
As people work with the data in your databases, they make changes. They may be inserting new information, deleting information they no longer need, or modifying other information, or all of the above. As the data changes, these changes directly affect your indexes, both rowstore and columnstore, albeit in different ways. For your rowstore indexes, the acts of modifying the data can lead to page splits, pages getting rearranged, and pages getting emptied, all summed up in a term called fragmentation. In your columnstore indexes, you’re not dealing with the same kind of fragmentation, but you are dealing with the deltastore, marking data that has been deleted, or keeping updated and inserted data ready for when it gets pivoted and compressed. Fragmentation can, in some circumstances, lead to performance degradation. Unfortunately, fixing fragmentation can also lead to performance degradation.
The causes of rowstore index fragmentation
The causes of columnstore index fragmentation
An explanation of fragmentation’s impact on performance
How to analyze the amount of fragmentation on rowstore and columnstore indexes
Techniques to resolve fragmentation
The significance of fill factor in controlling fragmentation in rowstore indexes
Automation techniques for fragmentation
Causes of Rowstore Fragmentation
Making changes to the data in a database can lead to index fragmentation. Adding or removing a row, through INSERT or DELETE operations, leads to changes in the clustered and nonclustered indexes on the table. UPDATES can also lead to fragmentation. We’ll discuss the various mechanisms for rowstore fragmentation here and will address columnstore fragmentation in the next section.
How Fragmentation Occurs in Rowstore Indexes
The key to understanding fragmentation goes right back to understanding how indexes store data. Everything goes on a page, fixed in size to 8k. Removing data from a page leaves gaps. Adding data to a page that is full results in the need for a new page. Modifying data in a page that is full can also lead to the need for a new page. As new pages get added to the index, they’re not necessarily next to the existing pages on the disk. Logically, the data will absolutely maintain the correct order as defined by the index key. However, the physical order and logical order may not be in any way related.

A diagram of an index has a row of 3 bars with 4 blocks each, with the bars linked by clockwise arrows. The 4 blocks in bar 1 contain the numbers 10 to 40, bar 2, 50 to 80, and bar 3 has 90, with the last 3 blocks empty.
Leaf pages in order

A diagram of an index has a row of 4 bars with 4 blocks each, with bar 1 to 4 linked by rightward arrows, and bar 4 to 2 and 3, by leftward arrows.
Leaf pages out of order

A diagram of an index has a row of 4 bars with 4 blocks each, with bar 1 to 4 linked by rightward arrows, bar 4 to 2 and 3, by leftward arrows, and bars 2 and 3 by clockwise arrows.
Pages distributed across extents
Fragmentation of the pages across extents as shown here is called external fragmentation. The fragmentation, free space, left by page splits or deletes, inside of a page, is called internal fragmentation. Both types of fragmentation can lead to poor performance.
The extent is switched to get the value 30 after the value 25.
The extent switches back to get the value of 50 after the value of 40.
Finally, another extent switch occurs to get the value of 90.
Interestingly enough, free space on the pages can help in a highly transactional system. In our example index, if the value of 26 was added, it can go right on the page next to 25.
All of this is exacerbated when we talk about tables that are stored as heaps. The fragmentation is exactly the same. However, when you decide to use the ALTER TABLE REBUILD command to eliminate fragmentation, you cause a major problem. Since any nonclustered indexes on the heap tables must point to the physical location of the data through the row identifier (RID), when the pages are rearranged to remove fragmentation, the nonclustered indexes must also be completely rebuilt in order to obtain the RID of the new location.
Enough theory. Let’s explore page splits and fragmentation through physical examples.
Page Split from an UPDATE Statement
Creating a table in support of a page split
Querying the index to get its physical layout

A table has 6 columns and 1 row with headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes. The row entries are 0, 1, 1,100, 8, and 1010, where the first entry is highlighted.
Physical attributes of the index iClustered
Updating a column in one row

A table has 6 columns and 1 row with column headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes.
Fragmentation in the index iClustered
We now have two pages. Each page has approximately half of the rows (if there were an odd number of rows, one would have slightly more). You can see that all the other values, except for the record_count, have been updated.
Page Split by an INSERT Statement
Adding a row to SplitTest

A table has 6 columns and 1 row with column headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes.
Fragmentation from an INSERT in iClustered
Once more, approximately half of the rows were moved, and we get a new distribution of the data about the index. There is now space in the rows, and new inserts won’t immediately cause a page split again. This is the advantage of free space in an index.
What would happen if you added a row to the trailing edge of the index, for example, with a value of 501? You will get a new page, but you won’t get a page split. New data will be accommodated on a newly allocated page.
How Fragmentation Occurs in the Columnstore Indexes
Columnstore indexes can be fragmented, after a manner, as well. If we assume that the columnstore index has at least 102,400 rows when it’s first loaded, the data is stored in the compressed column segments that make up a columnstore index as we talked about in Chapter 9. If it’s fewer than 102,400 rows, the data just gets stored in the deltastore, a standard B-Tree index. Once the data is stored in compressed column segments, it’s not fragmented in any way. In order to avoid fragmentation, the changes to the data are stored in the deltastore. Changes to the data, whether updates or deletes, are stored as logical changes. By logical changes, I mean that a delete doesn’t actually delete a given value, but instead the data is marked as deleted, but it is not removed. Updates are also marked as deleted, and the updated value from the deltastore is used in its place. All this means that a columnstore doesn’t suffer from page splits and empty space but instead has to deal with all the logically modified data. These logical deletes represent the fragmentation of the columnstore indexes.
Creating a clustered columnstore index
Querying sys.column_store_row_groups
Deleting rows in bigTransactionHistory

A table has 7 columns and 32 rows, with column headers table name, index name, row group i d, state description, total rows, deleted rows, and percent full. The row entry of big transaction history under the first column is highlighted.
Fragmentation within a clustered columnstore index
The percentage full, the column PercentFull, is now less than 100 for every single group as that DELETE statement hit all of them. This is the kind of fragmentation you may see over time within a columnstore index.
Fragmentation Overhead
This is a somewhat tough discussion. Fragmentation does come with overhead for both rowstore and columnstore indexes. However, the fixes for fragmentation come with overhead as well. We’ll discuss the fixes at length in the following section, resolving fragmentation. However, before we get there, we need to talk about whether or not you should worry about fragmentation at all.
While fragmentation does have some overhead, it also has some benefits. Once an index has been split, it can accommodate a number of rows before it splits again, enhancing performance of inserts and updates. Defragmentation hits you twice for performance. First, you pay a cost in resources, time, and potentially blocking while you run any of the fragmentation solutions. Second, you then begin to pay a cost in large amounts of page splits as your indexes take on new data or receive updates. A page split also causes blocking and additional resource use, especially I/O. Further, some of the more modern disk storage systems are so fast that the jumps between pages during a range scan are practically free.
Because of all this, the old, default stance that, of course you’re going to address fragmentation immediately, has fallen into serious question. Instead, with monitoring and testing to validate the result, some are simply letting fragmentation occur and are seeing no major performance hit because of it. Others are carefully choosing their fill factor on the index, to keep a certain amount of free space on each page when the index is created—in short, sacrificing storage, and memory, to reduce the overhead caused by page splits and the defragmentation process.
Keep these opposing views in mind as we discuss the overhead of fragmentation. Also, plan on carefully measuring performance regardless of the path you choose.
Rowstore Overhead
Both internal and external fragmentation can adversely affect data retrieval performance.
External fragmentation means that index pages are no longer physically stored in order. While the logical order is maintained, the physical order could be all over the disk. This means a range scan on an index will have multiple context switches between extents, slowing down performance. Also, any range scans on the index will be unable to benefit from read-ahead operations.
You’ll generally see superior performance when using sequential I/O, since this can read an entire extent (eight 8KB pages at once) in a single disk I/O operation. A noncontiguous layout of pages results in nonsequential I/O, which means only a single 8KB page can be read at a time.
However, single-row retrieval, or very limited range scans, can perform just fine, despite the fragmentation of an index. If a single page is all that is required to retrieve the necessary data, then the fragmentation doesn’t hurt performance at all.
Internal fragmentation is when the rows are distributed sparsely within a page, increasing the number of pages that must be accessed in order to retrieve the necessary rows. However, internal fragmentation also has benefits since updates and inserts can take advantage of the free space on the index.
Fragmenting a clustered index
Querying the FragTest table
Removing fragmentation in iClustered
You’ll notice that the average runtime for the small data set actually went up. The actual difference between reading 24 and 28 pages is relatively small. This is probably due to some resource contention on the system. However, you’ll also note that taking the reads from over 10k to just over 6.5k resulted in a real reduction in execution time.
So it really matters what kind of queries you’re running predominantly. Smaller queries are unlikely to benefit from defragmenting indexes, while large scans will receive some benefit.
Columnstore Overhead
While what we call fragmentation within the columnstore index is not an artifact of page splits, it still has some negative impact on performance. Deleted and updated values are stored in a B-Tree index associated with the row group. Data retrieval has to go through an internal, additional, join against that index. This added join is not visible in an execution plan. It is visible in the performance metrics, though.
Querying bigTransactionHistory
Deleting data from bigTransactionHistory
I was even surprised at that change in performance. The reads stayed identical, but the duration doubled as it dealt with the fragmented data. As you can see, while the root cause of the fragmentation is different, the negative impact on performance is real.
Analyzing the Amount of Fragmentation
We’ve already introduced the mechanisms to look at the level of fragmentation inside the rowstore and columnstore indexes: sys.dm_db_index_physical_stats and sys.column_store_row_groups, respectively. While sys.dm_db_index_physical_stats is used for clustered and nonclustered indexes, it’s also used for heap tables in the same way.
The output of sys.dm_db_index_physical_stats shows information on the pages and extents of an index (or a heap). A row is returned for each level of the B-Tree in the index. A single row for each allocation unit in a heap is returned.
SQL Server stores the data on 8KB pages. These pages are arranged into eight contiguous pages called an extent. Tables that contain less than the 64KB of data necessary to occupy an extent will share an extent with another table. This is referred to as mixed extents, and it helps SQL Server save space. You can’t defragment mixed extents.
As a table or index grows and requests more than eight pages, SQL Server creates an extent dedicated to the table/index. This type of extent is called a uniform extent. Uniform extents help SQL Server lay out the pages of the table/index contiguously, enhancing performance. While information within an extent can still be fragmented, you’re still going to see efficiencies from storing the pages of an extent together.
The dynamic management function sys.dm_db_index_physical_stats scans the pages of an index to return the data. You can control the level of the scan, which affects the speed and the accuracy of the scan. To quickly check the fragmentation of an index, use the Limited option. You can obtain increased accuracy with only a moderate decrease in speed by using the Sample option, as in the previous example, which scans 1% of the pages. For the most accuracy, use the Detailed scan, which hits all the pages in an index. Just understand that the Detailed scan can have a major performance impact depending on the size of the table and index in question. If the index has fewer than 10,000 pages and you select the Sample mode, then the Detailed mode is used instead. This means that despite the choice made in the earlier query, the Detailed scan mode was used. The default mode is Limited.
By defining the different parameters, you can get fragmentation information on different sets of data. By removing the OBJECTID function in the earlier query and supplying a NULL value, the query would return information on all indexes within the database. Don’t get surprised by this and accidentally run a Detailed scan on all indexes. You can also specify the index you want information on or even the partition with a partitioned index.
avg_fragmentation_in_percent: This number represents the logical average fragmentation for indexes and heaps as a percentage. If the table is a heap and the mode is Sampled, then this value will be NULL. If average fragmentation is less than 10 to 20% and the table isn’t massive, fragmentation is unlikely to be an issue. If the index is between 20 and 40%, fragmentation might be an issue, but it can generally be helped by defragmenting the index through an index reorganization (more information on index reorganization and index rebuild is available in the “Fragmentation Resolutions” section). Large-scale fragmentation, usually greater than 40%, may require an index rebuild. Your system may have different requirements than these general numbers.
fragment_count: This number represents the number of fragments, or separated groups of pages, that make up the index. It’s a useful number to understand how the index is distributed, especially when compared to the pagecount value. fragmentcount is NULL when the sampling mode is Sampled. A large fragment count is an additional indication of storage fragmentation.
page_count: This number is a literal count of the number of index or data pages that make up the statistic. This number is a measure of size but can also help indicate fragmentation. If you know the size of the data or index, you can calculate how many rows can fit on a page. If you then correlate this to the number of rows in the table, you should get a number close to the pagecount value. If the pagecount value is considerably higher, you may be looking at a fragmentation issue. Refer to the avg_fragmentation_in_percent value for a precise measure.
avg_page_space_used_in_percent: To get an idea of the amount of space allocated within the pages of the index, use this number. This value is NULL when the sampling mode is Limited.
recordcount: Simply put, this is the number of records represented by the statistics. For indexes, this is the number of records within the current level of the B-Tree as represented from the scanning mode. (Detailed scans will show all levels of the B-Tree, not simply the leaf level.) For heaps, this number represents the records present, but this number may not correlate precisely to the number of rows in the table since a heap may have two records after an update and a page split.
avg_record_size_in_bytes: This number simply represents a useful measure for the amount of data stored within the index or heap record.
Retrieving the complete, detailed scan of the index
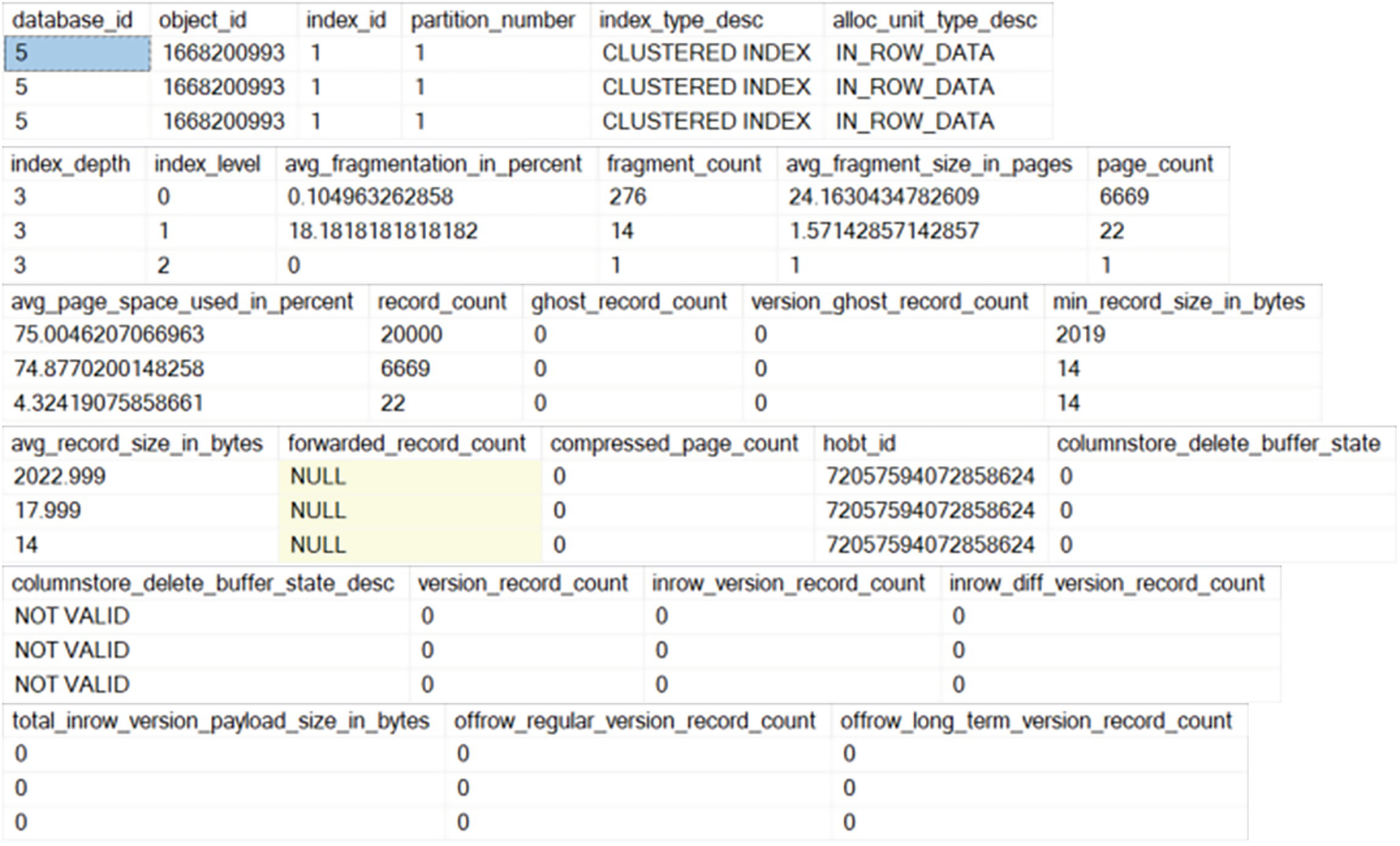
6 stacked tables have different numbers of columns and rows, with the first and fourth tables indicating highlighted entries. Table 1 on top has 6 columns and 3 rows with the first-row entry 5, under the first column, highlighted.
Complete results from sys.dm_db_index_physical_stats
We have three rows in Figure 12-8 because it represents the three levels of the current B-Tree index. There is a ton of extra data, including information on columnstore indexes. Yes, you can query here for columnstore as well, but you get more actionable information from the system view I provided. Most of this information isn’t necessary for your average look to see how fragmented an index is. Instead, a lot of this is used for additional, detailed, examination of the physical layout of the index.
Analyzing the Fragmentation of a Small Table
A small table or index with fewer than eight pages will be stored on mixed extents. That extent may have other indexes or tables within it. The output from sys.dm_db_index_physical_stats can be misleading. You’re likely to see fragmentation in a small index or table, but since it is a small table, you don’t need to worry about defragmenting it. In fact, while you can run an index rebuild on a small table, you may not see fragmentation get relieved in any way. For this reason, if you are dealing with a table or index below eight pages, don’t even try to defragment it.
Fragmentation Resolutions
Drop and recreate the index.
Recreate the index with the DROP_EXISTING clause.
Execute the ALTER INDEX REBUILD command.
Execute the ALTER INDEX REORGANIZE command.
Drop and Recreate the Index
Blocking: Recreating the index puts a high amount of overhead on the system, and it will cause blocking. Dropping and recreating the index blocks all other requests on the table (or on any other index on the table). It can also be blocked by other requests against the table.
Missing index: With the index dropped, and possibly being blocked, waiting to be recreated, queries against the table will not have that index available for use. You’ll also get a recompile of any query that was using the index.
Nonclustered index: If the index being dropped is a clustered index, then all the nonclustered indexes on the table will have to be rebuilt after the clustered index is dropped. They then have to be rebuilt again after the clustered index is recreated. This leads to further blocking and other problems such as statement recompiles.
Unique constraints: Indexes that are used to define a primary key or a unique constraint cannot be removed using the DROP INDEX statement. Also, both unique constraints and primary keys can be referred to by foreign key constraints. Prior to dropping the primary key, all foreign keys that reference the primary key would have to be removed first.
For all these reasons, dropping and recreating the index is a poor choice unless you can do it during scheduled down times.
Recreating the Index with the DROP_EXISTING Clause
Recreating the Person.EmailAddress primary key
You can use the DROP_EXISTING clause for both clustered and nonclustered indexes. You can even use it to convert a nonclustered index to a clustered index. You can’t do the reverse though and change a clustered index into a nonclustered index through DROP_EXISTING.
Blocking: Most of the very same blocking problems discussed in the DROP and CREATE section apply here.
Index with constraints: Unlike the first method, the CREATE INDEX statement with the DROP_EXISTING clause can be used to recreate indexes with constraints. If the constraint is a primary key or the unique constraint is associated with a foreign key, then failing to include the UNIQUE keyword in the CREATE statement will result in an error.
Execute the ALTER INDEX REBUILD Command
ALTER INDEX REBUILD rebuilds an index in one atomic step, just like CREATING INDEX with the DROP_EXISTING clause. Using the ALTER INDEX REBUILD command makes SQL Server allocate new pages and extents as it populates them with the data ordered logically and physically. However, unlike CREATE INDEX with the DROP_EXISTING clause, it allows the index to be rebuilt without forcing you to drop and recreate the constraints.
In a columnstore index, the REBUILD command will, in an offline fashion, completely rebuild the columnstore index. It will invoke the Tuple Mover to remove the deltastore, and it will rearrange the data to ensure effective compression.
With rowstore indexes, the preferred mechanism is ALTER INDEX REBUILD. For columnstore indexes, however, the preferred mechanism is ALTER INDEX REORGANIZE, covered in the next section.
Rebuilding an index will also compact any large object (LOB) pages associated with the table. You can choose not to do this by setting LOB_COMPACTION = OFF. You’ll need to experiment with this to determine if it’s needed in your system.
When you use the PAD_INDEX setting while creating an index, it determines how much free space to leave on the index intermediate pages, which can help you deal with page splits. This is taken into account during an index rebuild. New pages will be set back to the original values you determined at the time of index creation.
If you don’t specify otherwise, the default behavior is to defragment all indexes across all partitions. If you want to control the process, you just need to specify which partition you want to rebuild.
Rebuilding all indexes on a table
Blocking: Just like the other two techniques discussed, ALTER INDEX REBUILD introduces blocking to the system. It blocks all other queries trying to access the table (or any index on the table). It can also be blocked by other queries.
Transaction rollback: Since ALTER INDEX REBUILD is fully atomic in action, if it is stopped before completion, then all the defragmentation actions performed up to that point in time are lost.
You can run ALTER INDEX REBUILD using the ONLINE keyword, which will reduce the locking mechanisms but will increase the time involved in rebuilding the index.
Execute the ALTER INDEX REORGANIZE Command
For a rowstore index, ALTER INDEX REORGANIZE reduces the fragmentation of an index by rearranging the existing leaf pages to better match the logical order of the index. It compacts the rows within the pages, reducing internal fragmentation, and discards the resultant empty pages. When dealing with rowstore fragmentation, the REORGANIZE technique, while having the least overhead of all the techniques discussed, is also the most ineffectual. The amount of resources used to REORGANIZE an index is not as high as rebuilding it, but it is still a very expensive operation. I do not recommend using this command on your rowstore indexes.
For a columnstore index, ALTER INDEX REORGANIZE will ensure that the deltastore within the columnstore index gets cleaned out and that all the logical deletes are taken care of as actual, physical, deletes. It performs these actions while keeping the index online and accessible. You can also choose to force compression of all the row groups. This function is very similar to running ALTER INDEX REBUILD, but it keeps the index online and accessible during the process. This is why I recommend using ALTER INDEX REORGANIZE for columnstore indexes.
Another issue with rowstore indexes is that the REORGANIZE command uses a nonatomic method to clean up the index. As it processes the data, it requests a small number of locks for as short a period as possible. If it attempts to access a page that is locked, the process skips that page and never returns to it. While this makes REORGANIZE have a much lower overhead, it’s also part of what makes it so ineffectual.

A table has 6 columns and 1 row with headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes.
Fragmentation of the dbo.FragTest table
Using REORGANIZE on dbo.FragTest

A table has 6 columns and 1 row with headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes.
dbo.FragTest after running REORGANIZE
The fragmentation was reduced quite a lot, but you’ll notice that there is still some fragmentation. This would be worse if there were other queries running against the table at the same time.
If the index is highly fragmented, as this one was, ALTER INDEX REORGANIZE can take a lot longer than rebuilding the index. If an index spans multiple files, ALTER INDEX REORGANIZE doesn’t migrate pages between the files.
Deleting data in dbo.bigTransactionHistory

A table has 7 columns and 32 rows, with column headers table name, index name, row group i d, state description, total rows, deleted rows, and percent full. The row entry of big transaction history under the first column is highlighted.
Several rowgroups are missing 10%
Reorganizing the columnstore index dbo.bigTransactionHistory

A table has 7 columns and 47 rows, with column headers table name, index name, row group i d, state description, total rows, deleted rows, and percent full. The row entry of big transaction history under the first column is highlighted,
Results of REORGANIZE on dbo.bigTransactionHistory
There are quite a few things to note here. First, you’ll see that a bunch of rowgroups have switched from COMPRESSED to TOMBSTONE. That’s the result of the REORGANIZE command. You’ll see that some rowgroups are now COMPRESSED and at 100%, while a number of rowgroups that were at 89% deleted are now marked TOMBSTONE. That means that the data has been moved from them, and at some point in the future, those rowgroups will get removed from the index entirely.
Remember, this index is online and accessible during this operation, so the fact we didn’t get all the defragmentation possible is OK. You can still use ALTER INDEX REBUILD with a columnstore index if you choose.
REORGANIZE using row compression

A table has 7 columns and 31 rows, with column headers table name, index name, row group i d, state description, total rows, deleted rows, and percent full. The row entry of big transaction history under the first column is highlighted.
More defragmentation of the columnstore index
Characteristics of rowstore defragmentation techniques
Characteristics/Issues | Drop and Create Index | Create IndexwithDROP_EXISTING | ALTER INDEX REBUILD | ALTER INDEX REORGANIZE |
|---|---|---|---|---|
Rebuild nonclustered index on clustered index fragmentation | Twice | No | No | No |
Missing indexes | Yes | No | No | No |
Defragment index with constraints | Highly complex | Moderately complex | Easy | Easy |
Defragment multiple indexes together | No | No | Yes | Yes |
Concurrency with others | Low | Low | Medium, depending on concurrent user activity | High |
Intermediate cancellation | Dangers with no transaction | Progress lost | Progress lost | Progress preserved |
Degree of defragmentation | High | High | High | Moderate to low |
Apply new fill factor | Yes | Yes | Yes | No |
Statistics are updated | Yes | Yes | Yes | No |
Defragmentation and Partitions
Using ONLINE = ON
Setting the partition
Now you’re only rebuilding a single partition and using the ONLINE = ON to keep the index available.
Changing the lock priority
What this does is set the duration that the rebuild operation is willing to wait, in minutes. Then, it allows you to determine which processes get aborted in order to clear the system for the index rebuild. You can have it stop itself or the blocking process. The most interesting thing is that the waiting process is set to low priority, so it’s not using a lot of system resources, and any transactions that come in won’t be blocked by this process.
Significance of the Fill Factor
On rowstore indexes, the best performance comes when more rows are stored on a given page. More rows on a page mean fewer pages have to be read from disk and put into memory. This is one of the prime reasons for defragmenting indexes. However, when pages are full, especially in a high transaction OLTP system, you get more page splits, which hurts performance. Therefore, a balance between maximizing the number of rows on a page and avoiding page splits has to be maintained.
SQL Server allows you to control the amount of free space of an index by using the fill factor. If you know that there will be a lot of data manipulation and addition, you can pre-add free space to the pages of the index using the fill factor to help minimize the number of page splits. On the other hand, if the data is read-only, you can again use the fill factor to minimize the amount of free space.
The default fill factor is 0. When the fill factor is 0, the pages are packed to 100%. The fill factor for an index is applied only when the index is created. As keys are inserted and updated, the density of rows in the index eventually stabilizes within a narrow range. As you saw in the previous chapter’s sections on page splits caused by UPDATE and INSERT, when a page split occurs, generally half of the original page is moved to a new page, which happens irrespective of the fill factor used during the index creation.
Creating a test table
Adding a clustered index to the table

A table has 6 columns and 1 row with headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes.
Fill factor set to the default value of 0
Note that avg_page_space_used_in_percent is 100%, since the default fill factor allows the maximum number of rows to be compressed in a page. Since a page cannot contain a part row to fill the page fully, avg_page_space_used_in_percent will be often a little less than 100%, even with the default fill factor.
Altering the index using a fill factor

A table has 6 columns and 1 row with headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes.
Fill factor set to 75
Adding two more rows

A table has 6 columns and 1 row with headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes.
Fragmentation after new records
Adding one more row

A table has 6 columns and 1 row with headers, average fragmentation in percent, fragment count, page count, average page space used in percent, record count, and average record size in bytes.
The number of pages goes up
From the preceding example, you can see that the fill factor is applied when the index is created. But later, as the data is modified, it has no significance. Irrespective of the fill factor, whenever a page splits, the rows of the original page are distributed between two pages, and avg_page_space_used_in_percent settles accordingly. Therefore, if you use a nondefault fill factor, you should ensure that the fill factor is reapplied regularly to maintain its effect.
You can reapply a fill factor by recreating the index or by using ALTER INDEX REORGANIZE or ALTER INDEX REBUILD, as was shown. ALTER INDEX REORGANIZE takes the fill factor specified during the index creation into account. ALTER INDEX REBUILD also takes the original fill factor into account, but it allows a new fill factor to be specified, if required.
Without periodic maintenance of the fill factor, for both default and nondefault fill factor settings, avg_page_space_used_in_percent for an index (or a table) eventually settles within a narrow range.
One other option to consider is that you can create an index with PAD_INDEX. This will ensure that the intermediate pages are also using the fill factor. While the intermediate page splits are less costly overall than the rest, it’s still an impact that you can help to mitigate.
An argument can be made that rather than attempting to defragment indexes over and over again, with all the overhead that implies, you could be better off settling on a fill factor that allows for a fairly standard set of distribution across the pages in your indexes. Some people do use this method, sacrificing some read performance and disk space to avoid page splits and the associated issues in which they result. Testing on your own systems to both find the right fill factor and determine if that method works will be necessary.
Automatic Maintenance
As I said at the start of the chapter, more and more people are largely leaving fragmented indexes alone. They are either adjusting their fill factors, as we just finished discussing, or they’re carefully targeting exactly which indexes need to be defragmented and how frequently. Your system likely presents unique problems, and you’ll have to figure out if you intend to automatically maintain your indexes through a defragmentation process or not.
For a fully functional script that includes a large degree of capability, I strongly recommend using the Minion Reindex application located at http://bit.ly/2EGsmYU or Ola Hallengren’s scripts at http://bit.ly/JijaNI.
In addition to those scripts, you can use the maintenance plans built into SQL Server. However, I don’t recommend them because you surrender a lot of control for a little bit of ease of use. You’ll be much happier with the results you get from one of the sets of scripts recommended previously.
Summary
As you learned in this chapter, in a highly transactional database, page splits caused by INSERT and UPDATE statements may fragment the tables and indexes, increasing the cost of data retrieval. You can avoid these page splits by maintaining free spaces within the pages using the fill factor. Since the fill factor is applied only during index creation, you should reapply it at regular intervals to maintain its effectiveness. Data manipulation of columnstore indexes also leads to fragmentation and performance degradation. You can determine the amount of fragmentation in an index (or a table) using sys.dm_db_index_physical_stats for a rowstore index, or sys.column_store_row_groups for a columnstore index. Upon determining a high amount of fragmentation, you can use either ALTER INDEX REBUILD or ALTER INDEX REORGANIZE, depending on the required amount of defragmentation, database concurrency, and if you are dealing with a rowstore or columnstore index.
Defragmentation rearranges the data so that its physical order on the disk matches its logical order in the table/index, thus improving the performance of queries. However, unless the optimizer decides upon an effective execution plan for the query, query performance even after defragmentation can remain poor. Therefore, it is important to have the optimizer use efficient techniques to generate cost-effective execution plans.
In the next chapter, we’re going to discuss a pernicious problem and several ways to address it: bad parameter sniffing.