
8 DVX – the descriptive video exchange project: using crowd-based audio clips to improve online video access for the blind and the visually impaired
Abstract: In recent years, we have witnessed an explosion in the amount of online information available in video format. Full participation in an information society now requires the ability to access and understand video data. This requirement presents a major obstacle to people who can only see poorly, or not at all. As a result, their access to important medical information may be severely compromised. Furthermore, video data cannot be processed by current text-based search techniques. This chapter examines the use of audio and text description, created through crowd sourcing, to improve video accessibility for the blind and the visually impaired. In addition, it describes how description and speech recognition can improve video search.
8.1 Current problems with video data
The first problem is the difficulty of accessing video formatted data for the blind or the visually impaired. Given that more and more data are being presented in the video medium, participation in an information society requires the ability to view and understand ever-increasing amounts of video data. Blind people and the visually impaired want and need access to online video information for the same reasons as sighted people want access to such information. Here are a few examples:
Health care: An ever-increasing amount of health and medical information on the Internet is now available in video format. Nearly everything from lifestyle suggestions to prescription instructions is presented as small movies. In fact, access to this information can prove vital to one’s well-being.
Education: Course materials and lectures frequently contain large amounts of information in video format. Consequently, access to video has become an educational necessity.
Entertainment: blind people want to enjoy movies, DVDs, etc.
Unfortunately, video content presents a large portion of its information visually. While highly effective, it excludes those who cannot see it. How can video format be augmented to provide increased accessibility?
The second problem is the difficulty of searching information that is in video format. Consider a patient who has a set of video instructions for a medical prescription that they must take. They want to look up the dosage. Unlike with text, the patient has no search function available to them that can be used to find the dosage section. Instead, the patient must tediously play through the entire video, seeking this information more or less by trial-and-error until they find the dosage information. No doubt, this is a slow, cumbersome process, whether the searcher is sighted or blind. The question posed here is how can this be made easier for everyone regardless of their visual capacity?
8.2 The description solution
Given that video is so pervasive a medium in this society, what can we do to increase its accessibility to the blind and the visually impaired, as well as improve its ability to be searched by the general population writ large? One solution is to add more information in another format to augment the video content. This is called “description.”
8.2.1 What is description?
In its broadest sense, a description is a set of information in a secondary format that augments other information that exists in a primary format.
A common example is television captioning. The television program is a stream of information in video, which is the primary format. The captioning is the description that adds information as text, which is the secondary format.
By adding a secondary format, description provides access to information when the primary format is not usable. For example, the text captioning provides information to people who are deaf, or where the environment is too noisy to use audio, as in a crowded bar.
8.2.2 Description for the visually impaired
The main objective of the DVX project, described below, is to increase accessibility to video data for the visually impaired. In the DVX project, the primary format is video and the secondary format is audio, the addition of which provides increased access to videos for people with low or no vision.
8.2.2.1 Current types
Amateur live audio description (bring a friend)
This was, historically, the only type of description available. A blind person found a friend to watch a video with them, and the friend described the video in real time as they sat at the side of their unsighted friend.
Professional audio description
Occasionally, an organization (e.g., a film studio) that created a video would create a description to accompany it. The description became an addition to the professional product. Such descriptions were created in the same manner as other video content was created. As such, a scriptwriter would write what was to be spoken. Then, the resulting script would go through many cycles of editing and revision, and, finally, a professional speaker (voice talent) would record the script.
Problems with the current types
Description has three major technical issues, which must be addressed to work successfully: storage, distribution, and synchronization. A description’s data must be stored somewhere, so it can be used more than once. Wherever the description data is stored, it must be available on demand to the system that plays the video. Thus, it must be available for distribution.
Finally, description must be synchronized to the video. Descriptions are composed of clips – short pieces of speech, which are spoken at specific times within the video. This timing is critical. Deviations of even tens of milliseconds can cause clips to interfere with the sound track of the video, resulting in reduced comprehension of both the video and the description. Larger deviations can disrupt the synchronization between the description and the events that are occurring in the video, causing a great deal of confusion.
Amateur description has serious problems with storage and distribution. The description has no storage, and must be repeated every time the video is played. The obvious solution to this problem is to record the description on a separate device, such as a digital recorder. This method fails, because it offers no mechanism to provide the necessary synchronization. Even if that problem were solved, amateur description still lacks a means to distribute the description to every person who views the video. This raises a lot of questions: Should a DVD with the audio be available to order along with the DVD of the video itself? What about online videos? Must the description be added to the web site? In every case, the entity that makes the video available must also make the description available, but can that be practically done?
Professional description, on the other hand, usually solves the storage and distribution problems. Since the describers usually work with the content producers, the descriptions are stored and distributed with the content itself. Moreover, this approach also simplifies synchronization.
The major problems with professional description though are high cost and difficulty of scaling. Their production method creates a very refined and elegant product, but the process simply takes much too long. The cost and availability of the chain of people needed to produce professional description makes it ostensibly non-viable for small video productions. For example, an academic department at a university setting that wanted to describe videos of its seminars and lectures would no doubt lack the time and money to hire competent scriptwriters.
8.3 Architecture of DVX
The objective of the DVX project was to provide an environment, or platform, for the creation and dissemination of video description, which addressed the problems stated above, and more. To achieve this, the architecture is divided into two distinct parts. The first part is the Descriptive Video Exchange (DVX) server, which provides an open, distributed repository for descriptions. The second part includes the Applications Modules that utilize the DVX server to provide description solutions for their users.
8.3.1 The DVX server
The DVX server is the common repository that stores and disseminates video descriptions. It exposes a standard interface that applications can use to store, manage, and distribute description data. It does this in the form of a RESTful web service, which is an architectural style consisting of a coordinated set of architectural constraints applied to components, connectors, and data elements, within a distributed system.
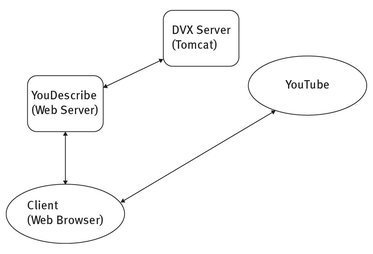
Fig. 8.1: DVX architecture.
8.3.1.1 Major data elements, attributes and actions
Figure 8.1 shows the three major data elements in the server: user, clip, and video. Each is specified by a set of attributes shown in Tab. 8.1. Together, they encapsulate the information and inter-relationships that clients of the server need in order to create and manage descriptions. Note: each element has more attributes than are listed here. These are just some of the major ones.
Tab. 8.1: DVX data elements.
| Element | Attributes | Actions |
|---|---|---|
| User | Handle – the user’s name | Add – create a new user |
| Password – the user’ identification | Logon – sign onto the server | |
| Email – user’s communication point | Logoff – sign off of the server | |
| Clip | Id – a unique identifier | Upload – add a clip |
| Format – the type of the clip | Download – retrieve a clip | |
| Video – identifies the video the clip belongs to Time – when the clip should be played | Metadata – provide information on a clip | |
| Filename – the file containing the clip’s data | Delete – remove a clip | |
| Author – the clip’s creator | ||
| Video | Id – identifies the video | Add – enters a new video into the server |
| Media identifier – identifies the exact version of the video | ||
| Video – retrieves information about a video | ||
| Author – the user who added a video |
User
The DVX server supports the concept of a user. Users represent the people who create descriptions. Each user has a unique identifier, as well as a name and password. Users must log in to the server to make any changes to data (add, delete, modify). They do not have to log in to simply query or view data. An “id” number uniquely identifies each user within the server.
Attributes
A user has a “handle,” which will be the name he or she is known by to the server.
A user’s “password” provides verification of user identity.
A user also has an “email” address.
Actions
A client can “add” a user to the DVX server. This starts a registration process that sends a confirmation message to the given email address so as to confirm the identity of the candidate user.
A client can “logon” to the server, using the “handle” and “password” attributes.
A client can “logoff” from the server.
Clip
A clip is a piece of information that says something about a video. A set of clips, each played at a different time in the same video, forms a description. The server allows clips to be in many different formats: audio files, text strings, etc.
Attributes
Each clip has several parameters associated with it.
A clip’s “id” uniquely identifies it.
Its “format” indicates what the medium of the clip is: audio, text, etc.
The “video” attribute is the id of the video that the clip belongs to.
The “time” of a clip defines the time, in seconds, from the beginning of the video that the clip belongs to, i.e., the time within the video that clip should be played.
The “filename” is the name of the file that contains the clip’s data.
Finally, the “author” is the id of the user who created the clip. Each clip belongs to a particular user. This allows multiple users to create separate descriptions of the same video.
Actions
Clients of the DVX server can perform four actions with clips.
Given the attributes “filename,” “time,” “author” and “video,” the “upload” action copies “filename” into the server.
The “download” action streams the contents of a clip to the requesting client. Any combination of attributes can be specified, as long as they define a unique clip.
A client can request a “Metadata” query for clips. This returns information about all clips (as opposed to the clips themselves) that match the parameters passed with the query. If no parameters are passed, information on every clip in the server is returned.
The “delete” action removes a clip from the server. As with download, any number of attributes can be specified, as long as they identify a unique clip.
Video
The video element contains information about a video. It does not contain the video itself.84
Attributes
The “id” attribute is an internal identifier for each video known to the server. The “media identifier” is a unique name for each video. As opposed to the “id” mentioned above, this is an id, found from the media or its source itself that identifies it as a particular piece of content. For example, it identifies a video as “great video, version 1.” This is important, because content with the same title, etc. can often be found in different versions. This is particularly common with DVDs – there is an original version, a “director’s cut,” a PG-edited version, etc. These versions will almost surely have different lengths.
In order to maintain synchronization, it is vital that the server knows the exact identity of each piece of content that is described. Websites, such as YouTube, often have unique identifiers for each video, making the solution relatively easy. Other media, such as DVDs, can be more difficult. There are sometimes tags within the DVD that are meant to be unique, but these are not always present or accurate. We have explored the use of hashing algorithms to derive unique keys from the actual data stream from DVDs. This is an ongoing area of research. The “author” attribute is the id of the user who added the video to the server. This is separate from the people or group who created the video.
Actions
The “add” action lets a client add a new video to the server.
The “video” action retrieves information about all videos that match the given attributes.
8.3.1.2 Current implementation
RESTful web service interface
A web service can be described as a web site whose clients are other computers, rather than humans. Programs communicate with the site to access and exchange data, as well as to perform actions on that data. A RESTful web service follows the paradigm given by Roy Fielding85 in 2000. Programs communicate with the service using the common HTTP protocol.
The server exposes URLs to clients over a network. In each URL, the action to be taken is presented as a combination of an HTTP method and an endpoint, and the attributes are represented by HTTP parameters. For example, a client request for a particular clip would have the form: http://dvxwebsite.com:8080/dvxApi/ clipdownload?video=1234&Time=32.6&Author=25.
This is an HTTP GET method that, which instructs the DVX server (hosted at dvxwebsite.com), to download the clip created by user number 25, for the video with an internal identification of 1234, which was recorded 32.6 seconds from the start of the video.
8.3.1.3 Tomcat servlet container
The DVX server resides in a Tomcat container. Tomcat is an open-source platform similar to a web server such as Apache or Windows IIS. Instead of hosting HTML web pages, however, it hosts Java objects called servlets. These objects respond to HTTP requests, and dynamically create HTTP responses. The DVX server is a collection of servlets that receive HTTP requests from clients, and reply with responses.
MySQL database/Hibernate
All data except for the actual clips are stored on a MySQL database. MySQL provides the persistent storage needed to preserve the relationships between clips and videos that comprise descriptions, as well as the information required to manage users, videos and other bookkeeping activities. Hibernate is an Object Relational Mapping (ORM ) framework. It facilitates the translation between the object-oriented environment of the Java code in Tomcat, and the relational data paradigm of MySQL.
8.3.1.4 Applications
The DVX server provides vital description information programmatically, in a form that is easy for software programs to work with. The second half of the DVX architecture is its applications. These are the software systems that utilize the DVX server to provide description capabilities and functions to users.
YouDescribe
YouDescribe is a description creation and distribution web application for YouTube videos. Anyone with a web browser can use it.
A user can select any normal YouTube video, and play it. At any point, they can pause the video and record an audio clip. By repeating this process, they create a description of the video.
Later, another user can select and play the same video. As it plays, YouDescribe plays the audio clips for them at the appropriate times in the video.
Figure 8.2 shows the main YouDescribe page.
If the user clicks on the “Show Most Recent YouDescribe Videos” link, a table displays all the YouTube videos that have descriptions. The table shows a row for each description of each video; therefore some videos are displayed on multiple rows.
Additionally, the user can enter text into the search textbox. The table will then show all YouTube videos that match the search criteria.
In either case, each row of the table displays an icon of the video, followed by its title. Clicking on either of these pops up a video player, which starts to play the selected video (Fig. 8.3).
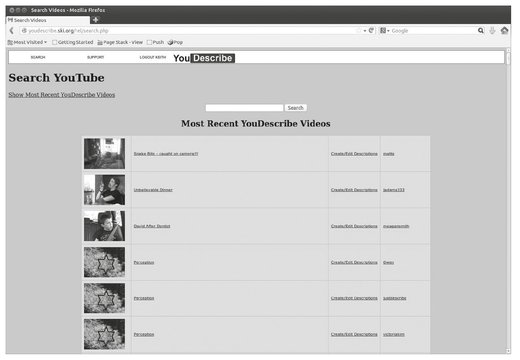
Fig. 8.2: YouDescribe.
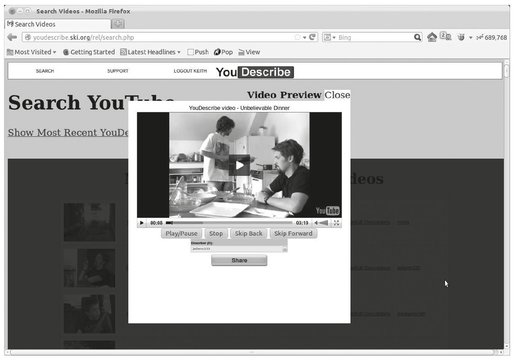
Fig. 8.3: YouDescribe player.
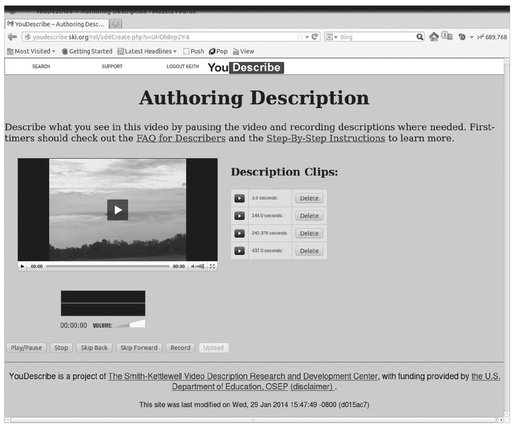
Fig. 8.4: YouDescribe authoring.
The player floats on top of the main page. It behaves similarly to any ordinary video player, except that while playing the video, it will pause and play audio clips at appropriate times, which provides a description of the video. They player also includes a describer dropbox, and a “share” button. The dropbox allows the user to select the describer they want to hear, while the “share” button displays a link to the described video, which a user can use to embed the video in any web document.
Returning to the main page, an optional third field is only displayed if the user is logged on to the system. Selecting it brings up the authoring page (Fig. 8.4), where the user can record descriptions for the selected video.
The authoring page allows a logged-in user to create and edit a video’s description, by recording and deleting individual clips. It displays a video player, similar to the one in the main page, except for four additional controls:
A record button, when pressed, will record the user’s speech.
A volume control allows the user to adjust the recording level.
A small oscilloscope displays shows a waveform of what is being recorded.
An upload button, when pressed, will send the recording to YouDescribe.
To author a description, a user would play the video, and pause it at a point where they want to describe something. They would then hit the record button, speak their explanation of the video, and click the upload button to send the clip to YouDescribe. YouDescribe then sends the clip to DVX, which stores it as a clip for the video, to be played back in the future at the time where the video is paused.
An additional frame in the authoring page lists all the clips the user has created for the video. Each line of the list allows the user to play back the clip, and delete it, if desired.
The final field in the main page table shows the name of the user who created descriptions for the video. Clicking on that name returns a table, which lists all the videos that user described. This provides a way to follow a particular user, and track the videos they have described.
An example scenario – Figure 8.5
An example will help illustrate how YouDescribe can use the DVX server to provide description services.
When a user goes to the YouDescribe web page, the browser sends a request to the DVX server, in the form:
HTTP method: GET
Endpoint: Video
This retrieves information about every video known to YouDescribe. The web page displays the returned information as a list. There is an entry in the list for each video that has a description created by a particular user. Therefore, a video may be listed several times, if more than one user created a description for it.
The user selects a video from the list. The browser creates a player to play the video. It then queries the server, to get a list of all the clips associated with that video:
HTTP method: GET
Endpoint: clip/metadata
Attributes: Id=“id of selected video,” Author=“id of selected user”
The server responds with data for every clip that was recorded by that user for that video. The browser then starts the player, and plays the video.
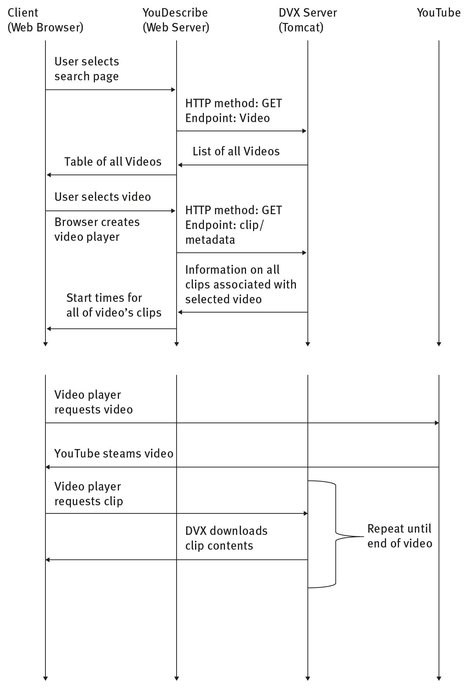
Fig. 8.5: Example scenario.
Because the data returned by the server includes a “time” attribute for each clip, the player knows when it should pause the video and play an audio clip. Whenever it is time to play a clip, the browser requests the clip from the server:
HTTP method: GET
Endpoint: clip
Attributes: Id = “id of selected video,” Author = “id of selected user,”
Time=“time of desired clip”
The browser then pauses the player, and plays the clip, which describes what occurs in the video at that time. When the clip is done, the browser tells the player to resume playing. In this manner, the application provides a description of the video.
8.4 DVX solves description problems
The combination of the DVX server and DVX-enabled applications solves many of the problems associated with description creation and dissemination:
First, it allows anyone to create descriptions. The DVX Server, combined with an application such as YouDescribe, creates a crowd-sourced solution for description generation. It grants the ability to describe video to every person with a web browser. This includes professional describers. The DVX interface augments the tools professional describers already use, thereby providing a gateway to DVX’s instant, worldwide distribution and storage.
Second, it provides description distribution. DVX breaks the traditional tie between description creation and a particular vendor or video medium. The origin of a description is independent of its storage and access. The descriptions are stored where any user with Internet connectivity can access them.
Third, it provides synchronization information. In DVX, all clips are stored with the time that they should be played in a video. Therefore, correct time information is always available to any application, which eases the task of description synchronization.
Fourth, it enforces common description formats. In DVX, all clips are stored in a common format. Descriptions can be easily shared regardless of the different applications that generated them.
Fifth, it decreases the time it takes to distribute descriptions. A description, once created, is immediately available. It does not have to be delayed, pending a new release of the content.
8.5 DVX and video search
While DVX can help solve many issues concerning video description, it can also be used to improve video search. As mentioned before, searching a video is a very difficult process. Imagine, however that the video had descriptions in text format, commonly known as “tags.” Those descriptions are available to the many text search tools on the market today. A search for the word “dosage” could quickly forward the video to the information one needs with regard to how much and how often an especially potent medication may be taken. Further, data mining tools, in addition to all the other powerful analytical techniques that have been developed for text data, can now process the video data as well.
The challenge is how to create tags for the vast number of videos.
Speech recognition has been used to create a text transcript of a video’s audio track. Search engines and other text-based tools can then access and process the transcript. This approach is fast, since it requires little or no human intervention, and it can work nearly automatically.
However, automatically creating tags has two shortcomings:
First, the transcript only contains information from the audio portion of the video. Thus it may omit vital information that could have been used to create useful indexing tags. For example, the prescription video may never actually say the word “dosage.” Just as with a visually-impaired viewer, the speech recognition system (which cannot see either) only knows what is contained on the audio track. Second, the transcription is not constituted or formulated as a set of tags; it is merely a text translation of all the voice on the video. Consequently, it must be processed further to extract a useful set of tags.
DVX could bring its solutions to greatly enhance the transcript approach. First, it could fill the gap that the transcript misses. The descriptions people create are information about the visual-only portions of the video, which is the very part the transcript doesn’t cover. It could use speech recognition on those descriptions to create a second set of text that fills in the information that is missing from the transcription. Second, the descriptions it translated to text were created by humans, who used their judgment to create intelligent translations of voice text, thereby making it much easier to extract useful tags than to rely on machine learning techniques to make these feature extractions.
Futhermore, DVX could also create tags directly. An application could be written that simply enables users to pause a video and type a description, rather than speak one. The DVX server can store any type of clip, as long as it can be stored as a file. DVX could even convert those descriptions to audio, using text-to-speech.
8.6 Conclusion
Description is a powerful tool that increases accessibility to information that is stored in video format. The Descriptive Video Exchange provides a framework that enables a large number of people, amateur and professional, to create descriptions both quickly and easily. It distributes those descriptions so that they are available to anyone on the Internet and, in particular, provides a special service for the visually impaired. Furthermore, DVX when combined with speech recognition can greatly improve video search.
Acknowledgment
The project described in this chapter was developed by the Smith-Kettlewell Video Description Research and Development Center, under a grant from the U.S. Department of Education (H327J110005), awarded to Dr. Joshua Miele, Principal Investigator at Smith-Kettlewell. However, these contents do not necessarily represent the policy of the U.S. Department of Education and you should not assume endorsement by the Federal Government.