
In this chapter, two enhancements are made to the application: pagination through infinite scroll loading, and a posts search. All modern blogs and micro blogs, such as Tumblr and Twitter, use an infinite scroll feature in place of explicit pagination to load blog entries in chunks. Since this is now a standard user experience, we'll implement it here. Infinite scroll isn't quite enough, though. Another reasonable user expectation for an app that manages large collections is the presence of a search feature. Luckily, our prototype backend software, JSON Server, has a full-text search capability.
The construction of the application is split into the following four parts:
- Part I: Actions and common components
- Part II: User account management
- Part III: Blog post operations
- Part IV: Infinite scroll and search
The two features introduced in this chapter are split into two code bundles. The code from the previous several chapters all the way through the infinite scroll feature can be found in ch9-1.zip. All of the final code for the blog application, including both the infinite scroll feature and the search feature, is found in ch9-2.zip.
So far, we can create users and create posts. When the number of posts gets lengthy it's useful to load the list in chunks. The visual we'll need, the loader animation component, is already complete. So, the logic parts are all that need to be updated. The user view and the post list view both include the post list component. The shared post list component will handle the pagination. So, each of those views will benefit from this enhancement without modification. We are now going to use the posts store more as a service interface than a store. Ostensibly, its role as a store could retain more of its classic definition if we decided to cache certain posts or pages as a later enhancement. All of the code for this feature section can be found in ch9-1.zip. Changes and additions in the source are highlighted here in the text.
The following screenshot shows what infinite scroll loading will look like when we're finished:
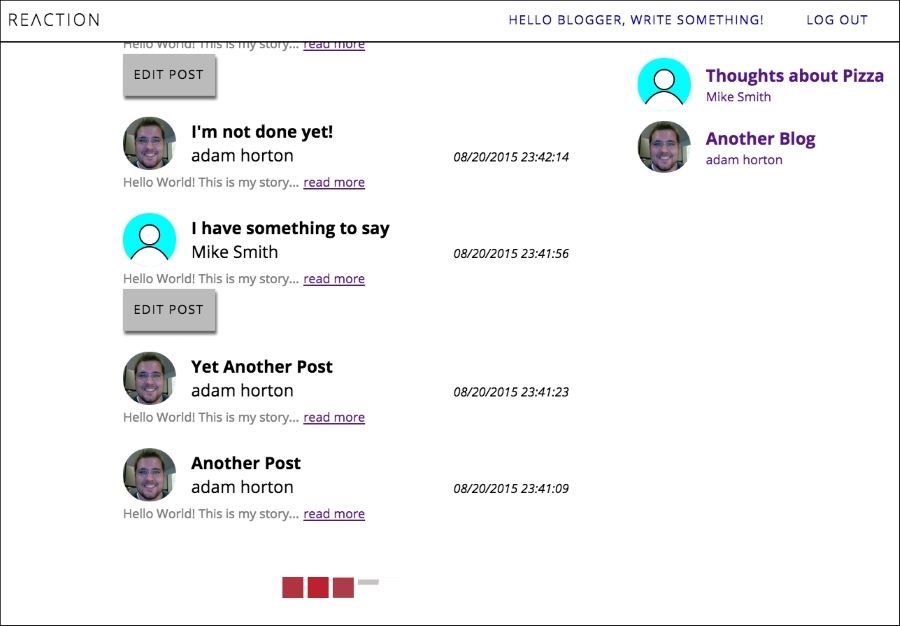
Infinite scroll in action
The following is a manifest of all of the files involved in the infinite scroll feature.
The posts store will need to be modified to request posts in page chunks.
- Posts store:
js/stores/posts.js
The post list component will drive the pagination process by requesting chunks.
- Post list component:
js/components/posts/list.jsx
To achieve pagination, we've simply surfaced a page request method, getPostsByPage, in the posts store. The pagination support from the server is achieved through JSON Server's ability to slice collections with _start and _end query parameters. It also supports sorting, which is used here to sort by date via the _sort and _order query parameters. It's left up to the caller to supply the page number, but page size is stored in the application configuration.
Since we are no longer retaining a structure for the posts, the init method, getInitialState, the posts member, as well as the insertion or replacement within the posts structure on modify, are all gone.
Here's the new source for the posts store. Changes are substantial and reside almost entirely in the new getPostsByPage function, so just the function signature is highlighted rather than the entire function.
File: js/stores/posts.js
import Reflux from 'reflux';
import Actions from 'appRoot/actions';
import Request from 'superagent';
import Config from 'appRoot/appConfig';
export default Reflux.createStore({
listenables: Actions,
endpoint: Config.apiRoot + '/posts',
// posts, init, and getInitialState are removed. getPostsByPage handles list requests
getPostsByPage: function (page = 1, params) {
var start = Config.pageSize * (page-1)
, end = start + Config.pageSize
, query = {
// newest to oldest
'_sort': 'date',
'_order': 'DESC',
'_start': Config.pageSize * (page-1),
'_end': Config.pageSize * (page-1) + Config.pageSize
}
, us = this
;
if (typeof params === 'object') {
// ES6 extend object
Object.assign(query, params);
}
if (this.currentRequest) {
this.currentRequest.abort();
this.currentRequest = null;
}
return new Promise(function (resolve, reject) {
us.currentRequest = Request.get(us.endpoint);
us.currentRequest
.query(query)
.end(function (err, res) {
var results = res.body;
function complete () {
// unfortunately if multiple request had been made
// They would all get resolved on the first
// invocation of this function
// Undesireable, when we are rapid firing searches
// Actions.getPostsByPage.completed({ start: query._start, end: query._end, results: results });
resolve({
start: query._start,
end: query._end,
results: results
});
}
if (res.ok) {
Config.loadTimeSimMs ? setTimeout(complete, Config.loadTimeSimMs) : complete();
} else {
reject(Error(err));
// same outcome as above
// Actions.getPostsByPage.failed(err);
}
this.currentRequest = null;
}.bind(us));
});
},
//-- ACTION HANDLERS
onGetPost: function (id) {
function req () {
Request
.get(this.endpoint)
.query({
id: id
})
.end(function (err, res) {
// Here we no longer insert into the local posts member
if (res.ok) {
if (res.body.length > 0) {
Actions.getPost.completed(res.body[0]);
} else {
Actions.getPost.failed('Post (' + id + ') not found');
}
} else {
Actions.getPost.failed(err);
}
});
}
Config.loadTimeSimMs ? setTimeout(req.bind(this), Config.loadTimeSimMs) : req();
},
onModifyPost: function (post, id) {
function req () {
Request
[id ? 'put' : 'post'](id ? this.endpoint+'/'+id : this.endpoint)
.send(post)
.end(function (err, res) {
if (res.ok) {
Actions.modifyPost.completed(res);
} else {
Actions.modifyPost.completed();
}
});
}
Config.loadTimeSimMs ?
setTimeout(req.bind(this), Config.loadTimeSimMs) : req();
}
});We used to fetch all of the posts in the init method and then use the connect mixin in components to wire component state directly to the store. The difference here is the use of the getPostsByPage method. The modify post and get post action handlers are the same as before. Note that the signature for this method has a parameter default of 1 for page number. This syntax is another ES6 treat.
To achieve the pagination, a query is formed to perform an HTTP GET against the JSON Server endpoint. _sort, _order, _start, and _end are parameters supplied by JSON Server to manage collection pagination. Notice that there's an additional parameter to the method that is just called params. This is for any case where callers want to augment the AJAX call with any additional query parameters. Folding in any additional query parameters is achieved by extending the object before transport using the ES6 Object.assign method.
Another notable aspect of the getPostsByPage method is that it uses its own ES6 promise interface instead of relying on the async mechanism supplied by Reflux actions. In fact, it's just a method on the store and not really an async action handler. This is because of a wrinkle in the way async action handlers in Reflux operate. In Reflux, when an action is resolved using the completed method, all of the listeners on that action are fired at once. This means that all then handlers will be called simultaneously for each resolution despite invocations originating from different components with different parameters. For now this isn't an issue because, in the post list component, we'll avoid firing multiple requests at once. However, soon we'll add a search feature that needs to be able to deal with rapid requests since requests will occur in quick succession as the user types. To make resolution more explicit and manage each request promise individually for the search scenario, the async action mechanism has been bypassed.
Along with the post result set, the promise is resolved with the start and end pointers used in the query so that the results can always be accurately spliced into the consuming component's local copy.
The list component needs to track its current page as well as make a new page request when the user scrolls. Almost all of this is new code. Every method in the following source except for render is new, so we've just highlighted the new method names.
File: js/components/posts/list.jsx
import React from 'react'; import ReactDOM from 'react-dom'; import Config from 'appRoot/appConfig'; import PostStore from 'appRoot/stores/posts'; import PostView from 'appRoot/views/posts/view'; import Loader from 'appRoot/components/loader'; export default React.createClass({ getInitialState: function () { return { page: 1, posts: [] }; }, componentWillMount: function () { this.getNextPage(); }, componentDidMount: function () { var ele = ReactDOM.findDOMNode(this).parentNode , style ; while (ele) { style = window.getComputedStyle(ele); if (style.overflow.length || style.overflowY.length || /body/i.test(ele.nodeName) ) { this.scrollParent = ele; break; } else { ele = ele.parentNode; } } this.scrollParent.addEventListener('scroll', this.onScroll); }, componentWillUnmount: function () { this.scrollParent .removeEventListener('scroll', this.onScroll); }, onScroll: function (e) { var scrollEle = this.scrollParent , scrollDiff = Math.abs(scrollEle.scrollHeight - (scrollEle.scrollTop + scrollEle.clientHeight)) ; if (!this.state.loading && !this.state.hitmax && scrollDiff < 100 ) { this.getNextPage(); } }, getNextPage: function () { this.setState({ loading: true }); PostStore.getPostsByPage( this.state.page, this.props ).then(function (results) { var data = results.results; // Make sure we put the data in the correct // location in the array. // If many results are resolved at once // trust the request data for start and end // instead of some internal state Array.prototype.splice.apply(this.state.posts, [results.start, results.end].concat(data)); // user may navigate away – // changing state would cause a warning // So, check if we're mounted when this promise resolves this.isMounted() && this.setState({ loading: false, hitmax: data.length === 0 || data.length < Config.pageSize, page: this.state.page+1 }); }.bind(this), function (err) {}); }, render: function () { var postsUI = this.state.posts.map(function (post) { return <PostView key={post.id} post={post} mode="summary"/>; }); return ( <div className="post-list"> <ul> {postsUI} </ul> {this.state.hitmax && !this.state.loading ? ( <div className="total-posts-msg"> showing { this.state.posts.length } posts </div> ) : '' } {this.state.loading ? <Loader inline={true} /> : ''} </div> ); } });
The component itself is going to maintain a local list of posts and a current page number. These are defaulted during the bootstrap process in the getInitialState method. When the component is about to mount, the componentWillMount method fetches the first page. The getNextPage method manages the loading state and fetches from the store via the getPostsByPage method. First, though, let's look at the componentDidMount method, which attaches the scroll event handlers.
To attach the scroll behavior, the scroll parent must be found. First, the DOM element for this component is obtained, then the code traverses up the DOM in a while loop. This traversal continues until it hits the first element that has an overflow CSS property set to auto, indicating a scrollable container. This is a tricky way to find the scroll parent in both the post list view and the user view by simply styling the container that we want to scroll as we usually would. Once the scroll parent is located, the scroll handler is attached. In the scroll handler, onScroll, some boundaries are checked on every scroll event to determine if the scroll parent is within 100 pixels from the bottom of its scroll height. If it is near the bottom, we aren't currently loading a page, and we haven't already hit the max number of available posts, then the getNextPage method is called.
Turning our attention to the getNextPage method, you can see that the getPostsByPage method is called on the store with the component props used as the additional query parameters. The props are passed through so that the user ID prop, user, in the user view flows through to the HTTP request. This prop goes all the way to the request to JSON Server to filter by user. When the promise resolves, the results are returned and spliced into the local collection. Before setState is called, a check is made to be sure the component is mounted in case the user has navigated away while the request was in flight. React will generate a warning if a setState is invoked on the context of a destroyed component. The hitmax member is a Boolean used to determine if there aren't any more posts to fetch. It is actively calculated each time a post payload is returned.
Finally, the loader is added to the render method. Also, if the maximum number of posts has been reached, a message is displayed reporting the number of posts that have loaded. You may remember this message from our wireframes way back in Chapter 3, Starting a React Application.