
Network-on-chip customizations for message passing interface primitives†
Abstract
Current networks-on-chip (NoCs) are always designed without the consideration of programming models, bringing about a great challenge for exploiting parallelism. In this chapter, we present an NoC design that takes into account a well-known parallel programming model, message passing interface (MPI), to boost applications by exploiting all hardware features available in NoC-based multicore architectures. Conventional MPI functions are normally implemented in software owing to their enormity and complexity, resulting in large communication latencies. We propose a new hardware implementation of basic MPI primitives. The premise is that all other MPI functions can be efficiently built upon these three MPI primitives. Our design includes two important hardware features: the customized NoC design incorporating virtual buses into NoCs and the optimized MPI unit efficiently executing MPI-related transactions. Extensive experimental results have demonstrated that the proposed designs effectively boost the performance of MPI primitives.
9.1 Introduction
To enable continuous exponential performance scaling for parallel applications, multicore designs have become the dominant organization forms for future high-performance microprocessors. The availability of massive on-chip transistors to hardware architects gives rise to the expectation that the exponential growth in the number of cores on a single processor will soon facilitate the integration of hundreds of cores into mainstream computers [3].
Traditional shared bus interconnects are incapable of sustaining the multicore architecture with the appropriate degree of scalability and required bandwidth to facilitate communication among a large number of cores. Moreover, full crossbars become impractical with the growing number of cores. Networks-on-chip (NoCs) are becoming the most viable solution to mitigate this problem. The NoCs are conceived to be more cost-effective than the bus in terms of traffic scalability, area, and power in large-scale systems. Such networks are ideal for component reuse, design modularity, plug-and-play, and scalability while avoiding issues with global wire delays. Recent proposals, such as the 64-core TILE64 processor from Tilera [51], Intel's 80-core Teraflops chip [22], Arteris's NoC interconnect IPs [2], and NXP-Philips' AEtheral NoC [18], have successfully demonstrated the potential effectiveness of NoC designs.
However, most existing general-purpose NoC designs do not support the high-level programming model well. This condition compromises performance and efficiency when programs are mapped onto NoC-based hardware architectures. That is, most current programming model optimizations aiming to address these problems maintain a firm abstraction of the interconnection network fabric as a communication medium: protocol optimizations comprise end-to-end messages between requestor and answer nodes, whereas network optimizations separately aim at reducing the communication latency and improving the throughput for data messages. Reducing or even eliminating the gap between the multicore programming models with the underlying NoC-based hardware is a demanding task. Thus, a key challenge in multicore research is the provision of efficient support for parallel programming models to boost applications by exploiting all hardware features available in NoC-based multicore architectures.
A large body of research has recently focused on integrating the message passing interface (MPI) standard into multicore architectures. The MPI is a standard, public-domain, platform-independent communications library for message-passing programming. Numerous applications have now been ported to or developed for the MPI model. The performance optimization of such models is a necessity for multicore architectures. These research efforts include the systems-on chip (SoC) MPI library implemented on a Xilinx Virtex field-programmable gate array (FPGA) [30], the rMPI targeting embedded systems using MIT's Raw processor [39], the TMD-MPI (a lightweight subset implementation of the MPI standard) focusing on the parallel programming of multicore multi-FPGA systems [42], the MPI communication layer for reconfigurable cluster-on-chip architecture [52], and the lightweight MPI (LMPI) for embedded heterogeneous systems [1]. These studies have successfully demonstrated the effectiveness of adapting MPI into NoC-based multicore processors. However, given the enormity and complexity of MPI, the aforementioned solutions are implemented in software and do not consider the refinement of NoC designs, thus resulting in large communication latencies.
The software overhead has been found to contribute a large percentage of message latency, particularly for small messages and collective communication messages. The software overhead problem will worsen when high-speed parallel communication channels are used to transmit messages. To accelerate the software processing time, the hardware support features of NoC designs require further exploration. The subsequent work on the TMD-MPI approach has considered the NoC designs (TMD-MPE, message passing engine) for low-overhead transmission [38, 44]. However, TMD-MPE is implemented on an FPGA network, which is designed without consideration of the underlying network infrastructure; this has performance drawbacks especially for small and collective messages. Thus, the network infrastructure and hardware design could be further optimized for small or collective messages in NoC-based multicore processors.
In this chapter, we present the hardware acceleration architecture for implementing basic MPI functions in NoC-based multicore processors. To minimize the processing delay overhead of MPI functions, we optimize the communication architecture in two aspects: the underlying NoC design and the optimized MPI unit (MU). First, the current multihop feature and inefficient multicast (one-to-many) or broadcast (one-to-all) support have degraded the performance of MPI communications. We thus designed a specialized NoC to decrease this transmission delay. This special NoC incorporates a virtual bus (VB) into NoCs, where the conventional NoC point-to-point links can be dynamically used as bus transaction links for VB requests to achieve low latency while sustaining high throughput for both unicast (one-to-one) and multicast (one-to-many) communications at low cost. Second, an MPI processing unit (MPU) is introduced for the direct execution of MPI functions. Transferring the MPI functionality into a hardware block (the MU) aims at improving the overall performance of the communication system by reducing the latency, increasing the message throughput, and relieving the processor from handling the message passing protocol. We implement a basic subset of MPI functions that could improve the performance of both point-to-point and collective communications. To show the effectiveness of the proposed design, we performed the evaluation by integrating our work into the conventional communication architecture.
9.2 Background
There are a large number of research works on the software optimization and hardware support for improving the performance of MPI applications. For multiprocessor systems, the MPI optimization is an extensively investigated domain [11, 21]. Faraj and Yuan [9] presented a method for automatically optimizing the MPI collective subroutines. Liu et al. [28] used the hardware multicast in native InfiniBand to improve the performance of MPI broadcast operation. Systems such as STAR-MPI (Self-Tuned Adaptive Routines for MPI collective operations) [10] and HP-MPI [47] have shown that the profile data can be used for optimizing MPI performance at link time or launch. However, given that the power, area, and latency constraints for off-chip versus on-chip communication architectures differ substantially, prior off-chip communication architectures are not directly suitable for on-chip usage.
A large number of recent studies have provided the message-passing software and hardware on the top of NoC-based multicore processor designs. A natural method of providing MPI functionality on multicore processors is to port the conventional MPI implementation, such as MPICH [33]. However, this approach is unsuitable for on-chip systems that have limited resources. A number of implementations have been ported for high-end embedded systems with large memories, such as MPI/Pro [41]. However, such implementations are also unsuitable for NoC systems because the required hardware and software overhead is still large. The code size for these conventional MPI implementations is over 40 MB for all layers [12].
In Ref. [13], a nonstandard message passing support is proposed for distributed shared memory architecture. In Ref. [36], an MPI-like microtask communication is applied to the Cell Broadband Engine processor. But a cell processor has a maximum of eight processing elements (PEs), which leads to architectural scalability problems. In Ref. [30], an SoC-MPI library is implemented on a Xilinx Virtex FPGA to explore different mappings upon several generic topologies. For the NoC-based multiprocessor SoC platform, the multiprocessor MPI [14] has been introduced, which can provide a flexible and efficient multiprocessor MPI. In Ref. [39], a custom MPI called rMPI that targeted embedded systems using MIT's Raw processor and an on-chip network was reported. A lightweight MPI for embedded heterogeneous systems was reported in Ref. [1]. The STORM system [7] implements a small set of MPI routines for essential point-to-point and collective communication in order to provide more programmability and portability for the applications of the platform.
Another interesting work similar to ours, presented in Ref. [42], focuses on the parallel programming of multicore multi-FPGA systems based on message passing. This work presents TMD-MPI as a subset of MPI, the definition and extension of the packet format to communication systems in different FPGAs, as well as the intra-FPGA using a simple NoC architecture. Unlike TMD-MPI, we develop a hardware implementation of several MPI functions targeting NoC-based multicore processor systems and provide a detailed NoC router and associated MU to support efficient message passing. In Ref. [43], the concept of embedding partial reconfiguration into the MPI programming model is introduced, which allows hardware designers to create reusable template bitstreams for multiple applications. A hardware implementation of the MPI-2 RMA communication library primitive in the FPGA platform is described in Ref. [16]. Peng [38] considered the NoC designs for low overhead broadcast and reduced transmission but did not consider the communication protocol.
Intel has recently released an experimental processor, called the Single-chip Cloud Computer (SCC) [49]. The 48-core SCC explores the message passing model, which provides an on-chip low-latency memory buffer called the message passing buffer; the message passing buffer is physically distributed across the tiles. Such designs can eliminate the “coherency wall” between cores existing in conventional shared memory architectures. In Ref. [6], a hybrid approach that combines shared memory and message passing in a single general-purpose chip multiprocessor architecture is proposed, and allows efficient executions of applications developed with both parallel programming approaches.
There are also several research works to improve the performance metrics of underlying packet-switched NoCs by integrating a second switching mechanism. The reconfigurable NoC proposed in Ref. [48] reduces the hop count by physical bypass paths. Though the virtual bus on-chip network (VBON) also has some similarities with this reconfigurable NoC, we reduce the hop count by virtually bypassing the intermediate routers and further consider the multicast problem. In Ref. [24], asynchronous bypass channels are proposed at intermediate nodes, thus avoiding the synchronization delay. A new class of network topologies and associated routing algorithms is also proposed to complement the router design in this work. Another approach is the express topology which employs long links between nonlocal routers to reduce the effective network diameter [20, 27]. Though the express topology can reduce the unicast latency of NoC communication, it does not consider the multicast or broadcast communication pattern, which is the main focus of collective MPI hardware implementations.
The support for multicast communications in NoCs may be implemented in software or hardware. The software-based approaches [5] rely on unicast-based message passing mechanisms to provide multicast communication. Implementing the required functionality partially or fully in hardware has been found to improve the performance of the multicast operations such as the connection-oriented multicast scheme in wormhole-switched NoCs [29], XHiNoC multicast router [45], and virtual circuit tree multicasting [8]. In this chapter, we propose the use of a VB as an attractive network for support-efficient MPI hardware implementation. The proposed VBON design with specialized MUs is discussed in detail to improve performance of MPI communications.
9.3 Motivation
9.3.1 MPI adaption in NoC designs
The challenge of effectively connecting and programming numerous cores for an NoC-based system has received significant attention from both academia and industry. A natural choice is a cache-coherent shared memory design based on previous symmetric multiprocessor architectures. These multicore processors likely have small private first-level (L1) or second-level (L2) caches but share a large last-level cache that is kept coherent with all L1 caches. However, as the number of cores increases, the protocol overhead would rapidly grow, leading to a “coherency wall” beyond which the overhead exceeds the value of adding cores [26]. To resolve this problem, message passing multicore architectures are introduced to eliminate cache coherence between cores.
The MPI has been proven to be a successful message passing framework for large-scale parallel computer systems [19]. It is known to be portable and extensible. It has numerous tools and parallel legacy codes to facilitate its use. The current MPI standard is large, containing over 200 function calls. However, several functions are essential to code a parallel application, with others facilitating its programming. The special capabilities of the MPI such as its standard interface, language-independent interface, and large user-base make it a potential and suitable solution for implementation in NoC systems. Previous studies [14, 39, 49] have successfully demonstrated the effectiveness of adapting the MPI into NoC-based multicore processors. This chapter is also based on the assumption that the MPI is a potential programming model candidate for future multicore processors.
9.3.2 Optimizations of MPI functions
MPI communication functions can be classified as either point-to-point or collective functions. Point-to-point communication involves only two nodes: the sender and the receiver. Collective communication involves all the nodes in the application; typically, a root node coordinates the communication, whereas the remaining nodes merely participate in the collective operation. MPI communications can also be classified as synchronous or buffered functions. In synchronous communication, the sender and the receiver block the execution of the program until the information transfer is complete. Buffered communication enables the overlap of communication and computation but places the responsibility of avoiding data corruption in the memory on the programmer because data transmission occurs in the background, such that the transmission buffer can be overwritten by further computation. These types of MPI functions would be our target baseline communication operations.
The problem of current MPI implementations is that they are realized in software and do not consider the refinement of NoC designs for both point-to-point and collective functions, thus resulting in large communication latencies. In this work, we aim to accelerate the processing performance of MPI primitives in future massive multicore architectures through underlying hardware support. These multicore architectures usually present a mesh-type interconnect fabric. A number of factors have to be considered when improving the performance of MPI functions through hardware support, especially for collective functions. Our design includes two main hardware techniques for accelerating MPI primitives: the specialized NoC design and the optimized MU.
9.4 Communication customization architectures
9.4.1 Architecture overview
Figure 9.1 shows a block diagram of the proposed implementation architecture with a baseline 8 × 8 mesh topology. We consider a multicore processor chip where each core has a private L1 cache and logically shares a large L2 cache. The L2 cache may be physically distributed on the chip, with one slice associated with each core (essentially forming a tiled chip). As shown in Figure 9.1, the underlying NoC design is the actual medium used to transfer messages, which can be designed with consideration for specialized features of MPI communications. Each node also has an MU between the core and the network interface (NI), which is used to execute corresponding instructions for MPI primitives.
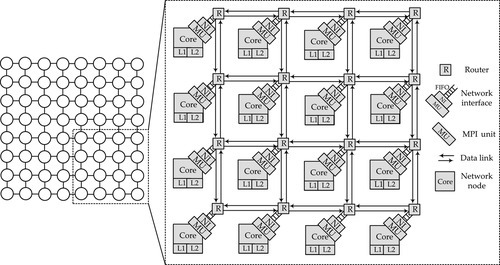
The latency and bandwidth of the NoC are important factors that affect the efficiency of computations with numerous intercore dependencies. To support the MPI efficiently, good service for control messages must be provided. Control messages may be used to signal network barriers and changes in network configuration, as well as the onset or termination of computation. The process requires minimal bandwidth, but needs very low latency for broadcast (one-to-all or all-to-all) communication. However, the multihop feature and inefficient multicast (one-to-many) or broadcast (one-to-all) support in conventional NoCs have degraded the performance of such kinds of communications. To facilitate the efficient transmission of data and control messages, a customized network is needed. In the proposed design, a hierarchical on-chip network, called VBON, is introduced.
By directly executing the MPI primitives and interrupting service routines, the MU reduces the context switching overhead in the cores and accelerates software processing. The MU also performs the message buffer management as well as the fast buffer copying for the cores. The MU transfers messages to and from dynamically allocated message buffers in the memory to avoid buffer copying between system and user buffers. This process eliminates the need for the sending process to wait for the message buffer to be released by the communication channel. The MU also reserves a set of buffers for incoming messages. With use of the above methods, the long message transmission protocol can be simplified to reduce transmission latency. In the following subsections, we will introduce the architecture of the proposed NoC and MU.
9.4.2 The customized NoC design: VBON
The VBON is introduced as a simple and efficient NoC design offering low latency for short unicast communication and broadcast communication services in MPI programs. The key idea behind the VBON is to provide a VB in the network. Such VBs can be used to bypass intermediate routers by skipping the router pipelines or transmitting to multiple destinations in a broadcast manner. Unlike a set of proposals that employ physical links to construct local buses [32, 34, 40], the bus mentioned here is a specialized packet routing in the VBON. Its transaction link is constructed dynamically for communication requests from the existing point-to-point links of conventional NoC designs. The detailed structure of the VBON design can be found in Chapter 4.
9.4.3 The MPI primitive implementation: MU
The MPI supports both the point-to-point and collective communication functions. Given the popularity of send-and-receive-based message-passing systems, MPI_Send and MPI_Receive are implemented for point-to-point communication functions. All other MPI communication functions can be realized by these two primitives. However, the collective communication based on these two primitives would be inefficient because the NoC, rather than an underlying transparent communication layer, should be involved in the transactions of collective communication to improve the performance. Furthermore, collective communications are always the performance bottlenecks for data-parallel applications [31]. In this chapter, we support three collective operations—MPI_Bcast, MPI_Barrier, and MPI_Reduce—which represent three kinds of communication patterns. An efficient implementation of these collective primitives is crucial for the performance improvement. MPI_Bcast is a commonly used collective function in parallel applications. In this process, the root broadcasts its data to all processes. Almost all collective communications would incorporate the broadcast communication. MPI_Barrier blocks the calling process until all the other processes have also called it. MPI_Barrier can return to any process only after all the processes have entered the call. MPI_Reduce operations collect data from all the processes using an associative operator, such as addition, maximum value, or even user-defined data operator. The final results are placed in the root. The following section specifies the detailed design of the proposed MU for the implementation of these MPI operations.
9.4.3.1 The architecture of the MU
The MU architecture is shown in Figure 9.2. The MU provides hardware support to address the communication protocol used in the MPI implementation. The primary functionality of the MU is to serve as a middle layer between the processor core and the interface of the NoC. The MU will receive the message and send requests from the PE core and will handle various messages from other processor cores. Two sources trigger the MU: the local processor core and the NI. The local processor core may request the MU to perform the MPI primitive functions, and then the associated communication data are transferred through this interface. Another source is the NI, which may request the MU to receive messages from the on-chip network and then perform corresponding operations for handling the received messages.

The MU consists of three key components: the preprocessing unit (PPU), parameter registers (PRs), and the MPU. The PPU is used to translate the instructions from the processor core into control signals and to generate the message passing parameters for data transfer that are temporarily stored in the PRs. Another important task of the PPU is to exchange data with the CPU cache to read or write the communication data. The PRs include several registers in theMU. Table 9.1 describes these registers. When MPI functions are performed, the MU first receives the message parameters from the PE core and then updates these registers.
Table 9.1
Parameter Registers in the MU
| Register | Bit Width | Description |
| OPCODE | 8 | Operation code |
| PID | 32 | Rank ID of local processor core |
| RID | 32 | Rank ID of remote processor core |
| TAG | 32 | Message tag |
| COM | 64 | Message communicator |
| MODE | 8 | Communication mode |
| ADDR | 32 | Memory address of network data |
| DATA | 128 | Communication data from register |
| MSGLEN | 32 | Message length |
Similarly to conventional MPI implementations [33], we use four parameters to identify a message: the source/destination rank, the message tag, and the communicator. The rank of a process is a unique number that identifies this particular process in a parallel application. The tag is an integer number that identifies a message. The meaning of a tag is entirely user definable. The rank of a process and the message tags are scoped to a communicator, which is a communication context that enables the MPI to communicate with a group of processes selectively within a particular context. As listed in Table 9.1, the OPCODE register specifies the operations for message communications; the PID, RID, TAG, and COM registers represent the four parameters for identifying the message; the MSGSIZE register indicates the length of the message.
The MPU is the key component of the MU that performs the actual operations for MPI primitive functions. Table 9.2 lists the set of primitive functions implemented by the MU with their MPI equivalent primitives in the middle column. Any other communication-related MPI functions can be implemented using these hardware-supported primitives. Such primitives are classified into two categories. The first category includes the first five MU operations that are related to communication functionalities. The second category includes the last five MU operations that are related to the MU context handling.
Table 9.2
Hardware-Implemented Primitive Functions
| MU Operation | Primitives | Description |
| Send(srcaddr eg, len, dpid, tag) | MPI_Send | Send a len size message with tag to target processor node dpid, where data is read from memory address srcaddr or register reg |
| Receive(recaddr eg, len, spid, tag) | MPI_Receive | Receive a len size message with tag from processor node spid, where data is stored into memory address recaddr or register reg |
| Broadcast(srcaddr eg, len, tag) | MPI_Bcast | Broadcast a len size message with tag to a group of cores in the communicator, where data is read from memory address srcaddr or register reg |
| Barrier() | MPI_Barrier | Synchronize all processor nodes, each calling it will be blocked until all the nodes have called it |
| Reduce(srcaddrsrcreg, dstaddrdstreg, len, tag, op, rpid) | MPI_Reduce | Collect data from all the processor nodes, each sends a len size message with tag from memory address srcaddr or register srcreg to the root node rpid with memory address dstaddr or register dstreg for the reduce operation op, which is specified in Table 9.3 |
| Init(com, spid, size) | MPI_Initial | Initialize the MU context including communicator com, Rank ID, spid, number of group cores size, and default hybrid communication mode |
| End() | MPI_Finalize | Clear the MU context |
| SetMode(mode) | – | Set the communication mode for MU operations with three types of mode supported synchronous, buffered, and hybrid (default mode) |
| ContextSave(caddr) | – | Save the register and buffer data into memory addressed by caddr |
| ContextRestore(caddr) | – | Restore the register and buffer data from memory addressed by caddr |
The Send and Receive operations both have four parameters, where data can be specified by either the memory address srcaddr or the register value reg. When the data are small and can be represented in a register, only their value is directly sent to the MU because such data are usually generated by a processor core and reside in the register. In this case, the direct move operation can reduce the latency. When the data are large, only the starting memory address of the data is sent to the MU, and then the MU will request the cache controller to load the data to create the network message. The collective operations have similar considerations for fetching data. The Broadcast operation sends the data block to all other processor nodes, so the destination nodes do not need to be specified. The Barrier operation is used to synchronize all the processor nodes, which do not have any parameter. The Reduce operation combines the elements of the data block of each processor node using a specified operation and then returns the results to the root processor node. This operation has six parameters: specifying the source data, destination data, data length, tag, reduce operation, and root node. To accelerate the reduce operation in each node, the MPU also implements a reduction function unit (RFU) to perform the reduce operations. Table 9.3 lists the reduction operations supported by the RFU. The operation data types can be integer numbers, floating-point numbers, or both according to different application scenarios. For the experiments in this chapter, both integer and floating-point numbers are supported. To reduce the hardware cost of the RFU, we do not implement area-consuming reduce operations, such as the product, specified in the MPI. The RFU is realized on the basis of an adder.
Table 9.3
The Reduction Operations Supported by the RFU
| Operations | Operation Code | Description |
| MAX | 0000 | Maximum operation |
| MIN | 0001 | Minimum operation |
| SUM | 0010 | Sum |
| LAND | 0011 | Logical and |
| BAND | 0100 | Bit-wise and |
| LOR | 0101 | Logical or |
| BOR | 0110 | Bit-wise or operation |
| LXOR | 0111 | Logical exclusive or operation |
| BXOR | 1001 | Bit-wise exclusive or operation |
| USER | 1000 | User-defined operation |
The execution of these functions is performed in two separate pipelines: the send and receive pipelines. The send pipeline is used for active operations such as Send and Broadcast. The receive pipeline is used for passive operations such as Receive.
9.4.3.2 MPI processing unit
Figure 9.3 shows a simplified block diagram of the MPU. The MPU is capable of handling unexpected messages and dividing large messages into smaller packets. The MPU comprises six main components organized in two separate pipelines: the message packetizing and building units for the send pipeline; the packet reception, expectation, and response units for the receive pipeline; the collective logic unit for handling three collective operations. Moreover, it also has an internal buffer to store unexpected messages. Thus, sending and receiving packets can occur simultaneously. We will discuss these components through the sending and receiving procedures.
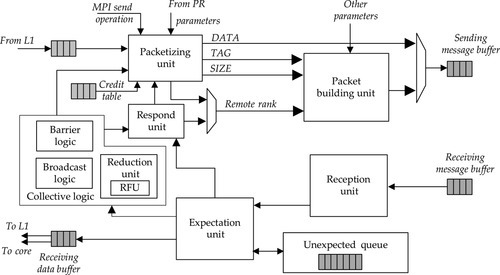
When the local processor core issues the sending operation, the message parameters related to the MPI communication are initially sent to the PR. The local processor core sends the data to the MPU through the cache controller. For the collective packet sending, the collective logic unit is also involved to generate the corresponding parameters. These parameters, as well as the data, are first sent to the packetizing unit to determine whether a message is larger than the maximum packet size. If such is the case, the packet size field in the packet header is modified accordingly. The large message is divided into equal-sized packets as long as the data exist. The packetized data, along with other message information, such as the packet size, message tag, PID, and RID, are sent to the building unit to create the packet.
The receiving procedure of the MPU is described as follows. The incoming packets are first decoded by the reception unit to obtain the message information for executing the receiving operations. The information is also provided to other units in the MPU on the basis of the received values. Such information is sent into the expectation unit to determine whether a message is expected. An unexpected message is a message which has been received by the MU for which a receive operation has not been posted (i.e., the program has not called a receive function like MPI_Recv). If the message is unexpected, the message packet will be stored in the message queue. The expectation unit also determines whether packets from a previous unexpected message are in the envelope memory queue. For the packets already determined as expected, the respond unit and collective logic unit may be involved to send respond packets according to the information acquired from incoming packets.
9.4.3.3 The collective operation implementation
The collective operations are the key functionalities implemented in the MU. In this subsection, we will discuss how the MU is used to support these collective operations, including Broadcast, Barrier, and Reduce operations. Figure 9.3 contains a diagram of the collective logic, which is capable of handling packets related to collective communications. It accepts the collective operations from the PPU, and generates the control signals for the packetizing unit to form packets. Moreover, the expected receiving packet information will also be sent to the collective logic to generate the respond information.
The broadcast operation is the most basic primitive among the three operations. When the local processor core issues the Broadcast instruction, the group information is first sent to the MU. Broadcast messages can be transmitted within a group (the multicast communication pattern). Thus, target group addresses are specified by the bitstring field in the packet. The status of each bit indicates whether the visited node is a target of the multicast. The broadcast unit should check this bitstring and generate packets accordingly. For other collective operations, this bitstring is also involved to indicate the group members of the communications. The packets are then transmitted through row/column VBs. Figure 9.4a shows the design method of broadcast operations based on the VB. For a 4 × 4 mesh configuration, only the latency of a maximum of two VB transactions is needed to broadcast data to all other cores.
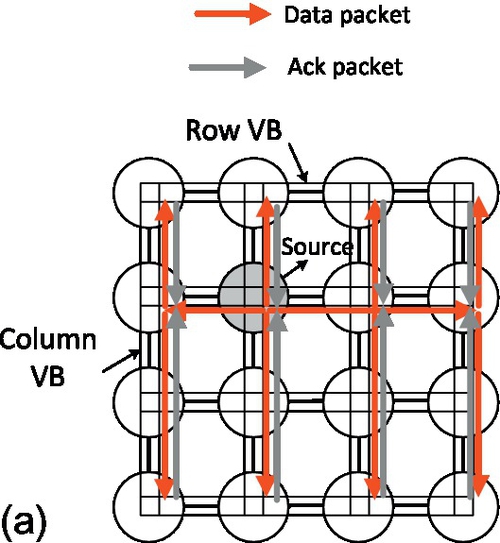


The barrier operation is used to synchronize processes among parallel applications. Given that multicore parallel applications tend to exploit fine-grained parallelism, such application can be highly sensitive to the barrier performance [46]. To support fast barrier operations, we design a VB-based synchronization barrier. The design concept of this implementation is shown in Figure 9.4b. This design uses a master-slave barrier, as shown at the top of Figure 9.4b, for a configuration with 16 cores. The design employs a centralized approach where a master core is responsible for locking and releasing slave cores. The barrier can be divided into two phases. In the first phase, each core waits for other cores to arrive at the same phase, whereas in the second phase, all cores have arrived at the barrier, and a release command is given by the master core.
To support such a barrier efficiently, we add special barrier signal lines for each VB to transmit the signals required by the synchronization process. They are wires that first connect horizontal cores, then connect the horizontal master cores to form vertical transmission. The barrier signals are transmitted through the request and acknowledge flow control. Without loss of generality, we describe the simultaneous executions by all the cores on a 16-core mesh layout, as shown at the bottom of Figure 9.4b. Each cycle of four barrier signals can be transmitted to the master. In the first arrival phase, the horizontal barrier arriving signal is transmitted through the barrier signal lines to the horizontal master. These cores then wait until the horizontal master sends a signal to resume execution. When the horizontal master receives all the barrier arriving signals along the horizontal barrier lines, it sends these signals to the master core through the vertical barrier signal line. The barrier operation only enters into the second release phase when the master core has received all the barriers from its horizontal master core. In this phase, the master core sends the release signals to its slave cores through the VB in the opposite direction. Finally, when the slave cores receive the release signals, they will resume the execution to complete the barrier operation.
The last collective operation is the reduce operation, which combines the partial results of a group of cores into a single final result. Considering that the reduce operation accounts for a significant portion of the execution time of MPI applications, the efficient implementation of the reduce operation is thus beneficial to overall performance [25]. Figure 9.4c shows a block diagram of the routing path for the reduce operation. This path is based on simple XY routing, that is, the reduce path first goes through X then through Y. Unlike the conventional centralized reduce operation, the proposed method distributes the reduce operations to all cores along the reduce path, as shown in Figure 9.4c. The reduce hardware in each core will receive the data from a neighboring core, after which it will dynamically determine the reduce data and will operate on the data locally only if all the expected data are received. After the reduce operation, the reduce hardware will send the result to the upper core for further reduction. To accelerate the reduce operation, such an operation is executed by the RFU according to the operation type and the data type, as described in Table 9.3. Performing the reduce operation can be classified into two cases. The first case is when the operation can be supported by the RFU. In such a case, all the data can be reduced normally in a distributed manner. The second case is when complex operations, such as product in the MPI, cannot be supported by the RFU. We use the centralized reduce method, where all the data are sent to the root, to perform the reduce operation.
9.4.3.4 Communication protocols
One of the key functionalities of MPI hardware implementation is to support the MPI communication modes. The MPI has two important communication modes: the synchronous mode and the buffered mode, as shown in Figure 9.5a and b respectively. The buffered mode enables the completion of the MPI send operation before the response packet is received. This process is based on the assumption that all the expected and unexpected packets can be buffered in the target MU. By contrast, the synchronous mode will send a request before sending data to the receiver. After the sender receives the ready packet, the actual data transfer will commence. Although this mode incurs a higher message overhead than the buffered mode, it demands less buffer space and ensures that the target MU can have sufficient buffer spaces to store messages.


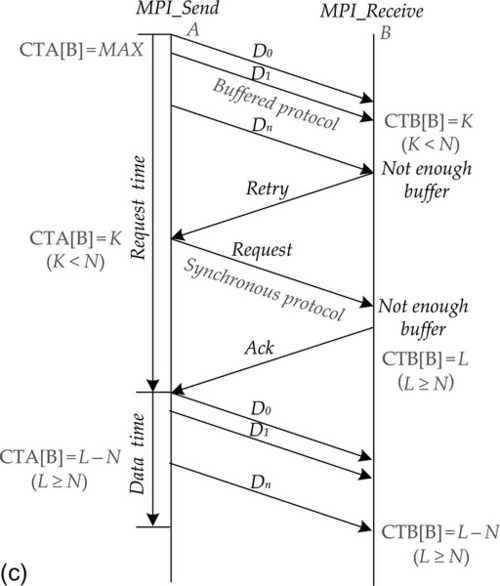
When the MPI message has already been sent out and the target processor core does not have sufficient buffers to receive this message, the retry mechanism should be triggered to maintain correctness. However, this mechanism would significantly degrade the performance. The buffered mode does not have to wait for a response message before triggering the retry mechanism. By contrast, the synchronous mode has to wait for the response message but would not activate the retry mechanism. To maximize the utilization rate of the buffered mode and minimize the number of retry operations due to overflowing the receive buffers, we propose a new optimized hardware mechanism for credit-based MPI control flow called the hybrid communication mode. The credit can be defined as the number of receive buffers available at the target processor core. The example packet format is shown in Figure 9.6.

This mechanism is described as follows. Each MPU maintains a credit table listing the credit values for all the nodes, and their initial values are set as the maximum. The processor core initially performs the send operation in the buffered mode and then decreases the credit value accordingly. If the target node has insufficient space for buffering the message, it will trigger the retry procedure and place its newest credit value in the corresponding message. The sending core will send the message in the synchronous mode if the received credit value n is less than the mode threshold p. If n equals zero, then the sending core will block the send operation until n is larger than the block threshold q. If n continues to increase to p, messages will again be sent in the buffered mode. Figure 9.5c shows an example of this mode. In sender A, the initial credit table value for receiver B (CTA[B]) is MAX, so it will trigger the buffered protocol to send the data with size N. Since the buffer count in receiver B (CTB[B] = K) is smaller than the message size, it will perform the retry operation with the credit table value (K) to notify sender A. When sender A receives this message, it will update its credit table and trigger the synchronous protocol to send the data again. So the hybrid protocol will achieve better performance than the buffered protocol in total.
9.5 Evaluation
In this section, we present a detailed evaluation of the proposed communication architecture with a baseline 2D mesh topology. We will describe the evaluation method, followed by the results using synthetic and real application traffic patterns. Thereafter, the effect of the proposed method on hardware costs is discussed.
9.5.1 Methodology
To evaluate the proposed communication design, we implemented its architecture using a SystemC-based cycle-level NoC simulator augmented with the MU. It is modified from the NIRGAM simulator [17]. The simulator models a detailed pipeline structure for the NoC router and the MU. We can change various network configurations, such as the network size, topology, buffer size, routing algorithm, and traffic pattern. Table 9.4 lists the network configurations across all experiments. For send and receive operation scenarios, once the hop count of the point-to-point message is larger than four (threshold in a 4 × 4 mesh) or eight (threshold in an 8 × 8 mesh), the message is transmitted by VBs. For collective operation scenarios, all multicast messages are transmitted through VBs.
Table 9.4
Communication Design Configurations
| Designs | Parameter | Measure |
| Basic design | Topology | 8 × 8 mesh |
| Basic routing | Dimensional ordered XY | |
| Ports | 5 | |
| VCs per port | 4 | |
| Buffers per VC | 16 | |
| Channel width/flit size | 128 bits | |
| Packet size | 8 flits | |
| Pipeline frequency | 1 GHz | |
| VBON design | VB structure | Row and column VBs |
| Hierarchy | 2×2, 4×4, 8×8 | |
| VB usage | Routing for MPI_Bcast | |
| Maximum VB length | 4 NoC hops | |
| MU design | Maximum message size | 1024 bits |
| Receiving buffer | 32 buffers | |
| Unexpected buffer | 32 buffers | |
| Credit threshold (p,q) | (4,2) entries |
We compare the characteristics of the proposed communication architecture based on the VBON scheme against the conventional NoC design. The basic router represents conventional NoC designs. The basic router originally has a four-stage router pipeline. To shorten the pipeline, the basic router uses lookahead routing [15] and the speculative method [37].
The synthetic traffic patterns used in this research are the round-trip and uniform random traffic patterns. Each simulation runs for 1 × 106 cycles. To obtain stable performance results, the initial 1 × 105 cycles are used for simulation warm-up to enable the network to reach its steady state. The following 9 × 105 cycles are then used for analysis. When destinations are chosen randomly, we repeat the simulation run five times and then determine the average of the values obtained in each run. The time for initializing the MU is not counted for the message transmission.
We also studied the proposed approach using real application communication traffic. Traces for the baseline conventional implementations were obtained on a full-system multicore simulator, M5 [4]. We collect the message passing and memory access requests from the full-system simulator, then we extract the MPI functions and network messages from them to generate the NoC application traffic. The target multicore system is modeled with the Alpha instruction set architecture, which is the stablest instruction set architecture supported in the M5 simulator. Each core is modeled with two-way 16-kB L1 ICache, two-way 32-kB DCache, and 1-MB L2 cache. For the MPI applications, the cache is configured without coherence protocols just like the Intel SCC processor [49]. We also integrate Orion [50] to estimate the NoC energy and Cacti [35] to estimate the cache energy, thus obtaining the power metric for the cache-NoC system. We use the NAS Parallel Benchmarks (NPB 2.4) suite as application traffic to evaluate the proposed design. The applications used to perform the experiments are a subset of the A class NPB, a well-known, allegedly representative set of application workloads often used to assess the performance of parallel computers. These applications include three kernels, namely conjugate gradient (CG), integer sort (IS), and discrete 3D fast Fourier transform (FT), as well as two pseudoapplications, block tridiagonal solver (BT) and scalar pentadiagonal solver (SP). For the baseline hardware implementation with only point-to-point MPI communication support, other communication types, such as the collective communication, are performed through the basic point-to-point MPI communications. For the proposed hardware implementation, other communication operations are performed through the supported point-to-point or collective communications.
9.5.2 Experimental results
9.5.2.1 The effect of point-to-point communication: Bandwidth
We first discuss the performance of point-to-point communications in the proposed design. We record the time taken for a number of round-trip message transfers. The randomly generated messages (i.e., destinations of unicast messages at each node are selected randomly) are sent to the target node by MPI_Send instructions. When the target node receives this message, this node will first perform the MPI_Receive instruction and then return the message to the source node immediately without any change through the MPI_Send instruction. This round-trip test can help determine the network bandwidth of the communication system. Such a bandwidth is considered as the average peak performance on a link channel. In the experiment, the simulation of MPI instructions, such as MPI_Send and MPI_Receive, will be triggered by benchmarks, such that the L1 cache controller will access the data and interconnect with the MU. Assuming that the maximum capacity of the L1 cache in the multicore processor is 32kB, the maximum length of the message triggered by MPI primitive instructions should be set to 16 kB (for send and receive operations).
Figure 9.7 illustrates the bandwidth results of the point-to-point communication. When the size of the message is more than 1 kB, the bandwidth of the communication system could reach more than 5GB/s. Compared with software-based MPI implementations, such as TMD-MPI [42] with 10MB/s, the bandwidth of the proposed design exhibits a qualitative leap. For the hardware implementation in Ref. [44], a bandwidth of 531.2 MB/s is obtained. The proposed approach exhibits improved performance, which adequately demonstrates the potential benefit of supporting the parallel programming model by using a special hardware mechanism.

9.5.2.2 The effect of collective communication: Broadcast operations
One of the key features of the proposed communication architecture is the effective hardware support for the MPI_Bcast primitive. In conventional MPI implementations, MPI_Bcast is typically implemented using software with a tree-based algorithm. Such implementations exploit point-to-point communication operations. Thus, the number of hops to reach leaf nodes increases with the total number of nodes (typically in a logarithmic manner); the latency of MPI_Bcast also increases. As demonstrated in Figure 9.8a, the latency of MPI_Bcast evidently increases with the number of nodes.

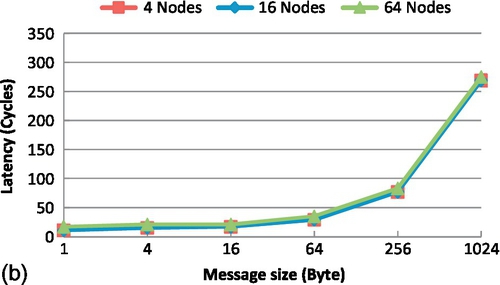
When we implement the MPI_Bcast primitive based on the VBON network, this relationship changes significantly. Figure 9.8b shows the performance results of MPI_Bcast based on the VBON with different numbers of processor cores. Figure 9.8b shows small increments in the latency of MPI_Bcast as the number of processor cores increases. This is because 4-core or 16-core systems have a latency of only two VB transactions and 64-core systems have a latency of only four VB transactions for broadcast operation. So the latency increases by two VB transactions from 16-core to 64-core systems. Since each VB transaction takes only a few cycles, the increased latency is not much. This feature is useful for achieving high performance when parallel applications involve a large number of processor cores. Furthermore, the low latency of the short-message MPI_Bcast primitive facilitates the synchronization of tasks among different processor cores.
To show the broadcast performance under increasing contending traffic, Figure 9.9 illustrates the average latency of MPI_Bcast operations for the two different MPI implementations. A fixed number of MPI_Bcast messages are generated during one period. That is, only after the transmission of all the messages is completed can the messages be generated again. Because of increased congestion, the latencies of the two implementations increase as the number of concurrent MPI_Bcast transmission messages increases. The latency increment on conventional NoCs (by about two time) is more obvious than that of the VBON (by about one time) when the number of generated messages is 1 to 32. This result shows that the support for MPI_Bcast operation in the VBON is effective for handling contending traffic.

9.5.2.3 The effect of collective communication: Barrier operations
To determine the performance impact of barrier operation, we compare our network-optimized barrier with two other hardware barrier implementations based on the VBON. The first implementation employs a centralized sense-reversal barrier, where each core increments a centralized shared counter as it reaches the barrier and spins until such a counter indicates that all cores are present. The second implementation employs a binary combination tree barrier, where several shared counters are distributed in a binary tree fashion. Thus, all cores are divided into groups assigned to each leaf (variable) of the tree. Each core increments its leaf and spins. Once the last core arrives in the group, this core continues up the tree to update the parent and so on until it reaches the root. The release phase employs a similar process but in the opposite direction (toward the leaves).
Figure 9.10 illustrates a comparison of the results of barrier performance with varying core numbers. The conventional centralized barrier has the longest operation latency since each core needs to communicate with the centralized core to complete the barrier operation, which would become the performance bottleneck. The tree barrier mitigates this situation by distributing the barrier combination in a binary tree fashion. However, this process also suffers from multihop network latency. The resulting latency reduction is approximately 23% for a 64-core configuration compared with the conventional barrier. To reduce further the latency of barrier operation, the proposed barrier uses a specialized network to transmit the barrier message. This feature reduces the latency of the tree barrier by approximately 79% for a 64-core configuration. Considering that multicore applications can be highly sensitive to barrier latency, such a reduction can result in significant performance improvement.

9.5.2.4 The effect of collective communication: Reduce operation
For the implementation of the reduce operation, we also compare the proposed method with the conventional centralized method, in which the actual reduction is performed solely by the root core. Figure 9.11a shows a comparison of results in terms of reduce operation performance with varying core count. To test the feasibility of the reduce operation, the data size of the reduce operations is set to 1. Thus, the latency results of reduce operations are related only to the number of cores and the corresponding reduction methods. The figure shows that when the number of cores is relatively small (approximately 4-16 cores), the two methods have comparable latencies since the network latency and contention introduced by the centralized method with small-scale cores do not significantly affect the reduce operation. However, as the number of cores increases, the proposed method exhibits significant performance advantage over the conventional centralized method. For a 64-core configuration, the proposed method reduces the latency by approximately 46%, which is beneficial to the overall application performance.
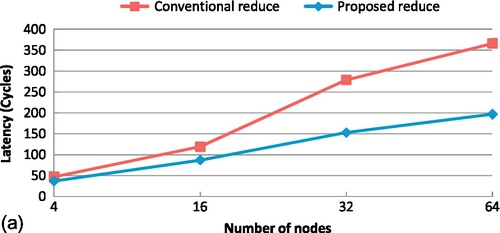
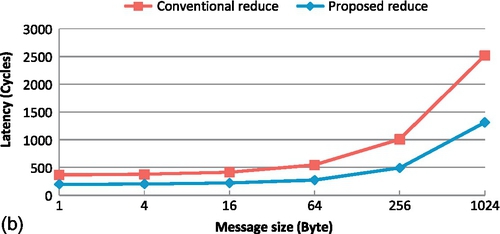
Figure 9.11b shows a comparison of the results in terms of reduce operation performance with varying message size for a 64-core configuration. This reduce operation is performed by reducing intermediate arrays in each core. The performance benefit of the proposed reduce method becomes more evident as the message size increases from 1 to 1024 bytes. This result highlights the advantage of distributing the reduce operation of data into each core. The advantage stems from two reasons. First, the proposed method does not require each core to communicate with the root, but requires it to communicate only with its neighboring cores. This process reduces not only the network traffic but also the network contention. Second, numerous data reduce operations can be performed simultaneously along the communication path. This process minimizes the reduce operations solely through the root core.
9.5.2.5 The effect of application communication: Performance
We run the application traffic to evaluate the proposed design and then use the message delay as the performance metric for various communication designs. These benchmarks were chosen for their large number of message transmissions. Figure 9.12a shows the performance comparison results for different benchmarks with a 64-core configuration. We also have two other MPI support designs. The first conventional MPI support design provides hardware support for point-to-point MPI communication (including MPI_Send and MPI_Receive) based on conventional NoC architectures, and the second VBON MPI support design is based on the proposed VBON architecture. We can see that the VBON MPI support outperforms the conventional MPI support by 8% on average. This improvement can be attributed to the fact that the VBON can reduce the latency when transferring long-latency and collective messages using the VB. When collective MPI support is added to the second design, the proposed design can achieve significant performance improvement of 48% on average. This finding further shows that the hardware support for collective communication in MPI implementation would be an effective method.

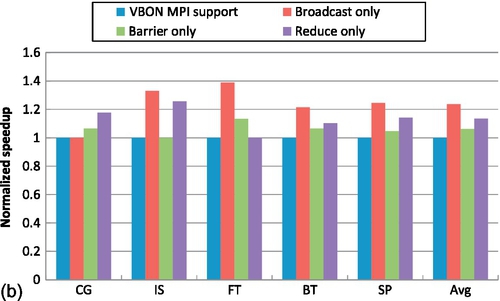
To present clearly the characteristics of collective operation support with regard to these benchmarks, Figure 9.12b shows the performance speedups for the benchmarks obtained in the baseline VBON point-to-point MPI implementation architecture with different collective communication supports. We can see that all the benchmarks except CG can benefit from the broadcast support, whose performance improvement can be up to 23% on average. The other two collective communication supports have less performance improvement, 6% and 13% respectively. This is because these two collective operations have small portions in terms of execution time. Nevertheless, the evaluation results show that the hardware support for collective communications is beneficial for accelerating MPI applications.
9.5.2.6 The effect of application communication: Power and scalability
Figure 9.13a illustrates the power consumption results of the proposed NoC-cache system. The power consumption results are obtained by executing the application traffic with a 64-core configuration. As the figure indicates, the conventional NoC design has the largest power consumption, which is used as the baseline design. The VBON point-to-point MPI support reduces the power consumption by an average of about 11%. This is mainly due to a reduction in the buffer and crossbar power consumption in bypassing routers. The proposed communication design can further reduce the power consumption, by about 3%. In summary, the proposed communication design clearly outperforms the other two NoC designs across all benchmarks not only in the performance but also in the power consumption.


To show the scalability of the proposed design, Figure 9.13b illustrates the computation results for the speedup over the conventional MPI support design with 4-core to 64-core configurations. The 4-core design is used as the baseline design, whose performance speedup is normalized to 1. That is, we compare the speedup of each configuration of the core count with the baseline MPI support design. The speedup of the 64-core configuration outperforms the speedup of 4-core and 16-core configurations for all benchmarks. For the 16-core system, about 25% more speedup can be obtained over the 4-core system; for the 64-core system, about 47% more speedup can be obtained over the 4-core system. This is because as the number of cores increases, reducing the MPI communication delay through hardware support becomes more important. The evaluation result successfully demonstrates that the proposed design has good scalability as the number of cores increases.
9.5.2.7 Implementation overheads
To determine the implementation overheads, the communication architectures, including the specially designed routers and MUs, were described in HDL and synthesized with a Taiwan Semiconductor Manufacturing Company 90 nm technology under typical operating conditions, 1.0 V and 25 °C. The area of the selected router and MU hardware was measured at their maximum supported frequencies and calculated by Synopsys Design Compiler. For comparability, the conventional NoC and VBON routers were equipped with the same buffer size in each direction. Approximately 6% area overhead for the VBON router is observed in the experiment.
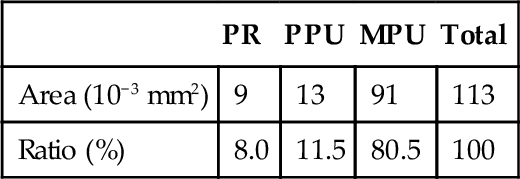
Table 9.5 shows the area overhead breakdown of the MU implementation, excluding the RFU. In this observation, the MPU occupies most of the router area, which includes various kinds of buffers and execution logic. The area of the MU is approximately 0.11mm2. This area calculation does not take the RFU into account because it may change a lot according to different functionalities. For the configuration of supporting the fixed-point and floating-point reduce operations implemented in this chapter, the area of the RFU is approximately 0.08 mm2. So the sum of the router overhead and the MU overhead is about 0.21 mm2. For the evaluated processor core with area above 10 mm2, such an area overhead is affordable since the performance improvement of real applications is large.
9.6 Chapter summary
Recent trends in NoC-based multicore architectures have considered message passing as a technology to enable efficient parallel processing for improved suitability, scalability, and performance. In this chapter, we presented a communication architecture that aims at accelerating basic MPI primitives by exploiting all hardware features of multicore processors. We first proposed the VBON, an underlying customized NoC that incorporates buses into NoCs, to achieve high performance for both point-to-point and collective data transfers. Furthermore, an optimized MU based on the VBON was designed to relieve the processor core from handling the message passing protocols as well as to reduce software processing overheads. As demonstrated in the experiment, the proposed design can significantly improve the overall performance of the communication system.