
Chapter 14
Platform and Content Security
Informed users of embedded systems typically want answers to three fundamental questions:
The first two questions differ from the third—which is the focus of this chapter—in more ways than one.
First, questions of correct function and cost are well within the traditionally recognized boundaries of embedded systems engineering. Engineers are trained to build things correctly, and engineers play an essential role in determining the cost of systems, both directly, by designing systems and choosing their components whose costs factor into the total system price, and indirectly, via their compensation for time spent on the development of the system. (Better engineers are paid higher wages and, hence, develop more costly technology!) But security? Historically, security has been someone else’s concern.
Consider the traditional separation between development and quality assurance. In many engineering practices, development of a functional system is assigned to one group of engineers, and testing and quality assurance of that system are assigned to another type of engineer. In traditional organizations, both groups are focused on establishing the correct operation of the device or system. Security has more often than not been an attribute to be observed and considered once the system has been built.
The second difference is more important, and qualitatively more troublesome. The question “Is the system secure?” is far more vague and subject to interpretation than the first two questions.
The questions “Does it work?” and “What will it cost?” have reasonably straightforward interpretations. Each device or technology has an intended purpose and a cost of manufacture. The answers to these questions may be complicated, particularly when standards compliance must be validated, but the questions themselves are easy to understand, and two similarly informed people are likely to understand them in the same way.
What about security? What might the question “Is the system secure?” mean? As it happens, there are many possible interpretations to this question. Let’s consider some possibilities.
• Can anyone else access my data?
• Can I control who uses the device?
• Can anyone interfere with or prevent my usage of the device?
• Can someone spy on my usage of the device?
Most would agree that each of these questions would be a reasonable interpretation. Moreover, most would agree that more could be added to the list! So, in order to answer “Is the system secure?” do we need to enumerate and answer all such possible interpretations? Let’s hope not, because it turns out that answering just one is hard enough. To see why, let’s consider the first.
“Can anyone else access my data?”
The complexity-inducing culprit in this question is the indefinite pronoun: someone. The question asks, quite plainly, is there anyone who is able to steal my information or data?
To be sure we are casting the net wide enough, let us begin by dividing all living beings on the planet into two categories: those with authorized access to our mythical device, and those without authorized access. The device may or may not have a built-in notion of users, but presumably at least the owner of the device has authorized access. Given this distinction, we can explore the space of data access with the following questions.
• Does the device have authenticated users? Is it a multi-user device? Are data access control mechanisms in place? If users sign in, how do they do so? Is it possible for someone to trick the system into accepting a false user identity?
• Can unauthorized users gain access? Has the device been determined to be hack-proof and impervious to unauthorized access through technical means? If so, what standard of security applies?
• Can authorized users delegate access to their data? If a user can grant data access to another user, does the original user have any control over who else might get access?
• Is there an administrative user account that can create and modify user accounts? If so, then whomever controls the administrative account can control access to data.
• Can the system be reset to factory defaults without destroying data? Some systems provide a means to reset a system following a lost account credential that keeps the original data intact.
• Is the data archived on a backup service or device? If so, how is access to that data managed?
• Do local laws require a back door for access by government authorities? If so, can a user verify either that such an access request is legitimate, or whether such accesses have taken place?
You can see that none of these questions reach the bottom of the issue, and we’re already three levels down.
Clearly, “Is the system secure?” is a different kind of question, and, as such, it requires a different perspective, an increased level of understanding, and a common vocabulary of security to go with it. The purpose of this chapter is to help you develop a point of view that enables you to answer this question despite all the uncertainty surrounding what it may mean to a person not versed in the vocabulary of security.
To this end, we will explore the core principles of computer and information security. We will also walk through specific approaches and concrete examples of securing Linux-based embedded systems.
We begin with a discussion of principles that will inform our perspective and better prepare us to answer the question: “Is the system secure?”
Security Principles
This is important: Security is a consequence of people, process, and technology. So security is more than a technical concern. While at first blush, it may appear that this fact simplifies the role of the engineer, this is most certainly not the case. Evidence suggests that no matter the cause of the security failure, technology and its creators are the intuitive and popular culprit.
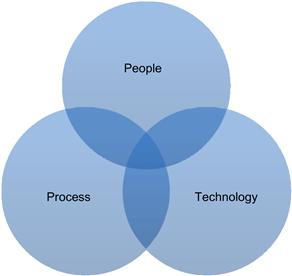
FIGURE 14.1 Security is a Consequence of People, Process, and Technology.
To see why, let’s dig a little deeper.
People. If an embedded system has users, then those users have an impact on the operation and security of the device. For example, if users of a device have accounts and associated passwords, then users must understand that their passwords must be kept secret and should be difficult for someone else to guess.
Process. By process, we mean the rules and procedures that people and systems must follow. For example, your employer may have a process that requires that you change your password every 90 days and that a new password can only be accepted if it meets difficulty criteria.
Technology. The system itself, along with the collection of automated tools, technologies, and services put in place to secure it, represents the technological contribution to system security.
Hence, the challenge to designers and engineers is to create technologies that encourage more secure user action and encourage the creation of more secure processes. Increasingly, the notion of an affordance—a term borrowed from architecture and design that suggests that the natural and obvious uses of a design will be the most common uses—is implied in the design of embedded systems.
Ultimately, we want to translate these high-level notions into something concrete that leads to the development of secure embedded systems. We have a bit more to review before we can walk through a practical example, but we can take a step in that direction by considering how this people-process-technology perspective relates to securing or subverting a system. Consider Table 14.1.
Table 14.1. Examples of the Relationships between People, Process, Technology, and Security
| Factor | Security Measure | Attack |
| People | Provide training periodically to ensure that users have an understanding of security risks and are aware of common pitfalls. | Fool users into divulging their access credentials by sending convincing email messages that appear to be legitimate requests. These tactics are known as phishing attacks. |
| Process | Design rules and procedures for users and systems that are intended to improve security and increase the effort required on the part of any attacker. For instance, a policy may dictate that a user account be locked out after five unsuccessful login attempts. Such a policy will make it impossible for remote attackers to gain access by submitting large numbers of possible passwords. | In systems that provide remote access and also lock out accounts after some number of failed attempts, attackers can disrupt service and cause problems by assembling a list of user account names and then launching failed login attempts in order to lock all the accounts out. Then, the attacker can send immediate phishing messages with false instructions for re-enabling their account. |
| Technology | Software-defined systems typically pull together a large number of libraries and applications to provide functionality. Each of these libraries and applications represents a point of attack; hence, systems should be designed with the means to regularly update and apply any security-related patches. | Software with an exploitable weakness is the primary attack target in Internet-connected systems because they can be sought and attacked in an automated fashion. Some attackers discover and exploit weaknesses; others simply wait for exploits to be published then find and attack systems susceptible to the exploit. |
Clearly, to secure a system, our attention must cut across these domains. In other words, to answer the question “Is the system secure?” our answer, or at least the evidence we provide to justify our answer, must address each of these aspects.
We are getting close to returning to the concrete world of software and systems, but we have still more background understanding to develop before we start looking at concrete solutions.
There is much to be said about security principles. Unfortunately, many books and papers on the subject verge on the brink of philosophy and are therefore difficult to rely upon for developing a practical understanding. For the purposes of this chapter, we can get by with the following discussion of additional ideas and illustrations. These will serve as an adequate preparation for our specific security examples to follow.
Confidentiality, Integrity, and Availability (CIA)
If you are comparatively new to thinking about security and associated risks, some of the discussion above may have felt disingenuous. Gaining unauthorized access to a system (i.e., hacking into a system) seems like a different kind of security concern as compared to interfering with an authorized user’s ability to access that system. So it feels a bit like sleight of hand when both types of examples are raised as risks in the same scenario. By extension, what is to keep up us from including all possible unanticipated events in the discussion of security?
The field of information security has emerged as a result of such questions being asked over time. Of course, information security is more encompassing than our specific focus on embedded systems security, but most of the time-tested observations and principles we rely upon to secure embedded systems come from information security principles.
In particular, the security of information is said to be due to its confidentiality, integrity, and availability. These three characteristics, often referred to as the CIA triad, derive from viewing the security of information in a manner analogous to the security of physical objects. That is, if information has some discrete existence (i.e., it exists just like diamonds or treasure maps), how can we characterize its security? To see one way of doing so, let us consider the components of the triad.
Confidentiality. Information is kept confidential when it can only be observed by authorized individuals. Those with permission can see it; those without it cannot. The meaning is clear, but there are some difficult consequences to reckon with. For example, observation must be limited to authorized users, no matter the form of the information. Your system may store user names and passwords in encrypted files, but if either is transmitted in plain text over a network that others may be monitoring, then confidentiality is violated. This most certainly includes web sites that transmit user names and session keys in unencrypted HTTP traffic. The use of user names and passwords is an example of an authentication mechanism, by which a system verifies that a user has rightful use of a digital identity. There are other such mechanisms, and we will discuss the topic in greater depth below.
Integrity. The integrity of information is preserved if it has not been altered in any unintended way. Note that this is a notion quite distinct from that of observing information. From an attacker’s perspective, disruption or deception may be the goal, in which case altering or destroying information may be the most effective means. Attackers aside, reliable and robust information systems should keep users from being able to accidentally violate the integrity of their own data. For instance, a secure and reliable word processor should not corrupt a document in an unrecoverable way when the system crashes.
Availability. If we view information as an asset to keep secure, then it follows naturally that access to the information is an important component in its security. If my information has been kept in a confidential manner and its integrity has been preserved but someone can interfere with my access to it, then it is not secure. Alas, ensuring absolute access and availability is a very deep commitment, and one that illustrates the practical challenge in precisely characterizing information security.
These common components have endured in the information security community for many years. While a few refinements have been suggested that separate concerns into additional top-level elements, the CIA triad remains the conceptual core of information security.
One vexing challenge confronting this core, as well as the refinements, is the issue of time. How long must these characteristics be maintained? Forever? The atemporal nature of these components perhaps suggests an ill-defined characterization.
For example, when information is shared among multiple users, there is a qualitative change to the nature of confidentiality. Suppose that users A and B have been granted rightful access to some information. After some time passes, suppose B’s access rights are withdrawn (e.g., B has changed employers and no longer has access to corporate information.) Can we be sure that B no longer has access to the information? Perhaps B can no longer log in to an information system, but did B make copies of files? Does B have memory of widely shared passwords and pass phrases that she can perhaps unlawfully give to others?
This issue—the revocation of access rights—is one that does not fit cleanly within most conceptual frameworks but must certainly be addressed in real-world systems. Fortunately, in this chapter, there is no need to make absolute definitions of information security watertight. It will suffice for us to be attentive to the important issues and develop a perspective that enables us to develop systems that are as secure as we can make them.
Security Concepts and Building Blocks
With some principles established, we can now explore some of the important ideas and practical concepts in computer security. There is an enormous body of knowledge that can be considered in this area. Indeed, there are entire degree programs and career paths devoted to the subject. Needless to say, our exploration will only serve as an introduction.
Our purpose here is to introduce the key ideas in sufficient depth to get started in securing the design and implementation of your embedded systems and software.
Encryption and Cryptography
For most, thoughts of computer and network security immediately turn to encryption, decryption, and cryptographic message transfers. Yet, here we are well into this chapter and we are only now getting around to discussing them!
Perhaps surprisingly, while critically important, encryption and cryptography occupy only a small part of the practical experience of securing real-world systems. This is mostly due to the fact that encryption represents one of the reliable aspects of security, and, hence, it is generally better understood by engineers.
Cryptography can be loosely defined as the art of keeping secrets with mathematical guarantees. When information is encrypted, it should be indistinguishable from random data. For our purposes, we need not explore the mathematics of encryption; rather, we will discuss how the mechanisms can be used to enable the secure storage and transfer of information.
We begin with single-key encryption. Suppose you have information in the form of a file on your computer that you want to keep secret. Encryption techniques make that easy.
First, you generate a repeatable secret (the “key” such as a pass phrase) that only you know. Second, the crypto algorithm translates that secret into a numerical form that is used to randomize the bits in the file you want to encrypt. The mathematical guarantee provided by “encryption algorithms” is that the bits in your encrypted file appear to contain no statistically discernable information. Of course, there are differences between encryption algorithms, and it is possible to get it wrong. As long as you are using an up-to-date open source crypto package with a large and active user community, such as GPG, you’ll be OK. A simple transcript using gpg for single-key encryption and decryption follows.
$ gpg -c data.txt
Enter passphrase:
Repeat passphrase:
$ # data.txt.gpg now exists
$ rm data.txt
$ gpg data.txt.gpg
Enter passphrase:
$ # data.txt now exists
In this way, we can restrict direct access to data in files to only those people who know the secret pass phrase. This method is referred to as single-key encryption because the same key is used to both encrypt and decrypt. As we can see, single-key cryptography is based on the idea of a shared secret, and that idea has been around for a very long time.
Establishing and maintaining shared secrets can be cumbersome. A revolutionary idea emerged in the 1970s that forever changed the practice of cryptography. That idea was asymmetric-key cryptography, also known as public-key cryptography. In asymmetric-key cryptography, one key is used to encrypt (the public key) and another is used to decrypt (the private key).
To begin, a user generates a key pair, which consists of a public and private key. The private key is a secret, for example, a long, hard-to-predict pass phrase, known only to the user. The public key is freely available. When anyone wants to send a private message to the user, they encrypt it with the public key. Once this is done, the only one who will be able to make sense of the apparently random bits in the encrypted message will be the holder of the private key. While these public and private keys are mathematically related, the relationship only goes in one direction; knowing the public key gives no insight into what the private key might be.
In 1978 the cryptographers Rivest, Shamir, and Adelson published a description of a cryptosystem for public-key encryption that provides the functionality described above, plus a few other features. Their system, referred to as RSA from the concatenation of the first letters of their family names, was not the first such scheme, but it was the first one publicly described and implemented in a practical way. Consequently, it is supported by most public-key encryption systems in use today.
One very notable aspect of RSA is its ability to support authentication and integrity. We know that a public key may be used to encrypt a message in such a way that only the holder of the private key can decrypt it. It is also typically useful to establish the authenticity of the one who encrypted the message and determine their integrity. If I get an encrypted message from Alice, I would like some assurance that Alice is indeed the source of the message before I take it seriously. Additionally, I would like to know that the message has not been tampered with.
To achieve both, RSA allows a user to sign a message with their private key. In our example, Alice will sign the message with her private key before she encrypts it with my public key. In practical terms, a signature is a separate file that is derived from both the source file and Alice’s private key. Upon receipt, I decrypt the message using my private key. Once decrypted, I can see that it comes with a signature. RSA will allow me to use Alice’s public key to verify the signature. If the signature does not match, I know that either Alice was not the source or the file has been altered after signing.
The mathematical assurances of public-key cryptography, and the demonstrated effectiveness of RSA, may suggest that we can relax a little. Alas, there is one major issue remaining, and it is a significant one.
Consider how such a secure communications scheme might begin. Suppose I want to communicate with Alice. How do I get a copy of her public key? One way would be to invite her over and have her install her public key on my system herself. That would get the job done, but it doesn’t scale.
What is needed is some objective assurance that a given public key in fact belongs to the personal identity it claims to represent. There are two broad approaches to this issue, one centralized and one decentralized.
The centralized solution—and the one that dominates use today—relies on the existence of so-called Certificate Authorities, or CA. A CA is a trusted source of identity information.
The term certificate refers to a collection of information:
Before a CA will sign someone’s certificate, they will take some steps to establish their identity. Typically, they collect personal information and charge a handsome fee.
If you have studied philosophy, you may be familiar with the notion of “begging the question.” It is natural to raise that notion here. How do we know if we should trust Certificate Authorities, and, assuming we trust one, how do we verify its public key? These are the right questions, but they are effectively moot. Practically speaking, effective Certificate Authorities are those whose certificates are included by default in the major web browsers. Mozilla, Microsoft, Apple, Google, and Opera choose to include a default set of certificates from CAs in their browsers (i.e., the “root” certificate authorities). So, the globally trusted CAs are the ones that the web browser vendors have elected to trust.
Given the stakes, it is reasonable to assume that the browser vendors take care to only include reputable and reliable CAs. VeriSign is one such trusted CA, and it is guilty of having committed the only publically discussed incident of CA subversion. In March 2001, VeriSign issued two certificates to someone fraudulently claiming to be a Microsoft employee. As a result, an unidentified fraudster has a certificate signed by VeriSign that associates a public key with the name “Microsoft Corporation.” As you might expect, this created quite a stir. These particular certificates can only be used to sign code (such as Active X controls in this case), so the window of risk for most has passed. But the story serves as a reminder of where trust is placed.
The alternate, decentralized approach is to rely on a web of trust. Rather than relying upon the single certifying signature of an authority, the web of trust model allows signatures to be signed by multiple parties. The idea is that you may accept the authenticity of someone’s certificate if other people you already trust have vouched for them by signing their certificate. This process is bootstrapped via “signing parties” where people gather together for the purpose of reciprocal signings. This method provides more trust, but it has not established any kind of foothold in the world of commerce.
As an aggregate, any scheme by which digital identities are managed is referred to as a public-key infrastructure, or PKI. One of the challenges in building an effective PKI is revocation: how do you remove authentication authority once it has been granted? This has proven to be a difficult challenge to overcome. Most revocation solutions are, in one way or another, based on the idea that, periodically, participants in the PKI should compare the keys and certificates they hold against a revocation list. A revocation list, published by a CA or key server, enumerates the keys that are no longer valid. This scheme can be made to work, but it is not entirely satisfactory. After all, if we should really consult a revocation list before we accept a certificate, how is that different from keeping all of our certificates in a central location? And, what happens if access to the revocation list is interrupted?
As you might guess, based on the preceding discussion, no PKI scheme has achieved Internet-scale success. There have been pockets of success in e-commerce, in governments, and within corporations, but the majority of Internet users lack personal certificates and the means by which to participate as an authenticated user in a public-key-based cryptosystem.
Secure Web Communications: TLS
In today’s World Wide Web, secure communications are provided by a protocol called Transport Layer Security, or TLS. TLS is the name of the latest variant of the Secure Sockets Layer, or SSL, which was originally created by Netscape Corp. SSL has been called TLS since version 3.1.
TLS, despite its name, is effectively an application-level security protocol, and support for it must be built into applications like web browsers and web servers. Network-level security protocols, like IPSec, do not require application-level support. TLS is an IETF standards-track protocol, and its most recent description can be found in RFC 5246.
In TLS, we find most of the principles discussed above assembled in a form that enables web security. In particular:
• Public-key encryption is used to authenticate clients and servers.
• Single-key encryption is used to secure communications between two applications.
• Cryptographic signatures are used to ensure message integrity.
• Certificates and Certificate Authorities are used to associate names with public keys in a trusted manner.
TLS is best known for its use in securing HTTPS, the secure variant of HTTP. Support for TLS is built into all modern browsers and servers. As an increasing fraction of Internet communications occurs via web services and HTTP, we can expect the use of TLS to grow.
In fact, for most use cases outside of deeply embedded systems, most data-oriented Internet communications will be managed via web services and HTTP, and, in the future, most of those will be secured via HTTPS and TLS. So, let’s take a look at how TLS works.
TLS begins with a handshaking protocol that, when successful, concludes by creating a secure communications channel that is guaranteed to be private and immune to tampering. The handshake protocol proceeds as follows.
The client sends the server a message (ClientHello, as described in the RFC) requesting a secure connection. This message contains the client’s supported TLS version, along with a list of cryptographic algorithms for symmetric cryptography, asymmetric cryptography, and signature generation that it can use (the so-called cipher suite). The message also indicates what, if any, forms of compression it can support.
The server responds with a message (ServerHello) containing both its choice from among the intersection of versions and algorithms that both support and a random number.
The server follows with another message (Certificate) containing its certificate, which, as we know, contains its identity, its public key, and the identity and signature of a Certificate Authority.
The server then sends a hand-off message (ServerHelloDone), indicating that it is finished with its portion of the handshake.
The client replies with a message (ClientKeyExchange) that contains a pre-shared secret and a second random number encrypted with the server’s public key. Note that two random numbers have been generated: one by the server and sent across the wire in the clear, and one by the client and sent across the wire encrypted so that only the server can decrypt it. Both the client and server compute a shared secret based on the pre-shared secret generated by the client, and the two random numbers (the two random numbers serve as “nonces” or numbers used once that ensure that these communications cannot be replayed again in the future). This shared secret is used to encrypt, using single-key cryptography, the channel between client and server.
The client next sends a ChangeCipherSpec message that signals that all following messages will be encrypted with the shared secret.
The client makes good on its previous message by sending an encrypted Finished message, which includes a signature computed over all of the previous handshake messages.
The handshake concludes when, after having verified the integrity of the client’s Finished message, the server replies with its own ChangeCipherSpec and Finished messages.
From now own, messages between client and server will be encrypted and authenticated.
This protocol walk-through conveys the high-level behavior of TLS, but we can also examine the protocol in action. In particular, we can use the curl command-line utility to examine the protocol operations that occur when accessing a secure web server.
Let’s examine TLS by visiting Gmail with curl. Consider the following console trace.
1 $ curl -v https://mail.google.com
2 ∗ About to connect() to mail.google.com port 443 (#0)
3 ∗ Trying 72.14.204.83… connected
4 ∗ Connected to mail.google.com (72.14.204.83) port 443 (#0)
5 ∗ successfully set certificate verify locations:
6 ∗ CAfile: none
7 CApath: /etc/ssl/certs
8 ∗ SSLv3, TLS handshake, Client hello (1):
9 ∗ SSLv3, TLS handshake, Server hello (2):
10 ∗ SSLv3, TLS handshake, CERT (11):
11 ∗ SSLv3, TLS handshake, Server finished (14):
12 ∗ SSLv3, TLS handshake, Client key exchange (16):
13 ∗ SSLv3, TLS change cipher, Client hello (1):
14 ∗ SSLv3, TLS handshake, Finished (20):
15 ∗ SSLv3, TLS change cipher, Client hello (1):
16 ∗ SSLv3, TLS handshake, Finished (20):
17 ∗ SSL connection using RC4-SHA
18 ∗ Server certificate:
19 ∗ subject: C=US; ST=California; L=Mountain View; O=Google Inc; CN=mail.google.com
20 ∗ start date: 2009-12-18 00:00:00 GMT
21 ∗ expire date: 2011-12-18 23:59:59 GMT
22 ∗ common name: mail.google.com (matched)
23 ∗ issuer: C=ZA; O=Thawte Consulting (Pty) Ltd.; CN=Thawte SGC CA
24 ∗ SSL certificate verify ok.
25 > GET / HTTP/1.1
26 > User-Agent: curl/7.19.7 (i486-pc-linux-gnu) libcurl/7.19.7 OpenSSL/0.9.8k zlib/1.2.3.3 libidn/1.15
27 > Host: mail.google.com
28 > Accept: ∗/∗
29 >
30 < HTTP/1.1 200 OK
31 < Cache-Control: private, max-age=604800
32 < Expires: Wed, 29 Jun 2011 14:25:10 GMT
33 < Date: Wed, 29 Jun 2011 14:25:10 GMT
34 < Refresh: 0;URL= https://mail.google.com/mail/
35 < Content-Type: text/html; charset=ISO-8859-1
36 < X-Content-Type-Options: nosniff
37 < X-Frame-Options: SAMEORIGIN
38 < X-XSS-Protection: 1; mode=block
39 < Content-Length: 234
40 < Server: GSE
41 <
42 <html><head><meta http-equiv="Refresh" content="0;URL= https://mail.google.com/ma
43 il/" /></head><body><script type="text/javascript" language="javascript"><!--
44 location.replace (" https://mail.google.com/mail/ ")
45 --></script></body></html>
46 ∗ Connection #0 to host mail.google.com left intact
47 ∗ Closing connection #0
48 ∗ SSLv3, TLS alert, Client hello (1):
49 $
Let’s see how this output matches with our understanding of the TLS protocol.
Lines 1–7: The first several lines of output make clear what’s happening. We’re attempting to contact mail.google.com, which corresponds to IP address 72.14.204.83, on port 443. That’s the port to which HTTPS is bound. Next, we can see where curl found the cryptographic certificates (i.e., the CA certificates) on this Ubuntu Linux system. We will later be receiving a certificate from the server, and curl will expect that certificate to be signed by one of the root certificates stored in /etc/ssl/certs.
Lines 8–16: These lines correspond to the handshake protocol steps described above.
Lines 17–24: The next lines give insight into what the protocol negotiation yielded. The RC4-SHA algorithm will be used to secure the communications channel. Also, the server certificate details are given, along with an indication (on line 24) that the CA signature was verified by one of the roots certificates present in the system.
Lines 25–49: The remainder of the output represents the HTTP protocol details (our user agent in curl, …), some of which we can manipulate in curl via other command line options, and the corresponding HTML that is returned. In this case, our request is redirected via embedded JavaScript code to https://mail.google.com/mail/.
In the next section, we will cover the steps necessary to prepare and configure an Apache web server to correctly respond to such requests.
Secure Shell (SSH)
The secure shell utility and protocol, ssh, enables users to log in to a Linux or Unix-inspired system remotely. This protocol, like TLS, is an application-level security protocol that relies upon public-key cryptography for authentication and secure communications. While ssh is primarily used to enable secure remote command line sessions, it can also be used to copy files securely (via scp) and execute remote commands. As we’ll see, ssh is a great help in remotely administering machines.
When ssh is installed on your system, a host keypair is created. More precisely, one keypair is created for each encryption algorithm supported. These public and private keys are typically found in /etc/ssh. Under normal circumstances, the public keys are world-readable and the private keys are only readable by root.
When using ssh to log in to a server host from a client host for the first time, the client begins by requesting a copy of the server’s public key. By default, the ssh program will print to the screen a signature of the public key and ask, “User, do you believe that this is a legitimate public key for the server you requested?” As user, you either know it is legitimate (because someone sent you the signature beforehand) or assume it is legitimate. With no additional knowledge, it is impossible to know. The threat here is that someone on the network path between your client machine and the server machine is masquerading as the server machine in an attempt to sit in the middle of your conversation. Once you’ve logged into the machine, you can verify that the public key on that machine matches the one you saw.
Once accepted, the public key for the remote host will be appended to your ~/.ssh/known_hosts file. Next time you ssh into this remote machine, this public key will be used directly.
Once your client machine has authenticated the remote server and gotten its public key, it can use it to encrypt your communications. By default, this means that it will allow you to enter your password and try to log in to the remote machine. The ssh tool also lets you log in via a public key associated with you.
To do so, you must first generate a public-private keypair to represent your account name. The ssh package includes a utility, ssh-keygen, that generates public-private key pairs. On your client machine, you execute the ssh-keygen program with a command like the following to generate a keypair and enter a pass phrase to encrypt your private key:
$ ssh-keygen -t rsa
Unless directed otherwise, your newly created keys will be installed in your .ssh directory as in the following example:
$ ls -l ~/.ssh
total 16
-rw------- 1 ubuntu ubuntu 398 2011-06-06 19:33 authorized_keys
-rw------- 1 ubuntu ubuntu 1679 2011-06-06 19:34 id_rsa
-rw-r--r-- 1 ubuntu ubuntu 397 2011-06-06 19:34 id_rsa.pub
-rw-r--r-- 1 ubuntu ubuntu 842 2011-06-06 19:35 known_hosts
$
The public key, id_rsa.pub above, can now be copied to the remote server. In particular, once it is appended to the ~/.ssh/authorized_keys file on the remote server, you will not need to enter a password to log in via ssh. In this case, the remote system does not need a password from you, because it can authenticate you based on your public key.
Of course, your client machine may prompt you for the pass phrase that has been used to encrypt your private key, which naturally causes one to wonder: how exactly is this better? Rest assured, it is better in at least two ways.
First, you can use yet another helper program called ssh-agent to authenticate once when you log in to your local machine, and, once having done so and for as long as ssh-agent is running on your system, subsequent ssh actions will not require a pass phrase. Second, it turns out that the pass phrase is optional! When prompted by ssh-keygen, you can hit “return” and provide an empty pass phrase. This method is used whenever scripts must both execute in an unsupervised fashion and require remote access. For example, consider a cron job that executes periodically on a local machine but checks the size of a log file on a remote system.
Security Architecture for IP: IPSec
TLS and ssh are secure protocols that operate over IP, which is a protocol that lacks security features such as authentication and privacy. If the IP layer did offer security services, then, quite naturally, the need for and features of higher-level security protocols would change dramatically.
IPSec is the IETF standards-track architecture (RFC 2401 is a good starting point) for securing IP. It was developed as part of IPv6, but also includes protocol extensions for IPv4. To date, its deployment is trivial in relation to TLS and ssh, but it has important uses, particularly with virtual private networks (VPNs).
IPSec is another way to secure the traffic between two hosts that is distinguished from the protocols we’ve discussed so far due to its location at the network layer, the IP layer. When IPSec is in use between two hosts, all IP traffic between the two machines is secured. All protocols based on TCP or UDP would automatically inherit the security benefits of IPSec.
Due to the point-to-point nature of IPSec, it finds its greatest uses in enterprise-network-oriented applications. For example, within one company’s network, each host can use IPSec to access servers on the company network. Similarly, to provide secure access to remote employees and machines, a network can provide a secure IPSec gateway through which remote machines access the local network. Traffic between the IPSec gateway and remote machines is kept secure, despite being carried over a wide-area network like the Internet.
In fact, these two uses correspond to the two operating modes supported by IPSec.
• Transport mode. In transport mode, security is applied to upper layer protocols and their data contents. The IP header itself is not encrypted and so is available for external observation. Transport mode is used in point-to-point fashion between end hosts.
• Tunnel mode. In tunnel mode, the original IP packet is encapsulated inside another IP packet. It is intended to be used to secure communications between hosts and security gateways, and between security gateways.
A key design goal and attribute of IPSec is to operate without requiring wholesale changes to the routing and forwarding infrastructure of existing networks. Traditional IP routers and switches forward IPSec packets in exactly the same way that IP packets are forwarded.
Before we look at the operation of the protocol itself, it is important for us to understand one more difference between IPSec and other protocols we’ve discussed. SSL (on which TLS is based) and ssh were protocols originally designed by individuals or small teams. By contrast, IPSec was developed by a committee—in particular, a working group consisting of several individuals representing several companies and industries—in the IETF. As such, the protocol had to satisfy many perspectives and apply to many use cases. For this reason, and surely others, the IPSec protocol is complex and has many narrowly defined pieces.
Consequently, no one has yet figured out how to describe IPSec succinctly yet deeply in a manner comparable to what can be done with, say, TLS and ssh. Alas, we must confess that we can be counted among that number because we have not been able to crack this problem of concise exposition either. So, our exploration of the protocol must remain at a high level, yet this will still require that we introduce and rely upon what feels like too many pieces of jargon that do not seem important enough to have their own names. Having issued this mea culpa, let’s look at the protocol.
IPSec services are provided in the context of two distinct security protocols, each with a different aim. The first, and simpler, protocol is called the IP Authentication Header. If you think that’s a strange name for a protocol because it looks like the name for a header, please understand that we agree.
The Authentication Header, or AH, provides authentication and integrity, but not privacy. When using AH, the communications between two systems are guaranteed to be authenticated and not tampered with. There are no guarantees that provide, or attempt to provide, data privacy. While this may sound strange, it is true that many communications services only require authentication from the network because, for instance, privacy can only adequately be provided by a higher-level protocol. Moreover, it is in many cases a vast improvement simply to be able to authenticate the end hosts in a conversation (something that IP itself does not enable). And, from a design and implementation perspective, a simpler protocol is a better protocol.
The second IPSec protocol is named the Encapsulating Security Payload, or ESP. ESP is the protocol that provides the security features of AH, as well as encrypted payloads. Most IPSec deployments rely upon ESP.
Fortunately, IPSec relies on the same categories of cryptographic and identity mechanisms to provide security as the protocols we have already discussed. In particular, IPSec relies upon the following.
Asymmetric key cryptography is used to authenticate and establish shared secrets.
Symmetric key cryptography enables communicating end hosts to encrypt communication payloads via a shared secret.
Cryptographic signatures are used to verify data integrity.
The IPSec protocol is designed in a modular fashion that allows implementations to choose from cryptographic algorithms and key management schemes. The protocol introduces the notion of a security association, or SA, that groups together the collection of keys, parameter choices, and algorithms used to secure an individual flow of information. In fact, before a packet can be transmitted by an IPSec-enabled network stack, its associate SA must be found. We will see how shortly.
It is valid to think of an SA as the dynamically negotiated security details associated with the flow of information between host A and host B. The SA is established in IPSec through a protocol called the Internet Security Association and Key Management Protocol, or ISAKMP. For our purposes, it is sufficient to think of this as the secure handshake protocol by which two hosts negotiate the cryptographic details of their secure communications. This exchange includes the establishment of shared secrets and the trading public keys, and there is a menu of options supported by the protocol.
Once an SA has been negotiated between two hosts, secure packets can be sent. Note again that these packets can be either between end hosts (transport mode) or secure gateways (tunnel mode), and can be either authenticated (AH) or authenticated and encrypted (ESP).
Once the collection of options and choices has been determined, they are stored in a security associations database and referred to by a number, the security parameters index, or SPI. To uniquely identify a specific security association, you need an SPI, a destination IP address, and the protocol identifier (AH or ESP).
When a packet is being transmitted from the host, this triplet is used to determine what security operations should be performed on the packet payload prior to transmission.
This level of indirection enables IPSec to support a very flexible and granular security management scheme. Between two hosts, IPSec can be configured to use separate encrypted tunnels for each IP-level flow; alternatively, it can be configured to use one secure tunnel for all traffic. The choice between these two is a security management choice, and the IPSec protocol defines a concrete management interface and scheme for enabling such choices.
IPSec is a tremendous work of engineering, and we could devote an entire textbook to its design and implementation. IPSec is well-supported in MS Windows since Windows Vista, Mac OS X, and Linux. IPSec is the primary protocol used to enable VPN access to remote networks. While this discussion has limited length and depth, the introduction to concepts should prepare you to dive into an existing implementation should the opportunity to do so ever arise.
Two-Factor Authentication
In computer-related security, often the desired goal is to make security violations impossible. Alas, we know that security is a consequence of people, process, and technology, and as long as this is the case security violations will always be possible.
A more practical goal is to make security violations more difficult to commit and therefore less common through time. One of the most practical steps that can be taken is to increase the difficulty of appropriating a digital identity.
In secure communications, a digital identity—whether it belongs to a person, machine, or other resource—must be authenticated. Previously, we discussed authentication method–based passwords and keys. We don’t know who first said it, but it is often said that authentication methods can be based on the following categories.
• Something you know. Examples include passwords and pass phrases.
• Something you have. Private keys paired with public keys and cryptographically shared secrets are examples. Other examples include physical devices with similar secrets inside, such as smart cards and security dongles.
• Something you are. Examples include biometric traits such as fingerprints and iris patterns.
In an attempt to increase the difficulty involved with defrauding authentication schemes, some organizations and systems rely upon two-factor authentication in which users must authenticate their identity using evidence from two of the categories above.
For instance, a user upon login may need to provide both their personal pass phrase and a piece of information signed with their private key. In this way, an impersonator would need to both know the password and have possession of the private key.
Why two factors and not three, or more? Well, it turns out that the biometric factors are either too unreliable or too costly to gain widespread adoption. So, while multi-factor authentication may be an appropriate generalization, two-factor authentication is the practical and more specific name.
Two-factor authentication is worth considering in the design of embedded systems. The use of both passwords and keys can make an attacker’s job harder, and that is a positive step as long as the intended use of the system is not diminished substantially, say, by burdening users with so much authentication effort that it reduces the utility of the embedded system.
Major Categories of Security Attacks
The preceding discussion has introduced methods and protocols for securing digital information and communications. We now turn out attention to the methods of attack that are most commonly exploited. Our aim is not to convert you to the dark side, but to inform you of how machines are exploited in order to help you engineer more secure systems.
In the following discussion, we will cover four significant categories of attack: buffer overflow, SQL injection, denial of service, and social engineering. All but the last are technically oriented attacks that target deficiencies in systems. The final one, social engineering, is non-technical in nature and seeks to subvert people or processes.
Buffer Overflow
The first category of attacks is stack buffer overflow, in which the stack-based execution model of many programming languages, like C and C++, is subverted to transfer control of execution to an externally provided program. The earliest and most public Internet-based security violation, the so-called Morris worm, which was a first in many categories beyond stack buffer exploits, relied upon it. Buffer overflow attacks are, alas, alive and well today, so they make a good starting point for this discussion.
To begin, consider the following typical implementation of the C standard library function strcpy, which copies the contents of a string to a destination string variable.
1 char ∗strcpy(char ∗dest, const char ∗src)
2 {
3 unsigned lcv;
4 for (lcv=0; src[lcv] != '�'; ++i)
5 dest[lcv] = src[lcv];
6 dest[lcv] = '�';
7 return dest;
8 }
This code works as advertised. The buffer dest will contain whatever buffer src contains, up to the first occurrence of the null character ‘�’, which is used to terminate strings in C.
The trouble with this code is that it takes no steps determine whether the buffer dest, the destination variable, is large enough to contain the string contents of src. And it is precisely this trait that can be exploited.
In a language like C, local variables are allocated on a stack data structure. Indeed, as you may understand very well if you have had a systems software course, C and other programming languages use a stack to implement procedure calls. Each invocation of a function gets its own region of a stack dynamically at run time; these regions on the stack are called stack frames. To implement function calls, the C compiler adds setup and teardown code before each function call, with the purpose of managing the stack. When a function uses local variables, those are allocated by the compiler on the stack frame. It is in this way that functions can call themselves without getting confused about what each occurrence of a local variable should contain. The shape of a stack and its frames are illustrated in Figure 14.2A.
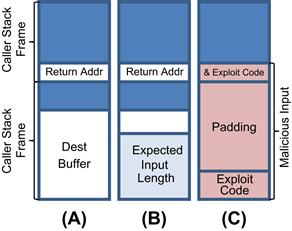
FIGURE 14.2 Illustration of Stack Buffer Overflow. (A) A normal stack frame. (B) A stack frame with an input variable within the bounds of the allocated stack buffer. (C) A stack frame with an input variable that is longer than the allocated stack buffer. In this case, the malicious input begins with assembly encoded executable exploit code, some padded bytes, and ends with the address of the beginning of the exploit code. This final address overruns the return address of the previous stack frame and, hence, will turn control of the flow of execution over to the exploit code.
One piece of information that must be included in any stack frame that calls another function is the return address: the address of the instruction that should be executed once the function call has finished.
Now, we come to the intersection of the destination buffer in strcpy and the stack. The variable dest, if it is a local variable, has a static declaration and some fixed size. If that size is sufficient to contain the string data found in buffer src, then all is well. This situation is depicted in Figure 14.2B.
If, however, the buffer dest is too small, then the contents of src will overrun dest and begin to overwrite data that immediately precede it on the stack. This type of buffer overflow of stack-based variables can easily corrupt the stack-management information stored on the stack, including the return address.
As illustrated in Figure 14.2C, if an attacker has the ability to provide arbitrary input to a program that calls strcpy in this way (it can be something as innocuous as asking for a user name on a web form), the attacker can assemble an input string that contains malicious executable code at the beginning and the starting address of that executable code at the end and that is just long enough to ensure that the malicious address overwrites the return address in the previous stack frame.
Of course, it may be difficult for an attacker to know in advance what address on the stack will be used for the destination variable. Ultimately, an attacker targeting a buffer overflow vulnerability needs to know two things: (1) how to get input to the vulnerability and (2) how to control a return address. Some programs, particularly older ones, have easily reverse-engineered stack behavior. More recently, methods have been used to randomize stack locations and activities in order to prevent such attacks.
Ultimately, however, the best way to avoid such attacks is to always check the bounds of arrays and buffers. As an embedded systems developer, you will want to make sure that none of the software you’ve written, and that none of the software you include in your system that has been written by others, copies input strings from one buffer to another without verifying that the destination buffer is large enough.
In fact, this introduces a principle worth remembering: always verify input values. Whenever possible, you should never trust that any assumptions made about user input are true. Instead of trusting assumptions, validate those assumptions with dynamic verification in your code. This principle applies to our next attack type as well.
SQL Injection
Many of today’s information services and devices rely on databases to keep structured information organized. Structured Query Language, or SQL, is the domain-specific language used to create, manage, and interact with database systems. More specifically, SQL is the language for relational databases, which are databases in which information is decomposed and represented by tables with columns that refer to one another in order to express relationships between data. For many years now, relational databases have been the most important and popular type of database; hence, SQL is the language of choice for managing structure data.
In particular, web sites and web applications are database driven. As mentioned previously, many classes of embedded systems use embedded web servers to provide user interfaces, to provide access to service APIs, and to export and import data.
In web applications that require user logins and associate stored data with individual users, this information and their relationships will be concretely managed by the use of a database. When a user signs in on a web form, one that is likely secured via HTTPS and TLS, the user name and password are compared to what is stored in the application’s database. If a matching user name and password are found in the database, then the user is allowed to log in.
To do this, the database could, for example, contain a table called Users with columns Userid, First_Name, Last_Name, and Password. Given this table layout, the web application might include a string like the following that contains the SQL query that returns the table record associated with this user.
login_stmt =
"SELECT ∗
FROM Users
WHERE Userid = '" + userid_input + "';"
In this SQL statement, the variable userid_input would come from the input form. If the user enters ‘alice’ as the login ID, then userid_input would be set to that value and the query would correspond to the following.
login_stmt =
"SELECT ∗
FROM Users
WHERE Userid = 'alice';"
So, as you can see, this query changes based on the input assigned to the variable userid_input. Let’s suppose for a moment that someone were to enter the this string: ‘; DROP TABLE Users;--’ ?
login_stmt =
"SELECT ∗
FROM Users
WHERE Userid = ''; DROP TABLE Users;-- ';"
The resulting SQL query is a dangerous one! Thanks to this ‘injection of SQL’ into the query, it is now a compound statement that contains two SQL statements. The SELECT statement is terminated by the first semicolon. The second SQL statement, as is clear even if you are new to SQL, proceeds to drop the Users table. In SQL, a double-dash is the comment operator; so, the double-dash following the second semicolon turns the rest of the line into a comment. Hence, there are no SQL syntax errors.
The vulnerability here, as with the buffer overflow example discussed above, is due to the unexamined use of user input. In this case, the user input is used in its literal form as a string input to an SQL query. Any database system that does this is vulnerable to SQL injection attacks. In addition to destroying information, as in the example above, SQL statements can be inserted that create new users, write new files to web directories, or modify user names, passwords, or email addresses.
As you might expect, an attacker still has work to do. For example, an attacker must somehow learn about table and column names used in the database. However, many important and otherwise well-protected systems have fallen prey to this attack. The key in avoiding this vulnerability is to sanitize and verify all user input before putting it to use.
Denial of Service
A denial of service attack has a different aim as compared to the attack types we have discussed so far. Rather than attempting to violate the confidentially or integrity of a system, a denial of service attack, or DOS attack, targets its availability.
There are at least three broad categories for DOS attacks: resource exhaustion, resource interruption, and active interference. Let’s consider each in turn.
The most public, and arguably most common, DOS attack aims to exhaust a resource. For example, consider a modestly provisioned web server. Many web server applications will exhibit sharp performance drop-offs as the number of concurrent connections approaches 1000 or so. To perform this style of DOS attack on such a server, an attacker must find a way to generate many thousands of connection requests per second. This can be achieved by writing high-performance software to generate such requests from a few machines or by directing a large number of hosts to make lower-rate requests of the server. Either can achieve the desired effect, because it is the product of the number of machines and their average request rate that determines the level of traffic seen at the server.
An excessive and ultimately disabling load on a web server is one form of resource-exhausting DOS attack, and there are others. A similar method can be used to exhaust the network bandwidth available to a target server or network; all that is required is that that attacker have greater aggregate network bandwidth than the target.
A subtler form of resource exhaustion attack targets an end host’s operating system. By sending carefully malformed TCP packets, it is possible to create a large number of TCP connections on a target computer that are in a semi-open state. In one particular method, called a SYN flood, the attacker sends TCP/SYN packets to the target machine with false (or “spoofed”) source IP addresses. By adhering to the TCP protocol, the machine under attack sends a TCP/SYN-ACK packet to the forged address. These packets, of course, never get a reply, and so the connection sits in a semi-open state until a timeout expires.
Ultimately, any end host has capacity for a fixed number of open TCP connections, and if an attacker can a open a large number of illegitimate connections, then legitimate communication requests on the host may be denied.
With resource interruption DOS attacks, a target is rendered ineffective by interrupting access to a key resource or service. With Internet-connected devices, the Domain Name Service, or DNS, is a critically important service. DNS, as we know, translates between Internet names and addresses, and if an attacker is able to a interrupt a device’s or network’s access to DNS, then many services will be rendered unavailable and many remote systems will become unreachable.
The final form of DOS attack concerns active interference. Most well-known instances of this attack once again rely upon features of the TCP protocol. If an attacker has the ability to both identify the destination IP addresses and ports used by a target machine and forge illegitimate packets that appear to come from those destination IP addresses, then the attacker can shut down individual TCP connections. This is done by sending to the machine under attack a TCP/RESET packet with a forged packet appearing to come from a legitimate destination machine. If the machine under attack has an open TCP connection with the forged address, the TCP/RESET packet will terminate it immediately.
Social Engineering and Phishing
What is the best way for attackers to obtain unauthorized access to systems or information? Evidence increasingly suggests that simply asking for it is the best attack. This approach is particularly attractive when a specific individual or organization is the target.
Social engineering refers to largely non-technical attacks that aim to trick suspects into divulging their secrets. Such scams are often perpetrated via telephone. Consider the following script.
Hello, my name is Bob Lastnamé with Big Credit Card, Co. We’ve noticed an irregularity in your account and we have temporarily suspended it in order to protect you. To unlock your account, I just need to ask you some questions about your recent purchases. First, however, I need to make sure that I am talking to the right person. Let’s verify your name, then I’ll need to verify your account number, expiration date, and CVV code....
Now, you may not fall for such a trick, but some certainly may. And, more to the point, how many attempts across 100 arbitrary users would you expect to be successful?
Such tricks are far more effective than we would like them to be. In recent decades, there has been a dramatic rise in email-based social engineering incidents. After all, it is now quite easy to send 1 million email messages or have VoIP systems make 1 million automated phone calls. When someone sends a forged digital message in an attempt to get you to divulge secrets, we call that a phishing attack. Rather than requesting an email reply, such requests typically include links to web forms where personal information is solicited. In such attacks, both the email message and the corresponding web form are typically designed to look legitimate.
Attacks like these are extremely difficult to prevent because they derive their leverage from tricking uninformed, confused, busy, or unlucky people.
Firewalls
Some of the attack types discussed above appear to exploit inherent characteristics of the Internet protocols. DOS attacks, for example, are possible by virtue of how the Internet works. In the Internet, any machine can send packets to any other machine, and the protocols are designed to make that not only possible but also scalable and efficient. DOS attacks, particularly the resource exhaustion exploits, leverage this fact.
Firewalls block packets. A firewall is a device or software layer that filters out packets based on a set of rules that define which packets can be allowed through and which should be dropped.
Firewalls are perhaps best known as stand-alone network appliances that are placed at network boundaries and enforce the network’s access policies. In addition, most operating systems ship with host-based firewall software that can be used to limit what type of network traffic can reach the host operating system. These firewalls operate within the system software, beneath the operating system networking stack. You might argue that it is still part of the operating system, which is technically true, but it is low enough in the packet processing sequence that drop decisions can be made before any system resources are allocated or consumed to handle arriving packets. This is low enough, for example, to avoid the threat of SYN flood attacks.
Linux includes a flexible and effective firewall. In fact, not only do most production Linux machines rely on it in one way or another, many organizations deploy a Linux-based device as their production firewall! Such systems cannot match the performance or range of features of some custom-designed firewall systems, but the price-performance cannot be beat. If your embedded system is Linux-based, it is likely that iptables will play an important role in its security.
The Linux iptables subsystem is built around the concepts of rules and chains. A rule is a combination of a packet filter and an action. The filter describes how it matches a packet; the action specifies what to do when a match is found. A chain is simply a linear sequence of rules. Let’s look at an example of a command line that makes these ideas concrete.
$ sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPT
In this line, the iptables command (which requires admin privileges, and typically lives at /sbin/iptables) is appending (-A) to a chain called INPUT, which is one of the five pre-defined chains. To match this rule, a packet must be a TCP packet (-p tcp) destined for port 80 (--dport 80), regardless of the interface on which it arrived. When a packet matches the rule, it is accepted into the system for protocol processing (-j ACCEPT). If a packet does not match the rule, it is evaluated against the next rule in the chain.
We will shortly walk through a scenario that secures access to a Linux machine under a sample set of access policy assumptions, but first we need to discuss some additional iptable concepts and details. First, as previously mentioned, there are five default chains created by the system. As admin, you can create additional chains, but the default chains correspond to the packet entry points in the system. They correspond, in fact, to the API of the underlying packet filtering mechanism, Netfilter, in Linux. The default chains are as follows.
• INPUT. Packets that have arrived at the system and are destined for the local IP address are processed by the INPUT chain.
• OUTPUT. Packets created on this host and sent from it are processed by the OUTPUT chain.
• FORWARD. When the system is configured as a router, packets may arrive at the machine that are destined for another. Such packets are processed on the this chain.
• PREROUTING. Before the system can decide whether an arriving packet is destined for this host or whether it needs to be forwarded elsewhere, a routing decision must be made. Before this routing decision is made, the arriving packet is processed by the PREROUTING chain.
• POSTROUTING. Before a packet is transmitted, it is processed by the POSTROUTING chain. This is true for both packets generated on this machine and those that are forwarded by this machine.
The preceding explanation makes clear that each packet will be processed by multiple chains. Upon arrival, all IP packets will be processed by the PREROUTING chain, and then, if it hasn’t been dropped, either by the INPUT or FORWARD chains. Likewise, on output, all IP packets will be processed on the POSTROUTING chain after making their way through either the OUTPUT or FORWARD chains. As an introduction, this description will suffice. As you may later discover, Linux networking has a rich set of features, including network address translation, and a deeper exploration would reveal that each packet traverses these chains more than once.
Packet matching conditions, or filters, can be expressed in terms of packet header-level details, such as addresses and ports. In iptables, they can also include the state of connections. When a firewall supports rules that are depending on the state of TCP/IP connections, it is said to be a stateful firewall. Otherwise, it is a stateless firewall.
In the example command line above, the action was to accept (-j ACCEPT) the packet for further network stack processing. The command line switch –j, in fact, means “jump.” In addition to specifying a final decision like ACCEPT, the switch also allows the transfer of processing to another user-defined chain. When –j is used in this way, the target chain will be processed, and unless an authoritative decision is reached there, it will return to this point in the original chain for further process. If this behavior is undesired, the –g or “goto” switch can be used to avoid returning to the original chain. These call and branch mechanisms allow the creation of extremely expressive packet processing routines.
There are several authoritative decisions that can be made, but the most important for us to understand at this point are ACCEPT, DROP, REJECT, and LOG, as described below.
• ACCEPT. The ACCEPT target directs iptables to allow the matching packet to continue along the packet processing path. Conceptually, this means allowing the packet to continue to work its way through the Linux network layer.
• DROP. The DROP target indicates that the system should delete the packet without sending any return notification to the sender.
• REJECT. The REJECT target, by contrast, attempts to send a failure notification to the sender. The specific type of notification can be declared explicitly or can be determined by default in some chains. For example, the system can generate an icmp-host-unreachable message. Most secured systems eschew used of the REJECT target, because it can serve as an aid to a probing attacker.
• LOG. The LOG target directs iptables to emit a system log message and continue processing the chain. You can set a log level (--log-level) and prefix (--log-prefix) that will determine which system log the message will appear in and how it should appear. Log level 7, perhaps the most common choice, will cause the messages to appear in /var/log/debug. To avoid filling logs unnecessarily, parameters are available to limit how often each type of message should be logged within a time interval.
With this background understanding in place, we can now consider an example of how to use iptables to secure access to a Linux-based, Internet-connected device.
Let’s suppose that our target system is an embedded one that provides a secure, HTTPS-based web interface to its users, whose Internet addresses change through time. Furthermore, let’s assume that we are responsible for the remote management of the device and that we will use ssh for remote login and administration.
To secure our system, we begin by checking the current configuration of the rules in iptables. If you are using a freshly installed system that has not been administered by anyone else, you will likely see the following.
$ sudo iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
By using the –L switch, we see that our there are no rules currently active on the default chains. Moreover, we see that the default behavior on each chain is to ACCEPT. So, Linux accepts traffic by default. To see the contents of the PREROUTING and POSTROUTING chains, you must also add the “–t nat” switch.
The following listing of iptables commands will configure our firewall according to our policies.
1 sudo iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
2 sudo iptables -A INPUT -i lo -j ACCEPT
3 sudo iptables -A INPUT -s 10.10.10.10 -p tcp --dport 22 -j ACCEPT
4 sudo iptables -A INPUT -p tcp --dport 443 -j ACCEPT
5
6 sudo iptables -P INPUT -j DROP
7 sudo iptables -P FORWARD -j REJECT
8 sudo iptables -P OUTPUT -j ACCEPT
The first four lines append rules to the INPUT chain and explicitly indicate which forms of traffic we want to actively admit to our system.
The first line contains a stateful matching rule (-m conntrack). Specifically, the rule says that any connections with a state that is established and related to an existing connection will be allowed. This allows connections originated by our device to receive inbound traffic; it does not allow externally initiated connections to pass.
The second line makes use of the interface switch, -i lo, and admits all inbound traffic on the local interface. This allows processes and programs active on the machine to communicate with one another. If we did not explicitly allow this, our later restriction rules (i.e., line 6) would ensure that processes could not communicate with one another over IP.
The third and fourth lines are like the ones we have seen earlier. Traffic on port 22, ssh traffic, is accepted provided that it is from remote IP 10.10.10.10 (this is a non-routable, private IP address used here for illustration only) and using the TCP protocol. Line 4 allows anyone to send TCP packets to port 443, in order to enable Internet access on the HTTPS port.
The first four rules express what types of traffic we want to admit into the system. The final three lines cover the remainder. Line 6 tells the system to drop all inbound traffic that has not already matched our accept rules. Line 7 ensures that the device does not act as a router. Line 8 explicitly enables outbound traffic.
Over time, the rules in iptables can grow complex. One way to keep track of its state, and the intention of the rules, is to maintain a commented script that includes everything. The utilities iptables-save and iptables-restore can also be used to save and restore snapshots of the currently active iptables configuration.
Servers and Logs
We conclude our discussion of building blocks and concepts with what amounts to a mention of good habits.
Even if you take every available precaution, and put in place every available preventative measure, you should expect the unexpected. The very nature of emerging security vulnerabilities is that they were not known prior to their exploitation. As such, you should prepare your systems as best you can, but be prepared to quickly respond to the unexpected.
One of the best ways to be prepared to respond is to maintain orderly logs of system activity. As you likely know, all major operating system features and applications optionally maintain logs of their activity. While each logging feature has its own set of configuration options, there is no better way to keep tabs on your system and its operation than by maintaining and monitoring logs of system activity. The following list represents a starting point for what your embedded system should probably be logging and monitoring.
• Failed login attempts. All operating systems maintain logs of login attempts. In Linux, you will likely find the log in /var/log/auth.log.
• Web server and database access logs. Attempts to extract information from web-based services are most likely to leave some indication in web server logs and any related database logs. The popular combination of Apache and MySQL would by default lead to logs left in /var/log/apache2 and /var/log/mysql, respectively.
• Firewall logs. As described above, logs can be maintained for the iptables firewall, in order to keep track of how often various rules are matched.
A good practice is to put in place an automated system for collecting, analyzing, and archiving these logs. For attacks that involve probing and brute force password guessing, often the size of the log file alone can serve as an alarm.
By extension, you should also consider the logging features of any application or systems software you develop yourself. As developers, we think of logs primarily as debugging tools, but, increasingly, they are proving to play an important role in system security.
Platform Support for Security
Given the importance of security in modern embedded and computer systems, it is natural to ask if hardware support in the platform can play a role in assisting or accelerating security related tasks. The answer is certainly yes! There are two broad categories of platform support for security.
In the first category, hardware implementations of security mechanisms are provided in order to reduce the computation burden of encryption. In modern systems, we know that most secure data are transmitted after having been encrypted via symmetric-key cryptography. By their nature, cryptographic algorithms are computationally heavy. Since multiple computations are carried out for each byte of the payload, the computational overhead for medium-to-large data volumes can be substantial. Many systems include hardware accelerators to aid in these bulk encryption/decryption tasks. Other hardware assists include random number generators, cryptographic signature units, and public-private key pair generators.
The second category is a broader one, one that not only supports cryptographic algorithms, but aims to manage and orchestrate a platform-wide security solution. The best known such solution goes by the name Trusted Computing, and is the outspring of a collaboration of many of the largest companies in the Windows and PC ecosystem, referred to collectively as the Trusted Computing Group, or TCG. The stated goal of Trusted Computing (which may well also apply to the lower-case version of the phrase) is to enable systems to consistently behave in expected ways and to enable the system hardware and software to verify the correct behavior and the integrity of the system. In other words, their goal is to enable systems to boot into an authenticated and known state and to allow the system software and operating system to continue to bring the system up to known secures states free of any tampering.
The core leverage of the Trusted Computing specifications comes from hardware-based trust. The Trusted Platform Module, or TPM, is a hardware component added either to the motherboard of computer system or as a unit on a system-on-a-chip. The Trusted Computing Group’s specifications for a TPM include the hardware support for cryptographic algorithms as discussed above. They also include additional operational features critical to achieving the stated goal of verifiable system integrity.
First, the TPM module includes a built-in, burnt-in public-private key pair. This fact, coupled with the ability to sign data provided to it, means that the TPM is capable of authenticating its unique identity. This ability is referred to as remote attestation in the TCG specifications (but we simply think of it as authentication).
The TPM module specifications have other features and roles, but, to date, it seems that the dominant use of TPM has been to support full-disk encryption in recent MS Windows OS versions.
The Trusted Computing movement has its critics. The main objection offered by some observers is that the mechanisms provided by Trusted Computing can potentially be used for other ends, beyond maintaining the integrity of the end system. For instance, who has the authority to request that a remote system authenticate itself via the TPM remote attestation scheme? While there are many valid scenarios one can imagine, it is also possible that this scheme could be abused and used for end host and user tracking, which is beyond the scope of Trusted Computing.
Summary
In this chapter, we have introduced some of the major concepts and tools that all embedded engineers should understand. This discussion has only scratched the surface but will provide you with the literacy and orientation needed to explore individual subjects more deeply in your future coursework and projects.
When developing embedded systems, correct function is rightly a primary concern, but all developers should consider security to be a major component of the “correct function” of a system. The reason is simple: a major security weakness may render a system unusable, even if it does all else.
Unfortunately, there are few absolutes in the security of computer systems. There is no security silver bullet, and there is no such thing as an impermeable security barrier. Instead, engineers must make the best of it, given the understanding and tools of the day.