
12
Pseudonoise Sequences
Tor Helleseth and P. Vijay Kumar
12.3 The q-ary Sequences with Low Autocorrelation
12.4 Families of Sequences with Low Cross-Correlation
Sequences with High Merit Factor
Sequences with Low Aperiodic Cross-Correlation
12.6 Other Correlation Measures
Low-Correlation Zone Sequences
12.1 Introduction
Pseudonoise sequences (PN sequences), also referred to as pseudorandom sequences, are sequences that are deterministically generated and yet possess some properties that one would expect to find in randomly generated sequences. Applications of PN sequences include signal synchronization, navigation, radar ranging, random number generation, spread-spectrum communications, multipath resolution, cryptography, and signal identification in multiple-access communication systems. The correlation between two sequences {x(t)} and {y(t)} is the complex inner product of the first sequence with a shifted version of the second sequence. The correlation is called (1) an autocorrelation if the two sequences are the same, (2) a cross-correlation if they are distinct, (3) a periodic correlation if the shift is a cyclic shift, (4) an aperiodic correlation if the shift is not cyclic, and (5) a partial-period correlation if the inner product involves only a partial segment of the two sequences. More precise definitions are given subsequently.
Binary m sequences, defined in the next section, are perhaps the best-known family of PN sequences. The balance, run-distribution, and autocorrelation properties of these sequences mimic those of random sequences. It is perhaps the random-like correlation properties of PN sequences that make them most attractive in a communication system, and it is common to refer to any collection of low-correlation sequences as a family of PN sequences.
Section 12.2 begins by discussing m sequences. Thereafter, the discussion continues with a description of sequences satisfying various correlation constraints along the lines of the accompanying self-explanatory figure (Figure 12.1).
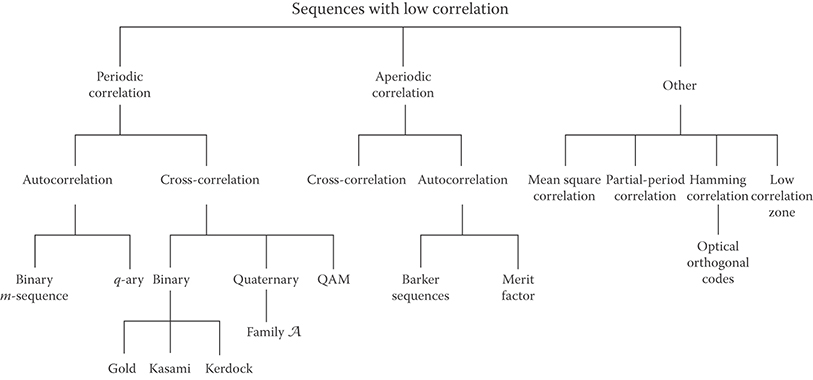
FIGURE 12.1 Overview of pseudonoise sequences.
Expanded tutorial discussions on pseudorandom sequences may be found in [9], [11], [12], [13, Chapter 21], [27], and [28, Chapter 5]. Sequence design related to peak-power control is covered in [19] while some recent advances in the area are covered in [10].
12.2 m Sequences
A binary {0,1} shift-register sequence {s(t)} is a sequence that satisfies a linear recurrence relation of the form
where r ≥ 1 is the degree of the recursion; the coefficients fi belong to the field GF(2) = {0,1} where the leading coefficient fr = 1. Thus, both sequences {a(t)} and {b(t)} appearing in Figure 12.2 are shift-register sequences.

FIGURE 12.2 An example Gold sequence generator. Here, {a(t)} and {b(t)} are m sequences of length 7.
A sequence satisfying a recursion of the form in Equation 12.1 is said to have characteristic polynomial . Thus, {a(t)} and {b(t)} have characteristic polynomials given by f(x) = x3 + x + 1 and f(x) = x3 + x2 + 1, respectively.
Since an r-bit binary shift register can assume a maximum of 2r different states, it follows that every shift-register sequence {s(t)} is eventually periodic with period n ≤ 2r, that is,
for some integer N. In fact, the maximum period of a shift-register sequence is 2r – 1, since a shift register that enters the all-zero state will remain forever in that state. The upper shift register in Figure 12.2 when initialized with starting state 001 generates the periodic sequence {a(t)} given by
of period n = 7. It follows then that this shift register generates sequences of maximal period starting from any nonzero initial state.
An m sequence is simply a binary shift-register sequence having maximal period. For every r ≥ 1, m sequences are known to exist. The periodic autocorrelation function θs of a binary {0,1} sequence {s(t)} of period n is defined by
An m sequence of length n = 2r – 1 has the following attributes: (1) Balance property: in each period of the m sequence there are 2r−1 ones and 2r−1 – 1 zeros. (2) Run property: every nonzero binary s-tuple, s ≤ r occurs 2r−s times, the all-zero s-tuple occurs 2r−s – 1 times. (3) Two-level autocorrelation function:
The first two properties follow immediately from the observation that every nonzero r-tuple occurs precisely once in each period of the m sequence. For the third property, consider the difference sequence {s(t + τ) – s(t)} for τ ≠ 0. This sequence satisfies the same recursion as the m sequence {s(t)} and is clearly not the all-zero sequence. It follows, therefore, that {s(t + τ)–s(t)} ≡ {s(t + τ′)} for some τ′, 0 ≤ τ′ ≤ n–1, that is, a different cyclic shift of the m sequence {s(t)}. The balance property of the sequence {s(t + τ′)} then gives us attribute 3. The m sequence {a(t)} in Equation 12.2 can be seen to have the three listed properties.
If {s(t)} is any sequence of period n and d is an integer, 1 ≤ d ≤ n, then the mapping {s(t)} → {s(dt)} is referred to as a decimation of {s(t)} by the integer d. If {s(t)} is an m sequence of period n = 2r – 1 and d is an integer relatively prime to 2r – 1, then the decimated sequence {s(dt)} clearly also has period n. Interestingly, it turns out that the sequence {s(dt)} is always also an m sequence of the same period. For example, when {a(t)} is the sequence in Equation 12.2, then
and
The sequence {a(3t)} is also an m sequence of period 7, since it satisfies the recursion
of degree r = 3. In fact, {a(3t)} is precisely the sequence labeled {b(t)} in Figure 12.2. The sequence {a(2t)} is simply a cyclically shifted version of {a(t)} itself; this property holds in general. If {s(t)} is any m sequence of period 2r – 1, then {s(2t)} will always be a shifted version of the same m sequence. Clearly, the same is true for decimations by any power of 2.
Starting from an m sequence of period 2r – 1, it turns out that one can generate all m sequences of the same period through decimations by integers d relatively prime to 2r – 1. The set of integers d, 1 ≤ d ≤ 2r – 1 satisfying (d,2r – 1) = 1 forms a group under multiplication modulo 2r – 1, with the powers {2i|0 ≤ i ≤ r – 1} of 2 forming a subgroup of order r. Since decimation by a power of 2 yields a shifted version of the same m sequence, it follows that the number of distinct m sequences of period 2r – 1 is [φ(2r – 1)/r], where φ(n) denotes the number of integers d, 1 ≤ d ≤ n, relatively prime to n. For example, when r = 3, there are just two cyclically distinct m sequences of period 7, and these are precisely the sequences {a(t)} and {b(t)} discussed in the preceding paragraph. The tables provided in [25] can be used to determine the characteristic polynomial of the various m sequences obtainable through the decimation of a single given m sequence. The classical reference on m sequences is [11].
If one obtains a sequence of some large length n by repeatedly tossing an unbiased coin, then such a sequence will very likely satisfy the balance, run, and autocorrelation properties of an m sequence of comparable length. For this reason, it is customary to regard the extent to which a given sequence possesses these properties as a measure of randomness of the sequence. Quite apart from this, in many applications such as signal synchronization and radar ranging, it is desirable to have sequences {s(t)} with low autocorrelation sidelobes, that is, |θs(τ)| is small for τ ≠ 0. Whereas m sequences are a prime example, there exist other methods of constructing binary sequences with low out-of-phase autocorrelation.
Sequences {s(t)} of period n having an autocorrelation function identical to that of an m sequence, that is, having θs satisfying Equation 12.3 correspond to well-studied combinatorial objects known as cyclic Hadamard difference sets. Known infinite families of such difference sets fall into three classes: (1) Singer and Gordon, Mills, and Welch (GMW), (2) quadratic residue, and (3) twin-prime difference sets. These correspond, respectively, to sequences of period n of the form n = 2r – 1, r ≥ 1; n prime; and n = p(p + 2) with both p and p + 2 being prime in the last case. For a detailed treatment of cyclic difference sets, see [3].
Some 40 years after the appearance of the GMW construction, new and interesting cyclic Hadamard difference sets with Singer parameters were discovered in the late 1990s by several research groups. In 1998, Maschietti [21] constructed a new family of cyclic Hadamard difference sets that were based on the theory of hyperovals in finite projective geometry. Around the same time, several difference sets were postulated by No et al. in [23] based on the results of a numeric search and these led to a subsequent postulate by Dobbertin [8]. All postulates have now been confirmed to hold. The difference sets postulated by No et al. and Dobbertin were subsequently shown by Dillon [6] and Dillon and Dobbertin [7] to be examples of difference sets constructed by considering the image set, in a finite field with 2m elements, of one of two mappings
The status at present is that all binary sequences of period 2n – 1 with ideal autocorrelation for n ≤ 10 can now be explained using known constructions.
12.3 The q-ary Sequences with Low Autocorrelation
As defined earlier, the autocorrelation of a binary {0,1} sequence {s(t)} leads to the computation of the inner product of an {–1, +1} sequence {(–1)s(t)} with a cyclically shifted version {(–1)s(t+τ)} of itself. The {–1, +1} sequence is transmitted as a phase shift by either 0° or 180° of a radio-frequency carrier, that is, using binary phase-shift keying (PSK) modulation. If the modulation is q-ary PSK, then one is led to consider sequences {s(t)} with symbols in the set , that is, the set of integers modulo q. The relevant autocorrelation function θs(τ) is now defined by
where n is the period of {s(t)} and ω is a complex primitive qth root of unity such as, for example, . It is possible to construct sequences {s(t)} over whose autocorrelation function satisfies
For obvious reasons, such sequences are said to have an ideal autocorrelation function.
We provide without proof two sample constructions. The sequences in the first construction are given by
Thus, this construction provides sequences with ideal autocorrelation for any period n. Note that the size q of the sequence symbol alphabet equals n when n is odd and 2n when n is even.
The second construction also provides sequences over of period n but requires that n be a perfect square. Let n = r2 and let π be an arbitrary permutation of the elements in the subset {0,1,2,…,(r – 1)} of Let g be an arbitrary function defined on the subset {0,1,2,…,r – 1} of . Then, any sequence of the form
where t = rt1 + t2 with 0 ≤ t1, t2 ≤ r – 1 is the base-r decomposition of t, has an ideal autocorrelation function. When the alphabet size q equals or divides the period n of the sequence, ideal autocorrelation sequences also go by the name generalized bent functions. For details, see [17]. A different approach to the construction of ideal autocorrelation sequences and based on the Zak transform, is described in [1].
12.4 Families of Sequences with Low Cross-Correlation
Given two sequences {s1(t)} and {s2(t)} over of period n, their cross-correlation function θ1,2(τ) is defined by
where ω is as before a primitive qth root of unity. The cross-correlation function is important in code-division multiple-access (CDMA) communication systems. Here, each user is assigned a distinct signature sequence and to minimize interference due to the other users, it is desirable that the signature sequences have pairwise, low values of cross-correlation function. To provide the system in addition with a self-synchronizing capability, it is desirable that the signature sequences have low values of the autocorrelation function as well.
Let be a family of M sequences {si(t)} over , each of period n. Let θi,j(τ) denote the cross-correlation between the ith and jth sequence at shift τ, that is,
The classical goal in sequence design for CDMA systems has been minimization of the parameter
for fixed n and M. It should be noted though that, in practice, because of data modulation the correlations that one runs into are typically of an aperiodic rather than a periodic nature (see Section 12.5). The problem of designing for low aperiodic correlation, however, is a more difficult one. A typical approach, therefore, has been to design based on periodic correlation, and then to analyze the resulting design for its aperiodic correlation properties. Again, in many practical systems, the mean square correlation properties are of greater interest than the worst-case correlation represented by a parameter such as θmax. The mean square correlation is discussed in Section 12.6.2. Low correlation zone sequences, described in Section 12.6.3, are of interest when the CDMA system possesses approximate, but not perfect synchronism.
Bounds on the minimum possible value of θmax for given period n, family size M, and alphabet size q are available that can be used to judge the merits of a particular sequence design. The most efficient bounds are those due to Welch, Sidelnikov, and Levenshtein; see [13]. In CDMA systems, there is greatest interest in designs in which the parameter θmax is in the range . Accordingly, Table 12.1 uses the Welch, Sidelnikov, and Levenshtein bounds to provide an order-of-magnitude upper bound on the family size M for certain θmax in the cited range.
Practical considerations dictate that q be small. The bit-oriented nature of electronic hardware makes it preferable to have q a power of 2. With this in mind, a description of some efficient sequence families having low auto- and cross-correlation values and alphabet sizes q = 2 and q = 4 are described below. Also included below is a description of a family of low-correlation sequences over the M2-quadrature amplitude modulation (QAM) alphabet for M = 2m as this is an alphabet in common use in present-day communication systems. A discussion on the construction of families of ideal-autocorrelation q-ary sequences with low values of cross-correlation can be found in [1].
TABLE 12.1 Bounds on Family Size M for Given n, θmax
θmax |
Upper Bound on M (q = 2) |
Upper Bound on M (q > 2) |
n/2 |
n |
|
n |
n2/2 |
|
3n2/10 |
n3/2 |
12.4.1 Gold and Kasami Sequences
Given the low autocorrelation sidelobes of an m sequence, it is natural to attempt to construct families of low correlation sequences starting from m sequences. Two of the better known constructions of this type are the families of Gold and Kasami sequences.
Let r be odd and d = 2k + 1, where k, 1 ≤ k ≤ r – 1, is an integer satisfying (k, r) = 1. Let {s(t)} be a cyclic shift of an m sequence of period n = 2r – 1 that satisfies and let be the Gold family of 2r + 1 sequences given by
Then, each sequence in has period 2r – 1 and the maximum-correlation parameter θmax of satisfies
An application of the Sidelnikov bound coupled with the information that θmax must be an odd integer yields that for the Family is as small as it can possibly be. In this sense, Family is an optimal family. We remark that these comments remain true even when d is replaced by the integer d = 22k – 2k + 1 with the conditions on k remaining unchanged. The Gold family remains the best-known family of m sequences having low cross-correlation. Applications include the Navstar Global Positioning System whose signals are based on Gold sequences.
The family of Kasami sequences has a similar description. Let r = 2v and d = 2v + 1. Let {s(t)} be a cyclic shift of an m sequence of period n = 2r – 1 that satisfies , and consider the family of Kasami sequences given by
Then the Kasami family contains 2v sequences of period 2r – 1. It can be shown that in this case
This time an application of the Welch bound and the fact that θmax is an integer shows that the Kasami family is optimal in terms of having the smallest possible value of θmax for given n and M.
12.4.2 Quaternary Sequences
The entries in Table 12.1 suggest that nonbinary (i.e., q > 2) designs may be used for improved performance. A family of quaternary sequences that outperform the Gold and Kasami sequences is now discussed below.
Let f(x) be the characteristic polynomial of a binary m sequence of length 2r – 1 for some integer r. The coefficients of f(x) are either 0 or 1. Now, regard f(x) as a polynomial over and form the product (–1)rf(x)f(–x). This can be seen to be a polynomial in x2. Define the polynomial g(x) of degree r by setting g(x2) = (–1)rf(x)f(–x). Let and consider the set of all quaternary sequences {a(t)} satisfying the recursion for all t.
It turns out that with the exception of the all-zero sequence, all of the sequences generated in this way have period 2r – 1. Thus, the recursion generates a Family A of 2r + 1 cyclically distinct quaternary sequences. Closer study reveals that the maximum correlation parameter θmax of this family satisfies . Thus, in comparison with the family of Gold sequences, the Family offers a lower value of θmax (by a factor of ) for the same family size. In comparison with the set of Kasami sequences, it offers a much larger family size for the same bound on θmax. Family sequences are discussed in [13] and in the references contained therein.
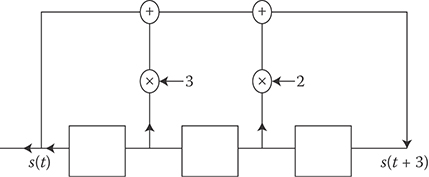
FIGURE 12.3 Shift register that generates family quaternary sequences {s(t)} of period 7.
We illustrate with an example. Let f(x) = x3 + x + 1 be the characteristic polynomial of the m sequence {a(t)} in Equation 12.1. Then, over
so that g(x) = x3 + 2x2 + x + 3. Thus, the sequences in Family are generated by the recursion s(t + 3) + 2s(t + 2) + s(t + 1) + 3s(t) = 0 (mod 4). The corresponding shift register is shown in Figure 12.3.
By varying initial conditions, this shift register can be made to generate nine cyclically distinct sequences, each of length 7. In this case, .
12.4.3 Binary Kerdock Sequences
The Gold and Kasami families of sequences are closely related to binary linear cyclic codes. It is known in coding theory, that there exists nonlinear binary codes the performance of which exceeds that of the best-possible linear code. Surprisingly, some of these examples come from binary codes, which are images of linear quaternary (q = 4) codes under the Gray map: 0 → 00, 1 → 01, 2 → 11, 3 → 10. A prime example of this is the Kerdock code, which has been shown to be the Gray image of a quaternary linear code. Thus, it is not surprising that the Kerdock code yields binary sequences, which we term as Kerdock sequences here, which improve upon the performance of the family of Kasami sequences.
The Kerdock sequences may be constructed as follows: let f(x) be the characteristic polynomial of an m sequence of period 2r – 1, r odd. As before, regarding f(x) as a polynomial over (which happens to have {0, 1} coefficients), let the polynomial g(x) over be defined via g(x2) = –f(x)f(–x). Thus, g(x) is the characteristic polynomial of a Family sequence set of period 2r – 1. Set , and let S be the set of all sequences satisfying the recursion . Then, Family S contains 4r-distinct sequences corresponding to all possible distinct initializations of the shift register.
Let T denote a subset of S of size 2r consisting of those sequences corresponding to initializations of the shift register only using the symbols 0 and 2 in . Then the set S – T of size 4r – 2r contains a set of 2r−1 cyclically distinct sequences each of period 2(2r – 1). Given with a,b ∈ {0,1}, let µ denote the most significant bit (MSB) map µ(x) = b. Let denote the family of 2r−1 binary sequences obtained by applying the map µ to each sequence in . It turns out that each sequence in also has period 2(2r – 1) and that, furthermore, for the Family , . Thus, is a much larger family than the Kasami family, while having almost exactly the same value of θmax.
For example, taking r = 3 and f(x) = x3 + x + 1, we have from the previous Family example that g(x) = x3 + 2x2 + x + 3, so that h(x) = –g(–x) = x3 + 2x2 + x + 1. Applying the MSB map to the head of the shift register, and discarding initializations of the shift register involving only 0’s and 2’s yields a family of four cyclically distinct binary sequences of period 14. Kerdock sequences are discussed in [13] and in the references contained therein.
12.4.3.1 QAM Sequences
For M an even integer, the M2-QAM alphabet is given by
When , this alphabet can alternately be represented in the form:
The connection with suggests the use of quaternary sequences in the construction of low-correlation QAM sequences and an example construction over the 16-QAM alphabet is presented below. Sequences over the QAM alphabet are of interest as QAM is a signaling alphabet that is commonly employed in practice, and additionally, in the context of a CDMA system, a QAM sequence can potentially be made to carry a greater amount of data. Let the 2r sequences in Family of period be partitioned into disjoint pairs . Then, a Family (for canonical QAM family) of 16-QAM sequences may be described as follows:
where
For the Family , it can be shown that the maximum correlation parameter , after normalization, satisfies
Normalization is carried out by dividing each correlation value by the factor 10 because each sequence has energy
when one neglects terms of order , whereas, in comparison, each q-ary sequences of period N has energy N. To convey data, the actual signal transmitted by the user is then given by
where and represent data, so that one period of the sequence carries 4 bits of data. Further details including improved constructions and generalization to the general -QAM constellation alphabet can be found in [2], [5], and [10].
12.5 Aperiodic Correlation
Let {x(t)} and {y(t)} be complex-valued sequences of length (or period) n, not necessarily distinct. Their aperiodic correlation values {ρx,y(τ)| – (n – 1) ≤ τ ≤ n – 1} are given by
where y*(t) denotes the complex conjugate of y(t). When x ≡ y, we will abbreviate and write ρx in place of ρx,y. The sequences described next are perhaps the most famous example of sequences with low-aperiodic autocorrelation values.
12.5.1 Barker Sequences
A binary {–1, +1} sequence {s(t)} of length n is said to be a Barker sequence [3] if the aperiodic autocorrelation values ρs(τ) satisfy |ρs(τ)| ≤ 1 for all τ, –(n – 1) ≤ τ ≤ n – 1. The Barker property is preserved under the following transformations:
as well as under compositions of the preceding transformations. Only the following Barker sequences are known:
where + denotes +1 and − denotes –1, apart from sequences that are generated from these via the transformations already discussed. It is known that if any other Barker sequence exists, it must have length n > 1,898,884, that is a multiple of 4.
An upper bound on the maximum out-of-phase aperiodic autocorrelation of an m sequence can be found in [26].
12.5.2 Sequences with High Merit Factor
The merit factor F of a {–1, +1} sequence {s(t)} is defined by
Since ρs(τ) = ρs(–τ) for 1 ≤ |τ| ≤ n – 1 and ρs(0) = n, the factor F may be regarded as the ratio of the square of the in-phase autocorrelation, to the sum of the squares of the out-of-phase aperiodic autocorrelation values. Thus, the merit factor is one measure of the aperiodic autocorrelation properties of a binary {–1, +1} sequence. It is also closely connected with the signal to self-generated noise ratio of a communication system in which coded pulses are transmitted and received.
Let Fn denote the largest merit factor of any binary {–1, +1} sequence of length n. For example, at length n = 13, the Barker sequence of length 13 has a merit factor F = F13 = 14.08. Assuming a certain ergodicity postulate it was established by Golay that limn→∞ Fn = 12.32. Exhaustive computer searches carried out for n ≤ 40 have revealed the following.
For 1 ≤ n ≤ 40, n ≠ 11,13.
F11 = 12.1, F13 = 14.08, 3.3 ≤ Fn ≤ 9.85.
The value F11 is also achieved by a Barker sequence. From partial searches, for lengths up to 117, the highest known merit factor is between 8 and 9.56; for lengths from 118 to 200, the best-known factor is close to 6. For lengths >200, statistical search methods have failed to yield a sequence having merit factor exceeding 5.
An offset sequence is one in which a fraction θ of the elements of a sequence of length n are chopped off at one end and appended to the other end, that is, an offset sequence is a cyclic shift of the original sequence by nθ symbols. It turns out that the asymptotic merit factor of m sequences is equal to 3 and is independent of the particular offset of the m sequence. There exist offsets of sequences associated with quadratic-residue and twin-prime difference sets that achieve a larger merit factor of 6. Details may be found in [14,15].
In 1999, Kirilusha and Narayanaswamy made the interesting observation that when one started with a sequence from a family with asymptotic merit factor 6 and appended the initial part of the sequence to the sequence, the resultant sequence was found through numerical experiments, to often have a merit factor strictly greater than 6. Following up on this approach, [4] and [16] were able to construct sequence families whose asymptotic merit factor was numerically observed to approach a value greater than 6.34. An analytical proof of the same however, is still lacking. Their constructions were based on cyclic shifts Sr of a Legendre sequence S by a fraction r of the period to which is then appended, a fraction t, 0 < t < 1, of the initial portion of Sr. There is extensive numerical evidence to indicate that for large n, the merit factor of the new sequence is greater than 6.2 when r = 0.25 and t ≈ 0.03 and further that when r ≈ 0.22 and t ≈ 0.06, the merit factor of the new sequence is greater than 6.34. Providing an analytical proof of these properties remains a challenging open problem. There is of course beyond this, the larger open question of determining the largest possible asymptotic merit factor Fn of any binary sequence.
12.5.3 Sequences with Low Aperiodic Cross-Correlation
If {u(t)} and {v(t)} are sequences of length 2n – 1 defined by
and
then
Given a collection
of sequences of length n over , let us define
It is clear from Equation 12.6 how bounds on the periodic correlation parameter θmax can be adapted to give bounds on ρmax. Translation of the Welch bound (mentioned earlier in Section 12.4) gives that for every integer k ≥ 1,
Setting k = 1 in the preceding bound gives
Thus, for fixed M and large n, Welch's bound gives
There exist sequence families which asymptotically achieve [22].
12.6 Other Correlation Measures
12.6.1 Partial-Period Correlation
The partial-period (p-p) correlation between the sequences {u(t)} and {v(t)} is the collection {Δu,v(l,τ,t0)|1 ≤ l ≤ n, 0 ≤ τ ≤ n – 1, 0 ≤ t0 ≤ n – 1} of inner products
where l is the length of the partial period and the sum t + τ is again computed modulo n. In direct-sequence CDMA systems, the pseudorandom signature sequences used by the various users are often very long for reasons of data security. In such situations, to minimize receiver hardware complexity, correlation over a partial period of the signature sequence is often used to demodulate data as well as to achieve synchronization. For this reason, the p-p correlation properties of a sequence are of interest.
Researchers have attempted to determine the moments of the p-p correlation. Here, the main tool is the application of the Pless power-moment identities of coding theory [20]. The identities often allow the first and second p-p correlation moments to be completely determined. For example, this is true in the case of m sequences (the remaining moments turn out to depend upon the specific characteristic polynomial of the m sequence). Further details may be found in [28].
12.6.2 Mean Square Correlation
Frequently in practice, there is a greater interest in the mean-square correlation distribution of a sequence family than in the parameter θmax. Quite often in sequence design, the sequence family is derived from a linear, binary cyclic code of length n by picking a set of cyclically distinct sequences of period n. The families of Gold and Kasami sequences are so constructed. In this case, as pointed out by Massey, the mean square correlation of the family can be shown to be either optimum or close to optimum, under certain easily satisfied conditions, imposed on the minimum distance of the dual code. A similar situation holds even when the sequence family does not come from a linear cyclic code. In this sense, mean square correlation is not a very discriminating measure of the correlation properties of a family of sequences. More details may be found in [13].
12.6.3 Low-Correlation Zone Sequences
For the case when there is approximate, but not perfect synchronism present in a CDMA communication system, there is interest in the design of families of sequences whose auto- and cross-correlations are small for small values of relative time shift [18]. In this context, a low correlation zone (LCZ) sequence family is defined as one in which the nontrivial auto- and cross-correlation values are small (typically 0 or −1) for small values of the time-shift parameter τ, that is,
Four parameters (N,M,L,δ) characterize an LCZ sequence family, namely, the size M of the family, the common period N of each sequence in the family, the time duration L of the low correlation zone, and the upper bound δ on correlation magnitudes within the low correlation zone. The size M of an (N,M,L,δ) LCZ sequence family is upper bounded [29] by
For more details, the reader is referred to the overview in [10] and to the references cited therein.
12.6.4 Optical Orthogonal Codes
Given a pair of {0,1} sequences {s1(t)} and {s2(t)} each having period n, we define the Hamming correlation function θ12(τ), 0 ≤ τ ≤ n – 1, by
Such correlations are of interest, for instance, in optical communication systems where the 1’s and 0’s in a sequence correspond to the presence or absence of pulses of transmitted light.
An (n,w,λ) optical orthogonal code (OOC) is a Family , of M{0,1} sequences of period n, constant Hamming weight w, where w is an integer lying between 1 and n – 1 satisfying θij(τ) ≤ λ whenever either i ≠ j or τ ≠ 0.
Note that the Hamming distance da,b between a period of the corresponding codewords {a(t)}, {b(t)}, 0 ≤ t ≤ n – 1 in an (n,w,λ) OOC having Hamming correlation ρ, 0 ≤ ρ ≤ λ, is given by da,b = 2(w – ρ), and, thus, OOCs are closely related to constant-weight error correcting codes. Given an (n,w,λ) OOC, by enlarging the OOC to include every cyclic shift of each sequence in the code, one obtains a constant-weight, minimum-distance dmin ≥ 2(w – λ) code. Conversely, given a constant-weight cyclic code of length n, weight w, and minimum distance dmin, one can derive an (n,w,λ) OOC code with λ ≤ w – dmin/2 by partitioning the code into cyclic equivalence classes and then picking precisely one representative from each equivalence class of size n.
By making use of this connection, one can derive bounds on the size of an OOC from known bounds on the size of constant-weight codes. The bound given next follows directly from the Johnson bound for constant weight codes [20]. The number M(n,w,λ) of codewords in a (n,w,λ) OOC satisfies
An OOC code that achieves the Johnson bound is said to be optimal. A family of OOCs indexed by the parameter n and arising from a common construction is said to be asymptotically optimum if
Constructions for OOCs are available for the cases when λ = 1 and λ = 2. For larger values of λ, there exist constructions which are asymptotically optimum. Further details may be found in [13].
2-D OOC: The OOC discussed above correspond to sequences of pulses of a single beam of monochromatic light. The advent of wavelength-division multiplexing has made it possible to design low-correlation optical signals that are spread across both wavelength and time. While such signals are often called wavelength-time hopping codes or multiple-wavelength codes, we will refer to these codes as two-dimensional OOCs (2-D OOCs). A 2-D (Λ × T,ω,κ) OOC C is a family of {0,1} (Λ × T) arrays of constant Hamming weight ω. Every pair {A,B} of arrays in C is required to satisfy
where either A ≠ B or τ ≠ 0. We will refer to κ as the maximum collision parameter (MCP) if κ ≥ 0 is the smallest integer for which Equation 12.10 holds. Note that asynchronism is present here only along the time axis. As in the 1-D case, in a 2-D optical CDMA system, each user is assigned a distinct 2-D OOC and when the particular user wishes to send either a 1 or a 0, the user either transmits or else does not transmit the user's code sequence, respectively. Given a parameter set, let φ(Λ × T,ω,κ) denote the largest possible cardinality of a 2-D OOC having these parameters. The analog of the Johnson bound for 2-D OOC is given by
The parameters n in the case of a 1-D OOC and the parameter T in the case of a 2-D OOC represent the multiplicative factor by which the pulse rate in the optical communication system has to be raised. Comparing Equation 12.11 with Equation 12.9, we see that for the same family size φ, the value of T in Equation 12.11 is significantly smaller than the value of n in Equation 12.9 and this is an important advantage enjoyed by a 2-D OOC. For details and constructions of 2-D OOC, the reader is referred to [24] and [30].
References
1. An M., Brodzik A.K., and Tolimieri R. Ideal Sequence Design in Time-Frequency Space: Applications to Radar, Sonar and Communication Systems, Birkhauser, Boston, 2009.
2. Anand M. and Kumar P.V. Low-correlation sequences over the QAM constellation, IEEE Transactions on Information Theory, IT-54, 791–810, 2008.
3. Baumert L.D. Cyclic Difference Sets, Lecture Notes in Mathematics, Vol. 182, Springer–Verlag, New York, 1971.
4. Borwein P., Choi K.-K.S., and Jedwab J. Binary sequences with merit factor greater than 6.34, IEEE Transactions on Information Theory, IT-50, 3234–3249, 2004.
5. Boztas S. CDMA over QAM and other arbitrary energy constellations, IEEE International Conference on Communication Systems, 2, 21.7.1–21.7.5, 1996.
6. Dillon J. Multiplicative difference sets via additive characters, Designs Codes and Cryptography, 17, 225–235, 1999.
7. Dillon J. and Dobbertin H. New cyclic difference sets with Singer parameters, Finite Fields and Their Applications, 10, 342–389, 2004.
8. Dobbertin H. Kasami power functions, permutation polynomials and cyclic difference sets, In Difference Sets, Sequences and Their Correlation Properties (eds.) A. Pott pp. 133–158, The Netherlands, Kluwer Academic Publishers, 1999.
9. Fan P. and Darnell M. Sequence Design for Communications Applications, John Wiley & Sons, London, 1996.
10. Garg G., Helleseth T., and Kumar P.V. Recent advances in low-correlation sequences, In New Directions in Wireless Communications Research (ed.) V. Tarokh, Springer, Berlin, 2009.
11. Golomb S.W. Shift Register Sequences, Aegean Park Press, San Francisco, CA, 1982.
12. Golomb S.W. and Gong G. Signal Design for Good Correlation: For Wireless Communication, Cryptography, and Radar, Cambridge University Press, New York, 2005.
13. Helleseth T. and Kumar P.V. Sequences with low correlation. In Handbook of Coding Theory (eds.) V.S. Pless and W.C. Huffman, Elsevier Science Publishers, Amsterdam, 1998.
14. Jedwab J. A survey of the merit factor problem for binary sequences, Proceedings of Sequences and Their Applications, 3486, 30–55, 2004.
15. Jensen J.M., Jensen H.E., and Høholdt T. The merit factor of binary sequences related to difference sets, IEEE Transactions on Information Theory, IT-37, 617–626, 1991.
16. Kristiansen R.A. and Parker M.G. Binary sequences with merit factor >6.3, IEEE Transactions on Information Theory, IT-50, 3385–3389, 2004.
17. Kumar P.V., Scholtz R.A., and Welch L.R. Generalized bent functions and their properties, Journal of Combinatorial Theory Series A., 40, 90–107, 1985.
18. Long B., Zhang P., and Hu J. A generalized QS-CDMA system and the design of new spreading codes, IEEE Transactions on Vehicular Technology, 47, 1268–1275, 1998.
19. Litsyn S. Peak Power Control in Multicarrier Communications, Cambridge University Press, New York, 2007.
20. MacWilliams F.J. and Sloane N.J.A. The Theory of Error-Correcting Codes, North-Holland, Amsterdam, 1977.
21. Maschietti A. Difference sets and hyperovals, Designs, Codes and Cryptography, 14, 89–98, 1998.
22. Mow W.H. On McEliece's open problem on minimax aperiodic correlation, Proceedings of the IEEE International Symposium on Information Theory, 75, 1994.
23. No J.-S., Golomb S.W., Gong G., Lee H.-K., and Gaal P. Binary pseudorandom sequences of period 2n – 1 with ideal autocorrelation properties, IEEE Transactions on Information Theory, IT-44, 814–817, 1998.
24. Omrani R. and Kumar P.V. Improved constructions and bounds for 2-D optical orthogonal codes, Proceedings of the IEEE International Symposium on Information Theory, 127–131, 2005.
25. Peterson W.W. and Weldon E.J., Jr. Error-Correcting Codes, 2nd ed., MIT Press, Cambridge, MA, 1972.
26. Sarwate D.V. An upper bound on the aperiodic autocorrelation function for a maximal-length sequence. IEEE Transactions on Information Theory, IT-30, 685–687, 1984.
27. Sarwate D.V. and Pursley M.B. Crosscorrelation properties of pseudorandom and related sequences, Proceedings of the IEEE, 68, 593–619, 1980.
28. Simon M.K., Omura J.K., Scholtz R.A., and Levitt B.K. Spread Spectrum Communications Handbook, revised ed., McGraw Hill, New York, 1994.
29. Tang X.H., Fan P.Z., and Matsufuji S. Lower bounds on correlation of spreading sequence set with low or zero correlation zone, Electronics Letters, 36, 551–552, 2000.
30. Yang G.C. and Kwong W.C. Two-dimensional spatial signature patterns, IEEE Transactions on Communications, 44, 184–191, 1996.
Further Reading
A more in-depth treatment of pseudonoise sequences may be found in [9], [11], [12], [13, Chapter 21], [27], and [28, Chapter 5]. Sequence design related to peak-power control of transmitted signal energy, not covered here, is covered in [19]. Recent advances in low-correlation sequence design, relating to new cyclic difference sets, sequences with high merit factor, sequences over a QAM alphabet, and low-correlation zone sequences appear in [10].