
In this chapter, we consider some advanced time series methods and their implementation using R. Time series analysis, as a discipline, is broad enough to fill hundreds of books (the most important references, both in theory and R programming, will be listed at the end of this chapter's reading list); hence, the scope of this chapter is necessarily highly selective, and we focus on topics that are inevitably important in empirical finance and quantitative trading. It should be emphasized at the beginning, however, that this chapter only sets the stage for further studies in time series analysis.
Our previous book Introduction to R for Quantitative Finance, Packt Publishing, discusses some fundamental topics of time series analysis such as linear, univariate time series modeling, Autoregressive integrated moving average (ARIMA), and volatility modeling Generalized Autoregressive Conditional Heteroskedasticity (GARCH). If you have never worked with R for time series analysis, you might want to consider going through Chapter 1, Time Series Analysis of that book as well.
The current edition goes further in all of these topics and you will become familiar with some important concepts such as cointegration, vector autoregressive models, impulse-response functions, volatility modeling with asymmetric GARCH models including exponential GARCH and Threshold GARCH models, and news impact curves. We first introduce the relevant theories, then provide some practical insights to multivariate time series modeling, and describe several useful R packages and functionalities. In addition, using simple and illustrative examples, we give a step-by-step introduction to the usage of R programming language for empirical analysis.
The basic issues regarding the movements of financial asset prices, technical analysis, and quantitative trading are usually formulated in a univariate context. Can we predict whether the price of a security will move up or down? Is this particular security in an upward or a downward trend? Should we buy or sell it? These are all important considerations; however, investors usually face a more complex situation and rarely see the market as just a pool of independent instruments and decision problems.
By looking at the instruments individually, they might seem non-autocorrelated and unpredictable in mean, as indicated by the Efficient Market Hypothesis, however, correlation among them is certainly present. This might be exploited by trading activity, either for speculation or for hedging purposes. These considerations justify the use of multivariate time series techniques in quantitative finance. In this chapter, we will discuss two prominent econometric concepts with numerous applications in finance. They are cointegration and vector autoregression models.
From now on, we will consider a vector of time series ![]() , which consists of the elements
, which consists of the elements ![]() each of them individually representing a time series, for instance, the price evolution of different financial products. Let's begin with the formal definition of cointegrating data series.
each of them individually representing a time series, for instance, the price evolution of different financial products. Let's begin with the formal definition of cointegrating data series.
The ![]() vector
vector ![]() of time series is said to be cointegrated if each of the series are individually integrated in the order
of time series is said to be cointegrated if each of the series are individually integrated in the order ![]() (in particular, in most of the applications the series are integrated of order 1, which means nonstationary unit-root processes, or random walks), while there exists a linear combination of the series
(in particular, in most of the applications the series are integrated of order 1, which means nonstationary unit-root processes, or random walks), while there exists a linear combination of the series ![]() , which is integrated in the order
, which is integrated in the order ![]() (typically, it is of order 0, which is a stationary process).
(typically, it is of order 0, which is a stationary process).
Intuitively, this definition implies the existence of some underlying forces in the economy that are keeping together the n time series in the long run, even if they all seem to be individually random walks. A simple example for cointegrating time series is the following pair of vectors, taken from Hamilton (1994), which we will use to study cointegration, and at the same time, familiarize ourselves with some basic simulation techniques in R:
The unit root in ![]() will be shown formally by standard statistical tests. Unit root tests in R can be performed using either the
will be shown formally by standard statistical tests. Unit root tests in R can be performed using either the tseries package or the urca package; here, we use the second one. The following R code simulates the two series of length 1000:
#generate the two time series of length 1000 set.seed(20140623) #fix the random seed N <- 1000 #define length of simulation x <- cumsum(rnorm(N)) #simulate a normal random walk gamma <- 0.7 #set an initial parameter value y <- gamma * x + rnorm(N) #simulate the cointegrating series plot(x, type='l') #plot the two series lines(y,col="red")
The output of the preceding code is as follows:

By visual inspection, both series seem to be individually random walks. Stationarity can be tested by the Augmented Dickey Fuller test, using the urca package; however, many other tests are also available in R.
The null hypothesis states that there is a unit root in the process (outputs omitted); we reject the null if the test statistic is smaller than the critical value:
#statistical tests install.packages('urca');library('urca') #ADF test for the simulated individual time series summary(ur.df(x,type="none")) summary(ur.df(y,type="none"))
For both of the simulated series, the test statistic is larger than the critical value at the usual significance levels (1 percent, 5 percent, and 10 percent); therefore, we cannot reject the null hypothesis, and we conclude that both the series are individually unit root processes.
Now, take the following linear combination of the two series and plot the resulted series:
z = y - gamma*x #take a linear combination of the series plot(z,type='l')
The output for the preceding code is as follows:
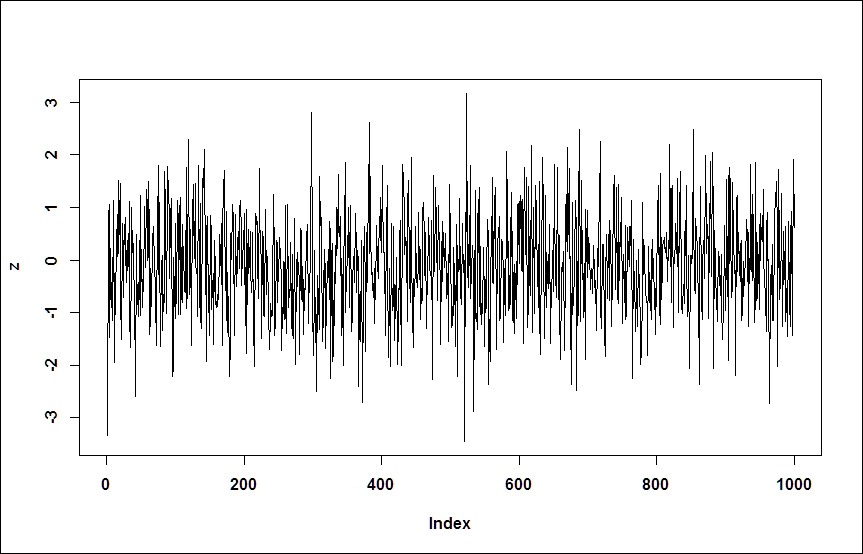
![]() clearly seems to be a white noise process; the rejection of the unit root is confirmed by the results of ADF tests:
clearly seems to be a white noise process; the rejection of the unit root is confirmed by the results of ADF tests:
summary(ur.df(z,type="none"))
In a real-world application, obviously we don't know the value of ![]() ; this has to be estimated based on the raw data, by running a linear regression of one series on the other. This is known as the Engle-Granger method of testing cointegration. The following two steps are known as the Engle-Granger method of testing cointegration:
; this has to be estimated based on the raw data, by running a linear regression of one series on the other. This is known as the Engle-Granger method of testing cointegration. The following two steps are known as the Engle-Granger method of testing cointegration:
Simple linear regressions can be fitted by using the lm function. The residuals can be obtained from the resulting object as shown in the following example. The ADF test is run in the usual way and confirms the rejection of the null hypothesis at all significant levels. Some caveats, however, will be discussed later in the chapter:
#Estimate the cointegrating relationship coin <- lm(y ~ x -1) #regression without intercept coin$resid #obtain the residuals summary(ur.df(coin$resid)) #ADF test of residuals
Now, consider how we could turn this theory into a successful trading strategy. At this point, we should invoke the concept of statistical arbitrage or pair trading, which, in its simplest and early form, exploits exactly this cointegrating relationship. These approaches primarily aim to set up a trading strategy based on the spread between two time series; if the series are cointegrated, we expect their stationary linear combination to revert to 0. We can make profit simply by selling the relatively expensive one and buying the cheaper one, and just sit and wait for the reversion.
What is the economic intuition behind this idea? The linear combination of time series that forms the cointegrating relationship is determined by underlying economic forces, which are not explicitly identified in our statistical model, and are sometimes referred to as long-term relationships between the variables in question. For example, similar companies in the same industry are expected to grow similarly, the spot and forward price of a financial product are bound together by the no-arbitrage principle, FX rates of countries that are somehow interlinked are expected to move together, or short-term and long-term interest rates tend to be close to each other. Deviances from this statistically or theoretically expected comovements open the door to various quantitative trading strategies where traders speculate on future corrections.
The concept of cointegration is further discussed in a later chapter, but for that, we need to introduce vector autoregressive models.
Vector autoregressive models (VAR) can be considered as obvious multivariate extensions of the univariate autoregressive (AR) models. Their popularity in applied econometrics goes back to the seminal paper of Sims (1980). VAR models are the most important multivariate time series models with numerous applications in econometrics and finance. The R package vars provide an excellent framework for R users. For a detailed review of this package, we refer to Pfaff (2013). For econometric theory, consult Hamilton (1994), Lütkepohl (2007), Tsay (2010), or Martin et al. (2013). In this book, we only provide a concise, intuitive summary of the topic.
In a VAR model, our point of departure is a vector of time series ![]() of length
of length ![]() . The VAR model specifies the evolution of each variable as a linear function of the lagged values of all other variables; that is, a VAR model of the order p is the following:
. The VAR model specifies the evolution of each variable as a linear function of the lagged values of all other variables; that is, a VAR model of the order p is the following:
Here, ![]() are
are ![]() the coefficient matrices for all
the coefficient matrices for all ![]() , and
, and ![]() is a vector white noise process with a positive definite covariance matrix. The terminology of vector white noise assumes lack of autocorrelation, but allows contemporaneous correlation between the components; that is,
is a vector white noise process with a positive definite covariance matrix. The terminology of vector white noise assumes lack of autocorrelation, but allows contemporaneous correlation between the components; that is, ![]() has a non-diagonal covariance matrix.
has a non-diagonal covariance matrix.
The matrix notation makes clear one particular feature of VAR models: all variables depend only on past values of themselves and other variables, meaning that contemporaneous dependencies are not explicitly modeled. This feature allows us to estimate the model by ordinary least squares, applied equation-by-equation. Such models are called reduced form VAR models, as opposed to structural form models, discussed in the next section.
Obviously, assuming that there are no contemporaneous effects would be an oversimplification, and the resulting impulse-response relationships, that is, changes in the processes followed by a shock hitting a particular variable, would be misleading and not particularly useful. This motivates the introduction of structured VAR (SVAR) models, which explicitly models the contemporaneous effects among variables:
Here, ![]() and
and ![]() ; thus, the structural form can be obtained from the reduced form by multiplying it with an appropriate parameter matrix
; thus, the structural form can be obtained from the reduced form by multiplying it with an appropriate parameter matrix ![]() , which reflects the contemporaneous, structural relations among the variables.
, which reflects the contemporaneous, structural relations among the variables.
In the reduced form model, contemporaneous dependencies are not modeled; therefore, such dependencies appear in the correlation structure of the error term, that is, the covariance matrix of ![]() , denoted by
, denoted by ![]() . In the SVAR model, contemporaneous dependencies are explicitly modelled (by the A matrix on the left-hand side), and the disturbance terms are defined to be uncorrelated, so the
. In the SVAR model, contemporaneous dependencies are explicitly modelled (by the A matrix on the left-hand side), and the disturbance terms are defined to be uncorrelated, so the ![]() covariance matrix is diagonal. Here, the disturbances are usually referred to as structural shocks.
covariance matrix is diagonal. Here, the disturbances are usually referred to as structural shocks.
What makes the SVAR modeling interesting and difficult at the same time is the so-called identification problem; the SVAR model is not identified, that is, parameters in matrix A cannot be estimated without additional restrictions.
Given a reduced form model, it is always possible to derive an appropriate parameter matrix, which makes the residuals orthogonal; the covariance matrix ![]() is positive semidefinitive, which allows us to apply the LDL decomposition (or alternatively, the Cholesky decomposition). This states that there always exists an
is positive semidefinitive, which allows us to apply the LDL decomposition (or alternatively, the Cholesky decomposition). This states that there always exists an ![]() lower triangle matrix and a
lower triangle matrix and a ![]() diagonal matrix such that
diagonal matrix such that ![]() . By choosing
. By choosing ![]() , the covariance matrix of the structural model becomes
, the covariance matrix of the structural model becomes ![]() , which gives
, which gives ![]() . Now, we conclude that
. Now, we conclude that ![]() is a diagonal, as we intended. Note that by this approach, we essentially imposed an arbitrary recursive structure on our equations. This is the method followed by the
is a diagonal, as we intended. Note that by this approach, we essentially imposed an arbitrary recursive structure on our equations. This is the method followed by the irf() function by default.
There are multiple ways in the literature to identify SVAR model parameters, which include short-run or long-run parameter restrictions, or sign restrictions on impulse responses (see, for example, Fry-Pagan (2011)). Many of them have no native support in R yet. Here, we only introduce a standard set of techniques to impose short-run parameter restrictions, which are respectively called A-model, B-model, and AB-model, each of which are supported natively by package vars:
-
In the case of an A-model,
 , and restrictions on matrix A are imposed such that
, and restrictions on matrix A are imposed such that  is a diagonal covariance matrix. To make the model "just identified", we need
is a diagonal covariance matrix. To make the model "just identified", we need  additional restrictions. This is reminiscent of imposing a triangle matrix (but that particular structure is not required).
additional restrictions. This is reminiscent of imposing a triangle matrix (but that particular structure is not required).
-
Alternatively, it is possible to identify the structural innovations based on the restricted model residuals by imposing a structure on the matrix B (B-model), that is, directly on the correlation structure, in this case,
 and
and  .
.
-
The AB-model places restrictions on both A and B, and the connection between the restricted and structural model is determined by
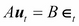 .
.
Impulse-response analysis is usually one of the main goals of building a VAR model. Essentially, an impulse-response function shows how a variable reacts (response) to a shock (impulse) hitting any other variable in the system. If the system consists of ![]() variables,
variables, ![]() impulse response functions can be determined. Impulse responses can be derived mathematically from the Vector Moving Average representation (VMA) of the VAR process, similar to the univariate case (see the details in Lütkepohl (2007)).
impulse response functions can be determined. Impulse responses can be derived mathematically from the Vector Moving Average representation (VMA) of the VAR process, similar to the univariate case (see the details in Lütkepohl (2007)).
As an illustrative example, we build a three-component VAR model from the following components:
- Equity return: This specifies the Microsoft price index from January 01, 2004 to March 03, 2014
- Stock index: This specifies the S&P500 index from January 01, 2004 to March 03, 2014
- US Treasury bond interest rates from January 01, 2004 to March 03, 2014
Our primary purpose is to make a forecast for the stock market index by using the additional variables and to identify impulse responses. Here, we suppose that there exists a hidden long term relationship between a given stock, the stock market as a whole, and the bond market. The example was chosen primarily to demonstrate several of the data manipulation possibilities of the R programming environment and to illustrate an elaborate concept using a very simple example, and not because of its economic meaning.
We use the vars and quantmod packages. Do not forget to install and load those packages if you haven't done this yet:
install.packages('vars');library('vars') install.packages('quantmod');library('quantmod')
The Quantmod package offers a great variety of tools to obtain financial data directly from online sources, which we will frequently rely on throughout the book. We use the getSymbols()function:
getSymbols('MSFT', from='2004-01-02', to='2014-03-31') getSymbols('SNP', from='2004-01-02', to='2014-03-31') getSymbols('DTB3', src='FRED')
By default, yahoofinance is used as a data source for equity and index price series (src='yahoo' parameter settings, which are omitted in the example). The routine downloads open, high, low, close prices, trading volume, and adjusted prices. The downloaded data is stored in an xts data class, which is automatically named by default after the ticker (MSFT and SNP). It's possible to plot the closing prices by calling the generic plot function, but the chartSeries function of quantmod provides a much better graphical illustration.
The components of the downloaded data can be reached by using the following shortcuts:
Cl(MSFT) #closing prices Op(MSFT) #open prices Hi(MSFT) #daily highest price Lo(MSFT) #daily lowest price ClCl(MSFT) #close-to-close daily return Ad(MSFT) #daily adjusted closing price
Thus, for example, by using these shortcuts, the daily close-to-close returns can be plotted as follows:
chartSeries(ClCl(MSFT)) #a plotting example with shortcuts
The screenshot for the preceding command is as follows:

Interest rates are downloaded from the FRED (Federal Reserve Economic Data) data source. The current version of the interface does not allow subsetting of dates; however, downloaded data is stored in an xts data class, which is straightforward to subset to obtain our period of interest:
DTB3.sub <- DTB3['2004-01-02/2014-03-31']
The downloaded prices (which are supposed to be nonstationary series) should be transformed into a stationary series for analysis; that is, we will work with log returns, calculated from the adjusted series:
MSFT.ret <- diff(log(Ad(MSFT))) SNP.ret <- diff(log(Ad(SNP)))
To proceed, we need a last data-cleansing step before turning to VAR model fitting. By eyeballing the data, we can see that missing data exists in T-Bill return series, and the lengths of our databases are not the same (on some dates, there are interest rate quotes, but equity prices are missing). To solve these data-quality problems, we choose, for now, the easiest possible solution: merge the databases (by omitting all data points for which we do not have all three data), and omit all NA data. The former is performed by the inner join parameter (see help of the merge function for details):
dataDaily <- na.omit(merge(SNP.ret,MSFT.ret,DTB3.sub), join='inner')
Here, we note that VAR modeling is usually done on lower frequency data. There is a simple way of transforming your data to monthly or quarterly frequencies, by using the following functions, which return with the opening, highest, lowest, and closing value within the given period:
SNP.M <- to.monthly(SNP.ret)$SNP.ret.Close MSFT.M <- to.monthly(MSFT.ret)$MSFT.ret.Close DTB3.M <- to.monthly(DTB3.sub)$DTB3.sub.Close
A simple reduced VAR model may be fitted to the data by using the VAR() function of the vars package. The parameterization shown in the following code allows a maximum of 4 lags in the equations, and choose the model with the best (lowest) Akaike Information Criterion value:
var1 <- VAR(dataDaily, lag.max=4, ic="AIC")
For a more established model selection, you can consider using VARselect(), which provides multiple information criteria (output omitted):
>VARselect(dataDaily,lag.max=4)
The resulting object is an object of the varest class. Estimated parameters and multiple other statistical results can be obtained by the summary() method or the show() method (that is, by just typing the variable):
summary(var1) var1
There are other methods worth mentioning. The custom plotting method for the varest class generates a diagram for all variables separately, including its fitted values, residuals, and autocorrelation and partial autocorrelation functions of the residuals. You need to hit Enter to get the new variable. Plenty of custom settings are available; please consult the vars package documentation:
plot(var1) #Diagram of fit and residuals for each variables coef(var1) #concise summary of the estimated variables residuals(var1) #list of residuals (of the corresponding ~lm) fitted(var1) #list of fitted values Phi(var1) #coefficient matrices of VMA representation
Predictions using our estimated VAR model can be made by simply calling the predict function and by adding a desired confidence interval:
var.pred <- predict(var1, n.ahead=10, ci=0.95)
Impulse responses should be first generated numerically by irf(), and then they can be plotted by the plot() method. Again, we get different diagrams for each variable, including the respective impulse response functions with bootstrapped confidence intervals as shown in the following command:
var.irf <- irf(var1) plot(var.irf)
Now, consider fitting a structural VAR model using parameter restrictions described earlier as an A-model. The number of required restrictions for the SVAR model that is identified is ![]() ; in our case, this is 3.
; in our case, this is 3.
The point of departure for an SVAR model is the already estimated reduced form of the VAR model (var1). This has to be amended with an appropriately structured restriction matrix.
For the sake of simplicity, we will use the following restrictions:
- S&P index shocks do not have a contemporaneous effect on Microsoft
- S&P index shocks do not have a contemporaneous effect on interest rates
- T-Bonds interest rate shocks have no contemporaneous effect on Microsoft
These restrictions enter into the SVAR model as 0s in the A matrix, which is as follows:

When setting up the A matrix as a parameter for SVAR estimation in R, the positions of the to-be estimated parameters should take the NA value. This can be done with the following assignments:
amat <- diag(3) amat[2, 1] <- NA amat[2, 3] <- NA amat[3, 1] <- NA
Finally, we can fit the SVAR model and plot the impulse response functions (the output is omitted):
svar1 <- SVAR(var1, estmethod='direct', Amat = amat) irf.svar1 <- irf(svar1) plot(irf.svar1)
Finally, we put together what we have learned so far, and discuss the concepts of Cointegrated VAR and Vector Error Correction Models (VECM).
Our starting point is a system of cointegrated variables (for example, in a trading context, this indicates a set of similar stocks that are likely to be driven by the same fundamentals). The standard VAR models discussed earlier can only be estimated when the variables are stationary. As we know, the conventional way to remove unit root model is to first differentiate the series; however, in the case of cointegrated series, this would lead to overdifferencing and losing information conveyed by the long-term comovement of variable levels. Ultimately, our goal is to build up a model of stationary variables, which also incorporates the long-term relationship between the original cointegrating nonstationary variables, that is, to build a cointegrated VAR model. This idea is captured by the Vector Error Correction Model (VECM), which consists of a VAR model of the order p - 1 on the differences of the variables, and an error-correction term derived from the known (estimated) cointegrating relationship. Intuitively, and using the stock market example, a VECM model establishes a short-term relationship between the stock returns, while correcting with the deviation from the long-term comovement of prices.
Formally, a two-variable VECM, which we will discuss as a numerical example, can be written as follows. Let ![]() be a vector of two nonstationary unit root series
be a vector of two nonstationary unit root series ![]() where the two series are cointegrated with a cointegrating vector
where the two series are cointegrated with a cointegrating vector ![]() . Then, an appropriate VECM model can be formulated as follows:
. Then, an appropriate VECM model can be formulated as follows:
Here, ![]() and the first term are usually called the error correction terms.
and the first term are usually called the error correction terms.
In practice, there are two approaches to test cointegration and build the error correction model. For the two-variable case, the Engle-Granger method is quite instructive; our numerical example basically follows that idea. For the multivariate case, where the maximum number of possible cointegrating relationships is ![]() , you have to follow the Johansen procedure. Although the theoretical framework for the latter goes far beyond the scope of this book, we briefly demonstrate the tools for practical implementation and give references for further studies.
, you have to follow the Johansen procedure. Although the theoretical framework for the latter goes far beyond the scope of this book, we briefly demonstrate the tools for practical implementation and give references for further studies.
To demonstrate some basic R capabilities regarding VECM models, we will use a standard example of three months and six months T-Bill secondary market rates, which can be downloaded from the FRED database, just as we discussed earlier. We will restrict our attention to an arbitrarily chosen period, that is, from 1984 to 2014. Augmented Dickey Fuller tests indicate that the null hypothesis of the unit root cannot be rejected.
library('quantmod') getSymbols('DTB3', src='FRED') getSymbols('DTB6', src='FRED') DTB3.sub = DTB3['1984-01-02/2014-03-31'] DTB6.sub = DTB6['1984-01-02/2014-03-31'] plot(DTB3.sub) lines(DTB6.sub, col='red')
We can consistently estimate the cointegrating relationship between the two series by running a simple linear regression. To simplify coding, we define the variables x1 and x2 for the two series, and y for the respective vector series. The other variable-naming conventions in the code snippets will be self-explanatory:
x1=as.numeric(na.omit(DTB3.sub)) x2=as.numeric(na.omit(DTB6.sub)) y = cbind(x1,x2) cregr <- lm(x1 ~ x2) r = cregr$residuals
The two series are indeed cointegrated if the residuals of the regression (variable r), that is, the appropriate linear combination of the variables, constitute a stationary series. You could test this with the usual ADF test, but in these settings, the conventional critical values are not appropriate, and corrected values should be used (see, for example Phillips and Ouliaris (1990)).
It is therefore much more appropriate to use a designated test for the existence of cointegration, for example, the Phillips and Ouliaris test, which is implemented in the tseries and in the urca packages as well. The most basic tseries version is demonstrated as follows:
install.packages('tseries');library('tseries'); po.coint <- po.test(y, demean = TRUE, lshort = TRUE)
The null hypothesis states that the two series are not cointegrated, so the low p value indicates rejection of null and presence of cointegration.
The Johansen procedure is applicable for more than one possible cointegrating relationship; an implementation can be found in the urca package:
yJoTest = ca.jo(y, type = c("trace"), ecdet = c("none"), K = 2) ###################### # Johansen-Procedure # ###################### Test type: trace statistic , with linear trend Eigenvalues (lambda): [1] 0.0160370678 0.0002322808 Values of teststatistic and critical values of test: test 10pct 5pct 1pct r <= 1 | 1.76 6.50 8.18 11.65 r = 0 | 124.00 15.66 17.95 23.52 Eigenvectors, normalised to first column: (These are the cointegration relations) DTB3.l2 DTB6.l2 DTB3.l2 1.000000 1.000000 DTB6.l2 -0.994407 -7.867356 Weights W: (This is the loading matrix) DTB3.l2 DTB6.l2 DTB3.d -0.037015853 3.079745e-05 DTB6.d -0.007297126 4.138248e-05
The test statistic for r = 0 (no cointegrating relationship) is larger than the critical values, which indicates the rejection of the null. For ![]() , however, the null cannot be rejected; therefore, we conclude that one cointegrating relationship exists. The cointegrating vector is given by the first column of the normalized eigenvectors below the test results.
, however, the null cannot be rejected; therefore, we conclude that one cointegrating relationship exists. The cointegrating vector is given by the first column of the normalized eigenvectors below the test results.
The final step is to obtain the VECM representation of this system, that is, to run an OLS regression on the lagged differenced variables and the error correction term derived from the previously calculated cointegrating relationship. The appropriate function utilizes the ca.jo object class, which we created earlier. The r = 1 parameter signifies the cointegration rank which is as follows:
>yJoRegr = cajorls(dyTest, r=1) >yJoRegr $rlm Call: lm(formula = substitute(form1), data = data.mat) Coefficients: x1.d x2.d ect1 -0.0370159 -0.0072971 constant -0.0041984 -0.0016892 x1.dl1 0.1277872 0.1538121 x2.dl1 0.0006551 -0.0390444 $beta ect1 x1.l1 1.000000 x2.l1 -0.994407
The coefficient of the error-correction term is negative, as we expected; a short-term deviation from the long-term equilibrium level would push our variables back to the zero equilibrium deviation.
You can easily check this in the bivariate case; the result of the Johansen procedure method leads to approximately the same result as the step-by-step implementation of the ECM following the Engle-Granger procedure. This is shown in the uploaded R code files.