
Chapter 7
Music and Language
Introduction: “All Theatre Starts with a Script”
In 1999, I was invited to participate in a Scenography Symposium at the OISTAT Scenography Commission meetings in Antwerp, Belgium. The symposium title was “Theatre and Design Today: Does the Scenographer Need to Become Director?” But before that subject could even get off the ground, Belgian director Marc Schillemans took me by surprise when he started his presentation by saying, “All theatre starts with a script.” While I simultaneously recognized that most everybody in the room tacitly agreed with his assessment, I also knew that we had been traveling down two very different aesthetic paths.
Schillemans’s assumption inevitably led me to the subject of my presentation at the Bregenz Opera the following year, and ultimately to many of the ideas in this book. In Bregenz, I developed a lecture that grew out of Adolphe Appia’s famous proclamation that all theatre starts with music: “Out of Music (in the widest sense) springs the conception of the drama” (Appia 1962, 27). I have discussed Appia’s thesis in detail in my 2001 Theatre Design and Technology Journal article, “The Function of the Soundscape” (Thomas 2001). Still, it is certainly interesting to consider how music—in its widest sense, as both Appia suggested, and we have defined—manifested itself in the evolution of humans, in the time arts, and, in my opinion, in the evolution of theatre itself. Whether music, language or mimesis came first may ultimately depend on how you define each, and of course, you can define theatre as an artistic endeavor that starts with a script, but there is a lot to be said for the intermingled role that emotive vocal expression, gesture and mimesis must have played in our earliest rituals.
While there is no consensus about when exactly music, speech and human ritual became fully developed, there does appear to be general consensus that they were pretty much firmly in place by about 40,000 to 60,000 years ago. In this chapter, we’ll trace the period from about 700,000 years or so ago that led up to these monumental events. We’ll try to get some idea of what must have happened biologically in order for us humans to take such a critical leap forward. Having arrived at an anatomically modern brain, we will next focus our attention on that. Since our brains are pretty much the same now as they were 200,000 years ago, we can finally examine how our brains process both music and language. We can consider which parts of the brain process common elements of both music and language, which parts process analogous parts of music and language in separate, but homologous1 areas of the brain, and which parts of the brain process elements of music and language completely separately and differently from each other. We’ll conclude by considering how music and language may function together to create a force potentially more powerful than either separately: song. Perhaps in a nod to both camps (Schillemans and Appia), I’ll argue that all theatre doesn’t start with a script, but with a song.

Brain Gains
About 700,000 years ago, a new Homo species appeared, Homo heidelbergensis, sometimes referred to as archaic Homo sapiens (Smithsonian Museum of Natural History 2016a).
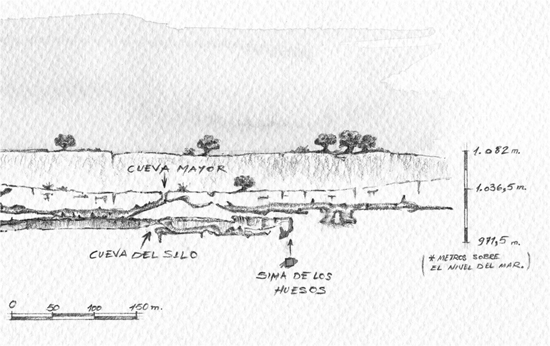
They were the first early humans to migrate into Northern Europe, where they left evidence of an ability to build shelters and to hunt animals with wooden spears (Smithsonian Museum of Natural History 2016b). In 1997, archaeologists discovered a large number of similar bones from about 400,000 years ago at the bottom of a deep pit in the Sima de los Huesos cave at Atapuerca in Northern Spain.

They suspect that the pit was a burial pit, and even more significantly, they also found a quartz hand axe that may have been ceremonially dropped into the pit along with the deceased. If so, this would provide evidence of the earliest known instance of a human ritual (Tremlett 2003).
A burial site such as the one in Spain must have been a place of extreme emotional distress, as a possible loved one was getting buried there. The loss would certainly cause a lot of great emotion, and a group that had a strong sense of caring about each other—which we know they did in this period—the obvious and perhaps only way to express this would be through music. A Hallmark greeting card would, of course, have been out of the question, but emotional wailing droning over a simply kept rhythm? Very possibly at once cathartic and healing.
Catharsis. That’s the first time we’ve used that word, but in Chapter 12 we will find that it plays an extremely important role in the relationship between music and theatre. It’s a tricky word to precisely define, but for right now consider this definition from Oxford Dictionary: “a process of releasing, and thereby providing relief from strong emotions” (2016). Our earliest human ancestors may have already figured out that sometimes the only way to cope with extreme emotional situations is through music. Neuroscientist Ian Cross suggests that the collective expression and experience of emotion in musical catharsis would also reinforce “group” traits. Such traits would include the formation of coalitions, promotion of cooperation among group members, and the potential creation of hostility for those outside the group (especially the perpetrator of the deceased member’s demise!). Music could reinforce the value of group ritual activities for survival, an important contributor to the emergence of human culture (Cross 2003, 50–51).
Beyond the implications for the evolution of music in a ritual-driven base, there is more evidence that Homo heidelbergensis had taken another leap forward in increased mental capacities. Homo erectus brains averaged about 1,050 cubic centimeters, whereas Homo heidelbergensis brains averaged about 1,250 cubic centimeters2 (Australian Museum 2015). Larger brains allow for a more numerous and complex array of synaptic connections between the many different and evolving areas. As humans evolve, our neural wiring gets more complex, and that allows us to do more complicated and sophisticated things, like putting words together in sentences using syntax and grammar. Of course, this didn’t happen overnight, but it certainly did eventually.

Figure 7.3 Map of Atapuerca mountains, site of the “pit of bones.”
Credit: Best-Backgrounds/Shutterstock.com.
In recent years, we have been able to sequence the genomes of both modern humans and our recent Hominin ancestors. A group of researchers from the Max Planck Institute for Evolutionary Anthropology sequenced the genome of a direct descendant of Homo heidelbergensis, Homo sapiens neanderthalensis, in 2007.
They discovered that Homo sapiens neanderthalensis shared an important evolutionary difference with us that separates us from our primate ancestors: the FoxP2 gene.
The FoxP2 gene is a part of our DNA important in speech and language. Researchers discovered that the Neanderthals’ FoxP2 gene had undergone the same changes3 as our direct Homo sapiens ancestors (Krause et al. 2007). This indicates that our common ancestor, Homo heidelbergensis, also contained this evolutionary adaptation. Scientists discovered the FoxP2 gene by noticing that mutations of the chromosome in human subjects impaired their ability to physically repeat words (and even non-words, among many other symptoms).4 They concluded that the FoxP2 gene appears to express itself in our ability to communicate using language, especially since the genetic adaptations that created the FoxP2 gene occurred around the same time humans acquired language. Many researchers consider it much more than a coincidence that the FoxP2 adaptation should so closely coincide with humans acquiring language, but as yet the proof that the FoxP2 adaptation directly led to humans acquiring language is inconclusive (Preuss 2012; Lieberman 2007, 51–52).
Credit: Javier Trueba/Science Source, a Division of Photo Researchers, Inc.

Figure 7.5 Archaeologists excavate the “Abyss of the Bones” at Atapuerca.
Credit: Javier Trueba/Science Source, a Division of Photo Researchers, Inc.

Other anatomical changes that would make language possible may have occurred in the transition from Homo heidelbergensis to Neanderthals and modern humans 400,000 to 200,000 years ago. In Chapter 5 we discussed Phillip Lieberman’s proposal that the face of early Homo flattening out and the human larynx beginning to descend to its current lower position were a consequence of our transition to walking upright, signaling the start of an almost 2-million-year journey to the evolution of fully formed language. When these transformations completed is still a matter of controversy, however. While the evolution of the brain, vocal tract, and oral chamber certainly seems to have allowed the possibility of language, there is no conclusive evidence for when language fully formed in humans, nor whether language evolved slowly or suddenly (Bickerton 2005, 515). As Frayer and Nicolay put it, “the paltry amount of actual evidence for language origins as recorded in fossils should be a little sobering to those willing to offer opinions about the origin of linguistic ability” (2007, 217). So, we won’t.
Homo erectus may have started using words well over a million years ago, as Bickerton suggested (Donald 1993b, 749). Language may have gradually evolved from Homo erectus into fully formed languages such as Lieberman proposes (2007, 52). Words may have been a much later evolutionary development out of mimesis as Donald suggests (Donald 1993a, 157), or were parsed out of musically holistic phrases as Mithen and Wray have suggested (Wray 1998, 50). We may know the answer to this puzzling question someday. Fortunately, we don’t need to know that answer to consider the implications of music and language developing in such a confusing, controversially intertwined way. It is important that we recognize that somewhere between Homo erectus and modern humans, fully formed languages evolved, and they are closely intertwined with music and mimesis. It’s also important to know that this all pretty much happened sometime about 300,000–200,000 years ago when our most direct ancestors Homo sapiens sapiens emerged.5
So, yes, about 300,000–200,000 years ago, our own species, anatomically modern Homo sapiens, or Homo sapiens sapiens, emerged from archaic Homo sapiens. The redundancy is not a typo; it’s used to separate us from our extinct cousins like Homo sapiens idaltu. And with this arrival comes a whole new method for observing ourselves. Not only do we have all of the other methods for examining our past—archaeology, genome sequencing, cognitive neuroscience and so forth—now we can simply examine our own brains. Our genomic sequence is 99.9% the same as our Homo sapiens sapiens ancestors, so we can be quite sure that what we discover about ourselves now corresponds pretty well to our past Homo sapiens sapiens selves (Smithsonian Museum of Natural History 2016b). For example, we know that our human brain size is huge compared to our ancestors, averaging 1,273 cubic centimeters for men and 1,131 for women (Allen, Damasio and Grabowski 2002, 347).6 For all of our differences among races and cultures on this planet, we are remarkably the same. How could this happen?

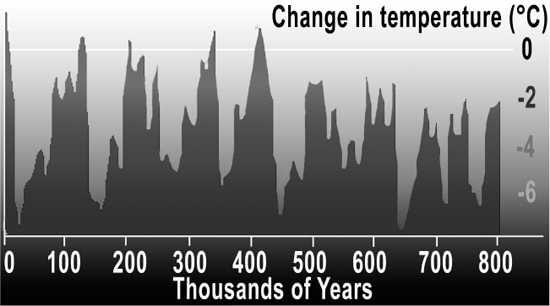
Figure 7.8 Graph shows ice ages, about 140,000 and 70,000 years ago.
Credit: Hannes Grobe/Awi. Accessed July 20, 2017. https://commons.wikimedia.org/wiki/File:Iceage_time-slice_hg.png. CC-BY-3.0. https://creativecommons.org/licenses/by/3.0/deed.en. Adapted by Richard K. Thomas.
{kind=link}
About the same time that anatomically modern Homo sapiens appeared, earth experienced another mini-ice age and ice sheets descended from the North Pole, covering much of Europe and North America.
Ice ages suck moisture out of the atmosphere, and this mini-ice age resulted in a massive drought in Africa. The drought created a “bottleneck” of humanity in South Africa about 140,000 years ago: only four to six potential locations existed in Africa that contained a phenomenally small breeding population of about 600 individuals. Every human on earth evolved genetically from this small population (PBS 2011). Not just from this small population, but from one single ancestral mother, dubbed by the media as Mitochondrial Eve (Cann, Stoneking and Wilson 1987). Think about it. If our genetic code is the same as theirs, somebody must have been the first one to have it! And even though their brains were biologically developed, there are still many who argue that they had not fully developed language (Arbib 2013, 130; Bickerton 2005, 520).
About 70,000 years ago, another period of glaciation combined with a massive eruption of a super-volcano near Lake Toba on the island of Sumatra to create major climate pressures on these tribes (Marean 2015, 34). Our human ancestors were once again decimated, leaving less than 2,000 (Chesner et al. 1991; Wells 2007). The big difference this time was that humans were ready for it, having much more sophisticated tools and ability to work collectively in highly organized social groups, and perhaps more fully formed language capabilities. Small groups migrated up the coastline and out of Africa into Yemen (see the Map of Human Migration in Figure 8.4). They eventually crossed over into southeast Asia and Australia. And just about everybody agrees that by about 90,000–50,000 years ago, our ancestors, Homo sapiens sapiens, had fully acquired language and music.
Fantastic Voyage
Having now arrived at a point in time where everyone seems to agree that our human ancestors had acquired both language and music raises an interesting problem for us: if we aren’t changing genetically, then how do we change over 50,000 years? Surely we’re not that similar to our cave dwelling ancestors? It is true that we have entered into an era in which we witness few genetic changes—50,000 years is just too short a time to witness much evolutionary change caused by genetic mutations. Instead, we enter into a period of rapid change called Lamarckian evolution, named after the French biologist Jean-Baptiste Lamarck. Lamarck thought that we can pass on our acquired characteristics to our offspring, and on to their offspring, and so forth. Such a theory would allow humans to evolve much more rapidly than standard theories of evolution would appear to allow. Molino argues that cultural evolution seems “quite Lamarckian since information acquired at each generation can be transmitted in whole to the next generation.” Of course, such an idea is not without its critics, but anthropologist Jean Molino makes a very good point when she suggests that “these differences do not in any way threaten the stability of the edifice” (the edifice being genetic evolution, of course) (Molino 1999, 166). In our particular case, it will become increasingly difficult to separate genetic traits that we inherited in our species from cultural traits acquired through the passing down of knowledge from generation to generation. With this murkiness in mind, we will continue to explore how the innate traits that first manifested themselves in vocal/physical expression of emotion, and signs (and now symbols) developed to become an art form we call theatre.
But first, in order to truly understand how we use music and language to manipulate our audiences in theatre, we must understand how we hear and process those sounds. So now would be a good time to stop and examine how the brain processes music and speech (the auditory form of language). Let’s consider which parts of the brain music and speech share, and then, let’s consider where they diverge.7
John Bracewell, a longtime professor at Ithaca College, may have been the first collegiate faculty in theatre sound in the United States. He was the first commissioner of the USITT Sound Commission, and the person I have to thank for dragging me in to do some of my first lectures and presentations in the organization. When I started working on my master’s degree in 1977, I wrote to John, and got a copy of his 1971 master’s thesis on theatre sound. I asked John how he started learning about sound in theatre. John told me that when he started working on his thesis, he met Harold Burris-Meyer, one of the earliest pioneers of theatre sound, and asked him, “what do I need to study to be a good sound designer?” And Harold Burris-Meyer responded, “well, you start with the ear. Because you really need to know how you hear.” In other words, in order to have an aesthetic of sound design, you need to understand that particular sensory organism, and how it works. It’s really hard to create something (a sound score) that manipulates something else (an audience member) unless you know how that something else works. In Harold Burris-Meyer’s and John Bracewell’s time, relatively little was really known about our auditory system, but the two of them helped pave the way for this book. Today, we know much more about how the brain works, and that knowledge provides clues about the nature of hearing that should influence how we think about creating sound scores.
So, fasten your seatbelts, refer to Figures 7.9, 7.10, 7.11, and maybe even have a look back at Figures 5.9 and 5.17 when appropriate, as we take the fascinating journey of a sound from the outside world into the deepest regions of our brain….
If you will recall from our first few chapters, all sound, whether naturally occurring, music, language or all of the above, enters our perceptual mechanism through the pinnae of our two ears.
The pinnae gather up sounds, and send them down the external auditory canal that resonates—amplifies—sounds between 2,000 and 4,000 Hz. Very handy when a predator steps on a twig behind you! The sound vibrates the tympani (eardrum), which in turn, vibrates the malleus (hammer), then the incus (anvil), then the stapes (stirrup), three bones you will remember that we acquired in our transition from water to land that helped our mammalian class match the impedance of air to the inner ear.
The stapes vibrates the oval window at the entrance to the cochlea, a spiral-shaped organ that contains the basilar membrane.
The basilar membrane vibrates in response to fluids in the cochlea that the oval window has set in motion. The basilar membrane sets into motion the hair cells along the membrane that are localized depending on the frequency of the incoming sound. High frequencies localize toward the near end and low frequencies toward the far end, kind of like the spectrum analyzers sound folks used to use to measure the auditory response of theatres. This division of “tones” according to their “place” on the basilar membrane is called a tonotopic organization. You will be surprised as we go along at how far the human nervous system maintains this tonotopic organization up into the brain!8 The hair cells of the inner ear convert their mechanical vibrations into electrochemical pulses and send them along the auditory nerve to the brainstem. The neurons fire in digital-like pulses, either on or off, nothing in between. Which nerve fibers fire determines frequencies, how fast the pulses occur determines amplitude (Giraud and Poeppel 2012, 180).
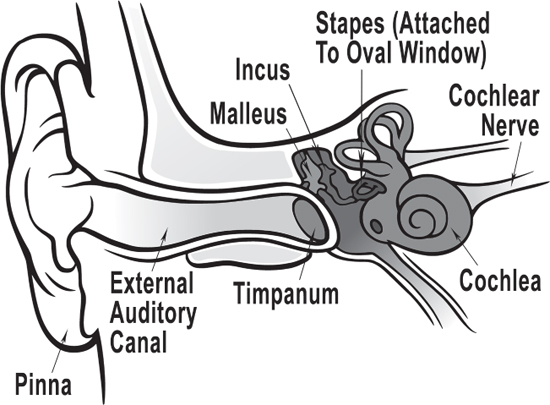
Figure 7.9 Overview of the human ear.
Credit: Chittka, L., and A. Brockmann. 2005. “Perception Space—The Final Frontier.” PLOS Biology 3 (4): e137. https://doi.org/10.1371/journal.pbio.0030137. Adapted by M. Komorniczak, Inductiveload. Accessed July 20, 2017. https://commons.wikimedia.org/wiki/File:Anatomy_of_the_Human_Ear_blank.svg. CC-BY-2.5. https://creativecommons.org/licenses/by/2.5/deed.en. Adapted by Richard K. Thomas.
{kind=link}
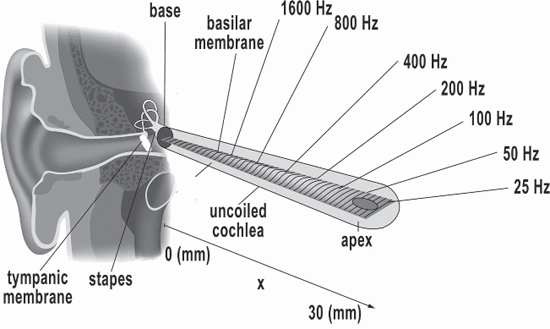
Figure 7.10 The basilar membrane uncoiled.
Credit: Kern, A., C. Heid, W-H. Steeb, N. Stoop, and R. Stoop. 2008. “Biophysical Parameters Modification Could Overcome Essential Hearing Gaps.” PLOS Computational Biology 4(8): e1000161. Accessed July 20, 2017. https://doi.org/10.1371/journal.pcbi.1000161. CC-BY-2.5. https://creativecommons.org/licenses/by/2.5/deed.en. Adapted by Richard K. Thomas.
A couple of milliseconds later, the sound travels through the internal auditory canal, an opening through the skull, and into the brainstem as part of the eighth cranial nerve,9 known as the vestibulocochlear nerve.
This nerve has over 30,000 nerve fibers (Spoendlin and Schrott 1989). The first stop in the brainstem is the cochlear nucleus, which is at the juncture of the medulla oblongata and the pons.
In the cochlear nucleus, the data from the eighth cranial nerve contacts neurons that each form a parallel circuit and perform their own analysis on the data. For example, one circuit preserves the timing of auditory events (simple information about when the sound arrives), while another circuit is sensitive to how we identify sound (Rubio 2010). The medulla oblongata is a part of the hindbrain, the gateway to the lower part of the body, along with the pons and cerebellum. The medulla oblongata is the lowest part of the brain that sits on top of the spinal cord, and has a lot to do with the involuntary control of muscles like breathing, heart rate and blood pressure. Music, as it turns out, can have a great effect upon the brainstem, and we’ll investigate that in Chapter 9. The pons goes in the other directions—up, toward the rest of the brain and laterally to the cerebellum, especially important in hearing and speaking. The pons sits below the part of the brainstem called the midbrain.
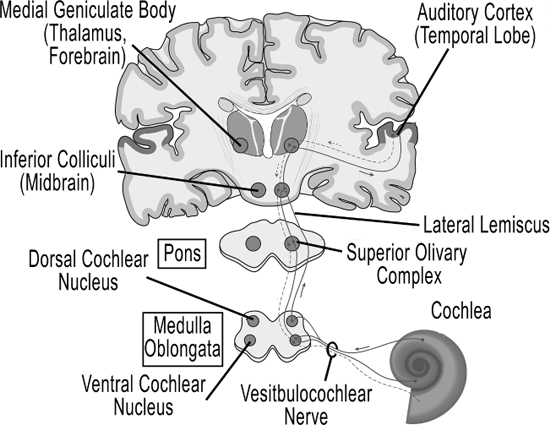
Figure 7.11 The auditory pathway from cochlea to auditory cortex.
Credit: Blamb/Shutterstock.com. Adapted by Richard K. Thomas.
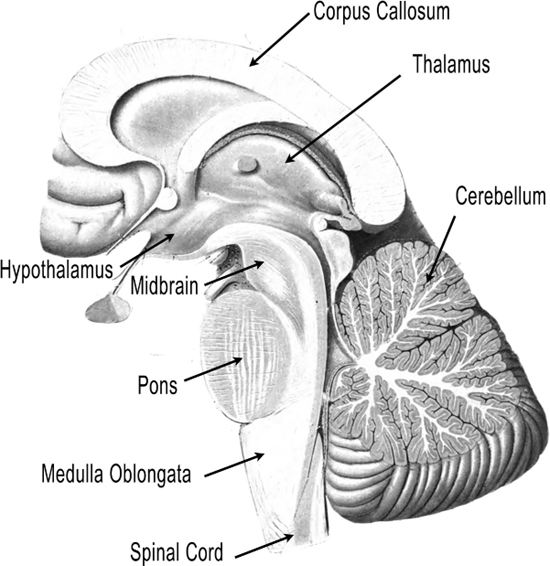
Figure 7.12 The thalamus, midbrain, pons and medulla.
Credit: Sobotta, Johannes. 1909. Textbook and Atlas of Human Anatomy. Edited with additions by McMurrich, J. Volume III. Philadelphia and London, W.B. Saunders Company. Figure 648, Page 156. Adapted by Richard K. Thomas.
Inside the pons is the superior olivary complex, a group of nuclei that is thought to determine localization in the horizontal plane, by comparing the time arrival and intensity difference between the auditory stimulus from each ear (Kandel, Schwartz and Jessell 2000, 591–624). From here, sound travels to the lateral lemiscus, a group of nerve fibers whose function is not understood, but is sensitive to timing and amplitude changes. The sound continues up to the inferior colliculi in the midbrain, where all of the various components that have become separated along the various pathways become integrated before continuing on to the brain itself. The inferior colliculi are also involved in a type of habituation that inhibits startle response (Parham and Willott 1990).
Next, the sound leaves the brainstem and enters the thalamus in the forebrain, the area of our brain that sits on top of the midbrain, and pretty much connects to every other part of the brain (see Figure 7.12). The thalamus acts as the main distribution system of the auditory signal to different parts of the brain, having been compared to the bouncer in a nightclub, deciding who to let in and who to kick out (Leonard 2006). It connects to the hippocampus, the seat of memory, and the basal ganglia that we met in Chapter 5 (see Figure 5.9 for the hippocampus, and 5.17 for the basal ganglia). The basal ganglia sequences patterns from other parts of the brain and sends them back to the thalamus for routing to our motor circuits when we walk or run (Lieberman 2007, 47–52). It is also active during rhythmic entrainment, although its function is not clearly understood. The thalamus also connects directly to the cerebellum, and there is a complex relationship related to entrainment we discussed in the last chapter involving the thalamus and cerebellum (Thaut 2005, 48–51). But most significantly, the auditory signal next goes from a part of the thalamus called the medial geniculate nucleus to the auditory cortex in the temporal lobe of our neocortex, or “new brain.”
At this point, you should either be yelling “jackpot!” or “my mind is fried and I need a break.” Hopefully the former. And if so, keep in mind as we progress to the auditory cortex that the frequencies that were so carefully separated along the basilar membrane in the cochlea of our ears, still remain separated in the thousands of nerve fibers entering the auditory cortex.
Up until this point, the brain has more or less treated incoming sound the same, whether it is a dog bark, a symbolic word, or a strain of music. Once it enters the auditory cortex, however, we start to see a noticeable split between how the brain deals with speech and auditory music. And this is where things really start to get interesting.
Inside the temporal lobes are the auditory cortices (yup, there are two, one on each side of the brain, left and right). Each auditory cortex is divided into two areas: the primary auditory cortex (also called the core), and the secondary auditory cortex (also called the belt and the parabelt; the belt being the section closest to the core, and the parabelt being adjacent to the belt).10
As we discussed, the auditory system maintains the frequency discrimination created by the basilar membrane in the cochlea of the ear all the way through to the core of the auditory cortex, where the signal lands in an area of the primary auditory cortex called Heschl’s gyrus. The primary auditory cortices process the individual frequencies and pass them on to the secondary auditory cortices for more processing, although these areas seem to discriminate frequency more broadly than the primary auditory cortices (Giraud and Poeppel 2012, 169).
The primary cortex also follows external tempos and radiates a brainwave, called M100, which increases in intensity (i.e., the number of neurons simultaneously firing) as tempo changes. Small tempo changes produce small increases in the M100 brainwave; larger tempo increases produce larger increases. Presumably these brainwave firings are projected onto our motor structures (especially through the thalamus) in order to synchronize things like foot tapping, but it is not well understood yet how and where this happens. Equally murky is the strong likelihood that since we already know that the cochlea connects directly with other parts of the brain such as the basal ganglia and cerebellum, parallel timing networks might also be working simultaneously to synchronize tempos. These networks might also activate differently depending on whether we are consciously or unconsciously synchronizing to an external tempo (Thaut 2005, 45–49).
One of the first things that the auditory cortex does is to attempt to separate incoming sounds into sound objects. Sound objects are how our brain separates one sound from another. They are similar to our description of color, in that they consist of the spectral characteristics of a sound (the particular frequencies of the sound) as they unfold in time (which we have described as the ADSR—attack, decay, sustain and release). Parsing incoming sounds into sound objects is a hugely important task—otherwise we would not be able to tell the difference between the lion roar and the background noise, between the lovely cello part and the violins. It turns out that the first task of the auditory cortex is to segregate sounds in the core. Research suggests that parsing sounds into sound objects is likely to happen in the auditory cortex even before perception of timbre and spatial characteristics (Griffiths, Micheyl and Overath 2012, 203).
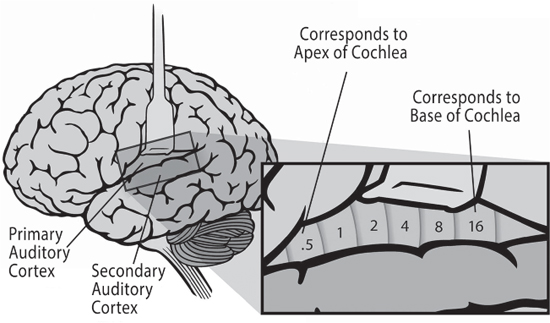
Figure 7.13 The primary and secondary auditory cortex (belt and parabelt) show the tonotopic relation to frequency first derived in the basilar membrane (see Figure 7.10).
Credit: Chittka, L., and A. Brockmann. 2005. “Perception Space—The Final Frontier.” PLOS Biology 3(4): e137. Accessed July 20, 2017. https://doi.org/10.1371/journal.pbio.0030137. CC- BY-2.5. https://creativecommons.org/licenses/by/2.5/deed.en. Adapted by Richard K. Thomas.
Before we move on, let’s consider another point of view regarding how humans process and segregate incoming sound. Michel Chion is one of the most highly regarded writers on the subject of the aesthetics of sound in the cinema. He has proposed a great way for categorizing sound objects that will be useful to us as well. Chion describes three types of listening in his book Audio-Vision. The first type corresponds to identifying the source of sound objects, which he calls causal listening. It is the type of listening that answers the question, “What was that sound?” We listen to determine the cause of the sound. The close correlation between causal listening and sound objects, is perhaps a result of our evolutionary heritage. One of the first things we would want to know when we hear an unusual sound is, “What was that?” And to know “that,” we have to be able to segregate that sound from the many others that are always occurring simultaneously. We have already discussed the rather limited use that this type of listening has for us as theatre composers and sound designers. Chion recognizes a similar problem, describing causal listening as “the most easily influenced and deceptive mode of listening” (1990, 26).
Chion’s second type of listening is semantic. This is the sound of language, speech. In speech, we derive meaning not from the cause of the sound, but from the aural symbols used to represent words in language. Chion’s third type of sound is the sound itself, which, in and of itself, has no reference to the outside world whatsoever. Chion refers to this type of listening as reduced (1990, 25–34). Chion’s reduced listening bears a strong resemblance to our definition of music. Both are concerned with the inherent characteristics of a sound rather than what caused them or any particular referential meaning we might derive from them. In Chion’s last two types of listening, we find a parallel to our categorization of speech and music. How the brain processes these are critically important to us as sound designers and composers, as they provide clues about how they work together to create the auditory experience of theatre.
It turns out that the secondary auditory cortex is one of the first places that processes music differently from speech. In 2015, a group of researchers at MIT discovered that, while the primary auditory cortex seemed to process both words and musical sound objects the same, the secondary auditory cortex processed musical sounds more toward its front11 and back12 areas adjacent to the primary auditory cortex and words more toward its side13 (Norman-Haignere, Kanwisher and McDermott 2015, 1285). This doesn’t sound like much, except that it provides clear evidence for the very first time that there is a part of the brain dedicated to processing music. Music could not then just be a fringe benefit of speech, “auditory cheesecake”; it must have evolved as its own adaptation to some sort of condition in the world. Biologically, we have now discovered genetic evidence for music, language and imitation: music and speech in the unique processing of the auditory cortex, and imitation, in the mirror neuron.
So what is the big difference between music and speech that our brain uses to analyze each? Robert Zatorre proposed that understanding speech requires very fine temporal resolution—we need to be able to differentiate between consonants that are all sequencing very quick. In music, however, we need very fine spectral resolution—an ability to very precisely tell the difference between different pitches. Zatorre noted that the different parts of the brain seemed to have evolved to discern these differences: some parts favoring fine temporal resolution, and other parts favoring fine frequency resolution. Zatorre noticed a similarity between this behavior and that of all linear systems:14 temporal and spectral resolutions are inversely related; the more you have of one, the less you get of the other (Zatorre 2003, 241–242). Can it be that some parts of the brain favored fine spectral resolution and others fine temporal resolution?
When I first heard Zatorre’s hypothesis, a light bulb went off: “wait a minute, this sounds very much like the tradeoff sound designers experience when they use typical FFT15 audio measuring systems!” In an FFT-based audio measurement system such as SmaartLive, we see exactly the same trade-off: using a longer sample time provides greater spectral resolution (you can see a larger region of frequencies at once), but you can’t examine what they are doing very quickly; the response feels “sluggish.” On the other hand, if you use shorter sample times, you can tell a lot better what is happening at each instant, but can’t see as large of a range of frequencies (Henderson 2016). Fortunately, the manufacturers of the SmaartLive systems have figured out some pretty nifty ways around these limitations in practical use, but you probably never imagined your brain working just like your audio analyzer!
The MIT researchers found much more of this temporal/spectral discrimination within each side of the secondary temporal cortex, but other researchers, including Zatorre, found significant speech and music differences lateralized between the left side and the right side of the auditory cortex and the brain in general (Norman-Haignere, Kanwisher and McDermott, 1287). We have perhaps all heard the well-known cliché that our left brain is logical and our right brain is creative. Unfortunately, the brain is far too complex for such a simplistic idea to hold up under close scrutiny. But the division that Zatorre and others identify precisely matches the way we have categorized and defined language and music—semantic and reduced listening in Chion’s parlance. For example, Giraud and Poeppel found that the right auditory cortex played a more essential role in coding pitch information that we use to identify a person’s voice, and in prosody, the “music” of speech, whereas the left hemisphere is better at processing shorter sounds like consonants, which are critical to our understanding of words.
To understand this difference, try to read this sentence:
Th qck brwn fx jmpd vr th lzy dg.
Now compare it to this sentence:
E i o o ue oe e a o.
In the first sentence, only the consonants of the sentence “The quick brown fox jumped over the lazy dog” were included. In the second, only the vowels. Giraud and Poeppel’s measurements suggest that the left auditory cortex is better at processing the fast-changing signals like consonants, while the slower but wider frequency discriminating right auditory cortex is better at processing vowels (Giraud and Poeppel 2012, 231, 242). Consonants provide much of the meaning of words, vowels provide much of the music. Robert Zatorre and Dean Falk approached the auditory cortex from the vantage point of music, and came to similar conclusions: the right hemisphere of the auditory cortex is better at perceiving fine variations in pitch and the linear sequencing of notes in melody (line), while the left auditory cortex works better with rhythm, since it is the side that seems to favor fine temporal discrimination (Zattore and Zarate 2012, 265–268; Falk 1999, 202–204).
We’ve done a pretty good job, so far, of figuring out what’s going on as our brain processes sound from the ear to the auditory cortex, but beyond that, things start to get a bit trickier. The auditory cortex sends signals out to just about every other part of the cerebrum, and receives signals back. The auditory cortex sends signals back to the thalamus and out to the cerebellum, forebrain, midbrain and all the way back to the ear itself. There are four times more auditory projections going from the auditory cortex to the thalamus than coming from the thalamus! (King and Schnupp 2007, R239). That’s a lot of processing to decipher! But neuroscientists do seem to be slowly gaining a better understanding of the fundamental ways in which the auditory cortex interacts with the rest of the brain when processing speech and music.
Steven Brown suggests considering the brain’s role in processing speech and music in three ways: first, the processes that speech and music share, second, those that operate in parallel (typically in a left brain, speech, right brain, music, manner), and finally those that are distinctively different for either activity. We’ve already seen examples of shared activity in the brainstem, hindbrain, midbrain, basal ganglia, cerebellum, thalamus and auditory cortex. In Brown’s second category, parallel processing, we have seen that there are homologous areas between the left auditory cortex and the right auditory cortex that parallel each other when analyzing speech and music. It turns out that much of the cerebral cortex seems to process speech in its high temporal resolution left lobe and music in its high spectral resolution right lobe. For example, Broca’s area in the left frontal lobe helps us understand sentence structure, and it’s homologue on the right side helps us make sense of melodies16 (Brown, Martinez and Parsons 2006, 2800). Both frontal lobes check in with our hippocampus and memory centers to see if we’ve ever experienced that structure or pattern before, or to see if we attach any sort of meaning to what we’ve heard (Levitin 2007, 130). So there are notable brain activities that process in a parallel manner for speech and music, and often operate in a left brain-speech and a right brain-music sort of fashion.
There are distinctly different areas of the brain that process music but not language, and language but not music. The processes we’ve described related to the direct connection between the cochlea and the cerebellum in startle and habituation have no correlates in language (Levitin 2007, 61). At the same time, there are distinct areas of the brain that process language meaning that have no correlates in music. Steven Brown identifies several specific areas in the parietal,17 temporal18 and frontal19 cortices that have no known parallel processes for music. Perhaps this is because, as Brown suggests, “the informational content of music (i.e., its ‘semantics’) is still ill-defined.” More useful to our approach, as Oliver Sacks put it in Chapter 4, is that “music doesn’t have any special meaning; it depends on what it’s attached to” (Sacks 2009). Or, as we prefer to think, what is attached to it.
It is perhaps because music has no inherent meaning that it can stimulate its audiences across cultural boundaries. Claude Lévi-Strauss famously said that music is “the only language with the contradictory attributes of being at once intelligible and untranslatable” (Lévi-Strauss 1969, 18). The noted cognitive neuroscientist Aniruddh Patel explains that although we can translate between words in any two languages, we can’t translate a Beethoven chamber work into a Javanese gamelan work (Patel 2008, 300–301). At the same time, one culture is quite able to quickly adapt and derive meaning from the music of another culture without any translation. For most of us, we would gain almost nothing reading a play by Aristophanes in Greek. It would literally be “all Greek to me!” However, we could probably derive quite a bit of understanding of the play by listening to a performance of the play in Greek. Even though we do not understand the Greek language, we could certainly find ourselves immersed in the emotional journey of the play simply by experiencing the prosody of the spoken word. Having traveled to many foreign countries and been invited to experience theatre performed in the native tongue, I can attest this is true—and the more music, the greater my comprehension of the mimesis.
Finally, we should note that rhythm does not neatly fit into Steven Brown’s neurological framework of shared, parallel and distinctly different areas of auditory processing. Thaut says, “rhythm processing is a widely distributed bilateral function and not lateralized hemispherically” (2005, 53), suggesting that we cannot simply think about rhythm as a neurological process that is added on top of our more fundamental brain processes. As an example, consider what happens to the brain as the external auditory tempo changes. When the tempo is constant the brain’s response is limited to the areas you would pretty much expect: auditory and motor cortices as well as subcortical regions. Start changing the tempo and the frontal lobe gets increasingly involved: first middle front, then the front sides, and then the back sides, spreading out from the center as it were as the tempo changes vary (2005, 48–49). While this is going on, keep in mind that the cerebellum is also activating in very complex ways, the more complex the rhythm, the more activation patterns in the cerebellum, for example, in the running example of Chapter 5 when running in a hemiola pattern (2005, 51).
Rather, rhythm is a core process of the brain that underlies many, if not most, brain functions. Daniel Mauro has observed this core relationship between fundamental properties of music and basic neurological temporal functions of the brain. He suggests that “three facets of brain processing (frequency, synchrony and temporal pattern), are reflected in three essential properties of rhythm (tempo, meter, phrasing),” respectively (2006, 164). A diverse array of neurological networks are responsible for each of these in virtually every part of the brain, and how we organize and use them largely depends on how our culture, language and musical traditions developed. We don’t have dedicated rhythm processing centers, because rhythm is so fundamental to everything we do. That’s why we are so lucky as sound designers and composers to be blessed with a tool that gives us access at such a primal level to human conscious and unconscious processes. Since rhythm evolved in the animal kingdom in such a fundamental way, we need to think about it as a foundation on which other brain processes build; as Thaut says, “rhythm must be viewed as a biological fact, not just as a cultural phenomenon” (2005, 57).
Conclusion: Song = Music + Idea
Thus far, we can see a relationship between language and music that complements each other in extraordinary and cognitively complete ways. This relationship facilitates human communication and creates shared experiences in ways far beyond the strengths of either separately. On the one hand lies language, which we use to communicate referential and extremely complex meaning according to semiotic rules and structures. On the other hand, we have music, which we use to incite a wide array of complex emotions and to manipulate our sense of time. When we combine the two, as we typically do in theatre, we create songs; songs that traverse a continuum from the more traditionally considered songs characterized by lyrics with melody, through verse (lyrics with prosody), through prose (speech with prosody). In theatre, any of these forms may be accompanied by instrumental music, which creates a hierarchical level of song (melody or speech with accompaniment) that sound designers and composers cannot afford to ignore.
Many researchers separate instrumental “music” from the speech “music” of spoken language in their investigations, preferring to draw the line between “music” and “speech.” They then note many similarities between the music and speech, such as pitch, rhythm, contour and so forth! We have found that it is more helpful to make the distinction between speech language, which refers to the meaning of speech, and speech music, which carries the meaning of speech, and includes tonal color, prosody and so forth, and fundamentally aligns with instrumental music in its elementary components of color and dynamics operating in space and time (e.g., rhythm, line and texture). There are far fewer similarities when we divide our perceptions in this manner! In this chapter, we have observed that the brain seems to process how we listen and respond to speech music and instrumental music in much the same way, adding additional support to our thesis about how we evolved hearing to perceive the fundamental nature of the mechanical waves we call sound. Music works quite differently than language. Language activates far fewer parts of the brain than music. Music activates a large part of the brain, and the most primitive parts of our brain. Language functions tend to be localized in a relatively constrained and lateralized neural network (Thaut 2005, 2). Even in a different modality such as American Sign Language (visual vs. auditory), language relies on many of the same left hemisphere brain areas as spoken language (Patel 2008, 364).
As composers and sound designers for theatre, it helps tremendously to understand that composing instrumental music orchestrates the spoken word in much the same way it does melody, with greater constraints typically being placed on melody due to the use of a fixed pitch system. In either case, the instrumental music is carefully arranged to support the lead melody or prosody of the spoken lyric or prose. Once we fully separate the semiotic functions of speech from the musical, we can develop fundamental properties of music that carry the complex meanings of language and incite in the listener an appropriate emotional reaction to the communication. Some will argue that the musical elements provide language with meaning. I tend to think that music carries the meaning of language, because on its own, the music has very little meaning in the traditional sense of the word. The term “communication” implies cognitive processes that we often typically attempt to avoid when we compose sound scores for theatre. Instead we work to create shared states of mood and emotion, to which we attach meaningful language. Because we are interested in fully studying the fundamental role that music plays in theatre, we need to keep music and language separate. This method of categorization allows us to group similar auditory perceptions as color, shape, rhythm, dynamics, line and so forth into a category shared with visual art, suitable for further inquiry, and leaves the referential aspects of language such as semiotics and phonemes to others. In other words, Music as a Chariot.
It may be true, then, that “all plays start with a script,” if that is how you choose to define theatre. However, it seems to me that if we ignore millions of years of evolution that consistently point to the theatre experience evolving out of a unique combination of music, language and mimesis, we might simultaneously undermine much of our theatrical endeavors in the twenty-first century. Rather, I think that a more appropriate approach to developing a work of theatre might be to consider that every play starts with a song which must be brought to life through mimesis.
In this chapter, we have seen our species evolve from primitive humans through to our fully formed modern anatomical state, Homo sapiens sapiens. We explored how this modern brain hears sound, how it converts sound from mechanical waves into neural firings, and then how the brain processes those neural firings. Simultaneous with this evolution, we witnessed the distinct evolution of language and music, a curious and distinct feature of these modern brains not shared with any other species. We saw many similarities in how the brain processes language and music, and some important differences. We then separated music and language according to these biological differences, noting that considering them in this manner is of the utmost value to the theatre composer and sound designer because it creates a hierarchy that we must not ignore.
In the next chapters, we’ll further consider the developing elements of music as humans discovered more sophisticated means of expressing themselves. Concepts of consonance and dissonance became much more critical when we started dividing the frequency spectrum into discreet pitches. We’ll take a closer look at how consonance and dissonance also entrain neurological circuits, adding to our argument that music, and its offspring, theatre, are fundamentally immersive and experiential in nature, like dreams. And, of course, we’ll examine how these biological underpinnings are important to us as composers and designers.
Ten Questions
- What was the significance of the quartz hand axe discovered in the Sima de los Huesos cave at Atapuerca in Northern Spain? Why?
- Name two significant differences between Homo heidelbergensis that separate them from Homo erectus.
- How does Homo sapiens sapiens differ from Homo sapiens, and why does that difference allow us to study them by studying our own anatomy?
- Why is it so important for composers and sound designers to understand how human hearing works?
- In remarkably few words, identify ten components of the human ear and describe what each does.
- In remarkably few words, identify ten components of the human hearing system between the output of the cochlea and the auditory cortex and describe what each does.
- Describe two things the primary auditory cortex (core) does.
- What are Michel Chion’s three types of listening, and where and how do they manifest themselves in the auditory cortex?
- How does the human brain function like an FFT-based audio analysis system, and what does this have to do with processing human speech and music?
- Briefly describe the shared, parallel and different ways the brain uses to process speech and music and explain why rhythm does not neatly fall into any of these categories.
Things to Share
- Now that you have a pretty good understanding of the element of rhythm, it’s time to explore its ability to stir emotions in your audience. Imagine five rhythms, one for each of the following emotions: love, anger, fear, joy, sadness. Using the eraser end of a pencil, tap out these short rhythms and record them. Record these into five separate takes as audio files. Keep your takes short, less than about five seconds.
We will play your five recordings back for the class, and the class will have to suggest which rhythms most incited which emotions in them. We’ll poll the class to see which tracks they associated with each emotion, and then we’ll ask you for the order you intended. We’ll then tabulate the percentage of emotions you were able to correctly incite in each audience member, and discuss the results. - Find a short poem that you are particularly fond of and track how you imagine the prosody of the poem should be performed melodically. Use a horizontal line to track your base pitch (what researchers call F0), and then notate opposite the actual text where you think the melody goes up, and where the melody goes down, and by how much. See the example below. Prepare your entire poem for presentation, and then “sing” the poem to the class, using your graph as a guide to your performance, grossly exaggerating the pitch variation you would normally use to help us perceive them better. Make copies of your poem to share with the class so we can follow along!

Notes
1Having the same relation, relative position, or structure, in the brain.
2See Figure 6.4 for a comparison of Hominidae brain sizes.
3Technically the changes are two amino acid substitutions.
4See the references at the end of this paragraph regarding the KE family, who did indeed inherit such a mutation involving the FoxP2 gene that affected half the family members. Those afflicted had difficulty constructing grammatical sentences, often speaking in very simple speech.
5Just when you thought it was safe to make a statement about the age of Homo sapiens (conventionally placed at about 200,000 years ago), new research shows that we may be much older than originally thought: 300,000 years or so. See Hublin et al. (2017). This helps to demonstrate that evolutionary biology, like so many of our sciences, is always a work in progress, and that it can be very hard to narrow down some of these conclusions definitively. As is typical for us, however, these nuances do not upset the applecart of our central premise.
6I’ve left the discrepancy in between this reference and the Australian Museum reference of Figure 7.2 as a healthy reminder that there it can sometimes be hard to find precise agreement among researchers!
7With great apologies, we are going to increasingly focus on auditory sound and music. We’ll leave it to other enterprising theatre artists to trace the journey for visual language and music!
8Remember when we said in Chapter 2 that “sound reveals time by defining it relative to space”?
9One of 12 or 13, depending on who you talk to!
10Some researchers still divide the cortex into two areas, the primary auditory cortex (the core), and the secondary auditory cortex (the belt and the parabelt).
11The planum polare.
12The left planum temporale only.
13The superior temporal gyrus.
14A linear system is simply a system in which what you get out is directly proportional to what you put in. A graph showing input versus output will always be a straight line (hence “linear”). The brain, of course, is wildly non-linear, but Zatorre noticed a connection in this particular instance.
15Fast Fourier Transform, a mathematical equation that transforms a signal from the time domain to the frequency domain and back again. This allows one to look at the same signal displayed as either frequency or time along the horizontal axis, with amplitude in the vertical axis.
16Brodmann Area 44.
17Left inferior parietal cortex, including an area known as Wernicke’s area, critical to understanding the meaning of words (Brodmann Areas 39 and 40).
18Left middle and inferior temporal gyrus (Brodmann Areas 20 and 21).
19Inferior frontal gyrus (Brodmann Area 47).
Bibliography
Allen, John S., Hanna Damasio, and Thomas J. Grabowski. 2002. “Normal Neuroanatomical Variation in the Human Brain: An MRI-Volumetric Study.” American Journal of Physical Anthropology 118 (4): 341–358.
Appia, Adolphe. 1962. Music and the Art of Theatre. Coral Gables, FL: University of Miami Press.
Arbib, Michael A. 2013. “Précis of How the Brain Got Language: The Mirror System Hypothesis.” Language and Cognition 5 (2–3): 107–131.
Australian Museum. 2015. “Homo Erectus/Homo Heidelbergensis.” September 25. Accessed April 6, 2016. http://australianmuseum.net.au/homo-erectus; http://australianmuseum.net.au/homo-heidelbergensis.
Bickerton, Derek. 2005. “Language Evolution: A Brief Guide for Linguists.” Science Direct 117 (3): 510–526.
Brown, Steven, Michael J. Martinez, and Lawrence M. Parsons. 2006. “Music and Language Side by Side in the Brain: A PET Study of the Generation of Melodies and Sentences.” European Journal of Neuroscience 23 (10): 2791–2803.
Cann, Rebecca L., Mark Stoneking, and Allan Wilson. 1987. “Mitochondrial DNA and Human Evolution.” Nature 325 (6099): 31–36.
Chesner, C.A., W.I. Rose, A. Deino, R. Drake, and J.A. Westgate. 1991. “Eruptive History of Earth’s Largest Quaternary Caldera (Toba, Indonesia) Clarified.” Geology 19 (3): 200–203.
Chion, Michel. 1990. Audio-Vision. New York: Columbia University Press.
Cross, Ian. 2003. “Music, Cognition, Culture, and Evolution.” In The Cognitive Neuroscience of Music, edited by Isabell Peretz, and Robert Zatorre. Oxford: Oxford University Press.
Donald, Merlin. 1993a. “Human Cognitive Evolution.” Social Research 60 (1): 143–170.
———. 1993b. “Précis of Origins of the Modern Mind.” Behavioral and Brain Sciences 16 (4): 737–791.
Falk, Dean. 1999. “Hominid Brain Evolution and the Origins of Music.” In The Origins of Music, edited by Nils L. Wallin, Björn Merker, and Steven Brown, 197–216. Cambridge, MA: MIT Press.
Frayer, David W., and Chris Nicolay. 2000. “Fossil Evidence for the Origin of Speech Sounds.” In The Origins of Music, edited by Nils L. Wallion, Björn Merker, and Steven Brown, 217–234. Cambridge, MA: MIT Press.
Giraud, Anne-Lise, and David Poeppel. 2012. “Speech Perception From a Neurophysiological Perspective.” In The Human Auditory Cortex, edited by David Poeppel, Tobias Overath, Arthur N. Popper, and Richard R. Fay, 225–260. New York: Springer.
Griffiths, Timothy D., Christophe Micheyl, and Tobias Overath. 2012. “Auditory Object Analysis.” In The Human Auditory Cortex, edited by David Poeppel, Tobias Overath, Arthur N. Popper, and Richard R. Fay, 199–224. New York: Springer.
Henderson, Paul D. 2016. “The Fundamentals of FFT-Based Audio Measurements in SmaartLive®.” Rational Acoustics. Accessed April 20, 2016. www.rationalacoustics.com/files/FFT_Fundamentals.pdf.
Hublin, Jean-Jacques, Abdelouahed Ben-Ncer, Shara Bailey, Sarah E. Freidline, Simon Neubauer, Matthew M Skinner, Inga Bergmann, et al. 2017. “New Fossils from Jebel Irhoud, Morocco and the Pan-African Origin of Homo Sapiens.” Nature 546 (7657): 289–292.
Kandel, Eric R., James H. Schwartz, and Thomas M. Jessell. 2000. Principles of Neuroscience. New York: McGraw-Hill.
King, Andrew J., and Jan W.H. Schnupp. 2007. “The Auditory Cortex.” Current Biology 17 (7): R236–239.
Krause, Johannes, Carles Lalueza-Fox, Ludovic Orlando, Hernán A. Burbano, Jean-Jacques Hublin, Catherine Hänni, Javier Fortea, et al. 2007. “The Derived FOXP2 Variant of Modern Humans Was Shared with Neandertals.” Current Biology 17: 1908–1912.
Leonard, Abigail W. 2006. “Your Brain Boots Up Like a Computer.” August 17. Accessed April 10, 2016. www.livescience.com/980-brain-boots-computer.html.
Lévi-Strauss, C. 1969. The Raw and the Cooked: Introduction to a Science of Mythology. Translated by J. Weightman and D. Weightman. New York: Harper and Row.
Levitin, Daniel J. 2007. This Is Your Brain on Music. New York: Penguin Group/Plume.
Lieberman, Philip. 2007. “The Evolution of Human Speech, Its Anatomical and Neural Bases.” Current Anthropology 48 (1): 39–66.
Marean, Curtis, W. 2015. “The Most Invasive Species of All.” Scientific American, August: 32–39.
Mauro, Daniel. 2006. “The Rhythmic Brain.” The Fifth International Conference of the Cognitive Sciences. Vancouver.
Molino, Jean. 1999. “Toward an Evolutionary Theory of Music and Language.” In The Origins of Music, edited by Nils L. Wallin, Bjorn Merker, and Steven Brown, 165–176. Cambridge, MA: MIT Press.
Norman-Haignere, Sam, Nancy G. Kanwisher, and Josh H. McDermott. 2015. “Distinct Cortical Pathways for Music and Speech Revealed by Hypothesis-Free Voxel Decomposition.” Neuron 88 (6): 1281–1296.
Oxford Dictionaries. 2016. “Scene.” Accessed April 2, 2016. www.oxforddictionaries.com/us/definition/american_english/scene.
Parham, Kourosh, and James F. Willott. 1990. “Effects of Inferior Colliculus Lesions on the Acoustic Startle Response.” Behavioral Neuroscience 104 (6): 831–840.
Patel, Aniruddh D. 2008. Music Language and the Brain. New York: Oxford University Press.
PBS. 2011. “Becoming Human Part 3.” August 31. Accessed April 8, 2016. www.pbs.org/wgbh/nova/evolution/becoming-human.html#becoming-human-part-3.
Preuss, Todd M. 2012. “Human Brain Evolution: From Gene Discovery to Phenotype Discovery.” Proceedings of the National Academy of Sciences 109: 10709–10716.
Rubio, Maria E. 2010. “The Cochlear Nucleus.” June. Accessed April 24, 2016. http://neurobiologyhearing.uchc.edu/Course_Content_Library/Cochlear_nucleus/Rubio-cochlear%20nucleus%201.pdf.
Sacks, Oliver, interview by John Stewart. 2009. The Daily Show. Comedy Central. June 29.
Smithsonian Museum of Natural History. 2016a. “Homo Heidelbergensis.” June 9. Accessed June 14, 2016. http://humanorigins.si.edu/evidence/human-fossils/species/homo heidelbergensis.
———. 2016b. “Human Evolution Timeline Interactive.” March 25. Accessed March 28, 2016. http://humanorigins.si.edu/evidence/human-evolution-timeline-interactive.
Spoendlin, H., and A. Schrott. 1989. “Analysis of the Human Auditory Nerve.” Hearing Research 43 (1): 25–38.
Thaut, Michael H. 2005. Rhythm, Music, and the Brain. New York: Routledge Taylor & Francis Group.
Thomas, Richard K. 2001. “The Function of the Soundscape.” Theatre Design & Technology 37 (1): 18–26.
Tremlett, Giles. 2003. “Excalibur, the Rock that May Mark a New Dawn for Man: Palaeontologists Claim 350,000-Year-Old Find in Spanish Cave Pushes Back Boundary of Early Human Evolution.” Guardian (London) January 9: 3.
Wells, Spencer. 2007. “Out of Africa.” Vanity Fair July: 110.
Wray, Allison. 1998. “Protolanguage as a Holistic System for Social Interaction.” Language and Communication. 18 (1): 47-67
Zatorre, Robert. 2003. “Neural Specializations for Tonal Processing.” In The Cognitive Neuroscience of Music, edited by Isabelle Peretz and Robert Zatorre. Oxford: Oxford University Press.
Zattore, Robert J., and Jean Mary Zarate. 2012. “Cortical Processing of Music.” In The Human Auditory Cortex, edited by David Poeppel, Tobias Overath, Arthur N. Popper, and Richard R. Fay, 261–294. New York: Springer.