
So far, we've focused on how machine learning works in theory. To apply the learning process to real-world tasks, we'll use a five-step process. Regardless of the task at hand, any machine learning algorithm can be deployed by following these steps:
- Data collection: The data collection step involves gathering the learning material an algorithm will use to generate actionable knowledge. In most cases, the data will need to be combined into a single source like a text file, spreadsheet, or database.
- Data exploration and preparation: The quality of any machine learning project is based largely on the quality of its input data. Thus, it is important to learn more about the data and its nuances during a practice called data exploration. Additional work is required to prepare the data for the learning process. This involves fixing or cleaning so-called "messy" data, eliminating unnecessary data, and recoding the data to conform to the learner's expected inputs.
- Model training: By the time the data has been prepared for analysis, you are likely to have a sense of what you are capable of learning from the data. The specific machine learning task chosen will inform the selection of an appropriate algorithm, and the algorithm will represent the data in the form of a model.
- Model evaluation: Because each machine learning model results in a biased solution to the learning problem, it is important to evaluate how well the algorithm learns from its experience. Depending on the type of model used, you might be able to evaluate the accuracy of the model using a test dataset or you may need to develop measures of performance specific to the intended application.
- Model improvement: If better performance is needed, it becomes necessary to utilize more advanced strategies to augment the performance of the model. Sometimes, it may be necessary to switch to a different type of model altogether. You may need to supplement your data with additional data or perform additional preparatory work as in step two of this process.
After these steps are completed, if the model appears to be performing well, it can be deployed for its intended task. As the case may be, you might utilize your model to provide score data for predictions (possibly in real time), for projections of financial data, to generate useful insight for marketing or research, or to automate tasks such as mail delivery or flying aircraft. The successes and failures of the deployed model might even provide additional data to train your next generation learner.
The practice of machine learning involves matching the characteristics of input data to the biases of the available approaches. Thus, before applying machine learning to real-world problems, it is important to understand the terminology that distinguishes among input datasets.
The phrase unit of observation is used to describe the smallest entity with measured properties of interest for a study. Commonly, the unit of observation is in the form of persons, objects or things, transactions, time points, geographic regions, or measurements. Sometimes, units of observation are combined to form units such as person-years, which denote cases where the same person is tracked over multiple years; each person-year comprises of a person's data for one year.
Tip
The unit of observation is related, but not identical, to the unit of analysis, which is the smallest unit from which the inference is made. Although it is often the case, the observed and analyzed units are not always the same. For example, data observed from people might be used to analyze trends across countries.
Datasets that store the units of observation and their properties can be imagined as collections of data consisting of:
- Examples: Instances of the unit of observation for which properties have been recorded
- Features: Recorded properties or attributes of examples that may be useful for learning
It is easiest to understand features and examples through real-world cases. To build a learning algorithm to identify spam e-mail, the unit of observation could be e-mail messages, the examples would be specific messages, and the features might consist of the words used in the messages. For a cancer detection algorithm, the unit of observation could be patients, the examples might include a random sample of cancer patients, and the features may be the genomic markers from biopsied cells as well as the characteristics of patient such as weight, height, or blood pressure.
While examples and features do not have to be collected in any specific form, they are commonly gathered in matrix format, which means that each example has exactly the same features.
The following spreadsheet shows a dataset in matrix format. In matrix data, each row in the spreadsheet is an example and each column is a feature. Here, the rows indicate examples of automobiles, while the columns record various each automobile's features, such as price, mileage, color, and transmission type. Matrix format data is by far the most common form used in machine learning. Though, as you will see in the later chapters, other forms are used occasionally in specialized cases:
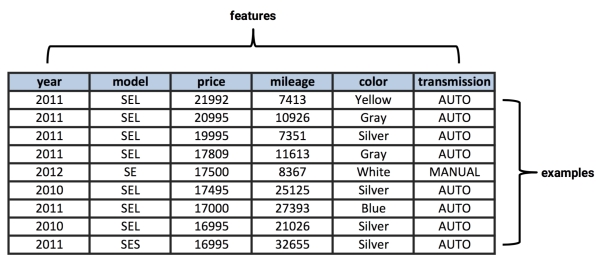
Features also come in various forms. If a feature represents a characteristic measured in numbers, it is unsurprisingly called numeric. Alternatively, if a feature is an attribute that consists of a set of categories, the feature is called categorical or nominal. A special case of categorical variables is called ordinal, which designates a nominal variable with categories falling in an ordered list. Some examples of ordinal variables include clothing sizes such as small, medium, and large; or a measurement of customer satisfaction on a scale from "not at all happy" to "very happy." It is important to consider what the features represent, as the type and number of features in your dataset will assist in determining an appropriate machine learning algorithm for your task.
Machine learning algorithms are divided into categories according to their purpose. Understanding the categories of learning algorithms is an essential first step towards using data to drive the desired action.
A predictive model is used for tasks that involve, as the name implies, the prediction of one value using other values in the dataset. The learning algorithm attempts to discover and model the relationship between the target feature (the feature being predicted) and the other features. Despite the common use of the word "prediction" to imply forecasting, predictive models need not necessarily foresee events in the future. For instance, a predictive model could be used to predict past events, such as the date of a baby's conception using the mother's present-day hormone levels. Predictive models can also be used in real time to control traffic lights during rush hours.
Because predictive models are given clear instruction on what they need to learn and how they are intended to learn it, the process of training a predictive model is known as supervised learning. The supervision does not refer to human involvement, but rather to the fact that the target values provide a way for the learner to know how well it has learned the desired task. Stated more formally, given a set of data, a supervised learning algorithm attempts to optimize a function (the model) to find the combination of feature values that result in the target output.
The often used supervised machine learning task of predicting which category an example belongs to is known as classification. It is easy to think of potential uses for a classifier. For instance, you could predict whether:
- An e-mail message is spam
- A person has cancer
- A football team will win or lose
- An applicant will default on a loan
In classification, the target feature to be predicted is a categorical feature known as the class, and is divided into categories called levels. A class can have two or more levels, and the levels may or may not be ordinal. Because classification is so widely used in machine learning, there are many types of classification algorithms, with strengths and weaknesses suited for different types of input data. We will see examples of these later in this chapter and throughout this book.
Supervised learners can also be used to predict numeric data such as income, laboratory values, test scores, or counts of items. To predict such numeric values, a common form of numeric prediction fits linear regression models to the input data. Although regression models are not the only type of numeric models, they are, by far, the most widely used. Regression methods are widely used for forecasting, as they quantify in exact terms the association between inputs and the target, including both, the magnitude and uncertainty of the relationship.
A descriptive model is used for tasks that would benefit from the insight gained from summarizing data in new and interesting ways. As opposed to predictive models that predict a target of interest, in a descriptive model, no single feature is more important than any other. In fact, because there is no target to learn, the process of training a descriptive model is called unsupervised learning. Although it can be more difficult to think of applications for descriptive models—after all, what good is a learner that isn't learning anything in particular—they are used quite regularly for data mining.
For example, the descriptive modeling task called pattern discovery is used to identify useful associations within data. Pattern discovery is often used for market basket analysis on retailers' transactional purchase data. Here, the goal is to identify items that are frequently purchased together, such that the learned information can be used to refine marketing tactics. For instance, if a retailer learns that swimming trunks are commonly purchased at the same time as sunglasses, the retailer might reposition the items more closely in the store or run a promotion to "up-sell" customers on associated items.
The descriptive modeling task of dividing a dataset into homogeneous groups is called clustering. This is sometimes used for segmentation analysis that identifies groups of individuals with similar behavior or demographic information, so that advertising campaigns could be tailored for particular audiences. Although the machine is capable of identifying the clusters, human intervention is required to interpret them. For example, given five different clusters of shoppers at a grocery store, the marketing team will need to understand the differences among the groups in order to create a promotion that best suits each group.
Lastly, a class of machine learning algorithms known as meta-learners is not tied to a specific learning task, but is rather focused on learning how to learn more effectively. A meta-learning algorithm uses the result of some learnings to inform additional learning. This can be beneficial for very challenging problems or when a predictive algorithm's performance needs to be as accurate as possible.
The following table lists the general types of machine learning algorithms covered in this book. Although this covers only a fraction of the entire set of machine learning algorithms, learning these methods will provide a sufficient foundation to make sense of any other method you may encounter in the future.
|
Model |
Learning task |
Chapter |
|---|---|---|
|
Supervised Learning Algorithms | ||
|
Nearest Neighbor |
Classification |
3 |
|
Naive Bayes |
Classification |
4 |
|
Decision Trees |
Classification |
5 |
|
Classification Rule Learners |
Classification |
5 |
|
Linear Regression |
Numeric prediction |
6 |
|
Regression Trees |
Numeric prediction |
6 |
|
Model Trees |
Numeric prediction |
6 |
|
Neural Networks |
Dual use |
7 |
|
Support Vector Machines |
Dual use |
7 |
|
Unsupervised Learning Algorithms | ||
|
Association Rules |
Pattern detection |
8 |
|
k-means clustering |
Clustering |
9 |
|
Meta-Learning Algorithms | ||
|
Bagging |
Dual use |
11 |
|
Boosting |
Dual use |
11 |
|
Random Forests |
Dual use |
11 |
To begin applying machine learning to a real-world project, you will need to determine which of the four learning tasks your project represents: classification, numeric prediction, pattern detection, or clustering. The task will drive the choice of algorithm. For instance, if you are undertaking pattern detection, you are likely to employ association rules. Similarly, a clustering problem will likely utilize the k-means algorithm, and numeric prediction will utilize regression analysis or regression trees.
For classification, more thought is needed to match a learning problem to an appropriate classifier. In these cases, it is helpful to consider various distinctions among algorithms—distinctions that will only be apparent by studying each of the classifiers in depth. For instance, within classification problems, decision trees result in models that are readily understood, while the models of neural networks are notoriously difficult to interpret. If you were designing a credit-scoring model, this could be an important distinction because law often requires that the applicant must be notified about the reasons he or she was rejected for the loan. Even if the neural network is better at predicting loan defaults, if its predictions cannot be explained, then it is useless for this application.
To assist with the algorithm selection, in every chapter, the key strengths and weaknesses of each learning algorithm are listed. Although you will sometimes find that these characteristics exclude certain models from consideration, in many cases, the choice of algorithm is arbitrary. When this is true, feel free to use whichever algorithm you are most comfortable with. Other times, when predictive accuracy is primary, you may need to test several algorithms and choose the one that fits the best, or use a meta-learning algorithm that combines several different learners to utilize the strengths of each.
