
This chapter could easily be two books, as testing and releasing are both very complex fields. There are folks, who refer to themselves as software test engineers and release engineers, who specialize in both these fields. The two topics are very closely integrated when it comes to reliability. They form the first layer of preventative reliability. While Chapter 2, Monitoring and Chapter 3, Incident Response were about reacting to the current state and Chapter 4, Postmortems was all about looking back, this chapter focuses on looking into the future.
Testing and releasing are processes that are often set up early in a project and then are forgotten. Many engineers assume that tests will just run and code can be released. However, processes that are built for a few engineers don't necessarily scale to larger teams. For projects that last a long time (years for example), improving the releasing and testing process is often ignored until an organization is much larger and scale begins to cause issues with the existing processes. Improving a team's developer tooling can often lead to productivity and developer happiness, and make it easier to release fixes for issues found in incidents.
That being said, both testing and releasing are very large topics. We will be approaching them mainly from a reliability aspect. You will learn how to invest in them and how to work with your teammates to make them valuable tools.
This chapter will focus on what to test and how to test it. It will also take a look at releasing software and the strategies and timing around releasing. After this chapter, you should have ideas about how to improve the experience of the teams you support as well as how to deploy code in a safe and stable way.
Figure 1: Our current position in the hierarchy
To test something is to verify that it works as expected. You can test just about everything and in a sense, testing is very similar to the analysis mentioned in Chapter 4, Postmortems. However, instead of coming up with a hypothesis, you are taking something that you want to exist, creating it, and then verifying that the thing you created does what you want. Be aware of the famous Dijkstra quote: "Testing shows the presence, not the absence of bugs." This is another way of saying that whatever hypothesis you test, you will not necessarily invalidate other hypotheses.
Some people ask why you should bother with testing. There is a belief that often exists, when people haven't done much programming with larger groups, that testing is pointless. This belief often comes from being told that testing is important but not seeing any immediate benefits. Testing can be frustrating and daunting, but it is not pointless because, as we have mentioned, humans are flawed. We misremember, misread, and misunderstand all the time. When we are programming and working with humans, we must not ignore this fact. When you write code, you make assumptions. Testing is important so, when someone else is working on code you wrote, they can verify that they did not break any of the assumptions that you made. For example, if you assume your function for putting sprinkles on ice cream will always be called after ice cream is put in a cup, someone will undoubtedly call it when there is no ice cream in your cup. Your code will then probably break. Instead, you need to add tests to validate that your code is only called at the right time and that it responds correctly when called with state or arguments that you did not expect.
As an individual developer, a common feeling is that you do not need anyone else to understand your code. You can keep all of the code you have written in your head. You wrote most of the code you are interfacing with, and you know how the code is used, so it will probably not break. This belief is not wrong. Smaller projects or features are often worked on by individuals, but holding this belief assumes two things—you will be the only one who works on that piece of code and that over time, you will not forget what you did. I cannot speak for every human, but my memory is horrible. I rely heavily on computers to show up at places on time, let alone to remember every piece of work I have ever created.
My brain, like most people's, often misremembers things or completely forgets them. Outside of my many abandoned side projects, most of the code that I have written has been picked up or modified by someone else. While these examples are from my own life, most software developers forget things and most software is touched by multiple engineers, if you look at the industry. Most software is written by teams.
On average, software engineers stay at a company for four years in the US, according to a study by the Bureau of Labor Statistics in 2016 (https://www.bls.gov/news.release/pdf/tenure.pdf) (according to other studies, it is much lower (https://hackerlife.co/blog/san-francisco-large-corporation-employee-tenure). This implies that if your code lasts for a few years, your team structure will change, as will who will work on the code.
Regarding memory, I propose a simple test. Try and remember everything that was in the room you slept in last night. If it was destroyed, could you recreate a list of everything in it to send to an insurance agent? While I don't doubt you could get the broad strokes (your bed, maybe some things on the walls and the stuff on your nightstand), getting a list together of everything under your bed or in drawers or closets gets more difficult. This may sound like a false dichotomy, but the point is that human memory is flawed. To assume you will remember every bit of code you have ever written, and how it works, forever, is just an absurd proposition.
One of the great quotes that I heard while learning to code is that software is 20% creation and 80% maintenance. Dr. John Dalbey told me this originally and although there is a lot of argument on the internet as to whether this number is made up, it's still interesting to think about. More likely, it comes from the idea of the Pareto Principle, which says that 20% of the causes create 80% of the effects. All of that aside, you can take away the idea that in a professional setting, software is usually created for something that will exist for a while.
If you are working on the initial 20%, there is a high chance that there will be maintenance required further down the line because of changes in your organization, environment, or requirements. Software, despite all of our hopes and dreams, is not static. Requirements always change because humans have no idea what they want and have a severe inability to describe and outline what they want accurately.
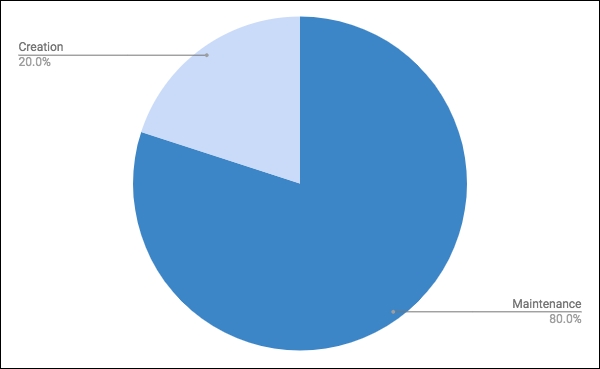
Figure 2: A graph of software development time
On top of an almost guaranteed need to change software as its definition and requirements change, there is the fact that software testing can be more fragile than the software itself. One of the more famous problems in computer science is the "halting problem". It says that we cannot know whether a program will finish or run forever, given a random program and inputs. This is actually a semi-complicated piece of mathematical theory but, basically, there is no one test or function you can run that will prove whether any program will finish. You can write a test for a single program, but you can't write one test for every program. Alan Turing proved this in 1936 in his paper On Computable Numbers, with an Application to the Entscheidungsproblem. So, given this, tests need to be written uniquely for each piece of software. This is annoying (how great would it be to have a test that worked on all of the code ever written?), but it allows us to write down our assumptions, so that when we need to maintain our software, or someone else's software, we can have some degree of assurance that our changes will not break the system.
Smaller organizations may also want to ignore testing because it slows them down. They have to take the time to write the tests, then they have to run the tests and that can be slow. Some companies believe that a far better idea is to just have one person who has all of the test cases in their head and can click through the website or decide whether the code has bugs in it or not.
That is ridiculous. Based on our previous statement, that is not possible. No one person should be held accountable for verifying whether software is correct or working properly. Your team should not just be writing code and throwing it at someone and saying, "Hey, does this work right?" Instead, if you do not want to write code tests, then work as a team to create a verification checklist. For every release, have everyone who has code in the release go through the checklist. This checklist can then also be grown and modified based on postmortems and new features.
I mentioned earlier that reliability is a team sport. Writing software is a team sport. Building things is a team sport. If you do not understand how to verify whether what you are building is correct, then expecting someone else to do so is just absurd. This is not to say that everyone should know everything, nor that everything should always be tested, but being able to write code that proves what you wrote works is just a good idea. Like most of SRE, testing is an exercise in finding the right balance between effort and risk. Your team needs to figure out what to test and what you can ignore testing, so that your team can move at the appropriate speed and also not have code failing all of the time. If you are too risky, people will burn out reacting to failures. Inversely, if you are too safe, you will not release new things fast enough for your small business to survive in the market.
Larger organizations are essentially just lots of small organizations unified together under similar goals. They need to make the same evaluations as small organizations do, but they often need to weigh the company's external reputation as well. Google, for instance, cannot launch new things as easily now that it is so large because customers expect the same reliability and polish from products that have existed for years. New products, then, have to include that reality in their evaluation of how much risk they can take. The upside, though, is that they usually have more infrastructure and support available to them to make testing easier and faster.
With larger organizations, you might also find yourself shunted into a specialized role. It might feel like testing is not your responsibility. Just remember it is not only your job to fight fires, but it is also your job to prevent them. We have mentioned this a few times but it bears repeating: an SRE is not just a sysadmin, nor are they just a software engineer. As an SRE, you can and should help those you support to write code, write tests, and promote reliability. Just as people should not be relying on a single person for testing, you should not be relying on others to be the sole developers of application code, nor should they expect you to be the sole owner of infrastructure. All of this requires teamwork.
As you make the argument to your team to write tests, or improve testing, it often helps to have a few suggestions on what to test. Let us talk about that next.
Hopefully, you now think that testing is important or at least not a waste of time. So, what do you test? There are many philosophies on this topic and I urge you to do lots of research, but I will try to provide some guidance on how to think about what to test.
First, let us ask a question: what can we test? We could test every line of code. We could test every piece of infrastructure. We could make sure that every random piece of user input does not break us. We could even test ourselves, to understand where our processes fall apart. Which of these should we invest our time and energy in? Deciding how much to test is an evaluation between risk and time. Only you and your team can figure out where the line truly is.
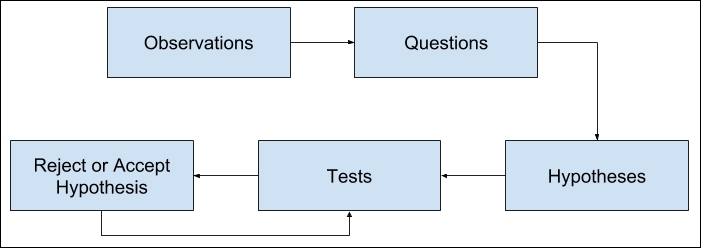
Figure 3: The scientific method
Whatever you do test, it will be iterative and should roughly follow the scientific method. For those who do not know this method, or if you have trouble applying it to software, the rough steps are as follows:
- Observe: This is often seeing an outage, getting a requirement, or just writing the software.
- Question: Ask yourself, what happens when software gets this type of input, or this dependency goes away, or the software gets into this state?
- Hypothesis: Come up with a hypothesis. In code, this is more asking what you want to happen.
- Test: Do the thing and ask, does the code react in the way I want?
- Reject or approve: If your test failed, then you need to modify something (tests, code, infrastructure, processes, and so on) to meet your expectations.
Testing in the software world differs from normal scientific testing because often, instead of trying to figure out how something works, you are instead trying to verify that things are working the way you want them to.
Testing code is often the most laborious type of testing, but it is also where people frequently start their testing. This is because it is the most obvious work output for most software developers. They are tasked with writing code and want to make sure they have done a good job. They also want to make sure a user's random inputs do not break things and that the code works properly with everyone else's code.
The most basic type of code test is a code review. Code reviews are not what people think about when they think of testing code, but they are a second pair of eyes validating your changes. For those that do not know much about code reviews, they are the act of taking a set of changes before they are released and having a coworker read through them. That coworker will make suggestions on code style, logic, and implementation. The two of you will then go back and forth, iterating until you are both happy with the code, and then release it. Releasing, in this case, is done by merging code into a shared repository. GitHub provides this to developers through pull requests. Git itself uses email to do this. Other systems people use include Trac, Gerrit, GitLab, and Phabricator.
If you are asked to be a code reviewer, try to be thorough and find code paths the developer may have overlooked. Make sure to read the surrounding code and understand how this change interacts with the rest of the system. Also, be sure to read the messages left in the code review by the developer, and any related issues or tickets, to make sure you understand the context of this change.
My aim, when I am a reviewer, is to reply to code reviews in one business day, assuming that the changes are not gigantic. Asking reviewers to shrink the size of their changes is always a good idea if they are too big. The goal should be to have related code in a single change set, but to make the chunk of code as small as possible to still be easily understood in a quick reading. Try not to be a jerk. As software development is a team exercise, you will often need to work with the person whose code you are reviewing. They will also probably review your code in the near future. Be nice, be courteous, be understanding, and provide constructive feedback. The point is to work together to make better code, not to belittle the other person or prove that you are somehow smarter.
As a code submitter, be considerate of the reviewer's time when requesting a review. Make sure things are well documented and that you have done the basics, such as validating that you have passing tests and passing any lint checks you might have. You can automate lint checks and test running using tools such as Git commit hooks. Many source code repositories can also be configured to automatically run tests when sent new code.
Note
Linting is the act of making sure that your code matches a specific style. It is great for helping projects with lots of developers to stick to a consistent code style. Linting and test running are useful processes to automate. We will talk about this in a bit, but anything you want someone to do before requesting a code review can usually be automated.
It's important to not take offense when reading code reviews. Rarely do code reviewers mean you any ill will. Instead, assume that your colleagues have the best intentions when suggesting changes. If their changes are significant, talk to the reviewers about the changes and see if waiting would be fine. I often file tickets from a code reviewer's suggestions if they request that I rewrite a large section of code. First, I try and understand why the request is being made and evaluate it. Not all suggestions are good, but it is useful to work with your reviewer to find a common ground. Is it just a difference in style or is there a deeper unaddressed concern? The filing of the ticket lets me return to the code, but I am still able to move forward. If there is something important though, such as a security concern, I will take the time immediately to fix the code, instead of delaying.
The goal of code reviews is to work together with another person to make sure that your code does what you want it to. Together, you can find the oversights and weaknesses of an individual's work and create more robust software.
There are many types of tests for code, but I tend to group them into three categories:
I will go into some detail on these three categories but first a caveat: do not get too hung up on writing the perfect test in each category. It's more important to test the thing you want to test. Do you want to test what happens when a user creates a username with an emoji in it? Find a level of testing that makes the most sense to you, instead of getting hung up on making sure that you stick perfectly to any one model of test category.
Unit tests tend to be small and some of the most prolific tests in existence. Test-driven development (TDD) is the mentality that you should write a test for every feature before you write any code. Those who follow TDD often write thousands of unit tests to make sure that the code they are writing sticks to their initial specification. I personally find TDD exhausting, but it is very popular and a great way to make sure that what you are writing is tested.
What is a good unit test suite? It is something that validates that your function performs correctly when given valid input, but also tests failure conditions when bad input is given. If the function is dependent on external factors, such as a database or external API, then it mocks that service, so only the local code is tested. If there are multiple types of responses that the function can respond with, making sure that the suite includes tests for all states is important. For example, if there is a user modification function, make sure to test that it can create a user, modify an existing user, or produce an error if the user does not exist.
One thing to note is that mocking (or stubbing or faking) external services is not required for unit tests. If your system has a lot of networked dependencies, it might be a good idea to not stub your dependencies but instead to guarantee that your code deals with network latency correctly. This is up to you and your team though. The reason people usually recommend that you mock your dependencies in unit tests is that you just want to be testing the logic inside of your method and not your dependencies. The problem with this is that you also often get people who only write simple mocks that don't deal with edge cases of services being disconnected or sending in corrupted data. You are probably seeing the problem with my statement though. Your dependencies will not always be in good or bad states, so you are not testing those either. There is not a good answer here. Testing every state for every dependency is hard and takes a lot of time. Finding the right solution is difficult and so far, I have not seen great answers. Some people suggest recording states using VCR tools. VCR is a library from the Ruby world that saves the response for a request into a file and then uses it for future tests. Others suggest using complicated mocking frameworks (which use code to imitate external systems), while some people advise not using any mocks.
Feature tests are for testing features, as you might expect. I tend to group feature tests into two groups: smoke and acceptance tests. Smoke tests should be run always and are often the very core features that you do not want to change. Smoke tests should be fast and easy to run. Acceptance tests, on the other hand, are often in-depth tests that will test many features. They tend to contain lots of edge cases. The goal for all feature tests is to make sure that features for a part of a service are working. You still should mock out external services (such as databases, external APIs, and so on) like you do in unit tests, but instead of testing a small function, test the business logic, user interactions, and data flow through multiple functions. Often feature tests will test an API, for example, making sure that it conforms to a published specification.
Integration tests, on the other hand, test the entire flow of data between services. They do not mock anything. They fire off an initial request and monitor to make sure everything happens correctly. An example integration test might be an API request to a virtual machine creation service that waits for a virtual machine instance to spin up and then tries to SSH into the machine to mark the test as passed. Another example is making API calls to add a product to a shopping cart, checkout with the item, and then cancel the order. Integration tests are sometimes not run as part of development because they tend to be slow. Instead, they are more often run as hourly or daily cron jobs.
Integration tests are complicated, though, because as your systems become sufficiently complex, the chance that one of your services is always acting in a degraded state increases. In these cases, more often than not you are testing how your error handling works as systems and dependencies are in various states of health.
If you have tests that require everything to be working properly to pass, then you might want to think about your systems architecture. When one of your dependencies fails, are you okay with that level of outage? Your integration tests' fragility will often reflect the fragility of your architecture and users' experience.
There are other ways to test your code, including static analysis and fuzzing, but the above strategies are great starting points. If you are doing code reviews and have some degree of tests at all three levels, you will be well on your way to more stable code.
Note
Negative testing
While not necessarily a type of testing, negative testing is an important methodology to keep in mind. The theory goes that people will always input data that you are not expecting. This could be input with unusual characters or code meant to cause a security vulnerability, or your users could just be doing things in an unexpected way.
When testing, try to come up with as many unusual cases for input as possible. Your users will often think differently than you and there will always be users who do not have good intentions or send you unusual input.
Another area to test besides your code is the infrastructure that your code runs on. When I talk about infrastructure, the line is becoming more and more blurred, as now everything in your datacenter can be software defined if you want. So, I will start with this—if you write code to maintain your infrastructure, such as a job scheduler or a vulnerability scanner, that code should have similar testing just like application code.
Testing infrastructure is interesting because there are multiple layers. One aspect is making sure that your infrastructure is configured correctly. Another aspect is ensuring that your infrastructure deals with single pieces failing at any one time. Finally, testing is important to make sure that new code can handle production's level of operation.
Configuration testing is often the easiest. It depends on your tooling, but whether you are using Chef, Puppet, Ansible, Salt, or Terraform, all these tools have a way to validate and test their configs. Once you have tested the actual configuration, you can test its application to a similar environment. Often, people will have a staging environment which is a clone of their production one but with slightly less resources. This is easier in setups where you use cloud infrastructure but finding ways to run your infrastructure configuration in a separate environment is very useful.
After verifying that your infrastructure is configured correctly, it can be a good idea to have some sort of regular verification that things have not changed. Monitoring server health, system configuration, and general infrastructure changes can keep your mind at ease. You can monitor lots of system metrics, from the classics like CPU, memory, disk space, and network traffic, to the number of applications deployed on a system or the number of applications behind each load balancer. One of my favorite metrics is bastion SSH logins by a user. You can watch to see who is actually connecting to your infrastructure in unsafe ways. If you are running in a cloud service, they often also provide audit logs, which let you see what API calls people are making against your infrastructure. If you run some sort of service discovery system, you can record the metrics of how many instances of a service are discoverable, compared to how many are configured. It all depends on how you have your infrastructure set up, but pulling in metrics about what is currently available, versus what is configured, can be very useful.
Once you know that your environment is created and configured correctly, you can start testing by removing pieces and testing failover. One of the more prominent tools for testing failover is Netflix's Chaos Monkey. The idea is that you can have a piece of software constantly killing or disabling software throughout your environment. By assuming this chaos is always there, you will, in theory, start writing software which is defensive and not as delicate as software that assumes things will always be working. There are other pieces of software that do this, but you can also do the same thing yourself. The key is to make a plan, have a recovery plan in case things break, and then execute it and monitor the results. An example experiment might look like this:
What if we remove access to memcached? We could test it by spinning up an extra server, sending fake traffic to it, and then turning off its access to memcached. Now, because it's not a normal production server, we don't need an off switch there, but if we need to cancel the test, we will stop sending traffic to the test server. We will look at error counts before, during, and after memcached removal to see how the system reacts.
This example may seem contrived, but in comparison you can also probably imagine the outage that might happen if one of your dependencies just dies and disappears in the middle of the night. Maybe your system is incredibly well architected and nothing bad happens, but often when your organization is building things and moving fast, you skip this part until it becomes an issue.
This field is now called Chaos Engineering. There are automated tools to kill Docker containers, add network latency, cause issues with CPU and RAM, and really cause chaos at every level. One of my favorite implementations was at Google where for a while it had a separate wireless network that acted like a 2G EDGE cell phone connection. You could connect to it and see how different the network speed made your browsing experience.
Another area which is often ignored is data recovery testing. I usually view this as the inverse of testing absence because this is testing your backups of stateful data systems to make sure that you can come back from a catastrophic failure. This usually involves three steps for everything you consider to be a datastore or database:
- Are you backing up your data regularly?
- Are you regularly testing restoring your data?
- Are you validating that restored data?
You cannot easily test backups if they do not exist, so that's usually a good starting place. The next test is trying to restore one of your backups. You can do this test manually, but make sure to have someone try to do the restore who is not the same person who set up the backups. Does everyone know there are backups? Do they know where the backups are? Do they know how to restore the backup? Once you have restored the backup, how do you verify that all of the data is there? Is there another source of truth you can look at or does it require you to look at your working database to verify the restore? Once you have done all of this manually, automate the test! Have it run regularly.
Since you have tested how things deal with the possible chaos of the environment, you should also test how they deal with real-world traffic. One way to do this is to write load tests. These are scripts that create artificial amounts of traffic. Often, they generate spikes of traffic that all match a certain pattern. There are lots of pieces of software which will do this for you, including:
- Apache Bench
- Siege
- wrk
- beeswithmachineguns
- hey
Most of these tools work in a similar way. You provide them with a URL, a number of connections to make, and a test duration, and they will send many HTTP requests to the URL in the duration. These HTTP requests are network traffic to your application. My personal favorite is hey, mainly because I like the name. That is not a great reason for choosing a piece of software, but since most of these tools act in the same way, it serves my needs. hey is also interesting to me because it is written in Go, so it's easy to read the source code, and it runs locally. All of the provided scripts above run locally as well except for beeswithmachineguns, which actually creates virtual machines in AWS and then runs there.
The default way to run hey is just with a URL:

By default, hey sends 200 requests at a concurrency level of 50. This means that it opens 50 channels and sends 200 requests as fast as it can. In this example request to etsy.com, hey made on average 12 requests per second. Next, we will tell hey to send one request every second, on a single channel, and only send 20 requests. Math says that this should take only 20 seconds (20 * 1 * 1 = 20), but because of network latency, and how long requests take to complete, it may take a longer or shorter time.
Also, because requests per second is an average over all requests, we will actually see a QPS less than one because of server processing time and networking transfer times. Note the Details section, which shows how time was spent by the client when sending and receiving HTTP requests:
$ hey -q 1 -c 1 -n 20 https://etsy.com Summary: Total: 27.8880 secs Slowest: 1.9484 secs Fastest: 0.9688 secs Average: 1.3444 secs Requests/sec: 0.7172 Response time histogram: 0.969 [1] | ∎∎∎∎∎∎∎∎∎∎ 1.067 [4] | ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 1.165 [2] | ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 1.263 [2] | ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 1.361 [3] | ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 1.459 [2] | ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 1.557 [1] | ∎∎∎∎∎∎∎∎∎∎ 1.655 [1] | ∎∎∎∎∎∎∎∎∎∎ 1.752 [1] | ∎∎∎∎∎∎∎∎∎∎ 1.850 [1] | ∎∎∎∎∎∎∎∎∎∎ 1.948 [2] | ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ Latency distribution: 10% in 0.9828 secs 25% in 1.0822 secs 50% in 1.3048 secs 75% in 1.6352 secs 90% in 1.9073 secs 95% in 1.9484 secs Details (average, fastest, slowest): DNS+dialup: 0.0428 secs, 0.0000 secs, 0.8559 secs DNS-lookup: 0.0209 secs, 0.0017 secs, 0.3805 secs req write: 0.0001 secs, 0.0000 secs, 0.0002 secs resp wait: 0.3897 secs, 0.2737 secs, 0.5480 secs resp read: 0.3370 secs, 0.0763 secs, 1.0449 secs Status code distribution: [200] 20 responses
While load tests can be useful for understanding how a service handles large amounts of requests, often this is unrealistic compared to normal web service traffic. Normal web traffic is very diverse and we will never see a uniform distribution of traffic. You get normal users trying all sorts of things all at the same time, plus random users driving by hitting random URLs and sending you arbitrary payloads.
To deal with this, people often test with production traffic. This concept scares people, but the two most common methods, shadow testing and canarying, are very useful. They scare people because you are putting services into production that you know could have bugs. The usual answer to this is that your code should deal with any system failing, but also that would be true of any code you launch into production because it all could have bugs.
Shadow testing is the act of recording requests to a service and then replaying them to a new version of the app, as a way to test it. This lets you take production traffic and have it tested against new code, without the cost of running it in front of actual production traffic. This can be difficult to set up but can be good for validating in certain types of scenarios.
Some tools for shadow testing include:
- For HTTP requests there is vegeta (https://github.com/tsenart/vegeta) and goreplay (https://goreplay.org)
- For raw TCP there is tcpreplay (http://tcpreplay.appneta.com/)
- For database queries there is query-playback (https://github.com/Percona-Lab/query-playback) and mongoreplay (https://github.com/mongodb/mongo-tools/tree/master/mongoreplay)
There are other tools as well, but these are just a sample.
A much simpler and more common method of testing against production traffic is canarying. Canarying is the act of introducing an instance of a service that is new and having it get a small portion of traffic. So, for instance, you have new code, or a new type of server or something, and you slowly divert traffic to it. You first send 1%, then 10%, then 50%, and finally 100% of traffic. This is the equivalent of putting your foot in the pool to see if it is too cold. It lets you verify that the code can handle normal traffic patterns, without exposing every single user to the new code. If you are doing a canary, make sure that the traffic you send to it is representative. For many services, 1% of traffic is not enough to effectively test your application.
Monitoring is what makes something like canarying work. When you have insight into your entire system, you can know whether there are bugs firing from the new code. Another testing methodology, that only really works when you have extensive monitoring, is feature flags. Feature flags work like canarying, but instead of using the deployment to separate the new code from the old, you use code. Feature flags let you surround new features or code paths with a Boolean statement. This Boolean statement says whether this feature is enabled for this user then continues. So, you can do things like only letting 10% of logged- in users see a feature or only letting employees see a feature. With monitoring, you can then see whether certain code paths are erring more than others. Feature flags can make debugging more difficult because if a user is seeing unusual things while using your service, then you may need to first figure out what features they are enabled for, before you can properly debug their experience.
Without monitoring, testing in production like this is very dangerous because you have little or no visibility of the effect your changes are having on everyone. The whole point of testing is to verify your hypothesis. If you have no way of seeing the results of your test, then you cannot verify anything, thus you are not actually testing anything.
Outside of testing computers and software, it is important to test processes and humans as well. The first process I want to bring your attention to comes from Google and has a rich history. The process I am referring to is DiRT (https://queue.acm.org/detail.cfm?id=2371516). DiRT is a yearly exercise where Google plans for large outages to see how teams react. DiRT (Disaster Recovery Testing) examples include making Google headquarters unreachable, shutting down systems that large numbers of teams are dependent on, taking a datacenter offline, and planning unified outages across multiple teams.
What makes DiRT particularly useful is not the scale of the outages, but that it prompts teams to plan their own training exercises during the week and provides resources to help teams to have successful experiments. Some experiments are purely theoretical, some are against testing servers, and some are against actual production systems. DiRT also tests people and systems. So, if everyone is forced to evacuate the building, can you still respond to an incident? Are there certain processes that only have one person who can do the thing?
The idea of such large-scale testing is very similar to the idea of a military exercise, where you get multiple arms of the military to work together to practice a war. Modern versions of this apparently came from the RAND corporation after World War II but can be traced as far back as the 19th century Prussians, who ran practice war simulations under the name of Kriegsspiel. Similarly, schools in California regularly have earthquake drills. On an even larger scale, Mexico holds a national public earthquake drill every year on September 19th.
This has been happening since 1985 when an 8.1 magnitude earthquake killed tens of thousands of people. It has led to heightened preparedness among the populace and is believed to be one of the main reasons that a similar 2017 quake killed approximately 200 people, instead of two magnitudes more.
While DiRT is a yearly large-scale test, like the Mexico drill, a much smaller but lighter weight test is the Wheel of Misfortune (also known as a WoM or Gameday). A WoM is a role-playing exercise, closer to the scale of a school earthquake drill. A WoM is where a person comes up with a scenario and then has someone pretend to be on-call and respond to the scenario. In most cases, the on-call person receives something like an outage notification and then talks through the scenario with the person running the scenario (the game master or GM). The GM will provide example graphs or describe what the on-call sees when they run a command or look at a tool.
A WoM is best done in a room with others watching and not talking. After the fake incident happens, which should be limited to a certain amount of time to respect everyone's time, open the floor for questions. Often, people will wonder why an on-call person tried something or how to do something in real life. Attendees might also want more detail about the incident. If it is based on a real outage, providing the postmortem or explaining how this scenario relates to real life is helpful.
Finally, you can test things before they are ever created. You can do this by holding design reviews. A design review is a meeting held in a similar way to a postmortem meeting (see Chapter 4, Postmortems), but instead of discussing a document talking about a past incident, you talk about the design of a piece of software you want to write. The document should be sent around ahead of time and include what problem you're solving, how you're solving it, other possible solutions you're not using, and anything else you think is important. A design review meeting then lets people poke holes in your design and talk about possible outages and problems that might arise.
Sometimes, no one sees anything wrong, while other times they will correct assumptions about dependencies or talk about possible concurrency issues. Design reviews aren't perfect because they often talk about theoretical software, but they can help you to move in the correct direction and also prime people to think about how new code will interact with the rest of the system and maybe cause other outages.