
Caching involves storing results, usually from a function call, in memory or on disk. If done correctly, caching helps by reducing the number of function calls. In general, we want to keep the cache small for space reasons. If we are able to find items in cache, we talk about hits; otherwise, we have misses. Obviously, we want to have as many hits as possible and as few misses as possible. This means that we want to maximize the hits-misses ratio.
Many caching algorithms exist, of which we will cover the least recently used (LRU) algorithm. This algorithm keeps track of when a cache item was used. If the cache is about to exceed its maximum specified size, LRU gets rid of the least recently used item. The reasoning is that these items are possibly older and, therefore, not as relevant any more. There are several variations of LRU. Other algorithms do the opposite—removing the most recent item, the least frequently used item, or a random item.
The standard Python library has an implementation of LRU, but there is also a specialized Python library with some parts implemented in C and it is therefore potentially faster. We will compare the two implementations using the NLTK lemmatize() method (refer to the Stemming, lemmatizing, filtering and TF-IDF scores recipe in Chapter 8, Text Mining and Social Network Analysis).
Install fastcache as follows:
$ pip/conda install fastcache
I tested the code with fastcache 1.0.2.
- The imports are as follows:
from fastcache import clru_cache from functools import lru_cache from nltk.corpus import brown from nltk.stem import WordNetLemmatizer import dautil as dl import numpy as np from IPython.display import HTML
- Define the following function to cache:
def lemmatize(word, lemmatizer): return lemmatizer.lemmatize(word.lower()) - Define the following function to measure the effects of caching:
def measure(impl, words, lemmatizer): cache = dl.perf.LRUCache(impl, lemmatize) times = [] hm = [] for i in range(5, 12): cache.maxsize = 2 ** i cache.cache() with dl.perf.StopWatch() as sw: _ = [cache.cached(w, lemmatizer) for w in words] hm.append(cache.hits_miss()) times.append(sw.elapsed) cache.clear() return (times, hm) - Initialize a list of words and an NLTK
WordNetLemmatizerobject:words = [w for w in brown.words()] lemmatizer = WordNetLemmatizer()
- Measure the execution time as follows:
with dl.perf.StopWatch() as sw: _ = [lemmatizer.lemmatize(w.lower()) for w in words] plain = sw.elapsed times, hm = measure(clru_cache, words, lemmatizer) - Plot the results for different cache sizes:
sp = dl.plotting.Subplotter(2, 2, context) sp.ax.plot(2 ** np.arange(5, 12), times) sp.ax.axhline(plain, lw=2, label='Uncached') sp.label() sp.next_ax().plot(2 ** np.arange(5, 12), hm) sp.label() times, hm = measure(lru_cache, words, lemmatizer) sp.next_ax().plot(2 ** np.arange(5, 12), times) sp.ax.axhline(plain, lw=2, label='Uncached') sp.label() sp.next_ax().plot(2 ** np.arange(5, 12), hm) sp.label() HTML(sp.exit())
Refer to the following screenshot for the end result:
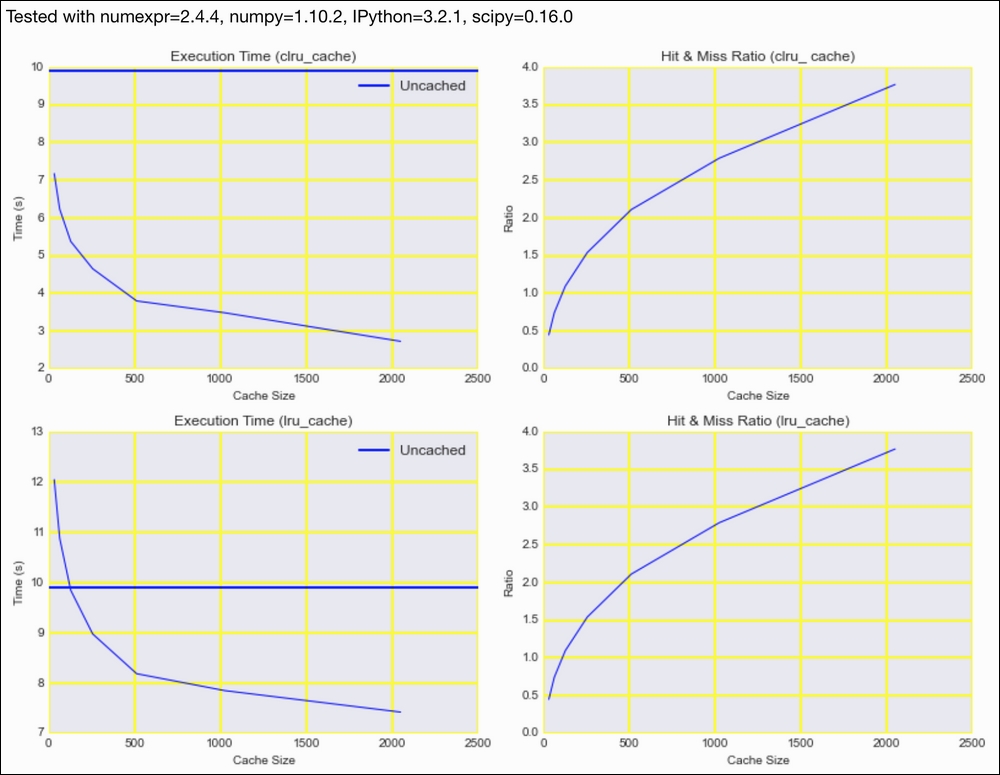
The code is in the caching_lru.ipynb file in this book's code bundle.
- The related Wikipedia page at http://en.wikipedia.org/wiki/Cache_algorithms (retrieved January 2016)
- The fastcache website at https://pypi.python.org/pypi/fastcache (retrieved January 2016)
- The
functools.lru_cachedocumentation at https://docs.python.org/3/library/functools.html#functools.lru_cache (retrieved January 2016)