
Once work is planned and assigned, you can sit down and start coding. As the developer, you need to remember all of the previous levels of the hierarchy as you introduce new code into your infrastructure. Often, as an SRE, your work will be looked to as a model for what the rest of your developer teams should be doing. If you skimp on a level, you may find the teams and developers you work with also skimping on it because of your example and hypocrisy.
A simple checklist for new software that you are writing based on our hierarchy framework is as follows:
- Monitoring: Do you have basic metrics coming from the code that you are writing? Are they being collected and stored?
- Incident response: Are you writing documentation on how to operate your service? Are there alerts that if they get fired, anyone who receives them will know what to do?
- Postmortems: When your code has an outage, are you treating it like other code having an outage and writing a postmortem?
- Testing and releasing: Are you writing unit and integration tests for your code? Are you documenting both the release process and the rollback process?
- Capacity planning: Are you documenting how this will affect the performance of your system?
Services built by SREs are no different than services built by any other engineer. Making sure you and your team follow the same standards you suggest for others is important.
When I originally outlined this chapter, I wanted to provide tips and best practices on building systems, but most advices that came to mind tended to be too domain specific or hyper specific to certain types of patterns that can appear in code. As I thought about it, I came up with four pieces of advice which can be applied to executing and delivering any project:
- Use version control: This is the use sunscreen of computer programming. There is no project too small that you should not use version control. Humans make mistakes and version control lets you easily revert mistakes or see when a mistake was introduced.
- Always do code reviews: As a developer, you only know so much, so having another set of eyes read over your work helps you to find bugs and remove assumptions that you may have made. Your code deserves at least one editor to help you limit the number of errors.
- All projects should have a designated owner: At some point, all projects will raise questions from external parties. All projects should have a designated owner so there is someone who can answer those questions. It is also important for when you are deciding on priorities. Having an owner means there is one person who can make the final decision on what is most important.
- The problem is always people: As you may have picked up from the previous three suggestions, humans are often the problem. Working with code and knowing that it will be consumed by humans is very important.
This could be by making sure processes are in place to deal with the fact that humans will need to work on the code or by changing how you program to assume that all inputs to your software will come from humans (either directly or indirectly) and thus need to be resilient. Humans will often change requirements, miscommunicate needs, or just cause chaos. Always be ready to be empathetic towards others and your own failures. A willingness to show others kindness and understand their feelings will improve people's moods and probably increase the possibility that they will help you when you fail. Remember that failures will happen, so smile and move forward.
One aspect of software to think about during the design and building phases is the separation of concerns. The idea is that all of the code for dealing with certain types of data should be located together and provide an API, then any other software that wants to work with that data does so through the API. This means that your data is not touched by other code or services. In some cases, this is easy, but more often than not, making data more separated by an API can cause data duplication or poor performance. This is because distributed state management is difficult.
If four pieces of software need to know how much money a user has in their bank account, for example, querying the database may seem easier, but in the long term, calling a well-defined API will make your life easier. An example is changing the schema of how your data is stored. If you keep the API consistent, you can change how the data is stored underneath, without having to update client applications. If you do want to make performance improvements, you can achieve significant gains by just updating the API interface, instead of having to improve every client that talks to your database.
If you do this separation well, then in theory, when needed, you can rip out a part and replace it with a service. A common example of this is authentication. Often teams start with authentication inside their application, but as other services start to need to do authentication, they replace the code in the app with a call to an external service, which presents a similar API.
A somewhat similar idea is the Unix philosophy. This philosophy has a few tenets, but the two that I like to focus on are writing software that does one thing and writing software that works together. You can see this in most common Linux command-line programs. For example, you can take the output of cat and sort it with the sort command. cat file{1,2,3}.txt | sort > sorted.txt takes three files (file1.txt, file2.txt and file3.txt), merges their output into a single stream and then sends that stream to sort, which sorts all of the incoming data, then is written to sorted.txt. The point is that cat, sort, and many other programs use standard input as their text input and standard output as their text output. Normally, a shell writes standard out to the screen, but by adding a pipe (|), your shell points the standard output of the first program into the standard input of the second program.
Note that separation of concerns and the Unix philosophy are often used as reasoning for moving to a service-oriented architecture or microservices. Both of these terms are the idea of separating your code into lots of smaller services or pieces. There are problems with such an infrastructure (more pieces to monitor, possibly more expensive and a higher possibility of a network failure), but usually separation of concerns is not a great argument if it is the sole argument to move. You can separate concerns inside your code if you want, just using separate classes or other organizational techniques.
Another factor that we should probably talk about in regard to development is long-term planning and thinking. So much of modern development is focused around fast iteration, that often people do not remember to look at where they have gone and where they are going. I like to do a quarterly retrospective and plan for myself to solve this. Some businesses have this built into their planning process, but you can also do it for yourself.
A common framework that some businesses use, I also use for my personal planning. It is called objectives and key results (OKRs). The idea behind OKRs is that you take a list of things that you want to achieve, which are objectives, and then create measurable checkpoints as your key results. Then, at the end of the quarter, you look at your OKRs and look at what you planned on doing, before comparing them to what you completed. In a larger, more formal organization, you may score your progress based on the OKRs you completed, but for yourself, it is just a benchmark. Look at what you thought you were going to do and ask: what prevented you from completing some projects? What other things did you do that you didn't plan for? Did you want to do those things? If not, can you make goals for the next quarter to remove them by building a tool to make them easier, automating them, removing the need for them, and so on. Then, looking forward, create new or adjusted OKRs based on the next quarter. Often, I will create year-long goals. Some are work related, such as unifying how all of our services do job scheduling, while some are life related, such as losing 40 pounds of weight. In my current role, my OKRs are completely disconnected from my management structure. So even though my boss is horrible at doing performance reviews, I can still do self-reflection and track progress for both my work and personal life.
The following example is inspired by Niket Desai, a friend and former co-worker. He writes a lot about product management and planning. It's a rough set of scored OKRs that a more formal business might have. This is what you might see at the end of a quarter.
In the table below, we see objectives for a quarter, with their completion percentage at the middle of the quarter, as well as their final score. Then, at the bottom, there is a total average for the whole quarter. The first place I used OKRs regularly was at Google. There, it was suggested that you want to get between 70% and 100% of your objectives. If you hit 100% every quarter, then you aren't aiming high enough.
|
Objective |
Mid |
Score |
|
Increase user base |
0.4 |
0.60 |
|
Improve deploy speed |
0.5 |
0.66 |
|
Investigate A/B testing |
0.4 |
0.75 |
|
Total |
0.43 |
0.67 |
Objective: Increase user base
Owner: Melissa
Key results:
- Increase per-day views to 1,000
- Increase total monthly unique visitors by 45,000
Objective: Improve deploy speed and reliability
Owner: June
Key results:
- Paralyze test builds
- Implement canary rollouts
- Add build asset caching
Objective: Investigate A/B testing
Owner: Xander
Key results:
- Investigate top five A/B testing frameworks
- Implement proof of concept with one framework
- Write design document
- Pitch chosen platform to product team
Another example is much more casual and not scored at all. These are a subset of my goals for 2017. Note that they still have measurable key results and higher-level objectives.
- Improve physical health
- Stretch every morning
- Successfully complete a 5K
- Successfully complete a half marathon
- Cook eight meals a week (out of the 21 possible)
- Record all eating
- Join some sort of sports team
- Put out content to improve the internet
- Take in revenue from one side project
- Write 200 posts in 2016
- Maintain a four-post-per-week average on https://writing.natwelch.com
- Give five talks to groups larger than 10
- Grow your brain
- Read 70 books.
- Go to four art exhibits, live shows, or movies a month.
- Read one non-fiction book a month. Note that I checked out these objectives every quarter to see how I was doing and if I needed to add or remove any goals. This quarterly reflection shows me how much I've progressed in three months, reminds me of things I did and reminds me of things I want to be doing.
Sometimes looking for future ideas can be difficult. I keep a notebook where I write random things in throughout the day. Sometimes I put down ideas that I want to build in the future. Some are one sentence, while others are bullet lists of features and some are very rough infrastructure and architecture sketches or wireframes of user interfaces.
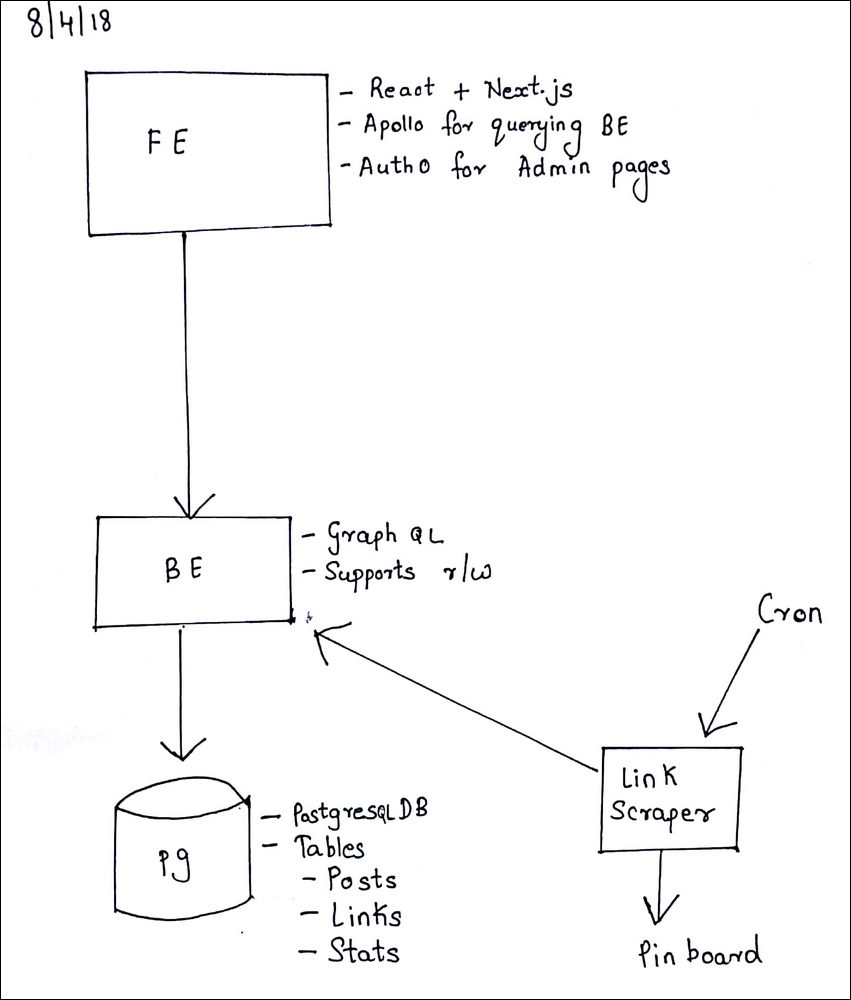
Figure 2: In this photograph, I have sketched out the rough design for a blog. The frontend, or FE, is built in JavaScript using React and Next.js for rendering content. Apollo is used to query the backend (or BE). The backend is a Go app with one path, /graphql, which controls the data. It sits on top of a PostgreSQL database for storing state. There is also a cron job that gets data from an external service, Pinboard, and makes queries to the GraphQL endpoint.
Notebooks are also great places to record how you are feeling, things you want to do, and things you want to get off your chest. A classic tool is to write a letter to a person you are angry with and then never do anything with it. I used to write these in emails, often in an inebriated state and still ended up sending a few, which often got me into trouble or hurt a relationship with someone when I didn't need to do that. By writing it on paper, that never happens! There's no way that I can accidentally send an email when it's on paper.