
Chapter 12: Replication and Upgrades
Replication isn't magic, though it can be pretty cool! It's even cooler when it works, and that's what this chapter is all about.
Replication requires understanding, effort, and patience. There are a significant number of points to get right. Our emphasis here is on providing simple approaches to get you started, as well as some clear best practices on operational robustness.
PostgreSQL has included some form of native or in-core replication since version 8.2, though that support has steadily improved over time. External projects and tools have always been a significant part of the PostgreSQL landscape, with most of them being written and supported by very skilled PostgreSQL technical developers. Some people with a negative viewpoint have observed that this weakens PostgreSQL or emphasizes shortcomings. Our view is that PostgreSQL has been lucky enough to be supported by a huge range of replication tools together, offering a wide set of supported use cases from which to build practical solutions. This view extends throughout this chapter on replication, with many recipes using tools that are not part of the core PostgreSQL project yet.
All tools mentioned in this chapter are actively enhanced by current core PostgreSQL developers. The pace of change in this area is high, and it is likely that some of the restrictions mentioned here could well be removed by the time you read this book. Double-check the documentation for each tool or project.
Which technique is the best? This is a question that gets asked many times. The answer varies depending on the exact circumstances. In many cases, people use one technique on one server and a different technique on other servers. Even the developers of particular tools use other tools when appropriate. Use the right tools for the job. All the tools and techniques listed in this chapter have been recommended by us at some point, in relevant circumstances. If something isn't mentioned here by us, that could imply that it is less favorable for various reasons, and there are some tools and techniques that we would personally avoid altogether in their present form or level of maturity.
I (Simon Riggs) must also confess to being the developer or designer of many parts of the basic technology presented here. That gives me some advantages and disadvantages over other authors. It means I understand some things better than others, which hopefully translates into better descriptions and comparisons. It may also hamper me by providing too narrow a focus, though the world is big, and this book is already long enough!
This book, and especially this chapter, covers technology in depth. As a result, we face the risk of minor errors. We've gone to a lot of trouble to test all of our recommendations, but just as with software, we have learned that books can be buggy too. We hope our efforts to present actual commands, rather than just words, will be appreciated by you.
In this chapter, we will cover the following recipes:
- Replication concepts
- Replication best practices
- Setting up streaming replication
- Setting up streaming replication security
- Hot Standby and read scalability
- Managing streaming replication
- Using repmgr
- Using replication slots
- Monitoring replication
- Performance and synchronous replication (sync rep)
- Delaying, pausing, and synchronizing replication
- Logical replication
- Bi-directional replication (BDR)
- Archiving transaction log data
- Upgrading minor releases
- Major upgrades in-place
- Major upgrades online
Replication concepts
In this recipe, we do not solve any specific replication problem—or, rather, we try to prevent the generic problem of getting confused when discussing replication. We do that by clarifying in advance the various concepts related to replication.
Indeed, replication technology can be confusing. You might be forgiven for thinking that people have a reason to keep it that way. Our observation is that there are many techniques, each with its own advocates, and their strengths and weaknesses are often hotly debated.
There are some simple, underlying concepts that can help you understand the various options available. The terms used here are designed to avoid favoring any particular technique, and we've used standard industry terms whenever available.
Topics
Database replication is the term we use to describe technology that's used to maintain a copy of a set of data on a remote system.
There are usually two main reasons for you wanting to do this, and those reasons are often combined:
- High availability (HA): Reducing the chances of data unavailability by having multiple systems, each holding a full copy of the data.
- Data movement: Allowing data to be used by additional applications or workload on additional hardware. Examples of this are Reference Data Management (RDM), where a single central server might provide information to many other applications, and systems for business intelligence (BI)/reporting.
Of course, both those topics are complex areas, and there are many architectures and possibilities for implementing each of them.
What we will talk about here is HA, where there is no transformation of the data. We simply copy the data from one PostgreSQL database server to another. So, we are specifically avoiding all discussion of popular keywords such as evaluate, transform, and load (ETL) tools, enterprise application integration (EAI) tools, inter-database migration, and data-warehousing strategies. Those are valid topics in information technology (IT) architecture; it's just that we don't cover them in this book.
Basic concepts
Let's look at the basic database cluster architecture. Typically, individual database servers are referred to as nodes. The whole group of database servers involved in replication is known as a cluster. That is the common usage of the term, but be careful—the term cluster has two other quite separate meanings elsewhere in PostgreSQL. Firstly, cluster is sometimes used to refer to the database instance, though we prefer the term database server. Secondly, there is a command named cluster, designed to sort data in a specific order within a table.
A database server that allows a user to make changes is known as a primary or master or may be described as a source of changes.
A database server that only allows read-only access is known as a standby or as a read replica. A standby server is an exact copy of its upstream node, and therefore is standing by, meaning that it can be quickly activated and replace the upstream node, should it fail (for instance).
A key aspect of replication is that data changes are captured on a master and then transferred to other nodes. In some cases, a node may send the changes it receives to other nodes, which is a process known as cascading or relay. Thus, the master is a sending node, but a sending node does not need to be a master.
Replication is often categorized by whether more than one master node is allowed, in which case it will be known as multi-master replication. There is a significant difference between how single-master and multi-master systems work, so we'll discuss that aspect in more detail later. Each has its advantages and disadvantages.
History and scope
PostgreSQL didn't always have in-core replication. For many years, PostgreSQL users needed to use one of many external packages to provide this important feature.
Slony was the first package to provide useful replication features. Londiste was a variant system that was somewhat easier to use. Both of those systems provided single-master replication based on triggers. Another variant of this idea was the bucardo package, which offered multi-master replication using triggers.
Trigger-based replication has now been superseded by transaction log-based replication, which provides considerable performance improvements. There is some discussion regarding exactly how much difference that makes, but log-based replication is approximately twice as fast, though many users have reported much higher gains. Trigger-based systems also have considerably higher replication lag. Lastly, triggers need to be added to each table involved in replication, making these systems more time-consuming to manage and more sensitive to production problems. These factors taken together mean that trigger-based systems are usually avoided for new developments, and we take the decision not to cover them at all in the latest edition of this book.
Outside the world of PostgreSQL, there are many competing concepts, and there is a lot of research being done on them. This is a practical book, so we've mostly avoided comments on research or topics concerning computer science.
The focus of this chapter is replication technologies that are part of the core software of PostgreSQL, or will be in the reasonably near future. The first of these is known as streaming replication (SR), introduced in PostgreSQL 9.0, but it is based on earlier file-based mechanisms for physical transaction log replication. In this book, we refer to this as physical SR (PSR) because we take the transaction log (often known as the write-ahead log (WAL)) and ship that data to the remote node. The WAL contains an exact physical copy of the changes made to a data block, so the remote node is an exact copy of the primary. Therefore, the remote node cannot execute transactions that write to the database because we want to keep applying the WAL from the upstream node; this type of node is known as a standby.
Starting with PostgreSQL 9.4, we introduced an efficient mechanism for reading the transaction log (WAL) and transforming it into a stream of changes; that is, a process known as logical decoding. This was then the basis for a later, even more useful mechanism, known as logical SR (LSR). This allows a receiver to replicate data without needing to keep an exact copy of the data blocks, as we do with PSR. This has significant advantages, which we will discuss later.
PSR requires us to have only a single master node, though it allows multiple standbys. LSR can be used for all the same purposes as PSR. It just has fewer restrictions and allows a great range of additional use cases. Crucially, LSR can be used as the basis of multi-master clusters.
PSR and LSR are sometimes known as physical log SR (PLSR) and logical log SR (LLSR). Those terms are sometimes used when explaining the differences between transaction log-based and trigger-based replication.
Practical aspects
Since we refer to the transfer of replicated data as streaming, it becomes natural to talk about the flow of data between nodes as if it were a river or stream. Cascaded data can flow through a series of nodes to create complex architectures. From the perspective of any node, it may have downstream nodes that receive replicated data from it and/or upstream nodes that send data to it. Practical limits need to be understood to allow us to understand and design replication architectures.
After a transaction commits on the primary, the time taken to transfer data changes to a remote node is usually referred to as the latency or replication delay. Once the remote node has received the data, changes must then be applied to the remote node, which takes an amount of time known as the apply delay. The total time a record takes from the primary to a downstream node is the replication delay plus the apply delay. Be careful to note that some authors describe those terms differently and sometimes confuse the two, which is easy to do. Also, note that these delays will be different for any two nodes.
Replication delay is best expressed as an interval (in seconds), but that is much harder to measure than it first appears. In PostgreSQL 14, the delays of particular phases of replication are given with the lag columns on pg_stat_replication. These are derived from sampling the message stream and interpolating the current delay from recent samples.
All forms of replication are initialized in roughly the same way. First, you enable change capture, and then make a full replica of the dataset on the remote node, which we refer to as the base backup or the initial copy. After that, we begin applying the changes, starting from the point immediately before the base backup started and continuing with any changes that occurred while the base backup was taking place. As a result, the replication delay immediately following the initial copy task will be equal to the duration of the initial copy task. The remote node will then begin to catch up with the primary, and the replication delay will begin to reduce. The time taken to get the lowest replication delay possible is known as the catch-up interval. If the primary is busy generating new changes, which can increase the time it takes for the new node to catch up, you should try to generate new nodes during quieter periods, if any exist. Note that in some cases, the catch-up period will be too long to be acceptable. Be sure to include this understanding in your planning and monitoring. The faster and more efficient your replication system is, the easier it will be to operate in the real world. Performance matters!
Either replication will copy all tables, or in some cases, we can copy a subset of tables, in which case we call it selective replication. If you choose selective replication, you should note that the management overhead increases roughly as the number of objects managed increases. Replicated objects are often manipulated in groups known as replication sets to help minimize the administrative overhead.
Data loss
By default, PostgreSQL provides asynchronous replication (async rep), where data is streamed out whenever convenient for the server. If replicated data is acknowledged back to the user prior to committing, we refer to that as sync rep.
With sync rep, the replication delay directly affects the elapsed time of transactions on the primary. With async rep, the primary may continue at full speed, though this opens up a possible risk that the standby may not be able to keep pace with the primary. All replications must be monitored to ensure that a significant lag does not develop, which is why we must be careful to monitor the replication delay.
Sync rep guarantees that data is written to at least two nodes before the user or application is told that a transaction has committed. You can specify the number of nodes and other details that you wish to use in your configuration.
Single-master replication
In single-master replication, if the primary dies, one of the standbys must take its place. Otherwise, we will not be able to accept new write transactions. Thus, the designations of primary and standby are just roles that any node can take at some point. To move the primary role to another node, we perform a procedure named switchover. If the primary dies and does not recover, then the more severe role change is known as a failover. In many ways, these can be similar, but it helps to use different terms for each event.
We use the term clusterware for software that manages the cluster. Clusterware may provide features such as automatic failover, and—in some cases—also load balancing.
The complexity of failover makes single-master replication harder to configure correctly than many people would like it to be. The good news is that from an application perspective, it is safe and easy to retrofit this style of replication to an existing system. Or, put another way, since application developers don't really worry about HA and replication until the very end of a project, single-master replication is frequently the best solution.
Multinode architectures
Multinode architectures allow users to write data to multiple nodes concurrently. There are two main categories—tightly coupled and loosely coupled:
- Tightly coupled database clusters: These allow a single image of the database, so there is less perception that you're even connected to a cluster at all. This consistency comes at a price—the nodes of the cluster cannot be separated geographically, which means if you need to protect against site disasters, then you'll need additional technology to allow disaster recovery (DR). Clustering requires replication as well.
- Loosely coupled database clusters: These have greater independence for each node, allowing us to spread nodes out across wide areas, such as across multiple continents. You can connect to each node individually. There are two benefits of this. The first is that all data access can be performed quickly against local copies of the data. The second benefit is that we don't need to work out how to route read-only transactions to one or more standby nodes and read/write transactions to the primary node.
Multi-master replication
An example of a loosely coupled system would be BDR. Postgres-BDR does not utilize a global transaction manager, and each node contains data that is eventually consistent between nodes. This is a performance optimization since tests have shown that trying to use tightly coupled approaches catastrophically limits performance when servers are geographically separated.
In its simplest multi-master configuration, each node has a copy of similar data. You can update data on any node, and the changes will flow to other nodes. This makes it ideal for databases that have users in many different locations, which is probably the case with most websites. Each location can have its own copy of the application code and database, giving fast response times for all your users, wherever they are located.
It is possible to make changes to the same data at the same time on different nodes, causing write conflicts. While these could become a problem, the reality is that it is also easily possible to design applications that do not generate conflicts in normal running, especially if each user is modifying their own data (for example, in social media or retail).
We need to understand where conflicts might arise so that we can resolve them. On a single node, any application that allows concurrent updates to the same data will experience poor performance because of contention. The negative effect of contention will get much worse on multi-master clusters. In addition, the ability to write on multiple nodes forces us to implement conflict resolution in any case, to resolve data differences between nodes. Therefore, with some thought and planning, we can use multi-master technologies very effectively in the real world.
In fact, the word conflict has a negative connotation that does not match an objective cost/benefit analysis, at least in some cases. If the conflict resolution logic is compatible with the application model, then a conflict is nothing more than a little amount of unnecessary work that does no harm, and the application will be faster by accepting sporadic conflicts rather than trying to prevent them.
Visit https://en.wikipedia.org/wiki/Replication_(computing) for more information on this.
Other approaches to replication
This book covers in-database replication only. Replication is also possible in the application layer (that is, above the database) or in the operating system (OS) layers (that is, below the database):
- Application-level replication: For example, HA-JDBC and rubyrep
- OS-level replication: For example, Distributed Replicated Block Device (DRBD)
None of these approaches is very satisfying, since core database features cannot easily integrate with them in ways that truly work. From a system administrator's (sysadmin's) perspective, they work, but not very well from the perspective of a database architect.
Replication best practices
Some general best practices for running replication systems are described in this recipe.
Getting ready
Reading a list of best practices should be the very first thing you do when designing your database architecture. So, the best way to get ready for it is to avoid doing anything and start straight away with the next section, How to do it...
How to do it…
Here are some best practices for replication:
- Use the latest release of PostgreSQL. Replication features are changing fast, with each new release improving on the previous in major ways based on our real-world experience. The idea that earlier releases are somehow more stable, and thus more easily usable, is definitely not the case for replication.
- Use similar hardware and OSs on all systems. Replication allows nodes to switch roles. If we switch over or fail over to different hardware, we may get performance issues, and it will be hard to maintain a smoothly running application.
- Configure all systems identically as far as possible. Use the same mount points, directory names, and users; keep everything the same where possible. Don't be tempted to make one system more important than others in some way. It's just a single point of failure (SPOF) and gets confusing.
- Give systems/servers good names to reduce confusion. Never, ever call one of your systems primary and the other standby. When you do a switchover, you will get very confused! Try to pick system names that have nothing to do whatsoever with their role. Replication roles will inevitably change; system names should not. If one system fails and you add a new system, never reuse the name of the old system; pick another name, or it will be too confusing. Don't pick names that relate to something in the business. Colors are also a bad choice because if you have two servers named Yellow and Red, you then end up saying things such as There is a red alert on server Yellow, which can easily be confusing. Don't pick place names, either. Otherwise, you'll be confused trying to remember that London is in Edinburgh and Paris is in Rome. Make sure that you use names, rather than Internet Protocol (IP) addresses.
- Set the application_name parameter to be the server name in the replication connection string. Set the cluster_name parameter to be the server name in the postgresql.conf file.
- Make sure that all tables are marked as LOGGED (the default). UNLOGGED and TEMPORARY tables will not be replicated by either PSR or LSR.
- Keep the system clocks synchronized. This helps you keep sane when looking at log files that are produced by multiple servers. You should automate this rather than do it manually, but however you do it, make sure it works.
- Use a single, unambiguous time zone. Use UTC or something similar. Don't pick a time zone that has daylight savings time (DST), especially in regions that have complex DST rules. This just leads to (human) confusion with replication, as servers are often in different countries, and time zone differences vary throughout the year. Do this even if you start with all your servers in one country, because over the lifetime of the application, you may need to add new servers in different locations. Think ahead.
- Monitor each of the database servers. If you want HA, then you'll need to check regularly that your servers are operational. I speak to many people who would like to regard replication as a one-shot deal. Think of it more as a marriage and plan for it to be a happy one!
- Monitor the replication delay between servers. All forms of replication are only useful if the data is flowing correctly between the servers. Monitoring the time it takes for the data to go from one server to another is essential for understanding whether replication is working for you. Replication can be bursty, so you'll need to watch to make sure it stays within sensible limits. You may be able to set tuning parameters to keep things low, or you may need to look at other factors.
The important point is that your replication delay is directly related to the amount of data you're likely to lose when running async rep. Be careful here because it is the replication delay, not the apply delay, that affects data loss. A long apply delay may be more acceptable as a result.
As described previously, your initial replication delay will be high, and it should reduce to a lower and more stable value over a period of time. For large databases, this could take days, so be careful to monitor it during the catch-up period.
There's more…
The preceding list doesn't actually say this explicitly, but you should use the same major version of PostgreSQL for all systems. With PSR, you are required to do that, so it doesn't even need to be said.
I've heard people argue that it's OK to have dissimilar systems and even that it's a good idea because if you get a bug, it only affects one node. I'd say that the massive increase in complexity is much more likely to cause problems.
Setting up streaming replication
Physical replication is a technique used by many database management systems. The primary database node records change in a transaction log (WAL), and then the log data is sent from the primary to the standby, where the log is replayed.
In PostgreSQL, PSR transfers WAL data directly from the primary to the standby, giving us integrated security and shorter replication delay.
There are two main ways to set up streaming replication: with or without an additional archive. We present how to set it up without an external archive, as this is simpler and generally more efficient. However, there is one downside, suggesting that the simpler approach may not be appropriate for larger databases, which is explained later in this recipe.
Getting ready
If you haven't read the Replication concepts and Replication best practices recipes at the start of this chapter, go and read them now. Note that streaming replication refers to the master node as the primary node, and the two terms can be used interchangeably.
How to do it…
You can use the following procedure for base backups:
- Identify your primary and standby nodes and ensure that they have been configured according to the Replication best practices recipe. In this recipe, we assume that host1 and host2 are the primary and the standby, respectively.
- Configure replication security. Create or confirm the existence of a replication user on the primary node:
CREATE USER repuser
REPLICATION
LOGIN
CONNECTION LIMIT 2
ENCRYPTED PASSWORD 'changeme';
- Allow the replication user on the standby node to authenticate on the primary node. The following example allows access from the standby node using password authentication encrypted with SCRAM-SHA-256; you may wish to consider other options. First, add the following line to pg_hba.conf on the primary node:
Host replication repuser host2 scram-sha-256
- Then, ensure that the client password file for the postgres user on the standby node contains the following line, as explained in the Avoiding hardcoding your password recipe in Chapter 1, First Steps:
host1:5432:replication:repuser:changeme
- Set the logging options in postgresql.conf on both the primary and the standby so that any replication connection attempts and associated failures are logged (this is not needed, but we recommend it, especially the first time when configuring replication):
log_connections = on
- Take a base backup of the primary node from the standby node:
pg_basebackup -d 'host=host1 user=repuser' -D /path/to_data_dir -R -P
- Start the standby server on host2:
pg_ctl start -D /path/to_data_dir
- Carefully monitor the replication delay until the catch-up period is over. During the initial catch-up period, the replication delay will be much higher than we would normally expect it to be.
How it works…
pg_basebackup will perform a base backup and populate the directory indicated with -D, and then configure the files in the newly created data directory as a standby of the upstream specified with the -d option, which is what we requested with the -R option. The -P option will enable progress display, which can be quite useful if the base backup takes a long time.
Multiple standby nodes can connect to a single primary; max_wal_senders must be set to the number of standby nodes, plus at least 1. The default value of 10 is enough unless you are planning a large number of standbys. You may wish to set up an individual user for each standby node, though it may be sufficient just to set the application_name parameter in primary_conninfo if you only want to know which connection is used by which standby node. The architecture for streaming replication is this: on the primary, one WALSender process is created for each standby that connects to the streaming replication. On the standby node, a WALReceiver process is created to work cooperatively with the primary. Data transfer has been designed and measured to be very efficient, and data is typically sent in 8,192-byte chunks, without additional buffering at the network layer.
Both WALSender and WALReceiver will work continuously on any outstanding data and will be replicated until the queue is empty. If there is a quiet period, then WALReceiver will sleep for a while.
The standby connects to the primary using native PostgreSQL LibPQ connections. This means that all forms of authentication and security work for replication, just as they do for normal connections; just specify replication as the database name, which PostgreSQL will interpret as follows: it will not connect to a database called replication, but it will apply these settings to establish a PSR connection, which replicates all databases at once. Note that, for replication sessions, the standby is the client and the primary is the server if any parameters need to be configured. Using standard PostgreSQL LibPQ connections also means that normal network port numbers are used, so no additional firewall rules are required. You should also note that if the connections use Secure Sockets Layer (SSL), then encryption costs will slightly increase the replication delay and the central processing unit (CPU) resources required.
There's more…
If the connection between the primary and standby drops, it will take some time for that to be noticed across an indirect network. To ensure that a dropped connection is noticed as soon as possible, you may wish to adjust the timeout settings.
The standby will notice that the connection to the primary has dropped after wal_receiver_timeout milliseconds. Once the connection is dropped, the standby will retry the connection to the sending server every wal_retrieve_retry_interval milliseconds. Set these parameters in the postgresql.conf file on the standby.
A sending server will notice that the connection has dropped after wal_sender_timeout milliseconds, set in the postgresql.conf file on the sender. Once the connection is dropped, the standby is responsible for re-establishing the connection.
Data transfer may stop if the connection drops or the standby server or the standby system is shut down. If replication data transfer stops for any reason, it will attempt to restart from the point of the last transfer. Will that data still be available? It depends on how long the standby was disconnected. If the requested WAL file has been deleted in the meantime, then the standby will no longer be able to replicate data from the primary, and you will need to rebuild the standby from scratch.
In order to avoid this scenario, there are a few options; the easiest one is now to use replication slots, which reserve WAL files for use by disconnected nodes. When using replication slots, it is important to watch that WAL files don't build up, causing out-of-disk-space errors—for instance, if one standby is disconnected for a long time and its slot prevents the deletion of old WAL while new WAL is being produced. The amount of space taken by WAL should be monitored, and the slot should be dropped if space reaches a critical limit. As in many cases, simple monitoring of basic measures such as available disk space can be very effective in preventing a wide range of problems with timely alerts.
There are --create-slot and --slot options in pg_basebackup, respectively, for creating a replication slot and for using it to set up the standby.
When using replication slots, we recommend setting max_slot_wal_keep_size to a positive value, which will define the maximum lag allowed for replication slots. Any slots that fall beyond that limit will be marked as invalid, meaning that they will no longer be considered for WAL retention. The default is -1, meaning that there is no limit.
For example, if you set max_slot_wal_keep_size = '1GB' and a standby is lagging more than 1 gigabyte (GB), then its replication connection might break when the next checkpoint removes old WAL, in which case that standby must be rebuilt from scratch; but this is normally preferable to breaking the primary (and all its standbys) because its pg_wal directory fills. If this parameter is so good, why is it not enabled by default? Because a reasonable value should be the maximum available disk space minus some allowance to let the checkpoint clear old WAL files. This depends on the workload and disk layout, and hence it is best estimated by the user.
This setting was introduced in PostgreSQL 12; before that, users would set wal_keep_segments, which specifies a fixed amount of WAL to be retained, irrespective of existing replication connections and their log sequence numbers (LSNs).
In some cases, using a replication slot is not the best choice because it effectively means that pg_wal on the upstream server is used as a long-term storage solution for a large number of old WAL files for the convenience of standby nodes. A better practice for that scenario is to configure restore_command on the standby so that it can fetch files from the backup server (for example, Barman). The standby will no longer need a replication slot to retain WAL on the primary and will be able to retrieve WAL files from Barman instead. Barman itself will still use a replication slot, and the primary server will then be vulnerable to a prolonged failure of Barman's connection, but this will be appropriate because a production system should not be considered healthy if its backup function is failing for a long time.
The --max-rate option can be used to throttle the base backup taken by pg_basebackup, which could be desirable—for instance—if the overall network bandwidth is limited and is shared with other important services.
Setting up streaming replication security
Streaming replication is at least as secure as normal user connections to PostgreSQL.
Replication uses standard LibPQ connections, so we have all the normal mechanisms for authentication and SSL support, and all the firewall rules are similar.
Replication must be specifically enabled on both the sender and standby sides. Cascading replication does not require any additional security.
When performing a base backup, the pg_basebackup, pg_receivewal, and pg_recvlogical utilities will use the same type of LibPQ connections as a running, streaming standby. You can use other forms of base backup, such as rsync, though you'll need to set up the security configuration manually.
Note
Standbys are identical copies of the primary, so all users exist on all nodes with identical passwords. All of the data is identical (eventually), and all the permissions are the same too. If you wish to control access more closely, then you'll need different pg_hba.conf rules on each server to control this. Obviously, if your config files differ between nodes, then failover will be slightly more dramatic unless you've given that some prior thought.
Getting ready
Identify or create a user/role to be used solely for replication. Decide what form of authentication will be used. If you are going across data centers or the wider internet, take this very seriously.
How to do it…
On the primary, perform these steps:
- Enable replication by setting a specific host access rule in pg_hba.conf.
- Give the selected replication user/role the REPLICATION and LOGIN attributes:
ALTER ROLE replogin REPLICATION;
- Alternatively, you can create it using this command:
CREATE ROLE replogin REPLICATION LOGIN;
On the standby, perform these steps:
- Request replication by setting primary_conninfo in recovery.conf.
- If you are using SSL connections, use sslmode=verify-full.
- Enable per-server rules, if any, for this server in pg_hba.conf.
How it works…
Streaming replication connects to a virtual database called replication. We do this because the WAL data contains changes to objects in all databases, so in a way, we aren't just connecting to one database—we are connecting to all of them.
Streaming replication connects similarly to a normal user, except that instead of a normal user process, we are given a WALSender process.
You can set a connection limit on the number of replication connections in two ways:
- At the role level, you can do it by issuing the following command:
ALTER ROLE replogin CONNECTION LIMIT 2;
- By limiting the overall number of WALSender processes using the max_wal_senders parameter
Always allow one more connection than you think is required to allow for disconnections and reconnections.
There's more…
You may notice that the WALSender process may hit 100% CPU if you use SSL with compression enabled and write lots of data or generate a large WAL volume from things such as data definition language (DDL) or vacuuming. You can disable compression on fast networks when you aren't paying per-bandwidth charges by using sslcompression=0 in the connection string specified for primary_conninfo. Note that security can be compromised if you use compression since the data stream is easier to attack.
Hot Standby and read scalability
Hot Standby is the name for the PostgreSQL feature that allows us to connect to a standby node and execute read-only queries. Most importantly, Hot Standby allows us to run queries while the standby is being continuously updated through either file-based or streaming replication.
Hot Standby allows you to offload large or long-running queries or parts of your read-only workload to standby nodes. Should you need to switch over or fail over to a standby node, your queries will keep executing during the promotion process to avoid any interruption of service.
You can add additional Hot Standby nodes to scale the read-only workload. There is no hard limit on the number of standby nodes, as long as you ensure that enough server resources are available and parameters are set correctly—10, 20, or more nodes are easily possible.
There are two main capabilities provided by a Hot Standby node. The first is that the standby node provides a secondary node in case the primary node fails. The second capability is that we can run queries on that node. In some cases, these two aspects can come into conflict with each other and can result in queries being canceled. We need to decide the importance we attach to each capability ahead of time so that we can prioritize between them.
In most cases, the role of standby will take priority: queries are good, but it's OK to cancel them to ensure that we have a viable standby. If we have more than one Hot Standby node, it may be possible to nominate one node as standby and dedicate the others to serving queries, without any regard for their capability to act as standbys.
Standby nodes are started and stopped using the same server commands as primary servers, which were covered in earlier chapters.
Getting ready
Hot Standby can be used with physical replication as well as with point-in-time recovery (PITR).
The parameters required by Hot Standby are enabled by default on all recent PostgreSQL versions, so there is nothing you need to do in advance unless you have changed them explicitly (in which case, if you have disabled this feature, you will know that already).
How to do it…
On the standby node, changes from the primary are read from the transaction log and applied to the standby database. Hot Standby works by emulating running transactions from the primary so that queries on the standby have the visibility information they need to respect multi-version concurrency control (MVCC). This makes the Hot Standby mode particularly suitable for serving a large workload of short or fast SELECT queries. If the workload is consistently short, then few conflicts will delay the standby and the server will run smoothly.
Queries that run on the standby node see a version of the database that is slightly behind the primary node. We describe this behavior as the cluster being eventually consistent. How long is "eventually"? That time is exactly the replication delay plus the apply delay, as discussed in the Replication concepts section. You may also request that standby servers delay the application of the changes they receive from their upstreams; see the Delaying, pausing, and synchronizing replication recipe later on in this chapter for more information.
Resource contention (CPU, I/O, and so on) may increase the apply delay. If the server is busy applying changes from the primary, then you will have fewer resources to use for queries. This also implies that if there are no changes arriving, then you'll get more query throughput. If there are predictable changes in the write workload on the primary, then you may need to throttle back your query workload on the standby when they occur.
Replication apply may also generate conflicts with running queries. Conflicts may cause the replay to pause, and eventually queries on the standby may be canceled or disconnected. Conflicts that can occur between the primary and queries on the standby can be classified based on their causes:
- Locks, such as access exclusive locks
- Cleanup records
- Other special cases
If cancellations do occur, they will throw either error or fatal-level errors. These will be marked with code—SQLSTATE 40001 SERIALIZATION FAILURE. The application can be programmed to detect this error code and then resubmit the same SQL code, given the nature of the error.
There are two sources of information for monitoring the number of conflicts. The total number of conflicts in each database can be seen using this query:
SELECT datname, conflicts FROM pg_stat_database;
You can drill down further to look at the types of conflict using the following query:
SELECT datname, confl_tablespace, confl_lock, confl_snapshot, confl_bufferpin, confl_deadlock
FROM pg_stat_database_conflicts;
Tablespace conflicts are the easiest to understand: if you try to drop a tablespace that someone is still using, then you're going to get a conflict. Don't do that!
Lock conflicts are also easy to understand. If you wish to run certain commands on the primary—such as ALTER TABLE ... DROP COLUMN, for instance—then you must lock the table first to prevent all types of access because of the way that command is implemented: while it will leave the database in a consistent state when it completes, it is not designed to preserve that consistency at all times while it is running, meaning that another session reading that table while that command runs could get inconsistent results. For that reason, the lock request is sent to the standby server as well, and the standby will then prevent those reads, meaning that it will cancel standby queries that are currently accessing that table after a configurable delay.
On HA systems, making DDL changes to tables that cause long periods of locking on the primary can be unacceptable. You may want the tables on the standby to stay available for reads during the period in which changes are being made on the primary, even if that means that the standby might delay the application of changes when it runs a conflicting query. To do that, temporarily set these parameters on the standby: max_standby_streaming delay = -1 and max_standby_archive_delay = -1. Then, reload the server. As soon as the first lock record is seen on the standby, all further changes will be held. Once the locks on the primary are released, you can reset the original parameter values on the standby, which will then allow changes to be made there.
Note that max_standby_streaming_delay is used when the standby is streaming WAL, which is usually the case while replication is running normally, while max_standby_archive_delay is used when WAL files are fetched using restore_command, which is the case when the standby has fallen behind considerably and is fetching older WAL from the archive (for example, Barman). There are two separate settings because the extent of what is an acceptable lag can differ between those scenarios.
Setting the max_standby_streaming_delay and max_standby_archive_delay parameters to -1 is very timid and may not be useful for normal running if the standby is intended to provide HA. No user query will ever be canceled if it conflicts with applying changes, which will cause the apply process to wait indefinitely. As a result, the apply delay can increase significantly over time, depending on the frequency and duration of queries and the frequency of conflicts. To work out an appropriate setting for these parameters, you need to understand more about the other types of conflicts, though there is also a simple way to avoid this problem entirely.
Snapshot conflicts require some understanding of the internal workings of MVCC, which many people find confusing. To avoid snapshot conflicts, you can set hot_standby_feedback = on in the standby's postgresql.conf file.
In some cases, this could cause table bloat on the primary, so it is not set by default. If you don't wish to set hot_standby_feedback = on, then you have further options to consider; you can set an upper limit with max_standby_streaming_delay and max_standby_archive_delay, as explained previously, and as a last resort, you can set vacuum_defer_cleanup_age to a value higher than 0. This parameter is fairly hard to set accurately, though we would suggest starting with a value of 1000 and then tuning upward. A vague and inaccurate assumption would be to say that each 1000 will be approximately 1 second of additional delay. This is probably helpful more often than it is wrong. Other conflict types (buffer pin, deadlocks, and so on) are possible, but they are rare.
Finally, if you want a completely static standby database with no further changes applied, then you can do this by modifying the configuration so that neither restore_command nor primary_conninfo is set but standby_mode is on, and then restarting the server. You can come back out of this mode, but only if the archive contains the required WAL files to catch up; otherwise, you will need to reconfigure the standby from a base backup again.
If you attempt to run a non-read-only query, then you will receive an error marked with SQLSTATE 25006 READ ONLY TRANSACTION. This could be used by the application (if aware) to redirect SQL to the primary, where it can execute successfully.
How it works…
Changes made by a transaction on the primary will not be visible until the commit is applied to the standby. So, for example, we have a primary and a standby with a replication delay of 4 seconds between them. A long-running transaction may write changes to the primary for 1 hour. How long does it take before those changes are visible on the standby? With Hot Standby, the answer is 4 seconds after the commit on the primary. This is because changes made during the transaction on the primary are streamed while the transaction is still in progress, and in most cases, they are already applied on the standby when the commit record arrives.
You may also wish to use the remote_apply mode; see the Delaying, pausing, and synchronizing replication recipe later on in this chapter.
Hot Standby can also be used when running a PITR, so the WAL records that are applied to the database need not arrive immediately from a live database server. We can just use file-based recovery in that case, not streaming replication.
Finally, query performance has been dramatically improved in Hot Standby over time, so it's a good idea to upgrade for that reason alone.
Managing streaming replication
Replication is great, provided that it works. Replication works well if it's understood, and it works even better if it's tested.
Getting ready
You need to have a plan for the objectives for each individual server in the cluster. Which standby server will be the failover target?
How to do it…
Switchover is a controlled switch from the primary to the standby. If performed correctly, there will be no data loss. To be safe, simply shut down the primary node cleanly, using either the smart or fast shutdown modes. Do not use the immediate mode shutdown because you will almost certainly lose data that way.
Failover is a forced switch from the primary node to a standby because of the loss of the primary. So, in that case, there is no action to perform on the primary; we presume it is not there anymore.
Next, we need to promote one of the standby nodes to be the new primary. A standby node can be triggered into becoming a primary node with the pg_ctl promote command.
The standby will become the primary only once it has fully caught up. If you haven't been monitoring replication, this could take some time.
Once the ex-standby becomes a primary, it will begin to operate all normal functions, including archiving files, if configured. Be careful and verify that you have all the correct settings for when this node begins to operate as a primary.
It is likely that the settings will be different from those on the original primary from which they were copied.
Note that I refer to this new server as a primary, not the primary. It is up to you to ensure that the previous primary doesn't continue to operate—a situation known as split-brain. You must be careful to ensure that the previous primary stays down.
Management of complex failover situations is not provided with PostgreSQL, nor is automated failover. Situations can be quite complex with multiple nodes, and appropriate clusterware is recommended and used in many cases to manage this.
There's more…
When following a switchover from one node to another, it is common to think of performing a switchover back to the old primary server, which is sometimes called failback or switchback.
Once a standby has become a primary, it cannot go back to being a standby again. So, with log replication, there is no explicit switchback operation. This is a surprising situation for many people and there is a repeated question, but it is quick to work around. Once you have performed a switchover, all you need to do is the following:
- Reconfigure the old primary node again, repeating the same process as before to set up a standby node
- Switch over from the current to the old primary node
The important part here is that if we perform the first step without deleting the files on the old primary, it allows rsync to go much faster. When no files are present on the destination, rsync just performs a copy. When similarly named files are present on the destination, then rsync will compare the files and send only the changes. So, the rsync we perform on a switchback operation performs much less data transfer than in the original copy. It is likely that this will be enhanced in later releases of PostgreSQL. There are also ways to avoid this, as shown in the repmgr utility, which will be discussed later.
The pg_rewind utility has been developed as a way to perform an automated switchback operation. It performs a much faster switchback when there is a large database with few changes to apply. To allow correct operation, this program can only run on a server that was previously configured with the wal_log_hints = on parameter.
Using that parameter can cause more I/O on large databases, so while it improves performance for switchback, it has a considerable overhead for normal running. If you think you would like to run pg_rewind, then make sure you work out how it behaves ahead of time. Trying to run it for the first time in a stress situation when the server is down is a bad idea.
If all goes wrong, then please remember that pg_resetwal is not your friend. It is specifically designed to remove WAL files, destroying your data changes in the process. Always back up WAL files before using it.
PostgreSQL provides a recovery_end_command utility that was used to clean up after switchover or failover with older versions when replication was based on copying WAL files to a third location (archive) that needed to be maintained; this is largely unnecessary nowadays.
See also
Clusterware may provide additional features, such as automated failover, monitoring, or ease of management of replication:
- The repmgr utility is designed to manage PostgreSQL replication and failover, and is discussed in more detail in the Using repmgr recipe.
- The pgpool utility is designed to allow session pooling and routing of requests to standby nodes.
Using repmgr
As we stated previously, replication is great, provided that it works; it works well if it's understood, and it works even better if it's tested. This is a great reason to use the repmgr utility.
repmgr is an open source tool that was designed specifically for PostgreSQL replication. To get additional information about repmgr, visit http://www.repmgr.org/.
The repmgr utility provides a command-line interface (CLI) and a management process (daemon) that's used to monitor and manage PostgreSQL servers involved in replication. The repmgr utility easily supports more than two nodes with automatic failover detection.
Getting ready
Install the repmgr utility from binary packages on each PostgreSQL node.
Set up replication security and network access between nodes according to the Setting up streaming replication security recipe.
How to do it…
The repmgr utility provides a set of single command-line actions that perform all the required activities on one nod:.
- To start a new cluster with repmgr with the current node as its primary, use the following command:
repmgr primary register
- To add an existing standby to the cluster with repmgr, use the following command:
repmgr standby register
- Use the following command to request repmgr to create a new standby for you by copying node1. This will fail if you specify an existing data directory:
repmgr standby clone node1 -D /path/of_new_data_directory
- To reuse an old primary as a standby, use the rejoin command:
repmgr node rejoin -d 'host=node2 user=repmgr'
- To switch from one primary to another one, run this command on the standby that you want to make a primary:
repmgr standby switchover
- To promote a standby to be the new primary, use the following command:
repmgr standby promote
- To request a standby to follow a new primary, use the following command:
repmgr standby follow
- Check the status of each registered node in the cluster, like this:
repmgr cluster show
- Request a cleanup of monitoring data, as follows. This is relevant only if --monitoring-history is used:
repmgr cluster cleanup
- Create a witness server for use with auto-failover voting, like this:
repmgr witness create
The preceding commands are presented in a simplified form. Each command also takes one of these options:
- --verbose: This is useful when exploring new features
- -f: This specifies the path to the repmgr.conf file
For each node, create a repmgr.conf file containing at least the following parameters. Note that the node_id and node_name parameters need to be different on each node:
node_id=2
node_name=beta
conninfo='host=beta user=repmgr'
data_directory=/var/lib/pgsql/11/data
Once all the nodes are registered, you can start the repmgr daemon on each node, like this:
repmgrd -d -f /var/lib/pgsql/repmgr/repmgr.conf &
If you would like the daemon to generate monitoring information for that node, you should set monitoring_history=yes in the repmgr.conf file.
Monitoring data can be accessed using this:
repmgr=# select * from repmgr.replication_status;
-[ RECORD 1 ]-------------+------------------------------
primary_node_id | 1
standby_node_id | 2
standby_name | node2
node_type | standby
active | t
last_monitor_time | 2017-08-24 16:28:41.260478+09
last_wal_primary_location | 0/6D57A00
last_wal_standby_location | 0/5000000
replication_lag | 29 MB
replication_time_lag | 00:00:11.736163
apply_lag | 15 MB
communication_time_lag | 00:00:01.365643
How it works…
repmgr works with all supported PostgreSQL versions. It supports the latest features of PostgreSQL, such as cascading, sync rep, and replication slots. It can use pg_basebackup, allowing you to clone from a standby. The use of pg_basebackup also removes the need for rsync and key exchange between servers. Also, cascaded standby nodes no longer need to re-follow.
There's more…
The default behavior for the repmgr utility is manual failover.
The repmgr utility also supports automatic failover capabilities. It can automatically detect failures of other nodes and then decide which server should become the new primary by voting among all of the still-available standby nodes. The repmgr utility supports a witness server to ensure that there are an odd number of voters in order to get a clear winner in any decision.
Using replication slots
Replication slots allow you to define your replication architecture explicitly. They also allow you to track details of nodes even when they are disconnected. Replication slots work with both PSR and LSR, though they operate slightly differently.
Replication slots ensure that data required by a downstream node persists until the node receives it. They are crash-safe, so if a connection is lost, the slot still continues to exist. By tracking data on downstream nodes, we avoid these problems:
- When a standby disconnects, the feedback data provided by hot_standby_feedback is lost. When the standby reconnects, it may be sent cleanup records that result in query conflicts. Replication slots remember the standby's xmin value even when disconnected, ensuring that cleanup conflicts can be avoided.
- When a standby disconnects, knowledge of which WAL files were required is lost. When the standby reconnects, we may have discarded the required WAL files, requiring us to regenerate the downstream node completely (assuming that this is possible). Replication slots ensure that nodes retain the WAL files needed by all downstream nodes.
Replication slots are required by LSR and for any other use of logical decoding. Replication slots are optional with PSR.
Getting ready
This recipe assumes that you have already set up replication according to the earlier recipes, either via manual configuration or by using repmgr.
A replication slot represents one link between two nodes. At any time, each slot can support one connection. If you draw a diagram of your replication architecture, then each connecting line is one slot. Each slot must have a unique name. The slot name must contain only lowercase letters, numbers, and underscores.
As we discussed previously, each node should have a unique name, so a suggestion would be to construct the slot name from the two node names that it links. For various reasons, there may be a need for multiple slots between two nodes, so additional information is also required for uniqueness. For two servers called alpha and beta, an example of a slot name would be alpha_beta_1.
For LSR, each slot refers to a single database rather than the whole server. In that case, slot names could also include database names.
How to do it…
If you set up replication with repmgr, then you just need to set the following in the repmgr.conf file:
use_replication_slots = yes
For manual setup, you need to follow these steps:
- Ensure that max_replication_slots > 0 on each sending PostgreSQL node; the default of 10 is usually enough.
- For PSR slots, you first have to create a slot on the sending node with SQL like this, which will then display its LSN after creation:
SELECT (pg_create_physical_replication_slot
('alpha_beta_1', true)).wal_position;
wal_position
-----------------
0/5000060
- Monitor the slot in use with the following query:
SELECT * FROM pg_replication_slots;
- Set the primary_slot_name parameter on the standby using the unique name that you assigned earlier:
primary_slot_name = 'alpha_beta_1'
Note that slots can be removed using the following query when you don't need them anymore:
SELECT pg_drop_physical_replication_slot('alpha_beta_1');
There's more…
If all of your replication connections use slots, then there is no need to set the wal_keep_segments parameter.
Replication slots can be used to support applications where downstream nodes are disconnected for extended periods of time. Replication slots prevent the removal of WAL files, which are needed by disconnected nodes. Therefore, it is important to be careful that WAL files don't build up and cause out-of-disk-space errors due to leftover physical replication slots with no currently connected standby.
See also
See the Logical replication recipe for more details on using slots with LSR.
Monitoring replication
Monitoring the status and progress of your replication is essential. We'll start by looking at the server status and then query the progress of replication.
Getting ready
You'll need to start by checking the state of your server(s).
Check whether a server is up using pg_isready or another program that uses the PQping() application programming interface (API) call. You'll get one of the following responses:
- PQPING_OK (return code 0): The server is running and appears to be accepting connections.
- PQPING_REJECT (return code 1): The server is running but is in a state that disallows connections (start up, shutdown, or crash recovery) or a standby that is not enabled with Hot Standby.
- PQPING_NO_RESPONSE (return code 2): The server could not be contacted. This might indicate that the server is not running, there is something wrong with the given connection parameters (for example, wrong port number), or there is a network connectivity problem (for example, a firewall blocking the connection request).
- PQPING_NO_ATTEMPT (return code 3): No attempt was made to contact the server—for example, invalid parameters.
Note
At present, pg_isready does not differentiate between a primary and a standby, though this may change in later releases, nor does it specify whether a server is accepting write transactions or only read-only transactions (a standby or a primary connection in read-only mode).
You can find out whether a server is a primary or a standby by connecting and executing this query:
SELECT pg_is_in_recovery();
A true response means this server is in recovery, meaning it is running in Hot Standby mode.
There are also two other states that may be important for backup and replication: while the server is paused, and while the server is in the middle of an exclusive backup. The paused state doesn't affect user queries, but replication will not progress at all when paused. Only one exclusive backup may occur at any one time (which explains the name).
You can also check whether replay is paused by executing this query:
SELECT pg_is_wal_replay_paused();
If you want to check whether a server is in exclusive backup mode, execute the following query:
SELECT pg_is_in_backup();
There is no supported function that shows whether a non-exclusive backup is in progress, though there isn't as much to worry about if there is. If you care about that, make sure that you set the application_name parameter of the backup program so that it shows up in the session status output of pg_stat_activity, as discussed in Chapter 8, Monitoring and Diagnosis.
How to do it…
The rest of this recipe assumes that Hot Standby is enabled. Actually, this is not an absolute requirement, but it makes things much, much easier.
Both repmgr and pgpool provide replication monitoring facilities. Munin plugins are available for graphing replication and apply delay.
Replication works by processing the WAL transaction log on servers other than the one where it was created. You can think of WAL as a single, serialized stream of messages. Each message in the WAL is identified by an 8-byte integer known as an LSN. For historical reasons (and for readability), we show this as two separate 4-byte hexadecimal (hex) numbers; for example, the LSN value 00000XXX0YYYYYYY is shown as XXX/YYYYY.
You can compare any two LSNs using pg_wal_lsn_diff(). In some column and function names, prior to PostgreSQL 10, an LSN was referred to as a location, a term that's no longer in use. Similarly, the WAL was referred to as an xlog or transaction log.
To understand how to monitor progress, you need to understand a little more about replication as a transport mechanism. The stream of messages flows through the system like water through a pipe, and at certain points of the pipe, you have a meter that displays the total amount of bytes (LSNs) that have flown via that point at that time. You can work out how much progress has been made by measuring the LSN at two different points in the pipe; the difference will be equal to the number of bytes that are in transit between those two points. You can also check for blockages in the pipe, as they will cause all downstream LSNs to stop.
Our pipe begins on the primary, where new WAL records are inserted into WAL files. The current insert LSN can be found using this query:
SELECT pg_current_wal_insert_lsn();
However, WAL records are not replicated until they have been written and synced to the WAL files on the primary. The LSN of the most recent WAL write is given by this query on the primary:
SELECT pg_current_wal_lsn();
Once written, WAL records are then sent to the standby. The recent status can be found by running this query on the standby (this and the later functions return NULL on a primary):
SELECT pg_last_wal_receive_lsn();
Once WAL records have been received, they are written to WAL files on the standby. When the standby has written those records, they can then be applied to it. The LSN of the most recent apply is found using this standby query:
SELECT pg_last_wal_replay_lsn();
Remember that there will always be timing differences if you run status queries on multiple nodes. What we really need is to see all of the information on one node. A view called pg_stat_replication provides the information that we need:
SELECT pid, application_name /* or other unique key */
,pg_current_wal_insert_lsn() /* WAL Insert lsn */
,sent_lsn /* WALSender lsn */
,write_lsn /* WALReceiver write lsn */
,flush_lsn /* WALReceiver flush lsn */
,replay_lsn /* Standby apply lsn */
,backend_start /* Backend start */
FROM pg_stat_replication;
-[ RECORD 1 ]-------------------+------------------------------ pid | 16496
application_name | pg_basebackup pg_current_wal_insert_lsn | 0/80000D0
sent_lsn |
write_lsn |
flush_lsn |
replay_lsn |
backend_start | 2017-01-27 15:25:42.988149+00
-[ RECORD 2 ]-------------------+-------------------pid
16497
application_name | pg_basebackup pg_current_wal_insert_lsn | 0/80000D0
sent_lsn | 0/80000D0
write_lsn | 0/8000000
flush_lsn | 0/8000000
replay_lsn |
backend_start | 2017-01-27 15:25:43.18958+00
Each row in this view represents one replication connection. The preceding snippet shows the output from a pg_basebackup that is using --wal-method=stream. The first connection that's shown is the base backup, while the second session is streaming WAL changes. Note that the replay_lsn value is NULL, indicating that this is not a standby.
This view is possible because standby nodes send regular status messages to their upstream to let it know how far they have progressed. If you run this query on the primary, you'll be able to see all the directly connected standbys. If you run this query on a standby, you'll see values representing any cascaded standbys, but nothing about the primary or any of the other standbys connected to the primary. Note that because the data has been sent from a remote node, the values displayed are not exactly in sync; they will each refer to a specific instant in the (recent) past. It is very likely that processing will have progressed beyond the point being reported, but we don't know that for certain. That's just physics. Welcome to the world of distributed systems!
In PostgreSQL 14, replication delay times are provided directly using sampled message timings to provide the most accurate viewpoint of current delay times. Use this query:
SELECT pid, application_name /* or other unique key */
,write_lag, flush_lag, replay_lag
FROM pg_stat_replication;
Finally, there is another view called pg_stat_wal_receiver that provides information about the current standby node; this view returns zero rows on the primary and one row on a standby. pg_stat_wal_receiver contains connection information to allow you to connect to the primary server and detailed state information on the WALReceiver process.
There's more…
The pg_stat_replication view shows only the currently connected nodes. If a node is supposed to be connected but it isn't, then there is no record of it at all, anywhere. If you don't have a list of the nodes that are supposed to be connected, then you'll just miss it.
Replication slots give you a way to define which connections are supposed to be present. If you have defined a slot and it is currently connected, then you will get one row in pg_stat_replication for the connection and one row in pg_replication_slots for the corresponding slot; they can be matched via the process identifier (PID) of the receiving process, which is the same. To find out which slots don't have current connections, you can run this query:
SELECT slot_name, database, age(xmin), age(catalog_xmin)
FROM pg_replication_slots
WHERE NOT active;
To find details of currently connected slots, run something like this:
SELECT slot_name
FROM pg_replication_slots
JOIN pg_stat_replication ON pid = active_pid;
Performance and sync rep
Sync rep allows us to offer a confirmation to the user that a transaction has been committed and fully replicated on at least one standby server. To do that, we must wait for the transaction changes to be sent to at least one standby, and then have that feedback returned to the primary.
The additional time taken for the message's round trip will add elapsed time for the commit of write transactions, which increases in proportion to the distance between servers. PostgreSQL offers a choice to the user as to what balance they would like between durability and response time.
Getting ready
The user application must be connected to a primary to issue transactions that write data. The default level of durability is defined by the synchronous_commit parameter. That parameter is user-settable, so it can be set for different applications, sessions, or even individual transactions. For now, ensure that the user application is using this level:
SET synchronous_commit = on;
We must decide which standbys should take over from the primary in the event of a failover. We do this by setting a parameter called synchronous_standby_names.
Note
You will need to configure at least three nodes to use sync rep correctly. This is the short story, which you probably know already. For completeness, let's explain the full story, which is slightly more nuanced.
When enabling sync rep as in the preceding example, you are requesting that a transaction is considered committed only if it is stored at least on two different nodes, so you have the guarantee that each transaction is safe even if one node suddenly fails.
Based on your request, if you only have two nodes A and B, and (say) node B is down, then you cannot commit that transaction. This is not a limitation of the software, but simply the logical consequence of your request: you only have node A left, so there is no way to place a transaction on two different nodes.
So, either (1) you wait until you have two nodes or (2) you accept the (tiny) risk of losing the transaction after commit, should node A fail. Most people prefer (2) over (1), and if they do not like (1) or (2), then they choose (3) to spend a bit more money and add a third node, C.
How to do it...
Make sure that you have set the application_name parameter on each standby node. Decide the order of servers to be listed in the synchronous_standby_names parameter. Note that the standbys named must be directly attached standby nodes, or else their names will be ignored. Sync rep is not possible for cascaded nodes, though cascaded standbys may be connected downstream. An example of a simple four-node configuration of nodeA (primary), nodeB, nodeC, and nodeD (standbys) would be set on nodeA, as follows:
synchronous_standby_names = 'nodeB, nodeC, nodeD'
If you want to receive replies from the first two nodes in a list, then we would specify this using the following special syntax:
synchronous_standby_names = '2 (nodeB, nodeC, nodeD)'
If you want to receive replies from any two nodes, known as quorum commit, then use the following syntax:
synchronous_standby_names = 'any 2 (nodeB, nodeC, nodeD)'
Set synchronous_standby_names on all of the nodes, not just the primary.
You can see the sync_state value of connected standbys by using this query on the primary:
SELECT
application_name
,state /* startup, backup, catchup or streaming */
,sync_priority /* 0, 1 or more */
,sync_state /* async, sync or potential */
FROM pg_stat_replication
ORDER BY sync_priority;
There are a few columns here with similar names, so be careful not to confuse them.
The sync_state column is just a human-readable form of sync_priority. When sync_state is async, the sync_priority value will be zero (0). Standby nodes that are mentioned in the synchronous_standby_names parameter will have a nonzero priority that corresponds to the order in which they are listed. The standby node with a priority of one (1) will be listed as having a sync_state value of sync. We refer to this node as the sync standby. Other standby nodes configured to provide feedback are shown with a sync_state value of potential and a sync_priority value of more than 1.
If a server is listed in the synchronous_standby_names parameter but is not currently connected, then it will not be shown at all by the preceding query, so it is possible that the node is shown with a lower actual priority value than the stated ordering in the parameter. Setting wal_receiver_status_interval to 0 on the standby will disable status messages completely, and the node will show as an async node, even if it is named in the synchronous_standby_names parameter. You may wish to do this when you are completely certain that a standby will never need to be a failover target, such as a test server.
The state for each server is shown as one of startup, catchup, or streaming. When another node connects, it will first show as startup, though only briefly before it moves to catchup. Once the node has caught up with the primary, it will move to streaming, and only then will sync_priority be set to a nonzero value.
Catch-up typically occurs quickly after a disconnection or reconnection, such as when a standby node is restarted. When performing an initial base backup, the server will show as backup. After this, it will stay for an extended period at catchup. The delay at this point will vary according to the size of the database, so it could be a long period. Bear this in mind when configuring the sync rep.
When a new standby node moves to the streaming mode, you'll see a message like this in the primary node log:
LOG standby $APPLICATION_NAME is now the synchronous
standby with priority N
How it works…
Standby servers send feedback messages that describe the LSN of the latest transaction they have processed. Transactions committed on the primary will wait until they receive feedback saying that their transaction has been processed. If there are no standbys available for sending feedback, then the transactions on the primary will wait for standbys, possibly for a very long time. That is why we say that you must have at least three servers to sensibly use sync rep. It has probably occurred to you that you could run with just two servers. You can, but such a configuration does not offer any transaction guarantees; it just appears to. Many people are confused on that point, but please don't listen to them!
Sync rep increases the elapsed time of write transactions (on the primary). This can reduce the performance of applications from a user perspective. The server itself will spend more time waiting than before, which may increase the required number of concurrently active sessions.
Remember that when using sync rep, the overall system is still eventually consistent. Transactions committing on the primary are visible first on the standby, and a brief moment later, those changes will be visible on the primary (yes—standby, and then primary). This means that an application that issues a write transaction on the primary followed by a read transaction on the sync standby will be guaranteed to see its own changes.
You can increase performance somewhat by setting the synchronous_commit parameter to remote_write, though you will lose data if both the primary and standby crash. You can also set the synchronous_commit parameter to remote_apply when you want to ensure that all changes are committed to the synchronous standbys and the primary before we confirm back to the user. However, this is not the same thing as synchronous visibility—the changes become visible on the different standbys at different times.
There's more…
There is a small window of uncertainty for any transaction that is in progress just at the point at which the primary goes down. This can be handled within the application by checking the return code following a commit operation, rather than just assuming that it has completed successfully, as developers often do.
If the commit fails, it is possible that the server committed the transaction successfully but was unable to communicate that to the client; however, we don't know for certain. Postgres-BDR resolves this problem, but unfortunately, PostgreSQL does not yet do that. A workaround to resolve that uncertainty is to recheck a unique aspect of the transaction, such as reconfirming the existence of a user ID that was inserted.
If no such object ID exists, we can create a table for this purpose:
CREATE TABLE TransactionCheck
(TxnId SERIAL PRIMARY KEY);
During the transaction, we insert a row into that table using this query:
INSERT INTO TransactionCheck DEFAULT VALUES RETURNING TxnId;
Then, if the commit appears to fail, we can later reread this value to confirm the transaction state as committed or aborted.
Sync rep works irrespective of whether you set up replication with or without repmgr, as long as you have the right number of standby nodes. It is enabled by setting the appropriate parameters in PostgreSQL, so nothing needs to be done in the configuration file of repmgr.
Delaying, pausing, and synchronizing replication
Some advanced features and thoughts for replication are covered here.
Getting ready
If you have multiple standby servers, you may want to have one or more servers operating in a delayed apply state—for example, 1 hour behind the primary. This can be useful to help recover from user errors such as mistaken transactions or dropped tables without having to perform a PITR.
How to do it…
Normally, a standby will apply changes as soon as possible. When you set the recovery_min_apply_delay parameter in recovery.conf, the application of commit records will be delayed by the specified duration. Note that only commit records are delayed, so you may receive Hot Standby cancelations when using this feature. You can prevent that in the usual way by setting hot_standby_feedback to on, but use this with caution since it can cause significant bloat on a busy primary if recovery_min_apply_delay is large.
If something bad happens, then you can hit the Pause button, meaning that Hot Standby provides controls for pausing and resuming the replay of changes. Precisely, do the following:
- To pause replay, issue this query:
SELECT pg_wal_replay_pause();
Once replay is paused, all queries will receive the same snapshot, which facilitates lengthy repeated analysis of the database, or retrieval of a dropped table.
- To resume (un-pause) processing, use this query:
SELECT pg_wal_replay_resume();
Be careful not to promote a delayed standby. If you have to, because your delayed standby is the last server available, then you should reset recovery_min_apply_delay, restart the server, and let it catch up before you issue a promote action.
There's more…
A standby is an exact copy of the primary. But how do you synchronize things so that the query results you get from a standby are guaranteed to be the same as those you'd get from the primary? Well, that in itself is not possible. It's just the physics of an eventually consistent system. On the one hand, we need our system to be eventually consistent because otherwise, the synchronization would become a performance bottleneck. And even if we ignored that concern, total consistency would still be impossible because the application cannot guarantee that two different servers are queried at exactly the same time.
What we can reasonably do is to synchronize two requests on different servers, meaning that we enforce their ordering—for example, we can issue a write on the primary and then issue a read from a standby in a way that is guaranteed to happen after the write. Such a case can be automatically handled by sync rep, but if we aren't using this feature, then we can achieve a similar behavior by waiting for the standby to catch up with a specific action on the primary (the write). To perform the wait, you need to do the following:
- On the primary, perform a transaction that writes WAL—for example, create a table or insert a row in an existing table. Make sure you do that with any setting other than synchronous_commit = off.
- On the primary, find the current write LSN using this query:
SELECT pg_current_wal_write_lsn();
- On the standby, execute the following query repeatedly, until the LSN value returned is equal to or higher than the LSN value you read from the primary in the previous step:
SELECT pg_last_wal_replay_lsn();
- At this point, you know that your transaction has been fully replayed, so you can query the standby and see the effects of the transaction that you performed on the primary.
The following function implements the activity of waiting until we pass a given LSN:
CREATE OR REPLACE FUNCTION wait_for_lsn(lsn pg_lsn)
RETURNS VOID
LANGUAGE plpgsql
AS $$
BEGIN
LOOP
IF pg_last_wal_replay_lsn() IS NULL OR
pg_last_wal_replay_lsn() >= lsn THEN
RETURN;
END IF;
PERFORM pg_sleep(0.1); /* 100ms */
END LOOP;
END $$;
Note that this function isn't ideal since it could be interrupted while waiting due to a Hot Standby conflict. Later releases may contain better solutions.
See also
It is also possible to pause and resume logical replication, except that we use the slightly different terms of disable and enable, as shown in the following example:
ALTER SUBSCRIPTION mysub DISABLE;
ALTER SUBSCRIPTION mysub ENABLE;
Logical replication
Logical replication allows us to stream logical data changes between two nodes. By logical, we mean streaming changes to data without referring to specific physical attributes such as a block number or row ID.
These are the main benefits of logical replication:
- Performance is roughly two times better than that of the best trigger-based mechanisms.
- Selective replication is supported, so we don't need to replicate the entire database.
- Replication can occur between different major releases, which can allow a zero-downtime upgrade.
PostgreSQL provides a feature called logical decoding, which can be used to stream a set of changes out of a primary server. This allows a primary to become a sending node in logical replication. The receiving node uses a logical replication process to receive and apply those changes, thereby implementing replication between those two nodes.
So far, we have referred to physical replication simply as streaming replication. Now that we have introduced another kind of streaming replication, we have to extend our descriptions and refer either to PSR (physical) or to LSR (logical) when discussing streaming replication. In terms of security, network data transfer, and general management, the two modes are very similar. Many concepts that are used to monitor PSR can also be used to monitor LSR.
When using logical replication, the target systems are fully writable primary nodes in their own right, meaning that we can use the full power of PostgreSQL without restrictions. We can use temporary tables, triggers, different user accounts, and GRANT permissions differently. We can also define indexes differently, collect statistics differently, and run VACUUM on different schedules.
LSR works on a publish/subscribe (pub/sub) model, meaning that the sending node publishes changes, and the receiving node receives the changes that it has subscribed to. Because of this, we use the terms publisher and subscriber to denote, respectively, the sending and receiving nodes.
LSR works on a per-database level, not a whole-server level like PSR, because logical decoding uses the catalog to decode transactions, and the catalog is mostly implemented at the database level. One publishing node can feed multiple subscriber nodes without incurring additional disk write overhead.
Getting ready
Logical replication was introduced in PostgreSQL 10, so it is available on all currently supported PostgreSQL versions.
The procedure goes like this:
- Identify all nodes that will work together as parts of your replication architecture; for instance, suppose that we want to replicate from node1 to node2.
- Each LSR link can replicate changes from a single database, so you need to decide which database(s) you want to replicate. Note that you will need one LSR link for each database that you want to replicate.
- Each LSR link will use one connection and one slot: ensure that the max_replication_slots and max_connections parameters match those requirements.
- Likewise, each LSR link requires one WAL sender on the publisher: ensure that max_wal_senders matches this requirement.
- Also, each LSR link requires one apply process on the subscriber: ensure that max_worker_processes matches this requirement.
How to do it…
The following steps have to be repeated once for each replicated database. In these queries, we have used mypgdb as the database name, but you obviously need to replace it with the real name of that databas:.
- Dump the database schema from the published database and reload it in the subscriber database:
pg_dump --schema-only -o schema.sql -h node1 mypgdb
psql -1 -f schema.sql -h node2 mypgdb
- Publish the changes from all tables with the following statement:
CREATE PUBLICATION pub_node1_mypgdb_all
FOR ALL TABLES;
- Subscribe to the changes from all tables with the following statement:
CREATE SUBSCRIPTION sub_node1_mypgdb_all
CONNECTION 'host=node1 dbname=mypgdb'
PUBLICATION pub_node1_mypgdb_all;
Logical replication supports selective replication, which means that you don't need to specify all the tables in the database. You just need to identify the tables to be replicated, and then define publications that correspond to groups of tables that should be replicated together.
The tables that will be replicated may need some preparatory steps as well. To enable logical replication to apply UPDATE and DELETE commands correctly on the target node, we need to define how PostgreSQL can identify rows. This is known as replica identity. A primary key (PK) is a valid replica identity, so you need not take any action if you have already defined PKs on all your replicated tables. If you want to replicate tables that do not have a PK, it is worth pausing and reviewing them. With this, we mean that you should consider whether those tables have a PK or should be given one. For example, if a table has a column called customer_id that is unique and not null, and that will be updated rarely or never, then it is a valid PK, even if it is not marked as such; so, you can make it an official PK.
If you have carried out that review and you still have some tables without a PK that you want to replicate, then you may need to define a replica identity explicitly by using a command like this:
ALTER TABLE mytable REPLICA IDENTITY USING INDEX myuniquecol_idx;
This means that PostgreSQL will use that index (and the columns it covers) to uniquely identify rows to be deleted or updated.
Tables in a subscriber node must have the same name as in the publisher node and be in the same schema. Tables on the subscriber must also have columns with the same name as the publisher and with compatible data types, to be able to apply incoming changes. Tables must have the same PRIMARY KEY constraint on both nodes. CHECK, NOT NULL, and UNIQUE constraints must be the same or weaker (more permissive) on the subscriber.
Logical replication also supports filtering replication, which means that only certain actions are replicated on the target node; for example, we can specify that INSERT commands are replicated while DELETE commands are filtered away.
How it works…
Logical decoding is very efficient because it reuses the transaction log data (WAL) that was already being written for crash safety. Triggers are not used at all for this form of replication. Physical WAL records are translated into logical changes that are then sent to the receiving node. Only real data changes are sent; no records are generated from changes to indexes, cleanup records from VACUUM, and so on. So, bandwidth requirements are usually reduced, depending on the exact application workload and database setup.
Changes are discarded if the top-level transaction aborts (savepoints and other subtransactions are supported normally). Changes are applied in the order of the transactions that have been committed, meaning that logical replication never breaks because of an inconsistent sequence of activities, which could instead occur with other cruder replication techniques such as statement-based replication.
On the receiving side, changes are applied using direct database calls, leading to a very efficient mechanism. SQL is not re-executed, so volatile functions in the original SQL don't produce any surprises. For example, let's say you make an update like this:
UPDATE table
SET
col1 = col1 + random()
,col2 = col2 + random()
WHERE key = value
Logical replication will send the final calculated values of col1 and col2, instead of repeating the execution of the functions (and getting different values) when we apply the changes.
PostgreSQL has a mechanism to specify whether triggers should fire or not depending on whether the changes are coming from a client session or via replication, with the default being to fire triggers only for client sessions.
This means that you can define BEFORE ROW triggers that block or filter rows as you wish, with a suitable configuration. For more information, check the documentation for the following:
- The session_replication_role parameter
- The ALTER TABLE ... ENABLE REPLICA TRIGGER syntax
Logical replication will work even if you update one or more columns of the key (or any other replica identity) since it will detect that situation and send the old values of the columns with the changed row values. A statement that writes many rows results in a stream of single-row changes.
Locks taken at table level (LOCK) or row level (SELECT ... FOR...) are not replicated, nor are SET or NOTIFY commands.
Logical replication doesn't suffer from cancellations of queries on the apply node in the way Hot Standby does. There isn't any need for a feature such as hot_standby_feedback.
Both the publishing and subscribing nodes are primary nodes, so technically, it would be possible for writes (INSERT, UPDATE, and DELETE) and/or row-level locks (SELECT ... FOR...) to be issued on the subscriber database. As a result, it is possible that local changes could lock out, slow down, or interfere with the application of changes from the source node. It is up to the user to enforce restrictions to ensure that this does not occur. You can do this by having a user role defined specifically for replication, and then using REVOKE on all access apart from the SELECT privilege to replicated tables, rather than the user role applying the changes.
Data can be read on the apply side while changes are being made. That is just normal, and it's the beautiful power of PostgreSQL's MVCC feature.
The use of replication slots means that if the network drops for some time or if one of the nodes is temporarily offline, replication will automatically pick up again from the precise point at which it stopped.
There's more…
LSR can work alongside PSR in the sense that the same node can have PSR standbys and LSR subscribers at the same time. There are no conflicting parameters; just ensure that all requirements are met for both PSR and LSR.
Logical replication provides cascaded replication.
With LSR and pglogical, neither DDL nor sequences are replicated; only data changes (data manipulation language, or DML) are sent, including TRUNCATE commands.
Logical replication is one-way only, so if you want multi-master replication, see Postgres-BDR, which is described in the BDR recipe. Also, this is currently the only logical replication software that can replicate DDL.
Subscriptions use normal user access security, so there is no need to enable replication via pg_hba.conf.
It is also possible to override the synchronous_commit parameter and demand that the server provides sync rep.
BDR
BDR (Postgres-BDR) is a project aiming to provide multi-master replication with PostgreSQL. There is a range of possible architectures. The first use case we support is all-nodes-to-all-nodes. Postgres-BDR will eventually support a range of complex architectures, which is discussed later.
With Postgres-BDR, the nodes in a cluster can be distributed physically, allowing worldwide access to data as well as DR. Each Postgres-BDR primary node runs individual transactions; there is no globally distributed transaction manager. Postgres-BDR includes replication of data changes such as DML, as well as DDL changes. New tables are added automatically to replication, ensuring that managing BDR is a low-maintenance overhead for applications.
Postgres-BDR also provides global sequences, if you wish to have a sequence that works across a distributed system where each node can generate new IDs. The usual local sequences are not replicated.
One key advantage of Postgres-BDR is that you can segregate your write workload across multiple nodes by application, user group, or geographical proximity. Each node can be configured differently, yet all work together to provide access to the same data. Some examples of use cases for this are shown here:
- Social media applications, where users need fast access to their local server, yet the whole database needs a single database view to cater for links and interconnections
- Distributed businesses, where orders are taken by phone in one location and by websites in another location, and then fulfilled in several other locations
- Multinational companies that need fast access to data from many locations, yet wish to see and enforce a single, common view of their data
Postgres-BDR builds upon the basic technology of logical replication, enhancing it in various ways. We refer heavily to the previous recipe, Logical replication.
Getting ready
Currently, Postgres-BDR can be deployed in the all-to-all architecture, which has been tested on clusters of up to 99 primary nodes. Each of those nodes is a normal, fully functioning PostgreSQL server that can perform both reads and writes.
Postgres-BDR establishes direct connections between each pair of nodes, forming a mesh of connections. Changes flow directly to other nodes in constant time, no matter how many nodes are in use. This is quite different from circular replication, which is a technique used by other database management systems (DBMSs) to reduce the number of connections at the expense of latency and (somewhat) simplicity.
All Postgres-BDR nodes should have pg_hba.conf definitions to allow connection paths between each node pair. It would be easier to have these settings the same on all nodes, but that is not strictly required.
Each node requires an LSR link to all other nodes for each replicated database. So, an eight-node Postgres-BDR cluster will require seven LSR links per node. Ensure that the settings are configured to allow for this and any possible future expansion. The parameters should be the same on all nodes to avoid confusion. Remember that these changes require a restart.
Postgres-BDR nodes also require configuring of the mechanism for conflict detection:
track_commit_timestamps = on
The current version of Postgres-BDR is 4.0, which was released in 2021 and supports PostgreSQL 12 and later. Earlier versions of PostgreSQL were supported by previous versions of BDR, such as 3.6 and 3.7.
For more information on release compatibility, please visit the compatibility matrix in the documentation at https://www.enterprisedb.com/docs/bdr/latest/.
PostgreSQL-BDR is a proprietary software owned and licensed by EnterpriseDB (EDB).
How to do it…
BDR must be deployed using a tool called TPAexec, based on Ansible and available on the same license terms as BDR, which internally runs the appropriate commands in the right order so that the user doesn't actually need to run those commands directly.
In this section, we go through some examples of those commands, for the purpose of illustrating how the BDR technology works.
New nodes are created in one of the following four ways:
- Using a command-line utility called bdr_init_physical that can convert a physical replica into a BDR node. This utility operates in three modes:
- Using an existing physical replica
- Creating a physical replica from a physical backup
- Creating a physical replica from scratch (bdr_init_physical will take a base backup)
- By running the bdr.join_node_group() function
The time-consuming part is the initial data copy, which in the first case is carried out while the node is still a physical replica, possibly using standard methods such as pg_basebackup, restore from a Barman backup, or simple file copy, while in the second case, it is included in the function run.
The four preceding options for joining a node can be compared in terms of which features they provide—for example, whether the following applied:
- The process can resume without having to restart from scratch if interrupted.
- The data for a single node can be copied using multiple connections in parallel.
- The data for multiple nodes can be copied concurrently.
In the following table, we compare these options:
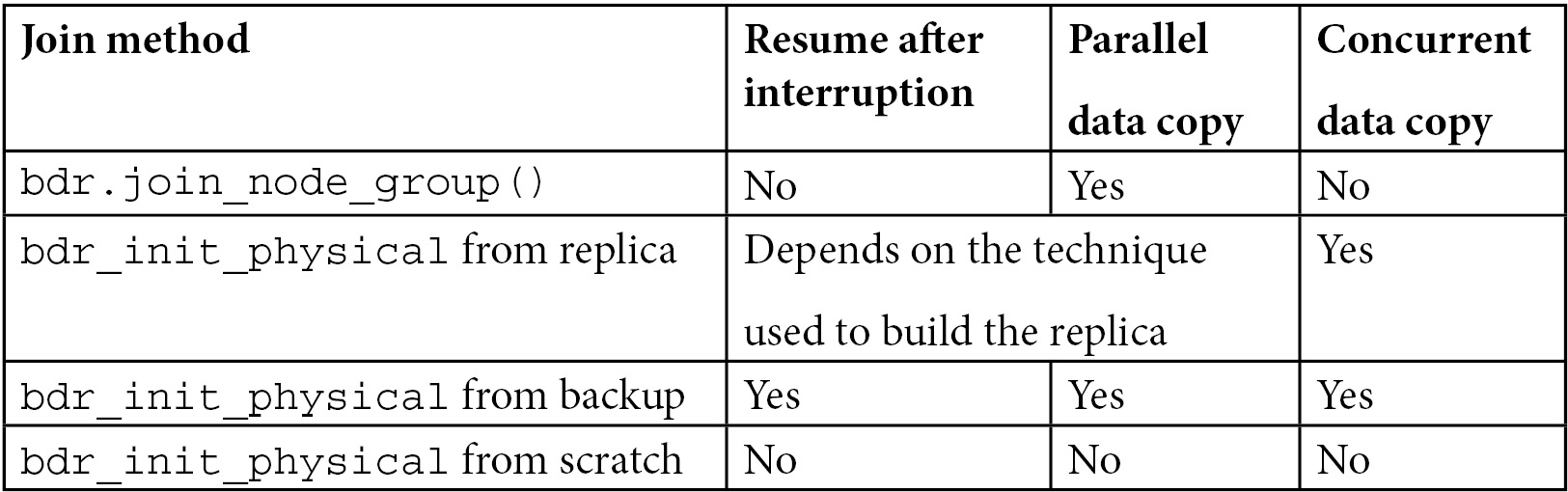
Figure 12.1 – Options available for joining a node
How it works...
Postgres-BDR optimistically assumes that changes on one node do not conflict with changes on other nodes. Any conflicts are detected and then resolved automatically using a predictable last-update-wins strategy, though custom conflict handlers are supported to allow more precise definition for particular applications.
Applications that regularly cause conflicts won't run very well on Postgres-BDR; while conflicts will be resolved automatically as expected, conflicting transactions are generally more expensive than non-conflicting ones, because of the extra effort required to resolve the conflict, and also because two conflicting transactions will result in a single transaction being eventually applied. Such applications would also suffer from lock waits and resource contention on a normal database; the effects will be slightly amplified by the distributed nature of Postgres-BDR, but it is only the existing problems that are amplified. Applications that are properly designed to be scalable and contention-free will work well on Postgres-BDR.
Postgres-BDR replicates changes at the row level, though there is an optional feature available to resolve conflicts at the column level, described later. The default mechanism used by BDR has some implications for applications, as shown here:
- Suppose we perform two simultaneous updates on different nodes, like this:
UPDATE foo SET col1 = col1 + 1 WHERE key = value;
- Then, in the event of a conflict, we will keep only one of the changes (the last change). What we might like in this case is to make the changes additive; Postgres-BDR provides this alternate behavior using dedicated data types called conflict-free replicated data types (CRDT).
- Two updates that change different columns on different nodes will still cause replication conflicts. Postgres-BDR provides an optional feature called column-level conflict resolution, which avoids conflicts altogether in this case.
Postgres-BDR also supports eager replication, meaning any issues are resolved before commit.
Postgres-BDR provides tools to diagnose and correct contention problems. Conflicts are logged to a conflict history table with all the necessary details so that they can be identified ex-post and removed at the application level. This also enables regular auditing of the conflict resolution logic, to allow a declarative verification.
There's more…
If a primary node fails, you can fail over to either logical or physical standby nodes. Other primary nodes continue processing normally—there is no wait for failover, nor is there the need for complex voting algorithms to identify the best new primary. Failed primary nodes that resume operations later will rejoin the cluster without needing any user action.
Archiving transaction log data
PSR can send transaction log data to a remote node, even if the node is not a full PostgreSQL server, so that it can be archived. This can be useful for various purposes, such as the following:
- Restoring a hot physical backup
- Investigating the contents of previous transactions
Getting ready
Normally, backups should be taken regularly on a production system; if you have configured Barman already, as described in the Hot physical backup with Barman recipe of Chapter 11, Backup and Recovery, then you are already archiving transaction logs because they are needed to restore a physical backup, so no further action is needed, and you can skip to the How to do it... section of the current recipe.
PostgreSQL includes two client tools to stream transaction data from the server to the client. The tools are designed using a pull model; that is, you run the tools on the node you wish the data to be saved on:
- pg_receivewal transmits physical transaction log data (WAL files), producing an exact copy of the original WAL files. Replication slots are not required when using this tool but could be useful.
- pg_recvlogical transmits the results of the logical decoding of transaction log data, producing a copy of the transformed data rather than reconstructing physical WAL files. A logical replication slot is required for this tool, created with an appropriate logical decoding plugin. Note that in this case, you must set wal_level to logical.
You can also configure archive_command on the PostgreSQL server; this uses a push model to send complete WAL files to a remote location of your choice.
How to do it…
If you are backing up your PostgreSQL server using Barman, then the WAL is already archived and can be retrieved as follows:
- First, you have to establish the name of the WAL file that you wish to fetch. For instance, you can extract the name of the last WAL file from the metadata for the chosen server:
$ barman show-server db1 | grep current_xlog
current_xlog: 00000001000000000000001B
- Then, you can download that file in the current directory, as follows:
$ barman get-wal -o . -P db1 00000001000000000000001B
Sending WAL '00000001000000000000001B.partial' for server 'db1' into './00000001000000000000001B' file
Note the message from Barman: the current WAL file has a partial suffix, as it is still being added data from new writes. Barman will download a copy that corresponds to the snapshot it has received so far.
- At this point, you can inspect the content of this WAL file:
$ pg_waldump 00000001000000000000001B | tail
pg_waldump: fatal: error in WAL record at 0/1B3221F0: invalid record length at 0/1B322228: wanted 24, got 0
rmgr: Heap len (rec/tot): 98/ 98, tx: 75392, lsn: 0/1B321F80, prev 0/1B321F40, desc: HOT_UPDATE off 104 xmax 75392 flags 0x10 ; new off 105 xmax 0, blkref #0: rel 1663/17055/18358 blk 0
(...)
Note the following:
- The fatal: error message is not something we should worry about; it just means that the last record in the WAL file does not point to a valid WAL record, which is normal considering that this is a copy of the WAL file that is currently being written.
- The pg_waldump executable might not be in the path of the shell you are using; in that case, you will need to write the full path before running it.
Internally, Barman uses either pg_receivewal or archive_command to receive the WAL from the PostgreSQL server, depending on how it was configured. In either case, you can retrieve and inspect WAL files as in the example we just described.
You can run a standalone pg_receivewal process on the archive node, as in this example:
pg_receivewal -D /pgarchive/alpha -d "$MYCONNECTIONSTRING" &
Note, however, that several users choose Barman, which is also capable of restarting pg_receivewal if it crashes and of compressing WAL files when they are stored while returning them uncompressed, as in the preceding example.
Also, you can add the --slot=slotname parameter if you want pg_receivewal to use a replication slot that you had previously created.
There's more...
The pg_recvlogical utility is somewhat different because it prints the contents of the transaction data it receives, rather than just making a copy of the remote WAL file. This utility requires a logical replication slot, and it is able to create one. In this example, we create a new logical slot attached to the mydb database:
$ pg_recvlogical -d mydb --slot=test1 --create-slot
Once a slot exists, we can use it—for example—to display the decoded WAL to stdout:
$ pg_recvlogical -d mydb --slot=test1 --start -f -
BEGIN 75811
table bdr.global_consensus_journal: INSERT: log_index[bigint]:17206 term[bigint]:0 origin[oid]:3643123840 req_id[bigint]:-296718623095749962 req_payload[bytea]:'x00000067d925a880000278c7f519d7e700000000114ee5700003bd9500000000114ee57000040000000d0000000d0000001800000019000000024552b912000000001b36f938000278c7f38d18fb000000006a9290f200000000114e65f0000278c7f50feb3d00000000' trace_context[bytea]:'x736e146a38578a207dbf6e2e01'
COMMIT 75811
(...)
While playing with this feature for the first time, try the --verbose option, which is supported by all the previous tools.
For more details on logical decoding plugins, refer to the Logical replication recipe earlier in this chapter.
Replication monitoring will show pg_receivewal and pg_recvlogical in exactly the same way as it shows other connected nodes, so there is no additional monitoring required. The default application_name parameter is the same as the name of the tool, so you may want to set that parameter to something more meaningful to you.
You can archive WAL files using sync rep by specifying pg_receivewal --synchronous. This causes a disk flush (fsync) on the client so that WAL data is robustly saved to disk. It then passes status information back to the server to acknowledge that the data is safe (regardless of the setting of the -s parameter). There is also a third option, which is faster (and more dangerous)—namely, pg_receivewal –-no-sync.
See also
- The pg_waldump program is an additional server-side utility documented here: https://www.postgresql.org/docs/14/pgwaldump.html
- The pg_receivewal program is documented here: https://www.postgresql.org/docs/14/app-pgreceivewal.html
- The pg_recvlogical program is documented here: https://www.postgresql.org/docs/14/app-pgrecvlogical.html
Upgrading minor releases
Minor release upgrades are released regularly by all software developers, and PostgreSQL has had its share of corrections. When a minor release occurs, we bump the last number, usually by one. So, the first release of a major release such as 14 is 14.0. The first set of bug fixes is 14.1, then 14.2, and so on.
The PostgreSQL community releases new bug fixes quarterly. If you want bug fixes more frequently than that, you will need to subscribe to a PostgreSQL support company. This recipe is about moving from a minor release to a minor release.
Getting ready
First, get hold of the new release, by downloading either the source or fresh binaries.
How to do it…
In most cases, PostgreSQL aims for minor releases to be simple upgrades. We put in great efforts to keep the on-disk format the same for both data/index files and transaction log (WAL) files, but this isn't always the case; some files can change.
The upgrade process goes like this:
- Read the release notes to see whether any special actions need to be taken for this particular release. Make sure that you consider the steps that are required by all extensions that you have installed.
- If you have professional support, talk to your support vendor to see whether additional safety checks over and above the upgrade instructions are required or recommended. Also, verify that the target release is fully supported by your vendor on your hardware, OS, and OS release level; it may not be, yet.
- Apply any special actions or checks; for example, if the WAL format has changed, then you may need to reconfigure log-based replication following the upgrade. You may need to scan tables, rebuild indexes, or perform some other actions. Not every release has such actions, and we try to keep compatibility for minor releases so that they exist only in case they are needed by a bug fix; in any case, watch closely for them because if they exist, then they are important.
- If you are using replication, test the upgrade by disconnecting one of your standby servers from the primary.
- Follow the instructions for your OS distribution and binary packager to complete the upgrade. These can vary considerably.
- Start up the database server being used for this test, apply any post-upgrade special actions, and check that things are working for you.
- Repeat Steps 4 to 6 for other standby servers.
- Repeat Steps 4 to 6 for the primary server.
How it works…
Minor upgrades mostly affect the binary executable files, so it should be a simple matter of replacing those files and restarting, but please check.
There's more…
When you restart the database server, the contents of the buffer cache will be lost. The pg_prewarm module provides a convenient way to load relation data into the PostgreSQL buffer cache.
You can install the pg_prewarm extension that's provided by default, as follows:
postgres=# CREATE EXTENSION pg_prewarm;
CREATE EXTENSION
You can perform pre-warming for any relation:
postgres=# select pg_prewarm('job_status');
pg_prewarm
------------
1
The return value is the number of blocks that have been pre-warmed.
Major upgrades in-place
PostgreSQL provides an additional supplied program, called pg_upgrade, which allows you to migrate between major releases, such as from 9.2 to 9.6, or from 9.6 to 11; alternatively, you can upgrade straight to the latest server version. These upgrades are performed in-place, meaning that we upgrade our database without moving to a new system. That does sound good, but pg_upgrade has a few things that you may wish to consider as potential negatives, which are outlined here:
- The database server must be shut down while the upgrade takes place.
- Your system must be large enough to hold two copies of the database server: old and new copies. If it's not, then you have to use the link option of pg_upgrade, or use the Major upgrades online recipe, coming next in this chapter. If you use the link option on pg_upgrade, then there is no pg_downgrade utility. The only option in that case is a restore from backup, and that means extended unavailability while you restore.
- If you copy the database, then the upgrade time will be proportional to the size of the database.
- The pg_upgrade utility does not validate all your additional add-in modules, so you will need to set up a test server and confirm that these work, ahead of performing the main upgrade.
The pg_upgrade utility supports versions from PostgreSQL 8.4 onward and allows you to go straight from your current release to the latest release in one hop.
Getting ready
Find out the size of your database (using the How much disk space does a database use? recipe in Chapter 2, Exploring the Database). If the database is large or you have an important requirement for availability, you should consider making the major upgrade using replication tools as well. Then, check out the next recipe.
How to do it…
- Read the release notes for the new server version to which you are migrating, including all of the intervening releases. Pay attention to the incompatibilities section carefully; PostgreSQL changes from release to release. Assume this will take some hours.
- Set up a test server with the old software release on it. Restore one of your backups on it. Upgrade that system to the new release to verify that there are no conflicts from software dependencies. Test your application. Make sure that you identify and test each add-in PostgreSQL module you were using to confirm that it still works at the new release level.
- Back up your production server. Prepare for the worst but hope for the best!
- Most importantly, work out who you will call if things go badly, and exactly how to restore from that backup you just took.
- Install new versions of all the required software on the production server and create a new database server.
- Don't disable security during the upgrade. Your security team will do backflips if they hear about this. Keep your job!
- Now, go and do that backup. Don't skip this step; it isn't optional. Check whether the backup is actually readable, accessible, and complete.
- Shut down the database servers.
- Run pg_upgrade -v and then run any required post-upgrade scripts. Make sure that you check whether any were required.
- Start up the new database server and immediately run a server-wide ANALYZE operation using vacuumdb -analyze-in-stages.
- Run through your tests to check whether they worked or if you need to start performing a contingency plan.
- If all is OK, re-enable wide access to the database server. Restart the applications.
- Don't delete your old server directory if you used the link method. The old data directory still contains the data for the new database server. It's confusing! So, don't get caught out by this.
How it works…
The pg_upgrade utility works by creating a new set of database catalog tables and then recreating the old objects in the new tables using the same IDs as before.
The pg_upgrade utility works easily because the data block format hasn't changed between some releases. Since we can't (always) see the future, make sure you read the release notes.
Major upgrades online
Upgrading between major releases is hard, and should be deferred until you have some good reasons and sufficient time to get it right.
You can use replication tools to minimize the downtime required for an upgrade, so we refer to this recipe as an online upgrade.
How to do it…
The following general steps should be followed, allowing at least a month for the complete process to ensure that everything is tested and everybody understands the implications:
- Set up a new release of the software on a new test system.
- Take a standalone backup from the main system and copy it to the test system.
- Test the applications extensively against the new release on the test system.
When everything works and performs correctly, then proceed to the next step.
- Set up a connection pooler to the main database (it may be there already).
- Set up logical replication for all tables from the old to new database servers, as described in the Logical replication recipe earlier in this chapter.
- Make sure that you wait until all the initial copy tasks have completed for all tables.
At this point, you have a copy of the data that you can use for testing with the next steps.
- Stop replication.
- Retest the application extensively against the new release on live data.
You might have to repeat Steps 5 to 8 more than once in case you require a new copy of the data; for example, if you want to repeat a test multiple times that affects the contents, or you simply want to test against more recent data.
Then, when you are ready for the final cutover, we can proceed to the next steps.
- Perform Steps 5 and 6 again, in order to create a new replica of the production data.
- Pause the connection pool.
- Switch the configuration of the pool over to the new system and then reload.
- Resume the connection pool (so that it now accesses a new server).
The actual downtime for the application is the length of time to execute these last three steps.
How it works...
The preceding recipe allows online upgrades with zero data loss because of the use of the clean switchover process. There's no need for lengthy downtime during the upgrade, and there's a much-reduced risk in comparison with an in-place upgrade, thanks to the ability to carry out extensive testing with less time pressure. It works best with new hardware and is a good way to upgrade the hardware or change the disk layout at the same time.
This procedure is also very useful for those cases where binary compatibility is not possible, such as changing server encoding or migrating the database to a different OS or architecture, where the on-disk format will change as a result of low-level differences, such as endianness and alignment.