
5 A study of personal health information posted online: using machine learning to validate the importance of the terms detected by MedDRA and SNOMED in revealing health informationin social media
Abstract: With the increasing amount of personal information that is shared on social networks, it is possible that the users might inadvertently reveal some personal health information. In this work, we show that personal health information can be detected and, if necessary, protected. We present empirical support for this hypothesis, and furthermore we show how two existing well-known electronic medical resources MedDRA and SNOMED help to detect personal health information (PHI) in messages retrieved from a social network site, MySpace. We introduce a new measure – risk factor of personal information – that assesses the likelihood that a term would reveal personal health information. We synthesize a profile of a potential PHI leak in a social network, and we demonstrate that this task benefits from the emphasis on the MedDRA and SNOMED terms. Our study findings are robust in detecting sentences and phrases that contain users’ personal health information.
5.1 Introduction
Studies of personal health information (PHI) posted on public communication hubs (e.g., blogs, forums, and online social networks) rely on four technologies: privacy preserving data mining; information leakage prevention; risk assessment; and social network analysis.
PHI relates to the physical or mental health of the individual, including information that consists of the health history of the individual’s family, and information about the healthcare provider (Ghazinour, Sokolova & Matwin 2013). We differentiate terms revealing PHI from medical terms that convey health information which is not necessarily personal (e.g., “smoking can cause lung cancer”), and terms that despite their appearance to be health-related have no medical meaning (e.g., “I have pain in my chest” vs. “I feel your pain”).
We believe that the online social networks’ growth and the general public involvement make social networks an excellent candidate for health information privacy research.
In this chapter we show empirically how personal health information is disclosed in social networks. Furthermore, we show how two existing electronic linguistic medical resources (i.e., MedDRA and SNOMED) help detect personal health information in messages retrieved from a social network.42 Both resources are well-established medical dictionaries used in biomedical text mining. We use machine learning to validate the importance of the terms detected by these two medical dictionaries in revealing health information and analyze the results of MedDRA (Medical Dictionary for Regulatory Activities) and SNOMED (Systematized Nomenclature of Medicine). We also evaluate our algorithm’s performance by manually finding sentences with PHI that were not detected by our algorithm. Our algorithm gives strong results in terms of the sentences that it detects for containing PHI and only an estimated false negative of 0.003 which is considered a great result for missing PHI compared to the state of the art of the false negative rate of 2.9–3.9 (Miles, Rodrigues & Sevdalis 2013).
In Section 2, we provide background material on the evolution and use of social networks and briefly discuss related work in the area of personal health information and this new form of online communication. Section 3 describes a brief introduction of the main technologies used for this type of research. Section 4 introduces current computational linguistic resources used in medical research. Section 5 explains our empirical study and Section 6 discusses our findings and introduces the Risk Factor of Personal Information and contributions of this study. Section 7 discusses how we use machine learning to validate our hypotheses. Section 8 concludes the paper and gives future research directions. Preliminary results of this work were published in (Ghazinour, Sokolova & Matwin 2013).
5.2 Related background
5.2.1 Personal health information in social networks
Social networks can be used for personal and/or professional purposes. Nowadays many healthcare providers are using social networks in their practices to interact with other colleagues, physicians and patients to exchange medical information, or to share their expertise and experiences with a broad audience (Keckley & Hoffman 2010). In addition to communicating with healthcare providers, the emergence of social networks, weblogs and other online technologies, has given people more opportunities to share their personal information (Gross & Acquisti 2005). Such sharing might include disclosing personal identifiable information (PII) (e.g., names, address, dates) and personal health information (PHI) (e.g., symptoms, treatments, medical care) among other factors of personal life.
Cyber-dangers in the healthcare sector generally fall into three categories: the exposure of private or sensitive data, manipulation of data, and loss of system integrity.
Websites such as Patientslikeme and Webmd, Facebook pages such as Managing Diabetes (see Fig. 5.1) and many other publically available pages give examples of where adversaries, or person’s whose access to one’s personal health information would compromise one’s financial and social status, can freely access these information.
It has been shown that 19%–28% of all Internet users participate in medical online forums, health-focused groups and communities and visit health-dedicated web sites (Renahy 2008; Balicco & Paganelli 2011). Recently Pew Research Center (Fox 2011) published their findings based on a national telephone survey conducted in August and September 2010 among 3001 adults in the United States. The complete methodology and results are appended to the Pew Research report.
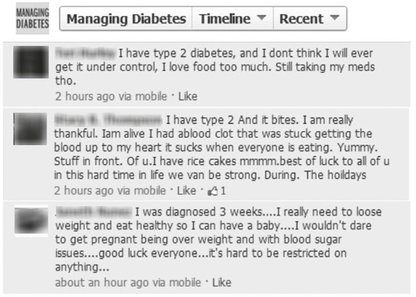
Fig. 5.1: Example of comments on a Facebook page which reveals personal health info.
The survey finds that of the 74% of adults who use the Internet:
- – 80% of internet users have looked online for information about any of 15 health topics such as a specific disease or treatment. This translates to 59% of all adults.
- – 34% of internet users, or 25% of adults, have read someone else’s commentary or experience about health or medical issues on an online news group, website, or blog.
- – 25% of internet users, or 19% of adults, have watched an online video about health or medical issues.
- – 24% of internet users, or 18% of adults, have consulted online reviews of particular drugs or medical treatments.
- – 18% of internet users, or 13% of adults, have gone online to find others who might have health concerns similar to theirs.
- – 16% of internet users, or 12% of adults, have consulted online rankings or reviews of doctors or other providers.
- – 15% of internet users, or 11% of adults, have consulted online rankings or reviews of hospitals or other medical facilities.
- – Of those who use social network sites (62% of adult internet users, or 46% of all adults):
- – 23% of social network site users, or 11% of adults, have followed their friends’ personal health experiences or updates on the site.
- – 17% of social network site users, or 8% of adults, have used social networking sites to remember or memorialize other people who suffered from a certain health condition.
- – 15% of social network site users, or 7% of adults, have gotten any health information on the sites.
A recent study (Li et al. 2011) had demonstrated a real-world example of cross-site information aggregation that resulted in disclosing PHI. A target patient has profiles on two online medical social networking sites. By comparing the attributes from both profiles, the adversary can link the two with high confidence. Furthermore, the attacker can use the attribute values to get more profiles of the target through searching the Web and other online public data sets. Medical information including lab test results was identified by aggregating and associating five profiles gathered by an attacker, including the patient’s full name, date of birth, spouse’s name, home address, home phone number, cell phone number, two email addresses, and occupation. In fact, using machine learning techniques and algorithms, the extracted health information could be aggregated with other personal information and do more harm than originally expected.
5.2.2 Protection of personal health information
When people share comments or some content related to their personal health information they may share very sensitive information which if combined with their personal identifiable information, can be a dangerous tool in wrong hands. For example, Knudsen (2013) states that 54% of data breaches in the healthcare sector were the result of theft. The numbers indicate that providers may be getting better at reducing inadvertent data loss, but criminals have continued to gain an advantage in forcing their way into the world of online communication. From a broader perspective, Harries and Yellowlees (2013) argue that in addition to bomb threat-type attacks, assaults on the public infrastructure – most notably water and power supplies – have the potential to cripple the healthcare system. Another likely target is that bastion of data: the electronic health record.
The success of healthcare providers that use social media and web-based systems is contingent on personal health information provided by individuals (see Fig. 5.2). Focused on the role of personal dispositions in disclosing health information on line, Bansal, Zahedi, and Gefen (2010) demonstrate that individuals’ intentions to disclose such information depends on trust and privacy concern, which are determined by personal disposition. Some of the factors that affect personal disposition are personality traits, one’s attitude toward information sensitivity, health status, prior privacy invasions, risk beliefs, and experience which act as intrinsic antecedents of trust. At the same time, uncontrolled access to health information could lead to privacy compromise, breaches of trust, and eventually harm the individuals. As discussed earlier, machine learning and data mining techniques could enable the adversary to gain more information and to do more harm than expected.

Fig. 5.2: Social media and more ways to share personal health information.
Zhang et al. (2011) propose a role prediction model to protect the electronic medical records (EMR) and privacy of the patients. As another example, Miller and Tucker (2009) studied the privacy protection state laws and technology limitations with respect to the electronic medical records.
However, protection of personal health information found in social network postings did not receive as much attention. In part, this is due to the lack of resources appropriate for detection and analysis of PHI in informally written messages posted by the users (Sokolova & Schramm 2011). The currently available resources and tools were designed to analyze PHI in more structured and contrived text of electronic health records (Yeniterzi 2010).
Bobicev et al. (2012) presented results of sentiment analysis in twitter messages that disclose personal health information. In these messages (tweets), users discuss ailment, treatment, medications, etc. They use the author-centric annotation model to label tweets as positive sentiments, negative sentiments or neutral. In another study on twitter data, Sokolova et al. (2013) introduced two semantic-based methods for mining personal health information in twitter. One method uses WordNet (Princeton University 2010) as a source of health-related knowledge, another, an ontology of personal relations. The authors compared their performance with a lexicon-based method that uses an ontology of health-related terms.
5.2.3 Previous work
Some studies analyzed personal health information disseminated in blogs written by healthcare professionals/doctors (Lagu et al. 2008). However, these studies did not analyze large volumes of texts. Thus, the published results may not have sufficient generalization power, (Silverman 2008; Kennedy 2012). Malik and Coulson (2010) manually analyze 3500 messages posted on seven sub-boards of a UK peer-moderated online infertility support group. The results of this study show that online support groups can provide a unique and valuable avenue through which healthcare professionals can learn more about the needs and experiences of patients.
In a recent study, Carroll, Koeling and Puri (2012) described experiments in the use of distributional similarity for acquiring lexical information from notes typed by primary care physicians who were general practitioners. They also present a novel approach to lexical acquisition from “sensitive” text, which does not require the text to be manually anonymized. This enables the use of much larger datasets compared to the situation where the sentences need to be manually anonymized and large datasets cannot be examined.
There is a considerable body of work that compares the practices of two popular social networking sites (Facebook & MySpace) related to trust and privacy concerns of their users, as well as self-disclosure of personal information and the development of new relationships (Dwyer, Hiltz & Passerini 2007). Scanfeld, Scanfeld and Larson (2010) studied the dissemination of health information through social networks. The authors reviewed Twitter status updates mentioning antibiotic(s) to determine overarching categories and explore evidence of misunderstanding or misuse of antibiotics. Most of the work uses only in-house lists of medical terms (Sokolova & Schramm 2011), each built for specific purposes, but they do not use existing electronic resources of medical terms designed for analysis of text from biomedical domain. However, those resources are general and in need of evaluation with respect to their applicability to the PHI extraction from social networks. The presented work fills this gap.
In most of the above cases, the authors analyze text manually and do not use automated text analysis. In contrast, in this work which we describe below, we want to develop an automated method for mining and analysis of personal health information.
5.3 Technology
5.3.1 Data mining
Data mining consists of building models to detect the patterns residing in data which allows us to classify and categorize data and extract more information that is buried in the data (Witten, Frank & Hall 2011). For example, find the co-relation between breast cancer and genetics of the patients, search for customers who are more interested in buying a product, and so forth. In order to analyze a problem, data mining extracts previous information and uses it to find solutions to the problem.
Data mining analyzes data stored in data repositories and databases. For example, it is possible that data originates from a business environment that deals with information regarding a product, which helps management determine different market strategies such as which customers are more interested to buy a product based on their shopping history. This data can be used to contrast and compare different enterprises. Using data mining, a company can have real-time analysis of their day-to-day business activity, advertisement, promotion and sales purposes, as well as competing with the rival companies.
5.3.2 Machine learning
Machine learning can be considered as science for the design of computational methods using experience to improve their performance (Mitchell 1997). The algorithms in machine learning on large-scale problems, make accurate predictions, and address a variety of learning problems (e.g., classification, aggression, clustering of data). Examples of such methods are: K-Nearest Neighbor (e.g., What are the K members of a group that have similar shopping habits, time of shopping and items that they purchase), Naïve Bayes (e.g., classify whether if a certain product will be purchased or not, based on its price, brand name and so on), association rule mining (e.g., from lists of purchases in a grocery store, find which items are bought together by the customers, e.g., most of the customers that buy milk, buy cookies).
We use machine learning in many domains including the following examples:
- – Text: Text and document classification, spam detection, morphological analysis, statistical parsing, fraud detection (credit card, telephone);
- – Audio/Visual: Optical character recognition, part-of-speech tagging, speech recognition, speech synthesis, speaker verification, image recognition, face recognition;
- – Other: Network intrusion, games, unassisted control of a vehicle (robots, navigation), medical diagnosis and many more.
In general, machine learning answers the questions such as: What can be learned, and under what conditions? What learning guarantees can be given? What is the algorithmic complexity?
5.3.3 Information extraction
Extracting structured information from an unstructured or semi-structured machine-readable document is referred to as information extraction (IE), which is mostly done on natural language texts (Mitkov 2003). Examples of information extraction from social media can be discovering the general public opinion about a movie or a president’s speech through comments and posts on social networks and weblogs.
The emergence of the user written web content created a greater need for the development of IE systems to assist people in dealing with the large amount of online data (Sokolova & Lapalme 2011). These systems should be scalable, flexible, and efficiently maintained.
5.3.4 Natural language processing
In computer science natural language processing (NLP) is referred to as a subsection of artificial intelligence and linguistics that addresses the interactions between computers and natural (human) languages. One of the main challenges in NLP is to enable computers to derive and understand meaning expressed by humans in text.
Modern NLP algorithms are based on machine learning methods. The idea of using machine learning is different from previous approaches to language processing, which involved direct hand coding of large sets of rules. That is, machine learning requires general learning algorithms to automatically learn such rules through the analysis of large input data also known as corpus. For example, in a sentence like Boeing is located in Seattle, a relationship between Boeing, tagged as a company, and Seattle, tagged as a location is derived and the system learns that this sentence is discussing a company-location relationship. These corpora are generally hand-annotated with the correct values to be learned (Jurafsky and Martin 2008), e.g., British National Corpus (BNC)43 and Penn Treebank44.
For example, NLP tasks have used different classes of machine learning algorithms, which require the input of large set of “features” (e.g., sentence length, word count, punctuation and characters) generated from the corpus. Common “if-then” rules were used in the algorithms, such as decision trees. Gradually, research has tended to focus more on models, which make soft, probabilistic decisions based on attaching real-valued weights to each input feature. These models can express more than one possible solution, which are more flexible and reliable (Manning & Schütze 2003).
5.4 Electronic resources of medical terminology
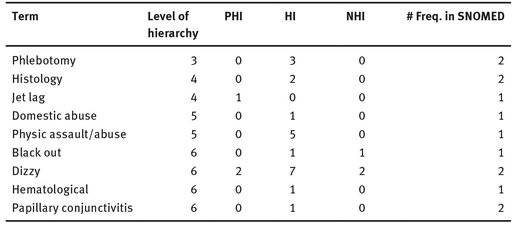
Biomedical information extraction and text classification have a successful history of method and tool development, including deployed information retrieval systems, knowledge resources and ontologies (Yu 2006). However, these resources are designed to analyze knowledge-rich biomedical literature. For example, GENIA is built for the microbiology domain. Its categories include DNA-METABOLISM, protein metabolism, and cellular process. Another resource, Medical Subjects Heading (MeSH), is a controlled vocabulary thesaurus, whose terms are informative to experts but might not be used by the general public. The Medical Entities Dictionary (MED) is an ontology containing approximately 60,000 concepts, 208,000 synonyms, and 84,000 hierarchies. Table 5.1 shows a sample of the MedDRA hierarchy. It shows Biliary disorders as one of the main categories under which there are many sub-categories including Biliary neoplasms. Furthermore, Biliary neoplasms can have a sub-category called Biliary neoplasms benign. In this hierarchy each sub-category gives more detailed information than its super category. This powerful lexical and knowledge resource is designed with medical research vocabulary in mind. The Unified Medical Language System (UMLS) has 135 semantic types and 54 relations that include organisms, anatomical structures, biological functions, chemicals, etc. Specialized ontology BioCaster was built for surveillance of traditional media. It helps to find disease outbreaks and predict possible epidemic threats. All these sources would require considerable modification before they could be used for analysis of messages posted on public Web forums.
5.4.1 MedDRA and its use in text data mining
The Medical Dictionary for Regulatory Activities (MedDRA) is an international medical classification for medical terms and drugs terminology used by medical professionals and industries. The standard set of MedDRA terms enables these users to exchange and analyze their medical data in a unified way. MedDRA has a hierarchical structure with 83 main categories in which some have up to five levels of sub-categories. MedDRA contains more than 11,400 nodes which are instances of medical terms, symptoms, etc.
Tab. 5.1: A sample of the MedDRA hierarchy and their labels.

Since its appearance nearly a decade ago, MedDRA has been used by the research community to analyze the medical records provided or collected by healthcare professionals: e.g., McLernon et al. (2010) use MedDRA in their study to evaluate patient reporting of adverse drug reactions to the UK “Yellow Card Scheme.” In another study, Star et al. (2011) use MedDRA to group adverse reactions and drugs derived from reports were extracted from the World Health Organization (WHO) global ICSR database that originated from 97 countries from 1995 until February 2010.
The above examples show that the corpus on which MedDRA tested is generally derived from patients’ medical history or other medical descriptions found in the structured medical documents that are collected or disclosed by healthcare professionals. Content and context of those documents differ considerably from those of messages written by social network users. In our study, we aim to evaluate the usefulness of MedDRA in detection of PHI disclosed on social networks.
5.4.2 SNOMED and its use in text data mining
Another internationally recognized classification scheme is the Systematized Nomenclature of Medicine Clinical Terms (SNOMED CT) maintained by the International Health Terminology Standards Development Organization. Although SNOMED is considered the most comprehensive clinical healthcare terminology classification system, it is primarily used in standardization of electronic medical records (Campbell, Xu & Wah Fung 2011).
Medical terms in SNOMED are called concepts. A concept is indicative of a particular meaning. Each concept has a unique id that with which it is referred. A concept has a description which is a string used to represent a concept. It is used to explain what the concept is about. Relationship is a tuple of (object – attribute – value) connecting two concepts through an attribute.
Same as MedDRA, SNOMED has also a hierarchical structure. The root node, SNOMED Concept, has 19 direct children which Fig. 5.3 shows 10 of them from Clinical finding to Record artifact. As illustrated in Fig. 5.3, one of the nodes, procedure, has 27 branches including but not limited to, administrative procedures (e.g., medical records transfer), education procedures (e.g., low salt diet education) and other procedures.
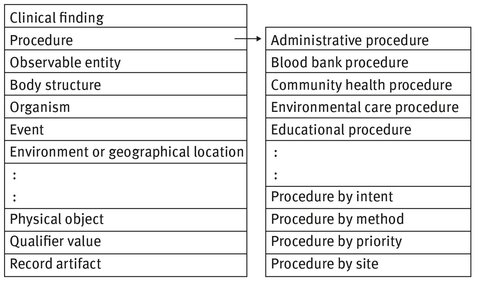
Fig. 5.3: A sample of the SNOMED hierarchy.
Among 353,154 instances of all 19 main branches we decided to only sub-select procedures and clinical findings (that encompasses diseases and disorders). These branches have more medical meanings than for instance the Environment or geographical location node which covers name of the cities, provinces/states, etc. The clinical findings node has 29,724 sub-nodes (19,349 diseases and disorders, 10,375 findings) and the node procedure has 15,078 sub-nodes. So in total we have selected 44,802 nodes out of 353,154.
Table 5.2 depicts a brief comparison between MedDRA and SNOMED hierarchical structure. It shows that SNOMED covers a larger set of terms and has deeper hierarchical levels compared to MedDRA.
Tab. 5.2: MedDRA and SNOMED hierarchical structure.

5.4.3 Benefits of using MedDRA and SNOMED
We believe referring to MedDRA and SNOMED as well-funded, well-studied and reliable sources has two benefits:
- We introduce a field of new text applications (the posts, weblogs and other information sources directly written by individuals) which extend the use for MedDRA and SNOMED. These medical dictionaries were previously used only for the health information collected by healthcare professionals.
- Since MedDRA and SNOMED have well-formed hierarchical structures, by examining them against the posts on the social network site, we should be able to identify which terms and branches in the MedDRA and SNOMED are used to identify PHI and which branches are not, and thus can be pruned. These operations should result in a more concise and practical dictionary that can be used on detecting PHI disclosed in diverse textual environments.
5.5 Empirical study
In this research, we examined the amount of PHI disclosed by individuals on an online social network site, MySpace. Unlike previous research work, introduced in Section 2, the presence of PHI was detected through the use of the medical terminologies of MedDRA and SNOMED.
In our empirical studies, we examined posts and comments publicly available on MySpace. We sorted and categorized the terms used in both MedDRA and SNOMED, and found in MySpace, based on the frequency of their use and whether they reveal PHI or not. We also studied the hierarchy branches that are used and the possibility of pruning the unused branches (if any exists). Based on the hierarchical structures of MedDRA and SNOMED, the deeper we traversed down the branches, the more explicit the medical terms become and the harder the pruning phase is.
5.5.1 MySpace data
MySpace is an online social networking site that people can share their thoughts, photos and other information on their profile or general bulletin, i.e., posts posted on to a “bulletin board” for everyone on a MySpace user’s friends list to see. There have been several research publications on use of MySpace data in text data mining, but none of them analyzed disclosure of personal health information in posted messages (Grace et al. 2007; Shani, Chickering & Meek 2008).
We obtained the MySpace data set from the repository of training and test data released by the workshop Content Analysis for the Web 2.0 (CAW 2009). The data creators stated that those datasets intended to comprehend a representative sample of what can be found in web 2.0. Our corpus was collected from more than 11,800 posts on MySpace. In the text pre-processing phase we eliminated numbers, prepositions and stop words. We also performed stemming which converted all the words to their stems (e.g., hospital, hospitals and hospitalized are treated the same).
5.5.2 Data annotation
We manually reviewed 11,800 posts on MySpace to see to what extent those medical terms are actually revealing personal health information on MySpace. The terms were categorized into three groups:
- – PHI: terms revealing personal health information.
- – HI: medical terms that address health information (but not necessarily personal).
- – NHI: terms with non-medical meaning.
To clarify this let us see the following examples:
The word lung which assumed to be a medical term appears in the following three sentences we got from our MySpace corpus: “… they are promoting cancer awareness particularly lung cancer …” which is a medical term but does not reveal any personal health information. “… I had a rare condition and half of my lung had to be removed…” this is clearly a privacy breach and “… I saw a guy chasing someone and screaming at the top of his lungs …” which carries no medical value. In this manner, we have manually analyzed and performed manual labelling based on the annotator’s judgment whether the post reveals information about the person who wrote it, or discloses information about other individuals that make them identifiable.
We acknowledge that there might be cases where the person might be identified with a high probability in posts that mention “… my aunt …, my roommate.” For simplicity in this research we categorize those posts as HI where the post has medical values but does not reveal a PHI. Table 5.3 shows some more examples of PHI, HI and NHI.
Tab. 5.3: Examples of terms found on MySpace which are PHI, HI and NHI.

5.5.3 MedDRA results
To assess MedDRA’s usability for PHI detection, we performed two major steps:
- We labeled the MedDRA hierarchy in a way that the label of each node reflects to which branch it belongs. The result is corpus-independent.
- We did uni-gram and bi-gram (a contiguous sequence of one term from a given sequence of text or speech) comparisons between the terms that appear in MySpace and the words detected by MedDRA. The result is corpus-dependent.
After the execution of the step 1, MedDRA’s main categories are labeled from 1 to 83 and for those with consequent sub-categories, the main category number is followed by a hyphen (-) and the sub-category’s number [e.g., Biliary disorders (10) and its sub categories Biliary neoplasms (10-1) and Biliary neoplasms benign (10-1-1)].
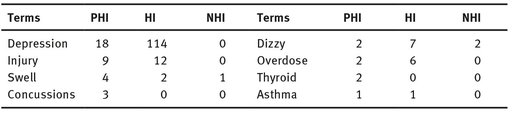
After the execution of the step 2, there are 87 terms that appear both in MedDRA and in the MySpace corpus. A subset of them is illustrated in Tab. 5.4.
There are also identical terms that appear under different categories and increase the ambiguity of the term. For instance, nausea appears under categories acute pancreatitis and in gastrointestinal nonspecific symptoms and therapeutic procedures, so when nausea appears in a post, it is not initially clear which category of the MedDRA hierarchy has been used, and the text needs further semantic processing.
Tab. 5.4: A subset of terms detected by MedDRA that appear in MySpace.
5.5.4 SNOMED results
SNOMED leaves are very specific and have many more medical terms compared to MedDRA. Our manual analysis has shown that the general public uses less technical, and therefore more general, terms when they discuss personal health and medical conditions. Hence, we expect that SNOMED’s less granular (defined as less specific in identifying information) terms appear more often in MySpace data than their more specific counterparts, which have higher granularity.
The structure of SNOMED is organized as follows: The root node has 19 sub-nodes. One of the sub-nodes is procedure that itself has 27 sub-nodes. One of those sub-nodes is called procedure by method which has 134 sub-nodes. Counseling is one of those 134 sub-nodes and itself has 123 sub-nodes. Another node among the 134 sub-nodes is cardiac pacing that has 12 sub-nodes which are mostly leaves of the hierarchy.
In extreme cases there might be nodes that are located 11 levels deep down the hierarchy. For example the following shows the hierarchy associated with the node hermaphroditism. Each “>” symbol can be interpreted as “is a …”:
Hermaphroditism > Disorder of endocrine gonad > Disorder of reproductive system > Disorder of the genitourinary system > Disorder of pelvic region > Finding of pelvic structure > Finding of trunk structure > Finding of body region > Finding by site > Clinical finding > SNOMED Concept
It is cumbersome to understand how many of the 44,802 nodes that we have sub-selected from SNOMED are leaves and how many are intermediate nodes; however, 66 nodes out of 44,802 appeared in MySpace, of which nine were leaves (see Tab. 5.5).
Tab. 5.5: A subset of terms detected by SNOMED that appear in MySpace.
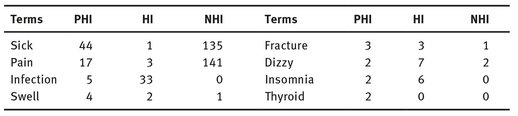
Table 5.6 shows some terms. The number of times the term appears in SNOMED, and whether it is a leaf in the hierarchy. We can see that except jet lag and dizzy, the other terms do not reveal PHI. Even in the example dizzy, the appearance as PHI compared to the number of times they appear as HI and NHI is trivial.
This result indicates that although SNOMED has a deep hierarchical structure, one should not traverse all the nodes and branches to reach leaf nodes to be able to detect PHI terms. In contrast, we hypothesize that branches can be pruned to reduce the PHI detection time and still achieve an acceptable result. We leave this as potential future work.
5.6 Risk factor of personal information
5.6.1 Introducing RFPI
Due to the semantic ambiguity of the terms we had to manually examine the given context to see whether the terms were used for describing medical concepts or not. For instance, the term adult in the post “… today young people indifferent to the adult world …” has no medical meaning.
We aimed to find whether the terms were used for revealing PHI or HI. Although some terms like surgery and asthma have strictly (or with high certainty) medical meaning, some terms may convey different meanings depending on where or how they are used. For instance, the word heart has two different meanings in “… heart attack …” and “… follow your own heart … .”
Tab. 5.6: Terms of MySpace detected by SNOMED leaf nodes.
We also measured the ratio of the number of times that the term was used in MySpace and the number of times that revealed PHI. We called the ratio the Risk Factor of Personal Information (RFPI). In other words, for a term t, RFPIt is:
RFPIt = number of times t reveals PHI/number of times t appears in a text
Table 5.7 illustrates the top RFPI terms from MedDRA and SNOMED that often reveal PHI. There is an overlap between the top most used terms of MedDRA and SNOMED with highest RFPI. These are terms that prone to the number of times they appear in data (concussions, thyroid, hypothermia, swell, ulcer and fracture).
Furthermore, according to our studies although the words sick and pain appear numerous times and reveal personal health information their RFPI is relatively low and might not be as privacy-revealing as words like fracture or thyroid.
For example sick in the sentence “… I am sick and tired of your attitude …” or “… the way people were treated made me sick …” clearly belong to the NHI group and does not carry any medical information. Or in the case of the term pain, the sentences “… having a high-school next to your house is going to be a pain …” or “… I totally feel your pain! …” belong to NHI group as well.
5.6.2 Results from MedDRA and SNOMED
In total, we found 127 terms that appear in MySpace and in both dictionaries. 87 terms in MySpace are captured by MedDRA and 66 terms are captured by SNOMED. There are 26 common terms that appear in both dictionaries. Although SNOMED is a larger dataset compared to MedDRA, since its terms are more specific, fewer terms are appeared in SNOMED. Thus, we consider MedDRA to be more useful for PHI detection.
Tab. 5.7: Top terms detected by MedDRA and SNOMED that have highest RFPI.
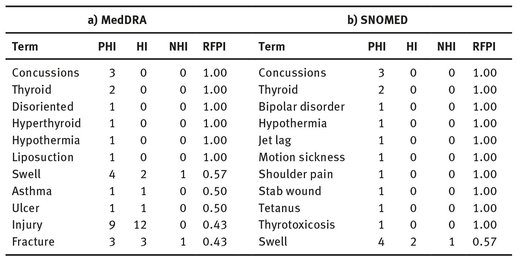
Figure 5.4 illustrates the number of sentences (not terms) in MySpace for each category of PHI, HI and NHI that are detected by MedDRA, SNOMED and the union of them. Table 5.8 demonstrates that although SNOMED detects more PHI terms compared to MedDRA, since it also detects more NHI terms (false positive) as well, it is less useful compared to MedDRA. In addition, the summation of both PHI and HI in MedDRA is greater than its equivalent in SNOMED which is another reason why MedDRA seems more useful than SNOMED.
In brief, since MedDRA covers a broader and more general area it detects more HI than SNOMED. In contrast, although SNOMED detects slightly more PHI and HI, it is less trustable than MedDRA since it also detects far more NHI. Hence, the precision of detection is much lower.
Although there are not many sentences (nine sentences out of almost 1000 sentences) that reveal PHI as a result of engaging in a conversation that initially contained HI, there is always the possibility that existence of HI sentences is more likely to result in PHI detection compared to the sentences that contain NHI.
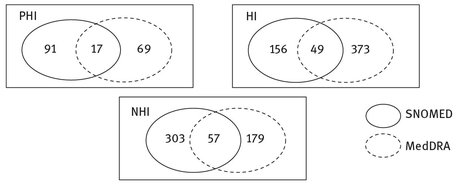
Fig. 5.4: HI, PHI and NHI sentences detected by each dictionary and their intersection.
Tab. 5.8: Percentage of the sentences that are detected by these two dictionaries in each group.
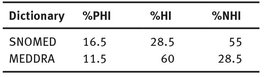
As shown in Fig. 5.4, the amount of terms that are detected by both MedDRA and SNOMED (their intersection in the Venn diagram) is not impressive and that is why these two dictionaries cannot be used interchangeably.
5.6.3 Challenges in detecting PHI
We wanted to estimate how many PHI sentences our method could miss. To make a rigorous estimate we decided on a manual evaluation. For this purpose, we used the Linux command:
shuf –n input | head –n 1000 > output
We tested the command by repeating it three times to make sure each time it produces a completely random list of 1000 comments in the corpus. On the fourth try, we extracted 1000 sentences and manually assessed them. We have seen that our algorithm missed only the following three PHI comments:
- – “ok i’m off to bed before this vicadine wears off yay head spinning sleep.
- – never come back i’m bored i took some vicadin so i should be goin to sleep soon. yay!
- – nope! 2 blurry of an photo. she may have an cold sore on her lips.”
In the first two comments the name of the drug was misspelled (the correct spelling is Vicodin) and could not be detected by either MedDRA or SNOMED.
Regarding the third sentence, PHI can be expressed in a descriptive way. Functionally, in PHI description, some words cannot be modified, whereas associated words can be changed (Sokolova & Lapalme 2011). Those words are called descriptors. For instance, in hot water, boiling water and cold water, the word water represents the target concept, thus cannot be modified. The accompanying words hot, boiling, and cold can change depending on the context. In our case, the word sore in MedDRA is used as a modifier, such as sore throat, whereas in the term cold sore it is used as a descriptor. Hence, in the third sentence, the term cold sore was used that could not be detected by our medical dictionaries.
We found three sentences in one thousand comments that contained some sort of PHI and were not detected by our algorithm. Our algorithm gives very impressive result in terms of sentences that it detects that have PHI and only an estimated false negative of 0.003 which is considered a great result for missing PHI compared to the state of the art false negative rate of 2.9–3.9 (Miles, Rodrigues & Sevdalis 2013). The obtained number missed PHI enhances our previous results reported in (Ghazinour, Sokolova & Matwin 2013).
5.7 Learning the profile of PHI disclosure
We approach the task of detecting PHI leaks as acquiring a profile of what “language” is characteristic of this phenomenon which occurs in posts on health-related social networks. This can be achieved if a profile of the occurrence of this phenomenon is acquired. A machine learning, or more specifically text classification, is a natural technique to perform this acquisition of a profile. We studied the classification of the sentences under two categories of PHI-HI and NHI using Machine Learning methods.
Hypothesis. Focusing on terms from MedDRA and SNOMERD results in a better performing profiling than the straightforward method of a bag of words.
Experiment. Our experiment consists of the following two parts:
5.7.1 Part I – Standard bag of words model
We vectorized each of the 976 sentence detected by the two medical dictionaries. In these sentences, there are 1865 distinct terms. After removing the words with the same roots and deleting the symbols and numerical terms, 1669 unique words were identified. Next, generating a standard Bag of Words document representation and the sentences are vectorized (0 for not existing and 1 for existing). Hence, we have vectors of 1669 attributes that are either 0 or 1 and one more attribute which is the label of the sentence, the privacy class (0 = NHI, 1 = PHI-HI).
After each vector is labeled accordingly to be either PHI-HI or NHI, we perform a bi-classification and train our model with 976 sentences of which 425 are labeled as NHI and 551 are labeled as PHI-HI.
We used two classification methods used most often in text classification, i.e., Naive Bayes (NB), KNN (IBK) in Weka based on the privacy class (0 = NHI, 1 = PHI-HI) shown in the left column of Tab. 5.9. Hence, our training data set would be the sentences with binary values of the terms appearing in them or not. Due to our small set data, we performed five by two cross-validations. In each fold, our collected data set were randomly partitioned into two equal-sized sets in which one was the training set which was tested on the other set. Then we calculated the average and variance of those five iterations for the privacy class. Table 9 shows the results of this 5×2-fold cross validations.
Tab. 5.9: Two classification methods on the privacy class with and without medical terms.
| Classification | Privacy class (Part I) | Privacy class (Part II) | |
|---|---|---|---|
| NB | Correctly classified% | 75.51 | 85.75 |
| Mean absolute error | 0.25 | 0.15 | |
| KNN | Correctly classified% | 74.48 | 86.88 |
| (k=2) | Mean absolute error | 0.27 | 0.13 |
5.7.2 Part II – Special treatment for medical terms
We took the vectors resulting from Part I and focused on the terms belong to the following three groups by weighting them stronger in the bag of words than the remaining words.
- a) List of pronouns or possessive pronouns, members/relatives (e.g., I, my, his, her, their, brother, sister, father, mother, spouse, wife, husband, ex-husband, partner, boyfriend, girlfriend, etc.).
- b) Medical term detected by MedDRA and SNOMED.
- c) Other medical terms that their existence in a sentence may result in a sentence to be a PHI or HI. Terms such as hospital, clinic, insurance, surgery, etc.
For group (a) and group (c) we associate weight 2 (one level more than the regular terms that are presented by 1 as an indication that the terms exist in the sentence). For group (b) which are the terms detected by the SNOMED and MEDRA and have higher value for us we associate weight with value of 3. So unlike the vectors in Part I which consist of 0s or 1s, in this part we have vectors of 0s, 1s, 2s and 3s. In fact, the values for weights are arbitrary and finding the right weights would be the task of optimization of the risk factor. We ran the experiment with values of 0s, 1s, 2s and 4s and we got the same results shown in Tab. 5.9.
Next, we used the same two classification methods and performed five by two cross-validations. The results are shown in Tab. 5.9 in the right column. Comparing the results from Part I and II show that there is an almost 10% improvement in detecting sentences that reveal health information using the terms detected by MedDRA and SNOMED which confirms our hypothesis. The results are statistically significant (Dietterich 1998) with the p-value of 0.95.
5.8 Conclusion and future work
In this research work, we studied personal health information (PHI) by means of data mining, machine learning, natural language processing and information extraction. We showed that such models can detect and, when necessary, protect personal health information that might be unknowingly revealed by users of social networks. In this work we presented empirical support for this hypothesis, and furthermore we showed how two existing electronic medical resources MedDRA and SNOMED helped to detect personal health information in messages retrieved from a social network. Our algorithm gives robust results in terms of sentences and phrases that it detects as containing PHI and only an estimated false negative of 0.003. This is considered a valid and reliable result for missing PHI compared to the state of the art false negative rate of 2.9–3.9 (Miles, Rodrigues & Sevdalis 2013). Our current work enhances the results reported in (Ghazinour, Sokolova & Matwin 2013).
We showed how existing medical dictionaries can be used to identify PHI. We labeled the MedDRA and SNOMED hierarchy in a way that the label of each node reflects which branch it belongs. Next, we did uni-gram and bi-gram comparisons between the terms that appear on the MySpace corpus and the words that appear on MedDRA and SNOMED. Comparing the number of terms captured by these two medical dictionaries, it suggests that MedDRA covers more general terms and seems more useful than SNOMED that has more detailed and descriptive nodes. Performing a bi-classification on the vectors resulted from the sentences labeled as PHI-HI and NHI support our hypotheses. We used two common classification methods to validate our hypothesis and analyse the results of MedDRA and SNOMED. Our experiments demonstrated that using the terms detected by MedDRA and SNOMED helps us to better identify sentences in which people reveal health information.
Future directions include analysis of words which tend to correlate but not perfectly match the terms contained in medical dictionaries (e.g., in the sentence “I had my bell rung in the hockey game last night”: the phrase “bell rung” which means a nasty blow suffered to the head during a sports game that may indicate a concussion). Researchers can use methods such as Latent Dirichlet Allocation (LDA) in such instances. Furthermore, testing our model (which we based on the MySpace social media network) on different posts found on other social networks, such as Facebook or Twitter, would be a good research experiment. We would want to compare the terms that appear in MedDRA and SNOMED and evaluate their RFPI values in analyzing the health-related posts of these other social networks.
An interesting project would be to develop a user interface or an application that could be plugged into the current social networks such as MySpace, Facebook and Twitter or appear on the user’s smartphone or tablet that would essentially warn the user about revealing PHI when they use these potentially privacy-violating words that we have introduced in this research.
Another potential future work could investigate use of more advanced NLP tools, beyond the lexical level, to identify some of the semantic structures that contain terms that might lead to health-related privacy violations.
Acknowledgment
The authors thank NSERC for the funding of the project and anonymous reviewers for many helpful comments.
References
Balicco, L. & Paganelli, C. (2011) Access to Health Information: Going From Professional to Public Practices Information Systems and Economic Intelligence: 4th Int. Conference - SIIE’2011.
Bansal, G., Zahedi, F. M. & Gefen, D. (2010) ‘The impact of personal dispositions on information sensitivity, privacy concern and trust in disclosing health information online’, Decis Support Syst, 49(2):138–150.
Bobicev, V., Sokolova, M., Jafer, Y. & Schramm, D. (2012) Learning Sentiments from Tweets with Personal Health Information. Canadian Conference on AI, pp. 37–48.
Campbell, J., Xu, J. & Wah Fung, K. (2011) ‘Can SNOMED CT fulfill the vision of a compositional terminology? Analyzing the use case for Problem List’, AMIA Annu Sympos Proc, 181–188.
Carroll, J., Koeling, R. & Puri, S. (2012) ‘Lexical acquisition for clinical text mining using distributional similarity. Computational linguistics and intelligent text processing’, Lect Notes Comput Sci, 7182:232–246.
Dietterich, T. G. (1998) ‘Approximate statistical tests for comparing supervised classification learning algorithms’, Neural Computn, 10(7):1895–1924.
Dwyer, C., Hiltz, S. R. & Passerini, K. (2007) ‘Trust and privacy concern within social networking sites: A comparison of Facebook and MySpace’. Proceedings of the Thirteenth Americas Conference on Information Systems, Keystone, Colorado, August.
Fox, S. (2011) The Social Life of Health Information. Pew Research Center’s Internet & American Life Project. [online] at: http://www.pewinternet.org/~/media/Files/Reports/2011/PIP_Social_Life_of_Health_Info.pdf [20 October 2013].
Ghazinour, K., Sokolova, M. & Matwin, S. (2013) ‘Detecting Health-Related Privacy Leaks in Social Networks Using Text Mining Tools’, Canadian Conference on AI, pp. 25–39.
Grace, J., Gruhl, D., Haas, K., Nagarajan, M., Robson, C. & Sahoo, N. (2007) Artist ranking through analysis of on-line community comments from: http://domino.research.ibm.com/library/cyberdig.nsf/papers/E50790E50756F371154852573870068A371154852573870184/$File/rj371154852573810421.pdf.
Gross, R. & Acquisti, A. (2005) ‘Information revelation and privacy in online social networks (the facebook case)’, In Proceedings of the ACM Workshop on Privacy in the Electronic Society, pp. 71–80.
Harries, D. & Yellowlees, P. M. (2013) ‘Cyberterrorism: Is the U.S. healthcare system safe?’, Telemed e-Health 19(1):61–66.
Jurafsky, D. & Martin, J. H. (2008) ‘Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics and Speech Recognition, Second Edition, Prentice-Hall, Upper Saddle River, NJ.
Keckley, P. H. & Hoffman, M. (2010) Social Networks in Health Care: Communication, Collaboration and Insights, Deloitte Development LLC.
Kennedy, D. (2012) ‘Doctor blogs raise concerns about patient privacy’. Available at: www.npr.org/templates/story/story.php?storyId#equal#88163567. [June 13, 2012].
Knudson, J. (2013) ‘Healthcare information, the new terrorist target’, The Record, 25(6):10.
Lagu, T., Kaufman, E., Asch, D. & Armstrong, K. (2008) ‘Content of weblogs written by health professionals’, J Gen Intern Med, 23(10):1642–1646.
Li, F., Zou, X., Liu, P. & Chan, J. Y. (2011) ‘New threats to health data privacy’, BMC Bioinformatics, 12:S7.
Malik, S. & Coulson, N. (2010) ‘Coping with infertility online: an examination of self-help mechanisms in an online infertility support group’, Patient Educ Couns, 81:315–318.
Manning, C. D. & Schütze, H. (2003) Foundations of Statistical Natural Language Processing, MIT Press: Cambridge, MA, Sixth Printing.
McLernon, D. J., Bond, C. M., Hannaford, P. C., Watson, M. C., Lee, A. J., Hazell, L. & Avery, A. (2010) ‘Adverse drug reaction reporting in the UK: a retrospective observational comparison of Yellow Card reports submitted by patients and healthcare professionals’, Drug Safety, 33(9):775–788.
MedDRA Maintenance and Support Services Organization. [online] http://www.meddramsso.com. [Jan 1, 2013].
Miles, A., Rodrigues, V. & Sevdalis, N. (2013) ‘The effect of information about false negative and false positive rates on people’s attitudes towards colorectal cancer screening using faecal occult blood testing (FOBt)’, Patient Edu Couns, 93(2):342–349.
Miller, A. R. & Tucker C. (2009) ‘Privacy protection and technology adoption: The case of electronic medical records’, Manag Sci, 55(7):1077–1093.
Mitchell, T. M. (1997) Machine learning. New York, NY: The McGraw-Hill Companies, Inc.
Mitkov, R. (2003) The Oxford Handbook of Computational Linguistics. Oxford University Press.
Princeton University (2010) About WordNet. WordNet. Princeton University, [online] Available at: http://wordnet.princeton.edu. [8th October, 2013].
Renahy, E. (2008) Recherche bd’infomation en matiere de sante sur INternet: determinants, practiques et impact sur la sante et le recours aux soins, Paris 6.
Scanfeld, D., Scanfeld, V. & Larson, E. (2010) ‘Dissemination of health information through social networks: twitter and antibiotics’, American Journal of Infection Control, 38(3):182–188.
Shani, G., Chickering, D. M. & Meek, C. (2008) ‘Mining recommendations from the web’. In RecSys ’08: Proceedings of the 2008 ACM Conference on Recommender Systems, pp. 35–42.
Silverman, E. (2008) ‘Doctor Blogs Reveal Patient Info & Endorse Products’. Pharmalot www.pharmalot.com/2008/07/doctor-blogs-reveal-patient-info-endorse-products/. [Dec. 15, 2009].
Sokolova, M. & Lapalme, G. (2011) ‘Learning opinions in user-generated web content’, Nat Lang Eng, 17(4):541–567.
Sokolova, M., Matwin, S., Jafer, Y. & Schramm, D. (2013) ‘How Joe and Jane Tweet about Their Health: Mining for Personal Health Information on Twitter’. In the Proceedings of Recent Advances in Natural Language Processing, Hissar, Bulgaria, pp. 626–632.
Sokolova, M. & Schramm, D. (2011) ‘Building a patient-based ontology for mining user-written content’. In Recent Advances in Natural Language, Processing Hissar, Bulgaria, pp. 758–763.
Star, K., Norén, G. N., Nordin, K. & Edwards, I. R. (2011) ‘Suspected adverse drug reaction reported for children worldwide: an exploratory study using VigiBase’, Drug Safety, 34:415–428.
Systematized Nomenclature of Medicine. [online] www.ihtsdo.org/snomed-ct/, [Jan 1, 2013].
Witten, I. H., Frank, E. & Hall, M. A. (2011) Data Mining: Practical Machine Learning Tools and Techniques, (third edition) Morgan Kaufmann: Burlington, MA.
Yeniterzi, R., Aberdeen, J., Bayer, S., Wellner, B., Clark, C., Hirschman, L. & Malin, B. (2010) ‘Effects of personal identifier resynthesis on clinical text de-identification’, J Am Med Inform Assoc, 17(2):159–168.
Yu, F. (2006) High Speed Deep Packet Inspection with Hardware Support, Technical Report No. [online] UCB/EECS-2006-156; www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-156.html, [January 2013].
Zhang, W., Gunter, C. A., Liebovitz, D., Tian, J. & Malin, B. (2011) ‘Role prediction using electronic medical record system audits’. In AMIA (American Medical Informatics Association) Annual Symposium, pp. 858–867.