
28
Speech Coding for Wireless Communications
Jerry D. Gibson
28.2 Basic Issues in Speech Coding
SNR and Bandwidth Scalable Methods
28.5 Next-Generation Standards
28.6 Outstanding Issues and Future Challenges
Appendix: Speech Quality and Intelligibility
28.1 Introduction
The goal of speech coding is to represent speech in digital form with as few bits as possible while maintaining the intelligibility and quality required for the particular application. Interest in speech coding is motivated by the evolution to digital communications and the requirement to minimize bit rate, and hence, conserve bandwidth. There is always a trade-off between lowering the bit rate and maintaining the delivered voice quality and intelligibility; however, depending on the application, many other constraints must also be considered, such as complexity, delay, and performance with bit errors or packet losses [1].
Speech coding is fundamental to the operation of the public switched telephone network (PSTN), videoconferencing systems, digital cellular communications, and voice over Internet protocol (VoIP) applications. In particular, efficient, high-quality speech codecs were (and are) essential to the evolution of cellular voice communications from analog to digital systems and for the development and widespread use of VoIP for voice communications.
In this chapter, we discuss the technologies and issues involved in speech coding, with particular applications to digital cellular and VoIP for wireless access points. Interestingly, some quite different issues are involved in these two systems, and in fact, for the most part, the speech codecs are different.
There was almost an exponential growth of speech coding standards in the 1990s for a wide range of networks and applications, including the wired PSTN, digital cellular systems, and multimedia streaming over the Internet. We develop the speech codecs used in digital cellular and wireless VoIP applications, and we also discuss the ITU-T standardized speech codecs because of the influence some of the ITU-T codec designs have had on the codecs in wireless systems and because some of these codecs appear in wireless applications. We provide comparisons of the performance, complexity, and coding delay of the several most prominent standards, and we examine key challenges for effective voice communications when the various codecs are employed in communications networks.
We also present the requirements and current capabilities, some projected, of new speech coding standards under development at the time of this writing. We begin the chapter by outlining the basic issues in speech coding, followed by some details on the basic speech coding structures that are widely used.
We use the terms speech coding and voice coding interchangeably in this chapter. Generally, it is desired to reproduce the voice signal, since we are interested in not only knowing what was said but also in being able to identify the speaker.
28.2 Basic Issues in Speech Coding
Speech and audio coding can be classified according to the bandwidth occupied by the input and the reproduced source. Narrowband or telephone bandwidth speech occupies the band from 200 to 3400 Hz, and is the band classically associated with telephone quality speech. In the mid- to late 1980s, a new bandwidth of 50 Hz–7 kHz, called wideband speech, became of interest for videoconferencing applications. High-quality audio is generally taken to cover the range of 20 Hz–20 kHz, and this bandwidth is designated today as fullband. In recent years, quite a few other bandwidths have attracted attention, primarily for audio over the Internet applications, and the bandwidth of 50 Hz–14 kHz, designated as superwideband, has gotten considerable recent attention in standardization activities. The discussions in this chapter address all of these bandwidths of interest, although most of the discussions and standardized codecs for wireless applications have emphasized narrowband and wideband speech.
Given a particular source, the classic trade-off in lossy source compression is rate versus distortion—the higher the rate, the smaller the average distortion in the reproduced signal. Of course, since a higher bit rate implies a greater channel or network bandwidth requirement, the goal is always to minimize the rate required to satisfy the distortion constraint. For speech coding, we are interested in achieving a quality as close to the original speech as possible within the rate, complexity, latency, and any other constraints that might be imposed by the application of interest. Encompassed in the term “quality” are intelligibility, speaker identification, and naturalness. Absolute category rating tests are subjective tests of speech quality and involve listeners assigning a category and rating for each speech utterance according to the classifications, such as, excellent (5), good (4), fair (3), poor (2), and bad (1). The average for each utterance over all listeners is the mean opinion score (MOS) [2]. More details on MOS are given in the Appendix.
Although important, the MOS values obtained by listening to isolated utterances do not capture the dynamics of conversational voice communications in the various network environments. It is intuitive that speech codecs should be tested within the environment and while executing the tasks for which they are designed. Thus, since we are interested in conversational (two-way) voice communications, a more realistic test would be conducted in this scenario. The perceptual evaluation of speech quality (PESQ) method was developed to provide an assessment of speech codec performance in conversational voice communications. The PESQ has been standardized by the ITU-T as P.862 and can be used to generate MOS values for both narrowband and wideband speech [3]. The narrowband PESQ performs fairly well for the situations for which it has been qualified, and the wideband PESQ MOS, while initially not very accurate, has become more reliable in recent years.
Throughout this chapter, we quote available MOS values taken from many different sources for all of the codecs. Since MOS values can vary from test to test and across languages, these values should not be interpreted as an exact indicator of performance. Care has been taken only to present MOS values that are consistent with widely known performance results for each codec. For more details on subjective and objective measures for speech quality assessment, the reader is referred to the Appendix and the references.
Across codecs that achieve roughly the same quality at a specified bit rate, codec complexity can be a distinguishing feature. In standards and in the literature, the number of MIPs (million instructions per second) is often quoted as a broad indicator of implementation complexity, where MIPs numbers generally relate to implementations on digital signal processing (DSP) chips rather than CPUs. Another quantity, called weighted millions of instructions per second (WMOPS), where each operation is assigned a weight based on the number of DSP cycles required to execute the operation is also used. The relationship between MIPS and WMOPS is determined based on the particular DSP. We quote both complexity indicators in this chapter as available in the literature and from other comparisons.
An issue of considerable importance for voice codecs to be employed in conversational applications is the delay associated with the processing at the encoder and the decoder. This is because excessive delay can cause “talk over” and an interruption of the natural flow of the conversation. ITU-T Recommendation G.114 provides specifications for delay when echo is properly controlled [4]. In particular, one-way transmission time (including processing and propagation delay) is categorized as (a) 0–150 ms: acceptable for most user applications; (b) 150–400 ms: acceptable depending upon the transmission time impact; and (c) above 400 ms: unacceptable for general network planning purposes. Figure 28.1 provides a broader view of the estimated impact of delay on user preferences as stated in the ITU-T G.114 standard. From this figure, it is seen that up to 150 ms represents the flat part of the curve, and acceptable delay is sometimes quoted as 200 ms, since delays up to 200 ms fall into the “Users Very Satisfied” category. In spite of the implications of this diagram and the above categorizations, it is generally felt that once the round trip delay is about 300 ms, two-way voice communications is difficult.
When different codecs are used in different but interconnected networks, or when the speech signal must be decoded at network interfaces or switches, the problem of tandem connections of speech codecs can arise. The term “asynchronous tandeming” originally referred to a series connection of speech coders that requires digital to analog conversion followed by resampling and reencoding. Today, and within the context of this chapter, tandeming refers to where the speech samples must be reconstructed and then reencoded by the next codec. Tandem connections of speech codecs can lead to a significant loss in quality, and of course, incur additional delays due to decoding and reencoding. Another possible approach to tandem connections of different speech codecs is to map the parameters of one codec into the parameters of the following codec without reconstructing the speech samples themselves. This is usually referred to as transcoding. Transcoding produces some quality loss and delay as well. Tandem connections of speech codecs are often tested as part of the overall codec performance evaluation process.

FIGURE 28.1 Effect of one-way delay on speech quality (G.114).
In many applications, errors can occur during transmission across networks and through wireless links. Errors can show up as individual bit errors or bursts of bit errors, or with the widespread movement toward IP-based protocols, errors can show up as packet losses. In error-prone environments or during error events, it is imperative that the decoded speech be as little affected as possible. Some speech codecs are designed to be robust to bit errors, but it is more common today that packet loss concealment methods are designed and associated with each speech codec. Depending upon the application, robustness to errors, and/or a good packet loss concealment scheme may be a dominating requirement.
It is by now well known that speech codecs should be tested across a wide variety of speakers, but it is also important to note that speech codecs are tested across many different languages as well. It is difficult to incorporate multiple languages into a design philosophy, but suffice it to say, since the characteristics of spoken languages around the world can be so different, codec designs must be evaluated across a representative set of languages to reveal any shortcomings.
28.3 Speech Coding Methods
The most common approaches to narrowband speech coding today center around two paradigms, namely, waveform-following coders and analysis-by-synthesis methods. Waveform-following coders attempt to reproduce the time domain speech waveform as accurately as possible, while analysis-by-synthesis methods utilize the linear prediction model and a perceptual distortion measure to reproduce only those characteristics of the input speech determined to be most important. Another approach to speech coding breaks the speech into separate frequency bands, called subbands, and then codes these subbands separately, perhaps using a waveform coder or analysis-by-synthesis coding, for reconstruction and recombination at the receiver. Extending the resolution of the frequency domain decomposition leads to transform coding, wherein a transform is performed on a frame of input speech and the resulting transform coefficients are quantized and transmitted to reconstruct the speech from the inverse transform. In this section, we provide some background details for each of these approaches to lay the groundwork for the later developments of speech coding standards based upon these principles. A discussion of the class of speech coders called vocoders or purely parametric coders is not included due to space limitations and their more limited range of applications today.
28.3.1 Waveform Coding
Familiar waveform-following methods are logarithmic pulse code modulation (log-PCM) and adaptive differential pulse code modulation (ADPCM), and both have found widespread applications. Log PCM at 64 kilobits/second (kbps) is the speech codec used in the long-distance PSTN at a rate of 64 kbps and it is the most widely employed codec for VoIP applications. It is a simple coder and it achieves what is called toll quality, which is the standard level of performance against which all other narrowband speech coders are judged. Log PCM uses a nonlinear quantizer to reproduce low-amplitude signals, which are important to speech perception, well. There are two closely related types of log-PCM quantizer used in the world—µ-law, which is used in North America and Japan, and A-law, which is used in Europe, Africa, Australia, and South America. Both achieve toll-quality speech, and in terms of the MOS value, it is usually between 4.0 and 4.5 for log-PCM.
ADPCM operates at 32 kbps or lower, and it achieves performance comparable to log-PCM by using an adaptive linear predictor to remove short-term redundancy in the speech signal before quantization. The most common form of ADPCM uses what is called backward adaptation of the predictors and quantizers to follow the waveform closely. Backward adaptation means that the predictor and quantizer are adapted based upon past reproduced values of the signal that are available at the encoder and decoder. No predictor or quantizer parameters are sent along with the quantized waveform values. By subtracting a predicted value from each input sample, the dynamic range of the signal to be quantized is reduced, and hence, good reproduction of the signal is possible with fewer bits.
28.3.2 Subband and Transform Methods
The process of breaking the input speech into subbands via bandpass filters and coding each band separately is called subband coding. To keep the number of samples to be coded at a minimum, the sampling rate for the signals in each band is reduced by decimation. Of course, since the bandpass filters are not ideal, there is some overlap between adjacent bands and aliasing occurs during decimation. Ignoring the distortion or noise due to compression, quadrature mirror filter (QMF) banks allow the aliasing that occurs during filtering and subsampling at the encoder to be cancelled at the decoder. The codecs used in each band can be PCM, ADPCM, or even an analysis-by-synthesis method. The advantage of subband coding is that each band can be coded differently and that the coding error in each band can be controlled in relation to human perceptual characteristics.
Transform coding methods were first applied to still images but later investigated for speech. The basic principle is that a block of speech samples is operated on by a discrete unitary transform and the resulting transform coefficients are quantized and coded for transmission to the receiver. Low bit rates and good performance can be obtained because more bits can be allocated to the perceptually important coefficients, and for well-designed transforms, many coefficients need not be coded at all, but are simply discarded, and acceptable performance is still achieved.
Although classical transform coding has not had a major impact on narrowband speech coding and subband coding has fallen out of favor in recent years, filter bank and transform methods play a critical role in high-quality audio coding, and several important standards for wideband, superwideband, and fullband speech/audio coding are based upon filter bank and transform methods. Although it is intuitive that subband filtering and discrete transforms are closely related, by the early 1990s, the relationships between filter bank methods and transforms were well understood [5]. Today, the distinction between transforms and filter bank methods is somewhat blurred, and the choice between a filter bank implementation and a transform method may simply be a design choice.
28.3.3 Analysis-by-Synthesis Methods
Analysis-by-synthesis (AbS) methods are a considerable departure from waveform-following techniques and from frequency domain methods as well. The most common and most successful analysis-by-synthesis method is code-excited linear prediction (CELP). In CELP speech coders, a segment of speech (say, 5–10 ms) is synthesized using the linear prediction model along with a long-term redundancy predictor for all possible excitations in what is called a codebook. For each excitation, an error signal is calculated and passed through a perceptual weighting filter. This operation is represented in Figure 28.2a. The excitation that produces the minimum perceptually weighted coding error is selected for use at the decoder as shown in Figure 28.2b. Therefore, the best excitation out of all possible excitations for a given segment of speech is selected by synthesizing all possible representations at the encoder, hence, the name analysis-by-synthesis. The predictor parameters and the excitation codeword are sent to the receiver to decode the speech. It is instructive to contrast the AbS method with waveform coders such as ADPCM where each sample is coded as it arrives at the coder input.
The perceptual weighting is key to obtaining good speech coding performance, and the basic idea is that the coding error is spectrally shaped to fall below the envelope of the input speech across the frequency band of interest. Figure 28.3 illustrates the concept wherein the spectral envelope of a speech segment is shown, along with the coding error spectrum without perceptual weighting (unweighted denoted by short dashes) and the coding error spectrum with perceptual weighting (denoted by long dashes). The perceptually weighted coding error falls below the spectral envelope of the speech across most of the frequency band of interest, just crossing over around 3100 Hz. The coding error is thus masked by the speech signal itself. In contrast, the unweighted error spectrum is above the speech spectral envelope starting at around 1.6 kHz, which produces audible coding distortion for the same bit rate.
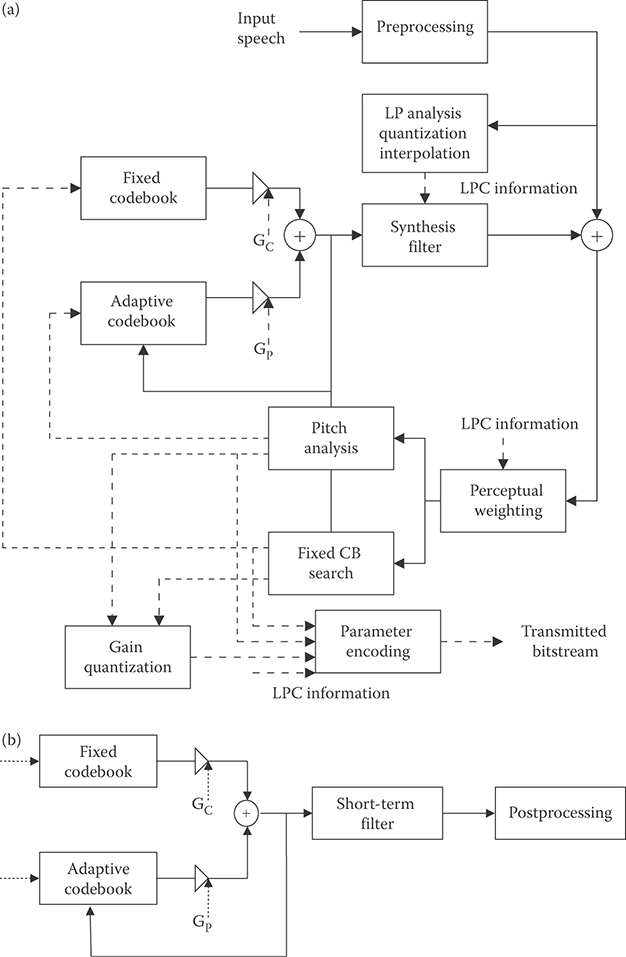
FIGURE 28.2 (a) Encoder for code-excited linear predictive (CELP) coding with an adaptive codebook. (b) CELP decoder with an adaptive codebook and postfiltering.
In recent years, it has become common to use an adaptive codebook structure to model the long-term memory rather than a cascaded long-term predictor. A decoder using the adaptive codebook approach is shown in Figure 28.2b. The analysis-by-synthesis procedure is computationally intensive, and it is fortunate that algebraic codebooks, which have mostly zero values and only a few nonzero pulses, have been discovered and work well for the fixed codebook [6].

FIGURE 28.3 Perceptual weighting of the coding error as a function of frequency.
28.3.4 Postfiltering
Although a perceptual weighting filter is used inside the search loop for the best excitation in the codebook for analysis-by-synthesis methods, there is often still some distortion in the reconstructed speech that is sometimes characterized as “roughness.” This distortion is attributed to reconstruction or coding error as a function of frequency that is too high at regions between formants and between pitch harmonics. Several codecs thus employ a postfilter that operates on the reconstructed speech to deemphasize the coding error between formants and between pitch harmonics. This is shown as “postprocessing” in Figure 28.2b. The general frequency response of the postfilter has the form similar to the perceptual weighting filter with a pitch or long-term postfilter added. There is also a spectral tilt correction since the formant-based postfilter results in an increased low-pass filter effect, and a gain correction term [5,6]. The postfilter is usually optimized for a single-stage encoding (however, not always), so if multiple tandem connections of speech codecs occur, the postfilter can cause a degradation in speech quality.
28.3.5 Variable Rate Coding
For more than 30 years, researchers have been interested in assigning network capacity only when a speaker is “active,” as in TASI, or removing silent periods in speech to reduce the average bit rate. This was successfully accomplished for some digital cellular coders where silence is removed and coded with a short length code and then replaced at the decoder with “comfort noise.” Comfort noise is needed because the background sounds for speech coders are seldom pure silence and inserting pure silence generates unwelcome artifacts at the decoder and can cause the impression that the call is lost. The result, of course, is a variable rate speech coder. Many codecs use voice activity detection to excise nonspeech signals so that nonspeech regions do not need to be coded explicitly. More sophisticated segmentation can also be performed so that different regions can be coded differently. For example, more bits may be allocated to coding strongly voiced segments and fewer allocated to unvoiced speech. Also, speech onset might be coded differently as well.
When used over fixed rate communications links, variable rate coders require the use of jitter buffers and can be sensitive to bit errors. However, packet switched networks reduce these problems and make variable rate coding attractive for packet networks.
28.3.6 SNR and Bandwidth Scalable Methods
SNR or bit rate scalability refers to the idea of coding the speech in stages such that the quality can be increased simply by appending an additional bit stream. For example, speech may be coded using a minimum bit rate stream that provides acceptable quality, often called a core layer, along with one or more incremental enhancement bit streams. When the first enhancement bit stream is combined with the core layer to reconstruct the speech, improved performance is obtained. SNR or bit rate scalable coding is inherently no better than single-stage encoding at the combined rate, so the challenge is to design good SNR scalable codecs that are as close to single-stage encoding as possible. One attraction of SNR scalable coding is that the enhancement bit stream may be added or dropped, depending upon available transmission bit rate. Another option facilitated by SNR scalable coding is that the core bit stream may be subject to error control coding whereas the enhancement bit stream may be left unprotected.
Bandwidth scalable coding is a method wherein speech with a narrower bandwidth is coded as a base layer bit stream, and an enhancement bit stream is produced that encodes frequencies above the base layer bandwidth. Particular applications of interest might be having a base layer bit stream that codes telephone bandwidth speech from 200 to 3400 Hz and enhancement layer bit streams that codes speech in the additional bands, thus incorporating wideband, superwideband, and fullband audio. The goal is to allow flexibility in bit rate and still have a high-quality representation of the speech at the low band and at additional bands when enhancement layers are combined with the base layer.
28.4 Speech Coding Standards
In this section, we describe the relevant details of current and some past standardized speech codecs for digital cellular and packet switched VoIP for wireless access points. We begin the discussion with ITU-T standardized codecs since some of those codecs have served as the basis for cellular codecs, and further since some of these codecs are used for VoIP applications.
28.4.1 ITU-T Standards
Tables 28.1 and 28.2 list some of the narrowband and wideband/fullband voice codecs that have been standardized by the ITU-T over the years, including details concerning the codec technology, transmitted bit rate, performance, complexity, and algorithmic delay. Those shown include G.711, G.726, G.728, G.729, and G.729A for narrowband (telephone bandwidth) speech (200 to 3400 Hz), G.722, G.722.1 [7], G.722.2 [8], and G.718 for wideband speech (50 Hz–7 kHz) [9], and G.719 for fullband audio [10].
G.711 at 64 kbps is the voice codec most often used in the PSTN and in VoIP today. This codec is based on a nonlinear quantization method called log-PCM, which allows low-amplitude speech signal samples to be quantized with the same accuracy as larger amplitude samples. This codec is the benchmark for narrowband toll-quality voice transmission. G.711 is designed with several asynchronous tandems in mind, since it was possible to encounter several analog switches during a long-distance telephone call prior to the mid-1980s. Even eight asynchronous tandems of G.711 with itself has been shown to still maintain a MOS greater than 4.0 when a single encoding is 4.4–4.5.
TABLE 28.1 Comparison of ITU-T Narrowband Speech Codecs
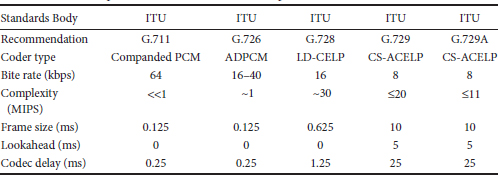
TABLE 28.2 ITU-T Wideband and Fullband Speech Coding Standards
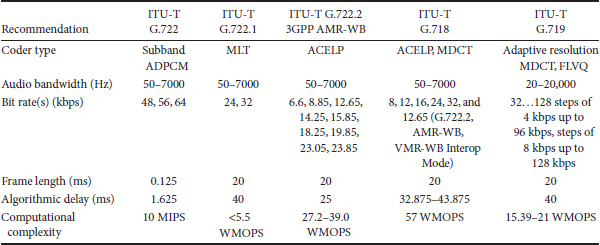
The G.726 and G.728 standards not only were required to perform well for single and multiple encodings, but they were also required to be able to pass voiceband modem signals and to have a low coding delay of less than 5 ms. To achieve the desired bit rate of 8 kbps, the low delay and voiceband modem requirements were removed for G.729. The G.729 codec is an analysis-by-synthesis codec based on algebraic code excited linear prediction (ACELP), and it uses an adaptive codebook to incorporate the long-term pitch periodicity. In addition to a lower complexity version of G.729, called G.729A, there is a higher-rate codec based on G.729, designated G.729E. The G.729 codec structure has been very influential on subsequent voice coding standards for VoIP and digital cellular networks.
Even though we are quite comfortable communicating using telephone bandwidth speech (200–3400 Hz), there is considerable interest in compression methods for wideband speech covering the range of 50 Hz–7 kHz. The primary reasons for the interest in this band are that wideband speech improves intelligibility, naturalness, and speaker identifiability. The first application of wideband speech coding was to videoconferencing, and the first standard, G.722, separated the speech into two subbands and used ADPCM to code each band. The G.722 codec is relatively simple and produces good-quality speech at 64 kbps, and lower-quality speech at the two other possible codec rates of 56 and 48 kbps [6]. The G.722 speech codec is still widely available in the H.324 videoconferencing standard, and it is often provided as an option in VoIP systems. G.722 at 64 kbps is often employed as a benchmark for the performance of other wideband codecs.
Two recently developed wideband speech coding standards, designated as G.722.1 and G.722.2, utilize coding methods that are quite different from G.722, as well as completely different from each other. The G.722.1 standard employs a filter bank/transform decomposition called the modulated lapped transform (MLT) and operates at the rates of 24 and 32 kbps. The coder has an algorithmic delay of 40 ms, which does not include any computational delay. Since G.722.1 employs filter bank methods, it performs well for music and less well for speech.
G.722.2 is actually an ITU-T designation for the adaptive multirate wideband (AMR-WB) speech coder standardized by the 3GPP [11]. This coder operates at rates of 6.6, 8.85, 12.65, 14.25, 15.85, 18.25, 19.85, 23.05, and 23.85 kbps and is based upon an ACELP analysis-by-synthesis codec. Since ACELP utilizes the linear prediction model, the coder works well for speech but less well for music, which does not fit the linear prediction model. G.722.2 achieves good speech quality at rates greater than 12.65 kbps and performance equivalent to G.722 at 64 kbps with a rate of 23.05 kbps and higher.
G.718 is a newer wideband speech codec that has an embedded codec structure and that operates at 8, 12, 16, 24, and 32 kbps, plus a special alternate coding mode that is bit stream compatible with AMR-WB. G.719 is a fullband audio codec that has relatively low complexity and low delay for a fullband audio codec, and the complexity is approximately evenly split between the encoder and decoder. This codec is targeted toward real-time communications such as in videoconferencing systems and the high-definition telepresence applications.
28.4.2 Digital Cellular Standards
The rapid deployment of digital cellular communications was facilitated by the development of efficient, high-quality voice codecs. Digital cellular applications impose a stringent set of requirements on voice codecs in addition to rate and quality, such as complexity, robustness to background impairments, and the ability to perform well over wireless channels. Over the years, standards have been set by different bodies for different segmentations of the market, particularly according to geographic regions and wireless access technologies. More specifically, digital cellular standards were produced in the late 1980s and early 1990s in Europe, Japan, and North America. The competing North American standards then led to standards efforts more pointed toward each of the competing technologies.
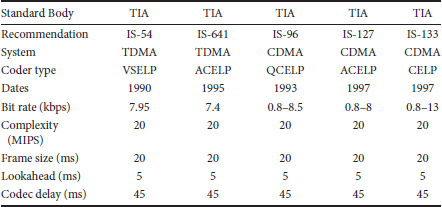
Table 28.3 lists some of the codecs standardized for the North American digital cellular systems in the 1990s. All of the voice codecs shown are analysis-by-synthesis linear prediction-based codecs. The excitation codebooks differ somewhat across the standards, although there is considerable similarity between IS-641 and IS-127, both being based on ACELP, and there is also commonality between IS-96 and IS-133 in their variable rate structure. There are two prominent access technologies in Table 28.3, namely time division multiple access (TDMA) and code division multiple access (CDMA). These two access technologies interact with voice coding in different ways. CDMA is an interference limited-access technology and so a variable rate voice codec, as represented by IS-96, IS-133, and IS-127, increases capacity by adjusting the transmission rate according to the needs indicated by the input source. TDMA can also benefit from a variable rate codec, but by reallocating transmission time slots in the physical layer. Thus, the IS-54 and IS-641 codecs operate at a single fixed rate. However, variable rate codecs were soon incorporated into non-CDMA access systems.
TABLE 28.3 North American Digital Cellular Standardized Voice Codecs
The GSM standards developed in Europe were the basis of perhaps the first widely implemented digital cellular systems. Table 28.4 lists voice codecs standardized for GSM systems, wherein FR stands for “full rate” and HR stands for “half rate.” The terms “FR” and “HR” refer to the total transmitted bit rate for combined voice coding and error correction (or channel) coding, and FR is always 22.8 kbps and HR is always 11.4 kbps. By subtracting the rate of the voice codec from either 22.8 or 11.4, one obtains the bit rate allocated to error control coding.
The first GSM FR voice codec standardized in 1989 was not an analysis-by-synthesis codec but used a simpler regular pulse excited linear predictive structure with a long-term predictor. As a result, the codec had to be operated at 13 kbps to achieve the needed voice quality, but it had very low complexity. The first GSM HR codec used the same vector sum excited linear prediction analysis-by-synthesis structure that originated with the North American IS-54 TDMA voice codec. The enhanced full rate GSM voice codec moved over to the ACELP structure and that has persisted in later codecs. An important and somewhat dominant voice codec today is the Adaptive Multirate Codec, both narrowband and wideband versions. Note that AMR-NB has multiple rates and can be operated as a FR or HR codec, depending upon the rates. For GSM, the AMR-NB codec rates are not source-controlled as the IS-96 and IS-133 codecs were, but the rates are switchable and usually adjusted by the network. The AMR codec maintains compatibility with other systems by incorporating the GSM EFR codec at 12.2 kbps and IS-641 at 7.4 kbps as two of its selectable rates. The AMR wideband codec, AMR-WB, also based upon ACELP is also a very important codec today; however, note how the complexity has grown.
A few other standardized codecs are not shown in any of the tables. One is the TIA-EIA/IS-893 cdma2000 standard Selectable Mode Vocoder (SMV), which has six different modes that produce different average data rates and voice quality. The highest-quality mode, Mode 0, can achieve a higher MOS than the IS-127 EVRC at an average data rate of 3.744 kbps, and Mode 1 is theoretically equivalent to IS-127. Another codec not shown is the cdma2000® Variable-Rate Multimode Wideband (VMR-WB) speech coding standard that shares the same core algorithm as AMR-WB, and was standardized by the 3GPP2 in March 2003 [12]. The codec has five modes, and the rate can be varied by the speech signal characteristics, called source-controlled, or by the traffic conditions on the network, called network-controlled. One mode is fully interoperable with AMR-WB at 12.65, 8.85, and 6.6 kbps and since AMR-WB is standardized for GSM/WCDMA, this could support some cross-system applications. In addition to cdma2000®, the VMR-WB codec was targeted for a wide range of applications, including VoIP, packet-switched mobile-to-mobile calls, multimedia messaging, multimedia streaming, and instant messaging. If appropriate signaling is available, there is also the goal of end-to-end tandem-free operation (TFO) or transcoder-free operation (TrFO) for some mobile-to-mobile calls. The VMR-WB codec has a narrowband signal processing capability in all modes that is implemented by converting the narrowband input sampling rate of 8 kHz to the internal sampling frequency of 12.8 kHz for processing, and then after decoding, converting the sampling rate back to 8 kHz.
TABLE 28.4 Selected GSM Voice Codecs

TABLE 28.5 Representative Asynchronous Tandem Performance of Selected Digital Cellular Codecs

Table 28.5 shows available results for multiple tandem encodings for a few of the codecs discussed, including results from tandem connections of these codecs with G.729 used in VoIP. It is clear that tandem encodings result in a drop in performance as seen in the lower MOS values. Furthermore, tandem encodings add to the end-to-end delay because of the algorithmic delays in decoding and reencoding. Tandem encodings often occur today on mobile-to-mobile calls. Tandem connections with PSTN/VoIP codecs are not discussed often within digital cellular applications since the codec for the backbone wireline network is often assumed to be G.711. However, it is recognized that calls connecting through the wired backbone may require tandem encodings with codecs other than G.711, which can lead to a loss in performance, and that tandem encodings constitute a significant problem for end-to-end voice quality. In particular, transcoding at network interfaces and source coding distortion accumulation due to repeated coding has been investigated with the goal of obtaining a transparent transition between certain speech codecs. Some system-wide approaches have also been developed for specific networks. The general tandeming/transcoding problem remains open.
28.4.3 VoIP Standards
VoIP for wireless access points involves many of the same issues as for wireline VoIP, such as voice quality, latency, jitter, packet loss performance, and packetization. One new challenge that arises is that since the physical link in Wi-Fi is wireless, bit errors commonly occur and this, in turn, affects link protocol design and packet loss concealment. A second challenge is that congestion can play a role, thus impacting real-time voice communications. The way these two issues relate to voice codecs are that packet loss concealment methods are more critical and that codec delay should be more carefully managed for such wireless access points.
We do not discuss protocols for these access points here, but in recent years, considerable effort has been expended to try and adjust prior data-centric approaches to accommodate VoIP applications. There have been quite a few studies concerning the number of calls that can be supported by the various wireless access points, including both physical layer and access protocol issues. One of the points that comes out of these studies is that a reduction in transmitted bit rate for the voice codecs may not result in an equivalent increase in capacity because of the access protocols and packetization issues. Therefore, anyone selecting voice codecs for these applications should familiarize themselves with the trade-offs involved.
Turning our attention to the voice codecs normally implemented in VoIP solutions, we find that at this point in time, almost all codecs are borrowed from other standards bodies. Specifically, G.711, G.729, and G.722 are commonly offered in VoIP products. Additionally, AMR-NB and perhaps AMR-WB are optional voice codecs. All of these codecs have well-developed packet loss concealment methods, which make them quite compatible with wireless applications. One thing to notice is that the AMR codecs are the only ones that are common with any digital cellular standards, and this can lead to tandem coding penalties when digital cellular and wireless VoIP are used for portions of the same connection for a voice call. The need to support multiple codecs can also be an issue as cell phones morph into handheld devices that support both digital cellular and wireless access point connectivity.
28.5 Next-Generation Standards
Standardization efforts for new voice codecs are continuing in several bodies, with some codecs being developed specifically for digital cellular and others being standardized that will be ported to wireless applications. We discuss a few of these here.
The ITU-T standardization efforts have already resulted in G.711.1 and G.729.1, both of which are extensions of existing standards to wider bands and different, higher rates. A superwideband version of G.722 is also expected soon [13]. These codecs could easily appear in future offerings of VoIP for wireless applications.
The dominant standard in going forward apparently worldwide in digital cellular is 3GPP Long Term Evolution (LTE), which is based on Orthogonal Frequency Division Multiple Access (OFDMA) in the downlink and Single Carrier Frequency Division Multiple Access (SC-FDMA) in the uplink. The initial releases of LTE relied upon the AMR voice codecs for voice coding, but now there is a new effort to develop a voice codec for Enhanced Voice Services (EVS). The objectives of the EVS voice codec for LTE are summarized in Table 28.6 [14]. Here, we see that there is a desire to maintain interoperability with the AMR codecs while adding a superwideband capability and giving more attention to in-call music. High-quality audio codecs for nonconversational services such as streaming, broadcasting, and multicasting have been standardized by 3GPP. These codecs are AMR-WB+ and aacPlus, but their high algorithmic delay restrict their importance for two-way conversational voice.
One way to achieve the desired interoperability with AMR codecs would be to use the AMR codecs as a core layer in an embedded structure as suggested in Reference 14. The codec structure then might take the form shown in Figure 28.4. This codec structure reflects many of the characteristics of the integrated codecs developed to code both voice and audio as well or better than existing standards in each area. Examples of such integrated codecs include G.718 which combines ACELP and MDCT technologies, but only covers 50 Hz–7 kHz, and the recently standardized USAC (Unified Speech and Audio Coding) architecture shown in Figure 28.5, which covers the entire range from 20 Hz to 20 kHz, with the goal of coding voice and fullband audio well [15]. These structures can be viewed as merely bolting together successful codecs for different bands, but the USAC effort notes that it is the handling of the transitions between different coding paradigms that requires innovation beyond a simple combination of known schemes.
TABLE 28.6 Summary of the Main Objectives for the EVC Codec

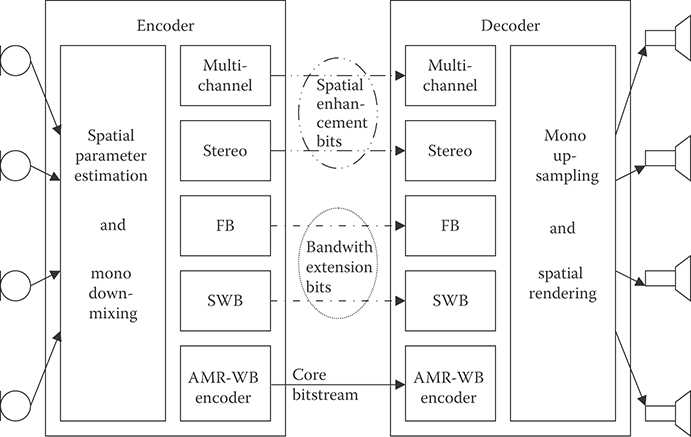
FIGURE 28.4 Embedded codec for EVS (Adapted from K. Jarvinen et al., Computer Communication, 1916–1927, 2010).
A key difference between the USAC effort and the ongoing LTE work is the emphasis of the latter on conversational services, which require low encoding delay. This target application was apparently not specified for the USAC codec standardization. However, there is another codec standardization effort that has the goal of coding narrowband voice all the way up to fullband audio and with the constraint of low delay. The Opus Audio Codec is being designed for interactive voice and audio and has three modes: (a) a linear prediction-based mode for low bit rate coding up to 8 kHz bandwidth, (b) a hybrid linear prediction and MDCT mode for fullband speech/audio at medium bit rates, and (c) an MDCT-only mode for very low latency coding of speech and audio. Details of this codec can be found in Reference 16.
The combination of linear prediction for voice-only coding and the discrete transform/filter bank approaches for music is evident in each of these codecs. There are differences in the applications of interest, and so latency, complexity, and how the complexity is distributed between the encoder and decoder should be an important consideration in wireless applications.
28.6 Outstanding Issues and Future Challenges
It is indeed extraordinary to recognize the large number of voice/audio codecs standardized for a host of applications covering an exhaustive range of desired audio bandwidths and a long list of possible transmitted bit rates. For the most part, these codecs produce the quality and intelligibility needed for the targeted applications. However, there are significant issues remaining. For wireless applications, the codecs are being used in public and perhaps very noisy environments. While great strides have been attained in the robustness of the codecs and in the noise preprocessing algorithms, there is much work left to be done here.
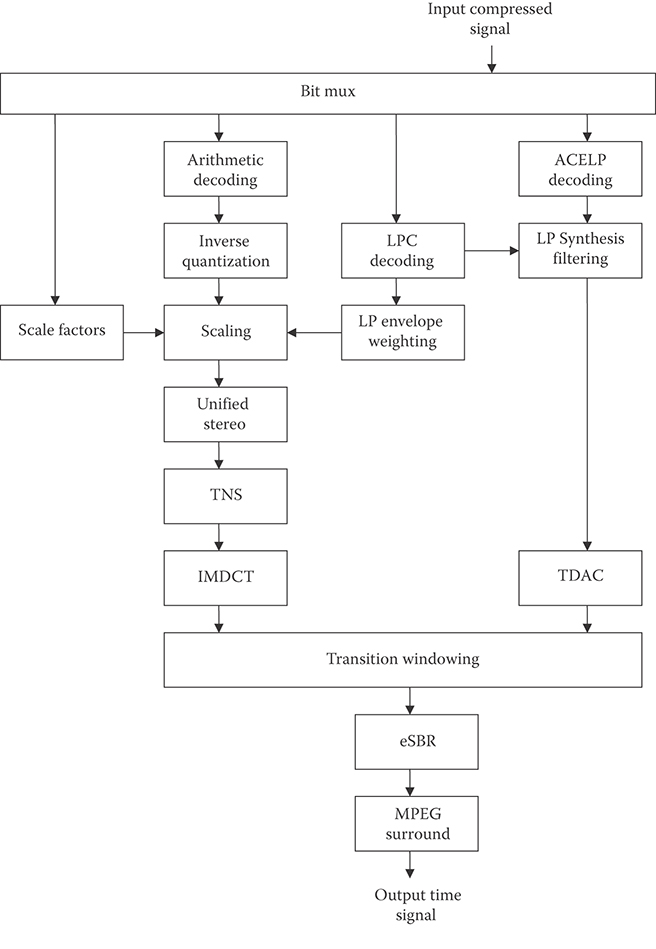
FIGURE 28.5 USAC decoder structure.
Another very significant remaining challenge is that tandem connections of codecs are not being extensively tested prior to standardization and that tandeming is not given a high priority during the standardization processes. However, one way this is being addressed within the setting of particular standards is to maintain interoperable modes. This is seen in the new EVS for LTE effort wherein some AMR mode interoperability is being retained. The issue is primarily the tandeming of codecs in different networks or with different input bandwidths and codec designs. A second way this is being addressed within homogeneous networks, say within a GSM network, is to implement a codec negotiation process. This is not an option for heterogeneous connections, however. A third way is to have each handset contain implementations of a wide variety of codecs. If the transmitted packets are then appropriately marked, the handset can make the appropriate decoder selection. This approach appears to be prohibitively complicated, and expensive.
One might be tempted to dismiss this problem out of hand since networks are evolving toward all packet transmissions, but the issue is not the transmission technology, the issue is what decoder is available at the other end of the call. When a digital cellular user makes a call to another mobile or to a VoIP user, the codecs at the far end are not known in general. Plus, the usual approach today in digital cellular is to decode at the base station or mobile switching center and reencode using a backbone codec. At the other end, it may be necessary to decode and reencode using a codec supported in the handset at the far end. These tandem encoding/decoding steps incur additional latency and a loss in voice quality and intelligibility. A critical issue is the tandem connections of commercial voice codecs with military/DoD codecs and/or with the codecs used by emergency first responders. These tandem connections are not well tested or analyzed.
As one reads this chapter, two trends are evident in the new standards receiving attention today. There is a desire for the capability to code narrowband speech to fullband music inputs, and the end result is more complexity and increasing latency. The LTE and the Opus Codec attempt to satisfy the former while avoiding the increased complexity and latency. It will be interesting to track their success.
28.7 Summary and Conclusions
Speech coding is an integral part of all wireless communications networks today, and much is being done to extend the capabilities in terms of quality and types of signals supported. This chapter has touched on a host of standardized voice and audio codecs, highlighting their strengths and limitations. Future standards have also been discussed and their proposed roles outlined. Given the increasing demands for wireless communications and the apparent dominance of the wireless paradigm in future communications systems, voice and audio coding are sure to continue to be of critical importance.
Appendix: Speech Quality and Intelligibility
To compare the performance of two speech coders, it is necessary to have some indicator of the intelligibility and quality of the speech produced by each coder. The term “intelligibility” usually refers to whether the output speech is easily understandable, while the term “quality” is an indicator of how natural the speech sounds. It is possible for a coder to produce highly intelligible speech that is low quality in that the speech may sound very machine-like and the speaker is not identifiable. On the other hand, it is unlikely that unintelligible speech would be called high quality, but there are situations in which perceptually pleasing speech does not have high intelligibility. We briefly discuss here the most common measures of intelligibility and quality used in formal tests of speech coders. We also highlight some newer performance indicators that attempt to incorporate the effects of the network on speech coder performance in particular applications.
MOS
The mean opinion score (MOS) is an often-used performance measure [2, Chapter 13]. To establish a MOS for a coder, listeners are asked to classify the quality of the encoded speech in one of five categories: excellent (5), good (4), fair (3), poor (2), or bad (1). The numbers in parentheses are used to assign a numerical value to the subjective evaluations, and the numerical ratings of all listeners are averaged to produce a MOS for the coder. A MOS between 4.0 and 4.5 usually indicates high quality.
It is important to compute the variance of MOS values. A large variance, which indicates an unreliable test, can occur because participants do not know what categories such as good and bad imply. It is sometimes useful to present examples of good and bad speech to the listeners before the test to calibrate the 5-point scale. Sometimes the percentage of poor and bad votes may be used to predict the number of user complaints. MOS values can and will vary from test to test and so it is important not to put too much emphasis on particular numbers when comparing MOS values across different tests.
DRT
The diagnostic rhyme test (DRT) was devised to test the intelligibility of coders known to produce speech of lower quality. Rhyme tests are so named because the listener must determine which consonant was spoken when presented with a pair of rhyming words; that is, the listener is asked to distinguish between word pairs such as meat–beat, pool–tool, saw–thaw, and caught–taught. Each pair of words differs on only one of six phonemic attributes: voicing, nasality, sustention, sibilation, graveness, and compactness. Specifically, the listener is presented with one spoken word from a pair and asked to decide which word was spoken. The final DRT score is the percent responses computed according to P = (R – W) × 100/T, where R is the number correctly chosen, W is the number of incorrect choices, and T is the total of word pairs tested. Usually, 75 ≤ DRT ≤ 95, with a good being about 90.
DAM
The diagnostic acceptability measure (DAM) developed by Dynastat is an attempt to make the measurement of speech quality more systematic. For the DAM, it is critical that the listener crews be highly trained and repeatedly calibrated in order to get meaningful results. The listeners are each presented with encoded sentences taken from the Harvard 1965 list of phonetically balanced sentences, such as “Cats and dogs each hate the other” and “The pipe began to rust while new.” The listener is asked to assign a number between 0 and 100 to characteristics in three classifications—signal qualities, background qualities, and total effect. The ratings of each characteristic are weighted and used in a multiple nonlinear regression. Finally, adjustments are made to compensate for listener performance. A typical DAM score is 45–55%, with 50% corresponding to a good system.
PESQ
An important objective measure is the perceptual evaluation of speech quality (PESQ) method in ITU Recommendation P.862, which attempts to incorporate more than just speech codecs but also end-to-end network measurements [3]. The PESQ has been shown to have good accuracy for the factors listed in Table 28.7. There are parameters for which the PESQ is known to provide inaccurate predictions or is not intended to be used with, such as listening levels, loudness loss, effect of delay in conversational tests, talker echo, and two-way communications. The PESQ also has not been validated to test for packet loss and packet loss concealment with PCM codecs, temporal and amplitude clipping of speech, talker dependencies, music as input to a codec, CELP, and hybrid codecs <4 kbps. There is also a wideband PESQ standard, and it has been improved from an earlier version and is used for evaluating quality for inputs in the 50 Hz to 7 kHz range.
TABLE 28.7 Factors for Which the PESQ Has Demonstrated Acceptable Accuracy

Acknowledgment
This work has been supported, in part, by NSF Grant No. CCF-0728646.
References
1. J. D. Gibson, Speech coding methods, standards, and applications, IEEE Circuits and Systems Magazine, 5, 30–49, 2005.
2. W. B. Kleijn and K. K. Paliwal, eds., Speech Coding and Synthesis, Amsterdam, Holland: Elsevier, 1995.
3. ITU-T Recommendation P.862, Perceptual Evaluation of Speech Quality (PESQ), an Objective Method for End-to-End Speech Quality Assessment of Narrowband Telephone Networks and Speech Codecs, February 2001.
4. ITU-T Recommendation G.114, One-Way Transmission Time, May 2000.
5. H. S. Malvar, Signal Processing with Lapped Transforms, Norwood, MA: Artech House, 1992.
6. A. M. Kondoz, Digital Speech: Coding for Low Bit Rate Communication Systems, West Sussex, England: John Wiley & Sons, 2004.
7. ITU-T Recommendation G.722.1, Coding at 24 and 32 kbit/s for Hands-Free Operation in Systems with Low Frame Loss, September 1999.
8. ITU-T Recommendation G.722.2, Wideband Coding of Speech at around 16 kbit/s Using Adaptive Multi-Rate Wideband (AMR-WB), 2002.
9. ITU-T Recommendation G. 718, Series G: Transmission Systems and Media, Digital Systems and Networks, Digital Terminal Equipments—Coding of Voice and Audio Signals, June 2008.
10. ITU-T Recommendation G. 719, Series G: Transmission Systems and Media, Digital Systems and Networks, Digital Terminal Equipments—Coding of Analogue Signals by Pulse Code Modulation, June 2008.
11. B. Bessette , The adaptive multirate wideband speech codec (AMR-WB), IEEE Transactions on Speech and Audio Processing, 10, 620–636, 2002.
12. M. Jelinek , On the architecture of the cdma2000® variable-rate multimode wideband (VMR -WB) speech coding standard, Proceedings of ICASSP, 2004, pp. I-281–I-284.
13. R. Cox, S. F. de Campos Neto, C. Lamblin, and M. H. Sherif, ITU-T coders for wideband, superwideband, and fullband speech communication, IEEE Communications Magazine, 106–109, 2009.
14. K. Jarvinen, I. Bouazizi, L. Laaksonen, P. Ojala, and A. Ramo, Media coding for the next generation mobile system LTE, Computer Communication, 1916–1927, 2010.
15. M. Neuendorf, P. Gournay, M. Multrus, J. Lecomte, B. Bessette, R. Geiger, S. Bayer , A novel scheme for low bitrate unified speech and audio coding-MPEG RM0, Audio Engineering Society, Convention Paper 7713, May 2009.
16. IETF Opus Interactive Audio Codec, http://opus-codec.org/, 2011.