
18. File and Directory Handling
This chapter describes Python modules for high-level file and directory handling. Topics include modules for processing various kinds of basic file encodings such as gzip and bzip2 files, modules for extracting file archives such as zip and tar files, and modules for manipulating the file system itself (e.g., directory listings, moving, renaming, copying, and so on). Low-level operating system calls related to files are covered in Chapter 19, “Operating System Services.” Modules for parsing the contents of files such as XML and HTML are mostly covered in Chapter 24, “Internet Data Handling and Encoding.”
bz2
The bz2 module is used to read and write data compressed according to the bzip2 compression algorithm.
![]()
Opens a .bz2 file, filename, and returns a file-like object. mode is 'r' for reading or 'w' for writing. Universal newline support is also available by specifying a mode of 'rU'. buffering specifies the buffer size in bytes with a default value of 0 (no buffering). compresslevel is a number between 1 and 9. A value of 9 (the default) provides the highest level of compression but consumes the most processing time. The returned object supports all the common file operations, including close(), read(), readline(), readlines(), seek(), tell(), write(), and writelines().
BZ2Compressor([compresslevel])
Creates a compressor object that can be used to sequentially compress a sequence of data blocks. compresslevel specifies the compression level as a number between 1 and 9 (the default).
An instance, c, of BZ2Compressor has the following two methods:
c.compress(data)
Feeds new string data to the compressor object, c. Returns a string of compressed data if possible. Because compression involves chunks of data, the returned string may not include all the data and may include compressed data from previous calls to compress(). The flush() method should be used to return any remaining data stored in the compressor after all input data has been supplied.
Flushes the internal buffers and returns a string containing the compressed version of all remaining data. After this operation, no further compress() calls should be made on the object.
BZ2Decompressor()
Creates a decompressor object.
An instance, d, of BZ2Decompressor supports just one method:
d.decompress(data)
Given a chunk of compressed data in the string data, this method returns uncompressed data. Because data is processed in chunks, the returned string may or may not include a decompressed version of everything supplied in data. Repeated calls to this method will continue to decompress data blocks until an end-of-stream marker is found in the input. If subsequent attempts are made to decompress data after that, an EOFError exception will be raised.
compress(data [, compresslevel])
Returns a compressed version of the data supplied in the string data. compresslevel is a number between 1 and 9 (the default).
decompress(data)
Returns a string containing the decompressed data in the string data.
filecmp
The filecmp module provides the following functions, which can be used to compare files and directories:
cmp(file1, file2 [, shallow])
Compares the files file1 and file2 and returns True if they’re equal, False if not. By default, files that have identical attributes as returned by os.stat() are considered to be equal. If the shallow parameter is specified and is False, the contents of the two files are compared to determine equality.
cmpfiles(dir1, dir2, common [, shallow])
Compares the contents of the files contained in the list common in the two directories dir1 and dir2. Returns a tuple containing three lists of filenames (match, mismatch, errors). match lists the files that are the same in both directories, mismatch lists the files that don’t match, and errors lists the files that could not be compared for some reason. The shallow parameter has the same meaning as for cmp().
dircmp(dir1, dir2 [, ignore[, hide]])
Creates a directory comparison object that can be used to perform various comparison operations on the directories dir1 and dir2. ignore is a list of filenames to ignore and has a default value of ['RCS','CVS','tags']. hide is a list of filenames to hide and defaults to the list [os.curdir, os.pardir] (['.', '..'] on UNIX).
A directory object, d, returned by dircmp() has the following methods and attributes:
d.report()
Compares directories dir1 and dir2 and prints a report to sys.stdout.
d.report_partial_closure()
Compares dir1 and dir2 and common immediate subdirectories. Results are printed to sys.stdout.
d.report_full_closure()
Compares dir1 and dir2 and all subdirectories recursively. Results are printed to sys.stdout.
d.left_list
Lists the files and subdirectories in dir1. The contents are filtered by hide and ignore.
d.right_list
Lists the files and subdirectories in dir2. The contents are filtered by hide and ignore.
d.common
Lists the files and subdirectories found in both dir1 and dir2.
d.left_only
Lists the files and subdirectories found only in dir1.
d.right_only
Lists the files and subdirectories found only in dir2.
d.common_dirs
Lists the subdirectories that are common to dir1 and dir2.
d.common_files
Lists the files that are common to dir1 and dir2.
d.common_funny
Lists the files in dir1 and dir2 with different types or for which no information can be obtained from os.stat().
d.same_files
Lists the files with identical contents in dir1 and dir2.
d.diff_files
Lists the files with different contents in dir1 and dir2.
d.funny_files
Lists the files that are in both dir1 and dir2 but that could not be compared for some reason (for example, insufficient permission to access).
d.subdirs
A dictionary that maps names in d.common_dirs to additional dircmp objects.
Note
The attributes of a dircmp object are evaluated lazily and not determined at the time the dircmp object is first created. Thus, if you’re interested in only some of the attributes, there’s no added performance penalty related to the other unused attributes.
fnmatch
The fnmatch module provides support for matching filenames using UNIX shell-style wildcard characters. This module only performs filename matching, whereas the glob module can be used to actually obtain file listings. The pattern syntax is as follows:

The following functions can be used to test for a wildcard match:
fnmatch(filename, pattern)
Returns True or False depending on whether filename matches pattern. Case sensitivity depends on the operating system (and may be non–case-sensitive on certain platforms such as Windows).
fnmatchcase(filename, pattern)
Performs a case-sensitive comparison of filename against pattern.
filter(names, pattern)
Applies the fnmatch() function to all of the names in the sequence names and returns a list of all names that match pattern.
Examples
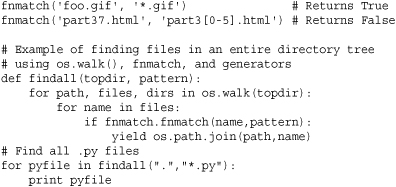
glob
The glob module returns all filenames in a directory that match a pattern specified using the rules of the UNIX shell (as described in the fnmatch module).
glob(pattern)
Returns a list of pathnames that match pattern.
iglob(pattern)
Returns the same results as glob() but using an iterator.
Example
![]()
Note
Tilde (~) and shell variable expansion are not performed. Use os.path.expanduser() and os.path.expandvars(), respectively, to perform these expansions prior to calling glob().
gzip
The gzip module provides a class, GzipFile, that can be used to read and write files compatible with the GNU gzip program. GzipFile objects work like ordinary files except that data is automatically compressed or decompressed.
GzipFile([filename [, mode [, compresslevel [, fileobj]]]])
Opens a GzipFile. filename is the name of a file, and mode is one of 'r', 'rb', 'a', 'ab', 'w', or 'wb'. The default is 'rb'. compresslevel is an integer from 1 to 9 that controls the level of compression. 1 is the fastest and produces the least compression; 9 is the slowest and produces the most compression (the default). fileobj is an existing file object that should be used. If supplied, it’s used instead of the file named by filename.
open(filename [, mode [, compresslevel]])
Same as GzipFile(filename, mode, compresslevel). The default mode is 'rb'. The default compresslevel is 9.
Notes
• Calling the close() method of a GzipFile object doesn’t close files passed in fileobj. This allows additional information to be written to a file after the compressed data.
• Files produced by the UNIX compress program are not supported.
• This module requires the zlib module.
shutil
The shutil module is used to perform high-level file operations such as copying, removing, and renaming. The functions in this module should only be used for proper files and directories. In particular, they do not work for special kinds of files on the file system such as named pipes, block devices, etc. Also, be aware that these functions don’t always correctly deal with advanced kinds of file metadata (e.g., resource forks, creator codes, etc.).
copy(src,dst)
Copies the file src to the file or directory dst, retaining file permissions. src and dst are strings.
copy2(src, dst)
Like copy() but also copies the last access and modification times.
copyfile(src, dst)
Copies the contents of src to dst. src and dst are strings.
copyfileobj(f1, f2 [, length])
Copies all data from open file object f1 to open file object f2. length specifies a maximum buffer size to use. A negative length will attempt to copy the data entirely with one operation (that is, all data will be read as a single chunk and then written).
copymode(src, dst)
Copies the permission bits from src to dst.
copystat(src, dst)
Copies the permission bits, last access time, and last modification time from src to dst. The contents, owner, and group of dst are unchanged.
copytree(src, dst, symlinks [,ignore]])
Recursively copies an entire directory tree rooted at src. The destination directory dst will be created (and should not already exist). Individual files are copied using copy2(). If symlinks is true, symbolic links in the source tree are represented as symbolic links in the new tree. If symlinks is false or omitted, the contents of linked files are copied to the new directory tree. ignore is an optional function that can be used to filter out specific files. As input, this function should accept a directory name and a list of directory contents. As a return value, it should return a list of filenames to be ignored. If errors occur during the copy process, they are collected and the Error exception is raised at the end of processing. The exception argument is a list of tuples containing (srcname, dstname, exception) for all errors that occurred.
ignore_pattern(pattern1, pattern2, ...)
Creates a function that can be used for ignoring all of the glob-style patterns given in pattern1, pattern2, etc. The returned function accepts as input two arguments, the first of which is a directory name and the second of which is a list of directory contents. As a result, a list of filenames to be ignored is returned. The primary use of the returned function is as the ignore parameter to the copytree() function shown earlier. However, the resulting function might also be used for operations involving the os.walk() function.
Moves a file or directory src to dst. Will recursively copy src if it is being moved to a different file system.
rmtree(path [, ignore_errors [, onerror]])
Deletes an entire directory tree. If ignore_errors is true, errors will be ignored. Otherwise, errors are handled by the onerror function (if supplied). This function must accept three parameters (func, path, and excinfo), where func is the function that caused the error (os.remove() or os.rmdir()), path is the pathname passed to the function, and excinfo is the exception information returned by sys.exc_info(). If an error occurs and onerror is omitted, an exception is raised.
tarfile
The tarfile module is used to manipulate tar archive files. Using this module, it is possible to read and write tar files, with or without compression.
is_tarfile(name)
Returns True if name appears to be a valid tar file that can be read by this module.
open([name [, mode [, fileobj [, bufsize]]]])
Creates a new TarFile object with the pathname name. mode is a string that specifies how the tar file is to be opened. The mode string is a combination of a file mode and a compression scheme specified as 'filemode[:compression]'. Valid combinations include the following:

The following modes are used when creating a TarFile object that only allows sequential I/O access (no random seeks):

If the parameter fileobj is specified, it must be an open file object. In this case, the file overrides any filename specified with name. bufsize specifies the block size used in a tar file. The default is 20*512 bytes.
A TarFile instance, t, returned by open() supports the following methods and attributes:
t.add(name [, arcname [, recursive]])
Adds a new file to the tar archive. name is the name of any kind of file (directory, symbolic link, and so on). arcname specifies an alternative name to use for the file inside the archive. recursive is a Boolean flag that indicates whether or not to recursively add the contents of directories. By default, it is set to True.
t.addfile(tarinfo [, fileobj])
Adds a new object to the tar archive. tarinfo is a TarInfo structure that contains information about the archive member. fileobj is an open file object from which data will be read and saved in the archive. The amount of data to read is determined by the size attribute of tarinfo.
t.close()
Closes the tar archive, writing two zero blocks to the end if the archive was opened for writing.
t.debug
Controls the amount of debugging information produced, with 0 producing no output and 3 producing all debugging messages. Messages are written to sys.stderr.
t.dereference
If this attribute is set to True, symbolic and hard links are dereferenced and the entire contents of the referenced file are added to the archive. If it’s set to False, just the link is added.
t.errorlevel
Determines how errors are handled when an archive member is being extracted. If this attribute is set to 0, errors are ignored. If it’s set to 1, errors result in OSError or IOError exceptions. If it’s set to 2, nonfatal errors additionally result in TarError exceptions.
t.extract(member [, path])
Extracts a member from the archive, saving it to the current directory. member is either an archive member name or a TarInfo instance. path is used to specify a different destination directory.
t.extractfile(member)
Extracts a member from the archive, returning a read-only file-like object that can be used to read its contents using read(), readline(), readlines(), seek(), and tell() operations. member is either an archive member name or a TarInfo object. If member refers to a link, an attempt will be made to open the target of the link.
t.getmember(name)
Looks up archive member name and returns a TarInfo object containing information about it. Raises KeyError if no such archive member exists. If member name appears more than once in the archive, information for the last entry is returned (which is assumed to be the more recent).
t.getmembers()
Returns a list of TarInfo objects for all members of the archive.
t.getnames()
Returns a list of all archive member names.
t.gettarinfo([name [, arcname [, fileobj]]])
Returns a TarInfo object corresponding to a file, name, on the file system or an open file object, fileobj. arcname is an alternative name for the object in the archive. The primary use of this function is to create an appropriate TarInfo object for use in methods such as add().
t.ignore_zeros
If this attribute is set to True, empty blocks are skipped when reading an archive. If it’s set to False (the default), an empty block signals the end of the archive. Setting this method to True may be useful for reading a damaged archive.
t.list([verbose])
Lists the contents of the archive to sys.stdout. verbose determines the level of detail. If this method is set to False, only the archive names are printed. Otherwise, full details are printed (the default).
t.next()
A method used for iterating over the members of an archive. Returns the TarInfo structure for the next archive member or None.
t.posix
If this attribute is set to True, the tar file is created according to the POSIX 1003.1-1990 standard. This places restrictions on filename lengths and file size (filenames must be less than 256 characters and files must be less than 8GB in size). If this attribute is set to False, the archive is created using GNU extensions that lift these restrictions. The default value is False.
Many of the previous methods manipulate TarInfo instances. The following table shows the methods and attributes of a TarInfo instance ti.

Exceptions
The following exceptions are defined by the tarfile module:
TarError
Base class for all other exceptions.
ReadError
Raised when an error occurs while opening a tar file (for example, when opening an invalid file).
CompressionError
Raised when data can’t be decompressed.
StreamError
Raised when an unsupported operation is performed on a stream-like TarFile object (for instance, an operation that requires random access).
ExtractError
Raised for nonfatal errors during extraction (only if errorlevel is set to 2).
Example
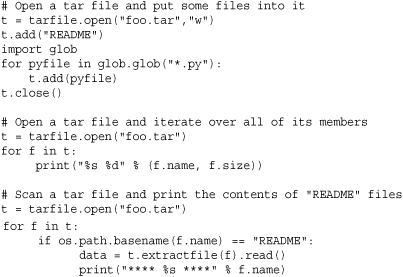
tempfile
The tempfile module is used to generate temporary filenames and files.
mkdtemp([suffix [,prefix [, dir]]])
Creates a temporary directory accessible only by the owner of the calling process and returns its absolute pathname. suffix is an optional suffix that will be appended to the directory name, prefix is an optional prefix that will be inserted at the beginning of the directory name, and dir is a directory where the temporary directory should be created.
mkstemp([suffix [,prefix [, dir [,text]]]])
Creates a temporary file and returns a tuple (fd, pathname), where fd is an integer file descriptor returned by os.open() and pathname is absolute pathname of the file. suffix is an optional suffix appended to the filename, prefix is an optional prefix inserted at the beginning of the filename, dir is the directory in which the file should be created, and text is a boolean flag that indicates whether to open the file in text mode or binary mode (the default). The creation of the file is guaranteed to be atomic (and secure) provided that the system supports the O_EXCL flag for os.open().
mktemp([suffix [, prefix [,dir]]])
Returns a unique temporary filename. suffix is an optional file suffix to append to the filename, prefix is an optional prefix inserted at the beginning of the filename, and dir is the directory in which the file is created. This function only generates a unique filename and doesn’t actually create or open a temporary file. Because this function generates a name before the file is actually opened, it introduces a potential security problem. To address this, consider using mkstemp() instead.
gettempdir()
Returns the directory in which temporary files are created.
gettempprefix()
Returns the prefix used to generate temporary files. Does not include the directory in which the file would reside.
TemporaryFile([mode [, bufsize [, suffix [,prefix [, dir]]]]])
Creates a temporary file using mkstemp() and returns a file-like object that supports the same methods as an ordinary file object. mode is the file mode and defaults to 'w+b'. bufsize specifies the buffering behavior and has the same meaning as for the open() function. suffix, prefix, and dir have the same meaning as for mkstemp(). The object returned by this function is only a wrapper around a built-in file object that’s accessible in the file attribute. The file created by this function is automatically destroyed when the temporary file object is destroyed.
NamedTemporaryFile([mode [, bufsize [, suffix [,prefix [, dir [, delete ]]]]]])
Creates a temporary file just like TemporaryFile() but makes sure the filename is visible on the file system. The filename can be obtained by accessing the name attribute of the returned file object. Note that certain systems may prevent the file from being reopened using this name until the temporary file has been closed. The delete parameter, if set to True (the default), forces the temporary file to be deleted as soon as it is closed.
SpooledTemporaryFile([max_size [, mode [, bufsize [, suffix [, prefix [, dir]]]]]])
Creates a temporary file such as TemporaryFile except that the file contents are entirely held in memory until they exceed the size given in max_size. This internal spooling is implemented by first holding the file contents in a StringIO object until it is necessary to actually go to the file system. If any kind of low-level file I/O operation is performed involving the fileno() method, the memory contents are immediately written to a proper temporary file as defined by the TemporaryFile object. The file object returned by SpooledTemporaryFile also has a method rollover() that can be used to force the contents to be written to the file system.
Two global variables are used to construct temporary names. They can be assigned to new values if desired. Their default values are system-dependent.

Note
By default, the tempfile module creates files by checking a few standard locations. For example, on UNIX, files are created in one of /tmp, /var/tmp, or /usr/tmp. On Windows, files are created in one of C:TEMP, C:TMP, TEMP, or TMP. These directories can be overridden by setting one or more of the TMPDIR, TEMP, and TMP environment variables. If, for whatever reason, temporary files can’t be created in any of the usual locations, they will be created in the current working directory.
zipfile
The zipfile module is used to manipulate files encoded in the popular zip format (originally known as PKZIP, although now supported by a wide variety of programs). Zip files are widely used by Python, mainly for the purpose of packaging. For example, if zip files containing Python source code are added to sys.path, then files contained within the zip file can be loaded via import (the zipimport library module implements this functionality, although it’s never necessary to use that library directly). Packages distributed as .egg files (created by the setuptools extension) are also just zip files in disguise (an .egg file is actually just a zip file with some extra metadata added to it).
The following functions and classes are defined by the zipfile module:
is_zipfile(filename)
Tests filename to see if it’s a valid zip file. Returns True if filename is a zip file; returns False otherwise.
ZipFile(filename [, mode [, compression [,allowZip64]]])
Opens a zip file, filename, and returns a ZipFile instance. mode is 'r' to read from an existing file, 'w' to truncate the file and write a new file, or 'a' to append to an existing file. For 'a' mode, if filename is an existing zip file, new files are added to it. If filename is not a zip file, the archive is simply appended to the end of the file. compression is the zip compression method used when writing to the archive and is either ZIP_STORED or ZIP_DEFLATED. The default is ZIP_STORED. The allowZip64 argument enables the use of ZIP64 extensions, which can be used to create zip files that exceed 2GB in size. By default, this is set to False.
PyZipFile(filename [, mode[, compression [,allowZip64]]])
Opens a zip file like ZipFile() but returns a special PyZipFile instance with one extra method, writepy(), used to add Python source files to the archive.
ZipInfo([filename [, date_time]])
Manually creates a new ZipInfo instance, used to contain information about an archive member. Normally, it’s not necessary to call this function except when using the z.writestr() method of a ZipFile instance (described later). The filename and date_time arguments supply values for the filename and date_time attributes described below.
An instance, z, of ZipFile or PyZipFile supports the following methods and attributes:
z.close()
Closes the archive file. This must be called in order to flush records to the zip file before program termination.
z.debug
Debugging level in the range of 0 (no output) to 3 (most output).
z.extract(name [, path [, pwd ]])
Extracts a file from the archive and places it in the current working directory. name is either a string that fully specifies the archive member or a ZipInfo instance. path specifies a different directory in which the file will extracted, and pwd is the password to use for encrypted archives.
z.extractall([path [members [, pwd]]])
Extracts all members of an archive into the current working directory. path specifies a different directory, and pwd is a password for encrypted archives. members is a list of members to extract, which must be a proper subset of the list returned by the namelist() method (described next).
Returns information about the archive member name as a ZipInfo instance (described shortly).
z.infolist()
Returns a list of ZipInfo objects for all the members of the archive.
z.namelist()
Returns a list of the archive member names.
z.open(name [, mode [, pwd]])
Opens an archive member named name and returns a file-like object for reading the contents. name can either be a string or a ZipInfo instance describing one of the archive members. mode is the file mode and must be one of the read-only file modes such as 'r', 'rU', or 'U'. pwd is the password to use for encrypted archive members. The file object that is returned supports the read(), readline(), and readlines() methods as well as iteration with the for statement.
z.printdir()
Prints the archive directory to sys.stdout.
z.read(name [,pwd])
Reads archive contents for member name and returns the data as a string. name is either a string or a ZipInfo instance describing the archive member. pwd is the password to use for encrypted archive members.
z.setpassword(pwd)
Sets the default password used to extract encrypted files from the archive.
z.testzip()
Reads all the files in the archive and verifies their CRC checksums. Returns the name of the first corrupted file or None if all files are intact.
z.write(filename[, arcname[, compress_type]])
Writes filename to the archive with the archive name arcname. compress_type is the compression parameter and is either ZIP_STORED or ZIP_DEFLATED. By default, the compression parameter given to the ZipFile() or PyZipFile() function is used. The archive must be opened in 'w' or 'a' mode for writes to work.
z.writepy(pathname)
This method, available only with PyZipFile instances, is used to write Python source files (*.py files) to a zip archive and can be used to easily package Python applications for distribution. If pathname is a file, it must end with .py. In this case, one of the corresponding .pyo, .pyc, or .py files will be added (in that order). If pathname is a directory and the directory is not a Python package directory, all the corresponding .pyo, .pyc, or .py files are added at the top level. If the directory is a package, the files are added under the package name as a file path. If any subdirectories are also package directories, they are added recursively.
Writes the string s into the zip file. arcinfo is either a filename within the archive in which the data will be stored or a ZipInfo instance containing a filename, date, and time.
ZipInfo instances i returned by the ZipInfo(), z.getinfo(), and z.infolist() functions have the following attributes:

Note
Detailed documentation about the internal structure of zip files can be found as a PKZIP Application Note at http://www.pkware.com/appnote.html.
zlib
The zlib module supports data compression by providing access to the zlib library.
adler32(string [, value])
Computes the Adler-32 checksum of string. value is used as the starting value (which can be used to compute a checksum over the concatenation of several strings). Otherwise, a fixed default value is used.
compress(string [, level])
Compresses the data in string, where level is an integer from 1 to 9 controlling the level of compression. 1 is the least (fastest) compression, and 9 is the best (slowest) compression. The default value is 6. Returns a string containing the compressed data or raises error if an error occurs.
compressobj([level])
Returns a compression object. level has the same meaning as in the compress() function.
crc32(string [, value])
Computes a CRC checksum of string. If value is present, it’s used as the starting value of the checksum. Otherwise, a fixed value is used.
decompress(string [, wbits [, buffsize]])
Decompresses the data in string. wbits controls the size of the window buffer, and buffsize is the initial size of the output buffer. Raises error if an error occurs.
decompressobj([wbits])
Returns a compression object. The wbits parameter controls the size of the window buffer.
A compression object, c, has the following methods:
c.compress(string)
Compresses string. Returns a string containing compressed data for at least part of the data in string. This data should be concatenated to the output produced by earlier calls to c.compress() to create the output stream. Some input data may be stored in internal buffers for later processing.
c.flush([mode])
Compresses all pending input and returns a string containing the remaining compressed output. mode is Z_SYNC_FLUSH, Z_FULL_FLUSH, or Z_FINISH (the default). Z_SYNC_FLUSH and Z_FULL_FLUSH allow further compression and are used to allow partial error recovery on decompression. Z_FINISH terminates the compression stream.
A decompression object, d, has the following methods and attributes:
d.decompress(string [,max_length])
Decompresses string and returns a string containing uncompressed data for at least part of the data in string. This data should be concatenated with data produced by earlier calls to decompress() to form the output stream. Some input data may be stored in internal buffers for later processing. max_length specifies the maximum size of returned data. If exceeded, unprocessed data will be placed in the d.unconsumed_tail attribute.
d.flush()
All pending input is processed, and a string containing the remaining uncompressed output is returned. The decompression object cannot be used again after this call.
d.unconsumed_tail
String containing data not yet processed by the last decompress() call. This would contain data if decompression needs to be performed in stages due to buffer size limitations. In this case, this variable would be passed to subsequent decompress() calls.
d.unused_data
String containing extra bytes that remain past the end of the compressed data.
Note
The zlib library is available at http://www.zlib.net.