successfully, and the results are written to our target output folder at pg4300-output. To verify this, we can take a peek at our HDFS file store:
[cloudera@quickstart ~]$ hadoop fs -ls Found 2 items drwxr-xr-x - cloudera cloudera 0 2014-12-06 09:40 pg4300- output - rw-r--r-- 1 cloudera cloudera 1573150 2014-12-05 22:26 pg4300.txt
We can see that a new folder has been added to our file store, which is one of our target output folders. Let's take a peek at the contents of this output folder:
[cloudera@quickstart ~]$ hadoop fs -ls pg4300-output Found 2 items -rw-r--r-- 1 cloudera cloudera 0 2014-12-06 09:40 pg4300- output/_SUCCESS -rw-r--r-- 1 cloudera cloudera 527716 2014-12-06 09:40 pg4300- output/part-00000
Here, we can see that Hadoop churns out two files in our target folder. The _SUCCESS file is just an empty file that tells us that the MapReduce operation by Hadoop is successful. The second file, part-00000, contains the results of the reduce operation. We can inspect the output file with the fs –cat command:
[cloudera@quickstart ~]$ hadoop fs -cat pg4300-output/part-00000 "Come 1 "Defects,"1 "I1 "Information 1 "J"1 "Plain 2 "Project5 "Right 1 "Viator"1 #4300] 1
The list of words is too long to be printed, but you get the idea.
Besides using the Terminal to navigate to the HDFS file store, another way of having a GUI interface to browse the HDFS file store for troubleshooting or invoking any other regular file operation is through the Hue web interface manager. Hue is also ideal for navigating large amounts of output information, such as viewing the full output of word counts.
Hue can be accessed from any web browser through the URL http://quickstart.cloudera:8888/filebrowser/.
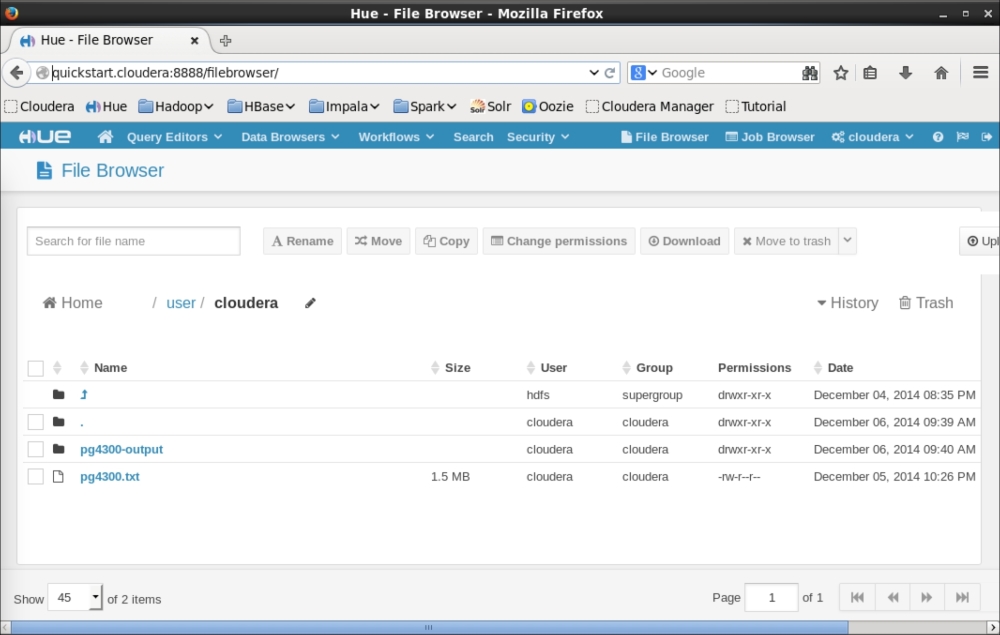
The link to Hue is included in the quick links bookmark of Firefox. The File Browser hyperlink is located in the top-right section of the Hue web page.