
C4.5 is an extension of ID3. The major extensions include handling data with missing attribute values, and handling attributes that belong to an infinite continuous range.
It is one of the decision tree algorithms, and is also a supervised learning classification algorithm. A model is learned and the input attribute values are mapped to the mutually exclusive class labels. Moreover, the learned model will be used to further classify new unseen instances or attribute values. The attribute select measure adopted in C4.5 is the gain ratio, which avoids the possible bias:


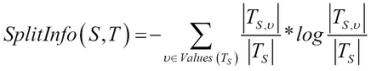
Based on the generic C4.5 algorithm, a suite for varieties derived, C4.5, C4.5-no-pruning, C4.5-rules, and so forth; all of them are called C4.5 algorithms, which means C4.5 is a suite of algorithms.
Compared to other algorithms, there are many important characteristics of C4.5:
- Tree pruning, a post-pruning strategy, is followed to remove some of the tree structure using selected accuracy criteria
- An improved use of continuous attributes
- Missing values handling
- Inducing rule sets
- It contains a multiway test that depends on the attribute value and is not just limited to the binary test
- Information theoretic tests are applied via the gain and gain ratio
- The greedy learning algorithm, that is, along with the tree growing, test best criteria test result is chosen
- The data fits in main memory (there are many extended algorithms that can use the secondary storages, such as BOAT, Rainforest, SLIQ, SPRINT, and so forth.)

The R code for the ID3 is listed as follows:
1 C45 <- function(data,x){
2 result.tree <- NULL
3
4 if( IsEmpty(data) ){
5 node.value <- "Failure"
6 result.tree <- CreateNode(node.value)
7 return(result.tree)
8 }
9 if( IsEmpty(x) ){
10 node.value <- GetMajorityClassValue(data,x)
11 result.tree <- CreateNode(node.value)
12 return(result.tree)
13 }
14 if( 1 == GetCount(x) ){
15 node.value <- GetClassValue(x)
16 result.tree <- CreateNode(node.value)
17 return(result.tree)
18 }
19
20 gain.ratio <- GetGainRatio(data,x)
21 best.split <- GetBestSplit(data,x,gain.ratio)
22
23 data.subsets <- SplitData(data,best.split)
24 values <- GetAttributeValues(data.subsets,best.split)
25 values.count <- GetCount(values)
26
27 node.value <- best.split
28 result.tree <- CreateNode(node.value)
29 idx <- 0
30 while( idx<=values.count ){
31 idx <- idx+1
32 newdata <- GetAt(data.subsets,idx)
33 value <- GetAt(values,idx)
34 new.x <- RemoveAttribute(x,best.split)
35 new.child <- C45(newdata,new.x)
36 AddChildNode(result.tree,new.child,value)
37 }
38
39 result.tree
40 }With the increase in the dataset volume or size, the C4.5 algorithm can be parallelized according to the MapReduce algorithm, the Hadoop technologies suite, and especially via RHadoop for R codes.
The MapReduce programming model is illustrated in the following diagram:





Spamming occurs along with the emergence of search engine technologies to pursue higher rank with the deceiving search engines relevancy algorithm, but not improve their own website technologies. It performs deliberate actions to trigger unjustifiable favorable relevance or importance for a specific web page, in contrast to the page's true value or merit. The spam page finally receives a substantial amount of score from other spam pages to boost its rank in search engine results by deliberately manipulating the search engine indexes. Finally, traffic is driven to the spammed pages. As a direct result of the Web spam, the information quality of the Web world is degraded, user experience is manipulated, and the security risk for use increases due to exploitation of user privacy.
One classic example, denoted as link-farm, is illustrated in the following diagram, in which a densely connected set of pages is created with the target of cheating a link-based ranking algorithm, which is also called collusion:

There are three major categories of spam from a business point of view:
- Page Spoofing
- Browser-Based Attacks
- Search Engine Manipulations
There are three major categories of spam from a technology point of view:
- Link spam: This consists of the creation of the link structure, often a tight-knit community of links, targeted at affecting the outcome of a link-based ranking algorithm. Possible technologies include honey pot, anchor-text spam, blog/wiki spam, link exchange, link farm, and expired domains.
- Content spam: This crafts the contents of web page pages. One example is inserting unrelated keywords to the web page content for higher ranking on search engines. Possible technologies include hidden text (size and color), repetition, keyword stuffing/dilution, and language-model-based technologies (phrase stealing and dumping).
- Cloaking: This sends content to search engines which looks different from the version viewed by human visitors.

The link-based spam detections usually rely on automatic classifiers, detecting the anomalous behavior of a link-based ranking algorithm, and so on. Classifier or language model disagreement can be adopted to detect content spam. While the cloaking detection solution is inherent, one of them is comparing the indexed page with the pages visitors saw.
How to apply a decision tree for web spam detection? The links and contents of the web spam, after statistical analysis, are unique compared to other normal pages. Some properties are valuable for detecting spam, trustworthiness of the page, neutrality (facts), and bias. Web spam detection can be a good example for illustrating the C4.5 algorithm.
Some domain-related knowledge can be applied to the classification solution. One observed phenomenon is that bad links always have links between them. The links between web pages and websites are often not randomly set but with certain rules and they can be detected by classifiers.
About the attributes for a certain data point, the dataset can be divided into two groups, link-based features and content-based features:
- Link-based features: These include degree-based measures such as in-degree and out-degree of the web hosts. The second is PageRank-based features, which is an algorithm to compute a score for every page. The third is TrustRank-based features, which measure the trustworthiness of certain web pages to some benchmarked, trustworthy web pages.
- Content-based features: These include the number of words in the page, number of words in the title, average word length, amount of anchor text, fraction of anchor text, fraction of visible text, fraction of page drawn from globally popular words, fraction of globally popular words, compressibility, corpus precision and corpus recall, query precision and query recall, independent trigram or n-gram likelihood, and entropy of trigrams or n-gram.
All these features are included in one data point to set up a preprocessed dataset, which in turn can be used by classification algorithms, especially decision tree algorithms such as C4.5 to work as web spam classifiers to distinguish spam from normal pages. Among all the classification solutions, C4.5 achieves the best performance.