
CHAPTER 17
![]()
Spring Integration and Spring Batch
Today's applications can be described in terms of the frameworks they use—web applications use web frameworks, service tiers use remoting and persistence frameworks (such as ORMs and Spring's remoting hierarchy), messaging applications use messaging frameworks, and so on. Often, however, there is another type of application that sits in all these layers and handles bulk operations—operations that deal with large amounts of data, such as data loading, exporting, synchronizing. Bulk processing, or batch processing, is a common requirement for most applications, both in the initial setup and the ongoing maintenance. The only thing most batch processing applications have in common, however, is the manipulation of large amounts of data; how they get the data, where it's written, and what must be done to adapt it all tend to be unique. Spring Batch provides a very flexible, expressive way to deal with large amounts of data.
This chapter will review the Spring Batch project and how it can be used with Spring Integration. Spring Integration has the ability to launch Spring Batch jobs via messaging, allowing for event-driven batch processes. In addition, Spring Integration can be used to scale out Spring Batch using partitioning. This provides the ability to partition big batch jobs over many nodes using message channels as the coordination fabric. Finally, this chapter will discuss Spring Batch Admin, which provides a web-based user interface for Spring Batch leveraging Spring Integration.
What Is Spring Batch?
Batch processing has been around for decades. The earliest widespread technology for managing information was batch processing. The environments at this time did not have interactive sessions, and usually did not have the capability to load multiple applications in memory. Computers were expensive and bore no resemblance to today's servers. Typically, machines were multiuser and in use during the day (time-shared). During the evenings however, the machines would sit idle, which was a tremendous waste. Businesses invested in ways to utilize the offline time to do work aggregated through the course of the day. Out of this practice emerged batch processing.
Batch processing solutions typically run offline, indifferent to events in the system. In the past, batch processes ran offline out of necessity. Today, however, some batch processes are run offline because having work done at a predictable time, and having large chunks of work done at once are requirements for a number of architectures. A batch processing solution does not usually respond to requests, although there is no reason it could not be started as a consequence of messages or requests. Batch processing solutions tend to be used on large datasets where the duration of the processingis a critical factor fortheir architecture and implementation. A process might run for minutes, hours, or days. Jobs may have unbounded durations (i.e., they run until all work is finished, even if this means running for a few days), or they may be strictly bounded (jobs must proceed in time, with each row taking the same amount of time regardless of bounds, which lets you predict that a given job will finish in a certain time frame.)
Mainframe applications used batch processing, and one of the largest modern-day environments for batch processing, Customer Information Control System (CICS) on z/OS, is still fundamentally a mainframe operating system. CICSis very well suited to a particular type of task: taking input, processing it, and writing it to output. CICS is a transaction server (used most in financial institutions and government) that runs programs in a number of languages (COBOL, C, PLI, etc.). It can easily support thousands of transactions per second. Having debuted in 1969, CICS was one of the first containers, which is a concept still familiar to Spring Framework and Java EE users. A CICS installation is very expensive, and IBM still sells and installs CICS.
Many other solutions have come along since then, of course. These solutions are usually specific to a particular environment: COBOL/CICS on mainframes, C on Unix, and, today, Java on any number of environments. The problem is that there is very little standardized infrastructure for dealing with these types of batch processing solutions. Very few people are even aware of what they are missing, because there is very little native support on the Java platform for batch processing. Businesses that need a solution typically end up writing it in-house, resulting in fragile, domain-specific code.
The pieces are there, however: transaction support, fast I/O, schedulers such as Quartz, Spring 3.0's scheduling abstraction and solid threading support, and the powerful concept of an application container in Java EE and Spring. It was only natural that Dave Syer and his team would come along and build Spring Batch, a batch processing solution for the Spring platform, to fill in the gaps left by these many pieces to provide a comprehensive, consistent batch processing framework.
A typical Spring Batch application typically reads in a large amount of data and then writes it back out in a modified form. Decisions about transactional barriers, input size, concurrency, and the order of steps in processing are all dimensions of a typical integration. Spring Batch is a flexible but not all-encompassing solution. Just as Spring does not reinvent the wheel when it can be avoided, Spring Batch leaves a few important pieces to the discretion of the implementer. Case in point: Spring Batch provides a generic mechanism by which to launch a job, be it by the command line, a Unix cron, an operating system service, Quartz, or in response to an event on a messaging bus. Another example is the way Spring Batch manages the state of batch processes. Spring Batch requires a durable store. The only useful implementation of an org.springframework.batch.core.repository.JobRepository (an interface provided by Spring Batch for storing runtime data) requires a database because a database is transactional and there is no need to reinvent it. The database required, however, is largely unspecified, although there are useful defaults provided.
A common pattern is loading data from a comma-separated value (CSV) file, perhaps as a business-to-business (B2B) transaction, or as an integration with an older legacy application. Another common application is nontrivial processing on records in a database. Perhaps the output is an update of the database record itself. An example might be resizing of images on the file system whose metadata is stored in a database, or needing to trigger another process based on some condition.
Fixed-width data, which is often used with legacy or embedded systems, is a fine candidate for batch processing. Processing that deals with a resource that's fundamentally nontransactional (e.g., a web service or a file) begs for batch processing, because batch processing provides retry/skip/fail functionality, and most web services don't.
Spring Batch provides the same POJO-based and dependency injection approach as the core Spring Framework. Spring Batch also provides a reusable infrastructure to help build batch jobs to deal with large volumes of data. In general, a Spring Batch job can be separated into three components: Application, Spring Batch Core, and Spring Batch Infrastructure, as illustrated in Figure 17–1.
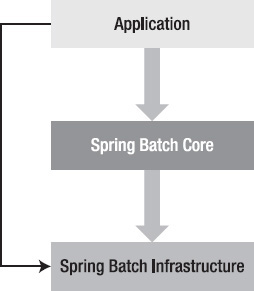
Figure 17–1. Spring Batch architecture
Spring Batch works with a JobRepository, which is the keeper of all the knowledge and metadata for each job (including component parts such as org.springframework.batch.core.JobInstance, org.springframework.batch.core.JobExecution, and org.springframework.batch.core.StepExecution). Each job is composed of one or more steps, one after another. With Spring Batch 2.0, a step can conditionally follow another step, allowing for primitive workflows. These steps can also be concurrent: two steps can run at the same time.
When a job is run, it is often coupled with org.springframework.batch.core.JobParameter to parameterize the behavior of the job. For example, a job might take a date parameter to determine which records to process. This coupling is called a JobInstance. A JobInstance is unique because of the JobParameter associated with it. Each time the JobInstance (i.e., the same job and JobParameter) is run, it is called a JobExecution. This is a runtime context for a version of the job. Ideally, for every JobInstance there would be only one JobExecution: the JobExecution that was created the first time the JobInstance ran. However, if there are any errors, the JobInstance should be restarted; the subsequent run would create another JobExecution. For every step in thejob, there is a StepExecution in the JobExecution.
<batch:job id="importData">
<batch:step id="step1"/>
</batch:job>
Thus, Spring Batch has a mirrored object graph, with one graph reflecting the design/build-time view of a job, and another reflecting the runtime view of a job. This split between the prototype and the instance is very similar to the way many workflow engines—including Activiti—work.
For example, suppose that a daily report is generated at 2 a.m. The parameter to the job would be the date (most likely the previous day's date). The job, in this case, would model a loading step, a summary step, and an output step. Each day the job is run, a new JobInstance and JobExecution would be created. If there are any retries of the same JobInstance, conceivably many JobExecutions would be created.
Setting Up Spring Batch
Spring Batch provides a lot of flexibility and guarantees to the application, but it cannot work in a vacuum—it needs to store data and job state somewhere to keep its guarantees. Add the following dependencies in Listing 17–1 to the Maven configuration file to support Spring Batch and the PostgreSQL database connection.
Listing 17–1. Spring Batch Maven Dependency
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
<version>2.1.6.RELEASE</version>
</dependency>
<dependency>
<groupId>postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>9.0-801.jdbc4</version>
</dependency>
To do its work, the JobRepository requires a database. For all the examples, PostgreSQL will be used as the database. PostgreSQL is easy to install and available for most operating systems at http://www.postgresql.org/download. Spring Batch requires a schema to be set up to properly maintain state. The simplest way to get that schema is to simply download the spring-batch-2.1.6.RELEASE-no-dependencies.zip and look in the directory at spring-batch-2.1.6.RELEASE/dist/org/springframework/batch/core. Within the directory, there are a number of.sql files, each containing the data definition language (DDL) for the required schema for the different kind of databases. PostgreSQL uses the DDL schema-postgresql.sql. The Java configuration required to support connecting to the PostgreSQL database is shown in Listing 17–2.
Listing 17–2. Java Configuration for the PostgreSQL Database
package com.apress.prospringintegration.springbatch.integration;
import org.apache.commons.dbcp.BasicDataSource;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class JdbcConfiguration {
@Value("${dataSource.driverClassName}")
private String driverClassName;
@Value("${dataSource.url}")
private String url;
@Value("${dataSource.username}")
private String username;
@Value("${dataSource.password}") private String password;
@Bean(destroyMethod = "close")
public BasicDataSource dataSource() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName(driverClassName);
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
return dataSource;
}
}
Additionally, there are several collaborators required for Spring Batch to do its work. This configuration is mostly boilerplate.The JobRepository interface is the first thing that the application has to deal with when setting up a Spring Batch process.Again, there is only one really useful implementation of the JobRepository interface: org.springframework.batch.core.repository.support.SimpleJobRepository. This stores information about the state of the batch processes in a database. Creation is done through an org.springframework.batch.core.repository.support.JobRepositoryFactoryBean. Another standard factory, org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean, is useful mainly for testing because its state is not durable—it is an in-memory implementation. Both factories create an instance of SimpleJobRepository. The Java configuration for the basic Spring Batch configuration is shown in Listing 17–3.
Listing 17–3. Java Configuration with Spring Batch
package com.apress.prospringintegration.springbatch.integration;
import org.apache.commons.dbcp.BasicDataSource;
import org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor;
import org.springframework.batch.core.configuration.support.MapJobRegistry;
import org.springframework.batch.core.launch.support.SimpleJobLauncher;
import org.springframework.batch.core.repository.support.JobRepositoryFactoryBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
@Configuration
public class BatchConfiguration {
@Value("#{dataSource}")
private DataSource dataSource;
@Bean
public DataSourceTransactionManager transactionManager(){
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager();
transactionManager.setDataSource(dataSource);
return transactionManager;
}
@Bean
public MapJobRegistry jobRegistry() {
MapJobRegistry jobRegistry = new MapJobRegistry();
return jobRegistry;
}
@Bean
public SimpleJobLauncher jobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository().getJobRepository());
return jobLauncher;
}
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor() {
JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor =
new JobRegistryBeanPostProcessor();
jobRegistryBeanPostProcessor.setJobRegistry(jobRegistry());
return jobRegistryBeanPostProcessor;
}
@Bean
public JobRepositoryFactoryBean jobRepository() {
JobRepositoryFactoryBean jobRepository = new JobRepositoryFactoryBean();
jobRepository.setDataSource(dataSource);
jobRepository.setTransactionManager(transactionManager());
return jobRepository;
}
}
Because the implementation uses a database to persist the metadata, take care to configure a javax.sql.DataSource,as well as the org.springframework.transaction.PlatformTransactionManager implementation org.springframework.jdbc.datasource.DataSourceTransactionManager. In this example, the property-placeholder element, which will be included in the following Spring configuration file, loads the contents of a properties file (batch.properties), whose values are used to configure the data source. The values need to be in place to match the choice of database in this file. The properties file is shown in Listing 17–4.
Listing 17–4. batch.properties DataSource Configuration
dataSource.password=password
dataSource.username=postgres
dataSource.databaseName=postgres
dataSource.driverClassName=org.postgresql.Driver
dataSource.serverName=localhost:5432
dataSource.url=jdbc:postgresql://${dataSource.serverName}/${dataSource.databaseName}
The first few beans are related strictly to configuration—nothing particularly novel or peculiar to Spring Batch: a data source and a transaction manager. Eventually, we get to the declaration of an org.springframework.batch.core.configuration.support.MapJobRegistry instance. This is critical—it is the central store for information regarding a given job, and it controls the big picture about all jobs in the system. Everything else works with this instance.
The org.springframework.batch.core.launch.support.SimpleJobLauncher provides a mechanism to launch batch jobs, where a job in this case is the batch solution. The jobLauncher is used to specify the name of the batch solution to run as well as any parameters required. Next, an org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor instance needs to be defined. This bean scans the Spring context file and associates any configured jobs with the MapJobRegistry.
Finally, the SimpleJobRepository (which is factoried by the org.springframework.batch.core.repository.support.JobRepositoryFactoryBean) implements the interface org.springframework.batch.core.repository.JobRepository.It handles persistence and retrieval for the domain models involving steps, jobs, and so on.
Reading and Writing
The org.springframework.batch.item.ItemReader<T> reads a chunk of data from the source, which could be a CSV file, a database result, or TCP connection. The data is processed by the org.springframework.batch.item.ItemProcessor<I, O>. Finally, the org.springframework.batch.item.ItemWriter<T> writes data to the destination, which could be anything. This process is shown in Figure 17–2.

Figure 17–2. Basic Spring Batch process
Listing 17–5 contains an example of a Spring Batch job. As described earlier in this chapter, a job consists of steps, which are the real workhorses of a given job. The steps can be complex or very simple. Indeed, a stepcan be considered the smallest unit of work for a job. Input (what is read) is passed to the step and potentially processed; then output (what is written) is created from the step. This processing is spelled out using an instance of the org.springframework.batch.core.step.tasklet.Tasklet interface. Developers can provide their own Tasklet implementation or simply use some of the preconfigured configurations for different processing scenarios. These implementations are made available in terms of subelements of the Tasklet element. One of the most important aspects of batch processing is chunk-oriented processing, which is employed here using the chunk element.
Listing 17–5. A Spring Batch Job integration.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:int="http://www.springframework.org/schema/integration"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration-2.0.xsd">
<context:property-placeholder location="batch.properties"/>
<context:component-scan
base-package="com.apress.prospringintegration.springbatch.integration"/>
<batch:job id="importData" job-repository="jobRepository">
<batch:step id="step1">
<batch:tasklet>
<batch:chunk reader="dataReader"
processor="userRegistrationValidationProcessor"
writer="dataWriter"
commit-interval="10"/>
</batch:tasklet>
</batch:step>
</batch:job>
</beans>
In chunk-oriented processing, input is read from a reader, optionally processed (in this example through the userRegistrationValidationProcessor bean), and then aggregated. Finally, at a configurable interval―as specified by the commit-interval attribute to configure how many items will be processed before the transaction is committed―all the input is sent to the writer. If there is a transaction manager in play, the transaction is also committed. Right before a commit, the metadata in the database is updated to mark the progress of the job.
There are some nuances surrounding the aggregation of the input (read) values when a transaction-aware writer (or processor) is rolled back. Spring Batch caches the values it reads and writes them to the writer. If the writer component is transactional, like a database, and the reader is not, there's nothing inherently wrong with caching the read values and perhaps retrying or taking some alternative approach. If the reader itself is also transactional, then the values read from the resource will be rolled back and could conceivably change, rendering the in-memory cached values stale. If this happens, you can configure the chunk to not cache the values by using read is-reader-transactional-queue="true" on the chunk element.
The first responsibility of the Spring Batch job is reading a file from the file system by using a provided implementation for the example. Reading CSV files is a very common scenario, and Spring Batch's support does not disappoint. The org.springframework.batch.item.file.FlatFileItemReader<T> class delegates the task of delimiting fields and records within a file to an org.springframework.batch.item.file.LineMapper<T>, which in turn delegates the task of identifying the fields within that record to an org.springframework.batch.item.file.transform.LineTokenizer. an org.springframework.batch.item.file.transform.DelimitedLineTokenizer can be used to delineate fields separated by a, (comma) character.
The FlatFileItemReader also declares a fieldSetMapper attribute, which requires an implementation of FieldSetMapper. This bean is responsible for taking the input name/value pairs and producing a type that will be given to the writer component.
The Java configurations for the writer and reader are shown in Listing 17–6. In this case, BeanWrapperFieldSetMapper will create a POJO of type UserRegistration. The fields are named so that they can be referenced later in the configuration. These names don't have to be the values of some header row in the input file; they just have to correspond to the order in which the fields are found in the input file. These names are also used by the FieldSetMapper to match properties on a POJO. As each record is read, the values are applied to an instance of a POJO, and that POJO is returned.
Listing 17–6. Spring Batch Reader and Writer
package com.apress.prospringintegration.springbatch.integration;
import com.apress.prospringintegration.springbatch.UserRegistration;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
import org.springframework.core.io.Resource;
import javax.sql.DataSource;
@Configuration
public class JobConfiguration {
@Autowired
private DataSource dataSource;
@Bean
@Scope("step")
public FlatFileItemReader dataReader(
@Value("file:src/main/resources/sample/#{jobParameters['input.file']}.csv")
Resource resource) {
FlatFileItemReader csvFileReader = new FlatFileItemReader();
csvFileReader.setResource(resource);
DelimitedLineTokenizer delimitedLineTokenizer =
new DelimitedLineTokenizer(DelimitedLineTokenizer.DELIMITER_COMMA);
delimitedLineTokenizer.setNames(
new String[]{"firstName", "lastName", "company", "address", "city",
"state", "zip", "county", "url", "phoneNumber", "fax"});
BeanWrapperFieldSetMapper beanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper();
beanWrapperFieldSetMapper.setTargetType(UserRegistration.class);
DefaultLineMapper defaultLineMapper = new DefaultLineMapper();
defaultLineMapper.setLineTokenizer(delimitedLineTokenizer);
defaultLineMapper.setFieldSetMapper(beanWrapperFieldSetMapper);
csvFileReader.setLineMapper(defaultLineMapper);
return csvFileReader;
}
@Bean
public JdbcBatchItemWriter dataWriter() {
JdbcBatchItemWriter jdbcBatchItemWriter = new JdbcBatchItemWriter();
jdbcBatchItemWriter.setAssertUpdates(true);
jdbcBatchItemWriter.setDataSource(dataSource);
jdbcBatchItemWriter
.setSql("insert into USER_REGISTRATION(FIRST_NAME, LAST_NAME, COMPANY," +
"ADDRESS, CITY, STATE, ZIP, COUNTY, URL, PHONE_NUMBER, FAX )" +
"values (:firstName, :lastName, :company, :address, :city ," +
":state, :zip, :county, :url, :phoneNumber, :fax )");
jdbcBatchItemWriter.setItemSqlParameterSourceProvider(
new BeanPropertyItemSqlParameterSourceProvider());
return jdbcBatchItemWriter;
}
}
The object UserRegistration in Listing 17–7 is just a POJO.
Listing 17–7. UserRegistration Domain Object
package com.apress.prospringintegration.springbatch;
import org.apache.commons.lang.builder.EqualsBuilder;
import org.apache.commons.lang.builder.HashCodeBuilder;
import org.apache.commons.lang.builder.ToStringBuilder;
import java.io.Serializable;
public class UserRegistration implements Serializable {
private static final long serialVersionUID = 1L;
public UserRegistration() {
}
public UserRegistration(String firstName, String lastName, String company,
String address, String city, String state, String zip,
String county, String url, String phoneNumber, String fax) {
super();
this.firstName = firstName;
this.lastName = lastName;
this.company = company;
this.address = address;
this.city = city;
this.state = state;
this.zip = zip;
this.county = county;
this.url = url;
this.phoneNumber = phoneNumber;
this.fax = fax;
}
private String firstName;
private String lastName;
private String company;
private String address;
private String city;
private String state;
private String zip;
private String county;
private String url;
private String phoneNumber;
private String fax;
// accessor / mutators omitted for brevity
}
The next component to do work is the writer, which is responsible for taking the aggregated collection of items read from the reader. A new collection (java.util.List<UserRegistration>) is created, written, and finally reset each time the collection exceeds the commit-interval attribute on the chunk element. Spring Batch's org.springframework.batch.item.database.JdbcBatchItemWriter attempts to write the items into a database. This class contains support for taking input and writing it to a database. It is up to the developer to provide the input and to specify what SQL should be run for the input. It will run the SQL specified by the sql property—in essence writing to the database—as many times as specified by the chunk element's commit-interval, and then commit the whole transaction. By doing a simple insert using the names and values for the named parameters created by the bean configured for the itemSqlParameterSourceProvider property, an instance of the class BeanPropertyItemSqlParameterSourceProvider, whose sole job it is to take POJO properties and make them available as named parameters corresponding to the property name on the POJO
While transferring data directly from a spreadsheet or CSV dump might be useful, one can imagine having to do some sort of processing on the data before it's written. Data in a CSV file, and more generally from any source, is not usually exactly the way you expect it to be or immediately suitable for writing. Just because Spring Batch can coerce it into a POJO on your behalf does not mean the state of the data will be correct. Additional data may need to be inferred or filled in from other services before the data is suitable for writing.Spring Batch allows developersto do processing on reader output by using beans that implement ItemProcessor<I, O>. This processing can do virtually anything to the output before it gets passed to the writer, including changing the type of the data. In this example a validation processor is added, as shown in Listing 17–8. This processor checks for a valid state, zip code, and phone number.
Listing 17–8. Processor Class That Validates the Address
package com.apress.prospringintegration.springbatch.integration;
import com.apress.prospringintegration.springbatch.UserRegistration;
import org.apache.commons.lang.StringUtils;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import java.util.Arrays;
import java.util.Collection;
@Component("userRegistrationValidationProcessor")
public class UserRegistrationValidationItemProcessor
implements ItemProcessor<UserRegistration, UserRegistration> {
private Collection<String> states;
public UserRegistrationValidationItemProcessor() {
this.states = Arrays.asList(
("AL AK AS AZ AR CA CO CT DE DC FM " +
"FL GA GU HI ID IL IN IA KS KY LA ME MH MD " +
"MA MI MN MS MO MT NE NV NH NJ NM NY NC ND " +
"MP OH OK OR PW PA PR RI SC SD TN TX UT " +
"VT VI VA WA WV WI WY").split(" "));
}
private String stripNonNumbers(String input) {
String output = StringUtils.defaultString(input);
StringBuffer numbersOnly = new StringBuffer();
for (char potentialDigit : output.toCharArray()) {
if (Character.isDigit(potentialDigit)) {
numbersOnly.append(potentialDigit);
}
}
return numbersOnly.toString();
}
private boolean isTelephoneValid(String telephone) {
return !StringUtils.isEmpty(telephone) && telephone.length() == 10;
}
private boolean isZipCodeValid(String zip) {
return !StringUtils.isEmpty(zip) && ((zip.length() == 5) || (zip.length() == 9));
}
private boolean isValidState(String state) {
return states.contains(StringUtils.defaultString(state).trim());
}
public UserRegistration process(UserRegistration input)
throws Exception {
String zipCode = stripNonNumbers(input.getZip());
String telephone = stripNonNumbers(input.getPhoneNumber());
String state = StringUtils.defaultString(input.getState());
if (isTelephoneValid(telephone) && isZipCodeValid(zipCode) && isValidState(state)) {
input.setZip(zipCode);
input.setPhoneNumber(telephone);
System.out.println("input is valid, returning");
return input;
}
System.out.println("Returning null");
return null;
}
}
In this example, with very little configuration or custom code, Spring Batch allows developers to build a solution for taking large CSV files and reading them into a database.
Retry
Batch jobs deal with resources that can fail, such as networking or file access. Retrying read and write is an important requirement when implementing jobs. Spring Batch provides retry capabilities to systematically retry the read or write, as shown in Listing 17–9. This example allows Spring Batch to retry when a DeadlockLoserDataAccessException is thrown.
Listing 17–9. Spring Batch Job Definition with Retry
<batch:job id="importData" job-repository="jobRepository">
<batch:step id="step1" next="step2">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="dataReader"
writer="dataWriter"
processor="userRegistrationValidationProcessor"
commit-interval="10"
retry-limit="3">
<batch:retryable-exception-classes>
<batch:include class="org.springframework.dao.DeadlockLoserDataAccessException"/>
</batch:retryable-exception-classes>
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
Transaction and Rollback
Since Spring Batch is based on the Spring Framework, transaction capabilities are already built in. Spring Batch surfaces the configuration so that developers can control it. Similar to a common Spring Framework application, Spring Batch step element accepts TransactionManager by setting the transaction-manager attribute for the tasklet element, as shown in Listing 17–10.
Listing 17–10. Spring Batch Job Definition with Transaction and Rollback
<batch:job id="importData" job-repository="jobRepository">
<batch:step id="step1" next="step2">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="dataReader"
writer="dataWriter"
processor="userRegistrationValidationProcessor"
commit-interval="10"/>
</batch:tasklet>
</batch:step>
</batch:job>
If the source of the reader is a transactional message queue and the writer is failing, the rollback may need to include the source of the reader, as follows:
<batch:chunk reader="dataReader"
writer="dataWriter"
processor="userRegistrationValidationProcessor"
commit-interval="10"
reader-transactional-queue="true"/>
If a write fails on an ItemWriter, or some other exception occurs in processing, Spring Batch will roll back the transaction. This is valid handling for a majority of cases. There may be scenarios in whichthe developers want to controlwhich exceptional cases cause the transaction to roll back. Listing 17–11 shows how to specify an exception that is ignored and allow processing to continue.
Listing 17–11. Spring Batch Job Definition with Exception Classes
<batch:step id = "step2">
<batch:tasklet>
<batch:chunk reader="reader" writer="writer" commit-interval="10" />
<batch:skippable-exception-classes>
<batch:include class="com.yourdomain.exceptions.YourBusinessException"/>
</batch:skippable-exception-classes>
</batch:tasklet>
</batch:step>
Concurrency
Thefirst version of Spring Batch was oriented toward batch processing inside the same thread—concurrency, however, was not as well integrated. There were workarounds, of course, but the situation was less than ideal. Fortunately, this shortcoming has been rectified in version 2.0.
Consider the example job shown in Listing 17–12: the first step has to come before the second two because the second two are dependent on the first. The second two, however, do not share any such dependencies. There is no reason why the audit log could not be written at the same time the JMS messages are delivered. Spring Batch provides the capability to fork processing to enable just this sort of arrangement.
Listing 17–12. Spring Batch Job Definition with Concurrency
<batch:job job-repository="jobRepository" id="insertIntoDbFromCsvJob">
<batch:step id="loadRegistrations" next="finalizeRegistrations">
<!--
...
-->
</batch:step>
<batch:split id="finalizeRegistrations" >
<batch:flow>
<batch:step id="reportStatistics" ><!-- ... --></step>
</batch:flow>
<batch:flow>
<batch:step id="sendJmsNotifications" ><!-- ... --></step>
</batch:flow>
</batch:split>
</batch:job>
In this example, there's nothing preventing you from having many steps within the flow elements, nor is there anything preventing you from having more steps after the split element. The split element, like the step elements, takes a next attribute as well.
Spring Batch provides a mechanism to offload processing to another process. This feature, called remote chunking, is new in Spring Batch 2.x. This distribution requires some sort of durable, reliable connection. This is a perfect use of JMS because it's rock-solid, transactional, fast, and reliable. Spring Batch support is modeled at a slightly higher level, on top of the Spring Integration abstractions for Spring Integration channels. This support is not in the main Spring Batch code, though.
Remote chunking lets individual steps read and aggregate items as usual in the main thread. The main job flowstep is called the master. Items read are sent to an ItemProcessor<I,O>/ItemWriter<T> running in another process (this is called the slave). If the slave is an aggressive consumer, there is a simple, generic mechanism to scale: work is instantly farmed out over as many JMS clients as you can throw at it. The aggressive-consumer pattern refers to the arrangement of multiple JMS clients all consuming the same queue's messages. If one client consumes a message and is busy processing, other idle queues will get the message instead. As long as there's a client that's idle, the message will be processed instantly.
Additionally, Spring Batch supports implicitly scaling out using a feature called partitioning. This feature is interesting because it is built in and generally very flexible. By replacingthe instance of a step with a subclass, org.springframework.batch.core.partition.support.PartitionStep, the need for a durable medium of communication is eliminated. The PartitionStep, as in the remote chunking technology, knows how to coordinate distributed executors and maintains the metadata for the execution of the step.
The functionality here is also very generic. It could conceivably be used with any sort of grid fabric technology (e.g., GridGain or Hadoop). Spring Batch ships with only an org.springframework.batch.core.partition.support.TaskExecutorPartitionHandler, which executes steps in multiple threads using a TaskExecutor strategy. This simple improvement might be enough of a justification for this feature. Another partition handler is available through the Spring Batch Integration project using Spring Integration. The org.springframework.batch.integration.partition.MessageChannelPartitionHandler allows partitioning to use a message channel as the fabric. This approach will be discussed in more detail following.
Launching a Job
Spring Batch works very well in all environments that support Spring. Some use cases are uniquely challenging. For example, it is rarely practical to run Spring Batch in the same thread as an HTTP response in a servlet container, because it might end up stalling execution. Fortunately, Spring Batch supports asynchronous execution for this particular scenario. Spring Batch also provides a convenience class that can be readily used with cron or autosys to support launching jobs. Additionally, Spring 3.0's excellent scheduler namespace provides a great mechanism to schedule jobs.
Launching a Spring Batch job, requires a job and a JobLauncher, as shown in Listing 17–13. The job is configured in the Spring XML application context while the JobLauncher is created inside the application code.
Listing 17–13. Launching a Spring Batch Job
package com.apress.prospringintegration.springbatch.integration;
import org.springframework.batch.core.*;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.Date;
public class Main {
public static void main(String[] args) throws Throwable {
ClassPathXmlApplicationContext classPathXmlApplicationContext =
new ClassPathXmlApplicationContext("integration.xml");
classPathXmlApplicationContext.start();
JobLauncher jobLauncher =
(JobLauncher) classPathXmlApplicationContext.getBean("jobLauncher");
Job job = (Job) classPathXmlApplicationContext.getBean("importData");
JobParametersBuilder jobParametersBuilder = new JobParametersBuilder();
jobParametersBuilder.addDate("date", new Date());
jobParametersBuilder.addString("input.file", "registrations");
JobParameters jobParameters = jobParametersBuilder.toJobParameters();
JobExecution jobExecution = jobLauncher.run(job, jobParameters);
BatchStatus batchStatus = jobExecution.getStatus();
while (batchStatus.isRunning()) {
System.out.println("Still running...");
Thread.sleep(1000);
}
System.out.println("Exit status: " + jobExecution.getExitStatus().getExitCode());
JobInstance jobInstance = jobExecution.getJobInstance();
System.out.println("job instance Id: " + jobInstance.getId());
}
}
The JobLauncher references the JobimportData instance, which was configured earlier in this chapter. The result is a JobExecution object, which contains the state of the job. The JobExecution object contains exit status, runtime status, and a lot of very useful information, such as creation time and starting time.
Besides being launched from a command-line Java application, Spring Batch jobs can be launched from web applications as well. This takes a slightly different approach, however. Since the client thread, for example an HTTP request, cannot usually wait for a batch job to finish, the ideal solution is to have the job execute asynchronously when launched from the controller or action in the web tier. Spring Batch supports this scenario by using the Spring TaskExecutor. Using it requires a small change to the JobLauncher in the BatchConfiguration Java configuration, as shown in Listing 17–14.
Listing 17–14. Launching a Spring Batch Job from a Web Application
import org.springframework.core.task.SimpleAsyncTaskExecutor;
@Bean
public SimpleJobLauncher jobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository().getJobRepository());
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor());
return jobLauncher;
}
Another approach for managing a Spring Batch job is by using Spring Batch Admin, which will be discussed in detail later in the chapter. Spring Batch Admin provides a web-based user interface for launching and managing Spring Batch jobs.
Event-Driven Batch Processing
Spring Integration and Spring Batch both deal with input- and output-centric processing. While both systems will work with files and message queues, Spring Integration does not do well with large payloads, because it is hard to deal with something as large as a file with a million rows that might require hours of work as an event. That is simply too big a burden for a messaging system. For that amount of data, the term event has no meaning anymore. A million records in a CSV file isn't an event on a bus, it is still a file with a million records; this is a subtle distinction.
Spring Integration and Spring Batch can be used together in a complementary fashion. Spring Integration can be used to detect and react to events in a system. Spring Batch can be used to penetrate large datasets and decompose them into events, which of course Spring Integration can deal with. Similarly, Spring Integration can be used to distribute processing across multiple VMs or machines on Spring Batch's behalf. So, for a file with a million rows, you might use Spring Batch to break the file into smaller parts, and then use Spring Integration to process the parts, or chunks.
Staged event-driven architecture (SEDA) is an architecture style that deals with this sort of processing. In SEDA, the load on components of the architecture is lessened by staging it in queues, and letting advance only what the components downstream can handle. For example, if a system were running a web site with a million users uploading video that in turn needed to be transcoded, and there were only ten servers, the system would fail if it attempted to process each video as soon as it received it. Transcoding can take hours, and pegs a CPU (or multiple CPUs) while it works. The most sensible thing to do is to store the file, and then, as capacity permits, process each one. In this way, the load on the nodes that handle transcoding is managed. There's always only enough work to keep the machine humming, but not to overrun.
Similarly, no messaging system (including Spring Integration) can deal with a million records at once efficiently. Strive to decompose bigger events and messages into smaller ones. Let's imagine a hypothetical solution designed to accommodate a drop of batch files representing hourly sales destined for fulfillment. The batch files are dropped onto a mount that Spring Integration is monitoring. Spring Integration kicks off processing as soon as it sees a new file. Spring Integration tells Spring Batch about the file and launches a Spring Batch job asynchronously.
Spring Batch reads the file, transforms the records into objects, and writes the output to a JMS topic with a key correlating the original batch to the JMS message. Naturally, this takes half a day to get done, but it does get done. Spring Integration, completely unaware that the job it started half a day ago is now finished, begins popping messages off the topic, one by one. Processing to fulfill the records begins. Simple processing involving multiple components might begin using a messaging system.
If fulfillment is a long-lived process with a long-lived, conversational state involving many actors, the fulfillment for each record could be farmed to a BPM engine such as Activiti (discussed in Chapter 8). The BPM engine would thread together the different actors and work lists, allowing work to continue over the course of days instead of the millisecond time frames that Spring Integration is more geared to.
Launching Jobs with Spring Integration
By combining Spring Integration and Spring Batch, batch job automation based on events is possible. For example, by using event-driven architecture (EDA), an event could trigger a batch job to be executed, and the job could send a message indicating whether it succeeded or failed.
Libraries that support the integration of Spring Batch and Spring Integration are available from the Spring Batch Integration project. This project has now become a part of the Spring Batch Admin project, which will be discussed in more detail later in the chapter. For now, these supporting Spring Batch Integration library can be added through Maven, as shown in Listing 17–15.
Listing 17–15. Maven Dependency for Spring Batch Integration
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-integration</artifactId>
<version>1.2.0.RELEASE</version>
</dependency>
Spring Batch Integration includes a number of components, including a service activator that will launch a Spring Batch job. This service activator takes an input message with the payload org.springframework.batch.integration.launch.Job.LaunchRequest and returns a message with the payload JobExecution. This service activator is configured using the Java configuration shown in Listing 17–16.
Listing 17–16. Java Configuration for Lauching Spring Batch Jobs
package com.apress.prospringintegration.springbatch.integration;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.integration.launch.JobLaunchingMessageHandler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class IntegrationConfiguration {
@Autowired
private JobLauncher jobLauncher;
@Bean
public JobLaunchingMessageHandler jobMessageHandler() {
JobLaunchingMessageHandler messageHandler =
new JobLaunchingMessageHandler(jobLauncher);
return messageHandler;
}
}
The configuration for Spring Integration is straightforward. The service activator jobMessageHandler is configured for the input message channel launchChannel and the output message channel statusChannel. The rest of the configuration file is identical to the previous examples as shown in Listing 17–17.
Listing 17–17. Spring Configuration File for Lauching Spring Batch Jobs integration.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:int="http://www.springframework.org/schema/integration"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch-2.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration-2.0.xsd">
<context:property-placeholder location="batch.properties"/>
<context:component-scan
base-package="com.apress.prospringintegration.springbatch.integration"/>
<batch:job id="importData" job-repository="jobRepository">
<batch:step id="step1">
<batch:tasklet>
<batch:chunk reader="dataReader"
processor="userRegistrationValidationProcessor"
writer="dataWriter"
commit-interval="10"/>
</batch:tasklet>
</batch:step>
</batch:job>
<int:channel id="launchChannel"/>
<int:channel id="statusChannel">
<int:queue capacity="10"/>
</int:channel>
<int:service-activator input-channel="launchChannel"
output-channel="statusChannel"
ref="jobMessageHandler"/>
</beans>
The main class for launching the Spring Batch job using Spring Integration is shown in Listing 17–18. The JobLaunchRequest instance is created with a reference to the Job and JobParameters objects. The JobLaunchRequest object is sent as a message payload to the launchChannel message channel. The main class then waits for the response message on the statusChannel message channel. When the job completes, the status information is logged to the console.
Listing 17–18. Main Class for Launching Spring Batch Jobs
package com.apress.prospringintegration.springbatch.integration;
import org.springframework.batch.core.*;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.integration.launch.JobLaunchRequest;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.integration.Message;
import org.springframework.integration.MessageChannel;
import org.springframework.integration.channel.QueueChannel;
import org.springframework.integration.support.MessageBuilder;
import java.util.Date;
public class IntegrationMain {
public static void main(String[] args) throws Throwable {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(
"integration.xml");
context.start();
MessageChannel launchChannel = context.getBean("launchChannel", MessageChannel.class);
QueueChannel statusChannel = context.getBean("statusChannel", QueueChannel.class);
Job job = (Job) context.getBean("importData");
JobParametersBuilder jobParametersBuilder = new JobParametersBuilder();
jobParametersBuilder.addDate("date", new Date());
jobParametersBuilder.addString("input.file", "registrations");
JobParameters jobParameters = jobParametersBuilder.toJobParameters();
JobLaunchRequest jobLaunchRequest = new JobLaunchRequest(job, jobParameters);
launchChannel.send(MessageBuilder.withPayload(jobLaunchRequest).build());
Message<JobExecution> statusMessage =
(Message<JobExecution>) statusChannel.receive();
JobExecution jobExecution = statusMessage.getPayload();
System.out.println(jobExecution);
System.out.println("Exit status: " + jobExecution.getExitStatus().getExitCode());
JobInstance jobInstance = jobExecution.getJobInstance();
System.out.println("job instance Id: " + jobInstance.getId());
}
}
Partitioning
One of the most interesting techniques available to Spring Batch and Spring Integration is the ability to partition big batch jobs over many nodes using a Spring Integration message channel as the coordination fabric. Spring Batch has a general API for partitioning a step execution and executing it remotely. The messages sent to each of the step instance do not need to be durable, since they have access to the Spring Batch metadata through the JobRepository database. The Java configuration for partitioning is shown in Listing 17–19.
Listing 17–19. Java Configuration for Partitioning
package com.apress.prospringintegration.springbatch.partition;
import org.springframework.batch.core.explore.JobExplorer;
import org.springframework.batch.core.explore.support.JobExplorerFactoryBean;
import org.springframework.batch.core.partition.support.SimplePartitioner;
import org.springframework.batch.integration.partition.BeanFactoryStepLocator;
import org.springframework.batch.integration.partition.MessageChannelPartitionHandler;
import org.springframework.batch.integration.partition.StepExecutionRequestHandler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.integration.MessageChannel;
import org.springframework.integration.core.MessagingTemplate;
import org.springframework.integration.core.PollableChannel;
import javax.sql.DataSource;
@Configuration
public class PartitionConfiguration {
@Autowired
@Qualifier("requestChannel")
private MessageChannel messageChannel;
@Autowired
@Qualifier("replyChannel")
private PollableChannel pollableChannel;
@Autowired
private DataSource dataSource;
@Bean
public MessageChannelPartitionHandler partitionHandler() {
MessageChannelPartitionHandler partitionHandler =
new MessageChannelPartitionHandler();
partitionHandler.setMessagingOperations(messagingTemplate());
partitionHandler.setReplyChannel(pollableChannel);
partitionHandler.setStepName("step1");
partitionHandler.setGridSize(10);
return partitionHandler;
}
@Bean
public MessagingTemplate messagingTemplate() {
MessagingTemplate messagingTemplate = new MessagingTemplate();
messagingTemplate.setDefaultChannel(messageChannel);
return messagingTemplate;
}
@Bean
public SimplePartitioner partitioner() {
SimplePartitioner simplePartitioner = new SimplePartitioner();
return simplePartitioner;
}
@Bean
public BeanFactoryStepLocator stepLocator() {
BeanFactoryStepLocator stepLocator = new BeanFactoryStepLocator();
return stepLocator;
}
@Bean
public JobExplorerFactoryBean jobExplorer() {
JobExplorerFactoryBean jobExplorerFactoryBean = new JobExplorerFactoryBean();
jobExplorerFactoryBean.setDataSource(dataSource);
return jobExplorerFactoryBean;
}
@Bean
public StepExecutionRequestHandler stepExecutionRequestHandler() throws Exception {
StepExecutionRequestHandler stepExecutionRequestHandler =
new StepExecutionRequestHandler();
stepExecutionRequestHandler.setJobExplorer((JobExplorer) jobExplorer().getObject());
stepExecutionRequestHandler.setStepLocator(stepLocator());
return stepExecutionRequestHandler;
}
}
The org.springframework.batch.integration.partition.MessageChannelPartitionHandler is the component that knows about the Spring Integration fabric controlling the remote step execution. The MessageChannelPartitionHandler is configured to send a message to the requestChannel Spring Integration channel using a MessagingTemplate. The reply message is returned through the replyChannel message channel. The remote step is step1 and the number of instances or grid size is set to 10.
The step execution is handled by the org.springframework.batch.integration.partition.StepExecutionRequestHandler. The StepExecutionRequestHandler can access the Spring Batch metadata through the org.springframework.batch.core.explore.JobExplorer instances. The step can be executed on a remote system since the state is maintained through the database. However, for simplicity, the step execution will take place locally.
The Spring configuration for the remote step execution is shown in Listing 17–20. The stepExecutionRequestHandler instance is a service activator that responds to the requestChannel input channel. The results the step execution sends a message to a message aggregator using the message channel staging. After all steps have been completed, a reply message is sent to the replyChannel message channel.
Listing 17–20. Spring Configuration for Partitioning message-partition.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:int="http://www.springframework.org/schema/integration"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration-2.0.xsd">
<context:property-placeholder location="batch.properties"/>
<context:component-scan
base-package="com.apress.prospringintegration.springbatch.partition"/>
<batch:job id="importData" job-repository="jobRepository">
<batch:step id="step1-master">
<batch:partition step="step1" handler="partitionHandler" partitioner="partitioner"/>
</batch:step>
</batch:job>
<batch:step id="step1">
<batch:tasklet>
<batch:chunk reader="dataReader"
processor="userRegistrationValidationProcessor"
writer="dataWriter"
commit-interval="5"/>
</batch:tasklet>
</batch:step>
<int:channel id="launchChannel"/>
<int:channel id="statusChannel">
<int:queue capacity="10"/>
</int:channel>
<int:service-activator input-channel="launchChannel"
output-channel="statusChannel"
ref="jobMessageHandler"/>
<int:channel id="requestChannel">
<int:queue capacity="10"/>
</int:channel>
<int:channel id="staging">
<int:queue capacity="10"/>
</int:channel>
<int:channel id="replyChannel">
<int:queue capacity="10"/>
</int:channel>
<int:service-activator ref="stepExecutionRequestHandler"
input-channel="requestChannel"
output-channel="staging">
<int:poller>
<int:interval-trigger interval="10"/>
</int:poller>
</int:service-activator>
<int:aggregator ref="partitionHandler"
input-channel="staging"
output-channel="replyChannel">
<int:poller>
<int:interval-trigger interval="10"/>
</int:poller>
</int:aggregator>
</beans>
The main class to run the partitioning example, as shown in Listing 17–21, is identical to that from the previous example of launching a job using Spring Integration. Running the main class will result in ten step instances processing and moving the registration data into the database. This could easily represent ten remote step instances running on various hosts, all connected through the Spring Integration message channel.
Listing 17–21. Main Class for Partitioning
package com.apress.prospringintegration.springbatch.partition;
import org.springframework.batch.core.*;
import org.springframework.batch.integration.launch.JobLaunchRequest;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.integration.Message;
import org.springframework.integration.MessageChannel;
import org.springframework.integration.channel.QueueChannel;
import org.springframework.integration.support.MessageBuilder;
import java.util.Date;
public class IntegrationPartitionMain {
public static void main(String[] args) throws Throwable {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(
"message-partition.xml");
context.start();
MessageChannel launchChannel = context.getBean("launchChannel", MessageChannel.class);
QueueChannel statusChannel = context.getBean("statusChannel", QueueChannel.class);
Job job = (Job) context.getBean("importData");
JobParametersBuilder jobParametersBuilder = new JobParametersBuilder();
jobParametersBuilder.addDate("date", new Date());
jobParametersBuilder.addString("input.file", "registrations");
JobParameters jobParameters = jobParametersBuilder.toJobParameters();
JobLaunchRequest jobLaunchRequest = new JobLaunchRequest(job, jobParameters);
launchChannel.send(MessageBuilder.withPayload(jobLaunchRequest).build());
Message<JobExecution> statusMessage = (Message<JobExecution>) statusChannel.receive();
JobExecution jobExecution = statusMessage.getPayload();
System.out.println(jobExecution);
System.out.println("Exit status: " + jobExecution.getExitStatus().getExitCode());
JobInstance jobInstance = jobExecution.getJobInstance();
System.out.println("job instance Id: " + jobInstance.getId());
}
}
Spring Batch Admin
Spring Batch Admin (http://static.springsource.org/spring-batch-admin) is an open source project from SpringSource. It provides a web-based user interface as an administrative console for Spring Batch applications and systems. The user interface allows job inspection, job launching, job execution inspection, and job execution life cycle management. Spring Batch Admin also provides an API for developers to build custom web applications adding a web interface with the ability to manage Spring Batch job execution from external applications.
You can download the latest version of Spring Batch Admin, 1.2.0.RELEASE, from the SpringSource Community Download page (www.springsource.com/products/spring-community-download). Download and unzip the spring-batch-admin-1.2.0.RELEASE-dist.zip file. A complete Spring Batch Admin project will be located in the sample/spring-batch-admin-sample directory. An additional project in the sample/spring-batch-admin-parent directory is also required. This sample project will be used as the basis for the next example.
We will be adding the previous Spring Batch example to Spring Batch Admin. The basic Spring Batch component will be made available by Spring Batch Admin, so the BatchConfiguration Java configuration class will not be needed. All that is required is to add the Spring configuration for the job to the src/resources/META-INF/spring/batch/jobs directory, and all the supporting classes to the package com.apress.prospringintegration.batch. The required supporting classes are JdbcConfiguration, JobConfiguration, UserRegistration, and UserRegistrationValidationItemProcessor. After modifying these classes for the new Java package, add these classes to the src/main/java/com/apress/prospringintegration/batch directory.
The Spring configuration file for the new myjob job is shown in Listing 17–22. The configuration is simple; it contains only the Java configuration, the job description, and the component-scan element to support component scanning. This is basically all that is needed to add a job to Spring Batch Admin.
Listing 17–22. myjob-context.xml: Spring Configuration File for Spring Batch Admin
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd">
<context:component-scan base-package="com.apress.prospringintegration.batch"/>
<batch:job id="myjob">
<batch:step id="step1">
<batch:tasklet>
<batch:chunk reader="dataReader"
processor="userRegistrationValidationProcessor"
writer="dataWriter"
commit-interval="5"/>
</batch:tasklet>
</batch:step>
</batch:job>
</beans>
Add the PostgreSQL connection properties to the batch-default.properties file, located in the src/main/resources directory, to make the properties available within the Spring Batch Admin application. The modifications to the properties file are shown in Listing 17–23.
Listing 17–23. Adding PostgreSQL Properties to batch-default.properties
# Default placeholders for database platform independent features
batch.remote.base.url=http://localhost:8080/spring-batch-admin-sample
dataSource.password=emilyk
dataSource.username=postgres
dataSource.databaseName=postgres
dataSource.driverClassName=org.postgresql.Driver
dataSource.serverName=localhost:5432
dataSource.url=jdbc:postgresql://${dataSource.serverName}/${dataSource.databaseName}
# Non-platform dependent settings that you might like to change
# batch.job.configuration.file.dir=target/config
To simplify running the job from the Spring Batch Admin web page, the input parameter for the file location will be changed to take the absolute path. The required change to the Java configuration file is shown in Listing 17–24.
Listing 17–24. Java Configuration Modification for Spring Batch Admin
package com.apress.prospringintegration.batch;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
import org.springframework.core.io.Resource;
import javax.sql.DataSource;
@Configuration
public class JobConfiguration {
@Autowired
private DataSource dataSource;
@Bean
@Scope("step")
public FlatFileItemReader csvFileReader(
@Value("file:#{jobParameters['input.file']}") Resource resource) {
FlatFileItemReader csvFileReader = new FlatFileItemReader();
csvFileReader.setResource(resource);
DelimitedLineTokenizer delimitedLineTokenizer =
new DelimitedLineTokenizer(DelimitedLineTokenizer.DELIMITER_COMMA);
delimitedLineTokenizer.setNames(
new String[]{"firstName", "lastName", "company", "address", "city",
"state", "zip", "county", "url", "phoneNumber", "fax"});
BeanWrapperFieldSetMapper beanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper();
beanWrapperFieldSetMapper.setTargetType(UserRegistration.class);
DefaultLineMapper defaultLineMapper = new DefaultLineMapper();
defaultLineMapper.setLineTokenizer(delimitedLineTokenizer);
defaultLineMapper.setFieldSetMapper(beanWrapperFieldSetMapper);
csvFileReader.setLineMapper(defaultLineMapper);
return csvFileReader;
}
@Bean
public JdbcBatchItemWriter jdbcItemWriter() {
JdbcBatchItemWriter jdbcBatchItemWriter = new JdbcBatchItemWriter();
jdbcBatchItemWriter.setAssertUpdates(true);
jdbcBatchItemWriter.setDataSource(dataSource);
jdbcBatchItemWriter
.setSql("insert into USER_REGISTRATION(FIRST_NAME, LAST_NAME, COMPANY," +
"ADDRESS, CITY, STATE, ZIP, COUNTY, URL, PHONE_NUMBER, FAX )" +
"values (:firstName, :lastName, :company, :address, :city ," +
":state, :zip, :county, :url, :phoneNumber, :fax )");
jdbcBatchItemWriter.setItemSqlParameterSourceProvider(
new BeanPropertyItemSqlParameterSourceProvider());
return jdbcBatchItemWriter;
}
}
Make the change to the JobIntegrationTests class, as shown in Listing 17–25, so the project will build without errors. Essentially we are adding our new job to the unit test.
Listing 17–25. Modifying the Unit Test for Spring Batch Admin
package org.springframework.batch.admin.sample;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotNull;
import java.util.TreeSet;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.batch.core.configuration.ListableJobLocator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.annotation.DirtiesContext;
import org.springframework.test.annotation.DirtiesContext.ClassMode;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@ContextConfiguration
@RunWith(SpringJUnit4ClassRunner.class)
@DirtiesContext(classMode=ClassMode.AFTER_CLASS)
public class JobIntegrationTests {
@Autowired
private ListableJobLocator jobLocator;
@Test
public void testSimpleProperties() throws Exception {
assertNotNull(jobLocator);
assertEquals("[infinite, job1, job2, myjob]",
new TreeSet<String>(jobLocator.getJobNames()).toString());
}
}
Build the Spring Batch Admin sample project using the usual mvn install command. The resultant file, spring-batch-admin-sample-1.2.0.RELEASE.war, will be found in the target directory.Deploy the war file to a servlet container such as Tomcat or Jetty by copying to the webapps directory. Using a browser, go to the URL http://localhost:8080/spring-batch-admin-sample-1.2.0.RELEASE. Click the Jobs tab, and then click the myjob link, which should bring up the page shown in Figure 17–3. In the Job Parameters text box, enter input.file=<path to registration.cvs>, using the path to the registration.cvs file used in the previous examples. Click the Launch button, and the Spring Batch job should run.

Figure 17–3. Spring Batch Admin
Summary
This chapter introduced the concept of batch processing, including some of its history and why it fits in modern-day architectures. Batch processing is used to process billions of transactions every day within mission critical enterprise applications. Spring Batch is designed to provide a runtime environment and reusable utilities for batch processing. It enables batch applications to have the same clean architecture and lightweight programming model as any other Spring Framework project.
In addition, this chapter introduced how Spring Batch can be use with Spring Integration. It demonstrated how Spring Integration can launch Spring Batch jobs via messaging to allow event-driven batch processes. It also discussed how Spring Integration can be used to scale out Spring Batch using partitioning. It described how big batch jobs can be distributed over many nodes using message channels as the coordination fabric. Finally, it have introduced Spring Batch Admin, which provides a web-based user interface for Spring Batch using Spring Integration in its internal plumbing.