
In Chapter 6, you learned how to use the AVX instruction set to perform packed floating-point operations using the XMM register set and 128-bit wide operands. In this chapter, you learn how carry out packed floating-point operations using the YMM register set and 256-bit wide operands. The chapter begins with a simple example that demonstrates the basics of packed floating-point arithmetic and YMM register use. This is followed by three source code examples that illustrate how to perform packed calculations with floating-point arrays.
Chapter 6 also presented source code examples that exploited the AVX instruction set to accelerate matrix transposition and multiplication using single-precision floating-point values. In this chapter, you learn how to perform these same calculations using double-precision floating-point values. You also study a source code example that computes the inverse of a matrix. The final two source code examples in this chapter explain how to perform data blends , permutes, and gathers using packed floating-point operands.
You may recall that the source code examples in Chapter 6 used only XMM register operands with AVX instructions. This was done to avoid information overload and maintain a reasonable chapter length. Nearly all AVX floating-point instructions can use either the XMM or YMM registers as operands. Many of the source code examples in this chapter will run on a processor that supports AVX. The function names in these examples use the prefix Avx. Similarly, source code examples that required an AVX2-compatible processor use the function name prefix Avx2. You can use one of the freely-available tools listed in Appendix A to determine whether your computer supports only AVX or both AVX and AVX2.
Packed Floating-Point Arithmetic
Example Ch09_01
Listing 9-1 begins with the declaration of a C++ structure named YmmVal that’s declared in the header file YmmVal.h. This structure is similar to the XmmVal structure that you saw in Chapter 6. YmmVal contains a publicly-accessible anonymous union that facilitates packed operand data exchange between functions written in C++ and x86 assembly language. The members of this union correspond to the packed data types that can be used with a YMM register. The structure YmmVal also includes several formatting and display functions (the source code for these member functions is not shown).
The C++ code for example Ch09_01 starts with declarations for the assembly language functions AvxPackedMathF32_ and AvxPackedMathF64_. These functions carry out various packed single-precision and double-precision floating-point arithmetic operations using the supplied YmmVal arguments. Following the assembly language function declarations is the function AvxPackedMathF32. This function starts by initializing YmmVal variables a and b. Note that the C++ specifier alignas(32) is used with each YmmVal declaration. This specifier instructs the C++ compiler to align each YmmVal variable on a 32-byte boundary. Following YmmVal variable initialization, AvxPackedMathF32 calls the assembly language function AvxPackedMathF32_ to perform the required arithmetic. The results are then streamed to cout. The function AvxPackedMathF64 is the double-precision floating-point counterpart of AvxPackedMathF32.
Near the top of the assembly language code in Listing 9-1 is a .const section that defines packed constant values for calculating floating-point absolute values . The text dup is a MASM operator that allocates and optionally initializes multiple data values. In the current example, the statement AbsMaskF32 dword 8 dup(7fffffffh) allocates storage space for eight doubleword values and each value is initialized to 0x7fffffff. The following statement, AbsMaskF64 qword 4 dup(7fffffffffffffffh), allocates four quadwords of 0x7fffffffffffffff. Note that neither of these 256-bit wide operands is preceded by an align statement, which means that they may not be properly aligned in memory. The reason for this is that the MASM align directive does not support 32-byte alignment within a .const, .data, or .code section. Later in this chapter, you learn how to define a custom segment of constant values that supports 32-byte alignment.
Following the .const section, the first instruction of AvxPackedMathF32_, vmovaps ymm0,ymmword ptr [rcx], loads argument a (i.e., the eight floating-point values of YmmVal a) into register YMM0. The vmovaps can be used here since YmmVal a was defined using the alignas(32) specifier in the C++ code. The operator ymmword ptr directs the assembler to treat the memory location pointed to by RCX as a 256-bit wide operand. Use of the ymmword ptr operator is optional in this instance and employed to improve code readability. The ensuing vmovaps ymm1,ymmword ptr [rdx] instruction loads b into register YMM1. The vaddps ymm2,ymm0,ymm1 instruction that follows sums the packed single-precision floating-point values in YMM0 and YMM1; it then saves the result to YMM2. The vmovaps ymmword ptr [r8],ymm2 instruction saves the packed sums to c[0].
The ensuing vsubps, vmulps, and vdivps instructions carry out packed single-precision floating-point subtraction, multiplication, and division. This is followed by a vandps ymm2,ymm1,ymmword ptr [AbsMaskF32] instruction that calculates packed absolute values using argument b. The remaining instructions in AvxPackedMathF32_ calculate packed single-precision floating-point square roots, minimums, and maximums.
Prior to its ret instruction, the function AvxPackedMath32_ uses a vzeroupper instruction, which zeros the high-order 128 bits of each YMM register. As explained in Chapter 4, the vzeroupper instruction is needed here to avoid potential performance delays that can occur whenever the processor transitions from executing x86-AVX instructions that use 256-bit wide operands to executing x86-SSE instructions. Any assembly language function that uses one or more YMM registers and is callable from code that potentially uses x86-SSE instructions should always ensure that a vzeroupper instruction is executed before program control is transferred back to the calling function. You’ll see additional examples of vzeroupper instruction use in this and subsequent chapters.
Packed Floating-Point Arrays
In previous chapters, you learned how to carry out integer and floating-point array calculations using the general-purpose and XMM register sets. In this section, you learn how to perform floating-point array operations using the YMM register set.
Simple Calculations
Example Ch09_02
The C++ code in Listing 9-2 includes a function named AvxCalcSphereAreaVolumeCpp. This function calculates sphere surface areas and volumes. The sphere radii are passed to AvxCalcSphereAreaVolumeCpp via an array. Prior to calculating a surface area or volume, the sphere’s radius (r[i]) is tested to verify that it’s not negative. If the radius is negative, the corresponding elements in the surface area and volume arrays (sa[i] and vol[i]) are set to c_QNaN_F32. The remaining C++ code performs the necessary initializations, exercises the C++ and assembly language calculating functions, and displays the results. Note that the function AvxCalcSphereAreaVolume employs the alignas(32) specifier with each array declaration.
The assembly language function AvxCalcSphereAreaVolume_ performs the same calculations as its C++ counterpart. Following its prolog, AvxCalcSphereAreaVolume_ uses a series of vbroadcastss instructions to initialize packed versions of the required constants. Prior to the start of the processing loop, a cmp r9,8 instruction checks the value of n. The reason for this check is that the processing loop carries out eight surface area and volume calculations simultaneously using 256-bit wide operands. The jb FinalR conditional jump instruction skips the processing loop if there are fewer than eight radii to process.
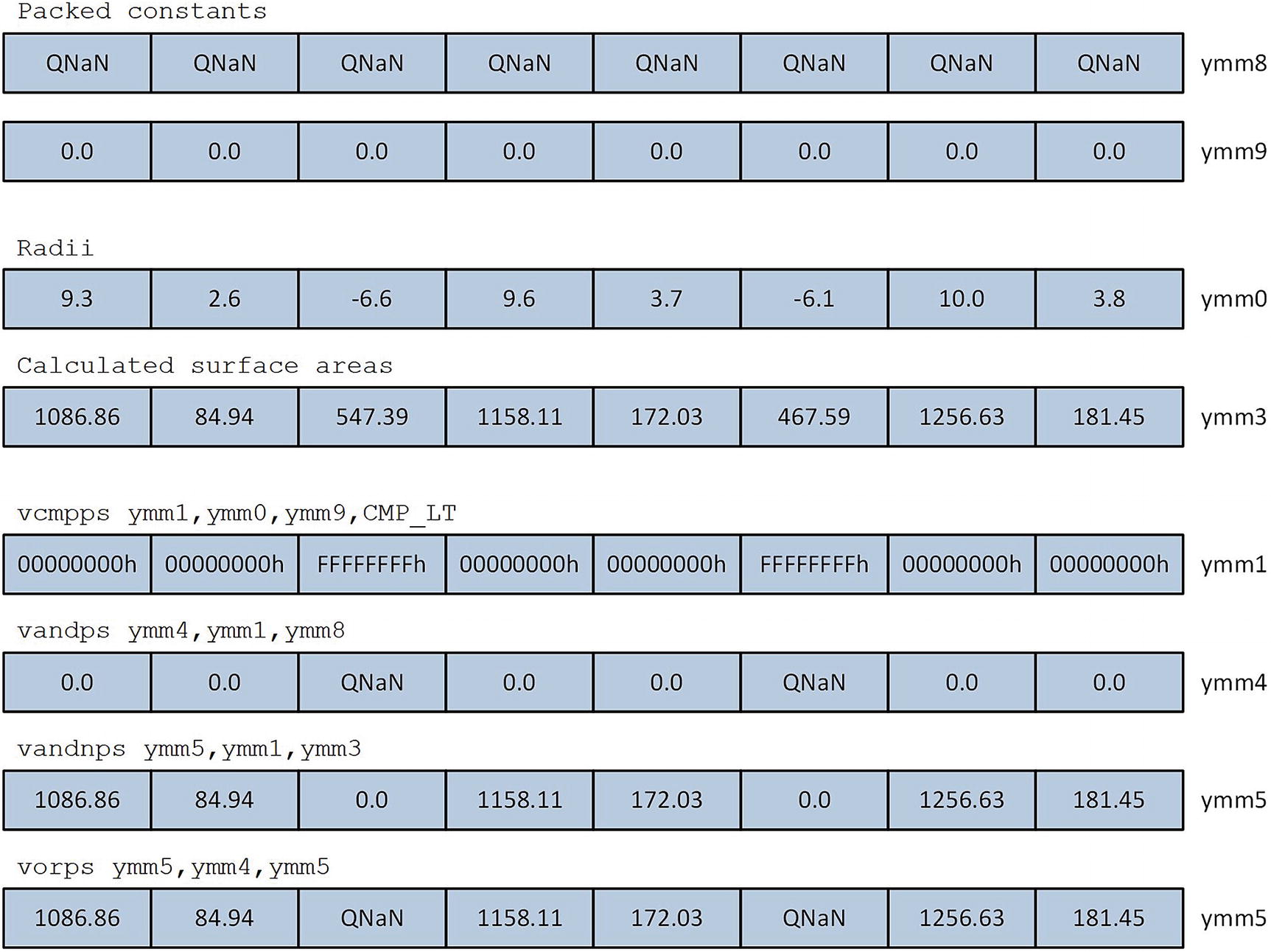
Surface area QNaN assignment for spheres with radius less than 0.0
Following the calculation of the surface areas, the vmulps ymm2,ymm3,ymm0 and vdivps ymm3,ymm2,ymm7 instructions compute the sphere volumes. The processing loop uses another vandps, vandnps, and vorps instruction sequence to set the volume of any negative-radius sphere to c_QNaN_F32. These values are then saved to the array vol. The processing loop repeats until there are fewer than eight remaining radii.
The output for source code example Ch09_02 includes a couple of lines with the text “compare discrepancy.” This text was generated by the compare code in AvxCalcSphereAreaVolume to exemplify the non-associativity of floating-point arithmetic. In this example, the functions AvxCalcSphereAreaVolumeCpp and AvxCalcSphereAreaVolume_ carried out their respective floating-point calculations using different operands orderings. For each sphere surface area, the C++ code calculates sa[i] = r[i] * r[i] * 4.0 * c_PI_F32, while the assembly language code calculates sa[i] = 4.0 * c_PI_F32 * r[i] * r[i]. Tiny numerical discrepancies like this are not unusual when comparing floating-point values that are calculated using different operand orderings irrespective of the programming language. This is something that you should keep in mind if you’re developing production code that includes multiple versions of the same calculating function (e.g., one coded using C++ and an AVX/AVX2 accelerated version that’s implemented using x86 assembly language).
Finally, you may have noticed that the function AvxCalcSphereAreaVolume_ handled invalid radii sans any x86 conditional jump instructions. Minimizing the number of conditional jump instructions in a function, especially data-dependent ones, often results in faster executing code. You’ll learn more about jump instruction optimization techniques in Chapter 15.
Column Means
Example Ch09_03
Toward the top of the C++ code is a function named AvxCalcColumnMeansCpp. This function calculates the column means of a two-dimensional array using a straightforward set of nested for loops and some simple arithmetic. The function AvxCalcColumnMeans contains code that uses the C++ smart pointer class unique_ptr<> to help manage its dynamically-allocated arrays. Note that storage space for the test array x is allocated using the C++ new operator, which means that the array may not be aligned on a 16- or 32-byte boundary. In this particular example, aligning the start of array x to a specific boundary would be of little benefit since it’s not possible to align the individual rows or columns of a standard C++ two-dimensional array (recall that the elements of a two-dimensional C++ array are stored in a contiguous block of memory using row-major ordering as described in Chapter 2).
The function AvxCalcColumnMeans also uses class unique_ptr<> and the new operator for the one-dimensional arrays col_means1 and col_means2. Using unique_ptr<> in this example simplifies the C++ code somewhat since its destructor automatically invokes the delete[] operator to release the storage space that was allocated by the new operator. If you’re interested in learning more about the smart pointer class unique_ptr<>, Appendix A contains a list of C++ references that you can consult. The remaining code in AvxCalcColumnMeans invokes the C++ and assembly language column-mean calculating functions and streams the results to cout.
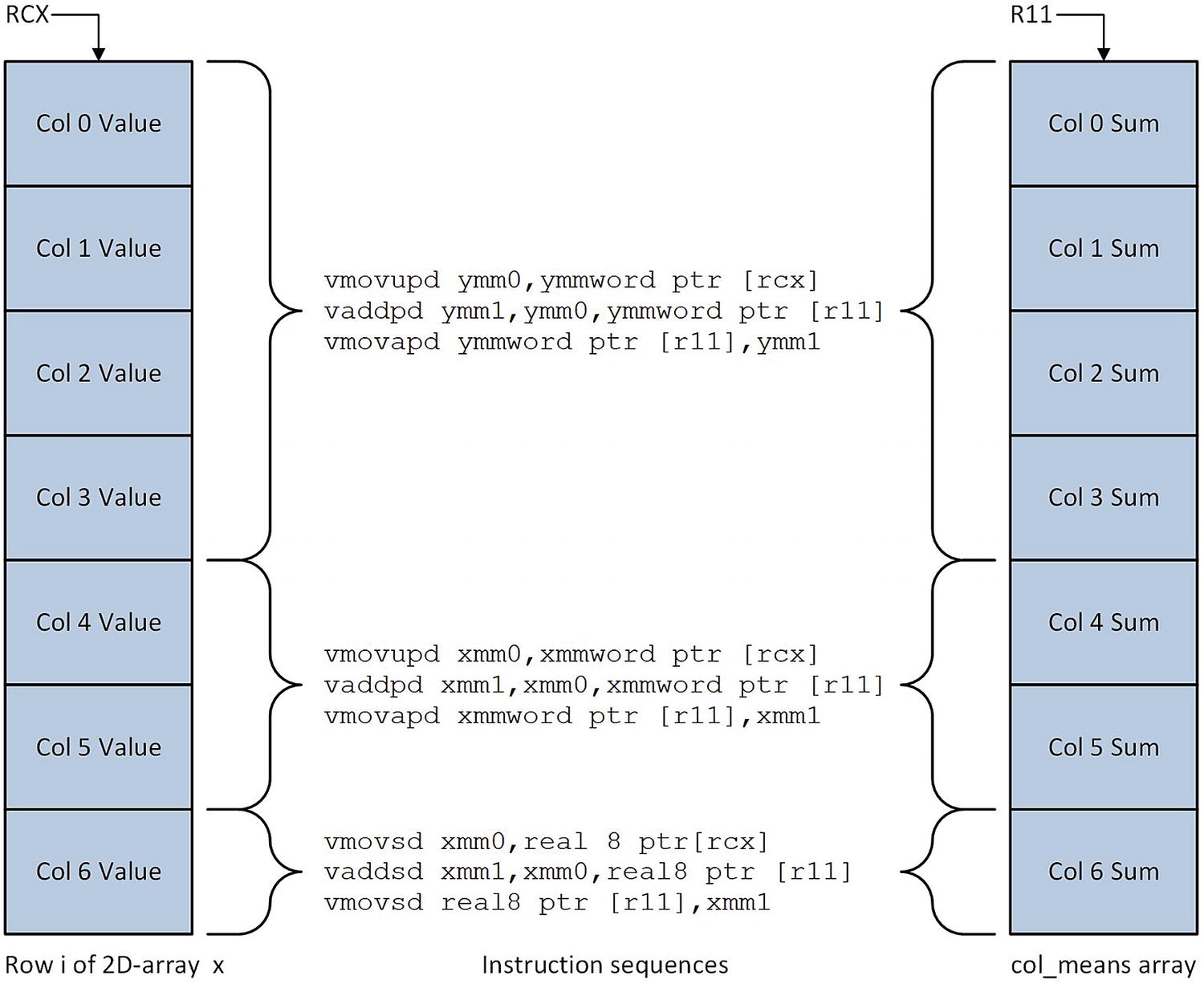
Updating the col_means array using different operand sizes
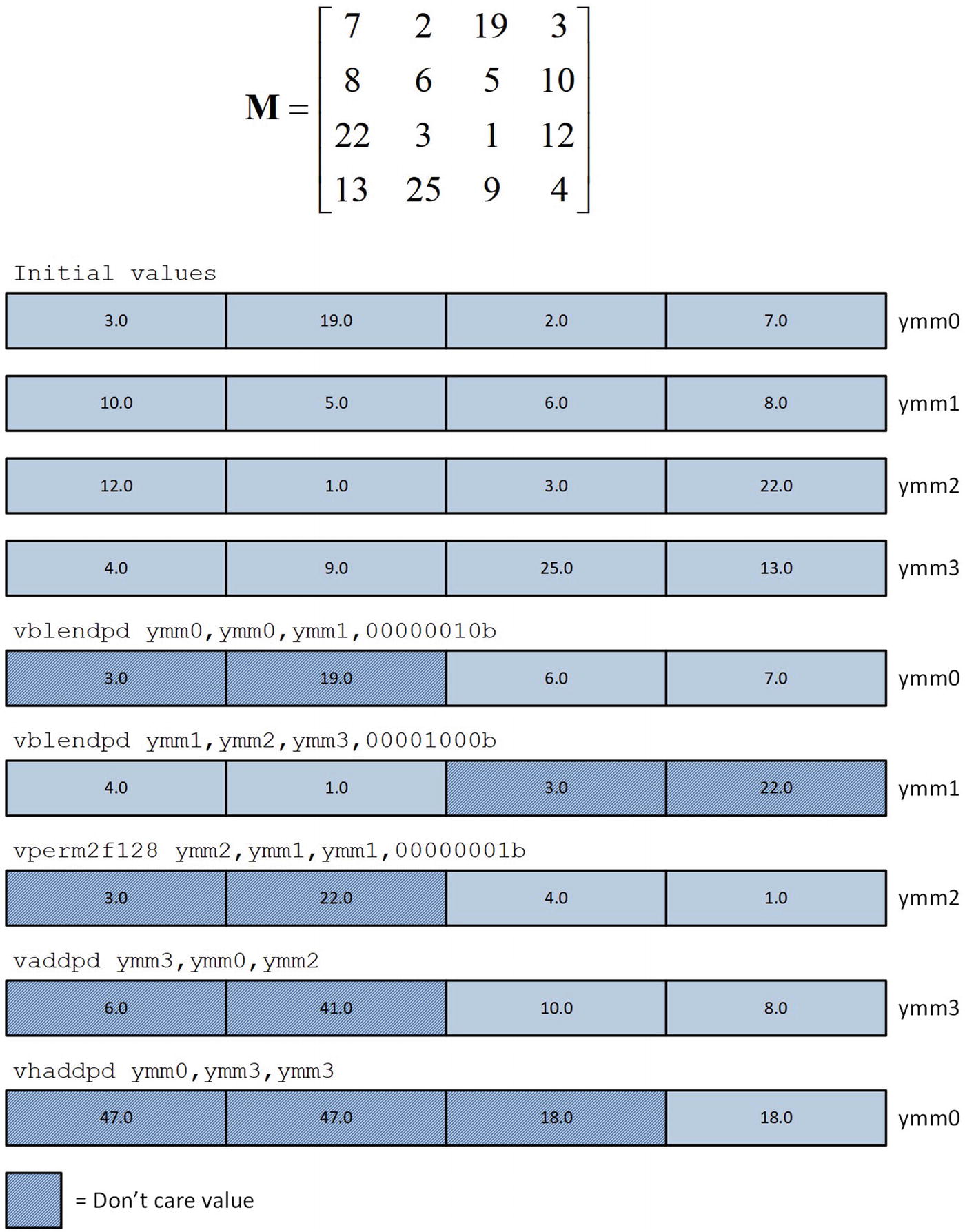
The mov r11,r9 instruction next to the label LP1 is the starting point for adding elements in the current row of x to col_means. This instruction initializes R11 to first entry in col_means. The col_index counter in register R10 is then set to zero. The instruction group near the label LP2 determines the number of columns remaining to be processed in the current row. If four or more columns remain, the next four elements from the current row are added to the column sums in col_means. A vmovupd ymm0,ymmword ptr [rcx] instruction loads four double-precision floating-point values from x into YMM0 (a vmovapd instruction is not used here since alignment of the elements is unknown). The ensuing vaddpd ymm1,ymm0,ymmword ptr [r11] instruction sums the current array elements with the corresponding elements in col_means, and the vmovupd ymmword ptr [r11],ymm1 instruction saves the updated results back to col_means. The function’s various pointers and counters are then updated in preparation for the next set of elements from the current row of x.
Correlation Coefficient
Example Ch09_04
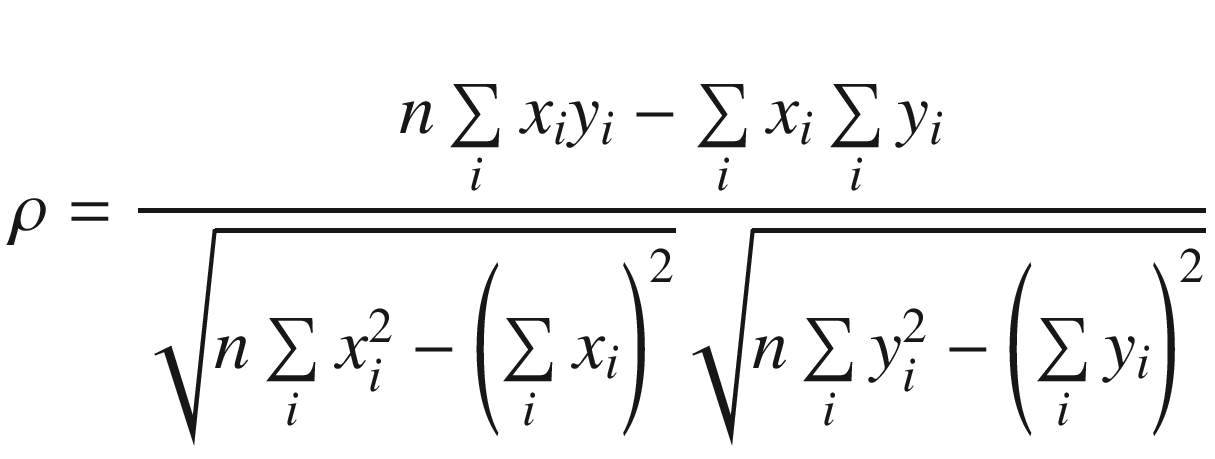
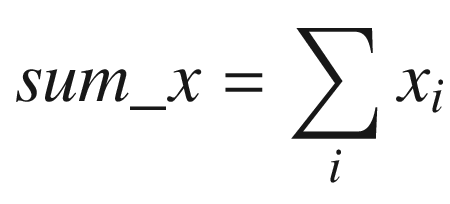
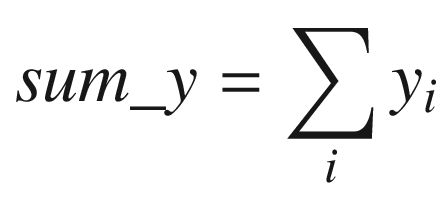
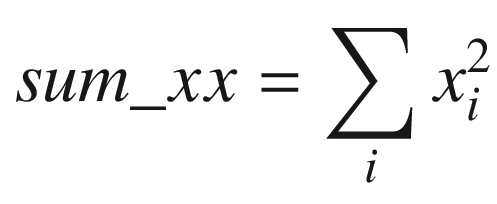
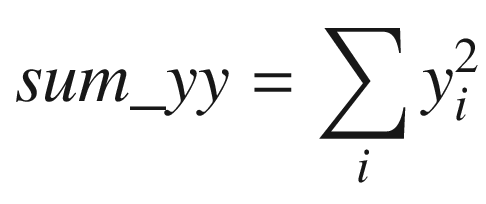
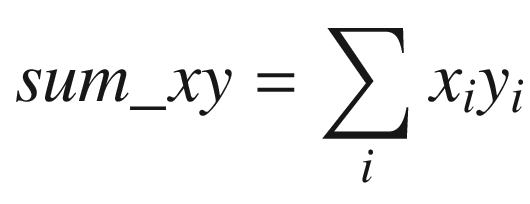
The C++ function AvxCalcCorrCoefCpp shows how to calculate a correlation coefficient. This function begins by checking the value of n to make sure it’s greater than zero. It also validates the two data arrays x and y for proper alignment. The aforementioned sum variables are then calculated using a simple for loop. Following completion of the for loop, the function AvxCalcCorrCoefCpp saves the sum variables to the array sums for comparison and display purposes. It then computes the intermediate values rho_num and rho_den. Before computing the final correlation coefficient rho, rho_den is tested to confirm that it’s greater than or equal to epsilon.
Following its prolog, the assembly language function AvxCalcCorrCoef_ performs the same size and alignment checks as its C++ counterpart. It then initializes packed versions of sum_x, sum_y, sum_xx, sum_yy, and sum_xy to zero in registers YMM3–YMM7. During each iteration, the loop labeled LP1 processes four elements from arrays x and y using packed double-precision floating-point arithmetic. This means that registers YMM3–YMM7 maintain four distinct intermediate values for each sum variable. Execution of loop LP1 continues until there are fewer than four elements remaining to process.
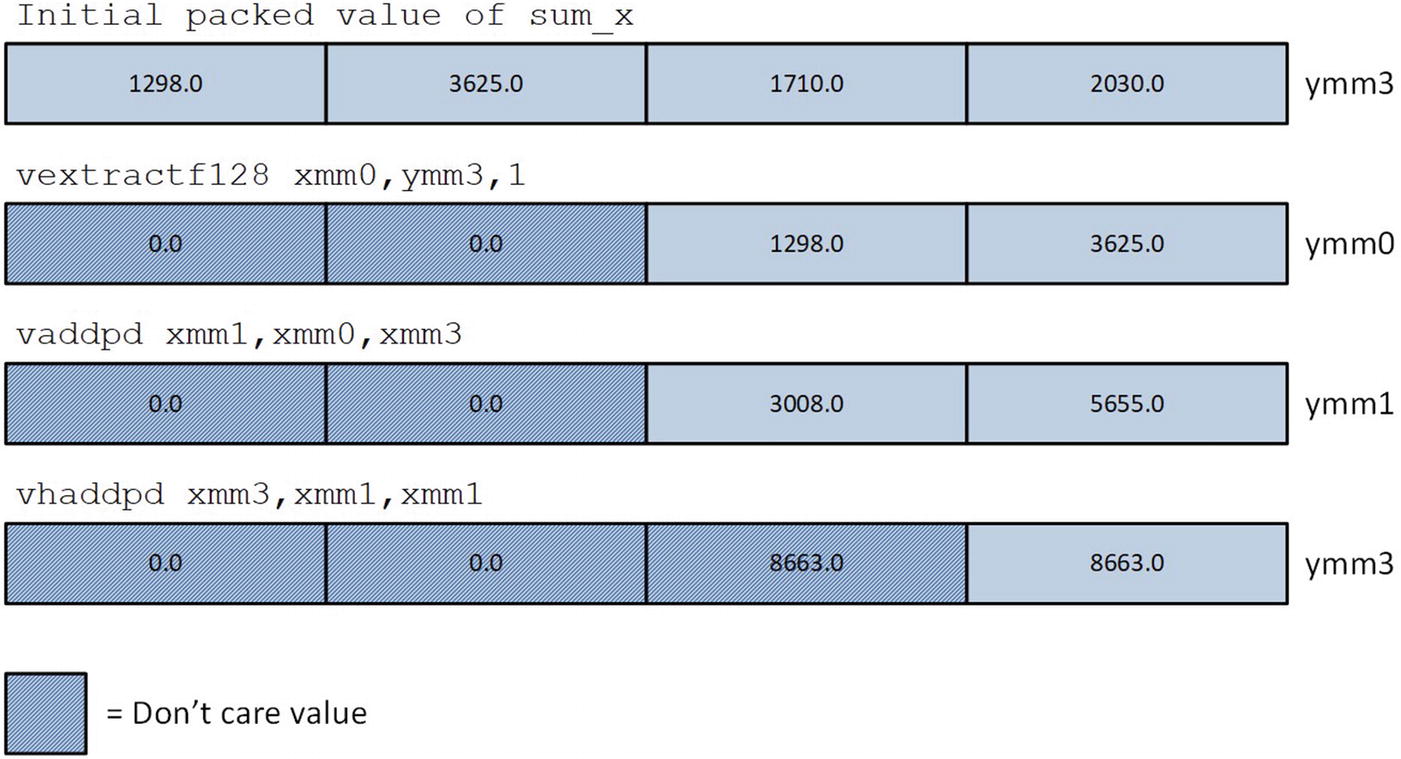
Calculation of sum_x using vextractf128, vaddpd, and vhaddpd
Matrix Multiplication and Transposition
Example Ch09_05
The C++ source code that’s shown in Listing 9-5 is very similar to what you saw in Chapter 6. It begins with a function named AvxMat4x4TransposeF64 that exercises both the C++ and assembly language matrix transposition calculating routines and displays the results. The function that follows, AvxMat4x4MulF64, implements the same tasks for matrix multiplication. Similar to the source code examples in Chapter 6, the C++ versions of matrix transposition and multiplication are implemented by the template functions Matrix<>::Transpose and Matrix<>::Mul, respectively. Chapter 6 contains additional details regarding these template functions.
Field Selection for vperm2f128 ymm0,ymm1,ymm2,imm8 Instruction
Destination Field | Source Field | imm8[1:0] | imm8[4:3] |
|---|---|---|---|
ymm0[127:0] | ymm1[127:0] | 0 | |
ymm1[255:128] | 1 | ||
ymm2[127:0] | 2 | ||
ymm2[255:128] | 3 | ||
ymm0[255:128] | ymm1[127:0] | 0 | |
ymm1[255:128] | 1 | ||
ymm2[127:0] | 2 | ||
ymm2[255:128] | 3 |
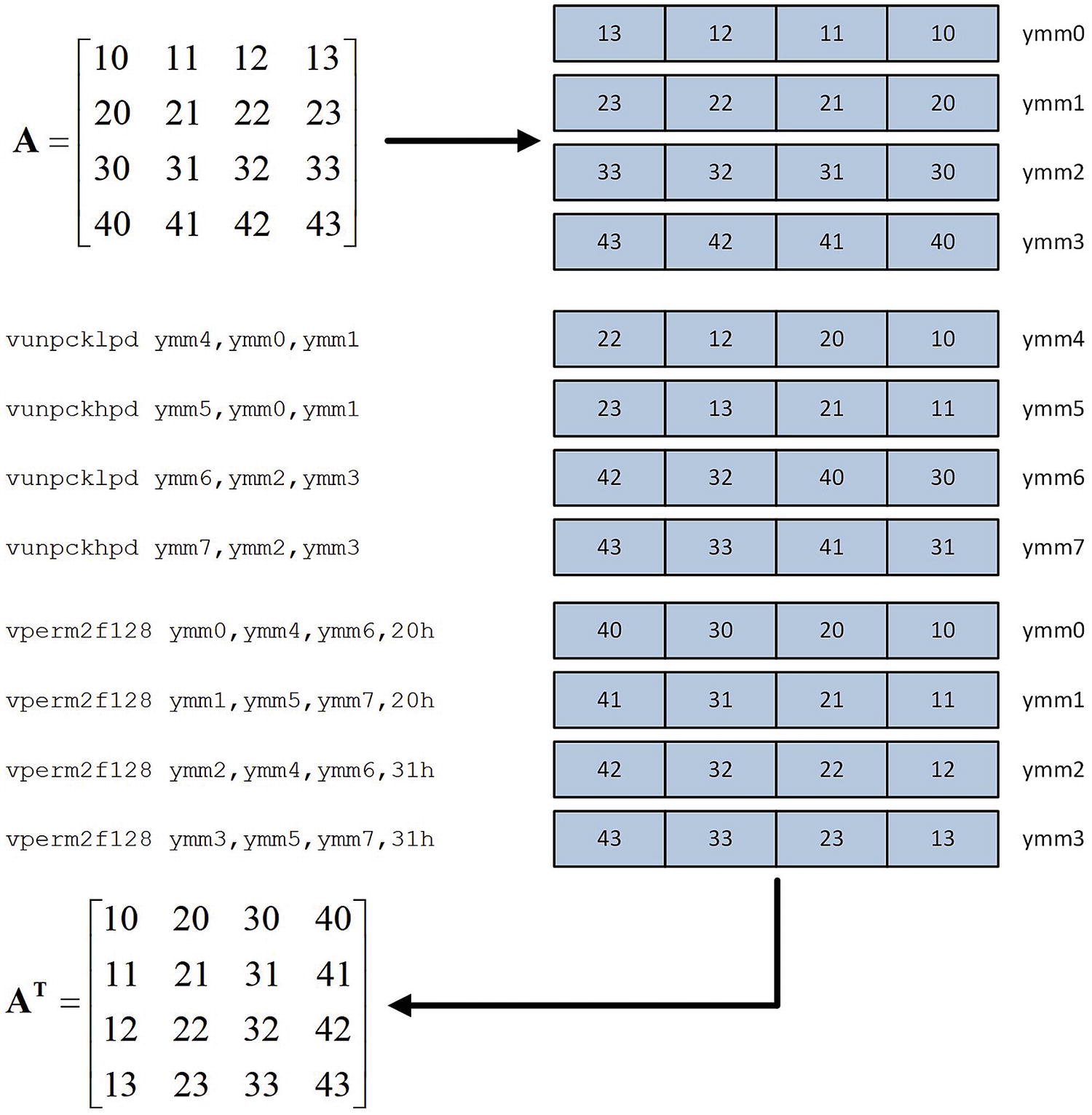
Instruction sequence used by _Max4x4TransposeF64 to transpose a 4 × 4 matrix of double-precision floating-point values
Matrix Transposition Mean Execution Times (Microseconds), 1,000,000 Transpositions
CPU | C++ | Assembly Language |
|---|---|---|
i7-4790S | 15562 | 2670 |
i9-7900X | 13167 | 2112 |
i7-8700K | 12194 | 1963 |
Matrix Multiplication Mean Execution Times (Microseconds), 1,000,000 Multiplications
CPU | C++ | Assembly Language |
|---|---|---|
i7-4790S | 55652 | 5874 |
i9-7900X | 46910 | 5286 |
i7-8700K | 43118 | 4505 |
Matrix Inversion
Example Ch09_06

Matrix A and its multiplicative inverse Matrix X
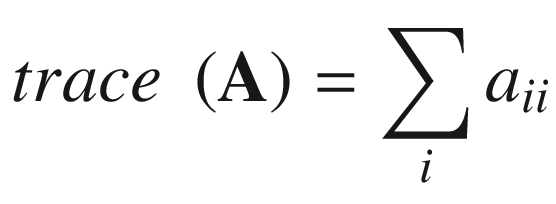
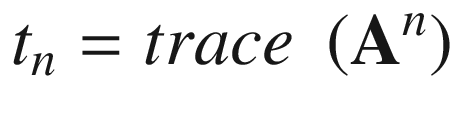
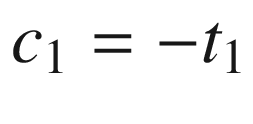
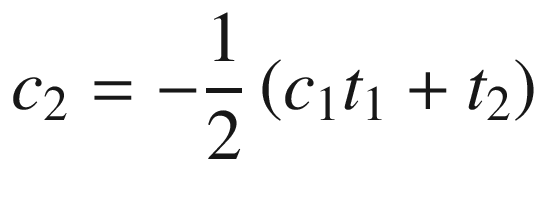
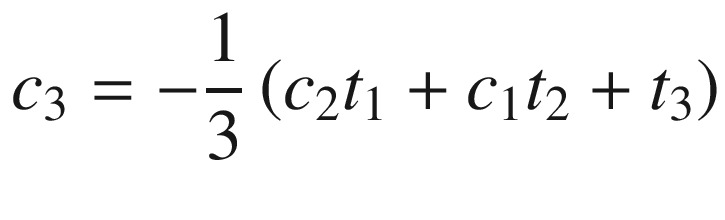
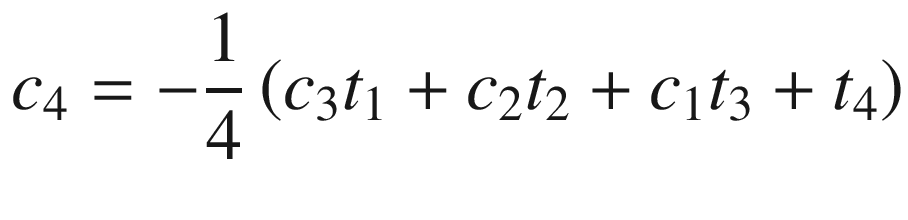
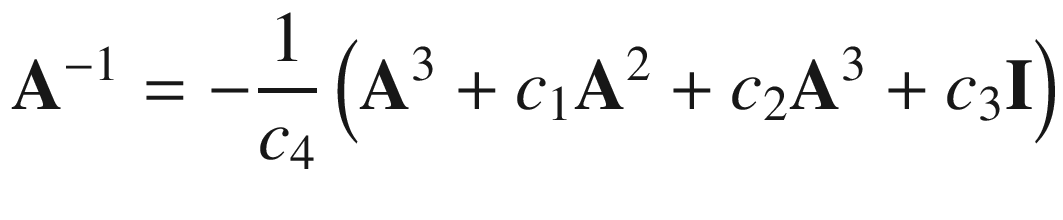
Toward the top of the C++ code is a function named Avx2Mat4x4InvF64Cpp. This function calculates the inverse of a 4 × 4 matrix of double-precision floating-point values using the aforementioned equations. Function Avx2Mat4x4InvF64Cpp uses the C++ class Matrix<> to perform many of the required intermediate computations, including matrix addition, multiplication, and trace. The source code for class Matrix<> is not shown but included with the chapter download package. Note that the intermediate matrices are declared using the static qualifier in order to avoid constructor overhead when performing benchmark timing measurements. The drawback of using the static qualifier here means that the function is not thread-safe (a thread-safe function can be simultaneously used by multiple threads). Following calculation of the trace values t1 - t4, Avx2Mat4x4InvF64Cpp computes c1–c4 using simple scalar arithmetic. It then checks to make sure the source matrix m is not singular by comparing c4 against epsilon. If matrix m is not singular, the final inverse is calculated. The remaining C++ code performs test case initialization and exercises both the C++ and assembly language matrix inversion functions.
The assembly language code in Listing 9-6 begins with a custom segment that contains definitions of the constant values needed by the assembly language matrix inversion functions. The statement ConstVals segment readonly align(32) 'const' marks the start of a segment that begins on a 32-byte boundary and contains read-only data. The reason for using a custom segment here is that the MASM align directive does not support aligning data items on a 32-byte boundary. In this example, proper alignment of the packed constants is essential in order to maximize performance. Note that the scalar double-precision floating-point constants are defined after the 256-bit wide packed constants and are aligned on an 8-byte boundary. The MASM statement ConstVals ends terminates the custom segment.
Trace calculation for a 4 × 4 matrix
Matrix Inverse Mean Execution Times (Microseconds), 100,000 Inversions
CPU | C++ | Assembly Language |
|---|---|---|
i7-4790S | 30417 | 4168 |
i9-7900X | 26646 | 3773 |
i7-8700K | 24485 | 2941 |
Blend and Permute Instructions
Example Ch09_07
The C++ code in Listing 9-7 begins with a function named AvxBlendF32 that initializes YmmVal variables src1 and src2 using single-precision floating-point values. It also initializes a third YmmVal variable named src3 for use as a blend control mask. The high-order bit of each doubleword element in src3 specifies whether the corresponding element from src1 (high-order bit = 0) or src2 (high-order bit = 1) is copied to the destination operand. These three source operands are used by the vblendvps (Variable Blend Packed Single- Precision Floating-Point Values) instruction, which is located in the assembly language function AvxBlendF32_. Following execution of this function, the results are streamed to cout.
The C++ code in Listing 9-7 also includes a function named Avx2PermuteF32. This function initializes several YmmVal variables that demonstrate use of the vpermps and vpermips instructions. Both of these instructions require a set of indices that specify which source operand elements are copied to the destination operand. For example, the statement idx1.m_I32[0] = 3 is used to direct the vpermps instruction in Avx2PermuteF32_ to perform des1.m_F32[0] = src1.m_F32[3]. The vpermps instruction requires each index in idx1 to be between zero and seven. An index can be used more than once in idx1 in order to copy an element from src1 to multiple locations in des1. The vpermilps instruction requires its indices to be between zero and three.
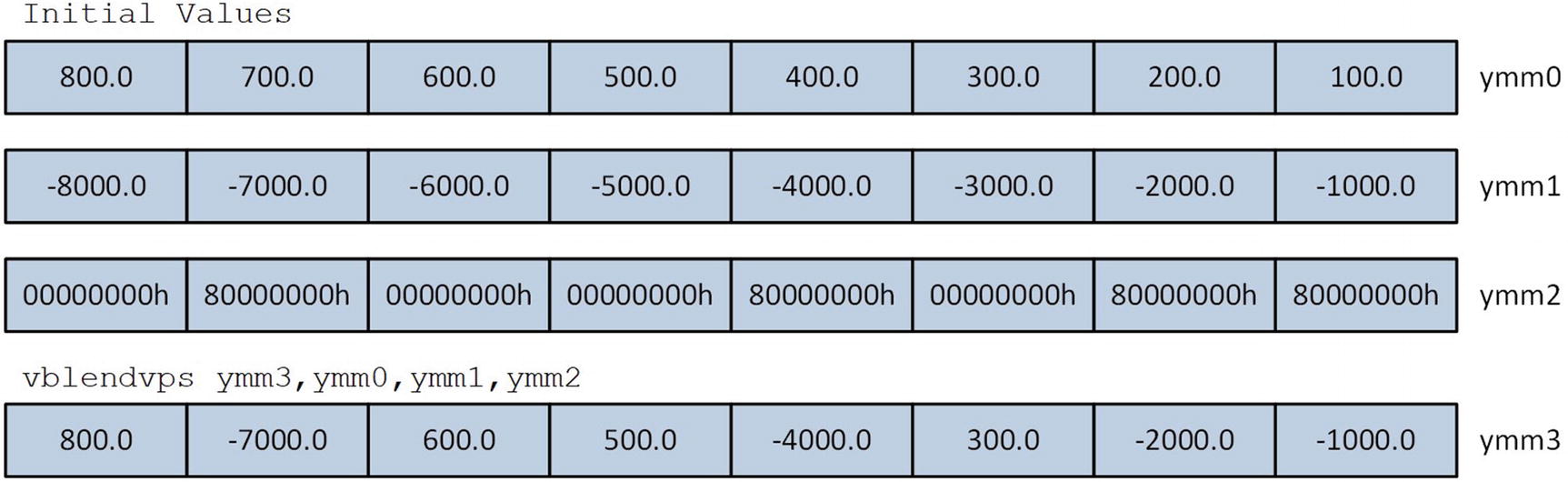
Execution of the vblendvps instruction
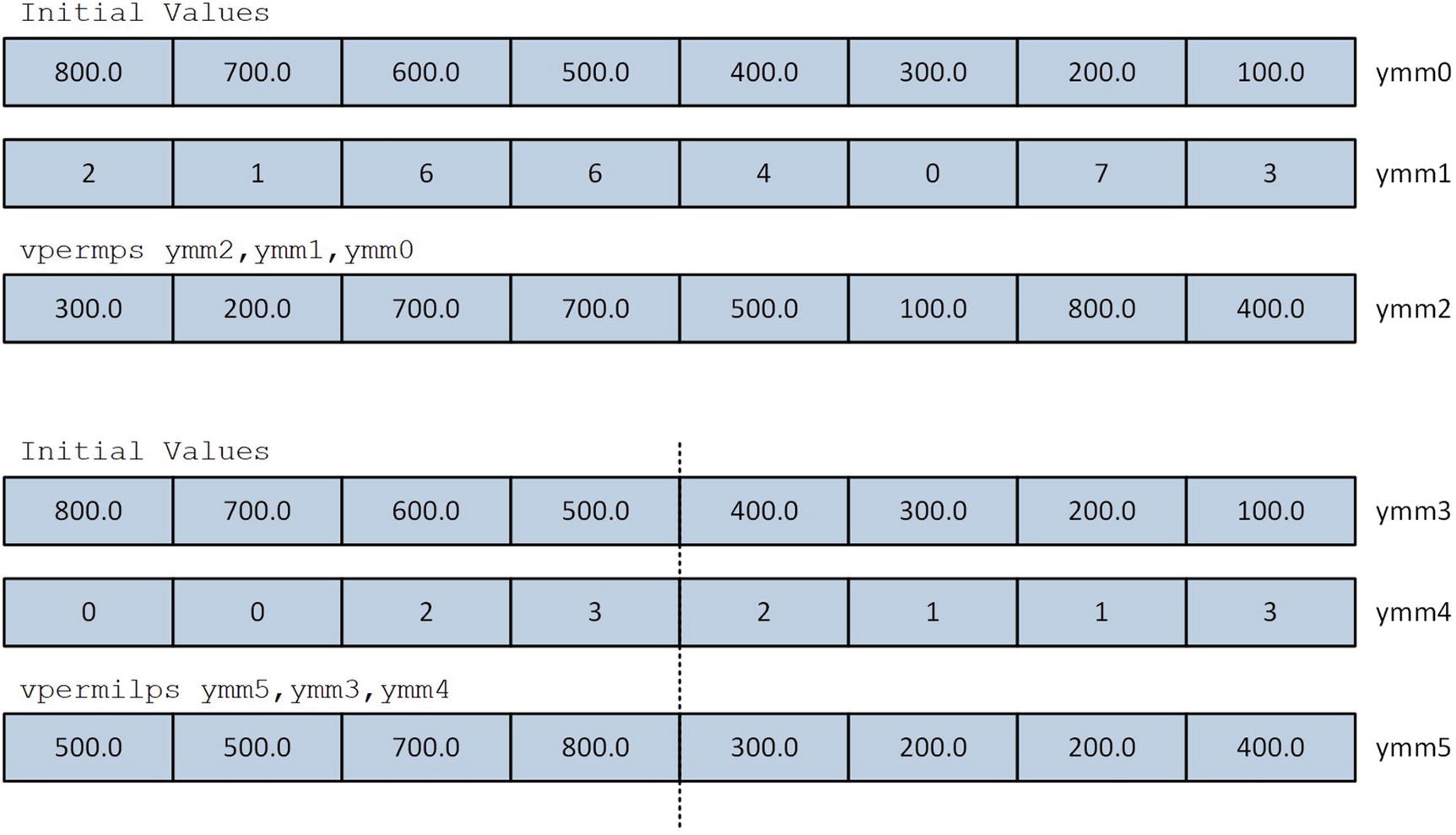
Execution of the vpermps and vpermilps instructions
Data Gather Instructions
Example Ch09_08
The C++ source code in example Ch09_08 includes four functions that initialize test cases to perform single-precision and double-precision floating-point gather operations using signed doubleword or quadword indices . The function Avx2Gather8xF32_I32 begins by initializing the elements of array x (the source array) with test values. Note that this function uses the STL class array<> instead of a raw C++ array to demonstrate use of the former with an assembly language function. Appendix A contains a list of C++ references that you can consult if you’re interested in learning more about this class. Next, each element in array y (the destination array) is set to -1.0 in order to illustrate the effects of conditional merging. The arrays indices and merge are also primed with the required gather instruction indices and merge control mask values, respectively. The assembly language function Avx2Gather8xF32_I32_ is then called to carry out the gather operation. Note that raw pointers for the various STL arrays are obtained using template function array<>.data. The other C++ functions in this source example—Avx2Gather8xF32_I64, Avx2Gather8xF64_I32, and Avx2Gather8xF64_I64—are similarly structured.
The assembly language function Avx2Gather8xF32_I32_ begins by loading registers YMM0, YMM1, and YMM2 with the test arrays y, indices, and merge, respectively. Register RDX contains a pointer to the source array x. The vpslld ymm2,ymm2,31 instruction shifts the merge control mask values (each value in this mask is zero or one) to the high-order bit of each doubleword element. The ensuing vgatherdps ymm0,[rdx+ymm1*4],ymm2 instruction loads eight single-precision floating-point values from array x into register YMM0. The merge control mask in YMM2 dictates which array elements are actually copied into the destination operand YMM0. If the high-order bit of a merge control mask doubleword element is set to 1, the corresponding element in YMM0 is updated; otherwise, it is not changed. Subsequent to the successful load of an array element, the vgatherdps instruction sets the corresponding doubleword element in the merge control mask to zero. The vmovups ymmword ptr [rcx],ymm0 then saves the gather result to y.
Summary
Nearly all AVX packed single-precision and double-precision floating-point instructions can be used with either 128-bit or 256-bit wide operands. Packed floating-point operands should always be properly aligned whenever possible, as described in this chapter.
The MASM align directive cannot be used to align a 256-bit wide operand on a 32-byte boundary. Assembly language code can align 256-bit wide constant or mutable operands on a 32-byte boundary using the MASM segment directive.
When performing packed arithmetic operations, the vcmpp[d|s] instructions can be used with the vandp[d|s], vandnp[d|s], and vorp[d|s] instructions to make logical decisions without any conditional jump instructions.
The non-associativity of floating-point arithmetic means that minute numerical discrepancies may occur when comparing values calculated using C++ and assembly language functions.
Assembly language functions can use the vperm2f128, vpermp[d|s], and vpermilp[d|s] instructions to rearrange the elements of a packed floating-point operand.
Assembly language functions can use the vblendp[d|s] and vblendvp[d|s] instructions to interleave the elements of two packed floating-point operands.
Assembly language functions can use the vgatherdp[d|s] and vgatherqp[d|s] instructions to conditionally load floating-point values from non-contiguous memory locations into an XMM or YMM register.
Assembly language functions that perform calculations using a YMM register should also use a vzeroupper instruction prior any epilog code or the ret instruction in order to avoid potential x86-AVX to x86-SSE state transition performance delays.