 A centralized logging solution
by Ravi Kant Soni, Rajesh RV, Amuthan Ganeshan
Spring: Developing Java Applications for the Enterprise
A centralized logging solution
by Ravi Kant Soni, Rajesh RV, Amuthan Ganeshan
Spring: Developing Java Applications for the Enterprise
- Spring: Developing Java Applications for the Enterprise
- Table of Contents
- Spring: Developing Java Applications for the Enterprise
- Spring: Developing Java Applications for the Enterprise
- Credits
- Preface
- 1. Module 1
- 1. Introducing the Spring Framework
- 2. Inversion of Control in Spring
- Understanding Inversion of Control
- Dependency Injection
- Bean definition inheritance
- Autowiring in Spring
- The bean's scope
- The Spring bean life cycle
- Exercise
- Summary
- 3. DAO and JDBC in Spring
- Overview of database
- The DAO design pattern
- JDBC without Spring
- Spring JDBC packages
- JDBC with Spring
- What is JdbcTemplate
- JDBC batch operation in Spring
- Calling a stored procedure
- Exercise
- Summary
- 4. Hibernate with Spring
- Why Object/Relational Mapping?
- Introducing ORM, O/RM, and O/R mapping
- Introducing Hibernate
- Integrating Hibernate with the Spring Framework
- Sample data model for example code
- Integrating Hibernate
- Required JARs for the Spring-Hibernate project
- Configuring Hibernate SessionFactory in Spring
- Annotated domain model class
- The Hibernate sessions
- Persistence layer – implement DAOs
- Service layer – implement services
- Directory structure of the application
- Running the application
- Hibernate Query Language
- Hibernate Criteria Query Language
- Exercise
- Summary
- 5. Spring Security
- 6. Spring Testing
- 7. Integrating JavaMail and JMS with Spring
- E-mail support in Spring
- Spring Java Messaging Service
- Exercise
- Summary
- A. Solutions to Exercises
- B. Setting up the Application Database – Apache Derby
- 2. Module 2
- 1. Configuring a Spring Development Environment
- 2. Spring MVC Architecture – Architecting Your Web Store
- Dispatcher servlet
- Understanding the Dispatcher servlet configuration
- Servlet mapping versus request mapping
- Web application context
- View resolvers
- Understanding the web application context configuration
- Model View Controller
- Overview of the Spring MVC request flow
- The web application architecture
- The Domain layer
- The Persistence layer
- The Service layer
- An overview of the web application architecture
- Summary
- 3. Control Your Store with Controllers
- 4. Working with Spring Tag Libraries
- 5. Working with View Resolver
- 6. Internalize Your Store with Interceptor
- 7. Incorporating Spring Security
- 8. Validate Your Products with a Validator
- 9. Give REST to Your Application with Ajax
- 10. Float Your Application with Web Flow
- 11. Template with Tiles
- 12. Testing Your Application
- A. Using the Gradle Build Tool
- B. Pop Quiz Answers
- Chapter 2, Spring MVC Architecture - Architecting Your Web Store
- Chapter 3, Control Your Store with Controllers
- Chapter 4, Working with Spring Tag Libraries
- Chapter 5, Working with View Resolver
- Chapter 6, Internalize Your Store with Interceptor
- Chapter 7, Incorporating Spring Security
- Chapter 10, Float Your Application with Web Flow
- Chapter 11, Template with Tiles
- 3. Module 3
- 1. Demystifying Microservices
- The evolution of microservices
- What are microservices?
- Microservices – the honeycomb analogy
- Principles of microservices
- Characteristics of microservices
- Microservices examples
- Microservices benefits
- Supports polyglot architecture
- Enabling experimentation and innovation
- Elastically and selectively scalable
- Allowing substitution
- Enabling to build organic systems
- Helping reducing technology debt
- Allowing the coexistence of different versions
- Supporting the building of self-organizing systems
- Supporting event-driven architecture
- Enabling DevOps
- Relationship with other architecture styles
- Relations with SOA
- Relations with Twelve-Factor apps
- A single code base
- Bundling dependencies
- Externalizing configurations
- Backing services are addressable
- Isolation between build, release, and run
- Stateless, shared nothing processes
- Exposing services through port bindings
- Concurrency to scale out
- Disposability with minimal overhead
- Development and production parity
- Externalizing logs
- Package admin processes
- Microservice use cases
- Summary
- 2. Building Microservices with Spring Boot
- Setting up a development environment
- Developing a RESTful service – the legacy approach
- Moving from traditional web applications to microservices
- Using Spring Boot to build RESTful microservices
- Getting started with Spring Boot
- Developing the Spring Boot microservice using the CLI
- Developing the Spring Boot Java microservice using STS
- Developing the Spring Boot microservice using Spring Initializr – the HATEOAS example
- What's next?
- The Spring Boot configuration
- Changing the default embedded web server
- Implementing Spring Boot security
- Enabling cross-origin access for microservices
- Implementing Spring Boot messaging
- Developing a comprehensive microservice example
- Spring Boot actuators
- Configuring application information
- Adding a custom health module
- Documenting microservices
- Summary
- 3. Applying Microservices Concepts
- Patterns and common design decisions
- Establishing appropriate microservice boundaries
- Designing communication styles
- Orchestration of microservices
- How many endpoints in a microservice?
- One microservice per VM or multiple?
- Rules engine – shared or embedded?
- Role of BPM and workflows
- Can microservices share data stores?
- Setting up transaction boundaries
- Service endpoint design consideration
- Handling shared libraries
- User interfaces in microservices
- Use of API gateways in microservices
- Use of ESB and iPaaS with microservices
- Service versioning considerations
- Design for cross origin
- Handling shared reference data
- Microservices and bulk operations
- Microservices challenges
- The microservices capability model
- Summary
- Patterns and common design decisions
- 4. Microservices Evolution – A Case Study
- Reviewing the microservices capability model
- Understanding the PSS application
- Death of the monolith
- Microservices to the rescue
- The business case
- Plan the evolution
- Migrate modules only if required
- Target architecture
- Target implementation view
- Summary
- 5. Scaling Microservices with Spring Cloud
- Reviewing microservices capabilities
- Reviewing BrownField's PSS implementation
- What is Spring Cloud?
- Setting up the environment for BrownField PSS
- Spring Cloud Config
- What's next?
- Setting up the Config server
- Understanding the Config server URL
- Handling configuration changes
- Spring Cloud Bus for propagating configuration changes
- Setting up high availability for the Config server
- Monitoring the Config server health
- Config server for configuration files
- Completing changes to use the Config server
- Feign as a declarative REST client
- Ribbon for load balancing
- Eureka for registration and discovery
- Zuul proxy as the API gateway
- Streams for reactive microservices
- Summarizing the BrownField PSS architecture
- Summary
- 6. Autoscaling Microservices
- 7. Logging and Monitoring Microservices
- 8. Containerizing Microservices with Docker
- Reviewing the microservice capability model
- Understanding the gaps in BrownField PSS microservices
- What are containers?
- The difference between VMs and containers
- The benefits of containers
- Microservices and containers
- Introduction to Docker
- Deploying microservices in Docker
- Running RabbitMQ on Docker
- Using the Docker registry
- Microservices on the cloud
- Running BrownField services on EC2
- Updating the life cycle manager
- The future of containerization – unikernels and hardened security
- Summary
- 9. Managing Dockerized Microservices with Mesos and Marathon
- Reviewing the microservice capability model
- The missing pieces
- Why cluster management is important
- What does cluster management do?
- Relationship with microservices
- Relationship with virtualization
- Cluster management solutions
- Cluster management with Mesos and Marathon
- Implementing Mesos and Marathon for BrownField microservices
- A place for the life cycle manager
- The technology metamodel
- Summary
- 10. The Microservices Development Life Cycle
- Reviewing the microservice capability model
- The new mantra of lean IT – DevOps
- Meeting the trio – microservices, DevOps, and cloud
- Practice points for microservices development
- Understanding business motivation and value
- Changing the mindset from project to product development
- Choosing a development philosophy
- Using the concept of Minimum Viable Product
- Overcoming the legacy hotspot
- Addressing challenges around databases
- Establishing self-organizing teams
- Building a self-service cloud
- Building a microservices ecosystem
- Defining a DevOps-style microservice life cycle process
- Automating the continuous delivery pipeline
- Development
- Continuous integration
- Automated testing
- Different candidate tests for automation
- Automated sanity tests
- Regression testing
- Automated functional testing
- Automated acceptance testing
- Performance testing
- Real user flow simulation or journey testing
- Automated security testing
- Exploratory testing
- A/B testing, canary testing, and blue-green deployments
- Other nonfunctional tests
- Testing in production
- Antifragility testing
- Target test environments
- Different candidate tests for automation
- Continuous deployment
- Monitoring and feedback
- Automated configuration management
- Microservices development governance, reference architectures, and libraries
- Summary
- 1. Demystifying Microservices
- Bibliography
- Index
In order to address the challenges stated earlier, traditional logging solutions require serious rethinking. The new logging solution, in addition to addressing the preceding challenges, is also expected to support the capabilities summarized here:
- The ability to collect all log messages and run analytics on top of the log messages
- The ability to correlate and track transactions end to end
- The ability to keep log information for longer time periods for trending and forecasting
- The ability to eliminate dependency on the local disk system
- The ability to aggregate log information coming from multiple sources such as network devices, operating system, microservices, and so on
The solution to these problems is to centrally store and analyze all log messages, irrespective of the source of log. The fundamental principle employed in the new logging solution is to detach log storage and processing from service execution environments. Big data solutions are better suited to storing and processing large numbers of log messages more effectively than storing and processing them in microservice execution environments.
In the centralized logging solution, log messages will be shipped from the execution environment to a central big data store. Log analysis and processing will be handled using big data solutions:
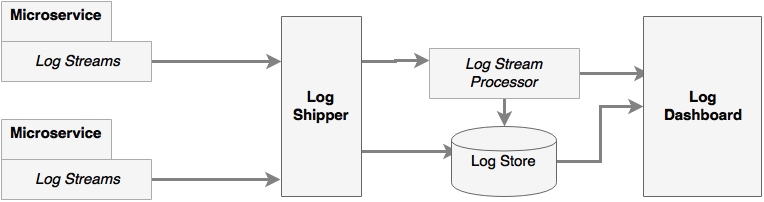
As shown in the preceding logical diagram, there are a number of components in the centralized logging solution, as follows:
- Log streams: These are streams of log messages coming out of source systems. The source system can be microservices, other applications, or even network devices. In typical Java-based systems, these are equivalent to streaming Log4j log messages.
- Log shippers: Log shippers are responsible for collecting the log messages coming from different sources or endpoints. The log shippers then send these messages to another set of endpoints, such as writing to a database, pushing to a dashboard, or sending it to stream-processing endpoint for further real-time processing.
- Log store: A log store is the place where all log messages are stored for real-time analysis, trending, and so on. Typically, a log store is a NoSQL database, such as HDFS, capable of handling large data volumes.
- Log stream processor: The log stream processor is capable of analyzing real-time log events for quick decision making. A stream processor takes actions such as sending information to a dashboard, sending alerts, and so on. In the case of self-healing systems, stream processors can even take actions to correct the problems.
- Log dashboard: A dashboard is a single pane of glass used to display log analysis results such as graphs and charts. These dashboards are meant for the operational and management staff.
The benefit of this centralized approach is that there is no local I/O or blocking disk writes. It also does not use the local machine's disk space. This architecture is fundamentally similar to the lambda architecture for big data processing.
Note
To read more on the Lambda architecture, go to http://lambda-architecture.net.
It is important to have in each log message a context, message, and correlation ID. The context typically has the timestamp, IP address, user information, process details (such as service, class, and functions), log type, classification, and so on. The message will be plain and simple free text information. The correlation ID is used to establish the link between service calls so that calls spanning microservices can be traced.
-
No Comment