
Once someone has been alerted, and they have acknowledged or "ACK"ed an alert, they need to start communicating. My rule of thumb is that you should send a message, no matter what, to all stakeholders every 30 minutes. If nothing has changed, then tell them. Know your audience, so do not go too technical if you do not need to, but if your audience is technical, then share what you can, but keep it brief. If it is an internal communication, then make sure to tell people where to go if they need to know more:

Figure 11: Screenshot of an Imgix (an image CDN company) outage status page. It shows updates from the company to the public in reverse chronological order. The oldest message, at the bottom, is when it first notified the public about the outage, then five minutes later it provided an update. 20 minutes after that, it posted the final message saying the incident was over and had been resolved.
Outside of your 30-minute updates, explain what you're doing in your team chat so that people can follow along and you have a log for the future. You should also do this so that work is not duplicated and people who are helping can contribute with educated questions and suggestions. Even if no one else is awake, it can be helpful for people to read your log when they come online, to understand the current status of the incident.
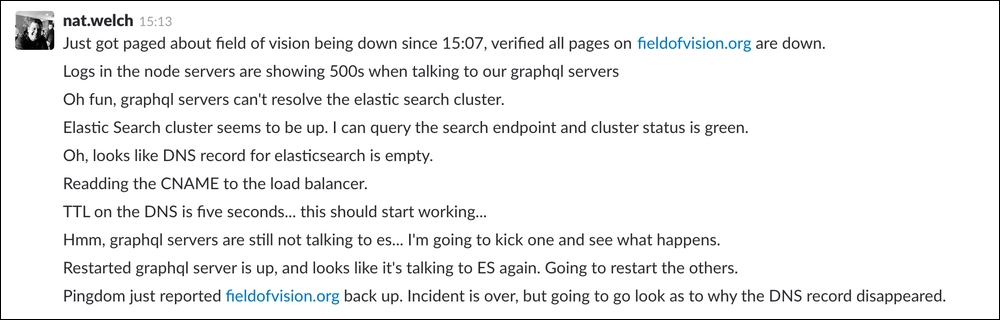
Figure 12: Example of talking to yourself during an outage
A good setup is often two channels. One channel can be used for discussion by people working on the outage and one channel can be used for people affected by the incident. Two channels split the discussion but keep things focused in their respective rooms. Having just the person on your team in charge of communication in the customer channel will also keep messaging consistent and give customers a single point of contact to send information back to the group of folks responding to the incident.
If you use just a single channel to discuss things, then make sure you set the mood as serious and create the expectation that it's a serious discussion place only, so you can keep things on topic and not too noisy. If you don't set this mood, you can get lots of chatter and conflicting information, which may make your incident last longer than it needs to or create extra confusion.
After you are alerted, and you are trying to figure out how to fix things, make sure that you keep talking to your team and also set a time to ask for help. A coworker once suggested that if you still have no idea what is wrong after 10 minutes of working on an issue, then start asking for help. Usually, at 10 minutes I start to ping my secondary, because then I will know whether I can handle it by myself or whether I will need a second pair of hands. If they do not know either, then bring in other people. Slowly grow those involved until you know what is not working and how to make the system healthy.
One important aspect of communication is who is in charge. With all of the communication and the work needed to actually repair a broken system, during a large incident a single person can get overwhelmed. I mentioned bringing people in to help and that's when it helps to have trained your team ahead of time in the National Incident Management System's (NIMS) ICS. ICS is a system from the 1970s, built for combating California wildfires. It focuses on making it easy for many different organizations to work together to deal with an incident. NIMS is a system designed in the US, which adopted and expanded ICS after 9/11. It has been used to respond to all sorts of national disasters across the country.
ICS is often used in the SRE world because of its focus on growing and scaling an ad hoc organization of people responding to an incident, or series of incidents, as the incident grows or continues for long periods of time. This is really important in larger organizations that have lots of teams that may be affected by an outage. For example, a networking outage causes a cascading set of failures across the company. Each team needs to work together to stop more services from failing, to make sure work isn't done twice, and to coordinate messaging to those affected who cannot do anything.
The first rule of ICS is that whoever is on the scene first is in charge. This is almost always the on-call person and they call the shots. If anyone else shows up, then until the role is delegated, no matter the seniority or organization, the first on the scene is in charge. The point of this is to formalize the structure of the incident to make sure no one has multiple bosses. You can imagine the results of this in the scenario of a wildfire. A crew of fire fighters arrives on the scene and they are dealing with the fire. Then, both a police chief and a fire chief show up, then a group of police officers shows up. This is a fire, so people might think that it's best to listen to the fire chief, but the normal structure dictates they must follow the police chief.
Thanks to ICS, the officers don't have to think during the incident because only one person is in charge. That person is the incident commander, who was the initial person to show up on the scene. In this case, it was probably the most senior person of the first fire crew on the scene. However, let us not forget about delegation. There will be tasks that, as the incident commander, you need to delegate away. In our example, you could put the police chief in charge of communication, the fire chief in charge of personnel and supplies, and ask the officers to work on evacuations and appoint one officer in charge of the evacuation work.
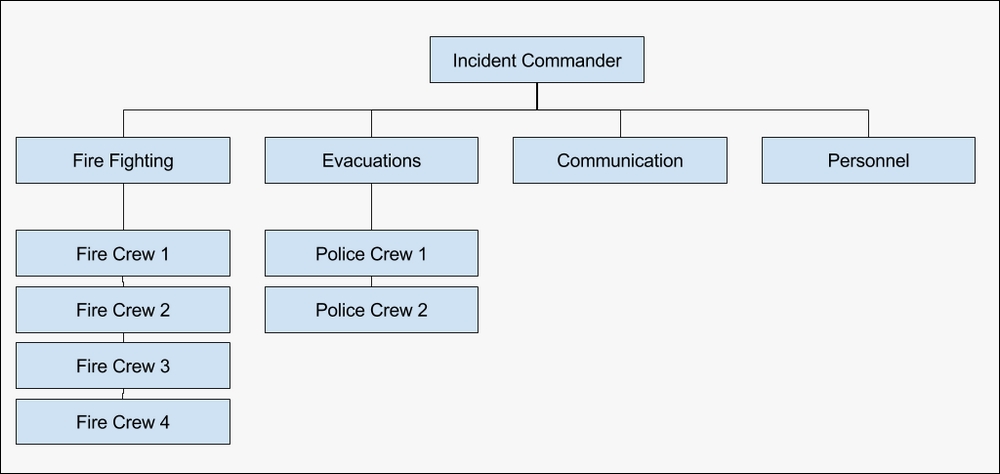
Figure 13: An example ICS structure for responding to something like a wildfire
For software on-call rotations, delegating through communication is often a good first step. Make sure that you tell everyone that this delegation is happening. For example, say, "Chris is now the communications commander and all updates will be coming from him." Then, if an incident goes on for a long time, you may delegate the commander role to someone else, so you can get some sleep. This should be clearly communicated to all and usually included in your next 30-minute update.
Many people have trouble with delegation, or taking charge, when they first go on call. For delegation, if I am the secondary, then I will offer to take over communication by saying something in chat along the lines of "@primary, you seem busy. Would you like me to take over communication and send an update email out?" For dealing with who takes charge, I usually show up with offers to help, but don't do anything until asked.
Often, messages like "@primary, I am online if you need a hand," or "@primary, I saw this graph, would you like me to dig into it?" can help to lower stress for people. Knowing that the primary has help available if they need it often makes people feel more at ease and lets them focus more on the problems at hand. If you go rushing in, trying to help before being asked, people can interpret that as a lack of respect. Other times, they may start interpreting it as you thinking that you are the only one who knows how to do something. Neither of these outcomes are good. You want to support your coworkers. You also want your team to be able to survive an incident, no matter who is on call. This requires everyone on the team to be able to fill roles and feel comfortable filling roles, as needed, during an incident.
The key for where to communicate is to always be consistent and share the location of where the communication is happening often. If the outage is being debugged in lots of places, then people will often make the problem even worse by doing things that do not need to be done. As an example, at one point, I was on an SRE team supporting three separate products. This was not a great situation, but the real issue was that no one knew where to contact us, so often issues would get raised in other teams' channels or in private messages with other people, and this information was not shared with the person who was on call. Outages would then be ignored and would only make it to our on-call person when a customer reached out after noticing an issue.
So, instead, we published an IRC channel and to all three teams we said, "If you need help, come here and we will all talk about it." It took a bit of time, but people started slowly bringing all new issues to that channel and we started delivering a consistent level of quality response to all three teams. This consolidation also helped to fix an issue that was hidden to us until it improved—people on our team felt like they were never able to disconnect. No one voiced this issue, but when random people stopped receiving private messages whenever there was an incident, or question, many voiced a sense of relief and an improvement in their ability to focus during their day.
Outside of internal communications, it often helps to publish public status pages. Things like https://status.cloud.google.com/ or https://www.cloudflarestatus.com/ are useful because your external customers need a place that they can go when there is an issue. Often, linking to these pages from places like Twitter or Facebook will lower the number of emails that your support team receives along the lines of "is something broken?"