 News categorization and hierarchical clustering
by Ágnes Vidovics-Dancs, Kata Váradi, Tamás Vadász, Ágnes Tuza, Balázs Árpád Szucs,
R: Data Analysis and Visualization
News categorization and hierarchical clustering
by Ágnes Vidovics-Dancs, Kata Váradi, Tamás Vadász, Ágnes Tuza, Balázs Árpád Szucs,
R: Data Analysis and Visualization
- R: Data Analysis and Visualization
- Table of Contents
- R: Data Analysis and Visualization
- I. Module 1: Data Analysis with R
- 1. RefresheR
- 2. The Shape of Data
- 3. Describing Relationships
- 4. Probability
- 5. Using Data to Reason About the World
- 6. Testing Hypotheses
- 7. Bayesian Methods
- 8. Predicting Continuous Variables
- 9. Predicting Categorical Variables
- 10. Sources of Data
- 11. Dealing with Messy Data
- 12. Dealing with Large Data
- 13. Reproducibility and Best Practices
- II. Module 2: R Graphs
- 1. R Graphics
- 2. Basic Graph Functions
- Introduction
- Creating basic scatter plots
- Creating line graphs
- Creating bar charts
- Creating histograms and density plots
- Creating box plots
- Adjusting x and y axes' limits
- Creating heat maps
- Creating pairs plots
- Creating multiple plot matrix layouts
- Adding and formatting legends
- Creating graphs with maps
- Saving and exporting graphs
- 3. Beyond the Basics – Adjusting Key Parameters
- Introduction
- Setting colors of points, lines, and bars
- Setting plot background colors
- Setting colors for text elements – axis annotations, labels, plot titles, and legends
- Choosing color combinations and palettes
- Setting fonts for annotations and titles
- Choosing plotting point symbol styles and sizes
- Choosing line styles and width
- Choosing box styles
- Adjusting axis annotations and tick marks
- Formatting log axes
- Setting graph margins and dimensions
- 4. Creating Scatter Plots
- Introduction
- Grouping data points within a scatter plot
- Highlighting grouped data points by size and symbol type
- Labeling data points
- Correlation matrix using pairs plots
- Adding error bars
- Using jitter to distinguish closely packed data points
- Adding linear model lines
- Adding nonlinear model curves
- Adding nonparametric model curves with lowess
- Creating three-dimensional scatter plots
- Creating Quantile-Quantile plots
- Displaying the data density on axes
- Creating scatter plots with a smoothed density representation
- 5. Creating Line Graphs and Time Series Charts
- Introduction
- Adding customized legends for multiple-line graphs
- Using margin labels instead of legends for multiple-line graphs
- Adding horizontal and vertical grid lines
- Adding marker lines at specific x and y values using abline
- Creating sparklines
- Plotting functions of a variable in a dataset
- Formatting time series data for plotting
- Plotting the date or time variable on the x axis
- Annotating axis labels in different human-readable time formats
- Adding vertical markers to indicate specific time events
- Plotting data with varying time-averaging periods
- Creating stock charts
- 6. Creating Bar, Dot, and Pie Charts
- Introduction
- Creating bar charts with more than one factor variable
- Creating stacked bar charts
- Adjusting the orientation of bars – horizontal and vertical
- Adjusting bar widths, spacing, colors, and borders
- Displaying values on top of or next to the bars
- Placing labels inside bars
- Creating bar charts with vertical error bars
- Modifying dot charts by grouping variables
- Making better, readable pie charts with clockwise-ordered slices
- Labeling a pie chart with percentage values for each slice
- Adding a legend to a pie chart
- 7. Creating Histograms
- Introduction
- Visualizing distributions as count frequencies or probability densities
- Setting the bin size and the number of breaks
- Adjusting histogram styles – bar colors, borders, and axes
- Overlaying a density line over a histogram
- Multiple histograms along the diagonal of a pairs plot
- Histograms in the margins of line and scatter plots
- 8. Box and Whisker Plots
- Introduction
- Creating box plots with narrow boxes for a small number of variables
- Grouping over a variable
- Varying box widths by the number of observations
- Creating box plots with notches
- Including or excluding outliers
- Creating horizontal box plots
- Changing the box styling
- Adjusting the extent of plot whiskers outside the box
- Showing the number of observations
- Splitting a variable at arbitrary values into subsets
- 9. Creating Heat Maps and Contour Plots
- 10. Creating Maps
- 11. Data Visualization Using Lattice
- Introduction
- Creating bar charts
- Creating stacked bar charts
- Creating bar charts to visualize cross-tabulation
- Creating a conditional histogram
- Visualizing distributions through a kernel-density plot
- Creating a normal Q-Q plot
- Visualizing an empirical Cumulative Distribution Function
- Creating a boxplot
- Creating a conditional scatter plot
- 12. Data Visualization Using ggplot2
- 13. Inspecting Large Datasets
- 14. Three-dimensional Visualizations
- 15. Finalizing Graphs for Publications and Presentations
- Introduction
- Exporting graphs in high-resolution image formats – PNG, JPEG, BMP, and TIFF
- Exporting graphs in vector formats – SVG, PDF, and PS
- Adding mathematical and scientific notations (typesetting)
- Adding text descriptions to graphs
- Using graph templates
- Choosing font families and styles under Windows, Mac OS X, and Linux
- Choosing fonts for PostScripts and PDFs
- III. Module 3: Learning Data Mining with R
- 1. Warming Up
- 2. Mining Frequent Patterns, Associations, and Correlations
- An overview of associations and patterns
- Market basket analysis
- Hybrid association rules mining
- Mining sequence dataset
- The R implementation
- High-performance algorithms
- 3. Classification
- Classification
- Generic decision tree induction
- High-value credit card customers classification using ID3
- Web spam detection using C4.5
- Web key resource page judgment using CART
- Trojan traffic identification method and Bayes classification
- Identify spam e-mail and Naïve Bayes classification
- Rule-based classification of player types in computer games and rule-based classification
- 4. Advanced Classification
- 5. Cluster Analysis
- 6. Advanced Cluster Analysis
- Customer categorization analysis of e-commerce and DBSCAN
- Clustering web pages and OPTICS
- Visitor analysis in the browser cache and DENCLUE
- Recommendation system and STING
- Web sentiment analysis and CLIQUE
- Opinion mining and WAVE clustering
- User search intent and the EM algorithm
- Customer purchase data analysis and clustering high-dimensional data
- SNS and clustering graph and network data
- 7. Outlier Detection
- Credit card fraud detection and statistical methods
- Activity monitoring – the detection of fraud involving mobile phones and proximity-based methods
- Intrusion detection and density-based methods
- Intrusion detection and clustering-based methods
- Monitoring the performance of the web server and classification-based methods
- Detecting novelty in text, topic detection, and mining contextual outliers
- Collective outliers on spatial data
- Outlier detection in high-dimensional data
- 8. Mining Stream, Time-series, and Sequence Data
- 9. Graph Mining and Network Analysis
- 10. Mining Text and Web Data
- IV. Module 4: Mastering R for Quantitative Finance
- 1. Time Series Analysis
- 2. Factor Models
- 3. Forecasting Volume
- 4. Big Data – Advanced Analytics
- 5. FX Derivatives
- 6. Interest Rate Derivatives and Models
- 7. Exotic Options
- A general pricing approach
- The role of dynamic hedging
- How R can help a lot
- A glance beyond vanillas
- Greeks – the link back to the vanilla world
- Pricing the Double-no-touch option
- Another way to price the Double-no-touch option
- The life of a Double-no-touch option – a simulation
- Exotic options embedded in structured products
- References
- 8. Optimal Hedging
- 9. Fundamental Analysis
- 10. Technical Analysis, Neural Networks, and Logoptimal Portfolios
- 11. Asset and Liability Management
- 12. Capital Adequacy
- 13. Systemic Risks
- V. Module 5: Machine Learning with R module
- 1. Introducing Machine Learning
- 2. Managing and Understanding Data
- R data structures
- Managing data with R
- Exploring and understanding data
- Exploring the structure of data
- Exploring numeric variables
- Measuring the central tendency – mean and median
- Measuring spread – quartiles and the five-number summary
- Visualizing numeric variables – boxplots
- Visualizing numeric variables – histograms
- Understanding numeric data – uniform and normal distributions
- Measuring spread – variance and standard deviation
- Exploring categorical variables
- Exploring relationships between variables
- 3. Lazy Learning – Classification Using Nearest Neighbors
- 4. Probabilistic Learning – Classification Using Naive Bayes
- 5. Divide and Conquer – Classification Using Decision Trees and Rules
- Understanding decision trees
- Example – identifying risky bank loans using C5.0 decision trees
- Understanding classification rules
- Example – identifying poisonous mushrooms with rule learners
- 6. Forecasting Numeric Data – Regression Methods
- Understanding regression
- Example – predicting medical expenses using linear regression
- Understanding regression trees and model trees
- Example – estimating the quality of wines with regression trees and model trees
- 7. Black Box Methods – Neural Networks and Support Vector Machines
- 8. Finding Patterns – Market Basket Analysis Using Association Rules
- 9. Finding Groups of Data – Clustering with k-means
- 10. Evaluating Model Performance
- 11. Improving Model Performance
- 12. Specialized Machine Learning Topics
- Working with proprietary files and databases
- Working with online data and services
- Working with domain-specific data
- Improving the performance of R
- Managing very large datasets
- Learning faster with parallel computing
- GPU computing
- Deploying optimized learning algorithms
- Building bigger regression models with biglm
- Growing bigger and faster random forests with bigrf
- Training and evaluating models in parallel with caret
- A. Reflect and Test Yourself Answers
- Module 1: Data Analysis with R
- Chapter 1: RefresheR
- Chapter 2: The Shape of Data
- Chapter 3: Describing Relationships
- Chapter 4: Probability
- Chapter 5: Using Data to Reason About the World
- Chapter 6: Testing Hypotheses
- Chapter 7: Bayesian Methods
- Chapter 8: Predicting Continuous Variables
- Chapter 9: Predicting Categorical Variables
- Chapter 10: Sources of Data
- Chapter 11: Dealing with Messy Data
- Chapter 12: Dealing with Large Data
- Module 2: R Graphs
- Chapter 1: R Graphics
- Chapter 2: Basic Graph Functions
- Chapter 3: Beyond the Basics – Adjusting Key Parameters
- Chapter 4: Creating Scatter Plots
- Chapter 5: Creating Line Graphs and Time Series Charts
- Chapter 6: Creating Bar, Dot, and Pie Charts
- Chapter 7: Creating Histograms
- Chapter 8: Box and Whisker Plots
- Chapter 9: Creating Heat Maps and Contour Plots
- Module 4: Mastering R for Quantitative Finance
- Module 5: Machine Learning with R
- Chapter 1: Introducing Machine Learning
- Chapter 2: Managing and Understanding Data
- Chapter 3: Lazy Learning – Classification Using Nearest Neighbors
- Chapter 4: Probabilistic Learning – Classification Using Naive Bayes
- Chapter 5: Divide and Conquer – Classification Using Decision Trees and Rules
- Chapter 6: Forecasting Numeric Data – Regression Methods
- Chapter 7: Black Box Methods – Neural Networks and Support Vector Machines
- Chapter 8: Finding Patterns – Market Basket Analysis Using Association Rules
- Module 1: Data Analysis with R
- B. Bibliography
- Index
Hierarchical clustering divides the target dataset into multilevels or a hierarchy of clusters. It segments data points along with successive partitions.
There are two strategies for hierarchical clustering. Agglomerative clustering starts with each data object in the input dataset as a cluster, and then in the following steps, clusters are merged according to certain similarity measures that end in only one cluster. Divisive clustering, in contrast, starts with one cluster with all the data objects in the input dataset as members, and then, the cluster splits according to certain similarity measures in the following steps, and at the end, singleton clusters of individual data objects are left.
The characteristics of hierarchical clustering methods are as follows:
- Multilevel decomposition.
- The merges or splits cannot perform a rollback. The error in the algorithm that is introduced by merging or splitting cannot be corrected.
- The hybrid algorithm.

The BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) algorithm is designed for large dynamic datasets and can also be applied to incremental and dynamic clustering. Only one pass of dataset is required, and this means that there is no need to read the whole dataset in advance.
CF-Tree is a helper data structure that is used to store the summary of clusters, and it is also a representative of a cluster. Each node in the CF-Tree is declared as a list of entries, ![]() , and
, and B is the predefined entry limitation. ![]() denotes the link to the ith child.
denotes the link to the ith child.
Given ![]() as the representative of cluster i, is defined as
as the representative of cluster i, is defined as ![]() , where
, where ![]() is the member count of the cluster, LS is the linear sum of the member objects, and SS is the squared sum of the member objects.
is the member count of the cluster, LS is the linear sum of the member objects, and SS is the squared sum of the member objects.
The leave of the CF-Tree must conform to the diameter limitation. The diameter of the  cluster must be less than the predefined threshold value, T.
cluster must be less than the predefined threshold value, T.
The main helper algorithms in BIRCH are CF-Tree insertion and CF-Tree rebuilding.
The summarized pseudocode for the BIRCH algorithm is as follows:

The overall framework for the chameleon algorithm is illustrated in the following diagram:

There are three main steps in the chameleon algorithm, which are as follows:
- Sparsification: This step is to generate a k-Nearest Neighbor graph, which is derived from a proximity graph.
- Graph partitioning: This step applies a multilevel graph-partitioning algorithm to partition the dataset. The initial graph is an all-inclusive graph or cluster. This then bisects the largest graph in each successive step, and finally, we get a group of roughly, equally-sized clusters (with high intrasimilarity). Each resulting cluster has a size not more than a predefined size, that is,
MIN_SIZE. - Agglomerative hierarchical clustering: This last step is where the clusters are merged based on self-similarity. The notion of self-similarity is defined with the RI and RC; they can be combined in various ways to be a measure of self-similarity.
Relative Closeness (RC), given the ![]() and
and ![]() clusters with sizes
clusters with sizes ![]() and
and ![]() , respectively.
, respectively. ![]() denotes the average weight of the edges that connect the two clusters.
denotes the average weight of the edges that connect the two clusters. ![]() denotes the average weight of the edges that bisect the
denotes the average weight of the edges that bisect the ![]() cluster:
cluster:

Relative Interconnectivity (RI) is defined in the following equation. Here, ![]() is the sum of the edges to connect the two clusters, and
is the sum of the edges to connect the two clusters, and ![]() is the minimum sum of the cut edges that bisect the
is the minimum sum of the cut edges that bisect the ![]() cluster:
cluster:
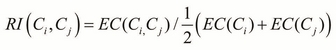
The summarized pseudocode for the chameleon algorithm is as follows:


The probabilistic hierarchical clustering algorithm is a hybrid of hierarchical clustering and probabilistic clustering algorithms. As a probabilistic clustering algorithm, it applies a completely probabilistic approach, as depicted here:

Take a look at the ch_05_ahclustering.R R code file from the bundle of R code for the previously mentioned algorithms. The codes can be tested with the following command:
> source("ch_05_ahclustering.R")
News portals provide visitors with tremendous news categorized with a predefined set of topics. With the exponential growth of information we receive from the Internet, clustering technologies are widely used for web documents categorization, which include online news. These are often news streams or news feeds.
One advantage of a clustering algorithm for this task is that there is no need for prior domain knowledge. News can be summarized by clustering news that covers specific events. Unsupervised clustering can also play a pivotal role in discovering the intrinsic topical structure of the existing text collections, while new categorization is used to classify the documents according to a predefined set of classes.
Services such as Google News are provided. For a story published by a couple of new agencies or even the same agency, there are often various versions that exist at the same time or span the same range of days. Here, clustering can help aggregate the news related to the same story, and the result is a better overview of the current story for visitors.
As preprocessing steps, plain texts are extracted from the web pages or news pages. Reuters-22173 and -21578 are two popular documents dataset used for research. The representation of a data instance in the dataset can either be classical term-document vectors or term-sentence vectors, as the dataset is a collection of documents, and the cosine-like measures are applied here.


-
No Comment