 Advanced topics
by Ágnes Vidovics-Dancs, Kata Váradi, Tamás Vadász, Ágnes Tuza, Balázs Árpád Szucs,
R: Data Analysis and Visualization
Advanced topics
by Ágnes Vidovics-Dancs, Kata Váradi, Tamás Vadász, Ágnes Tuza, Balázs Árpád Szucs,
R: Data Analysis and Visualization
- R: Data Analysis and Visualization
- Table of Contents
- R: Data Analysis and Visualization
- I. Module 1: Data Analysis with R
- 1. RefresheR
- 2. The Shape of Data
- 3. Describing Relationships
- 4. Probability
- 5. Using Data to Reason About the World
- 6. Testing Hypotheses
- 7. Bayesian Methods
- 8. Predicting Continuous Variables
- 9. Predicting Categorical Variables
- 10. Sources of Data
- 11. Dealing with Messy Data
- 12. Dealing with Large Data
- 13. Reproducibility and Best Practices
- II. Module 2: R Graphs
- 1. R Graphics
- 2. Basic Graph Functions
- Introduction
- Creating basic scatter plots
- Creating line graphs
- Creating bar charts
- Creating histograms and density plots
- Creating box plots
- Adjusting x and y axes' limits
- Creating heat maps
- Creating pairs plots
- Creating multiple plot matrix layouts
- Adding and formatting legends
- Creating graphs with maps
- Saving and exporting graphs
- 3. Beyond the Basics – Adjusting Key Parameters
- Introduction
- Setting colors of points, lines, and bars
- Setting plot background colors
- Setting colors for text elements – axis annotations, labels, plot titles, and legends
- Choosing color combinations and palettes
- Setting fonts for annotations and titles
- Choosing plotting point symbol styles and sizes
- Choosing line styles and width
- Choosing box styles
- Adjusting axis annotations and tick marks
- Formatting log axes
- Setting graph margins and dimensions
- 4. Creating Scatter Plots
- Introduction
- Grouping data points within a scatter plot
- Highlighting grouped data points by size and symbol type
- Labeling data points
- Correlation matrix using pairs plots
- Adding error bars
- Using jitter to distinguish closely packed data points
- Adding linear model lines
- Adding nonlinear model curves
- Adding nonparametric model curves with lowess
- Creating three-dimensional scatter plots
- Creating Quantile-Quantile plots
- Displaying the data density on axes
- Creating scatter plots with a smoothed density representation
- 5. Creating Line Graphs and Time Series Charts
- Introduction
- Adding customized legends for multiple-line graphs
- Using margin labels instead of legends for multiple-line graphs
- Adding horizontal and vertical grid lines
- Adding marker lines at specific x and y values using abline
- Creating sparklines
- Plotting functions of a variable in a dataset
- Formatting time series data for plotting
- Plotting the date or time variable on the x axis
- Annotating axis labels in different human-readable time formats
- Adding vertical markers to indicate specific time events
- Plotting data with varying time-averaging periods
- Creating stock charts
- 6. Creating Bar, Dot, and Pie Charts
- Introduction
- Creating bar charts with more than one factor variable
- Creating stacked bar charts
- Adjusting the orientation of bars – horizontal and vertical
- Adjusting bar widths, spacing, colors, and borders
- Displaying values on top of or next to the bars
- Placing labels inside bars
- Creating bar charts with vertical error bars
- Modifying dot charts by grouping variables
- Making better, readable pie charts with clockwise-ordered slices
- Labeling a pie chart with percentage values for each slice
- Adding a legend to a pie chart
- 7. Creating Histograms
- Introduction
- Visualizing distributions as count frequencies or probability densities
- Setting the bin size and the number of breaks
- Adjusting histogram styles – bar colors, borders, and axes
- Overlaying a density line over a histogram
- Multiple histograms along the diagonal of a pairs plot
- Histograms in the margins of line and scatter plots
- 8. Box and Whisker Plots
- Introduction
- Creating box plots with narrow boxes for a small number of variables
- Grouping over a variable
- Varying box widths by the number of observations
- Creating box plots with notches
- Including or excluding outliers
- Creating horizontal box plots
- Changing the box styling
- Adjusting the extent of plot whiskers outside the box
- Showing the number of observations
- Splitting a variable at arbitrary values into subsets
- 9. Creating Heat Maps and Contour Plots
- 10. Creating Maps
- 11. Data Visualization Using Lattice
- Introduction
- Creating bar charts
- Creating stacked bar charts
- Creating bar charts to visualize cross-tabulation
- Creating a conditional histogram
- Visualizing distributions through a kernel-density plot
- Creating a normal Q-Q plot
- Visualizing an empirical Cumulative Distribution Function
- Creating a boxplot
- Creating a conditional scatter plot
- 12. Data Visualization Using ggplot2
- 13. Inspecting Large Datasets
- 14. Three-dimensional Visualizations
- 15. Finalizing Graphs for Publications and Presentations
- Introduction
- Exporting graphs in high-resolution image formats – PNG, JPEG, BMP, and TIFF
- Exporting graphs in vector formats – SVG, PDF, and PS
- Adding mathematical and scientific notations (typesetting)
- Adding text descriptions to graphs
- Using graph templates
- Choosing font families and styles under Windows, Mac OS X, and Linux
- Choosing fonts for PostScripts and PDFs
- III. Module 3: Learning Data Mining with R
- 1. Warming Up
- 2. Mining Frequent Patterns, Associations, and Correlations
- An overview of associations and patterns
- Market basket analysis
- Hybrid association rules mining
- Mining sequence dataset
- The R implementation
- High-performance algorithms
- 3. Classification
- Classification
- Generic decision tree induction
- High-value credit card customers classification using ID3
- Web spam detection using C4.5
- Web key resource page judgment using CART
- Trojan traffic identification method and Bayes classification
- Identify spam e-mail and Naïve Bayes classification
- Rule-based classification of player types in computer games and rule-based classification
- 4. Advanced Classification
- 5. Cluster Analysis
- 6. Advanced Cluster Analysis
- Customer categorization analysis of e-commerce and DBSCAN
- Clustering web pages and OPTICS
- Visitor analysis in the browser cache and DENCLUE
- Recommendation system and STING
- Web sentiment analysis and CLIQUE
- Opinion mining and WAVE clustering
- User search intent and the EM algorithm
- Customer purchase data analysis and clustering high-dimensional data
- SNS and clustering graph and network data
- 7. Outlier Detection
- Credit card fraud detection and statistical methods
- Activity monitoring – the detection of fraud involving mobile phones and proximity-based methods
- Intrusion detection and density-based methods
- Intrusion detection and clustering-based methods
- Monitoring the performance of the web server and classification-based methods
- Detecting novelty in text, topic detection, and mining contextual outliers
- Collective outliers on spatial data
- Outlier detection in high-dimensional data
- 8. Mining Stream, Time-series, and Sequence Data
- 9. Graph Mining and Network Analysis
- 10. Mining Text and Web Data
- IV. Module 4: Mastering R for Quantitative Finance
- 1. Time Series Analysis
- 2. Factor Models
- 3. Forecasting Volume
- 4. Big Data – Advanced Analytics
- 5. FX Derivatives
- 6. Interest Rate Derivatives and Models
- 7. Exotic Options
- A general pricing approach
- The role of dynamic hedging
- How R can help a lot
- A glance beyond vanillas
- Greeks – the link back to the vanilla world
- Pricing the Double-no-touch option
- Another way to price the Double-no-touch option
- The life of a Double-no-touch option – a simulation
- Exotic options embedded in structured products
- References
- 8. Optimal Hedging
- 9. Fundamental Analysis
- 10. Technical Analysis, Neural Networks, and Logoptimal Portfolios
- 11. Asset and Liability Management
- 12. Capital Adequacy
- 13. Systemic Risks
- V. Module 5: Machine Learning with R module
- 1. Introducing Machine Learning
- 2. Managing and Understanding Data
- R data structures
- Managing data with R
- Exploring and understanding data
- Exploring the structure of data
- Exploring numeric variables
- Measuring the central tendency – mean and median
- Measuring spread – quartiles and the five-number summary
- Visualizing numeric variables – boxplots
- Visualizing numeric variables – histograms
- Understanding numeric data – uniform and normal distributions
- Measuring spread – variance and standard deviation
- Exploring categorical variables
- Exploring relationships between variables
- 3. Lazy Learning – Classification Using Nearest Neighbors
- 4. Probabilistic Learning – Classification Using Naive Bayes
- 5. Divide and Conquer – Classification Using Decision Trees and Rules
- Understanding decision trees
- Example – identifying risky bank loans using C5.0 decision trees
- Understanding classification rules
- Example – identifying poisonous mushrooms with rule learners
- 6. Forecasting Numeric Data – Regression Methods
- Understanding regression
- Example – predicting medical expenses using linear regression
- Understanding regression trees and model trees
- Example – estimating the quality of wines with regression trees and model trees
- 7. Black Box Methods – Neural Networks and Support Vector Machines
- 8. Finding Patterns – Market Basket Analysis Using Association Rules
- 9. Finding Groups of Data – Clustering with k-means
- 10. Evaluating Model Performance
- 11. Improving Model Performance
- 12. Specialized Machine Learning Topics
- Working with proprietary files and databases
- Working with online data and services
- Working with domain-specific data
- Improving the performance of R
- Managing very large datasets
- Learning faster with parallel computing
- GPU computing
- Deploying optimized learning algorithms
- Building bigger regression models with biglm
- Growing bigger and faster random forests with bigrf
- Training and evaluating models in parallel with caret
- A. Reflect and Test Yourself Answers
- Module 1: Data Analysis with R
- Chapter 1: RefresheR
- Chapter 2: The Shape of Data
- Chapter 3: Describing Relationships
- Chapter 4: Probability
- Chapter 5: Using Data to Reason About the World
- Chapter 6: Testing Hypotheses
- Chapter 7: Bayesian Methods
- Chapter 8: Predicting Continuous Variables
- Chapter 9: Predicting Categorical Variables
- Chapter 10: Sources of Data
- Chapter 11: Dealing with Messy Data
- Chapter 12: Dealing with Large Data
- Module 2: R Graphs
- Chapter 1: R Graphics
- Chapter 2: Basic Graph Functions
- Chapter 3: Beyond the Basics – Adjusting Key Parameters
- Chapter 4: Creating Scatter Plots
- Chapter 5: Creating Line Graphs and Time Series Charts
- Chapter 6: Creating Bar, Dot, and Pie Charts
- Chapter 7: Creating Histograms
- Chapter 8: Box and Whisker Plots
- Chapter 9: Creating Heat Maps and Contour Plots
- Module 4: Mastering R for Quantitative Finance
- Module 5: Machine Learning with R
- Chapter 1: Introducing Machine Learning
- Chapter 2: Managing and Understanding Data
- Chapter 3: Lazy Learning – Classification Using Nearest Neighbors
- Chapter 4: Probabilistic Learning – Classification Using Naive Bayes
- Chapter 5: Divide and Conquer – Classification Using Decision Trees and Rules
- Chapter 6: Forecasting Numeric Data – Regression Methods
- Chapter 7: Black Box Methods – Neural Networks and Support Vector Machines
- Chapter 8: Finding Patterns – Market Basket Analysis Using Association Rules
- Module 1: Data Analysis with R
- B. Bibliography
- Index
Linear models are the biggest idea in applied statistics and predictive analytics. There are massive volumes written about the smallest details of linear regression. As such, there are some important ideas that we can't go over here because of space concerns, or because it requires knowledge beyond the scope of this book. So you don't feel like you're in the dark, though, here are some of the topics we didn't cover—and that I would have liked to—and why they are neat.
- Regularization: Regularization was mentioned briefly in the subsection about balancing bias and variance. In this context, regularization is a technique wherein we penalize models for complexity, to varying degrees. My favorite method of regularizing linear models is by using elastic-net regression. It is a fantastic technique and, if you are interested in learning more about it, I suggest you install and read the vignette of the
glmnetpackage:> install.packages("glmnet") > library(glmnet) > vignette("glmnet_beta") - Non-linear modeling: Surprisingly, we can model highly non-linear relationships using linear regression. For example, let's say we wanted to build a model that predicts how many raisins to use for a cookie using the cookie's radius as a predictor. The relationship between predictor and target is no longer linear—it's quadratic. However, if we create a new predictor that is the radius squared, the target will now have a linear relationship with the new predictor, and thus, can be captured using linear regression. This basic premise can be extended to capture relationships that are cubic (power of 3), quartic (power of 4), and so on; this is called polynomial regression. Other forms of non-linear modeling don't use polynomial features, but instead, directly fit non-linear functions to the predictors. Among these forms include regression splines and Generalized Additive Models (GAMs).
- Interaction terms: Just like there are generalizations of linear regression that remove the requirement of linearity, so too are there generalizations of linear regressions that eliminate the need for the strictly additive and independent effects between predictors.
Take grapefruit juice, for example. Grapefruit juice is well known to block intestinal enzyme CYP3A, and drastically effect how the body absorbs certain medicines. Let's pretend that grapefruit juice was mildly effective at treating existential dysphoria. And suppose there is a drug called Soma that was highly effective at treating this condition. When alleviation of symptoms is plotted as a function of dose, the grapefruit juice will have a very small slope, but the Soma will have a very large slope. Now, if we also pretend that grapefruit juice increases the efficiency of Soma absorption, then the relief of dysphoria of someone taking both grapefruit juice and Soma will be far higher than would be predicted by a multiple regression model that doesn't take into account the synergistic effects of Soma and the juice. The simplest way to model this interaction effect is to include the interaction term in the
lmformula, like so:> my.model <- lm(relief ~ soma*juice, data=my.data)
which builds a linear regression formula of the following form:

where if
 is larger than
is larger than 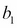 and
and  then there is an interaction effect that is being modeled. On the other hand, if is zero and and are positive, that suggests that the grapefruit juice completely blocks the effect of Soma (and vice versa).
then there is an interaction effect that is being modeled. On the other hand, if is zero and and are positive, that suggests that the grapefruit juice completely blocks the effect of Soma (and vice versa). - Bayesian linear regression: Bayesian linear regression is an alternative approach to the preceding methods that offers a lot of compelling benefits. One of the major benefits of Bayesian linear regression—which echoes the benefits of Bayesian methods as a whole—is that we obtain a posterior distribution of credible values for each of the beta coefficients. This makes it easy to make probabilistic statements about intervals in which the population coefficient is likely to lie. This makes hypothesis testing very easy.
Another major benefit is that we are no longer held hostage to the assumption that the residuals are normally distributed. If you were the good person you lay claim to being on your online dating profiles, you would have done the exercises at the end of the last chapter. If so, you would have seen how we could use the t-distribution to make our models more robust to the influence of outliers. In Bayesian linear regression, it is easy to use a t-distributed likelihood function to describe the distribution of the residuals. Lastly, by adjusting the priors on the beta coefficients and making them sharply peaked at zero, we achieve a certain amount of shrinkage regularization for free, and build models that are inherently resistant to overfitting.


-
No Comment