
Routing algorithms for workload consolidation†
Abstract
To provide efficient, high-performance routing algorithms, a holistic approach should be taken. The key aspects of routing algorithm design include adaptivity, path selection strategy, virtual channel allocation, isolation, and hardware implementation cost; these design aspects are not independent. The key contribution of this chapter lies in the design of a novel selection strategy, the destination-based selection strategy (DBSS), which targets interference that can arise in many-core systems running consolidation workloads. In the process of this design, we holistically consider all aspects to ensure an efficient design. Existing routing algorithms largely overlook issues associated with workload consolidation. Locally adaptive algorithms do not consider enough status information to avoid network congestion. Globally adaptive routing algorithms attack this issue by utilizing network status beyond neighboring nodes. However, they may suffer from interference, coupling the behavior of otherwise independent applications. To address these issues, DBSS leverages both local and nonlocal network status to provide more effective adaptivity. More importantly, by integrating the destination into the selection procedure, DBSS mitigates interference and offers dynamic isolation among applications. Experimental results show that DBSS offers better performance than the best baseline selection strategy and improves the energy-delay product for medium and high injection rates; it is well suited for workload consolidation.
5.1 Introduction
Given the difficulty of extracting parallelism, it is quite likely that multiple applications will run concurrently on a many-core system [3, 25, 36], often referred to as workload consolidation. Significant research exists on maintaining isolation and effectively sharing on-chip resources such as caches [53] and memory controllers [46]. The network-on-chip (NoC) [11] is another, less-explored example of a shared resource where one application's traffic may degrade the performance of another. This work focuses on improving performance and providing isolation for workload consolidation via the routing algorithm.
Several requirements are placed on the routing algorithm for high performance. First, the routing algorithm should leverage available path diversity to provide sufficient adaptivity to avoid network congestion. Closely related to the issue of adaptivity is virtual channel (VC) [9] allocation (VA) and the need to provide deadlock freedom. Second, it should not leverage superfluous information leading to inaccurate estimates of network status. Finally, the routing algorithm should be implemented with low hardware cost. Workload consolidation has an additional requirement: dynamic isolation among applications. Existing routing algorithms are unable to meet all these needs. Oblivious routing, such as dimensional order routing (DOR), ignores network status, resulting in poor load balancing. Adaptive routing offers the ability to avoid congestion by supporting multiple paths between a source and the destination; a selection strategy is applied to choose between multiple outputs. Most existing selection strategies do not offer both adaptivity and isolation.
The selection strategy should choose the output port that will route a packet along the least congested path. A local selection strategy (LOCAL) leverages only the status of neighboring nodes, which tends to violate the global balance intrinsic to traffic [22]. Globally adaptive selection strategies, such as regional congestion awareness (RCA) [22], utilize a dedicated network to gather global information; it introduces excess information when selecting the output port and offers no isolation among applications, leading to performance degradation for consolidated workloads. This excess information can be classified as intra-application and interapplication interference. Interference makes the performance less predictable.
Considering the future prevalence of server consolidation and the need for performance isolation, an efficient routing algorithm should combine high adaptivity with dynamic workload isolation. Therefore, we believe utilizing precise information is preferable; redundant or insufficient information easily leads to inferior performance. On the basis of this insight, we introduce the destination-based selection strategy (DBSS), which is well suited to workload consolidation.
We design a low-cost congestion information propagation network to leverage both local and nonlocal network status, giving DBSS high adaptivity. Furthermore, DBSS chooses the output port by considering only the nodes that a packet may traverse, while ignoring nodes located outside the minimum quadrant defined by the current location and the destination. Thus, it eliminates redundant information and dynamically isolates applications.
Integral to the evaluation of a new selection strategy is the underlying routing function. To provide a thorough exploration, we analyze the offered path diversity of several fully and partially adaptive routing functions. We also consider the VC reallocation scheme [12] that is required for deadlock freedom. On the basis of an appropriate routing function, we evaluate DBSS against other selection strategies for both a regular mesh and a concentrated mesh (CMesh). Our experimental results show that DBSS outperforms the other strategies for all evaluated network configurations.
In this chapter we make the following contributions:
• We analyze the limitations of other selection strategies and propose DBSS, which affords sufficient adaptivity for congestion avoidance and dynamic isolation among applications.
• We explore the effect of interference and demonstrate that the amount of congestion information considered impacts performance, especially for consolidated workloads.
• We design a low-cost congestion status propagation network with only 3.125% wiring overhead to leverage both local and nonlocal information.
• We holistically consider path diversity and VC reallocation to provide further insight for routing algorithm design.
5.2 Background
In this section, we discuss related work in application mapping and adaptive routing algorithm design.
Since the arrival order and execution time of consolidated workloads cannot be known at the design time, run-time application mapping techniques are needed [7, 8, 27, 34]. Mapping each application to a near convex region is optimal for workload consolidation [7, 8]. Most application mapping techniques consider the Manhattan distance between the source and the destination but not the routing paths [8, 34]; routing algorithm design is complementary to these techniques.
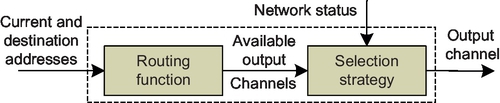
As shown in Figure 5.1, an adaptive routing algorithm consists of two parts: the routing function and the selection strategy [1]. The routing function computes the set of possible output channels, while the selection strategy chooses one of them on the basis of the network status. A routing function must achieve deadlock freedom. This can be achieved by removing cycles from the channel dependency graph [10]. Duato [15, 16] proved that cycles are allowed in the channel dependency graph once there is a deadlock-free routing subfunction. Duato's theory is powerful for designing fully adaptive routing functions which allow all minimal paths for packet routing. Turn model functions avoid deadlock by offering only a subset of all minimal paths [6, 19, 21]. In addition to the offered path diversity, partially and fully adaptive functions differ in the VC reallocation. Partially adaptive routing can utilize an aggressive VC reallocation scheme, while fully adaptive routing can only leverage a conservative scheme. VC reallocation strongly impacts performance and cannot be overlooked in the design of routing algorithms [19, 39].
Off-chip networks are constrained by pin bandwidth, but the abundant wiring resources in NoCs allow easier implementation of congestion propagation mechanisms. Therefore, the NoC paradigm has sparked renewed interest in adaptive routing algorithms. DyAD combines the advantages of both deterministic and adaptive routing schemes [26]. DyXY uses dedicated wires to investigate the status of neighboring routers [35]. A low-latency adaptive routing algorithm performs lookahead routing and preselects the optimal output port [31]. The selection strategies of these designs [26, 31, 35] all leverage the status of the neighboring nodes. Many oblivious selection strategies have also been evaluated, including zigzag, XY, and no turn [13, 18, 21, 42, 52]. Neighbors-on-path (NoP) makes a selection based on the condition of the nodes adjacent to neighbors [1].
RCA is the first strategy utilizing global information to improve load balancing in NoCs [22]; however, it introduces interference. Redundant information may degrade the quality of the congestion estimates; to combat this, packet destination information can be leveraged to eliminate excess information [49]. Per-destination delay estimates steer the output selection. Despite leveraging a similar observation, our design is quite different. Moreover, we focus on the performance with workload consolidation. The bLBDR design [50] provides strict isolation among applications by statically configuring connectivity bits. In contrast, we offer more dynamic isolation.
5.3 Motivation
The need for a novel selection strategy was motivated from two directions. First, the selection strategy should have enough information about network conditions to offer effective congestion avoidance. Both local and NoP [1] selection strategies lack enough information, leading to suboptimal performance. Second, intra-application and interapplication interference should be minimized. The RCA strategy [22] utilizes global network information but does not consider interference. DBSS offers a middle ground between these extremes.
5.3.1 Insufficient information
The local selection strategy (LOCAL) leverages the conditions of neighboring nodes. These conditions may be free buffers [1, 22, 26, 31, 35], free VCs [13, 22], crossbar demands [22], or a combination of these [22]. Figure 5.2a shows a packet at router (0,2) that is routed to (2,0). A selection strategy is needed to choose between the west and south ports; LOCAL uses only the information about the nearest nodes ((0,1) and (1,2)). Without any information about the condition beyond neighbors, it cannot avoid congestion more than one hop away from the current node.
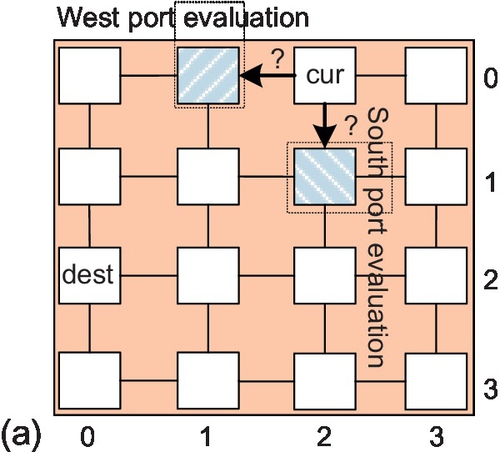



NoP uses the status of nodes adjacent to neighboring nodes as shown in Figure 5.2b. The limitation is that NoP ignores the status of neighbors ((0,1) and (1,2)); it makes decisions only on the basis of the conditions of nodes two hops away. In the example, for west output evaluation, it considers nodes (0,0) and (1,1). For the south port, it considers nodes (2,2) and (1,1). This strategy works well with an odd-even turn model [1]. However, with a fully adaptive routing function, its performance degrades owing to limited knowledge.
5.3.2 Intraregion interference
Three RCA variants have been proposed: RCA-1D, RCA-Fanin, and RCA-Quadrant [22]. No single RCA variant provides the best performance across all traffic patterns; therefore, we use RCA-1D as a baseline. Figure 5.2c shows an intraregion1 scenario for RCA-1D. All 16 nodes run the same application. When evaluating the west output, RCA-1D considers nodes (0,1) and (0,0). Similarly, it considers nodes (1,2), (2,2), and (3,2) when evaluating the south port. For destination node (2,0), the information from node (3,2) causes interference as it lies outside the minimum quadrant defined by (0,2) and (2,0); the packet will not traverse this node. This interference may result in poor output port selection, especially considering traffic locality.
We show the average hop count (AHP) to measure locality for several synthetic traffic patterns [12] in Figure 5.3. Most traffic has an AHP of less than 5.6 (average 5.58) and 3 (average 2.63) for 8 × 8 and 4 × 4 meshes respectively. These patterns exhibit locality as most packets travel a short distance. Thus, we need strategies to mitigate intra-application interference.

5.3.3 Inter-region interference
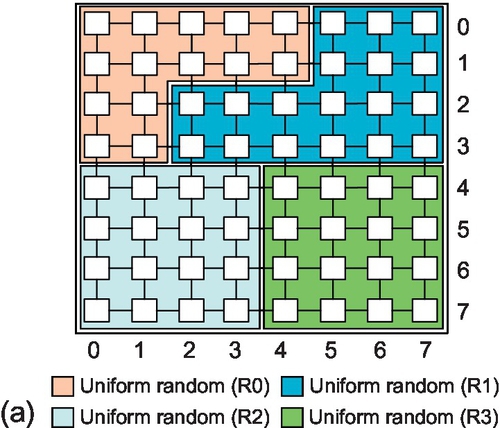
Figure 5.4 illustrates a workload consolidation example for an 8 × 8 mesh; similar scenarios will be prevalent in many-core systems. Here, there are four concurrent applications and each one is mapped to a 4 × 4 region. Region R0 is defined by nodes (0,0) and (3,3), region R1 is defined by nodes (0,4) and (3,7), region R2 is defined by nodes (4,0) and (7,3), and region R3 is defined by nodes (4,4) and (7,7). Figure 5.4 shows a packet in R0 whose current location and destination are (0,2) and (2,0) respectively. Even though traffic in R0 is isolated from traffic in other regions, RCA-1D considers the congestion status of nodes in R2 when selecting output ports for traffic belonging to R0. Obviously, this method introduces interference and reduces performance isolation.
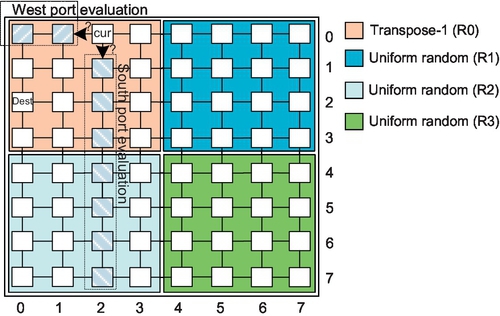
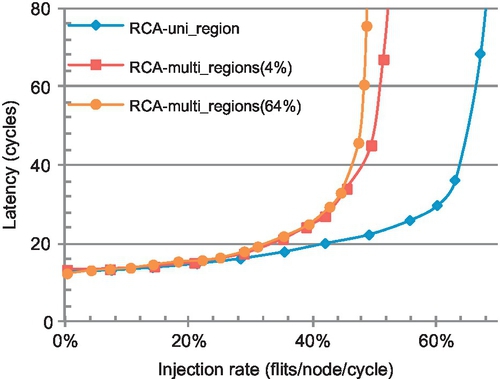
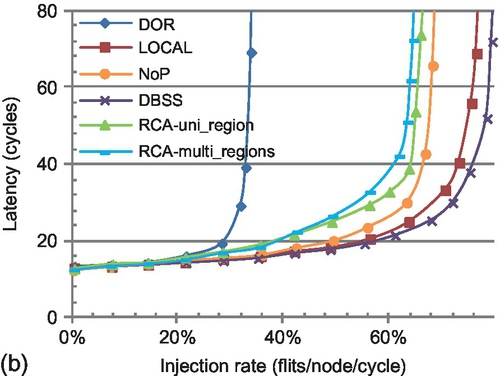
To evaluate the effect of inter-region interference, we assign transpose-1 traffic [6, 12] to R0 and uniform random traffic to R1, R2, and R3.2 Figure 5.5 shows the performance of R0. The RCA-uni_region curve represents a single region (R0) in a 4 × 4 network; this latency reflects perfect isolation and no inter-region interference. The saturation throughput of RCA-1D is approximately 65%. However, without isolation, the saturation throughput drops dramatically to approximately 50%, as shown by the RCA-multi_regions(4%) curve, where R1, R2, and R3 all have an injection rate of 4%. For the RCA-multi_regions(64%) curve, R1 has an injection rate of 64%, while the injection rate remains 4% for R2 and R3; in this unbalanced scenario, the saturation throughput of R0 further decreases to 47%. Clearly, the congestion information of R1, R2, and R3 greatly affects the routing selection in R0. RCA-1D couples the activities of otherwise independent applications, which is not desirable for workload consolidation.
DBSS aims to reduce the interference by considering only nodes in the minimum quadrant defined by the current and destination nodes. In Figure 5.2d, when evaluating the west output, DBSS considers nodes (0,1) and (0,0); for the south output, it considers nodes (1,2) and (2,2). DBSS leverages information from both local and nonlocal nodes; it has more accurate knowledge than LOCAL and NoP. DBSS does not consider node (3,2), which eliminates interference. More importantly, for workload consolidation with each application mapped to a near convex region [7, 8], DBSS dynamically isolates routing for each region.
5.4 Destination-based adaptive routing
5.4.1 Destination-based selection strategy
The selection strategy in adaptive routing algorithms significantly impacts performance [1, 18, 42, 52]. An efficient strategy should ideally satisfy two goals: high adaptivity and dynamic isolation.
5.4.1.1 Congestion information propagation network
NoCs can take advantage of abundant wiring to employ a dedicated network to exchange congestion status. First we explain the design of the low-cost congestion information propagation network, which enables a router to leverage both local and nonlocal status. Both NoP and RCA utilize such a low-bandwidth monitoring network [1, 22]. We focus on obtaining global information; the propagation network in RCA serves as the best comparison point.
At each hop in RCA's congestion propagation network, the local status is aggregated with information from remote nodes and then propagated to upstream routers [22]. This implementation has two limitations. First, the aggregation logic combines local and distant information during transmission, making it impossible to filter out superfluous information. Second, the aggregation logic adds an extra cycle of latency per hop, leading to stale information at distant routers. On the basis of these two observations, we propose a novel propagation network, which consumes only one cycle per tile, giving DBSS timelier network status. More importantly, the design makes it feasible to filter out information on the basis of the packet destination.
Figure 5.6 shows the congestion propagation network for the third row of an 8 × 8 mesh; the same structure is present in each row and column. Along a dimension, each router has a register (congestion_X or congestion_Y) to store the incoming congestion information. The incoming information along with the local status is forwarded to the neighboring nodes in the next cycle via congestion propagation channels.

We use free VC count as the congestion metric. To cover the range of free VCs, the width of each congestion propagation channel along one direction is log (numVCs). However, a coarser approximation is sufficient. For neighboring routers, making a fine distinction has little impact. On the other hand, since the incoming congestion information is weighted according to the distance, it is also unnecessary to have accurate numbers for distant routers. As we show in Section 5.6.2, one wire per node is sufficient to achieve high performance; the router forwards congestion information in an on/off manner. The threshold for indicating congestion is four VCs (out of eight VCs); when five or more VCs are available, no congestion is signaled. Coarse-grained congestion signals will toggle infrequently, resulting in a low activity factor and low power consumption.
With use of this coarse-grained monitoring, the congestion_X and congestion_Y registers are both n + 1 bits wide for an n × n network (e.g., 9 bits for an 8 × 8 network). Incoming congestion information from routers in the same dimension is stored in 7 bits and the other 2 bits store the conditions of two ports of the local router. The router weights the incoming congestion information on the basis of the distance from the current router; the weight is halved for each additional hop. This ratio is chosen on the basis of prior work [22] and implementation complexity. Adjacent bit positions of a register inherently maintain a step ratio of 0.5; we implement this weighting by putting the incoming information into the appropriate positions in the register.
Figure 5.7 shows the format of congestion_X in router (3,2). Bit 0 stores the east input port status of the current router. Bits 1 and 2 store the incoming congestion information from its nearest and one hop farther west neighbors: (3,1) and (3,0) respectively. These 3 bits are forwarded to the east neighbor: (3,3). Bit 3 stores the west input port status of the current router, and the following 5 bits sequentially store the west input port status of the remaining east side routers on the basis of the distance. These 6 bits are forwarded to the west neighbor: (3,1). The format of congestion_Y is similar.

5.4.1.2 DBSS router microarchitecture
The DBSS router is based on a canonical VC router [12, 17]. The router pipeline has four stages: routing computation (RC), VA, switch allocation (SA), and switch traversal (ST). Link traversal (LT) requires one cycle to forward the flit to the next hop. For high performance, the router uses speculative SA [48]; VA and SA proceed in parallel at low load. We also leverage lookahead adaptive RC; the router calculates at most two alternative output ports for the next hop [20, 22, 31]. Advanced bundles [24, 32] encoding the packet destination traverse the link to the next hop while the flit is in the ST stage as shown in Figure 5.8.

Selection metric computation
The selection metric computation (SMC) and dimension preselection (DP) modules are added as illustrated in Figure 5.9. SMC computes the dimension of the optimal output port for every possible destination using the congestion information stored in congestion_X and congestion_Y. An additional register, out_dim, stores the results of SMC. With minimal routing, there are at most two admissible ports (one per dimension) for each destination. Because of this property, the out_dim register uses 1 bit to represent the optimal output port. If the value is “0,” the optimal output port is along dimension X; otherwise, it is along dimension Y.

Figure 5.10 shows the pseudocode of SMC to compute the optimal output dimension for a packet whose destination is the posth bit position of the out_dim register. Packets forwarded to the local node are excluded from this logic. Along each dimension, only those bit positions in congestion_X and congestion_Y storing congestion information for nodes inside the quadrant defined by the current and the posth nodes are chosen. The values chosen are the congestion status metric for each dimension. According to the relative magnitude of the congestion status for the X and Y dimensions, SMC sets the value of the posth bit in the out_dim register. If their magnitudes are equal, DBSS randomly chooses an output dimension.

Dimension preselection
To remove the output port selection from the critical path, the DP module accesses the out_dim register one cycle ahead of the flit's arrival. The value of out_dim is computed out by SMC in the previous cycle. The DP module is implemented as a 64-to-1 multiplexer, which selects the corresponding bit position of the out_dim register according to the destination encoded in an advanced bundle. When the head flit arrives, it chooses the output port according to the result of DP. With use of the logical effort model [48], the delay of the DP module is approximately 8.1 fan-outs of 4 (FO4). If the DP were added to the VA stage, the critical path would increase from 20 FO4 to 28.1 FO4. Advanced bundles serve to avoid this increase.
5.4.2 Routing function design
The focus of this work is a novel selection strategy; however, the efficacy of the selection strategy is tightly coupled to other aspects of routing algorithm design, including adaptivity and VC reallocation. We compare several adaptive routing functions. Previous analysis [44] ignored the effect of VC reallocation. The majority of NoC packets are short [23, 39], making VC reallocation more important. Thus, it is necessary to re-evaluate routing functions by considering both the offered path diversity and VC reallocation.
5.4.2.1 Offered path diversity
Partially adaptive routing functions avoid deadlock by forbidding certain turns [6, 19, 21]. Owing to the prohibition of east→south and north→west turns, negative-first routing can utilize all minimal paths when the X and Y positions of the destination are both positive or negative with respect to the source. If only one is positive, it provides one minimal path [21]. Similarly, west-first and north-last routing utilize all minimal paths when the destination is east and south of the source respectively. Otherwise, only one path is allowed [21]. The odd-even routing applies different turn restrictions on odd and even columns for even adaptiveness.
In contrast to turn models, fully adaptive routing provides all minimal physical paths but places restrictions on VCs. Most fully adaptive routing functions are designed on the basis of Duato's theory [15], in which the VCs are classified into adaptive and escape VCs. There is no restriction on the routing of adaptive VCs; escape VCs can be utilized only if the output port adheres to a deadlock-free algorithm, usually DOR.
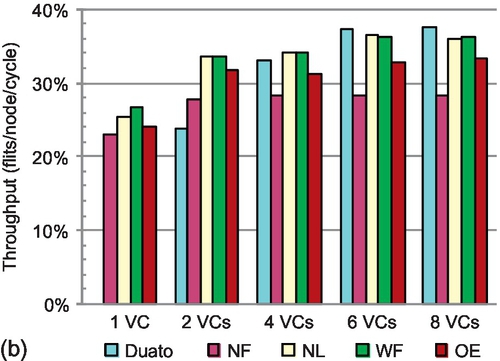
We compare the path diversity offered by a fully adaptive routing function (Duato) with several turn models in Figure 5.11. The path diversity is measured as the ratio of the number of times that the routing function provides two admissible ports versus one. We vary the VC count. For turn models, one VC is enough to avoid deadlock; the Duato model needs at least two VCs. A local selection strategy is utilized. When each port is configured with four or fewer VCs, the selection is based on the buffer availability of neighbors. The VC availability is utilized if the VC count is greater than four. Adjusting the congestion metric according to the VC count can more stringently reflect the network status. The experiments are conducted on a 4 × 4 mesh; larger networks show similar trends.
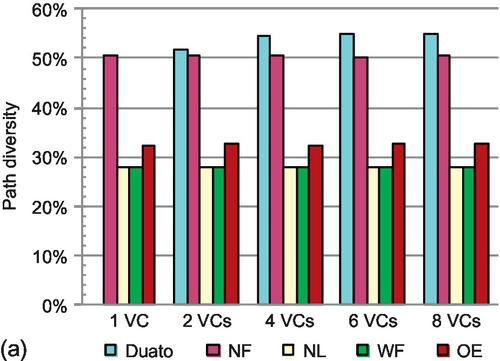


As can be seen, at least approximately 25% of RCs produce two admissible ports; a selection strategy is needed to make a choice. For Duato and negative-first, more than 50% of RCs utilize the selection strategy under bit reverse and transpose-1 patterns. This ratio increases with larger network size. These results emphasize the importance of designing an effective selection strategy.
Duato generally shows the highest path diversity. The only exception is for transpose-1. Since all traffic is between the north-east and south-west quadrants, negative-first has the highest path diversity. The limitation on escape VCs yields slightly lower diversity for Duato. Once a packet enters an escape VC, it can only use escape VCs in subsequent hops; this packet loses path diversity. For the same reason, the diversity of Duato decreases with smaller VC counts. There is almost no difference for Duato with six and eight VCs; six VCs are enough to mitigate the escape VC limitation. The path diversity of partially adaptive routing is not sensitive to VC count. Negative-first offers no path diversity for transpose-2 since all traffic is between the north-west and south-east quadrants. Negative-first offers unstable path diversity for two symmetric transpose patterns. The four patterns evaluated are symmetric around the center of the mesh; west-first and north-last perform the same under such patterns.
5.4.2.2 VC reallocation scheme
The VC reallocation is an important yet often overlooked limitation for fully adaptive routing functions. Owing to cyclic channel dependencies, only empty VCs can be reallocated [15, 16]. If nonempty VCs are reallocated, a deadlock configuration is easily formed [15, 16].
Since partially adaptive functions prohibit cyclic channel dependencies, nonempty VCs can be reallocated [10]. They reallocate an output VC when the tail flit of the last packet goes through the ST stage of the current router, which is called aggressive VC reallocation. Instead, fully adaptive functions reallocate an output VC only after the tail flit of the last packet has gone through the ST stage of the next-hop router, which is called conservative VC reallocation [12, 19]. The difference between these schemes is shown in Figure 5.12.



In cycle 0, packet P0 resides in VC0. P0 waits for VC2 and VC3, which are occupied by P1 and P2 respectively. Both VC2 and VC3 have some free slots. The aggressive VC reallocation scheme forwards the header flit of P0 to VC2 in cycle 1, as shown in Figure 5.12b. However, for fully adaptive routing, P0 must wait for 3 + i cycles to be forwarded (Figure 5.12c), where i denotes the delay due to contention. Assuming round-robin arbitration [12] for both VA and SA and no contention from other input ports, it takes six cycles for VC2 to become empty. Then, P0 can be forwarded. More cycles are needed with contention from other input ports. The aggressive VC reallocation has better VC utilization, leading to improved performance. Allowing multiple packets to reside in one VC may result in head-of-line (HoL) blocking [29]. However, as we will show in Section 5.5.1, with limited VCs, making efficient use of VCs strongly outweighs the negative effect of HoL blocking.
5.5 Evaluation
We modify BookSim [28] to model the microarchitecture discussed in Section 5.4.1.2. The evaluation consists of three parts: we first consider the routing functions. Negative-first, north-last, west-first, and odd-even models and a fully adaptive routing function based on Duato's theory are evaluated with a local selection strategy. Then, the fully adaptive function is chosen for the selection strategy evaluation. A local strategy (LOCAL), NoP, RCA-1D,3 and DBSS are implemented for meshes of different size. Finally, we extend the evaluation to CMeshes [2, 33].
Several synthetic traffic patterns [6, 12] are used. Each VC is configured with five flit buffers, and the packet length is uniformly distributed between one and six flits. Workload consolidation scenarios are evaluated with multiple regions configured inside a network. The injection procedure for each region is independently controlled as if a region is a whole network. The destinations of all traffic generated from one region stay within the same region. The latency and throughput are measured for each region. The routing algorithm is configured at the network level.
To measure full-system performance, we leverage FeS2 [47] for x86 simulation and BookSim for NoC simulation. FeS2 is implemented as a module for Virtutech Simics [41]. We run PARSEC benchmarks [4] with 16 threads on a 16-core chip multiprocessor, organized in a 4 × 4 mesh. Workload consolidation scenarios are also evaluated. An 8 × 8 mesh with four 4 × 4 regions is configured in BookSim. Region R0 delivers the traffic generated by FeS2, while the remaining regions run uniform random patterns. A mix of real applications and synthetic traffic was used owing to scalability problems with the simulator and operating system [5]. Prior research showed the frequency of simple cores can be optimized to 5-10 GHz, while the frequency of NoC routers is limited by the allocator speed [14]. We assume cores are clocked four times faster than the network. Cache lines are 64 bytes, and the network flit width is 16 bytes. All benchmarks use the simsmall input sets. The total run time is used as the performance metric. Table 5.1 presents the system configuration.
Table 5.1
The Full System Simulation Configuration
| Parameter | Value |
| No. of cores | 16 |
| L1 cache (D and I) | Private, 4-way, 32 kB each |
| L2 cache | Private, 8-way, 512 kB each |
| Cache coherence | MOESI distributed directory |
| Topology | 4 × 4 mesh, 4 VNs, 8 VCs per VN |
L1, first level; L2, second level; VN, virtual network.
5.5.1 Evaluation of routing functions
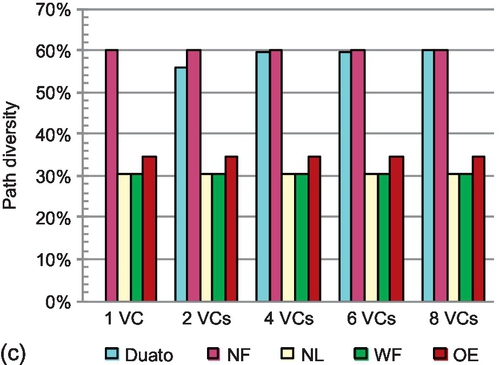
Figure 5.13 illustrates the results of routing function evaluation; the saturation throughput4 achieved is the performance metric. From the comparison of partially adaptive functions in Figures 5.11 and 5.13, generally higher path diversity leads to higher saturation throughput. However, owing to the conservative VC reallocation, Duato's performance with two VCs is lower than that of some partially adaptive functions even though it offers higher path diversity. For example, with bit reverse traffic, negative-first and odd-even show 47.1% and 30.6% higher performance than Duato respectively. With two VCs, improving the VC utilization greatly outweighs the negative effect of HoL blocking induced by aggressive VC reallocation.


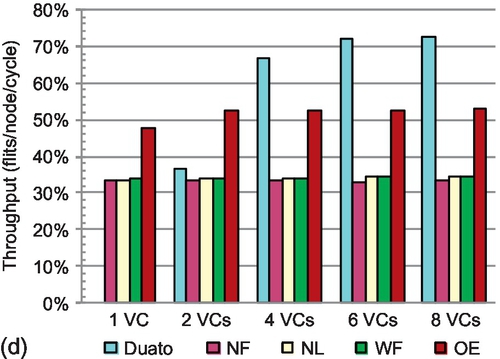
Duato's performance increases significantly with four VCs. More VCs improve the possibility of finding empty VCs; the difference between aggressive and conservative VC reallocation schemes declines. For example, Duato achieves the highest performance for bit reverse traffic. Most partially adaptive functions have significant improvement in performance when the VC count increases from one to two, but the performance gain increases only slightly when the VC count increases to four. More VCs mitigate the negative effect of HoL blocking. Two VCs are enough to reduce the HoL effect, thus improving the importance of path diversity. Moreover, with aggressive VC reallocation, configuring two VCs fully utilizes the physical channel. These two factors make path diversity the performance bottleneck with four VCs.
Duato's performance steadily increases with six VCs. Six VCs help to stress the physical channel with conservative VC reallocation. Also, Duato provides enough path diversity, preventing it from rapidly becoming the bottleneck. The performance gain when the VC count increases from six to eight is small; with eight VCs, the physical path congestion becomes the limiting factor. A noteworthy phenomenon is observed for bit complement traffic with eight VCs: although Duato has twice the path diversity of the three turn models, its performance is only slightly better. Most bit-complement traffic traverses the center area of the mesh, and Duato's high path diversity can only slightly mitigate this region's congestion problem.
In summary, our evaluation of routing functions gives the following insights:
(1) With limited VCs, providing efficient VC utilization greatly outweighs the negative effect of HoL blocking. The efficient VC utilization provided by aggressive VC reallocation compensates for the limited path diversity of partially adaptive functions, resulting in higher performance than for fully adaptive ones.
(2) With more VCs, the offered path diversity of routing functions becomes the dominating factor for performance.
(3) Configuring the appropriate VC count for NoCs must consider the applied routing function. For partially adaptive routing functions with aggressive VC reallocation, generally two VCs are enough to provide high performance. More VCs not only add hardware overhead, but do not improve performance much. For the fully adaptive routing functions, at most eight VCs are enough for performance gains.
5.5.2 Single-region performance
From previous analysis, Duato achieves the highest performance with more than six VCs; we chose it as the routing function for the selection strategy analysis. Synthetic traffic evaluation is conducted with eight VCs, which are enough to stress the physical channel. We first evaluate the performance of two single-region configurations: 4 × 4 and 8 × 8 meshes. There is only one traffic pattern throughout the whole network.
5.5.2.1 Synthetic traffic results
Figures 5.14 and 5.15 give the latency results for transpose-1, bit reverse, shuffle, and bit complement traffic patterns in 4 × 4 and 8 × 8 meshes respectively. In the 4 × 4 mesh, DBSS has the best performance for these four traffic patterns as RCA suffers from intraregion interference. There is one exception: for bit complement traffic, RCA's saturation point is 2.1% higher. Bit complement traffic has the largest AHP, with four hops in a 4 × 4 network (Figure 5.3); this AHP mitigates the intraregion interference. LOCAL and NoP perform the worst for bit complement traffic owing to their limited knowledge. The small AHP (2.5 hops) of transpose-1 traffic leads to RCA performing the worst among all four adaptive algorithms. DBSS, LOCAL, and NoP offer similar performance for transpose-1 traffic, with approximately 13% improvement in saturation throughput versus RCA. DBSS has a significant improvement of 21.9% relative to RCA for bit reverse traffic.



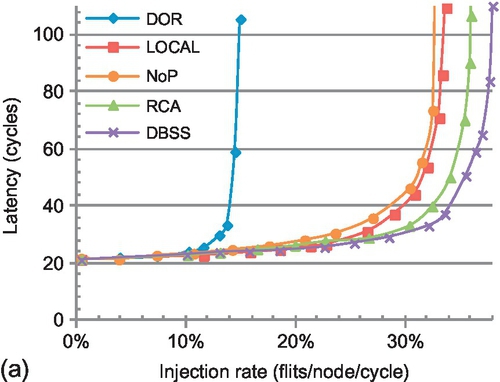
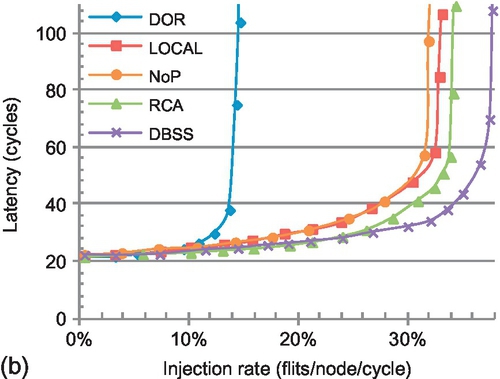


DBSS improves saturation throughput by 10.2% and 8.5% over LOCAL for shuffle and bit complement traffic. These patterns cause global congestion, and the shortsightedness of the locally adaptive strategy makes it unable to avoid congested areas. The saturation throughput improvements of DBSS over NoP are 17.7% and 11.1% for bit reverse and bit complement traffic respectively. NoP overlooks the status of neighbors. Comparing the performance of LOCAL against NoP further illuminates this limitation. This phenomenon validates our weighting mechanism placing more emphasis on closer nodes.
LOCAL outperforms RCA on a 4 × 4 mesh; intraregion interference leads RCA to make inferior decisions. However, in the 8 × 8 mesh, DBSS and RCA offer the best performance, while LOCAL has inferior performance. RCA's improvement comes from the weighting mechanism in the congestion propagation network. The weight of the congestion information halves for each hop; the effect of intraregion interference from distant nodes diminishes. This interference reduction is a result of the high AHP of 5.58 for these patterns. However, the AHP on the 4 × 4 network is 2.63, which is not large enough to hide the negative effect of interference. Although the weighted aggregation mechanism mitigates some interference in the 8 × 8 mesh, DBSS still outperforms RCA by 11.1% for bit reverse traffic. Compared with the 4 × 4 network, DBSS further improves the saturation throughput for shuffle and bit complement traffic versus LOCAL by 12.4% and 16.5%. The shortsightedness of LOCAL has a stronger impact in a larger network. Similar trends are seen for NoP. For most traffic, DOR's rigidity prevents it from avoiding congestion, resulting in the poorest performance.
5.5.2.2 Application results
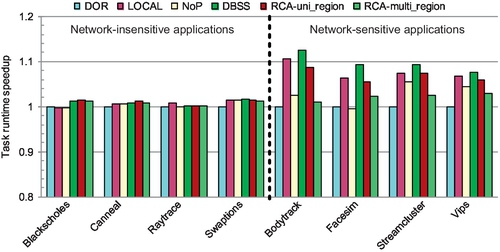
Figure 5.16 shows the speedups relative to DOR for eight PARSEC workloads. The workloads can be classified into two groups: network-insensitive applications and network-sensitive applications. Sophisticated routing algorithms can improve the network saturation throughput, but the full-system performance improvements depend on the load and traffic pattern created by each application [51]. Applications with a high network load and significant bursty traffic receive benefit from advanced routing algorithms. For blackscholes, canneal, raytrace, and swaption, their working sets fit into the private second-level caches, resulting in low network load. Different routing algorithms have similar performance for this group. The other four applications have lots of bursty traffic, emphasizing network-level optimization techniques; their performance benefits from routing algorithms supporting higher saturation throughput. For these four applications, DBSS and LOCAL have the best performance owing to the small network size. DBSS achieves an average speedup of 9.6% and a maximum speedup of 12.5% over DOR. RCA performs better than NoP. NoP is worse than DOR for facesim. Its ignorance of neighboring nodes results in suboptimal selections.
5.5.3 Multiple-region performance
We evaluate two multiple-region configurations: one regular-region configuration (Figure 5.4) and one irregular-region configuration (Figure 5.17a). In both configurations, we focus on the performance of region R0.

5.5.3.1 Results for a small regular region
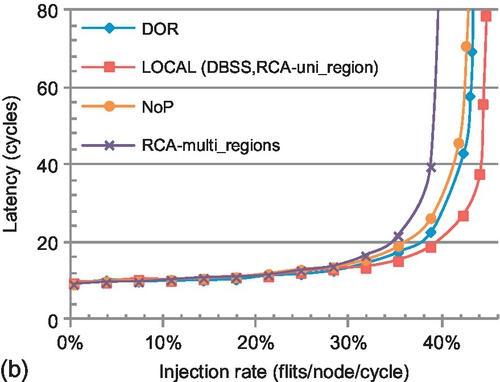
In this configuration (Figure 5.4), regions R1, R2, and R3 run uniform random traffic with injection rates of 4%, while we vary the pattern in region R0. LOCAL, NoP, and DBSS do not have inter-region interference, since they consider only the congestion status of nodes belonging to the same region when making selections. Thus, in this configuration, all algorithms except RCA have the same performance as in Figure 5.14. RCA's performance suffers from inter-region interference. The RCA-multi_regions curves in Figure 5.14 show RCA's performance for the multiple-region configuration.
Compared with a single region, RCA's performance declines; RCA suffers not only from intraregion interference, but also from inter-region interference. Transpose-1 and shuffle traffic see 22.7% and 16.9% drops in saturation throughput. For bit reverse traffic, the performance degradation is minor; the intraregion interference has already significantly degraded RCA's performance and hides the effect of inter-region interference. DBSS maintains its performance for this configuration, thus revealing a clear advantage. The average saturation throughput improvement is 25.2%, with a maximum improvement of 46.1% for transpose-1 traffic. Figure 5.16 (RCA-multi_regions) shows that RCA's performance decreases for these four network-sensitive applications compared with the single-region configuration (R1, R2, and R3 run uniform random traffic with injection rates of 4%). The maximum performance decrease (7.3%) occurs for bodytrack.
Routers at the region boundaries strongly affect R0's performance, since some of their input ports are never used. For example, the west input VCs of router (0,4) are always available since no packets arrive from the west. The interference from internal nodes of R1 and R2 is partially masked by RCA's weighting mechanism at these boundary nodes with eight free VCs. This explains why R0's saturation point decreases from 50% to only 47% when the injection rate of R1 increases from 4% to 64% in Figure 5.5.
5.5.3.2 Irregular-region results
Figure 5.17a shows nonrectangular regions. The isolation boundaries of R0 and R1 are the minimal rectangles surrounding them; traffic from both regions shares some network links, so the traffic from R1 affects routing in R0 in some cases. Figure 5.17b shows the performance of R0 while the injection rate of R1 is varied from low load (4%) to high load (55%); the injection rates of R2 and R3 are fixed at 4%. All regions run uniform random traffic.
For both high and low loads in R1, DBSS has the best performance. As the load in R1 increases, the performance of all algorithms declines. For low load in R1, RCA has the second-highest saturation throughput. Two rows of R0 have five routers; LOCAL and NoP are not sufficient to avoid congestion. When R1 has a high injection rate, the saturation points decline for DOR, LOCAL, NoP, RCA, and DBSS by 7%, 7%, 6.8%, 6.7%, and 4% respectively; DBSS has the least performance degradation since it offers the best isolation between R0 and R1. As these two regions are not completely isolated, some traffic for R0 and R1 shares common network links; in this case, traffic from R1 should affect routing in R0. Only traffic between the routers in the first two columns and routers in the last two columns is completely isolated; DBSS correctly accounts for this dependency across the regions, which makes it a flexible and powerful technique.
5.5.3.3 Summary
In workload consolidation scenarios, different applications will be mapped to different region sizes according to their intrinsic parallelism. However, with small regions, RCA suffers from interference, while LOCAL and NoP are limited by shortsightedness for large regions. Table 5.2 lists the average saturation throughput improvement of DBSS against other strategies. DBSS provides the best performance for all configurations evaluated and it shows the smallest performance degradation in multiple irregular regions. DBSS can provide more predictable performance when running multiple applications. DBSS is well suited to workload consolidation.

5.5.4 CMesh evaluation
5.5.4.1 Configuration
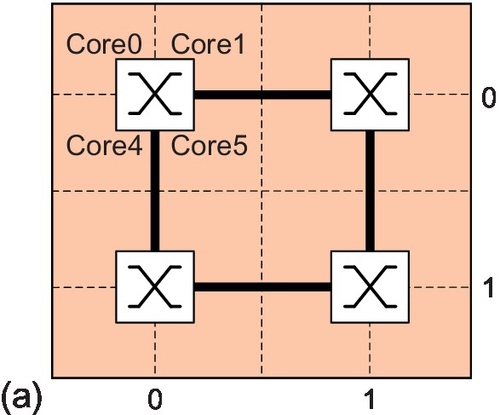
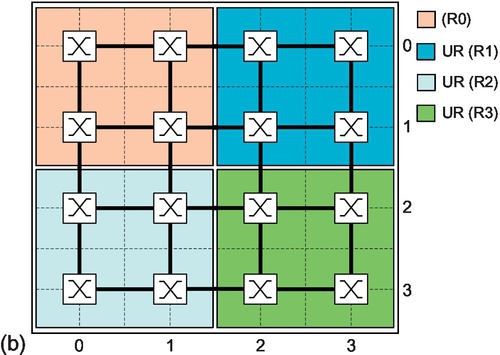
Here, we extend the analysis to the CMesh topology [2, 33]. As a case study, we use radix-4 CMeshes [2, 33]; four cores are concentrated around one router, with two cores in each dimension, as shown in Figure 5.18a. Here, Core0, Core1, Core4, and Core5 are concentrated on router (0,0). Each core has its own injection/ejection channels to the router. Based on a CMesh latency model, the network channel has a two-cycle delay, while the injection/ejection channel has a one-cycle delay [33]. The router pipeline is the same as discussed in Section 5.4.1.2. As shown in Figure 5.18, we evaluate 16-core and 64-core platforms. For the 64-core platform, both single-region and multiple-region experiments are conducted. For the multiple-region configuration (Figure 5.18b), regions R1, R2, and R3 run uniform random traffic with an injection rate of 4% and we vary the pattern in region R0.
5.5.4.2 Performance
Figure 5.19 shows the results. In the 2 × 2 CMesh, LOCAL, DBSS, and RCA have the same performance as there are only two routers along each dimension; these selection strategies utilize the same congestion information. For example, in Figure 5.18a, when a packet is routed from router (0,1) to (1,0), LOCAL, DBSS, and RCA all make selections by comparing the congestion status of the east input port of (0,0) and the north input port of (1,1). NoP performs differently; it compares the status of the north and south input ports of (1,0). This difference results in poorer performance for NoP (Figure 5.19a and b), since it ignores the status of the nearest nodes. DOR has the lowest performance for transpose-1 traffic (Figure 5.19a). With bit reverse traffic in a 4 × 4 mesh, DOR's performance is about one third of the performance of the best adaptive algorithm (Figure 5.14a). But in a 2 × 2 CMesh with bit reverse traffic, the performance difference between DOR and adaptive routing declines (Figure 5.19b). Concentration reduces the AHP; adaptive routing has less opportunity to balance network load.


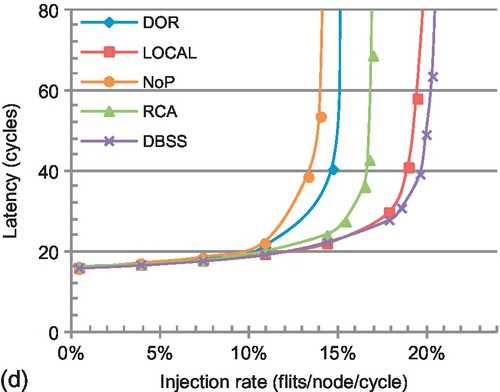
In the multiple-region scenario of a 4 × 4 CMesh, RCA's performance drops owing to the inter-region interference. There is a 26.2% performance decline with transpose-1 traffic (RCA-uni_region vs. RCA-multi_region in Figure 5.19a). In a 4 × 4 mesh region with bit reverse traffic, the inter-region interference only slightly affects RCA since the intraregion interference already strongly deteriorates its performance (Figure 5.14b). However, here with bit reverse traffic, the inter-region interference brings a 9.8% performance drop as there is no intraregion interference in a 2 × 2 CMesh (Figure 5.19b).
With one region configured in a 4 × 4 CMesh, the performance trend (Figure 5.19c and d) is generally similar to that of a 4 × 4 mesh (Figure 5.14a and b); DBSS and LOCAL show the highest performance, while RCA suffers from intraregion interference. RCA's performance is 29.4% lower than that of DBSS in a 4 × 4 CMesh (Figure 5.19c), while the performance gap is only 7.4% in a 4 × 4 mesh (Figure 5.14a). The effect of intraregion interference increases owing to the change of the latency ratio between the network and injection/ejection channel, resulting in judicious selection becoming more important in a 4 × 4 CMesh. These results indicate that considering the appropriate congestion information is also important in CMeshes; DBSS still offers high performance.
5.5.5 Hardware overhead
5.5.5.1 Wiring overhead
Adaptive routers require some wiring overhead to transmit congestion information. Assuming an 8 × 8 mesh with eight VCs per port, DBSS introduces eight additional wires for each dimension. RCA uses eight wires in each direction for a total of 16 per dimension. NoP requires 4 × log(numVCs) = 12 wires per direction; there are 24 wires for one dimension. LOCAL requires log(numVCs) = 3 wires in each direction for a total of 6 wires per dimension. Given a state-of-the-art NoC [23] with 128-bit flit channels, the overhead of DBSS is just 3.125% versus 6.25%, 9.375%, and2.34% for RCA, NoP, and LOCAL respectively. DBSS has a modest overhead; abundant wiring on chip is able to accommodate these wires.
5.5.5.2 Router overhead
DBSS adds the SMC, DP, and three registers to the canonical router. In an 8 × 8 mesh network, SMC utilizes two 7-bit shifters to select and align the congestion information of the two dimensions. The 64-to-1 multiplexer of DP can be implemented in tree format. Congestion_X and congestion_Y are 9 bits wide, while out_dim is 64 bits wide. Considering the wide (128-bit) datapath of our mesh network (five ports, eight VCs per ports, and five slots per VC), the overhead of these registers is only 0.3% compared with the existing buffers.
5.5.5.3 Power consumption
We leverage an existing NoC power model [43], which divides the total power consumption into three main components: channels, input buffers, and router control logics. We also model the power consumption of the congestion propagation network. The activity of these components is obtained from BookSim. We use a 32 nm technology process with a clock frequency of 1 GHz.
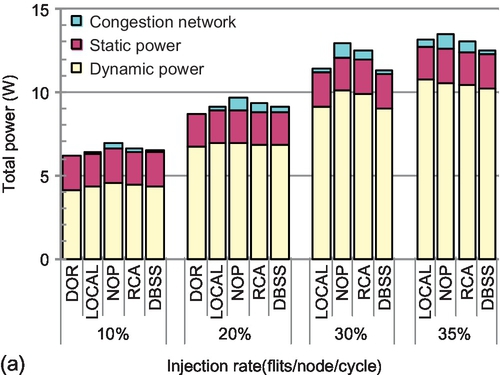
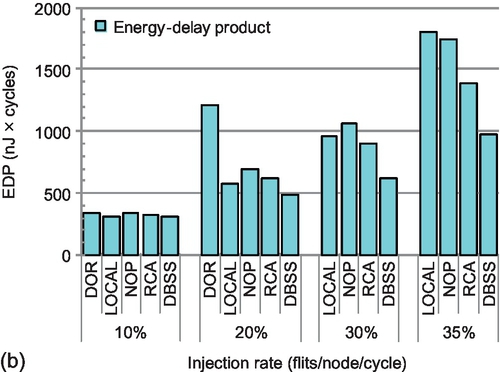
Figure 5.20a shows the average power for transpose-1 traffic in an 8 × 8 mesh. Since DOR cannot support injection rates higher than 20%, there are no results for injection rates of 30% and 35%. The increased hardware complexity, especially the congestion propagation network of adaptive routing, results in a higher average power than the simple DOR. Among these adaptive routers, LOCAL and DBSS have the lowest power consumption owing to their wiring overhead being the lowest. NoP has the highest power consumption. LOCAL needs fewer additional wires than DBSS, but these wires have a higher activity factor. For an injection rate of 20%, the activity of DBSS's congestion propagation network is 15.8% versus 17.5% for LOCAL. This smaller activity factor mitigates the increased power consumption of DBSS's congestion propagation network. For an injection rate of 35%, LOCAL consumes more power than DBSS. The adaptive routing accelerates packet transmission, showing a significant energy-delay product (EDP) advantage. As shown in Figure 5.20b, DBSS provides the smallest EDP for medium (20%) and high (30% and 35%) injection rates.
5.6 Analysis and discussion
5.6.1 In-depth analysis of interference
Here, we delve into the cause of interference. We find that it is strongly related to the detailed implementation of the congestion metric. There are many metrics, such as free VCs, free buffers, and crossbar demands [22]. We use free buffers as an example.
There are two implementation choices. One is to choose the output port with the maximal free buffers, and the other is to use minimal occupied buffers. These two choices appear equivalent at first glance. Indeed, for LOCAL, they are the same. This is not the case for RCA owing to the interference. To clarify this point, consider the packet routing example shown in Figure 5.2c. The following equation shows the calculation of the congestion metrics:

In Equation (5.1), Mw and Ms are the congestion metrics for the west and south output ports. E(i, j) and N(i, j) are the free buffer counts (or the occupied buffer counts according to the implementation choice) in the east and north input ports of router (i, j). The coefficients, such as 0.5 and 0.25, are due to the weighting mechanism used by RCA.
Since fully adaptive routing uses the conservative VC reallocation scheme, and the packet length in NoCs is generally short, most of the buffer slots are unoccupied. Let us consider that an example range of occupied buffers occupiedrange for each input port is 0 ≤ occupiedrange ≤ 6. Then the range of free buffers freerange for each input port is 34 ≤ freerange ≤ 40 in our experimental configuration. If we implement minimal occupied buffers as the congestion metric, then the range of Mw in Equation (5.1) is 0 ≤ Mw ≤ 9. Similarly, the range of Ms in Equation (5.1) is 0 ≤ Ms ≤ 10.5. The ranges of Mw and Ms are nearly the same.
However, if we use maximal free buffers as the congestion metric, then the range of Mw in Equation (5.1) is 51 ≤ Mw ≤ 60. Similarly, the range of Ms is 59.5 ≤ Ms ≤ 70. Unlike the situation with the minimal occupied buffers, the ranges of Mw and Ms have almost no overlap with the maximal free buffers implementation choice. For almost all situations, Ms is larger than Mw; this packet loses significant adaptivity as RCA will always choose the south port as the optimal one.
This example shows that the interference is strongly related to the detailed implementation choices of the same congestion metric. We find that if the output port with the maximal free buffers is chosen as the optimal one in RCA, its saturation throughput is about half that of LOCAL for most synthetic traffic patterns. But if the output port with the minimal occupied buffers is chosen as the optimal one, RCA's performance is almost the same as LOCAL's performance.
Even with aggressive VC reallocation in partially adaptive routing, maximal free buffers and minimal occupied buffers show similar properties as well. The reason is that the network saturates when some resources are saturated [12]. In particular, these central buffers, VCs, and links may easily be saturated, while other resources may have low utilization [45]. Kim et al. [30] observed that even with one VC per physical channel, the average buffer utilization is below 40% at saturation; more resources are in a free status than in an occupied status. For this reason, other metrics, such as “free VCs,” have similar properties; the “maximum free VCs” implementation used in previous evaluations has inferior performance compared with the “minimal occupied VCs” metric. Although RCA achieves good performance by carefully implementing the congestion metric, its instability with different implementation choices easily leads to an inferior design. However, DBSS shows stable performance with either maximal free buffers (VCs) or minimal occupied buffers (VCs) since it eliminates the interference.
5.6.2 Design space exploration
5.6.2.1 Number of propagation wires
We evaluate the saturation throughput of DBSS with 1-, 2-, and 3-bit-wide propagation networks. The detailed results are given in Ma et al. [37]. The increase in wiring yields only minor performance improvements, and these performance gains decrease as the network scales. Making a fine distinction about the available VCs has little practical impact as the selection strategy is interested only in the relative difference between two routing candidates. To demonstrate this point, we simultaneously keep the 1-, 2-, and 3-bit status information and record the fraction of times the selection strategy using 1 bit or 2 bits makes a different selection than the 3-bit status in a 4 × 4 mesh. At very low network load (2% injection rate) with uniform random traffic, the 1-bit status and the 2-bit status make a different selection 8.8% and 7.6% of the time. This difference mainly comes from the randomization when facing two equal output port statuses. These fractions decrease with higher network loads. The fractions are 1.8% and 1.1% respectively at saturation. This minor difference verifies that making a fine distinction is not necessary.
5.6.2.2 DBSS scalability
The cost of scaling DBSS to a larger network increases linearly as N 1-bit congestion propagation wires are needed for each row (column) in an N × N network. For a 16 × 16 mesh, this represents a 6.25% overhead with 128-bit flit channels. The size of the added registers in Figure 8.10 increases linearly. The latency of the DP module increases logarithmically with network radix; however, this delay is not on the critical path so it will not increase the cycle time. DBSS is a cost-effective solution for many-core networks.
5.6.2.3 Congestion propagation delay
In addition to eliminating interference, our novel congestion network operates with only a one cycle per hop delay compared with two cycles per hop in RCA. To isolate this effect from interference effects, we compare DBSS with a one cycle per hop and a two cycles per hop congestion propagation network. The timeliness of the one cycle per hop network improves saturation throughput by up to 5% over the two-cycle design (for shuffle traffic).
5.7 Chapter summary
The shortsightedness of locally adaptive routing limits the performance for large networks, while globally adaptive routing suffers from interference for multiple regions. Interference (or false dependency) comes from utilizing network status across region boundaries. By leveraging a novel congestion propagation network, DBSS provides both high adaptivity for congestion avoidance and dynamic isolation to eliminate interference. Although DBSS does not provide strict isolation, it is a powerful technique that can dynamically adapt to changing region configurations as threads are migrated or rescheduled. Experimental results show that DBSS offers high performance in all network configurations evaluated. The wiring overhead of DBSS is small. We have provided additional insights into the design of routing functions.