
![]()
Backup
In this chapter, you’ll find recipes covering several methods of backing up a database using T-SQL. This chapter is in no way meant to be a comprehensive source for database backups but rather provides greater insight into the problems or limitations you may encounter. This chapter will outline the different types of backup methods using T-SQL as well as how to query the msdb database to find information about backup information.
Problem
You want to do a full backup of the AdventureWorks2012 database to your C:Apress folder using T-SQL.
Solution
Execute a BACKUP DATABASE statement. Specify TO DISK, and provide the path and desired file name. There are several options that can be used with the BACKUP DATABASE statement that will be covered in the following recipes.
The following example demonstrates using the BACKUP DATABASE statement, specifying the file location where the backup will be stored:
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressAdventureworks2012.bak';
GO
Processed 25568 pages for database 'AdventureWorks2012', file 'AdventureWorks2012_Data' on file 1.
Processed 2 pages for database 'AdventureWorks2012', file 'AdventureWorks2012_Log' on file 1.
BACKUP DATABASE successfully processed 25570 pages in 8.186 seconds (24.403 MB/sec).
![]() Tip Make sure that the Apress folder exists on the C: drive or change the path in the previous query.
Tip Make sure that the Apress folder exists on the C: drive or change the path in the previous query.
This command will make a full backup of all data and log files of the AdventureWorks2012 database, including the FILESTREAM file.
How It Works
The BACKUP DATABASE command, absent all options, will make a full backup of all data and log files of the specified database to the path or device declared in the statement. The process involves copying the data files as well as the active portion of any log files.
This process is rather straightforward, but the resulting backup can be a bit confusing. Consider a database that has a single 50GB data file and a 10MB log file. The resultant backup should be just more than 50GB, but this is not always the case.
During the backup process, SQL Server does not back up empty data pages, meaning that the backup will contain only partially or fully used data pages within the data files. Comparing the backups may lead some to believe that proprietary compression is involved in the backup process, but really only “used” space is copied to the backup media.
I hate to jump ahead, but I need to answer the most common question that arises when describing the backup process: “When I restore the database, will it be the exact size of the backup?” The data files sizes are contained in the backup media, and that file size is what is used to reserve the space to write the data pages to. In this example, this would mean that another 50GB data file would be created in the restored path, and the data pages would then be written to the data file.
26-2. Compressing a Backup
Problem
As a database grows, disk space can be a fleeting commodity, and the space needed to store a full backup can be prohibitive. So you want to compress your backup files to free up disk space.
Solution
Backing up the database using the WITH COMPRESSION clause will compress the associated backup. The following example demonstrates creating a full backup of the AdventureWorks2012 database using compression:
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressAdventureWorks2012compress.bak'
WITH COMPRESSION;
GO
Processed 25568 pages for database 'AdventureWorks2012', file 'AdventureWorks2012_Data' on file 1.
Processed 2 pages for database 'AdventureWorks2012', file 'AdventureWorks2012_Log' on file 1.
BACKUP DATABASE successfully processed 25570 pages in 5.145 seconds (38.825 MB/sec).
How It Works
The solution command will create a full backup to the C:Apress folder with the file name AdventureWorks2012.bak that utilizes compression to reduce the size of the backup file. There are several notable benefits of using compression in your backup sets, the first being reducing the space that is being taken by backups. Another notable advantage of backup compression is reduced disk I/O. This seems only reasonable: because there is less to write to disk, there is noticeable reduced disk I/O.
The specific compression ratio is dependent on the data that is compressed, which is based on several factors including the following:
- The type of data
- The consistency of the data among rows on a page
- Whether the data is encrypted
- Whether the database is compressed
This makes it difficult to ascertain the specific compression ratio and the resulting backup size without first comparing a compressed file to an uncompressed backup file. Since the exact compressed size is mostly unknown until completion, the database engine uses a preallocation algorithm to reserve space for the backup file. The algorithm reserves a predefined percentage of the size of the database for the backup. During the backup process, if more space is required, then the database engine will grow the file as needed. Upon completing the backup, the database engine will shrink the file size of the backup as needed.
The following script illustrates the noticeable difference, as a ratio, between a compressed and uncompressed backup file of the AdventureWorks2012 database.
--Compressed Full Backup
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressAdventureWorks2012.bak'
WITH COMPRESSION;
GO
--Uncompressed Full Backup
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressUnAdventureWorks2012.bak';
GO
--Retrieve the compression ratio
SELECT TOP 2 backup_size,compressed_backup_size,
backup_size/compressed_backup_size AS ratio
FROM msdb..backupset
ORDER BY backup_start_date DESC;
GO
Results may vary:
---------- ------------
209797120 209797120 1.000000000000000000
209797120 52287373 4.012385934936911058
This shows that the compressed backup had a compression ratio of just over 4 to 1, while the uncompressed was obviously 1 to 1. This in turn means the compressed backup was just less than 24 percent of the size of the uncompressed. This substantially reduced file size can also be evaluated by comparing the physical file size within Windows Explorer, as shown in Figure 26-1.

Figure 26-1 . Comparison of compressed and uncompressed backup
So as not to paint a one-sided picture, it is important to note that there are some considerations regarding backup compression. One of the most limiting constraints for utilizing backup compression is that it is an Enterprise and Developer edition feature. This means that any edition less than Enterprise is stuck with uncompressed backups.
After discussing the performance benefits in both backup size and disk I/O, I may have convinced you to begin changing all your maintenance plans and scripts to utilize WITH COMPRESSION, but all good things come with a cost. The reduced file size and disk I/O are replaced with increased CPU usage during the backup process, which can prove to be significant. The increase in CPU can be mitigated by using Resource Governor, another Enterprise edition feature, but it does need to be weighed against server resources and priorities.
Compressed backups also cannot coexist with uncompressed backups on the same media set, which means that full, differential, and transaction log compressed backups must be stored in separate media sets than ones that are uncompressed.
26-3. Ensuring That a Backup Can Be Restored
Problem
Backing up a database is straightforward, but you want to make sure that the backup is not corrupt and can be successfully restored.
Solution
There are several ways to ensure that a backup can be successfully restored, the first of which is to utilize the WITH CHECKSUM option in the backup command.
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressAdventureWorks2012check.bak'
WITH CHECKSUM
This can be partnered with the command RESTORE VERIFYONLY to ensure not only that a backup is not corrupted but that it can be restored.
RESTORE VERIFYONLY
FROM DISK = 'C:ApressAdventureWorks2012.bak'
WITH CHECKSUM;
Results may vary:
Processed 25568 pages for database 'AdventureWorks2012', file 'AdventureWorks2012_Data' on file 2.
Processed 2 pages for database 'AdventureWorks2012', file 'AdventureWorks2012_Log' on file 2.
BACKUP DATABASE successfully processed 25570 pages in 13.932 seconds (14.338 MB/sec).The backup set on file 1 is valid.
How It Works
Using the WITH CHECKSUM option in a backup will verify each page checksum, if it is present on the page. Regardless of whether page checksums are available, the backup will generate a separate checksum for the backup streams. The backup checksums are stored in the backup media and not the database pages, which means they can be used in restore operations to validate that the backup is not corrupt.
Using the WITH CHECKSUM option in a backup command allows you to control the behavior of what will happen if an error occurs. The default behavior if a page checksum does not verify that the backup will stop reporting an error. This can be changed by adding CONTINUE_AFTER_ERROR.
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressAdventureWorks2012.bak'
WITH CHECKSUM, CONTINUE_AFTER_ERROR
Using WITH CHECKSUM to ensure a backup’s integrity is a good start, but it does not validate the ability to restore the backup. The RESTORE VERIFYONLY command, when used in tandem WITH CHECKSUM, will validate the backup checksum values, that the backup set is complete, some header fields of the database pages, and that there is sufficient space in the restore path.
Using WITH CHECKSUM alongside RESTORE VERIFYONLY helps validate a backup’s integrity, but it is not fool-proof. Database backups are stored in a format called Microsoft Tape Format (MTF), which includes MTF blocks that contain the backup metadata while the backed-up data is stored outside of the MTF blocks. RESTORE VERIFYONLY performs simple checks on the MTF blocks and not the actual data blocks, which means the blocks could be consistent while the backup files could be corrupted. In such a case, RESTORE VERIFYONLY would show that the backup set could be restored, but issuing a restore would result in failure.
The moral of this solution is that you can try to ensure backup integrity, but the only sure way to test backup integrity is to restore backups and run DBCC CHECKDB on the restored database.
26-4. Understanding Why the Transaction Log Continues to Grow
Problem
A database transaction log has grown larger than the data files and continues to grow larger by the day. You want to know why.
Solution
The solution to this is easy enough for databases that are set to the full or bulk logged recovery model. Back up the transaction log!
BACKUP LOG AdventureWorks2012
TO DISK = 'C:ApressAdventureWorks2012.trn';
How It Works
As a moderator on MSDN forums, I see this issue posted at least once a week, and the solution exemplifies the saying “An ounce of prevention is better than a pound of the cure.” Databases that are set to a bulk logged or full recovery model have the possibility of being restored to a point in time because the transaction log can be backed up. A database that is set to the simple recovery model can never be restored to a point in time because the transaction log is truncated upon a checkpoint.
So you fully understand this concept, I’ll cover each of the recovery models beginning with the simple model. Because transactions occur in a database, SQL Server will first check to see whether the affected data pages are in memory, and if they’re not, then the page(s) will be read into memory. Subsequent requests for affected pages are presented from memory because these reflect the most up-to-date information. All transactions are then written to the transaction log. Occasionally, based upon the recovery interval, SQL will run a checkpoint in which all “dirty” pages and log file information will be written to the data file.
Databases that use the simple recovery model will then truncate the inactive portion of the log, thereby preventing the ability to back up the transaction log but reducing and possibly eliminating the pesky problem of runaway log file size.
The following script creates a database, Logging, that uses the simple recovery model and creates a single table, FillErUp:
--Create the Logging database
CREATE DATABASE Logging;
GO
ALTER DATABASE Logging
SET RECOVERY SIMPLE;
GO
USE Logging;
CREATE TABLE FillErUp(
RowInfo CHAR(150)
);
GO
Monitoring the log file size and the reason why a log file is waiting to reclaim space can be done through the sys.database_files and sys.databases catalog views. The following queries show the initial log and data file sizes as well as the log_reuse_wait_desc description; keep in mind that the size column represents the size in 8KB data pages.
SELECT type_desc,
size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name,
log_reuse_wait_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
Execute this query, and the results should be similar to the following:
type_desc size
--------- ----
LOG 98
name, log_reuse_ wait_desc
------- --------------------
Logging NOTHING
The log_reuse_wait_desc option is of particular importance in this solution because it provides the reason that the log file is not being truncated. Since the database has just been created and no transactions have been posted to it, there is nothing preventing the log from being truncated.
The following query uses a loop to post 100,000 rows to the FillErUp table and again queries the log file size and the log_reuse_wait_desc:
DECLARE @count INT = 10000
WHILE @count > 0
BEGIN
INSERT FillErUp
SELECT 'This is row # ' + CONVERT(CHAR(4), @count)
SET @count - = 1
END;
GO
CHECKPOINT;
GO
SELECT type_desc AS filetype,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name AS name,
log_reuse_wait_desc AS reuse_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
The results of the query show that the log file size is the same and that the log_reuse_wait_desc description is still nothing.
filetype size
------- ----
LOG 98
name log_reuse_ wait_desc
------ --------------------
Logging NOTHING
Since the database recovery model is set to simple recovery, the log file can be truncated after a checkpoint is issued so the log file size remains the same size. Keep in mind that just because a database is set to the simple recovery model does not mean that the log file will not grow. Upon issuing a checkpoint, the nonactive portion of the log will be truncated, but the active portion cannot be truncated. The following example uses a BEGIN TRAN to display the effects of a long-running transaction and log file growth and also uses DBCC SQLPERF to display some statistics on the log file after the transaction runs:
BEGIN TRAN
DECLARE @count INT = 10000
WHILE @count > 0
BEGIN
INSERT FillErUp
SELECT 'This is row # ' + CONVERT(CHAR(4), @count)
SET @count - = 1
END;
GO
SELECT type_desc AS filetype,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name AS name,
log_reuse_wait_desc AS reuse_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
DBCC SQLPERF(LOGSPACE);
GO
The results of the query show that the log file has grown, and it cannot be truncated because of an open transaction. A portion of the DBCC SQLPERF results are included to show the size and percent of used log space.
filetype size
--------- ---- LOG 728
name log_reuse_ wait_desc ------ --------------------
Logging ACTIVE TRANSACTION
Database Name Log Size (MB) Log Space Used (%)
------------- ------------- ------------------
Logging 5.679688 98.62448
The results show that the log file size has grown and that the log space is more than 98 percent used. Issuing a COMMIT TRAN and a manual CHEKPOINT will close the transaction, but you will also notice that the log file remains the same size.
COMMIT TRAN;
GO
CHECKPOINT;
GO
SELECT type_desc AS filetype,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name AS name,
log_reuse_wait_desc AS reuse_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
DBCC SQLPERF(LOGSPACE);
GO
filetype size
------- ---- LOG 728
name log_reuse_ wait_desc ------- --------------------
Logging NOTHING
Database Name Log Size (MB) Log Space Used (%)
------------- ------------- ------------------
Logging 5.679688 16.72971
It is obvious from the query results that the transaction has been closed, but the log file size is the same size when the transaction remained unopened. The difference between the results is the percentage of log space that is used. The log space used before the commit and checkpoint is more than 98 percent, while afterward, the used space falls to just more than 16 percent.
![]() Tip There are ways in which to regain disk space from bloated log files, but the focus of this solution is to highlight maintenance. Any steps taken to shrink the log file is always user beware.
Tip There are ways in which to regain disk space from bloated log files, but the focus of this solution is to highlight maintenance. Any steps taken to shrink the log file is always user beware.
Because log size can become complex while a database is set to the simple recovery model, full and bulk logged add many more considerations that must be taken into account. Unlike the simple recovery model, both the full and bulk logged recovery models require transaction log backups to be taken before a transaction log will be truncated.
To demonstrate, the following query will drop and re-create the Logging database and, again, use a loop to create a number of transactions. The log file size and log reuse wait description are queried immediately after the creation of the database.
USE master;
GO
--Create the Logging database
IF EXISTS (SELECT * FROM sys.databases WHERE name = 'Logging')
BEGIN
DROP DATABASE Logging;
CREATE DATABASE Logging;
END
GO
ALTER DATABASE Logging
SET RECOVERY FULL;
GO
USE Logging;
CREATE TABLE FillErUp(
RowInfo CHAR(150)
);
GO
--Size is 98
SELECT type_desc,
size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name,
log_reuse_wait_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
DECLARE @count INT = 10000
WHILE @count > 0
BEGIN
INSERT FillErUp
SELECT 'This is row # ' + CONVERT(CHAR(4), @count)
SET @count - = 1
END;
GO
CHECKPOINT;
GO
SELECT type_desc,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name AS name,
log_reuse_wait_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
type_desc size
--------- ------- LOG 98
name log_reuse_ wait_desc ------- --------------------
Logging NOTHING
type_desc size
--------- -------
LOG 98
name log_reuse_ wait_desc
------- --------------------
Logging NOTHING
The results are obviously not what were expected, but this is for good reason. The database was created and then altered to the full recovery model. After a number of transactions, the log file remains the same size. Based on the definition of the full recovery model, the log should have grown. The log file will continue to be truncated upon a checkpoint until a full backup is taken. This is by design because the transaction log backup requires a full backup be taken first, and until a transaction log backup is taken, the log file will grow.
After taking a full backup of the database and again running the INSERT loop, the results are much different.
BACKUP DATABASE Logging
TO DISK = 'C:ApressLogging.bak';
GO
DECLARE @count INT = 10000
WHILE @count > 0
BEGIN
INSERT FillErUp
SELECT 'This is row # ' + CONVERT(CHAR(4), @count)
SET @count - = 1
END;
GO
CHECKPOINT;
GO
SELECT type_desc,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name,
log_reuse_wait_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
type_desc size
--------- -------
LOG 1432
name log_reuse_ wait_desc
------- --------------------
Logging LOG_BACKUP
The end result is that the log file continued to grow, and the log reuse wait description reflects that a transaction log backup is required. The size of the transaction log can be maintained by scheduled transaction log backups. The following script re-creates the Logging database and uses the INSERT loop to fill the log but includes a transaction log backup after each transaction to demonstrate the effect it has on log growth.
USE master;
GO
--Create the Logging database
IF EXISTS (SELECT * FROM sys.databases WHERE name = 'Logging')
BEGIN
DROP DATABASE Logging;
CREATE DATABASE Logging;
END
GO
ALTER DATABASE Logging
SET RECOVERY FULL;
GO
USE Logging;
CREATE TABLE FillErUp(
RowInfo CHAR(150)
);
GO
USE Logging;
GO
SELECT type_desc,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name,
log_reuse_wait_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
BACKUP DATABASE Logging
TO DISK = 'C:ApressLogging.bak';
GO
DECLARE @count INT = 100
WHILE @count > 0
BEGIN
INSERT FillErUp
SELECT 'This is row # ' + CONVERT(CHAR(4), @count)
BACKUP LOG Logging
TO DISK = 'C:ApressLogging.trn'
SET @count - = 1
END;
GO
SELECT type_desc AS filetype,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name,
log_reuse_wait_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
type_desc size
--------- ---- LOG 98
name log_reuse_ wait_desc ------- --------------------
Logging NOTHING
type_desc size
--------- ----
LOG 98
name log_reuse_ wait_desc
------- --------------------
Logging NOTHING
The results show that the size of the log file before and after the loop remains the same, as does the log reuse wait description. This example obviously does not simulate real-life situations in scope or scheduling but does demonstrate that transaction log backups provide a proactive means of maintaining manageable log size files for full or bulk logged recovery models.
A database using the bulk logged recovery model still uses the log file to record transactions, but bulk transactions are minimally logged, causing less growth in the log. Unlike the full recovery model, bulk logged recovery does not provide the ability to restore the database to a point in time and records only enough information to roll back the transaction.
Only specific operations are marked as bulk logged such as BULK INSERT, SELECT INTO, and BULK INSERT, to name a few. A common misconception is that the bulk logged recovery model will not cause the log file to grow, which is untrue.
The following code demonstrates that bulk operations do still cause the transaction log file to grow with a database in the bulk logged recovery model:
USE master;
GO
IF EXISTS (SELECT * FROM sys.databases WHERE name = 'Logging')
BEGIN
DROP DATABASE Logging;
CREATE DATABASE Logging;
END
GO
ALTER DATABASE Logging
SET RECOVERY BULK_LOGGED;
GO
USE Logging;
GO
CREATE TABLE Currency(
CurrencyCode CHAR(3) NOT NULL,
Name CHAR(500) NOT NULL,
ModifiedDate CHAR(500) NOT NULL);
GO
BACKUP DATABASE Logging
TO DISK = 'C:ApressLogging.bak';
GO
SELECT type_desc,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name,
log_reuse_wait_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
type_desc size
--------- ---- LOG 98
name log_reuse_ wait_desc ------- --------------------
Logging NOTHING
BULK INSERT Logging.dbo.Currency
FROM 'C:ApressCurrency.dat'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR =' '
);
GO
BULK INSERT Logging.dbo.Currency
FROM 'C:ApressCurrency.dat'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR =' '
);
GO
BULK INSERT Logging.dbo.Currency
FROM 'C:ApressCurrency.dat'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR =' '
);
GO
BULK INSERT Logging.dbo.Currency
FROM 'C:ApressCurrency.dat'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR =' '
);
GO
--26
BULK INSERT Logging.dbo.Currency
FROM 'C:ApressCurrency.dat'
WITH
(
FIELDTERMINATOR =',',
ROWTERMINATOR =' '
);
GO
SELECT type_desc,
size AS size
FROM sys.database_files
WHERE type_desc = 'LOG';
GO
SELECT name,
log_reuse_wait_desc
FROM sys.databases
WHERE database_id = DB_ID('Logging'),
GO
type_desc size
--------- ---- LOG 136
name log_reuse_ wait_desc ------- --------------------
Logging LOG_BACKUP
The results show that a database in bulk logged recovery mode will cause the log file to grow even when using bulk operations.
26-5. Performing a Differential Backup
Problem
To ensure that a recovery can be made as quickly as possible, you want a backup that will contain all the changes in a database since the last full backup.
Solution
A differential backup contains all the changes made since the last full backup. A backup/restore strategy can use as many differential backups as desired, and since a differential contains all the changes from the last full, this can speed up the restoration process.
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressAdventureWorks2012.dif'
WITH DIFFERENTIAL;
GO
How It Works
The differential backup statement is almost identical to a full backup statement, with the exception of the WITH DIFFERENTIAL. A differential backup will contain all changes in a database since the last full backup, which means that a full backup must already exist before a differential can be taken. Differential backups can speed the restoration process since, unlike log file backups, only the most recent differential backup needs to be restored.
Although a differential backup can speed up the restoration process, it is important to understand the mechanics of the backup. Consider a backup strategy that utilizes a full backup at 12 p.m. and a differential every two hours thereafter. The further away in time the differential backup gets from the full backup, the larger, based on activity, that backup would be. The 2 p.m. differential would contain all the changes from 12 p.m. to 2 p.m., the 4 p.m. differential would contain all the changes from 12 p.m. to 4 p.m., and so on.
Figure 26-2 illustrates the overlap of data that can be contained within a differential backup.
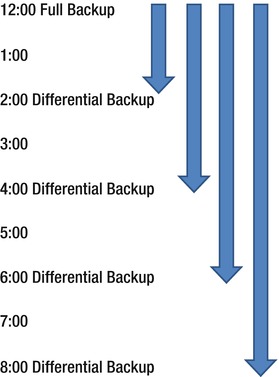
Figure 26-2 . Differential backup timeline
This figure shows that the space needed to maintain multiple differential backups may become prohibitive for a high OLTP database, and the resources needed to create the backup can result in degradation of performance as the differential backup grows.
26-6. Backing Up a Single Row or Table
Problem
Several incidents have required that only a specific row or table be restored and not the entire database.
Solution #1: Restore Rows from a Backup
Backup granularity within SQL Server starts with the database and then the filegroup and finally the file. Unless a table resides on its own filegroup, the backup statement does not natively support this functionality, but you can use several workarounds to meet this need.
To demonstrate how a full database backup can be used to restore a single row, I’ve created a database with a single table called Person using a SELECT INTO statement.
USE master;
GO
IF EXISTS (SELECT * FROM sys.databases WHERE name = 'Granular')
BEGIN
DROP DATABASE Granular;
END
CREATE DATABASE Granular;
GO
USE Granular;
GO
SELECT BusinessEntityID,
FirstName,
MiddleName,
LastName
INTO People
FROM AdventureWorks2012.Person.Person;
GO
SELECT TOP 6 *
FROM People
ORDER BY BusinessEntityID;
GO
Executing the previous query will create the Granular database and populate the People table with the result of the SELECT statement from the Person.Person table from AdventureWorks2012.
BusinessEntityID FirstName MiddleName LastName
---------------- --------- ---------- --------
1 Ken J Sánchez
2 Terri Lee Duffy
3 Roberto NULL Tamburello
4 Rob NULL Walters
5 Gail A Erickson
6 Jossef H Goldberg
Once the database is created and the table populated, a backup is created, and a single row is deleted in the following code:
BACKUP DATABASE Granular
TO DISK = 'C:ApressGranular.bak';
GO
DELETE People
WHERE BusinessEntityID = 1;
GO
SELECT TOP 6 *
FROM People
ORDER BY BusinessEntityID;
GO
Executing the previous query creates a full backup and deletes the person with a business entity ID of 1, as illustrated in these results:
BusinessEntityID FirstName MiddleName LastName
---------------- --------- ---------- --------
2 Terri Lee Duffy
3 Roberto NULL Tamburello
4 Rob NULL Walters
5 Gail A Erickson
6 Jossef H Goldberg
7 Dylan A Miller
To be able to restore the single deleted row, the backup must be restored with a different name, and the row can then be restored using an INSERT statement.
USE master;
GO
RESTORE DATABASE Granular_COPY
FROM DISK = 'C:ApressGranular.bak'
WITH MOVE N'Granular' TO 'C:Program FilesMicrosoft SQL ServerMSSQL11.MSSQLSERVER MSSQLSERVERDATAGranular_COPY.mdf',
MOVE N'Granular_log' TO N'C:Program FilesMicrosoft SQL ServerMSSQL11.MSSQLSERVER MSSQLDATAGranular_log_COPY.ldf';
GO
USE Granular;
GO
INSERT People
SELECT BusinessEntityID,
FirstName,
MiddleName,
LastName
FROM AdventureWorks2012.Person.Person
WHERE BusinessEntityID = 1;
GO
SELECT TOP 6 *
FROM People
ORDER BY BusinessEntityID;
GO
The results of the previous query show that the row was restored:
BusinessEntityID FirstName MiddleName LastName
---------------- --------- ---------- ----------
1 Ken J Sánchez
2 Terri Lee Duffy
3 Roberto NULL Tamburello
4 Rob NULL Walters
5 Gail A Erickson
6 Jossef H Goldberg
How It Works
The process behind this method is fairly self-evident. The database backup being restored with a different name provides the ability to use a SELECT statement from the restored table. Several issues may complicate this method, such as a column that is an IDENTITY, replication, or triggers on the affected table.
Another concern is the size of the database. If the database size is 1TB, space needs to be available to restore the database, and the data and log files should be placed on separate disks from the production database to reduce disk I/O during the restore.
Solution #2: Restore Rows from a Database Snapshot
Restoring an entire database to recover lost rows or tables can be overly burdensome and definitely can be considered overkill. Another method is to utilize a database snapshot as a means of backing up “state” data. A database snapshot is created on a user database from within an instance of SQL and works on a “write” on change. After creating a database snapshot, disk space is reserved for the snapshot that is equal to the reserved space of the data files of the user database. The disk space reserved for the snapshot remains completely empty until a data page from the user database is modified or deleted. Once this change occurs the original data page is written to the database snapshot preserving the data as it appeared at the point in time of the snapshot being taken.
The following code will create a database called Original and populate it with a SELECT INTO statement from the AdventureWorks2012 database and then create a database snapshot from the Original database called Original_SS.
USE master;
GO
IF EXISTS (SELECT * FROM sys.databases WHERE name =
'Original')
BEGIN
DROP DATABASE Original;
END
CREATE DATABASE Original;
GO
USE Original;
GO
SELECT BusinessEntityID,
FirstName,
MiddleName,
LastName
INTO People
FROM AdventureWorks2012.Person.Person;
GO
CREATE DATABASE Original_SS ON
( NAME = Original, FILENAME =
'C:Program FilesMicrosoft SQL ServerMSSQL11.MSSQLSERVERMSSQLDATA Original _SS.ss' )
AS SNAPSHOT OF Original;
GO
USE Original;
GO
SELECT name,
type_desc,
size
FROM sys.database_files;
GO
USE Original_SS;
GO
SELECT name,
type_desc,
size
FROM sys.database_files;
GO
The results of the previous query show that the Original and Original_SS databases were created and that the file sizes are identical.
name type_desc size
------------ --------- ----
Original ROWS 520
Original_log LOG 168
name type_desc size
------------ --------- ----
Original ROWS 520
Original_log LOG 168
Despite the results showing that the database snapshot has both a data file and a log file, there is in fact only a single file. Browsing the directory of the snapshot will show that a single file; the .ss extension represents the database snapshot, as illustrated in Figure 26-3.

Figure 26-3 . Database snapshot file compared to data file
Upon creating a database snapshot, the single snapshot file is completely empty and is used only as a placeholder. Data pages are added to the snapshot file as changes occur within the original database. This means that when directly querying the database snapshot, the requested 8KB data pages have not been modified since the snapshot was taken the data pages are being returned from the original database.
The following query is directly querying the Original_SS database, but because no changes have been made, the query is actually being returned from the Original database:
USE Original_SS;
GO
SELECT *
FROM People
WHERE LastName = 'Abercrombie';
GO
The results show the original values of people with the last name of Abercrombie.
BusinessEntityID FirstName MiddleName LastName
---------------- --------- ---------- -----------
295 Kim NULL Abercrombie
2170 Kim NULL Abercrombie
38 Kim B Abercrombie
Updating the last name from Abercrombie to Abercromby will cause the original data page to be written to the database snapshot, while the Original database writes the updated value. The following query updates all people with the last name Abercrombie and then queries both the Original and Original_SS databases to show the different values:
USE Original;
UPDATE People
SET LastName = 'Abercromny'
WHERE LastName = 'Abercrombie';
GO
SELECT *
FROM People
WHERE LastName = 'Abercrombie';
GO
USE Original_SS
GO
SELECT *
FROM People
WHERE LastName = 'Abercrombie';
GO;
(0 row(s) affected)
BusinessEntityID FirstName MiddleName LastName
---------------- --------- ---------- -----------
295 Kim NULL Abercrombie
2170 Kim NULL Abercrombie
38 Kim B Abercrombie
The results show that once the Original database was updated, the last name of Abercrombie was updated, and no results were returned. Querying the snapshot database, Original_SS, shows all affected records have been written to the snapshot.
The snapshot can be used to revert the records to their original state by using a nonequi join on the desired columns.
USE Original;
GO
UPDATE People
SET LastName = ss.LastName
FROM People p JOIN Original_SS.dbo.People ss
ON p.LastName <> ss.LastName
AND p.BusinessEntityID = ss.BusinessEntityID;
GO
SELECT *
FROM People
WHERE LastName = 'Abercrombie';
GO
(3 row(s) affected)
BusinessEntityID FirstName MiddleName LastName
---------------- --------- ---------- -----------
295 Kim NULL Abercrombie
2170 Kim NULL Abercrombie
38 Kim B Abercrombie
How It Works
The results show that for all records in the Original database’s People table where the BusinessEntityID matches the Original_SS database’s Peoples table, the BusinessEntityID and LastName column values do not match. The net result is that the changes made to the last name are reverted to the values that are stored in the database snapshot, restoring them to the values at the time of the snapshot.
Although this chapter focuses on backups, it is important to know that a database snapshot can be used to restore a database, which is referred to as reverting the database. Reverting a database is also typically much faster than doing a full restore because the only thing that needs to be done is to revert the data pages from the snapshot to the original data files. The following code shows how to revert the Original database from the Original_SS snapshot:
USE master;
RESTORE DATABASE Original
FROM DATABASE_SNAPSHOT = 'Original_SS';
GO
26-7. Backing Up Data Files or Filegroups
Problem
Your database size is so large that it is prohibitive to complete a full database backup on a daily basis.
Solution #1: Perform a File Backup
It can become burdensome to maintain an effective and efficient backup procedure in very large databases (VLDBs) because of the time it takes to perform a full backup and the amount of space required. Rather than a full backup, backups can be made of the data files individually. This can be demonstrated by creating a database with multiple files and filegroups.
CREATE DATABASE BackupFiles CONTAINMENT = NONE
ON PRIMARY
( NAME = N'BackupFiles', FILENAME = N'C:Program FilesMicrosoft SQL ServerMSSQL11.MSSQLSERVER MSSQLDATABackupFiles.mdf' , SIZE = 4096KB , FILEGROWTH = 1024KB ),
FILEGROUP [Current]
( NAME = N'CurrentData', FILENAME = 'C:Program FilesMicrosoft SQL ServerMSSQL11.MSSQLSERVERMSSQLDATACurrentData.ndf' , SIZE = 4096KB , FILEGROWTH = 1024KB ),
FILEGROUP [Historic]
( NAME = N'HistoricData', FILENAME = 'C:Program FilesMicrosoft SQL ServerMSSQL11.MSSQLSERVERMSSQLDATAHistoricData.ndf' , SIZE = 4096KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'BackupFiles_log', FILENAME = 'C:Program FilesMicrosoft SQL ServerMSSQL11.MSSQLSERVERMSSQLDATABackupFiles_log.ldf' , SIZE = 1024KB , FILEGROWTH = 10%);
GO
ALTER DATABASE [BackupFiles] SET RECOVERY FULL;
GO
To back up a single file from a database, simply use the BACKUP DATABASE command and specify the files to back up.
BACKUP DATABASE BackupFiles
FILE = 'HistoricData'
TO DISK = 'C:ApressHistoric.bak';
GO
Solution #2: Perform a Filegroup Backup
Sometimes a filegroup contains multiple files that need to be backed up in a single backup set. This is accomplished easily enough using the BACKUP DATABASE command and specifying the filegroup to be backed up.
BACKUP DATABASE BackupFiles
FILEGROUP = 'Historic'
TO DISK = 'C:ApressHistoricGroup.bak';
GO
How It Works
Backing up a file or filegroup works the same as a full database backup other than that it provides a more focused granular approach to the specific filegroup or file in the database. Either method can be employed to reduce the amount of time and space required for a full database backup.
It is critical to fully plan a database design if this backup/recovery method is going to be used to ensure that the entire database can be restored to a point in time and remain consistent. Consider placing one table on a file that references another table on a separate file. If either file had to be restored and referential integrity was violated because of the point in time of the restoration, this can cause a great deal of work to be able to restore the database to a consistent and valid state.
Always also remember that the primary file/filegroup must be backed up because it contains all of the system tables and database objects.
Problem
You want to ensure that multiple backups are written to different disks/tapes without affecting the backup media set or having to manually copy the backup files.
Solution
SQL Server 2005 Enterprise edition introduced the MIRROR TO clause, which will write the backup to multiple devices.
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressAdventureWorks2012.bak'
MIRROR TO DISK = 'C:MirroredBackupAdventureWorks2012.bak'
WITH
FORMAT,
MEDIANAME = 'AdventureWorksSet1';
GO
![]() Tip Make sure that the Apress and MirroredBackup folders exist on the C: drive or change the path in the previous query.
Tip Make sure that the Apress and MirroredBackup folders exist on the C: drive or change the path in the previous query.
How It Works
During the backup, using MIRROR TO will write the backup to multiple devices, which ensures that the backup file resides on separate tapes or disks in case one should become corrupt or unusable. There are several limitations to using the MIRROR TO clause, the first being that it requires the Developer or Enterprise edition. The mirrored devices must be the same type, meaning you cannot write one file to disk and the other to tape. The mirrored devices must be similar and have the same properties. Insufficiently similar devices will generate the error message 3212.
26-9. Backing Up a Database Without Affecting the Normal Sequence of Backups
Problem
An up-to-date backup needs to be created that will not affect the normal sequence of backups.
Solution
Using the BACKUP command and specifying WITH COPY_ONLY will create the desired backup but does not affect the backup or restore sequence.
BACKUP DATABASE AdventureWorks2012
TO DISK = 'C:ApressAdventureWorks2012COPY.bak'
WITH COPY_ONLY;
GO
How It Works
The only difference in the backup process when using WITH COPY_ONLY is that the backup will have no effect on the backup or restore procedure for a database.
Problem
You have to create a programmatic way to return backup information.
Solution
The msdb database maintains all of the backup history in the system tables. The system tables backupfile, backupfilegroup, backupmediafamily, backupmediaset, and backupset contain the full history of database backups as well as the media types and location. These tables can be queried to return information on any database backup that has occurred.
The following query will return the database name, the date and time the backup began, the type of backup that was taken, whether it used COPY_ONLY, the path and file name or device name, and the backup size ordering by the start date in descending order.
USE msdb;
GO
SELECT database_name,
CONVERT(DATE, backup_start_date) AS date,
CASE type
WHEN 'D' THEN 'Database'
WHEN 'I' THEN 'Differential database'
WHEN 'L' THEN 'Log'
WHEN 'F' THEN 'File or filegroup'
WHEN 'G' THEN 'Differential file'
WHEN 'P' THEN 'Partial'
WHEN 'Q' THEN 'Differential partial'
ELSE 'Unknown'
END AS type,
physical_device_name
FROM backupset s JOIN backupmediafamily f
ON s.media_set_id = f.media_set_id
ORDER BY backup_start_date DESC;
GO
Your results may vary
database_name date type physical_device_name
------------------ ---------- ---------------- ---------------------------------------
AdventureWorks2012 2012-06-01 Database C:BackupsAdventureWorks2012COPY.bak
AdventureWorks2012 2012-06-01 Database C:BackupsAdventureWorks2012.bak
AdventureWorks2012 2012-06-01 Database C:MirroredBackupAdventureWorks2012.bak
BackupFiles 2012-06-01 File or filegroup C:BackupsHistoricGroup.bak
BackupFiles 2012-06-01 File or filegroup C:BackupsHistoric.bak
Granular 2012-05-31 Database C:BackupsGranular.bak
The results show the most recent backups in descending order by the date the backup was taken.
How It Works
Whenever a backup is taken of a database, it is recorded in the msdb database. The system tables that record this information are made available to query. This information can be used for a number of different purposes including automating restoration of a database.