
In Chapter 7, you learned how to use the AVX instruction set to perform packed integer operations using 128-bit wide operands and the XMM register set. In this chapter, you learn how to carry out similar operations using AVX2 instructions with 256-bit wide operands and the YMM register set. Chapter 10’s source code examples are divided into two major sections. The first section contains elementary examples that illustrate basic operations using AVX2 instructions and 256-bit wide packed integer operands. The second section includes examples that are a continuation of the image processing techniques first presented in Chapter 7.
All of the source code examples in this chapter require a processor and operating system that supports AVX2. You can use one of the free utilities listed in Appendix A to verify the processing capabilities of your system.
Packed Integer Fundamentals
In this section, you learn how to perform fundamental packed integer operations using AVX2 instructions. The first source code example expounds basic arithmetic using 256-bit wide operands and the YMM register set. The second source code example demonstrates AVX2 instructions that carry out integer pack and unpack operations. This example also explains how to return a structure by value from an assembly language function. The final source code example illuminates AVX2 instructions that execute packed integer size promotions using zero or sign extended values.
Basic Arithmetic
Example Ch10_01
The C++ function Avx2PackedMathI16 contains code that demonstrates packed signed word arithmetic. This function begins with the definitions of YmmVal variables a, b, and c. Note that the C++ specifier alignas(32) is used with each YmmVal definition to ensure alignment on a 32-byte boundary. The signed word elements of both a and b are then initialized with test values. Following variable initialization, Avx2PackedMathI16 calls the assembly language function Avx2PackedMathI16_, which performs several packed arithmetic operations. The results are then streamed to cout. The C++ function Avx2PackedMathI32 is next. The structure of this function is similar to Avx2PackedMathI16, with the main difference being that it exercises packed doubleword operands.
On systems that support AVX2, most of the instructions exercised in this example can be used with a variety of 256-bit wide packed integer operands. For example, the vpadd[b|q] and vpsub[b|q] instructions carry out addition and subtraction using 256-bit wide packed byte or quadword operands. The vpaddsb and vpsubsb instructions perform signed saturated addition and subtraction using packed byte operands. The instructions vpmins[b|d] and vpmaxs[b|d] calculate packed signed minimums and maximums, respectively. The variable bit shift instructions vpsllv[d|q], vpsravd, and vpsrlv[d|q] are new AVX2 instructions. These instructions are not available on systems that only support AVX.
Pack and Unpack
Example Ch10_02
The C++ code in Listing 10-2 begins the declaration of a structure named YmmVal2. This structure contains two YmmVal members: m_YmmVal0 and m_YmmVal1. Note that the alignas(32) specifier is used immediately after the keyword struct. Using this specifier ensures that all instances of YmmVal2 are aligned on a 32-byte boundary including temporary instances created by the compiler. More on this in a moment. The assembly language function Avx2UnpackU32_U64_, whose declaration follows, returns an instance of YmmVal2 by value.
The C++ function AvxUnpackU32_U64 begins by initializing the unsigned doubleword elements of YmmVal variables a and b. Following variable initialization is the statement YmmVal2 c = Avx2UnpackU32_U64_(a, b), which calls the assembly language function Avx2UnpackU32_U64_ to unpack the elements of a and b from doublewords to quadwords. Unlike previous examples, Avx2UnpackU32_U64_ returns its YmmVal2 result by value. Before proceeding, it is important to note that in most cases, returning a user-defined structure like YmmVal2 by value is less efficient than passing a pointer argument to a variable of type YmmVal2. The function Avx2UnpackU32_U64_ uses return-by-value principally for demonstration purposes and to elucidate the Visual C++ calling convention protocols that an assembly language function must observe when returning a structure by value is warranted. The remaining statements in AvxUnpackU32_U64 stream the results from Avx2UnpackU32_U64_ to cout.
Following AvxUnpackU32_U64 is the C++ function Avx2PackI32_I16. This function initializes the signed doubleword elements of YmmVal variables a and b. These values will be size reduced to packed words. Subsequent to YmmVal variable initialization, Avx2PackI32_I16 calls the assembly language function Avx2PackI32_I16_ to carry out the aforementioned size reduction. The results are then streamed to cout.
The calling convention that Visual C++ uses for functions that return a structure by value varies somewhat from the normal calling convention. Upon entry to the assembly language function Avx2UnpackU32_U64_, register RCX points to a temporary buffer where Avx2UnpackU32_U64_ must store its YmmVal2 return result. It is important to note that this buffer is not necessarily the same memory location as the destination YmmVal2 variable in the C++ statement that called Avx2UnpackU32_U64_. In order to implement expression evaluation and operator overloading, a C++ compiler often generates code that allocates temporary variables (or rvalues) to hold intermediate results. An rvalue that needs to be saved is ultimately copied to a named variable (or lvalue) using either a default or overloaded assignment operator. This copy operation is the reason why returning a structure by value is usually slower than passing a pointer argument. The alignas(32) specifier that’s used in the declaration of struct YmmVal2 directs the Visual C++ compiler to align all variables of type YmmVal2 including rvalues on a 32-byte boundary.
The caller of a function that returns a large structure by value must allocate storage space for the returned structure. A pointer to this storage space must be passed to the called function in register RCX.
The normal calling convention argument registers are “right-shifted” by one. This means that the first three arguments are passed using registers RDX/XMM1, R8/XMM2, and R9/XMM3. Any remaining arguments are passed on the stack.
Prior to returning, the called function must load register RAX with a pointer to the returned structure.
If the size of a return-by-value structure is less than or equal to eight bytes, it must be returned in register RAX. The normal calling convention argument registers are used in these situations.
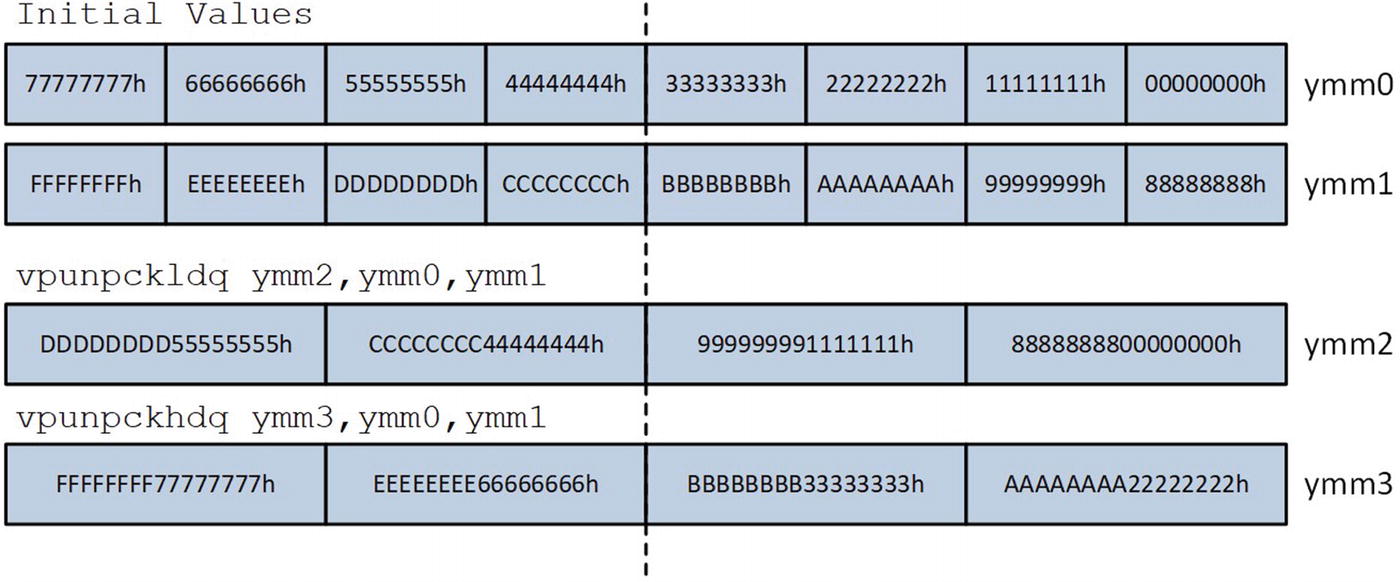
Execution of the vpunpckldq and vpunpckhdq instructions
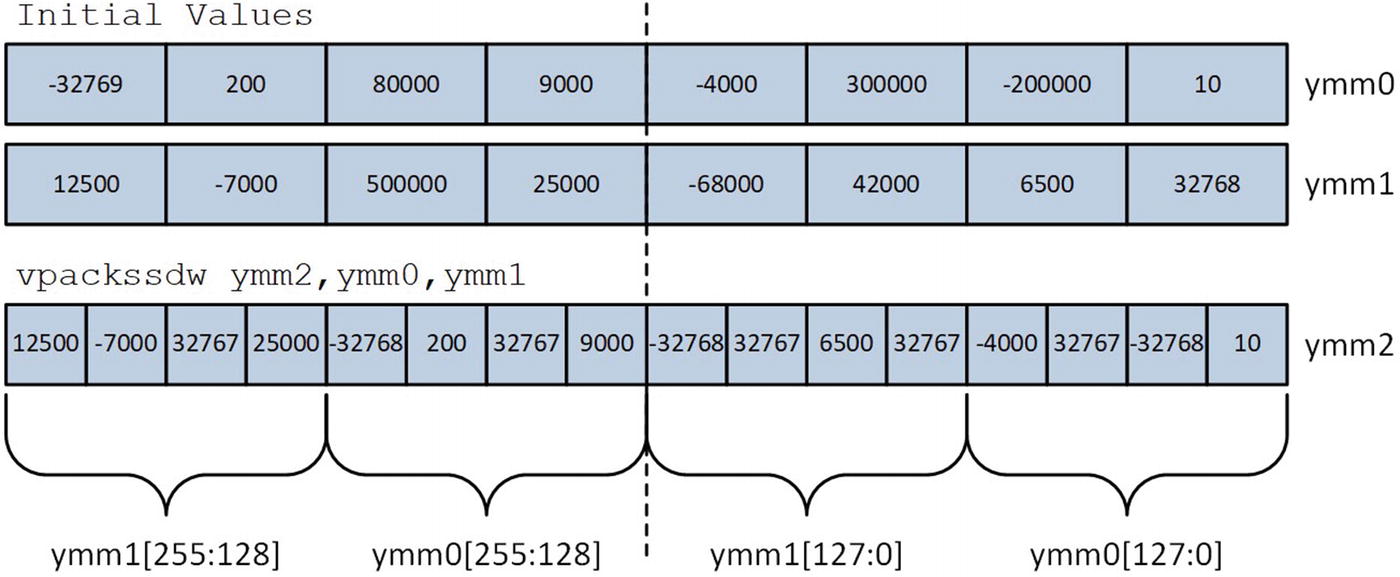
Execution of the vpackssdw instruction
Size Promotions
Example Ch10_03
The C++ code in Listing 10-3 contains four functions that initialize test cases for various packed size-promotion operations. The first function, Avx2ZeroExtU8_U16, begins by initializing the unsigned byte elements of YmmVal a. It then calls the assembly language function Avx2ZeroExtU8_U16_ to size-promote the packed unsigned bytes into packed unsigned words. The function Avx2ZeroExtU8_U32 performs a similar set of initializations to demonstrate packed unsigned byte to packed unsigned doubleword promotions. The functions Avx2SignExtI16_I32 and Avx2SignExtI16_I64 initialize test cases for packed signed word to packed signed doubleword and packed signed quadword size promotions.
The first instruction in the assembly language function Avx2ZeroExtU8_U16_, vpmovzxbw ymm0,xmmword ptr [rcx], loads and zero-extends the 16 low-order bytes of YmmVal a (pointed to by register RCX) and saves these values in register YMM0. The ensuing vpmovzxbw ymm1,xmmword ptr [rcx+16] instruction performs the same operation using the 16 high-order bytes of YmmVal a. The function Avx2ZeroExtU8_U16_ then uses two vmovdqa instructions to save the size-promoted results.
The assembly language function Avx2ZeroExtU8_U32_ performs packed byte to doubleword size promotions. The first instruction, vpmovzxbd ymm0,qword ptr [rcx], loads and zero-extends the eight low-order bytes of YmmVal a into doublewords and saves these values in register YMM0. The three ensuing vpmovzxbd instructions size-promote the remaining byte values in YmmVal a. The results are then saved using a series of vmovdqa instructions. When working with unsigned 8-bit values, it is sometimes (depending on the algorithm) more expedient to use the vpmovzxbd instruction to perform a packed byte to packed doubleword size promotion instead of a semantically equivalent series of vpunpckl[bw|dw] and vpunpckh[bw|dw] instructions. You see an example of this in Chapter 14.
Packed Integer Image Processing
In Chapter 7, you learned how to use the AVX instruction set to perform some common image processing operations using 128-bit wide packed unsigned integer operands. The source code examples of this section demonstrate additional image processing methods using AXV2 instructions with 256-bit wide packed unsigned integer operands. The first source example illustrates how to clip the pixel intensity values of a grayscale image. This is followed by an example that determines the minimum and maximum pixel intensity values of an RGB image. The final source code example uses the AVX2 instruction set to perform RGB to grayscale image conversion.
Pixel Clipping
Example Ch10_04
The C++ code begins with declaration of a structure named ClipData. This structure and its assembly language equivalent are used to maintain the pixel-clipping algorithm’s data. Following the function declarations in the header file Ch10_04.h is the definition of a C++ function named Init. This function initializes the elements of a uint8_t array using random values, which simulates the pixel values of a grayscale image. The function Avx2ClipPixelCpp is a C++ implementation of the pixel clipping algorithm. This function starts by validating num_pixels for correct size and divisibility by 32. Restricting the algorithm to images that contain an even multiple of 32 pixels is not as inflexible as it might appear. Most digital camera images are sized using multiples of 64 pixels due to the processing requirements of the JPEG compression algorithms. Following validation of num_pixels, the source and destination pixel buffers are checked for proper alignment .
The procedure used in Avx2ClipPixelCpp to perform pixel clipping is straightforward. A simple for loop examines each pixel element in the source image buffer. If a source image pixel buffer intensity value found to be below thresh_lo or above thresh_hi, the corresponding threshold limit is saved in the destination buffer. Source image pixels whose intensity values lie between the two threshold limits are copied to the destination pixel buffer unaltered. The processing loop in Avx2ClipPixelCpp also counts the number of clipped pixels for comparison purposes with the assembly language version of the algorithm.
Function Avx2ClipPixels exploits the C++ template class AlignedArray to allocate and manage the required image pixel buffers (see Chapter 7 for a description of this class). Following source image pixel buffer initialization, Avx2ClipPixels primes two instances of ClipData (cd1 and cd2) for use by the pixel clipping functions Avx2ClipPixelsCpp and Avx2ClipPixels_. It then invokes these functions and compares the results for any discrepancies.
Toward the top of the assembly language code is the declaration for data structure ClipPixel, which is semantically equivalent to its C++ counterpart. The function Avx2ClipPixels_ begins its execution by validating num_pixels for size and divisibility by 32. It then checks the source and destination pixels buffers for proper alignment. Following argument validation, Avx2ClipPixels_ employs two vpbroadcastb instructions to create packed versions of the threshold limit values thresh_lo and thresh_hi in registers YMM4 and YMM5, respectively. During each processing loop iteration, the vmovdqa ymm0,ymmword ptr [r10] instruction loads 32 pixel values from the source image pixel buffer into register YMM0. The ensuing vpmaxub ymm1,ymm0,ymm4 instruction clips the pixel values in YMM0 to thresh_lo. This is followed by a vpminub ymm2,ymm1,ymm5 instruction that clips the pixel values to thresh_hi. The vmovdqa ymmword ptr [r11],ymm2 instruction then saves the clipped pixel intensity values to the destination image pixel buffer.
Mean Execution Times (Microseconds) for Pixel Clipping Functions (Image Buffer Size = 8 MB)
CPU | Avx2ClipPixelsCpp | Avx2ClipPixels_ |
|---|---|---|
i7-4790S | 13005 | 1078 |
i9-7900X | 11617 | 719 |
i7-8700K | 11252 | 644 |
RGB Pixel Min-Max Values
Example Ch10_05
The function Avx2CalcRgbMinMaxCpp that’s shown in Listing 10-5 is a C++ implementation of the RGB min-max algorithm. This function employs a set of nested for loops to determine the minimum and maximum pixel intensity values for each color plane. These values are maintained in the arrays min_vals and max_vals. The function main uses the C++ template class AlignedArray to allocate three arrays that simulate the color plane buffers of an RGB image. These buffers are loaded with random values by the function Init. Note that function Init assigns known values to several elements in each color plane buffer. These known values are used to verify correct execution of both the C++ and assembly language min-max functions.
Toward the top of the assembly language code is a custom constant segment named ConstVals that defines packed versions of the initial pixel minimum and maximum values. A custom segment is used here to ensure alignment of the 256-bit wide packed values on a 32-byte boundary, as explained in Chapter 9. The macro definitions _YmmVpextrMinub and _YmmVpextrMaxub are next. These macros contain instructions that extract the smallest and largest byte values from a YMM register. The inner workings of these macros will be explained shortly.
The function Avx2CalcRgbMinMax_ uses registers YMM3-YMM5 and YMM6-YMM8 to maintain the RGB minimum and maximum values, respectively. During each iteration of the main processing loop, a series of vpminub and vpmaxub instructions update the current RGB minimums and maximums. Upon completion of the main processing loop, the aforementioned YMM registers contain 32 minimum and maximum pixel intensity values for each color component. The _YmmVpextrMinub and _YmmVpextrMaxub macros are then used to extract the final RGB minimum and maximum pixel values. These values are then saved to the result arrays min_vals and max_vals, respectively.
The macros definitions _YmmVpextrMinub and _YmmVpextrMaxub are identical, except for the instructions vpminub and vpmaxub. In the text that follows, all explanatory comments made about _YmmVpextrMinub also apply to _YmmVpextrMaxub. The _YmmVpextrMinub macro requires three parameters: a destination general-purpose register (GprDes), a source YMM register (YmmSrc), and a temporary YMM register (YmmTmp). Note that macro parameters YmmSrc and YmmTmp must be different registers. If they’re the same, the .erridni directive (Error if Text Items are Identical, Case Insensitive) generates an error message during assembly. MASM also supports several other conditional error directives besides .erridni, and these are described in the Visual Studio documentation.
In order to generate the correct assembly language code, the macro _YmmVpextrMinub requires an XMM register text string (XmmSrc) that corresponds to the low-order portion of the specified YmmSrc register. For example, if YmmSrc equals YMM0, then XmmSrc must equal XMM0. The MASM directives substr (Return Substring of Text Item) and catstr (Concatenate Text Items) are used to initialize XmmSrc. The statement YmmSrcSuffix SUBSTR <YmmSrc>,2 assigns a text string value to YmmSrcSuffix that excludes the leading character of macro parameter YmmSrc. For example, if YmmSrc equals YMM0, then YmmSrcSuffix equals MM0. The next statement, XmmSrc CATSTR <X>,YmmSrcSuffix, adds a leading X to the value of YmmSrcSuffix and assigns it to XmmSrc. Continuing with the earlier example, this means that the text string XMM0 is assigned to XmmSrc. The SUBSTR and CATSTR directives are then used to assign a text string value to XmmTmp.
RGB to Grayscale Conversion
Example Ch10_06
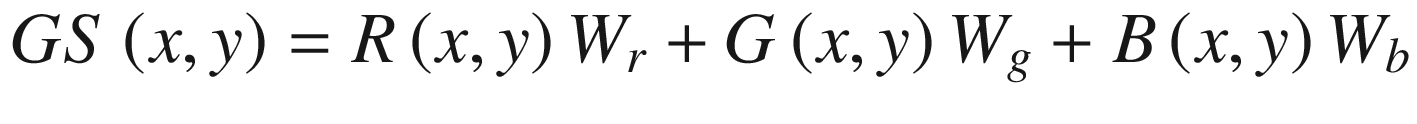
Each RGB color component weight (or coefficient) is a floating-point number between 0.0 and 1.0, and the sum of the three component coefficients normally equals 1.0. The exact values used for the color component coefficients are usually based on published standards that reflect a multitude of visual factors including properties of the target color space, display device characteristics, and perceived image quality. If you’re interested in learning more about RGB to grayscale image conversion, Appendix A contains some references that you can consult.
Source code Ch10_06 opens with the structure declaration RGB32. This structure is declared in the header file ImageMatrix.h and specifies the color component ordering scheme of each RGB pixel. The function Avx2ConvertRgbToGsCpp contains a C++ implementation of the RGB to grayscale conversion algorithm. This function uses an ordinary for loop that sweeps through the RGB32 image buffer pb_rgb and computes grayscale pixel values using the aforementioned conversion equation. Note that RGB32 element m_A is not used in any of the calculations in this example. Each calculated grayscale pixel value is adjusted by a rounding factor and clipped to [0.0, 255.0] before it is saved to the grayscale image buffer pointed to by pb_gs.
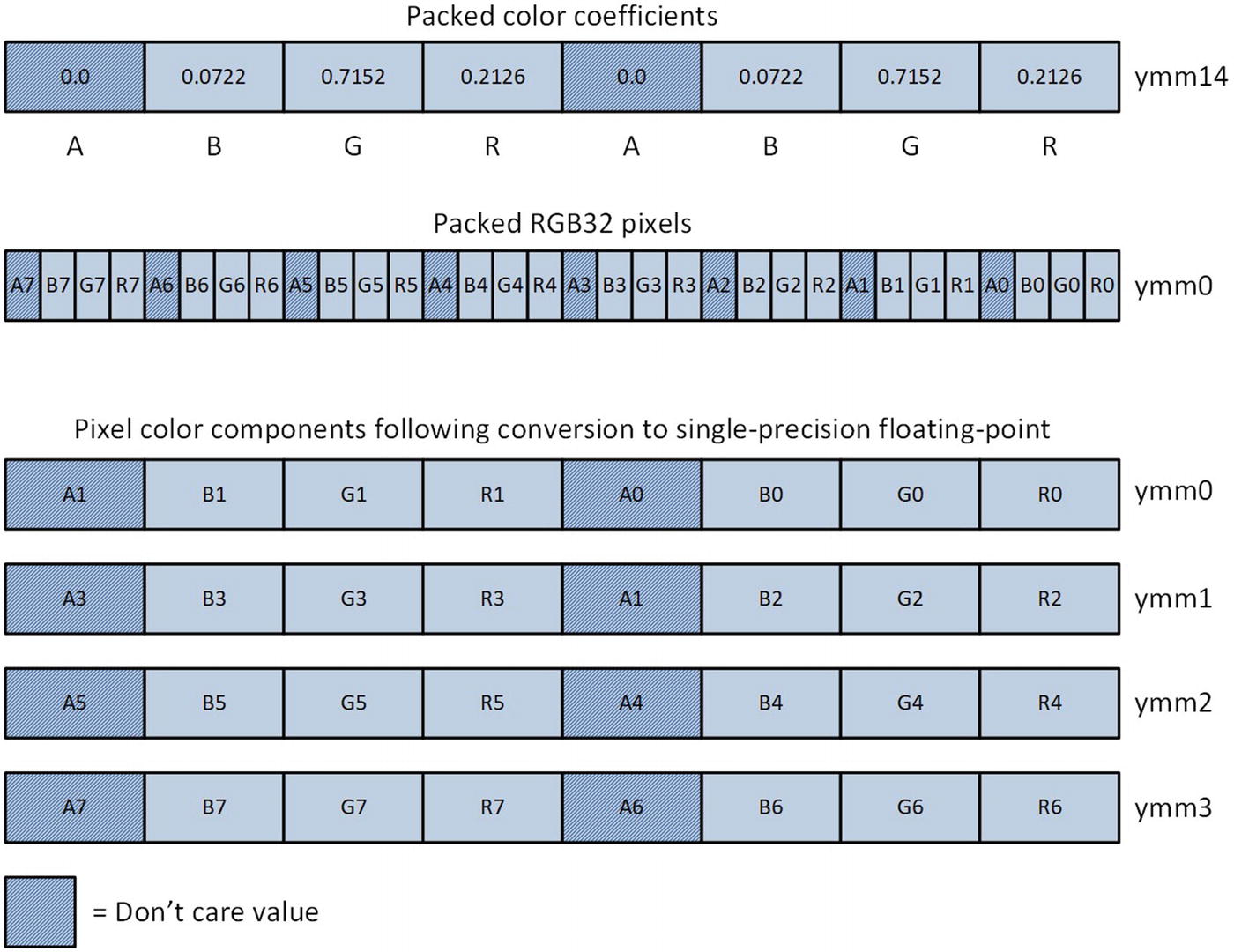
RGB32 pixel color component size promotions and conversions
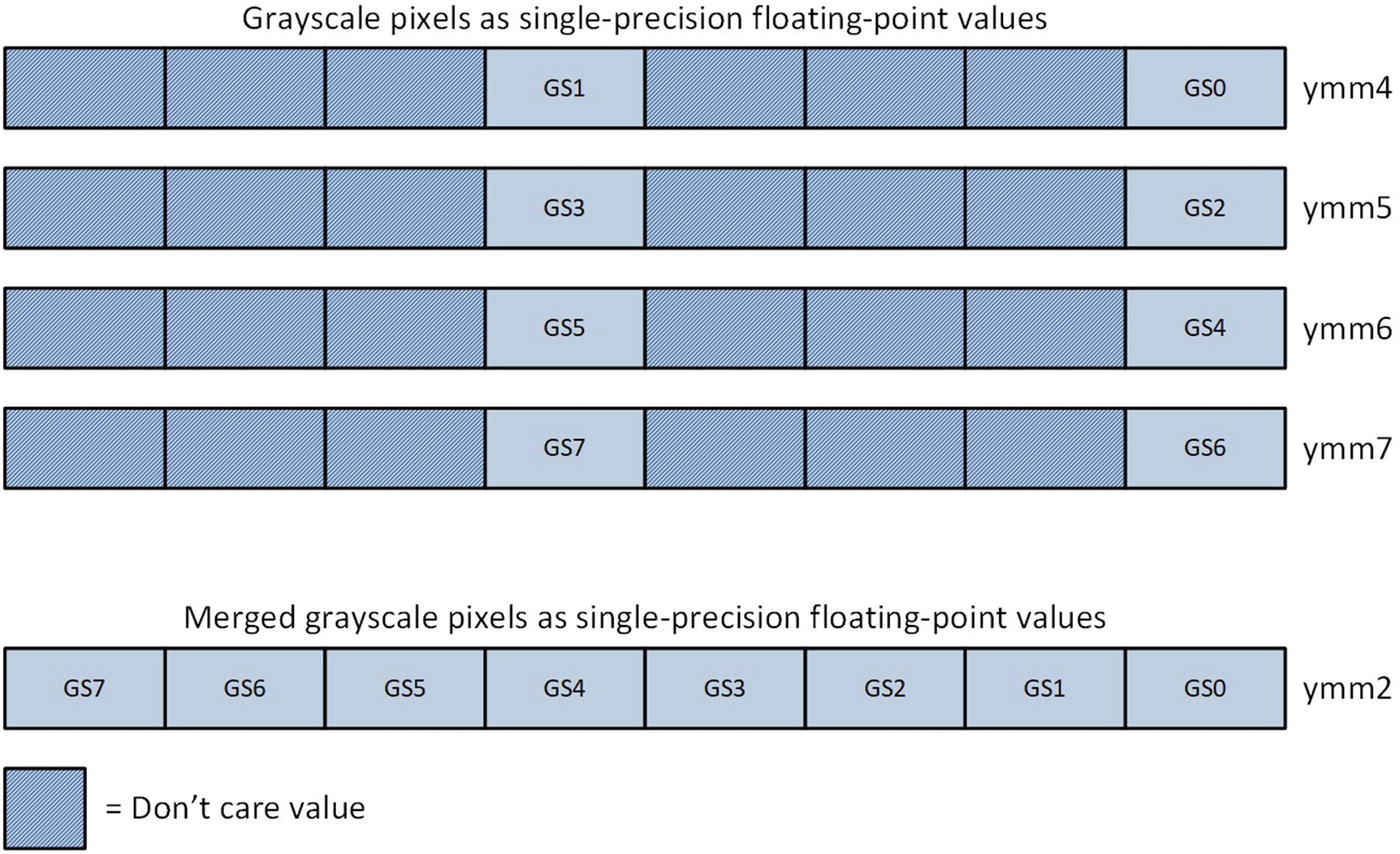
Grayscale single-precision floating-point pixel values before and after merging
Mean Execution Times (Microseconds) for RGB to Grayscale Image Conversion Using TestImage3.bmp
CPU | Avx2ConvertRgbToGsCpp | Avx2ConvertRgbToGs_ |
|---|---|---|
i7-4790S | 1504 | 843 |
i9-7900X | 1075 | 593 |
i7-8700K | 1031 | 565 |
Summary
AVX2 extends the packed integer capabilities of AVX. Most x86-AVX packed integer instructions can be used with either 128-bit or 256-bit wide operands. These operands should always be properly aligned whenever possible.
Similar to x86-AVX floating-point, assembly language functions that perform packed integer calculations using a YMM register should use a vzeroupper instruction prior any epilog code or the ret instruction. This avoids potential performance delays that can occur when the processor transitions from executing x86-AVX instructions to x86-SSE instructions.
The Visual C++ calling convention differs for assembly language functions that return a structure by value. A function that returns a structure by value must copy a large structure (one greater than eight bytes) to the buffer pointed to by the RCX register. The normal calling convention registers are also “right-shifted” as explained in this chapter.
Assembly language functions can use the vpunpckl[bw|wd|dq] and vpunpckh[bw|wd|dq] instructions to unpack 128-bit or 256-bit wide integer operands.
Assembly language functions can use the vpackss[dw|wb] and vpackus[dw|wb] instructions to pack 128-bit or 256-bit wide integer operands using signed or unsigned saturation.
Assembly language functions can use the vmovzx[bw|bd|bq|wd|wq|dq] and vmovsx[bw|bd|bq|wd|wq|dq] instructions to perform zero or sign extended packed integer size promotions.
MASM supports directives that can perform rudimentary string processing operations, which can be employed to construct text strings for macro instruction mnemonics, operands, and labels. MASM also supports conditional error directives that can be used to signal error conditions during source code assembly.