
![]()
NULLs and Other Pitfalls
A NULL value represents the absence of data, in other words, data that is missing or unknown. When coding queries, stored procedures, or any other T-SQL, it is important to keep in mind the nullability of data because it will affect many aspects of your logic. For example, the result of any operator (for example, +, -, AND, and OR) when either operand is NULL is NULL.
- NULL + 10 = NULL
- NULL OR TRUE = NULL
- NULL OR FALSE = NULL
Many functions will also return NULL when an input is NULL. This chapter discusses how to use SQL Server’s built-in functions and other common logic to overcome some of the hurdles associated with working with NULL values. Table 3-1 describes some of the functions that SQL Server provides to work with NULL values.
Table 3-1. NULL Functions
These next few recipes will demonstrate these functions in action.
3-1. Replacing NULL with an Alternate Value
Problem
You are selecting rows from a table, and your results contain NULL values. You would like to replace the NULL values with an alternate value.
Solution
ISNULLvalidates whether an expression is NULL and, if so, replaces the NULL value with an alternate value. In this example, any NULL value in the CreditCardApprovalCode column will be replaced with the value 0:
SELECT h.SalesOrderID,
h.CreditCardApprovalCode,
CreditApprovalCode_Display = ISNULL(h.CreditCardApprovalCode,
'**NO APPROVAL**')
FROM Sales.SalesOrderHeader h ;
This returns the following (abridged) results:
SalesOrderID CreditCardApprovalCode CreditApprovalCode_Display
43735 1034619Vi33896 1034619Vi33896
43736 1135092Vi7270 1135092Vi7270
43737 NULL **NO APPROVAL**
43738 631125Vi62053 631125Vi62053
43739 NULL **NO APPROVAL**
43740 834624Vi94036 834624Vi94036
How It Works
In this example, the column CreditCardApprovalCode contains NULL values for rows where there is no credit approval. This query returns the original value of CreditCardApprovalCode in the second column. In the third column, the query uses the ISNULL function to evaluate each CreditCardApprovalCode. If the value is NULL, the value passed to the second parameter of ISNULL—**NO APPROVAL**'—is returned.
It is important to note that the return type of ISNULL is the same as the type of the first parameter. To illustrate this, view the following SELECT statements and their results. The first statement attempts to return a string when the first input to ISNULL is an integer:
SELECT ISNULL(CAST(NULL AS INT), 'String Value') ;
This query returns the following:
Msg 245, Level 16, State 1, Line 1
Conversion failed when converting the varchar value 'String Value' to data type int.
The second example attempts to return a string that is longer than the defined length of the first input:
SELECT ISNULL(CAST(NULL AS CHAR(10)), '20 characters*******') ;
This query returns the following:
----------
20 charact
Note that the 20-character string is truncated to 10 characters. This behavior can be tricky because the type of the second parameter is not checked until it is used. For example, if the first example is modified so that the non-NULL value is supplied in the first parameter, no error is generated.
SELECT ISNULL(1, 'String Value') ;
This query returns the following:
-----------
1
No error is generated in this query because the second parameter is not used. When testing your use of ISNULL, it is important both to test the conditions where NULL and non-NULL values are supplied to the first parameter and to take note that any string values are not truncated.
3-2. Returning the First Non-NULL Value from a List
Problem
You have a list of values that may contain NULLs, and you would like to return the first non-NULL value from your list.
Solution
The COALESCE function returns the first non-NULL value from a provided list of expressions. The syntax is as follows:
COALESCE ( expression [ ,…n ] )
This recipe demonstrates how to use COALESCE to return the first occurrence of a non-NULL value:
SELECT c.CustomerID,
SalesPersonPhone = spp.PhoneNumber,
CustomerPhone = pp.PhoneNumber,
PhoneNumber = COALESCE(pp.PhoneNumber, spp.PhoneNumber, '**NO PHONE**')
FROM Sales.Customer c
LEFT OUTER JOIN Sales.Store s
ON c.StoreID = s.BusinessEntityID
LEFT OUTER JOIN Person.PersonPhone spp
ON s.SalesPersonID = spp.BusinessEntityID
LEFT OUTER JOIN Person.PersonPhone pp
ON c.CustomerID = pp.BusinessEntityID
ORDER BY CustomerID ;
This returns the following (abridged) results:

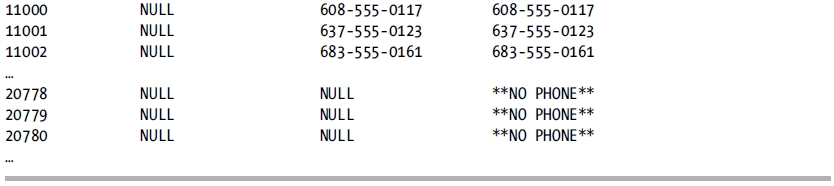
How It Works
In this recipe, you know that a customer is either a customer in the Person table or the SalesPerson associated with a Store. You would like to return the PhoneNumber associated with all of your customers. You use the COALESCE function to return the customer’s PhoneNumber if it exists; otherwise, you return the SalesPerson’s PhoneNumber. Note that a third value was added to the COALESCE function: '** NO PHONE **'. The COALESCE function will not return a non-NULL value and will raise an error if all choices evaluate to NULL. It is good practice when using COALESCE in conjunction with an OUTER JOIN or NULLABLE columns to add a known non-NULL value to the list of choices for COALESCE to choose from.
3-3. Choosing Between ISNULL and COALESCE in a SELECT Statement
Problem
You are coding a SELECT statement, and the calling application expects that NULL values will be replaced with non-NULL alternates. You know that you can choose between ISNULL and COALESCE to perform the operation but cannot decide which option is best.
Solution
There are generally two camps when it comes to making one’s mind up between ISNULL and COALESCE:
- ISNULL is easier to spell, and the name makes more sense; use COALESCE only if you have more than two arguments and even then consider chaining your calls to ISNULL to avoid COALESCE, like so: ISNULL(value1, ISNULL(value2, ISNULL(value3, ''))).
- COALESCE is more flexible and is part of the ANSI standard SQL so is a more portable function if a developer is writing SQL on more than one platform.
At their core, both functions essentially accomplish the same task; however, the functions have some subtle differences, and being aware of them may assist in debugging efforts.
On the surface, ISNULL is simply a version of COALESCE that is limited to two parameters; however, ISNULL is a function that is built into the SQL Server engine and evaluated at query-processing time, and COALESCE is expanded into a CASE expression during query compilation.
One difference between the two functions is the data type returned by the function when the parameters are different data types. Take the following example:
DECLARE @sql NVARCHAR(MAX) = '
SELECT ISNULL(''5'', 5),
ISNULL(5, ''5''),
COALESCE(''5'', 5),
COALESCE(5, ''5'') ;
' ;
EXEC sp_executesql @sql ;
SELECT column_ordinal,
is_nullable,
system_type_name
FROM master.sys.dm_exec_describe_first_result_set(@sql, NULL, 0) a ;
![]() Note This example introduces some concepts that have not yet been discussed in this book. In the example, we would like to execute a query but also retrieve metadata about the query. The procedure sp_executesql accepts an NVARCHAR parameter and executes that string as a T-SQL batch. This is a useful tactic when building and executing dynamic queries in your applications. For further information on sp_executesql, please refer to the SQL Server Books Online at http://msdn.microsoft.com/en-us/library/ms188001.aspx.
Note This example introduces some concepts that have not yet been discussed in this book. In the example, we would like to execute a query but also retrieve metadata about the query. The procedure sp_executesql accepts an NVARCHAR parameter and executes that string as a T-SQL batch. This is a useful tactic when building and executing dynamic queries in your applications. For further information on sp_executesql, please refer to the SQL Server Books Online at http://msdn.microsoft.com/en-us/library/ms188001.aspx.
To describe the results of the query, we use the table-valued function dm_exec_describe_first_result_set. Table-valued functions are described in Chapter 18, and this function in particular is documented in SQL Server Books Online at http://msdn.microsoft.com/en-us/library/ff878236.aspx.
The following is the result of this set of statements:
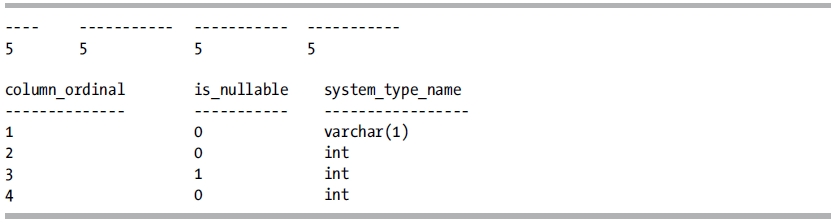
Note that the type returned from ISNULL changes depending on the order of the input parameters, while COALESCE returns the data type of highest precedence regardless of argument order. So long as an implicit conversion exists between the value selected by the ISNULL or COALESCE function and the return type selected, the function will implicitly cast the return value to the return type. However, be aware that if an implicit conversion does not exist between the return type and value to be returned, SQL Server will raise an error.
![]() Note For a complete list of data types in SQL Server listed in order of precedence, refer to SQL Server Books Online at http://msdn.microsoft.com/en-us/library/ms190309(v=sql.110).aspx.
Note For a complete list of data types in SQL Server listed in order of precedence, refer to SQL Server Books Online at http://msdn.microsoft.com/en-us/library/ms190309(v=sql.110).aspx.
SELECT COALESCE(‘five’, 5) ;
This returns the following:
Msg 245, Level 16, State 1, Line 1
Conversion failed when converting the varchar value 'five’ to data type int.
DECLARE @i INT = NULL ;
SELECT ISNULL(@i, 'five') ;
This returns the following:
Msg 245, Level 16, State 1, Line 2
Conversion failed when converting the varchar value 'five' to data type int.
The nullability of the return value may be different as well. Take the case where an application requests LastName, FirstName, and MiddleName from a table. The application expects the NULL values in the MiddleName columns to be replaced with an empty string. The following SELECT statement uses both ISNULL and COALESCE to convert the values, so the differences can be observed by describing the result set.
DECLARE @sql NVARCHAR(MAX) = '
SELECT TOP 10
FirstName,
LastName,
MiddleName_ISNULL = ISNULL(MiddleName, ''''),
MiddleName_COALESCE = COALESCE(MiddleName, '''')
FROM Person.Person ;
' ;
EXEC sp_executesql @sql ;
SELECT column_ordinal,
name,
is_nullable
FROM master.sys.dm_exec_describe_first_result_set(@sql, NULL, 0) a ;
The preceding statements return the two result sets:
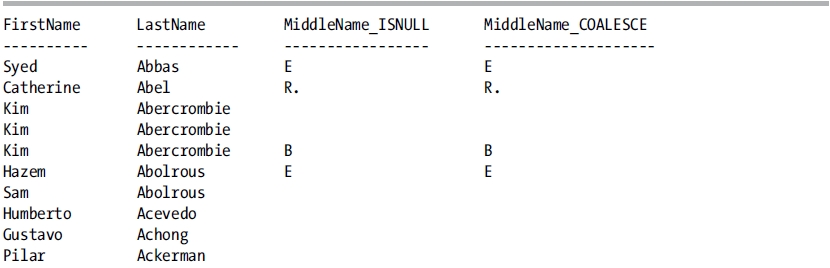

The nullability of ISNULL will always be false if at least one of the inputs is not nullable. COALESCE’s nullability will be false only if all inputs are not nullable.
![]() Tip This is a fairly subtle difference and may or may not affect you. Where I have seen these differences creep up is in application code where you may have a data access library or object relational mapping layer that makes data type decisions based on the nullability of columns in your result set.
Tip This is a fairly subtle difference and may or may not affect you. Where I have seen these differences creep up is in application code where you may have a data access library or object relational mapping layer that makes data type decisions based on the nullability of columns in your result set.
How It Works
It is important to understand the nuances of the function you are using and how the data returned from ISNULL and COALESCE will be used. To eliminate the confusion that may occur with implicit type conversions, type precedence rules, and nullability rules, it is good practice to explicitly cast all inputs to the same type prior to input to ISNULL or COALESCE.
![]() Note There are a number of discussions regarding the performance of ISNULL vs. COALESCE. For most uses of these functions, the performance differences are negligible. There are some cases when using correlated subqueries where ISNULL and COALESCE will cause the query optimizer to generate different query plans with COALESCE generating a suboptimal plan compared to ISNULL.
Note There are a number of discussions regarding the performance of ISNULL vs. COALESCE. For most uses of these functions, the performance differences are negligible. There are some cases when using correlated subqueries where ISNULL and COALESCE will cause the query optimizer to generate different query plans with COALESCE generating a suboptimal plan compared to ISNULL.
3-4. Looking for NULLs in a Table
Problem
You have a table with a nullable column. You would like to return rows where that column is NULLor where the column is not NULL.
Solution
The first hurdle to overcome when working with NULLs is to remove this WHERE clause from your mind: WHERE SomeColumn = NULL. The second hurdle is to remove this clause: WHERE SomeCol <> NULL. NULL is an “unknown” value. Because the value is unknown, SQL Server cannot evaluate any operator where an input to the operator is unknown.
- What is NULL + 1? NULL?
- What is NULL * 5? NULL?
- Does NULL = 1? NULL?
- Is NULL <> 1? NULL?
To search for NULL values, use the unary operators IS NULL and IS NOT NULL. Specifically, IS NULL returns true if the operand is NULL, and IS NOT NULL returns true if the operand is defined. Take the following statement:
DECLARE @value INT = NULL;
SELECT CASE WHEN @value = NULL THEN 1
WHEN @value <> NULL THEN 2
WHEN @value IS NULL THEN 3
ELSE 4
END ;
This simple CASE statement demonstrates that the NULL value stored in the variable @value cannot be evaluated with traditional equality operators. The IS NULL operator evaluates to true, and the result of the statement is the following:
3
So, how does this apply to searching for NULL values in a table? Say an application requests all rows in the Person table with an NULL MiddleName.
SELECT TOP 5
LastName, FirstName, MiddleName
FROM Person.Person
WHERE MiddleName IS NULL ;
The result of this statement is as follows:
LastName FirstName MiddleName
----------- --------- -----------
Abercrombie Kim NULL
Abercrombie Kim NULL
Abolrous Sam NULL
Acevedo Humberto NULL
Achong Gustavo NULL
How It Works
The IS NULL operator evaluates one operand and returns true if the value is unknown. The IS NOT NULL operator evaluates on operand and returns true if the value is defined.
Previous recipes in this chapter introduced the ISNULL and COALESCE functions. The ISNULL function is often confused with the IS NULL operator. After all, the names differ by only one space. Functionally, the ISNULL operator may be used in a WHERE clause; however, there are some differences in how the SQL Server query plan optimizer decides how to execute statements with IS NULL vs. ISNULL used as a predicate in a SELECT statement.
Look at the following three statements that query the JobCandidate table and return the JobCandidate rows that have a non-NULLBusinessEntityID. All three statements return the same rows, but there is a difference in the execution plan.
The first statement uses ISNULL to return 1 for NULL values and returns all rows where ISNULL does not return 1.
SET SHOWPLAN_TEXT ON ;
GO
SELECT JobCandidateID,
BusinessEntityID
FROM HumanResources.JobCandidate
WHERE ISNULL(BusinessEntityID, 1) <> 1 ;
GO
SET SHOWPLAN_TEXT OFF ;
|--Index Scan(OBJECT:([AdventureWorks2008R2].[HumanResources].[JobCandidate].
[IX_JobCandidate_BusinessEntityID]),
WHERE:(isnull([AdventureWorks2008R2].[HumanResources].[JobCandidate].
[BusinessEntityID],(1))<>(1)))
The execution plan contains an index scan. In this case, SQL Server will look at every row in the index to satisfy the results. Maybe the reason for this is the inequality operator (<>). The query may be rewritten as follows:
SET SHOWPLAN_TEXT ON ;
GO
SELECT JobCandidateID,
BusinessEntityID
FROM HumanResources.JobCandidate
WHERE ISNULL(BusinessEntityID, 1) = BusinessEntityID ;
GO
SET SHOWPLAN_TEXT OFF ;
|--Index Scan(OBJECT:([AdventureWorks2008R2].[HumanResources].[JobCandidate].
[IX_JobCandidate_BusinessEntityID]),
WHERE:(isnull([AdventureWorks2008R2].[HumanResources].[JobCandidate].[BusinessEntityID],(1))=
[AdventureWorks2008R2].[HumanResources].[JobCandidate].[BusinessEntityID]))
Again, the query optimizer chooses to use an index scan to satisfy the query. What happens when the IS NULL operator is used instead of the ISNULL function?
SET SHOWPLAN_TEXT ON ;
GO
SELECT JobCandidateID,
BusinessEntityID
FROM HumanResources.JobCandidate
WHERE BusinessEntityID IS NOT NULL ;
GO
SET SHOWPLAN_TEXT OFF ;
|--Index Seek(OBJECT:([AdventureWorks2008R2].[HumanResources].[JobCandidate].
[IX_JobCandidate_BusinessEntityID]), SEEK:([AdventureWorks2008R2].[HumanResources].
[JobCandidate].[BusinessEntityID] IsNotNull) ORDERED FORWARD)
By using the IS NULL operator, SQL Server is able to seek on the index instead of scan the index. ISNULL() is a function, when a column is passed into a function SQL Server must evaluate that function for every row and is not able to seek on an index to satisfy the WHERE clause.
3-5. Removing Values from an Aggregate
Problem
You are attempting to understand production delays and have decided to report on the average variance between ActualStartDate and ScheduledStartDate of operations in your production sequence. You would like to understand the following:
- What is the variance for all operations?
- What is the variance for all operations where the variance is not 0?
Solution
NULLIF returns a NULL value when the two provided expressions have the same value; otherwise, the first expression is returned.
SELECT r.ProductID,
r.OperationSequence,
StartDateVariance = AVG(DATEDIFF(day, ScheduledStartDate,
ActualStartDate)),
StartDateVariance_Adjusted = AVG(NULLIF(DATEDIFF(day,
ScheduledStartDate,
ActualStartDate), 0))
FROM Production.WorkOrderRouting r
GROUP BY r.ProductID,
r.OperationSequence
ORDER BY r.ProductID,
r.OperationSequence ;
The query returns the following results (abridged):
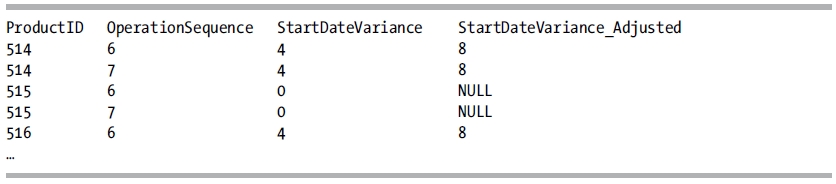
How It Works
The query includes two columns that use the aggregate function AVG to return the average difference in days between the scheduled and actual start dates of a production sequence for a given product. The column StateDateVariance includes all of the rows in the aggregate. The column StartDateVariance_Adjusted eliminates rows where the variance is 0 by using the NULLIF function. The NULLIF function accepts the result of DATEDIFF as the first parameter and compares this result to the value 0 that we passed to the second parameter. If DATEDIFF returns 0,NULLIF returnsNULL, and theNULL value is eliminated from theAVG aggregate.
3-6. Enforcing Uniqueness with NULL Values
Problem
You have a table that contains a column that allows NULLs. There may be many rows with NULL values, but any non-NULL value must be unique.
Solution
For this recipe, create a table Product where CodeName may be NULL.
CREATE TABLE Product
(
ProductId INT NOT NULL
CONSTRAINT PK_Product PRIMARY KEY CLUSTERED,
ProductName NVARCHAR(50) NOT NULL,
CodeName NVARCHAR(50)
) ;
GO
Create a unique nonclustered index on CodeName.
CREATE UNIQUE INDEX UX_Product_CodeName ON Product (CodeName) ;
GO
Test the unique index by adding some rows to the table.
INSERT INTO Product
(ProductId, ProductName, CodeName)
VALUES (1, 'Product 1', 'Shiloh') ;
INSERT INTO Product
(ProductId, ProductName, CodeName)
VALUES (2, 'Product 2', 'Sphynx'),
INSERT INTO Product
(ProductId, ProductName, CodeName)
VALUES (3, 'Product 3', NULL);
INSERT INTO Product
(ProductId, ProductName, CodeName)
VALUES (4, 'Product 4', NULL);
GO
Here is the result of the insert statements:
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
Msg 2601, Level 14, State 1, Line 13
Cannot insert duplicate key row in object 'dbo.Product' with unique index 'UX_Product_CodeName'. The duplicate key value is (<NULL>).
The statement has been terminated.
A unique index may be built on a nullable column; however, the unique index can contain only one NULL. SQL Server allows filtered indexes where the index is created only for a subset of the data in the table. Drop the unique index created earlier and create a new unique, nonclustered, filtered index on CodeName to index (and enforce uniqueness) only on rows that have a defined CodeName.
DROP INDEX Product.UX_Product_CodeName;
GO
CREATE UNIQUE INDEX UX_Product_CodeName ON Product (CodeName) WHERE CodeName IS NOT NULL
GO
Test the new index by adding some rows.
INSERT INTO Product
(ProductId, ProductName, CodeName)
VALUES (4, 'Product 4', NULL);
INSERT INTO Product
(ProductId, ProductName, CodeName)
VALUES (5, 'Product 5', NULL);
The results show two rows added successfully:
(1 row(s) affected)
(1 row(s) affected)
If a row is added that violates the unique constraint on the CodeName, a constraint violation will be raised:
INSERT INTO Product
(ProductId, ProductName, CodeName)
VALUES (6, 'Product 6', 'Shiloh'),
Here are the results:
Msg 2601, Level 14, State 1, Line 1
Cannot insert duplicate key row in object 'dbo.Product' with unique index 'UX_Product_CodeName'. The duplicate key value is (Shiloh).
The statement has been terminated.
A select from the table will show that multiple nulls have been added to the CodeName table; however, uniqueness has been maintained on defined CodeName values.
SELECT *
FROM Product
The SELECT statement yields the following:
ProductId ProductName CodeName
--------- ----------- --------
1 Product 1 Shiloh
2 Product 2 Sphynx
3 Product 3 NULL
4 Product 4 NULL
5 Product 5 NULL
How It Works
Unique constraints and unique indexes will, by default, enforce uniqueness the same way with respect to NULL values. Indexes allow for the use of index filtering, and the filter will be created only on the rows that meet the filter criteria. There are many benefits to filtered indexes, as discussed in Chapter 17.
3-7. Enforcing Referential Integrity on Nullable Columns
Problem
You have a table with a foreign key defined to enforce referential integrity. You want to enforce the foreign key where values are defined but allow NULLvalues into the foreign key column.
Solution
The default behavior of a foreign key constraint is to enforce referential integrity on non-NULL values but allow NULL values even though there may not be a corresponding NULL value in the primary key table. This example uses a Category table and an Item table. The Item table includes a nullable CategoryId column that references the CategoryId of the Category table.
First, create the Category table and add some values.
CREATE TABLE Category
(
CategoryId INT NOT NULL
CONSTRAINT PK_Category PRIMARY KEY CLUSTERED,
CategoryName NVARCHAR(50) NOT NULL
) ;
GO
INSERT INTO Category
(CategoryId, CategoryName)
VALUES (1, 'Category 1'),
(2, 'Category 2'),
(3, 'Category 3') ;
GO
Next, create the Item table and add the foreign key to the Category table.
CREATE TABLE Item
(
ItemId INT NOT NULL
CONSTRAINT PK_Item PRIMARY KEY CLUSTERED,
ItemName NVARCHAR(50) NOT NULL,
CategoryId INT NULL
) ;
GO
ALTER TABLE Item ADD CONSTRAINT FK_Item_Category FOREIGN KEY (CategoryId) REFERENCES Category(CategoryId) ;
GO
Attempt to insert three rows into the Item table. The first row contains a valid reference to the Category table. The second row will fail with a foreign key violation. The third row will insert successfully because the CategoryId is NULL.
INSERT INTO Item
(ItemId, ItemName, CategoryId)
VALUES (1, 'Item 1', 1) ;
INSERT INTO Item
(ItemId, ItemName, CategoryId)
VALUES (2, 'Item 2', 4) ;
INSERT INTO Item
(ItemId, ItemName, CategoryId)
VALUES (3, 'Item 3', NULL) ;
The insert statements generate the following results:
(1 row(s) affected)
Msg 547, Level 16, State 0, Line 5
The INSERT statement conflicted with the FOREIGN KEY constraint “FK_Item_Category”. The conflict occurred in database “AdventureWorks2012”, table “dbo.Category”, column 'CategoryId'.
The statement has been terminated.
(1 row(s) affected)
How It Works
If a table contains a foreign key reference on a nullable column, NULLvalues are allowed in the foreign key table. To enforce the referential integrity on all rows, the foreign key column must be declared as non-nullable. Foreign keys are discussed in detail in Chapter 15.
3-8. Joining Tables on Nullable Columns
Problem
You need to join two tables but have NULLvalues in one or both sides of the join.
Solution
When joining on a nullable column, remember that the equality operator returns false for NULL = NULL. Let’s see what happens when you have NULL values on both sides of a join. Create two tables with sample data.
CREATE TABLE Test1
(
TestValue NVARCHAR(10) NULL
);
CREATE TABLE Test2
(
TestValue NVARCHAR(10) NULL
) ;
GO
INSERT INTO Test1
VALUES ('apples'),
('oranges'),
(NULL),
(NULL) ;
INSERT INTO Test2
VALUES (NULL),
('oranges'),
('grapes'),
(NULL) ;
GO
If an inner join is attempted on these tables, like so:
SELECT t1.TestValue,
t2.TestValue
FROM Test1 t1
INNER JOIN Test2 t2
ON t1.TestValue = t2.TestValue ;
the query returns the following:
TestValue TestValue
--------- ---------
oranges oranges
How It Works
Predicates in the join condition evaluate NULLs the same way as predicates in the WHERE clause. When SQL Server evaluates the condition t1.TestValue = t2.TestValue, the equals operator returns false if one or both of the operands is NULL; therefore, the only rows that will be returned from an INNER JOIN are rows where neither side of the join is NULL and those non-NULL values are equal.