
The global financial crisis of 2007-2008 highlighted the importance of transparency and rigor in banking practices. As the availability of credit was limited, banks tightened their lending systems and turned to machine learning to more accurately identify risky loans.
Decision trees are widely used in the banking industry due to their high accuracy and ability to formulate a statistical model in plain language. Since government organizations in many countries carefully monitor lending practices, executives must be able to explain why one applicant was rejected for a loan while the others were approved. This information is also useful for customers hoping to determine why their credit rating is unsatisfactory.
It is likely that automated credit scoring models are employed to instantly approve credit applications on the telephone and web. In this section, we will develop a simple credit approval model using C5.0 decision trees. We will also see how the results of the model can be tuned to minimize errors that result in a financial loss for the institution.
The idea behind our credit model is to identify factors that are predictive of higher risk of default. Therefore, we need to obtain data on a large number of past bank loans and whether the loan went into default, as well as information on the applicant.
Data with these characteristics is available in a dataset donated to the UCI Machine Learning Data Repository (http://archive.ics.uci.edu/ml) by Hans Hofmann of the University of Hamburg. The dataset contains information on loans obtained from a credit agency in Germany.
The credit dataset includes 1,000 examples on loans, plus a set of numeric and nominal features indicating the characteristics of the loan and the loan applicant. A class variable indicates whether the loan went into default. Let's see whether we can determine any patterns that predict this outcome.
As we did previously, we will import data using the read.csv() function. We will ignore the stringsAsFactors option and, therefore, use the default value of TRUE, as the majority of the features in the data are nominal:
> credit <- read.csv("credit.csv")
The first several lines of output from the str() function are as follows:
> str(credit) 'data.frame':1000 obs. of 17 variables: $ checking_balance : Factor w/ 4 levels "< 0 DM","> 200 DM",.. $ months_loan_duration: int 6 48 12 ... $ credit_history : Factor w/ 5 levels "critical","good",.. $ purpose : Factor w/ 6 levels "business","car",.. $ amount : int 1169 5951 2096 ...
We see the expected 1,000 observations and 17 features, which are a combination of factor and integer data types.
Let's take a look at the table() output for a couple of loan features that seem likely to predict a default. The applicant's checking and savings account balance are recorded as categorical variables:
> table(credit$checking_balance) < 0 DM > 200 DM 1 - 200 DM unknown 274 63 269 394 > table(credit$savings_balance) < 100 DM > 1000 DM 100 - 500 DM 500 - 1000 DM unknown 603 48 103 63 183
The checking and savings account balance may prove to be important predictors of loan default status. Note that since the loan data was obtained from Germany, the currency is recorded in Deutsche Marks (DM).
Some of the loan's features are numeric, such as its duration and the amount of credit requested:
> summary(credit$months_loan_duration) Min. 1st Qu. Median Mean 3rd Qu. Max. 4.0 12.0 18.0 20.9 24.0 72.0 > summary(credit$amount) Min. 1st Qu. Median Mean 3rd Qu. Max. 250 1366 2320 3271 3972 18420
The loan amounts ranged from 250 DM to 18,420 DM across terms of 4 to 72 months with a median duration of 18 months and an amount of 2,320 DM.
The default vector indicates whether the loan applicant was unable to meet the agreed payment terms and went into default. A total of 30 percent of the loans in this dataset went into default:
> table(credit$default) no yes 700 300
A high rate of default is undesirable for a bank, because it means that the bank is unlikely to fully recover its investment. If we are successful, our model will identify applicants that are at high risk to default, allowing the bank to refuse credit requests.
As we have done in the previous chapters, we will split our data into two portions: a training dataset to build the decision tree and a test dataset to evaluate the performance of the model on new data. We will use 90 percent of the data for training and 10 percent for testing, which will provide us with 100 records to simulate new applicants.
As prior chapters used data that had been sorted in a random order, we simply divided the dataset into two portions, by taking the first 90 percent of records for training, and the remaining 10 percent for testing. In contrast, the credit dataset is not randomly ordered, making the prior approach unwise. Suppose that the bank had sorted the data by the loan amount, with the largest loans at the end of the file. If we used the first 90 percent for training and the remaining 10 percent for testing, we would be training a model on only the small loans and testing the model on the big loans. Obviously, this could be problematic.
We'll solve this problem by using a random sample of the credit data for training. A random sample is simply a process that selects a subset of records at random. In R, the sample() function is used to perform random sampling. However, before putting it in action, a common practice is to set a seed value, which causes the randomization process to follow a sequence that can be replicated later on if desired. It may seem that this defeats the purpose of generating random numbers, but there is a good reason for doing it this way. Providing a seed value via the set.seed() function ensures that if the analysis is repeated in the future, an identical result is obtained.
Tip
You may wonder how a so-called random process can be seeded to produce an identical result. This is due to the fact that computers use a mathematical function called a pseudorandom number generator to create random number sequences that appear to act very random, but are actually quite predictable given knowledge of the previous values in the sequence. In practice, modern pseudorandom number sequences are virtually indistinguishable from true random sequences, but have the benefit that computers can generate them quickly and easily.
The following commands use the sample() function to select 900 values at random out of the sequence of integers from 1 to 1000. Note that the set.seed() function uses the arbitrary value 123. Omitting this seed will cause your training and testing split to differ from those shown in the remainder of this chapter:
> set.seed(123) > train_sample <- sample(1000, 900)
As expected, the resulting train_sample object is a vector of 900 random integers:
> str(train_sample) int [1:900] 288 788 409 881 937 46 525 887 548 453 ...
By using this vector to select rows from the credit data, we can split it into the 90 percent training and 10 percent test datasets we desired. Recall that the dash operator used in the selection of the test records tells R to select records that are not in the specified rows; in other words, the test data includes only the rows that are not in the training sample.
> credit_train <- credit[train_sample, ] > credit_test <- credit[-train_sample, ]
If all went well, we should have about 30 percent of defaulted loans in each of the datasets:
> prop.table(table(credit_train$default)) no yes 0.7033333 0.2966667 > prop.table(table(credit_test$default)) no yes 0.67 0.33
This appears to be a fairly even split, so we can now build our decision tree.
We will use the C5.0 algorithm in the C50 package to train our decision tree model. If you have not done so already, install the package with install.packages("C50") and load it to your R session, using library(C50).
The following syntax box lists some of the most commonly used commands to build decision trees. Compared to the machine learning approaches we used previously, the C5.0 algorithm offers many more ways to tailor the model to a particular learning problem, but more options are available. Once the C50 package has been loaded, the ?C5.0Control command displays the help page for more details on how to finely-tune the algorithm.

For the first iteration of our credit approval model, we'll use the default C5.0 configuration, as shown in the following code. The 17th column in credit_train is the default class variable, so we need to exclude it from the training data frame, but supply it as the target factor vector for classification:
> credit_model <- C5.0(credit_train[-17], credit_train$default)
The credit_model object now contains a C5.0 decision tree. We can see some basic data about the tree by typing its name:
> credit_model Call: C5.0.default(x = credit_train[-17], y = credit_train$default) Classification Tree Number of samples: 900 Number of predictors: 16 Tree size: 57 Non-standard options: attempt to group attributes
The preceding text shows some simple facts about the tree, including the function call that generated it, the number of features (labeled predictors), and examples (labeled samples) used to grow the tree. Also listed is the tree size of 57, which indicates that the tree is 57 decisions deep—quite a bit larger than the example trees we've considered so far!
To see the tree's decisions, we can call the summary() function on the model:
> summary(credit_model)
This results in the following output:

The preceding output shows some of the first branches in the decision tree. The first three lines could be represented in plain language as:
- If the checking account balance is unknown or greater than 200 DM, then classify as "not likely to default."
- Otherwise, if the checking account balance is less than zero DM or between one and 200 DM.
- And the credit history is perfect or very good, then classify as "likely to default."
The numbers in parentheses indicate the number of examples meeting the criteria for that decision, and the number incorrectly classified by the decision. For instance, on the first line, 412/50 indicates that of the 412 examples reaching the decision, 50 were incorrectly classified as not likely to default. In other words, 50 applicants actually defaulted, in spite of the model's prediction to the contrary.
Tip
Sometimes a tree results in decisions that make little logical sense. For example, why would an applicant whose credit history is very good be likely to default, while those whose checking balance is unknown are not likely to default? Contradictory rules like this occur sometimes. They might reflect a real pattern in the data, or they may be a statistical anomaly. In either case, it is important to investigate such strange decisions to see whether the tree's logic makes sense for business use.
After the tree, the summary(credit_model) output displays a confusion matrix, which is a cross-tabulation that indicates the model's incorrectly classified records in the training data:
Evaluation on training data (900 cases): Decision Tree ---------------- Size Errors 56 133(14.8%) << (a) (b) <-classified as ---- ---- 598 35 (a): class no 98 169 (b): class yes
The Errors output notes that the model correctly classified all but 133 of the 900 training instances for an error rate of 14.8 percent. A total of 35 actual no values were incorrectly classified as yes (false positives), while 98 yes values were misclassified as no (false negatives).
Decision trees are known for having a tendency to overfit the model to the training data. For this reason, the error rate reported on training data may be overly optimistic, and it is especially important to evaluate decision trees on a test dataset.
To apply our decision tree to the test dataset, we use the predict() function, as shown in the following line of code:
> credit_pred <- predict(credit_model, credit_test)
This creates a vector of predicted class values, which we can compare to the actual class values using the CrossTable() function in the gmodels package. Setting the prop.c and prop.r parameters to FALSE removes the column and row percentages from the table. The remaining percentage (prop.t) indicates the proportion of records in the cell out of the total number of records:
> library(gmodels) > CrossTable(credit_test$default, credit_pred, prop.chisq = FALSE, prop.c = FALSE, prop.r = FALSE, dnn = c('actual default', 'predicted default'))
This results in the following table:

Out of the 100 test loan application records, our model correctly predicted that 59 did not default and 14 did default, resulting in an accuracy of 73 percent and an error rate of 27 percent. This is somewhat worse than its performance on the training data, but not unexpected, given that a model's performance is often worse on unseen data. Also note that the model only correctly predicted 14 of the 33 actual loan defaults in the test data, or 42 percent. Unfortunately, this type of error is a potentially very costly mistake, as the bank loses money on each default. Let's see if we can improve the result with a bit more effort.
Our model's error rate is likely to be too high to deploy it in a real-time credit scoring application. In fact, if the model had predicted "no default" for every test case, it would have been correct 67 percent of the time—a result not much worse than our model's, but requiring much less effort! Predicting loan defaults from 900 examples seems to be a challenging problem.
Making matters even worse, our model performed especially poorly at identifying applicants who do default on their loans. Luckily, there are a couple of simple ways to adjust the C5.0 algorithm that may help to improve the performance of the model, both overall and for the more costly type of mistakes.
One way the C5.0 algorithm improved upon the C4.5 algorithm was through the addition of adaptive boosting. This is a process in which many decision trees are built and the trees vote on the best class for each example.
As boosting can be applied more generally to any machine learning algorithm, it is covered in detail later in this book in Chapter 11, Improving Model Performance. For now, it suffices to say that boosting is rooted in the notion that by combining a number of weak performing learners, you can create a team that is much stronger than any of the learners alone. Each of the models has a unique set of strengths and weaknesses and they may be better or worse in solving certain problems. Using a combination of several learners with complementary strengths and weaknesses can therefore dramatically improve the accuracy of a classifier.
The C5.0() function makes it easy to add boosting to our C5.0 decision tree. We simply need to add an additional trials parameter indicating the number of separate decision trees to use in the boosted team. The trials parameter sets an upper limit; the algorithm will stop adding trees if it recognizes that additional trials do not seem to be improving the accuracy. We'll start with 10 trials, a number that has become the de facto standard, as research suggests that this reduces error rates on test data by about 25 percent:
> credit_boost10 <- C5.0(credit_train[-17], credit_train$default, trials = 10)
While examining the resulting model, we can see that some additional lines have been added, indicating the changes:
> credit_boost10 Number of boosting iterations: 10 Average tree size: 47.5
Across the 10 iterations, our tree size shrunk. If you would like, you can see all 10 trees by typing summary(credit_boost10) at the command prompt. It also lists the model's performance on the training data:
> summary(credit_boost10) (a) (b) <-classified as ---- ---- 629 4 (a): class no 30 237 (b): class yes
The classifier made 34 mistakes on 900 training examples for an error rate of 3.8 percent. This is quite an improvement over the 13.9 percent training error rate we noted before adding boosting! However, it remains to be seen whether we see a similar improvement on the test data. Let's take a look:
> credit_boost_pred10 <- predict(credit_boost10, credit_test) > CrossTable(credit_test$default, credit_boost_pred10, prop.chisq = FALSE, prop.c = FALSE, prop.r = FALSE, dnn = c('actual default', 'predicted default'))
The resulting table is as follows:

Here, we reduced the total error rate from 27 percent prior to boosting down to 18 percent in the boosted model. It does not seem like a large gain, but it is in fact larger than the 25 percent reduction we expected. On the other hand, the model is still not doing well at predicting defaults, predicting only 20/33 = 61% correctly. The lack of an even greater improvement may be a function of our relatively small training dataset, or it may just be a very difficult problem to solve.
This said, if boosting can be added this easily, why not apply it by default to every decision tree? The reason is twofold. First, if building a decision tree once takes a great deal of computation time, building many trees may be computationally impractical. Secondly, if the training data is very noisy, then boosting might not result in an improvement at all. Still, if greater accuracy is needed, it's worth giving it a try.
Giving a loan out to an applicant who is likely to default can be an expensive mistake. One solution to reduce the number of false negatives may be to reject a larger number of borderline applicants, under the assumption that the interest the bank would earn from a risky loan is far outweighed by the massive loss it would incur if the money is not paid back at all.
The C5.0 algorithm allows us to assign a penalty to different types of errors, in order to discourage a tree from making more costly mistakes. The penalties are designated in a cost matrix, which specifies how much costlier each error is, relative to any other prediction.
To begin constructing the cost matrix, we need to start by specifying the dimensions. Since the predicted and actual values can both take two values, yes or no, we need to describe a 2 x 2 matrix, using a list of two vectors, each with two values. At the same time, we'll also name the matrix dimensions to avoid confusion later on:
> matrix_dimensions <- list(c("no", "yes"), c("no", "yes")) > names(matrix_dimensions) <- c("predicted", "actual")
Examining the new object shows that our dimensions have been set up correctly:
> matrix_dimensions $predicted [1] "no" "yes" $actual [1] "no" "yes"
Next, we need to assign the penalty for the various types of errors by supplying four values to fill the matrix. Since R fills a matrix by filling columns one by one from top to bottom, we need to supply the values in a specific order:
- Predicted no, actual no
- Predicted yes, actual no
- Predicted no, actual yes
- Predicted yes, actual yes
Suppose we believe that a loan default costs the bank four times as much as a missed opportunity. Our penalty values could then be defined as:
> error_cost <- matrix(c(0, 1, 4, 0), nrow = 2, dimnames = matrix_dimensions)
This creates the following matrix:
> error_cost actual predicted no yes no 0 4 yes 1 0
As defined by this matrix, there is no cost assigned when the algorithm classifies a no or yes correctly, but a false negative has a cost of 4 versus a false positive's cost of 1. To see how this impacts classification, let's apply it to our decision tree using the costs parameter of the C5.0() function. We'll otherwise use the same steps as we did earlier:
> credit_cost <- C5.0(credit_train[-17], credit_train$default, costs = error_cost) > credit_cost_pred <- predict(credit_cost, credit_test) > CrossTable(credit_test$default, credit_cost_pred, prop.chisq = FALSE, prop.c = FALSE, prop.r = FALSE, dnn = c('actual default', 'predicted default'))
This produces the following confusion matrix:
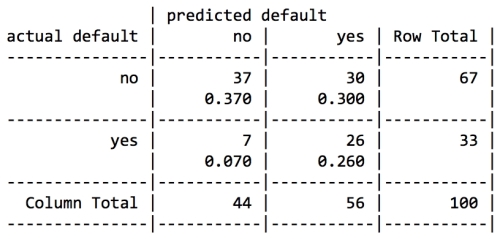
Compared to our boosted model, this version makes more mistakes overall: 37 percent error here versus 18 percent in the boosted case. However, the types of mistakes are very different. Where the previous models incorrectly classified only 42 and 61 percent of defaults correctly, in this model, 79 percent of the actual defaults were predicted to be defaults. This trade resulting in a reduction of false negatives at the expense of increasing false positives may be acceptable if our cost estimates were accurate.
