
![]()
It is the rare database that has all its data in a single table. Data tends to be spread over multiple tables in ways that optimize storage and ensure consistency and integrity. Part of your job when writing a query is to deploy and link together T-SQL operations that can operate across tables in order to generate needed business results.
Building blocks at your disposal include:
- Joins. Imagine holding two spreadsheets side by side. A join takes two rowsets and combines the rows from each to create a single rowset having the combined columns. Look towards a join when you want to correlate data from two tables into a single result set. For example, you can combine a list of paychecks with information about the employees being paid.
- Unions. Now imagine holding the two spreadsheets vertically, one atop the other. The result is a rowset having the same number of columns. A union allows you to combine two rowsets into one when rows from those two rowsets represent instances of the same thing. For example, you can combine a list of customer names with a list of employee names to generate a single list of person names.
- Subqueries. Think about looking at a single row in one spreadsheet, and then consulting all the rows in a second spreadsheet for some bit of relevant information. Subqueries provide the analogous functionality in T-SQL.
These are not rigorous definitions. Their imagery provides only a beginning to help you understand the operations. The recipes that follow go deeper and show how to combine these building blocks, along with other basic T-SQL functionality, to generate business results.
4-1. Correlating Parent and Child Rows
Problem
You want to bring together data from parent and child tables. For example, you have a list of people in a parent table named Person, and a list of phone numbers in a child table named PersonPhone. Each person may have zero, one, or several phone numbers. You want to return a list of each person having at least one phone number, along with all their numbers.
![]() Note It is also possible to return all persons, including those having zero phone numbers. You would do that by making the phone number side of the join optional, using the method from Recipe 4-3.
Note It is also possible to return all persons, including those having zero phone numbers. You would do that by making the phone number side of the join optional, using the method from Recipe 4-3.
Solution
Write an inner join to bring related information from two tables together into a single result set. Begin with a FROM clause and one of the tables:
FROM Person.Person
Add the keywords INNER JOIN followed by the second table:
FROM Person.Person
INNER JOIN Person.PersonPhone
Follow with an ON clause to specify the join condition. The join condition identifies the row combinations of interest. It is the BusinessEntityID that identifies a person. That same ID identifies the phone numbers for a person. For this example, you want all combinations of Person and PersonPhone rows sharing the same value for BusinessEntityID. The following ON clause gives that result:
FROM Person.Person
INNER JOIN Person.PersonPhone
ON Person.BusinessEntityID = PersonPhone.BusinessEntityID
Specify the columns you wish to see in the output. All columns from both tables are available. The following final version of the query returns two columns from each table:
SELECT PersonPhone.BusinessEntityID,
FirstName,
LastName,
PhoneNumber
FROM Person.Person
INNER JOIN Person.PersonPhone
ON Person.BusinessEntityID = PersonPhone.BusinessEntityID
ORDER BY LastName,
FirstName,
Person.BusinessEntityID;
The ORDER BY clause sorts the results so that all phone numbers for a given person fall together. Results are as follows:

How It Works
The inner join is one of the most fundamental operations to understand. Imagine the following, very simplified two tables:

From a conceptual standpoint, an inner join begins with all possible combinations of rows from the two tables. Some combinations make sense. Some do not. The set of all possible combinations is called the Cartesian product. Notice the bold rows in the following Cartesian product.

It makes sense to have Syed’s name in the same row as his phone number. Likewise, it is sensible to list Catherine with her phone number. There’s no logic at all in listing Syed’s name with Catherine’s number, or vice versa. Thus, the join condition is very sensibly written to specify the case in which the two BusinessEntityID values are the same:
ON Person.BusinessEntityID = PersonPhone.BusinessEntityID
The Cartesian product gives all possible results from an inner join. Picture the Cartesian product in your mind. Bring in the fishnet analogy from Recipe 1-4. Then write join conditions to trap the rows that you care about as the Cartesian product falls through your net.
![]() Note Database engines do not materialize the entire Cartesian product when executing an inner join. There are more efficient approaches for SQL Server to take. However, regardless of approach, the results will always be in line with the conceptual description given here in this recipe.
Note Database engines do not materialize the entire Cartesian product when executing an inner join. There are more efficient approaches for SQL Server to take. However, regardless of approach, the results will always be in line with the conceptual description given here in this recipe.
THE TERM “RELATIONAL”
One sometimes hears the claim that the word “relational” in relational database refers to the fact that one table can “relate” to another in the sense that one joins the two tables together as described in Recipe 4-1. That explanation sounds so very plausible, yet it is wrong.
The term relation comes from set theory, and you can read in detail about what a relation is by visiting Wikipedia’s article on finitary relations:
http://en.wikipedia.org/wiki/Finitary_relation
The key statement from the current version of this article reads as follows (emphasis mine).
Typically, the property [a relation] describes a possible connection between the components of a k-tuple.
The words “between the components of” tell the tale. A tuple’s analog is the row. The components of a tuple are its values, and thus the database analog would be the values in a row. The term relation speaks to a relationship, not between tables, but between the values in a row.
We encourage you to read the Wikipedia article. Then if you really want to dive deep into set theory and how it can help you work with data, we recommend the book Applied Mathematics for Database Professionals by Lex de Haan and Toon Koppelaars (Apress, 2007).
4-2. Querying Many-to-Many Relationships
Problem
You have a many-to-many relationship with two detail tables on either side of an intersection table. You want to resolve the relationship across all three tables.
Solution
String two inner joins together. The following example joins three tables in order to return discount information on a specific product:
SELECT p.Name,
s.DiscountPct
FROM Sales.SpecialOffer s
INNER JOIN Sales.SpecialOfferProduct o
ON s.SpecialOfferID = o.SpecialOfferID
INNER JOIN Production.Product p
ON o.ProductID = p.ProductID
WHERE p.Name = 'All-Purpose Bike Stand';
The results of this query are as follows:
Name DiscountPct
----------------------- -----------
All-Purpose Bike Stand 0.00
How It Works
A join starts after the first table in the FROM clause. In this example, three tables are joined together: Sales.SpecialOffer, Sales.SpecialOfferProduct, and Production.Product. Sales.SpecialOffer, the first table referenced in the FROM clause, contains a lookup of sales discounts:
FROM Sales.SpecialOffer s
Notice the letter s that trails the table name. This is a table alias . Once you begin using more than one table in a query, it is important to identify the data source of the individual columns explicitly. If the same column names exist in two different tables, you can get an error from the SQL compiler asking you to clarify which column you really want to return.
As a best practice, it is a good idea to use aliases whenever column names are specified in a query. For each of the referenced tables, an alias is used to symbolize the table name, saving you the trouble of spelling it out each time. This query uses a single character as a table alias, but you can use any valid identifier. A table alias, aside from allowing you to shorten or clarify the original table name, allows you to swap out the base table name if you ever have to replace it with a different table or view, or if you need to self-join the tables. Table aliases are optional, but recommended when your query has more than one table. (Because table aliases are optional, you can instead specify the entire table name every time you refer to the column in that table.)
Getting back to the example, the INNER JOIN keywords follow the first table reference, and then the table being joined to it, followed by its alias:
INNER JOIN Sales.SpecialOfferProduct o
After that, the ON keyword prefaces the column joins:
ON
This particular INNER JOIN is based on the equality of two columns, one from the first table and another from the second:
s.SpecialOfferID = o.SpecialOfferID
Next, the Production.Producttable is inner joined too:
INNER JOIN Production.Product p
ON o.ProductID = p.ProductID
Lastly, a WHERE clause is used to filter rows returned in the final result set:
WHERE p.Name = 'All-Purpose Bike Stand';
![]() Tip As a query performance best practice, try to avoid having to convert data types of the columns in your join clause (using CONVERT or CAST, for example). Opt instead for modifying the underlying schema to match data types (or convert the data beforehand in a separate table, temp table, table variable, or common table expression [CTE]). Also, allowing implicit data type conversions to occur for frequently executed queries can cause significant performance issues (for example, converting nchar to char).
Tip As a query performance best practice, try to avoid having to convert data types of the columns in your join clause (using CONVERT or CAST, for example). Opt instead for modifying the underlying schema to match data types (or convert the data beforehand in a separate table, temp table, table variable, or common table expression [CTE]). Also, allowing implicit data type conversions to occur for frequently executed queries can cause significant performance issues (for example, converting nchar to char).
4-3. Making One Side of a Join Optional
Problem
You want rows returned from one table in a join even when there are no corresponding rows in the other table. For example, you want to list states and provinces and their tax rates. Sometimes no tax rate is on file. In those cases, you still want to list the state or province.
Solution
Write an outer join rather than the inner join that you have seen in the recipes so far. You can designate an outer join as either left or right. Following is a left outer join to produce a list of all states and provinces, including tax rates when they are available.
SELECT s.CountryRegionCode,
s.StateProvinceCode,
t.TaxType,
t.TaxRate
FROM Person.StateProvince s
LEFT OUTER JOIN Sales.SalesTaxRate t
ON s.StateProvinceID = t.StateProvinceID;
This returns the following (abridged) results.
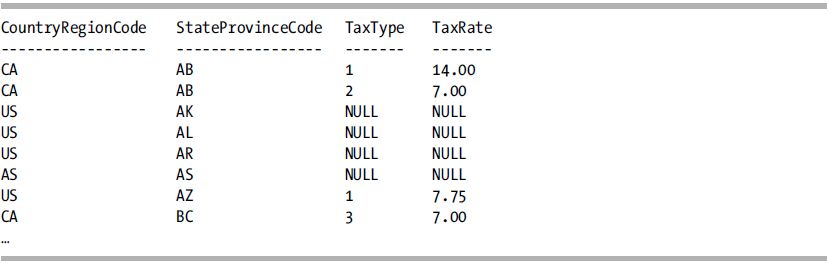
How It Works
A left outer join causes the table named first to become the nonoptional, or anchor table. The word “left” derives from the fact that English is written left to right. The left outer join in the solution makes StateProvince the anchor table, so all states are returned. The sales tax side of the join is then the optional side, and the database engine supplies nulls for the sales tax columns when no corresponding row exists for each state in question.
Change the join type in the solution from LEFT OUTER to INNER, and you’ll get only those rows for states having tax rates defined in the SalesTaxRate table. That’s because an inner join requires a row from each table involved. By making the join a left outer join, you make the right-hand table optional. Rows from the left-hand table are returned regardless of whether corresponding rows exist in the other table. Thus, you get all states and provinces; lack of a tax rate does not prevent a state or province from appearing in the results.
It is common to write outer joins with one optional table as left outer joins. However, you do have the option of looking at things from the other direction. For example:
FROM Sales.SalesTaxRate t
RIGHT OUTER JOIN Person.StateProvince s
This right outer join will yield the same results as the left outer join in the solution example. That’s because the order of the tables has been flipped. StateProvince is now on the right-hand side, and it is the anchor table once again because this time a right outer join is used.
![]() Tip Experiment! Take time to execute the solution query. Then change the join clause to read INNER JOIN. Note the difference in results. Then change the entire FROM clause to use a right outer join with the StateProvince table on the right-hand side. You should get the same results as from the solution query.
Tip Experiment! Take time to execute the solution query. Then change the join clause to read INNER JOIN. Note the difference in results. Then change the entire FROM clause to use a right outer join with the StateProvince table on the right-hand side. You should get the same results as from the solution query.
4-4. Making Both Sides of a Join Optional
Problem
You want the effect of a left and a right outer join at the same time.
Solution
Write a full outer join. Do that using the keywords FULL OUTER JOIN.
For example:
SELECT soh.SalesOrderID,
sr.SalesReasonID,
sr.Name
FROM Sales.SalesOrderHeader soh
FULL OUTER JOIN Sales.SalesOrderHeaderSalesReason sohsr
ON soh.SalesOrderID = sohsr.SalesOrderID
FULL OUTER JOIN Sales.SalesReason sr
ON sr.SalesReasonID = sohsr.SalesReasonID;
This query follows the same pattern as that in Recipe 4-3 on querying many-to-many relationships. Only the join type and tables are different.
How It Works
The solution query returns sales orders and their associated reasons. The full outer join in the query guarantees the following:
- All the results from an inner join
- One additional row for each order not associated with a sale
- One additional row for each sales reason not associated with an order
The additional rows have nulls from one side of the join or the other. If there is no order associated with a reason, then there is no value available for the SalesOrderID column in the result, and the value is null. Likewise, the SalesReasonID and Name values are null in the case of an order having no reason.
Results are as follows for orders associated with reasons:
| SalesOrderID | SalesReasonID | Name |
| ------------ | ------------- | ------------ |
| 43697 | 5 | Manufacturer |
| 43697 | 9 | Quality |
| 43702 | 5 | Manufacturer |
| … |
Any reasons not associated with an order will come back with nulls in the order columns:
| SalesOrderID | SalesReasonID | Name |
| ------------ | ------------- | ---------------------- |
| NULL | 3 | Magazine Advertisement |
| NULL | 7 | Demo Event |
| NULL | 8 | Sponsorship |
| … |
Any orders not given a reason will likewise come back with nulls in the reason columns:
| SalesOrderID | SalesReasonID | Name |
| ------------ | ------------- | ---- |
| 45889 | NULL | NULL |
| 48806 | NULL | NULL |
| 51723 | NULL | NULL |
| … |
All the preceding results will come back as a single result set.
![]() Tip Consider adding a WHERE clause to hone in on the special-case rows in the result set. By itself, the sample query returns a great many rows, most of them having data from both sides of the join. You can hone in on the rows having only reasons by appending the clause WHERE soh.SalesOrderID IS NULL to the end of the query. Likewise, append WHERE sr.SalesReasonID IS NULL to see rows having only data from the sales side of the join.
Tip Consider adding a WHERE clause to hone in on the special-case rows in the result set. By itself, the sample query returns a great many rows, most of them having data from both sides of the join. You can hone in on the rows having only reasons by appending the clause WHERE soh.SalesOrderID IS NULL to the end of the query. Likewise, append WHERE sr.SalesReasonID IS NULL to see rows having only data from the sales side of the join.
4-5. Generating All Possible Row Combinations
Problem
You want to generate all possible combinations of rows from two tables. You want to generate the Cartesian product described in Recipe 4-1.
Solution
Write a cross join. In this example, the Person.StateProvince and Sales.SalesTaxRate tables are cross joined to generate all possible combinations of rows from the two tables:
SELECT s.CountryRegionCode,
s.StateProvinceCode,
t.TaxType,
t.TaxRate
FROM Person.StateProvince s
CROSS JOIN Sales.SalesTaxRate t;
This returns the following (abridged) results:

How It Works
A cross join is essentially a join with no join conditions. Every row from one table is joined to every row in the other table, regardless of whether the resulting combination of values makes any sense. The result is termed a Cartesian product.
The solution results show StateProvince and SalesTaxRate information that doesn’t logically go together. Because the Person.StateProvince table had 181 rows, and the Sales.SalesTaxRate had 29 rows, the query returned 5249 rows.
4-6. Selecting from a Result Set
Problem
You find it easier to think in terms of selecting a set of rows, and then selecting again from that result.
Solution
Create a derived table in your FROM clause by enclosing a SELECT statement within parentheses. For example, the following query joins SalesOrderHeader to the results from a query against SalesOrderDetail:
SELECT DISTINCT
s.PurchaseOrderNumber
FROM Sales.SalesOrderHeader s
INNER JOIN (SELECT SalesOrderID
FROM Sales.SalesOrderDetail
WHERE UnitPrice BETWEEN 1000 AND 2000
) d
ON s.SalesOrderID = d.SalesOrderID;
This returns the following abridged results:
PurchaseOrderNumber
-------------------
PO10962177551
PO11571175810
PO10469158272
PO10237188382
PO17661178081
…
How It Works
Derived tables are SELECT statements that act as tables in the FROM clause. A derived table is a separate query in itself, and doesn’t require the use of a temporary table to store its results. Thus, queries that use derived tables can sometimes perform significantly better than the process of building a temporary table and querying from it, as you eliminate the steps needed for SQL Server to create and allocate a temporary table prior to use.
This example’s query searches for the PurchaseOrderNumber from the Sales.SalesOrderHeader table for any order containing products with a UnitPrice between 1000 and 2000. The query joins a table to a derived table using an inner join operation. The derived table query is encapsulated in parentheses and is followed by a table alias.
4-7. Testing for the Existence of a Row
Problem
You are writing a WHERE clause. You want to return rows from the table you are querying based upon the existence of related rows in some other table.
Solution
One solution is to write a subquery in conjunction with the EXISTS predicate:
SELECT DISTINCT
s.PurchaseOrderNumber
FROM Sales.SalesOrderHeader s
WHERE EXISTS ( SELECT SalesOrderID
FROM Sales.SalesOrderDetail
WHERE UnitPrice BETWEEN 1000 AND 2000
AND SalesOrderID = s.SalesOrderID );
This returns the following abridged results.
PurchaseOrderNumber
-------------------
PO10962177551
PO11571175810
PO10469158272
PO10237188382
…
How It Works
The critical piece in the solution example is the subquery in the WHERE clause, which checks for the existence of SalesOrderIDs that have products with a UnitPrice between 1000 and 2000. A JOIN is essentially written into the WHERE clause of the subquery by stating SalesOrderID = s.SalesOrderID. The subquery uses the SalesOrderID from each returned row in the outer query.
The subquery in this recipe is known as a correlated subquery. It is called such because the subquery accesses values from the parent query. It is certainly possible to write an EXISTS predicate with a noncorrelated subquery, however, it is unusual to do so.
Look back at Recipe 4-6. It solves the same problem and generates the same results, but using a derived table in the FROM clause. Often you can solve such problems multiple ways. Pick the one that performs best. If performance is equal, then pick the approach with which you are most comfortable.
4-8. Testing Against the Result from a Query
Problem
You are writing a WHERE clause and wish to write a predicate involving the result from another query. For example, you wish to compare a value in a table against the maximum value in a related table.
Solution
Write a noncorrelated subquery. Make sure it returns a single value. Put the query where you would normally refer to the value. For example:
SELECT BusinessEntityID,
SalesQuota CurrentSalesQuota
FROM Sales.SalesPerson
WHERE SalesQuota = (SELECT MAX(SalesQuota)
FROM Sales.SalesPerson
);
This returns the three salespeople who had the maximum sales quota of 300,000:
BusinessEntityID CurrentSalesQuota
---------------- ---------------------
275 300000.00
279 300000.00
284 300000.00
Warning: Null value is eliminated by an aggregate or other SET operation.
How It Works
There is no WHERE clause in the subquery, and the subquery does not reference values from the parent query. It is therefore not a correlated subquery. Instead, the maximum sales quota is retrieved once. That value is used to evaluate the WHERE clause for all rows tested by the parent query.
Ignore the warning message in the results. That message simply indicates that some of the SalesQuota values fed into the MAX function were null. You can avoid the message by adding WHERE SalesQuota IS NOT NULL to the subquery. You can also avoid the message by issuing the command set ANSI_WARNINGS OFF. However, there is no real need to avoid the message at all unless it offends your sense of tidiness to see it.
4-9. Comparing Subsets of a Table
Problem
You have two subsets in a table, and you want to compare values between them. For example, you want to compare sales data between two calendar years.
Solution
One solution is to join the table with itself through the use of table aliases. In this example, the Sales.SalesPersonOuotaHistory table is referenced twice in the FROM clause, once for 2008 sales quota data and again for 2007 sales quota data:
SELECT s.BusinessEntityID,
SUM(s2008.SalesQuota) Total_2008_SQ,
SUM(s2007.SalesQuota) Total_2007_SQ
FROM Sales.SalesPerson s
LEFT OUTER JOIN Sales.SalesPersonQuotaHistory s2008
ON s.BusinessEntityID = s2008.BusinessEntityID
AND YEAR(s2008.QuotaDate) = 2008
LEFT OUTER JOIN Sales.SalesPersonQuotaHistory s2007
ON s.BusinessEntityID = s2007.BusinessEntityID
AND YEAR(s2007.QuotaDate) = 2007
GROUP BY s.BusinessEntityID;
This returns the following (abridged) results:
BusinessEntityID Total_2008_SQ Total_2007_SQ
---------------- ------------- -------------
274 1084000.00 1088000.00
275 6872000.00 9432000.00
276 8072000.00 9364000.00
…
How It Works
Sometimes you may need to treat the same table as two separate tables. This may be because the table contains nested hierarchies of data (for example, a table containing employee records has a manager ID that is a foreign key reference to the employee ID), or perhaps you wish to reference the same table based on different time periods (comparing sales records from the year 2008 versus the year 2007).
This recipe queries the year 2008 and year 2007 sales quota results. The FROM clause includes an anchor to all salesperson identifiers:
FROM Sales.Salesperson s
The query then left outer joins the first reference to the sales quota data, giving it an alias of S2008:
LEFT OUTER JOIN Sales.SalesPersonQuotaHistory s2008
ON s.BusinessEntityID = s2008.BusinessEntityID
AND YEAR(s2008.QuotaDate) = 2008
Next, another reference was created to the same sales quota table, however, this time aliasing the table as S2007:
LEFT OUTER JOIN Sales.SalesPersonQuotaHistory s2007
ON s.BusinessEntityID = s2007.BusinessEntityID
AND YEAR(s2007.QuotaDate) = 2007
As demonstrated here, you can reference the same table multiple times in the same query as long as you give each reference a unique table alias to differentiate it from the others.
![]() Tip When you find yourself using the technique in Recipe 4-9, step back and consider whether you can rethink your approach and apply window function syntax instead. The article “H.G. Wells and SQL: Travelling in the Second Dimension” at http://gennick.com/windowss02.html describes a scenario similar to this recipe’s solution in which values are compared across time. Window functions often solve such problems with better performance than the self-join technique given in this recipe. Chapter 7 includes examples covering this useful and expressive class of functions.
Tip When you find yourself using the technique in Recipe 4-9, step back and consider whether you can rethink your approach and apply window function syntax instead. The article “H.G. Wells and SQL: Travelling in the Second Dimension” at http://gennick.com/windowss02.html describes a scenario similar to this recipe’s solution in which values are compared across time. Window functions often solve such problems with better performance than the self-join technique given in this recipe. Chapter 7 includes examples covering this useful and expressive class of functions.
4-10. Stacking Two Row Sets Vertically
Problem
You are querying the same data from two different sources. You wish to combine the two sets of results. For example, you wish to combine current with historical sales quotas.
Solution
Write two queries. Glue them together with the UNION ALL operator. For example:
SELECT BusinessEntityID,
GETDATE() QuotaDate,
SalesQuota
FROM Sales.SalesPerson
WHERE SalesQuota > 0
UNION ALL
SELECT BusinessEntityID,
QuotaDate,
SalesQuota
FROM Sales.SalesPersonQuotaHistory
WHERE SalesQuota > 0
ORDER BY BusinessEntityID DESC,
QuotaDate DESC;
Results are as follows.
| BusinessEntityID | QuotaDate | SalesQuota |
| ---------------- | ----------------------- | ---------- |
| 290 | 2012-02-09 00:04:39.420 | 250000.00 |
| 290 | 2008-04-01 00:00:00.000 | 908000.00 |
| 290 | 2008-01-01 00:00:00.000 | 707000.00 |
| 290 | 2007-10-01 00:00:00.000 | 1057000.00 |
| … |
How It Works
The solution query appends two result sets into a single result set. The first result set returns the BusinessEntitylD, the current date, and the SalesQuota. Because GETDATE() is a function, it doesn’t naturally generate a column name, so a QuotaDate column alias was used in its place:
SELECT BusinessEntityID,
GETDATE() QuotaDate,
SalesQuota
FROM Sales.SalesPerson
The WHERE clause filters data for those salespeople with a SalesQuota greater than zero:
WHERE SalesQuota > 0
The next part of the query is the UNION ALL operator, which appends all results from the second query:
UNION ALL
The second query pulls data from the Sales.SalesPersonQuotaHistory, which keeps the history for a salesperson’s sales quota as it changes through time:
SELECT BusinessEntityID,
QuotaDate,
SalesQuota
FROM Sales.SalesPersonQuotaHistory
The ORDER BY clause sorts the result set by BusinessEntitylD and QuotaDate, both in descending order. The ORDER BY clause, when needed, must appear at the bottom of the entire statement. In the solution query, the clause is:
ORDER BY BusinessEntityID DESC,
QuotaDate DESC;
You cannot write individual ORDER BY clauses for each of the SELECTs that you UNION together. ORDER BY can only appear once at the end, and applies to the combined result set.
Column names in the final, combined result set derive from the first SELECT in the overall statement. Thus, the ORDER BY clause should only refer to column names from the first result set.
![]() Tip UNION ALL is more efficient than UNION (described in the next recipe), because UNION ALL does not force a sort or similar operation in support of duplicate elimination. Use UNION ALL whenever possible, unless you really do need duplicate rows in the result set to be eliminated.
Tip UNION ALL is more efficient than UNION (described in the next recipe), because UNION ALL does not force a sort or similar operation in support of duplicate elimination. Use UNION ALL whenever possible, unless you really do need duplicate rows in the result set to be eliminated.
4-11. Eliminating Duplicate Values from a Union
Problem
You are writing a UNION query and prefer not to have duplicate rows in the results. For example, you wish to generate a list of unique surnames from among employees and salespersons.
Solution
Write a union query, but omit the ALL keyword and write just UNION instead. For example:
SELECT P1.LastName
FROM HumanResources.Employee E
INNER JOIN Person.Person P1
ON E.BusinessEntityID = P1.BusinessEntityID
UNION
SELECT P2.LastName
FROM Sales.SalesPerson SP
INNER JOIN Person.Person P2
ON SP.BusinessEntityID = P2.BusinessEntityID;
Results are as follows.
LastName
-----------
Abbas
Abercrombie
Abolrous
Ackerman
Adams
…
How It Works
The behavior of the UNION operator is to remove all duplicate rows. The solution query uses that behavior to generate a list of unique surnames from among the combined group of employees and salespersons.
For large result sets, deduplication can be a very costly operation. It very often involves a sort. If you don’t need to deduplicate your data, or if your data is naturally distinct, write UNION ALL instead and your queries will run more efficiently. (See Recipe 4-10 for an example of UNION ALL.)
![]() Caution Do you need your results sorted? Then be sure to write an ORDER BY clause. The solution results appear sorted, but that is a side effect from the deduplication operation. You should not count on such a side effect. The database engine might not drive the sort to completion. Other deduplication logic can be introduced in a future release and break your query. If you need ordering, write an ORDER BY clause into your query.
Caution Do you need your results sorted? Then be sure to write an ORDER BY clause. The solution results appear sorted, but that is a side effect from the deduplication operation. You should not count on such a side effect. The database engine might not drive the sort to completion. Other deduplication logic can be introduced in a future release and break your query. If you need ordering, write an ORDER BY clause into your query.
4-12. Subtracting One Row Set from Another
Problem
You want to subtract one set of rows from another. For example, you want to subtract component ID numbers from a list of product ID numbers to find those products that are at the top of the heap and are not themselves part of some larger product.
Solution
Write a union query involving the EXCEPT operator. Subtract products that are components from the total list of products, leaving only those products that are not components. For example:
SELECT P.ProductID
FROM Production.Product P
EXCEPT
SELECT BOM.ComponentID
FROM Production.BillOfMaterials BOM;
ProductID
-----------
378
710
879
856
…
How It Works
EXCEPT begins with the first query and eliminates any rows that are also found in the second. It is considered to be a union operator, although the operation is along the lines of a subtraction.
In the Adventure Works database, the BillOfMaterials table describes products that are made up of other products. The component products are recorded in the ComponentID column. Thus, subtracting the ComponentID values from the ProductID values in the Product table leaves only those products that are at the top and are not themselves part of some larger product.
![]() Note The EXCEPT operator implicitly deduplicates the final result set.
Note The EXCEPT operator implicitly deduplicates the final result set.
4-13. Finding Rows in Common Between Two Row Sets
Problem
You have two queries. You want to find which rows are returned by both. For example, you wish to find products that have incurred both good and poor reviews.
Solution
Write a union query using the INTERSECT keyword. For example:
SELECT PR1.ProductID
FROM Production.ProductReview PR1
WHERE PR1.Rating >= 4
INTERSECT
SELECT PR1.ProductID
FROM Production.ProductReview PR1
WHERE PR1.Rating <= 2;
Results from this query show the one product having both good and bad reviews:
ProductID
---------
937
How It Works
The INTERSECT operator finds rows in common between two row sets. The solution example defines a good review as one with a rating of 4 and above. A bad review is a rating of 2 and lower. It’s easy to write a separate query to identify products falling into each case. The INTERSECT operator takes the results from both those simple queries and returns a single result set showing the products—just one in this case—that both queries return.
![]() Note Like the EXCEPT operator, INTERSECT implicitly deduplicates the final results.
Note Like the EXCEPT operator, INTERSECT implicitly deduplicates the final results.
Sometimes you’ll find yourself wanting to include other columns in an INTERSECT query, and those columns cause the intersection operation to fail because that operation is performed taking all columns into account. One solution is to treat the intersection query as a derived table and join it to the Product table. For example:
SELECT PR3.ProductID,
PR3.Name
FROM Production.Product PR3
INNER JOIN (SELECT PR1.ProductID
FROM Production.ProductReview PR1
WHERE PR1.Rating >= 4
INTERSECT
SELECT PR1.ProductID
FROM Production.ProductReview PR1
WHERE PR1.Rating <= 2
) SQ
ON PR3.ProductID = SQ.ProductID;
ProductID Name
--------- -----------------
937 HL Mountain Pedal
Another approach is to move the intersection subquery into the WHERE clause and use it to generate an in-list using a technique similar to that shown earlier in Recipe 4-8. For example:
SELECT ProductID,
Name
FROM Production.Product
WHERE ProductID IN (SELECT PR1.ProductID
FROM Production.ProductReview PR1
WHERE PR1.Rating >= 4
INTERSECT
SELECT PR1.ProductID
FROM Production.ProductReview PR1
WHERE PR1.Rating <= 2);
ProductID Name
--------- -----------------
937 HL Mountain Pedal
In this version of the query, the subquery generates a list of product ID numbers. The database engine then treats that list as input into the IN predicate. There is only one product in this case, so you can think loosely in terms of the database engine ultimately executing a statement such as the following:
SELECT ProductID,
Name
FROM Production.Product
WHERE ProductID IN (937);
You can actually write an IN predicate giving a list of hard-coded values. Or you can choose to generate that list of values from a SELECT, as in this recipe.
4-14. Finding Rows That Are Missing
Problem
You want to find rows in one table or result set that have no corresponding rows in another. For example, you want to find all products in the Product table having no corresponding special offers.
Solution
Different approaches are possible. One approach is to write a query involving EXCEPT:
SELECT ProductID
FROM Production.Product
EXCEPT
SELECT ProductID
FROM Sales.SpecialOfferProduct;
ProductID
-----------
1
2
3
…
If you want to see more than just a list of ID numbers, you can write a query involving NOT EXISTS and a correlated subquery. For example:
SELECT P.ProductID,
P.Name
FROM Production.Product P
WHERE NOT EXISTS ( SELECT *
FROM Sales.SpecialOfferProduct SOP
WHERE SOP.ProductID = P.ProductID );
ProductID Name
--------- ---------------
1 Adjustable Race
2 Bearing Ball
3 BB Ball Bearing
…
How It Works
The solution involving EXCEPT is simple to write and easy to understand. The top query generates a list of all possible products. The bottom query generates a list of products that have been given special offers. EXCEPT subtracts the second list from the first and returns a list of products having no corresponding rows in SpecialOfferProduct. The downside is that the approach of using EXCEPT limits the final results to just a list of ID numbers.
The second solution involves a NOT EXISTS predicate. You first read about EXISTS in Recipe 4-7. NOT EXISTS is a variation on that theme. Rather than testing for existence, the predicate tests for nonexistence. The parent query then returns all product rows not having corresponding special offers. You are able to include any columns from the Product table in the query results that you desire.
Problem
You have two copies of a table. You want to test for equality. Do both copies have the same rows and column values?
Solution
Begin by creating a copy of a table, in this case the Password table:
SELECT *
INTO Person.PasswordCopy
FROM Person.Password;
Then execute the following union query to compare the data between the two tables and report on the differences.
SELECT *,
COUNT(*) DupeCount,
'Password' TableName
FROM Person.Password P
GROUP BY BusinessEntityID,
PasswordHash,
PasswordSalt,
rowguid,
ModifiedDate
HAVING NOT EXISTS ( SELECT *,
COUNT(*)
FROM Person.PasswordCopy PC
GROUP BY BusinessEntityID,
PasswordHash,
PasswordSalt,
rowguid,
ModifiedDate
HAVING PC.BusinessEntityID = P.BusinessEntityID
AND PC.PasswordHash = P.PasswordHash
AND PC.PasswordSalt = P.PasswordSalt
AND PC.rowguid = P.rowguid
AND PC.ModifiedDate = P.ModifiedDate
AND COUNT(*) = COUNT(ALL P.BusinessEntityID))
UNION
SELECT *,
COUNT(*) DupeCount,
'PasswordCopy' TableName
FROM Person.PasswordCopy PC
GROUP BY BusinessEntityID,
PasswordHash,
PasswordSalt,
rowguid,
ModifiedDate
HAVING NOT EXISTS ( SELECT *,
COUNT(*)
FROM Person.Password P
GROUP BY BusinessEntityID,
PasswordHash,
PasswordSalt,
rowguid,
ModifiedDate
HAVING PC.BusinessEntityID = P.BusinessEntityID
AND PC.PasswordHash = P.PasswordHash
AND PC.PasswordSalt = P.PasswordSalt
AND PC.rowguid = P.rowguid
AND PC.ModifiedDate = P.ModifiedDate
AND COUNT(*) = COUNT(ALL PC.BusinessEntityID) );
Results from this query will be zero rows. That is because the tables are unchanged. You’ve made a copy of Password, but haven’t changed values in either table.
Now make some changes to the data in the two tables. BusinessEntityID numbers are in the range 1, . . . , 19972. Following are some statements to change data in each table, and to create one duplicate row in the copy:
UPDATE Person.PasswordCopy
SET PasswordSalt = 'Munising!'
WHERE BusinessEntityID IN (9783, 221);
UPDATE Person.Password
SET PasswordSalt = 'Marquette!'
WHERE BusinessEntityID IN (42, 4242);
INSERT INTO Person.PasswordCopy
SELECT *
FROM Person.PasswordCopy
WHERE BusinessEntityID = 1;
Having changed the data, reissue the previous union query to compare the two tables. This time there are results indicating the differences just created:


These results indicate rows from each table that are not found in the other. They also indicate differences in duplication counts.
How It Works
The solution query is intimidating at first, and it is a lot to type. But it is a rote query once you get the hang of it, and the two halves are essentially mirror images of each other.
The grouping and counting is there to handle the possibility of duplicate rows. Each of the queries on either side of the union begins by grouping on all columns and generating a duplication count. For example, the second subquery examines PasswordCopy:
SELECT *,
COUNT(*) DupeCount,
'PasswordCopy' TableName
FROM Person.PasswordCopy PC
GROUP BY BusinessEntityID,
PasswordHash,
PasswordSalt,
rowguid,
ModifiedDate;

Here you can see that there are two rows containing the same set of values. Both rows are associated with BusinessEntityID 1. The DupeCount for that ID is 2.
Next comes a subquery in the HAVING clause to restrict the results to only those rows not also appearing in the Password table:
HAVING NOT EXISTS ( SELECT *,
COUNT(*)
FROM Person.PasswordCopy PC
GROUP BY BusinessEntityID,
PasswordHash,
PasswordSalt,
rowguid,
ModifiedDate
HAVING PC.BusinessEntityID = P.BusinessEntityID
AND PC.PasswordHash = P.PasswordHash
AND PC.PasswordSalt = P.PasswordSalt
AND PC.rowguid = P.rowguid
AND PC.ModifiedDate = P.ModifiedDate
AND COUNT(*) = COUNT(ALL P.BusinessEntityID) )
This HAVING clause is tedious to write, but it is conceptually simple. It compares all columns for equality. It compares row counts to check for differences in the number of times a row is duplicated in either of the tables. The results are a list of rows in PasswordCopy that do not also exist the same number of times in Password.
Both queries do the same thing from different directions. The first query in the union finds rows in Password that are not also in PasswordCopy. The second query reverses things and finds rows in PasswordCopy that are not also in Password. Both queries will detect differences in duplication counts.
In the solution results there is one row that is reported because it occurs twice in the copy and once in the original:

The TableName column lets you see that Password contains just one row for BusinessEntityID 1. That makes sense, because that column is the primary key. The PasswordCopy table, however, has no primary key. Somehow, someone has duplicated the row for BusinessEntityID 1. That table has two copies of the row. Because the number of copies is different, the tables do not compare as being equal.
The solution query reports differences between the two tables. An empty result set indicates that the two tables contain the same rows, having the same values, and occurring the same number of times.