
9
Connected Speech
GHINWA ALAMEEN AND JOHN M. LEVIS
Introduction
Words spoken in context (in connected speech) often sound quite different from those same words when they are spoken in isolation (in their citation forms or dictionary pronunciations). The pronunciation of words in connected speech may leave vowel and consonant sounds relatively intact, as in some types of linking, or connected speech may result in modifications to pronunciation that are quite dramatic, including deletions, additions, or changes of sounds into other sounds, or combinations of all three in a given word in context. These kinds of connected speech processes (CSPs) are important in a number of areas, including speech recognition software, text-to-speech systems, and in teaching English to second language learners. Nonetheless, connected speech, in which segmental and suprasegmental features interact strongly, lags far behind work in other areas of segmentals and suprasegmentals in second language research and teaching. Some researchers have argued that understanding CSPs may be particularly important for the development of listening skills (Field 2008; Jenkins 2000; Walker 2010), while others see CSPs’ production as being particularly important for more intelligible pronunciation (Celce-Murcia et al. 2010; Reed and Michaud 2005).
Once a word is spoken next to other words, the way it is pronounced is subject to a wide variety of processes. The changes may derive from linguistic context (e.g., can be said as cam be), from speech rate (e.g., tomorrow’s temperature runs from 40 in the morning to 90 at midday, in which temperature may be said as tɛmpɹətʃɚ, tɛmpətʃɚ, or tɛmtʃɚ, depending on speed of speech), or from register (e.g., I don’t know spoken with almost indistinct vowels and consonants but a distinctive intonation in very casual speech). When these conditioning factors occur together in normal spoken discourse, the changes to citation forms can become cumulative and dramatic.
Connected speech processes based on register may lead to what Cauldwell (2013) calls jungle listening. Just as plants may grow in isolation (in individual pots in a greenhouse), they may also grow in the company of many other plants in the wild. The same is true of words. Typically, the more casual and informal the speech register is, the more the citation forms of words may change. As a result, the pronunciation of connected speech may become a significant challenge to intelligibility, both the intelligibility of native speech for non-native listeners and the intelligibility of non-native speech for native listeners. Connected speech, perhaps more than other features of English pronunciation, demonstrates the importance of intelligibility in listening comprehension. In many elements of English pronunciation, non-native speakers need to speak in a way that is intelligible to their listeners, but connected speech processes make clear that non-native listeners must also learn to understand the speech of native words that may sound quite different from what they have come to expect, and their listening ability must be flexible enough to adjust to a range of variation based not only on their interlocutors but also on the formality of the speech.
Definitions of connected speech
Hieke (1987) defined connected speech processes as “the changes which conventional word forms undergo due to the temporal and articulatory constraints upon spontaneous, casual speech” (1987: 41). That is, they are the processes that words undergo when their border sounds are blended with neighboring sounds (Lass 1984). Citation form pronunciations occur in isolated words under heavy stress or in sentences delivered in a slow, careful style. By contrast, connected speech forms often undergo a variety of modifications that cannot always be predicted by applying phonological rules (Anderson-Hsieh, Riney, and Koehler 1994; Lass 1984; Temperley 1987). It may be that all languages have some form of connected speech processes, as Pinker (1995: 159–160) claims:
In speech sound waves, one word runs into the next seamlessly; there are no little silences between spoken words the way there are white spaces between written words. We simply hallucinate word boundaries when we reach the edge of a stretch of sound that matches some entry in our mental dictionary. This becomes apparent when we listen to speech in a foreign language: it is impossible to tell where one word ends and the next begins.
Although CSPs are sometimes thought to be a result of sloppy speech, they are completely normal (Celce-Murcia et al. 2010; Henrichsen 1984). Highly literate speakers tend to make less use of some CSPs (Prator and Robinett 1985); however, even in formal situations, such processes are completely acceptable, natural, and essential part of speech.
Similar modifications to pronunciation also occur within words (e.g., input pronounced as imput), but word-based modifications are not connected speech since they are characteristic pronunciations of words based on linguistic context alone (the [n] moves toward [m] in anticipation of the bilabial stop [p]). In this chapter, we will not address changes within words but only those between words.
Function of CSPs in English
The primary function of CSPs in English is to promote the regularity of English rhythm by compressing syllables between stressed elements and facilitating their articulation so that regular running speech timing can be maintained (Clark and Yallop 1995). For example, certain closed class words such as prepositions, pronouns, and conjunctions are rarely stressed, and thus appear in a weak form in unstressed contexts. Consequently, they are “reduced” in a variety of processes to preserve the rhythm of the language. Reducing speech can also be attributed to the law of economy where speakers economize on effort, avoiding, for example, difficult consonant sequences by eliding sounds (Field 2003). The organs of speech, instead of taking a new position for every sound, tend to connect sounds together using the same or intermediate articulatory gestures to save time and energy (Clarey and Dixson 1963).
One problem that is noticeable in work on connected speech is the types of features that are included in the overall term. Both the names given to the connected speech processes and the phenomena included in connected speech vary widely in research and in ESL/EFL textbooks. Not only are the types and frequency of processes dependent on rhythmic constraints, speech register, and linguistic environment, the types of connected speech processes may vary among different varieties of English.
A classification for connected speech processes
In discussing connected speech, two issues cannot be overlooked: differences in terminology and the infrequency of relevant research. Not only do different researchers and material designers use different terms for CSPs (e.g., sandhi variations, reduced forms, absorption), they also do not always agree on how to classify them. In addition, conducting experimental studies of connected speech can be intimidating to researchers because “variables are normally not controllable and one can never predict the number of tokens of a particular process one is going to elicit, which in turn makes the application of statistical measures difficult or impossible” (Shockey 2003: 109). As a result, only a few people have researched CSPs in relation to English language teaching and have done so only sporadically (Brown and Kondo-Brown 2006).
Connected speech terminology varies widely, as does the classification of the CSPs. This is especially true in language teaching materials, with features such as contractions, blends (coalescent assimilation or palatalization), reductions (unstressed words or syllables), linking, assimilation (progressive and regressive), dissimilation, deletion (syncope, apocope, aphesis), epenthesis flapping, disappearing /t/, gonna/wanna type changes, –s and –ed allomorphs, and linking. This small selection of terms suggests that there is a need for clarity in terminology and in classification.
We propose that connected speech processes be classified into six main categories: linking, deletion, insertion, modification, reduction, and multiple processes. Our proposed chart is in Figure 9.1. Linking, the first category, is the only one that does not involve changes to the segments of the words. Its function in connected speech is to make two words sound like one without changes in segmental identity, as in the phrases some_of [sʌm əv] and miss_Sarah [mɪs sɛɹə]. Linking can result in resyllabification of the segments without changing them [sʌ.məv] or in lengthening of the linked segments in cases where both segments are identical, e.g., [mɪsːɛɹə]. Our description of linking is narrower than that used by many writers. We restrict linking to situations in which the ending sound of one word joins the initial sound of the next (a common enough occurrence), but only when there is no change in the character of the segments. Other types of links include changes, and we include them in different categories. For example, the /t/ in the phrase hat band would be realized as a glottal stop and lose its identity as a [t], i.e., [hæʔb![]() nd]. We classify this under our category of modifications. In addition, in the phrase so awful, the linking [w] glide noticeably adds a segment to the pronunciation, i.e., [sowɔfəɫ]. We classify this under additions.
nd]. We classify this under our category of modifications. In addition, in the phrase so awful, the linking [w] glide noticeably adds a segment to the pronunciation, i.e., [sowɔfəɫ]. We classify this under additions.
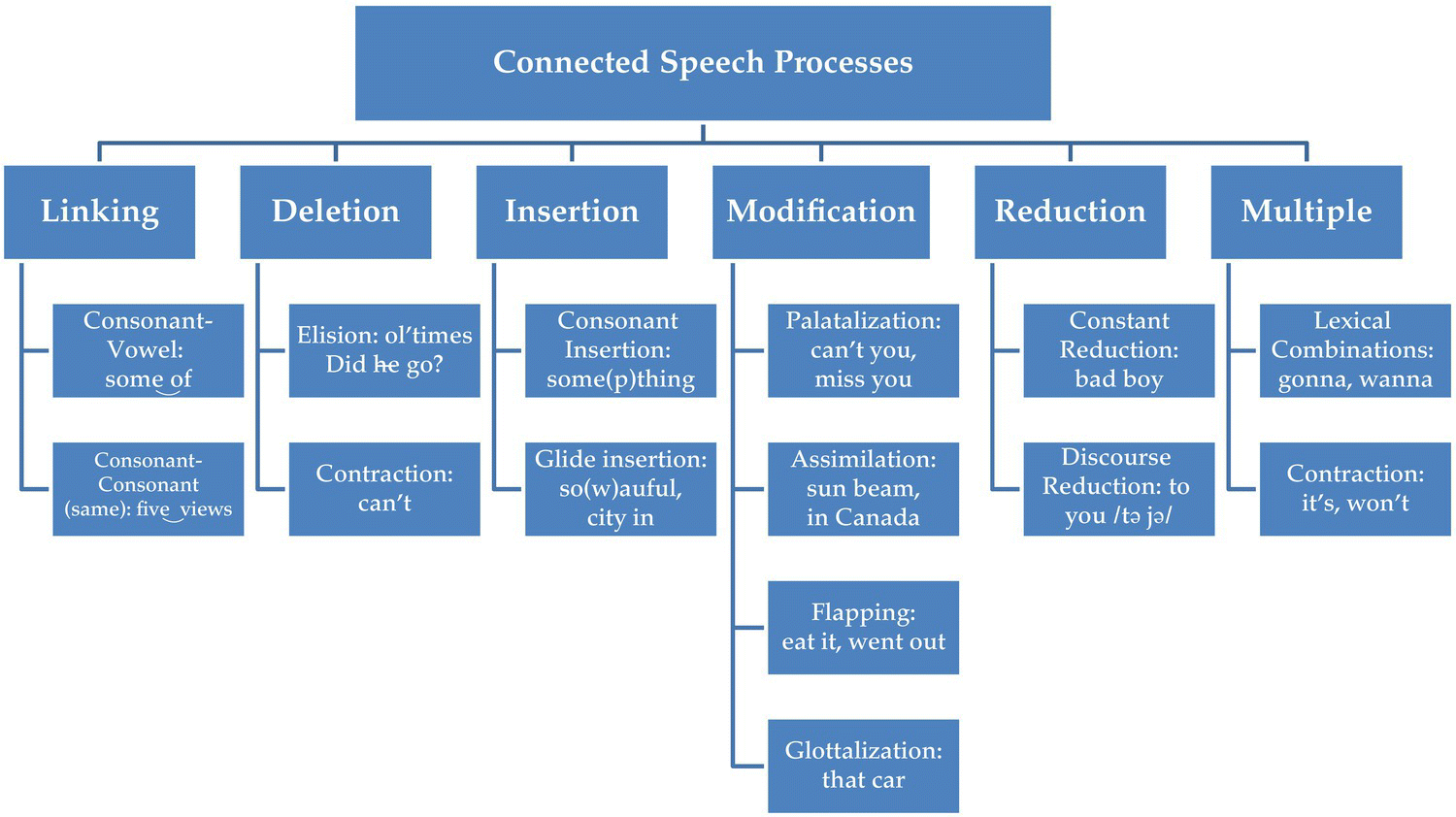
Figure 9.1 Our categorization of Connected Speech Processes.
The second category, deletion, involves changes in which sounds are lost. Deletions are common in connected speech, such as potential loss of the second vowel in a phrase like see it [siːt] in some types of casual speech, the loss of [h] in pronouns, determiners, and auxiliaries (e.g., Did h̶
e do h̶is h̶omework?, Their friends h̶
ave already left) or deletions of medial consonant sounds in complex consonant groupings (e.g., the best̵
gift, old̶
times). Some types of contractions are included in the category, mainly where one or more sounds are deleted in a contraction (e.g., cannot becomes can’t).
The third category, insertion, involves changes that add sounds. An example would be the use of glides to combine two vowels across words (e.g., Popeye’s statement of I am what I am → I yam what I yam). Consonant additions also occur, as in the intrusive /r/ that is characteristic of some types of British or British-influenced English (The idea of → The idea(r) of). There are few insertions of vowels across word boundaries, although vowel insertion occurs at the lexical level, as in athlete → athelete as spoken by some NAmE speakers.
The fourth category is modification. Changes involve modifications to pronunciation that substitute one phoneme for others (e.g., did you pronounced as [dɪdʒu] rather than [dɪdju], or less commonly, modifications that are phonetically (allophonically) but not phonemically distinct (e.g., can you pronounced as [kɛɲju] rather than [kɛnju]). The palatalization examples are more salient than changes that reflect allophonic variation. Other examples of modifications include assimilation of place, manner, or voicing (e.g., on point, where the /n/ becomes [m] before the bilabial stop); flapping (sit around or went outside, in which the alveolar stops or nasal-stop clusters are frequently pronounced as alveolar oral or nasal flaps in NAmE); and glottalization, in which /t/ before nasals or stops are pronounced with a distinct glottal articulation (can’t make it, that car as [kænʔmekɪt] and [ðæʔkɑɹ]).
The fifth category is reduction. Reductions primarily involve vowels in English. Just as reduced vowels are lexically associated with unstressed syllables, so words may have reduced vowels when spoken in discourse, especially word classes such as one-syllable determiners, pronouns, prepositions, and auxiliaries. Reductions may also involve consonants, such as the lack of release on stop consonants as with the /d/ in a phrase like bad boy, for some speakers.
The final category, multiple CSPs, involves instances of lexical combination. These are highly salient lexical chunks that are known for exhibiting multiple CSPs in each lexical combination. These include chunks like gonna (going to in full form), with its changes of [ŋ] to [n], vowel reduction in to, modifications of the [o] to [ʌ] in going, and the deletion of the [t]. Other examples of lexical combinations are What do you/What are you (both potentially realized as whatcha/whaddya) and wanna (for want to). In addition, we also include some types of contractions in this category, such as they’re, you’re, it’s, and won’t. All three of these involve not only deletions but modifications such as vowel changes and voicing assimilation.
The final category points out a common feature of CSPs. The extent to which phonetic form of authentic utterances differs from what might be expected is illustrated by Shockey (2003). That is, the various types of CSPs occur together, not only in idiomatic lexical combinations but also in all kinds of language. This potentially makes connected speech sound very different from citation forms of the same lexical items. For example, the phrase part of is subject to both flapping and linking, so that its phonetic quality will be [phɑɹ.ɾəv].
Connected speech features
It appears that certain social and linguistic factors affect the frequency, quality, and contexts of CSPs. Lass (1984) attributes CSPs to the immediate phonemic environment, speech rate, the formality of the speech situation, and other social factors, such as social distance. Most researchers distinguish two styles of speech: casual everyday style and careful speech used for certain formal occasions, such as presentations. According to Hieke (1984), in casual spontaneous speech, speakers pay less attention to fully articulating their words, hence reducing the distinctive features of sounds while connecting them. Similarly, when examining linking for a native speaker (NS) and a non-native speaker (NNS) of English, Anderson-Hsieh, Riney, and Koehler (1994) found that style shifting influenced the manner in which speakers link their words. In their study, NSs and NNSs performed more linking in spontaneous speech tasks than those involving more formal sentence reading.
However, other studies have found that while there was some evidence that read speech was less reduced, unscripted and scripted speech shows great phonological similarity (Alameen 2007; Shockey 1974). The same processes apply to both styles and nearly to the same degree. Native speakers do not seem to know that they are producing speech that differs from citation form. In Alameen (2007), NNSs as well as NSs of English did not have significant differences between their linking performance in text reading and spontaneous speech tasks, which indicates that a change in speech style may not entail a change in linking frequency. Furthermore, Shockey (2003) noted that many CSPs occur in fast speech as well as in slow speech, so “if you say ‘eggs and bacon' slowly, you will probably still pronounce ‘and' as [m], because it is conventional – that is, your output is being determined by habit rather than by speed or inertia” (2003: 13).
Other factors, such as social distance, play a role in determining the frequency with which such processes happen (Anderson-Hsieh, Riney and Koehler 1994). When the speaker and the listener both belong to the same social group and share similar speech conventions, the comprehension load on the listeners will be reduced, allowing them to pay less attention to distinctive articulation.
Variation in degree is another feature that characterizes CSPs. Many researchers tend to think of connected speech processes in clear-cut definitions; however, speakers do not always produce a specific CSP in the same way. A large study of CSPs was done at the University of Cambridge, results of which appeared in a series of articles (e.g., Barry 1984; Wright 1986). The results showed that most CSPs produce a continuum rather than a binary output. For instance, if the process of contraction suggests that do not should be reduced to don’t; we often find, phonetically, cases of both expected variations and a rainbow of intermediate stages, some of which cannot be easily detected by ear. Such findings are insightful for CSP instruction since they help researchers and teachers decide on what CSP to give priority to depending on the purpose and speech style. They also provide a better understanding of CSPs that may facilitate the development of CSP instructional materials.
Research into CSPs
Various studies have investigated an array of connected speech processes in native speaker production and attempted to quantify their characteristics. These studies examined processes such as assimilation and palatalization (Barry 1991; Shi et al. 2005), deletion (R.W. Norris 1994), contraction (Scheibman 2000), British English liaison (Allerton 2000), linking (Alameen 2007; Hieke 1987; Temperley 1987), and nasalization (Cohn 1993). Such studies provide indispensable background for any research in L2 perception and pronunciation. The next sections will look at studies that investigated the perception and production of NNSs connected speech in more detail.
Perception
The perception of connected speech is closely connected to research on listening comprehension. In spoken language, frustrating misunderstandings in communication may arise because NSs do not pronounce English the way L2 learners are taught in the classroom. L2 learners’ inability to decipher foreign speech comes from the fact that they develop their listening skills based on the adapted English speaking styles they experience in an EFL class. In addition, they are often unaware of the differences between citation forms and modifications in connected speech (Shockey 2003). When listening to authentic L2 materials, Brown (1990: 4) claims an L2 learner:
Will hear an overall sound envelope with moments of greater and lesser prominence and will have to learn to make intelligent guesses, from all the clues available to him, about what the probable content of the message was and to revise this interpretation if necessary as one sentence follows another – in short, he has to learn to listen like a native speaker.
A part of the L2 listener’s problem can be attributed to the fact that listening instruction has tended to emphasize the development of top-down listening processes over bottom-up processes (Field 2003; Vandergrift 2004). However, in the past decade, researchers have increasingly recognized the importance of bottom-up skills, including CSPs, for successful listening (Rost 2006). In the first and only book dedicated to researching CSPs in language teaching, Brown and Kondo-Brown (2006) note that, despite the importance of CSPs for learners, little research on their instruction has been done, and state that the goal of their book is to “kick-start interest in systematically teaching and researching connected speech” (2006: 6). There also seems to be a recent parallel interest in CSPs studies in EFL contexts, especially in Taiwan (e.g., Kuo 2009; Lee 2012; Wang 2005) and Japan (e.g., Crawford 2006; Matsuzawa 2006). The next section will discuss strategies NSs and NNSs use to understand connected speech, highlight the effect of CSPs on L2 listening and review the literature on the effectiveness of CSPs perceptual training on listening perception and comprehension.
Speech segmentation
A good place to start addressing L2 learners’ CSPs problems is by asking how native listeners manage to allocate word boundaries and successfully segment speech. Some models of speech perception propose that specific acoustic markers are used to segment the stream of speech (e.g., Nakatani and Dukes 1977). In other models, listeners are able to segment connected speech through the identification of lexical items (McClelland and Elman 1986; D. Norris 1994). Other cues to segmentation can also be triggered by knowledge of the statistical structure of lexical items in the language in the domains of phonology (Brent and Cartwright 1996) and metrical stress (Cutler and Norris 1988; Grosjean and Gee 1987). In connected speech, the listener compares a representation of the actual speech stream to stored representations of words. Here, the presence of CSPs may create lexical ambiguity due to the mismatch between the lexical segments and their modified phonetic properties. For experienced listeners, however, predictable variation does not cause a breakdown in perception (Gaskell, Hare, and Marslen-Wilson 1995).
On the other hand, several speech perception models have been postulated to account for how L2 listeners segment speech. Most focus on the influence of the L1 phonological system on L2 perception, for example, the Speech Learning Model (Flege 1995), the Perceptual Assimilation Model (Best 1995), and the Native Language Magnet Model (Kuhl 2000). In order to decipher connected speech, NNSs depend heavily on syntactic-semantic information, taking in a relatively large amount of spoken language to process. This method introduces a processing lag instead of processing language as it comes in (Shockey 2003). L2 learners’ speech segmentation is primarily led by lexical cues pertaining to the relative usage frequency of the target words, and secondarily from phonotactic cues pertaining to the alignment of syllable and word boundaries inside the carrier strings (Sinor 2006). This difference in strategy leads to greater difficulty in processing connected speech because of the relatively less efficient use of lexical cues.
CSPs in perception and comprehension
The influence of connected speech on listening perception (i.e., listening for accuracy) and comprehension (i.e., listening for content) has been investigated in several studies (Brown and Hilferty 1986; Henrichsen 1984; Ito 2006). These studies also show how reduced forms in connected speech can interfere with listening comprehension. Evidence that phoneme and word recognition are indeed a major source of difficulty for low-level L2 listeners comes from a study by Goh (2000). Out of ten problems reported by second language listeners in interviews, five were concerned with perceptual processing. Low-level learners were found to have markedly more difficulties of this kind than more advanced ones.
In a pioneer study in CSP research, Henrichsen (1984) examined the effect of the presence and absence of CSPs on ESL learners’ listening comprehension skills. He administered two dictation tests to NNS of low and high proficiency levels and NSs. The results confirmed his hypothesis that reduced forms in listening input would decrease the saliency of the words and therefore make comprehension more difficult for ESL learners. Comprehending the input with reduced forms, compared to when the sentences were fully enunciated, was more difficult for both levels of students, indicating that connected speech was not easy to understand regardless of the level of the students.
Ito (2006) further explored the issue by adding two more variables to Henrichsen’s design: modification of sentence complexity in the dictation test and different types of CSPs. She distinguished between two types of reduced forms, lexical and phonological forms. Her assumption was that lexical reduced forms (e.g., won’t) exhibit more saliency and thus would be more comprehensible compared to phonological forms (e.g., she’s). As in Henrichsen’s study, the non-native participants scored statistically significantly higher on the dictation test when reduced forms were absent than when they were present. Furthermore, NNSs scored significantly lower on the dictation test of phonological forms than that of lexical forms, which indicated that different types of reduced forms did distinctively affect comprehension. Considering the effects of CSPs on listening perception and comprehension and the fact that approximately 35% of all words can be reduced in normal speech (Bowen 1975), perceptual training should not be considered a luxury in the language classroom.
Effectiveness of CSP training on perception and comprehension
Since reduced forms in connected speech cause difficulties in listening perception and comprehension, several research studies have attempted to investigate the effectiveness of explicit instruction of connected speech on listening. After Henrichesen’s findings that features of CS reduced perceptual saliency and affected ESL listeners’ perception, other researchers have explored the effectiveness of teaching CS to a variety of participants. In addition to investigating whether L2 perceptual training can improve learners’ perceptual accuracy of CSPs, some of the researchers examined the extent to which such training can result in improved overall listening comprehension (Brown and Hilferty 1986; Carreira 2008; Lee and Kuo 2010; Wang 2005). The types of CSPs that could be taught effectively with perceptual training or which are more difficult for students were also considered in some studies (Crawford 2006; Kuo 2009; Ting and Kuo 2012). Furthermore, students’ attitudes toward listening difficulties, types of reduced forms, and reduced forms instruction were surveyed (Carreira 2008; Kuo 2009; Matsuzawa 2006).
The range of connected speech processes explored in those studies was not comprehensive. Some focused on teaching specific high-frequency modifications, i.e., word combinations undergoing various CSPs and appearing more often in casual speech than others; for instance gonna for going to, palatalization in couldja instead of could you (Brown and Hilferty 1986; Carreira 2008; Crawford 2006; Matsuzawa 2006). Others researched certain processes, such as C-V linking, palatalization, and assimilation (Kuo 2009; Ting and Kuo 2012). These studies trained participants to recognize CSP general rules using a great number of reduction examples, instead of focusing on a limited number of examples and teaching them repeatedly.
Results of the previous studies generally indicate that CSP instruction facilitated learners' perception of connected speech. However, most studies failed to address the long-term effects of such training on learners’ perceptual accuracy. Moreover, no study has investigated generalization and transfer of improvement to novel contexts, which indicates that improved abilities could extend beyond the training to natural language usage.
Production
Connected speech is undeniably important for perception, but it is also important for production. Most language teaching materials emphasize exercises meant to teach L2 learners how to pronounce connected speech features more successfully, based on the assertion that “these guidelines will help your comprehension as well as your pronunciation of English” (Grant 1993: 157). Temperley (1987) suggests that “closer examination of linking shows its more profound effect on English pronunciation than is usually recognized, and that its neglect leads to misrepresentation and unnatural expectations” (1987: 65). However, the study of connected speech phenomena has been marginalized within the field of speech production. This section discusses connected speech production in NS and NNS speech, highlighting its significance and prevalence, and demonstrating the effectiveness of training in teaching CS production.
CSPs in production
Hieke (1984, 1987), Anderson-Hsieh, Riney, and Kochear (1994), and Alameen (2007) investigated aspects of connected speech production of American English, including linking, and compared them to those of non-native speakers of English. In a series of studies, Hieke (1984, 1987) investigated the prevalence and distribution of selected CSPs in native and non-native speech. Samples of spontaneous, casual speech were collected from NS (n = 12) and NNS (n = 29) participants according to the paraphrase mode, that is, they retold a story heard just once. C-V linking, alveolar flapping, and consonant cluster reduction were considered representative of major connected speech categories in these studies. Hieke (1987) concluded that these phenomena could be considered “prominent markers of running speech” since they “occur in native speech with sufficient consistency to be considered regular features of fluency” (1987: 54).
Building on Hieke's research, Anderson-Hsieh, Riney, and Kochler (1994) examined linking, flapping, vowel reduction, and deletion, in the English of Japanese ESL learners, comparing them to NSs of American English. The authors examined the production of intermediate-proficiency (IP) and high-proficiency (HP) NNSs by exploring the extent to which style-shifting affected the CSPs of ESL learners. Results showed that while the HP group approximated the performance of the native speaker group, the IP group often lagged far behind. An analysis of the reduced forms used revealed that the IP group showed a strong tendency to keep word boundaries intact by inserting a glottal stop before the word-initial vowel in the second word. The HP group showed the same tendency but less frequently.
Alameen (2007) replicated Anderson-Hsieh et al.'s (1994) macroanalytical study while focusing on only C-V and V-V linking. Results indicated that beginning-proficiency and intermediate-proficiency participants linked their words significantly less often than NS participants. However, the linking rates of the two NNS groups were similar despite the difference in proficiency level. While supporting past research findings on linking frequency, results of the study contradicted Anderson-Hsieh et al.'s (1994) results in terms of finding no significant difference between spontaneous and reading speech styles. In addition, the study showed that native speakers linked more frequently towards function words than to content words.
Effectiveness of CSP training on production
Although there have been numerous studies on the effectiveness of teaching CSP on listening perception and comprehension, very little research has been conducted on CSP production. This can be largely attributed to the pedagogical priorities of teaching listening to ESL learners since they are more likely to listen than to speak in ESL contexts and partly to a general belief that CSPs are not a central topic in pronunciation teaching and sometimes markers of “sloppy speech”. Three research studies (Kuo 2009; Melenca 2001; Sardegna 2011) have investigated the effectiveness of CSP instruction on L2 learners. Interestingly, all studies were primarily interested in linking, and all were masters or PhD theses. This can probably be accounted for by the facts that (a) linking, especially C-V linking, is the simplest and “mildest” CSP (Hieke 1987) since word boundaries are left almost intact, (b) linking as a phenomenon is prevalent in all speech styles, while other CSPs are more frequent in more informal styles, e.g., palatalization, and (c) L2 problems in linking production can render production disconnected and choppy and, hence, difficult for NS to understand (Dauer 1992) and unlinked speech can sometimes be viewed as aggressive and abrupt (Anderson-Hsieh, Riney, and Kochler 1994; Hatch 1992).
Melenca (2001) explored the influence of explicitly teaching Japanese speakers of English how to connect speech so as to avoid a robotic speech rhythm. A control (N = 4) and an experimental group (N = 5) were each given three one-hour sessions in English. Their ability to link word pairs was rated using reading aloud and elicited free-speech monologues that were compared to an NS baseline. Descriptive statistics showed that individual performances in pre- and post-test varied considerably. Yet they also demonstrated that the performance of experimental group participants either improved or remained relatively stable in linking ability while the CG performance stayed the same. Noteworthy are the findings that the average percentages of linking while reading a text was at 67% and while speaking freely at 73%. This suggests that linking occurs with approximately equal frequency under both conditions. Melenca, furthermore, recommended that C-V and V-V linking be taught in one type of experiment, while C-C linking should be investigated in a separate study, due to the variety and complexity of C-C linking contexts.
By training EFL elementary school students in Taiwan on features of linking for 14 weeks, Kuo (2009) examined whether such training positively affected students’ speech production. After receiving instruction, the experimental group significantly improved their speech production and developed phonological awareness. Among the taught categories, V-V linking posed more problems for the experimental group due to its high degree of variance.
In spite of the positive influence of training measured immediately after the treatment, effectiveness of the training cannot be fully evaluated without examining the long-term effects of such training. Sardegna (2011) attempted to fill this gap. Using the Covert Rehearsal Model (Dickerson 1994), she trained 38 international graduate students on how to improve their ability to link sounds within and across words. A read-aloud test was administered and recorded twice during the course, and again five months to two years after the course ended. The results suggested that students maintained a significant improvement over time regardless of their native language, gender, and length of stay in the United States prior to instruction. However, other learner characteristics and factors seemed to contribute to greater or lesser improvement over time, namely (a) entering proficiency level with linking, (b) degree of improvement with linking during the course, (c) quantity, quality, and frequency of practice with linking when using the covert rehearsal model, (d) strong motivations to improve, and (e) prioritization of linking over other targets for focused practice.
The studies show that CSP training can help NNSs improve their speech production both immediately after the treatment and in delayed post-tests. More importantly, the previous studies reveal several problem areas on which researchers need to focus in order to optimize time spent in researching CSP production training. A longer period of instruction may facilitate more successful output. Practising several types of CSPs can be time-consuming and confusing to students (Melenca 2001). Finally, there is a need for exploring newer approaches to teaching CSPs that could prove to be beneficial to L2 learners.
Future research into connected speech
A more complete understanding of connected speech processes is essential for a wide variety of applications, from speech recognition to text-to-speech applications to language teaching. In English language teaching, which we have focused on in this chapter, CSPs have already been the focus of heavy attention in textbooks, much of which is only weakly grounded in research. There is a great need to connect the teaching of CSPs with research. Although we have focused on research that is connected to applied linguistics and language teaching, this is not the only place that research is being done. Speech recognition research, in particular, could be important for pedagogy in the need to provide automated feedback on production.
Previous studies suggest several promising paths for research into CSPs. The first involves the effects of training and questions about classroom priorities. It is generally agreed that intelligibility is a more realistic goal for language learners than is native-like acquisition (Munro and Derwing 1995). In addition, intelligibility is important both for acquisition of perception and for acquisition of production (Levis 2005). Most language teaching materials today include exercises on CSPs without clear priorities about which CSPs are most important. Is linking more important for spoken intelligibility than addressing insertion or deletion? We also know that CSPs can improve with training, but we do not know whether improvement increases intelligibility. Since practising many types of CSPs during the same training period can be confusing to students, CSPs that are likely to make the greatest difference should be emphasized in instruction.
Next, it is not clear if there is an optimal period of training for improvement. A longer period of instruction may facilitate more successful learning. In addition, we do not know which type of input is optimal. CSPs occur in both read and spontaneous speech, formal and informal, and for some types of CSPs there is very little difference in frequency of occurrence for both ways of speaking (Alameen 2007; Melenca 2001). The reading task approximates the spontaneous speech task in actual linking levels. It remains to be seen as to whether using read speech is best for all CSPs, or whether different types of input may serve different purposes, including raising awareness, improving perception, or improving production.
Thirdly, there is a need for exploring newer approaches to teaching CSPs that could prove beneficial to L2 learners, especially the use of electronic visual feedback (EVF). Coniam (2002) demonstrated that EVF can be valuable in raising awareness of stress-timed rhythm. Alameen (2014) demonstrated that the same kind of awareness can be developed for linking. Since pronunciation time is limited in any classroom, EVF is a promising way to promote autonomous learning of CSPs outside the classroom.
CSPs are among the most diverse, complex, and fascinating phonological phenomena, and despite inconsistent research on them, are deserving of greater attention. While these features of speech are likely to be universal, they are also language specific in how they are realized. While research into CSPs is not abundant in English, it is far less abundant for other languages. French is an exception to this rule, with research into liaison. Spanish synalepha is another documented type of CSP, but other languages have no body of research to speak of. This means that there is also a great need for research into CSPs in other languages.
REFERENCES
- Alameen, G. 2007. The use of linking by native and non-native speakers of American English. Unpublished MA thesis, Iowa State University, Ames, IA.
- Alameen, G. 2014. The effectiveness of linking instruction on NNSs speech perception and production. Unpublished doctoral dissertation, Iowa State University, Ames, IA.
- Allerton, D. 2000. Articulatory inertia vs “systemzwang”: changes in liaison phenomena in recent British English. English Studies 6: 574–581.
- Anderson-Hsieh, J., Riney, T., and Koehler, K. 1994. Connected speech modifications in the English of Japanese ESL learners. IDEAL 7: 31–52.
- Barry, M. 1984. Connected speech: processes, motivation, models. Cambridge Papers in Phonetics and Experimental Linguistics 3.
- Barry, M. 1991. Assimilation and palatalisation in connected speech. Presented at The ESCA Workshop on Phonetics and Phonology of Speaking Styles, Barcelona, Spain, 1–9.
- Best, C. 1995. A direct realist view of cross-language speech perception. In: Speech Perception and Linguistic Experience: Issues in Cross-Language Research, W. Strange (ed.), 171–204, Timonium, MA: York Press.
- Bowen, J.D. 1975. Patterns of English Pronunciation, Rowley, MA: Newbury House.
- Brent, M. R. and Cartwright, T.A. 1996. Distributional regularity and phonotactic constraints are useful for segmentation. Cognition 61: 93–125.
- Brown, G. 1990. Listening to Spoken English, 2nd edition, London and New York: Longman.
- Brown, J.D. and Hilferty, A. 1986. The effectiveness of teaching reduced forms for listening comprehension. RELC Journal 17: 59–70.
- Brown, J.D. and Kondo-Brown, K. 2006. Introducing connected speech. In: Perspectives on Teaching Connected Speech to Second Language Speakers, J.D. Brown and K. Kondo-Brown (eds.), 1–15), Manoa and Honolulu, HI: National Foreign Language Resource Center, University of Hawaii at Manoa.
- Carreira, J.M. 2008. Effect of teaching reduced forms in a university preparatory course. In: JALT2007 Conference Proceedings, K. Bradford-Watts, T. Muller, and M.S. Swanson (eds.), 200–207, Tokyo: JALT.
- Cauldwell, R. 2013. Phonology for Listening: Teaching the stream of speech. Birmingham: speechinaction.
- Celce-Murcia, M., Brinton, D.M., Goodwin, J.M., and Griner, B. 2010. Teaching Pronunciation Paperback with Audio CDs (2): A Course Book and Reference Guide, 2nd edition, Cambridge University Press.
- Clarey, M.E. and Dixson, R.J. 1963. Pronunciation Exercises in English, New York: Regents.
- Clark, J. and Yallop, C. 1995. An Introduction to Phonetics and Phonology, Oxford: Blackwell.
- Cohn, A.C. 1993. Nasalisation in English: phonology or phonetics. Phonology 10(1): 43–81.
- Coniam, D. 2002. Technology as an awareness-raising tool for sensitising teachers to features of stress and rhythm in English. Language Awareness 11(1): 30–42.
- Crawford, M.J. 2006. A study on teaching reductions perceptually. In: JALT 2005 Conference Proceedings, K. Bradford-Watts, C. Ikeguchi, and M. Swanson (eds.), Tokyo: JALT.
- Cutler, A. and Norris, D. 1988. The role of strong syllables in segmentation for lexical access. Journal of Experimental Psychology: Human Perception and Performance 14: 113–121.
- Dauer, R.M. 1992. Accurate English: A Complete Course in Pronunciation, Prentice-Hall.
- Dickerson, W.B. 1994. Empowering students with predictive skills. In: Pronunciation Pedagogy and Theory: New Views, New Directions, J. Morley (ed.), 17–33, Alexandria, VA: TESOL Publications.
- Field, J. 2003. Promoting perception: lexical segmentation in L2 listening. ELT Journal 57(4): 325–334.
- Field, J. 2008. Bricks or mortar: Which parts of the input does a second language listener rely on? TESOL Quarterly 42(3): 411–432.
- Flege, J.E. 1995. Second language speech learning: theory, findings, and problems. In: Speech Perception and Linguistic Experience: Issues in Cross-language Research, W. Strange (ed.), 233–276, Timonium, MA: York Press.
- Gaskell, M.G., Hare, M., and Marslen-Wilson, W.D. 1995. A connectionist model of phonological representation in speech perception. Cognitive Science 19: 407–439.
- Goh, C.C.M. 2000. A cognitive perspective on language learners’ listening comprehension problems. System 28: 55–75.
- Grosjean, F. and Gee, J.P. (1987). Prosodic structure and spoken word recognition. Cognition 25: 135–156.
- Hatch, E.M. 1992. Discourse and Language Education, Cambridge: Cambridge University Press.
- Henrichsen, L.E. 1984. Sandhi-variation: a filter of input for learners of ESL. Language Learning 34(3): 103–123.
- Hieke, A.E. 1984. Linking as a marker of fluent speech. Language and Speech 27: 343–354.
- Hieke, A.E. 1987. Absorption and fluency in native and non-native casual speech in English. In: Sound Patterns in Second Language Acquisition, A. James and J. Leather (eds.), Dordrecht, The Netherlands and Providence, RI: Foris.
- Ito, Y. 2006. The significance of reduced forms in L2 pedagogy. In Perspectives on Teaching Connected Speech to Second Language Speakers, J.D. Brown and K. Kondo-Brown (eds.), 17–26, Manoa, Honolulu, HI: National Foreign Language Resource Center, University of Hawaii at Manoa.
- Jenkins, J. 2000. The Phonology of English as an International Language, 1st edition, Oxford and New York: Oxford University Press.
- Kuhl, P. 2000. A new view of language acquisition. Proceedings of the National Academy of Science 97(22): 11850–11857.
- Kuo, H.C. 2009. The effect of English linking instruction on EFL elementary school students’ speech production and phonological awareness. Unpublished MA thesis, National Chung Cheng University, Chiayi, Taiwan.
- Lass, R. 1984. Phonology, Cambridge: Cambridge University Press.
- Lee, J.-T. 2012. A comparative study on the effectiveness of communicative and explicit connected speech instruction on Taiwanese EFL junior high school students’ listening comprehension. Unpublished MA thesis, National Chunghua University of Education, Taiwan.
- Lee, J.-T. and Kuo, F.-L. 2010. Effects of teaching connected speech on listening comprehension. In: Selected Papers from the Nineteenth Symposium on Englsih Teaching, 153–162.
- Levis, J.M. 2005. Changing contexts and shifting paradigms in pronunciation teaching. Tesol Quarterly 39(3): 369–377.
- Matsuzawa, T. 2006. Comprehension of English reduced forms by Japanese business people and the effectiveness of instruction. In: Perspectives on Teaching Connected Speech to Second Language Speakers, J.D. Brown and K. Kondo-Brown (eds.), 59–66, Manoa, Honolulu, HI: National Foreign Language Resource Center, University of Hawaii at Manoa.
- McClelland, J.L. and Elman, J.L. 1986. The TRACE model of speech perception. Cognitive Psychology 18: 1–86.
- Melenca, M.A. 2001. Teaching connected speech rules to Japanese speakers of English so as to avoid a staccato speech rhythm. Unpublished thesis, Concordia University.
- Munro, M.J. and Derwing, T.M. 1995. Foreign accent, comprehensibility, and intelligibility in the speech of second language learners. Language Learning 45(1): 73–97.
- Nakatani, L. H. and Dukes, K.D. 1977. Locus of segmental cues for word juncture. Journal of the Acoustical Society of America 62: 715–719.
- Norris, D. 1994. Shortlist: a connectionist model of continuous speech recognition. Cognition 52: 189–234.
- Norris, R.W. 1994. Keeping up with native speaker speed: an investigation of reduced forms and deletions in informal spoken English. Studies in Comparative Culture 25: 72–79.
- Pinker, S. 1995. The Language Instinct: How the Mind Creates Language, New York: HarperPerennial.
- Prator, C. H. and Robinett, B.W. 1985. Manual of American English Pronunciation, New York: Holt, Rinehart, and Winston.
- Reed, M. and Michaud, C. 2005. Sound Concepts: An Integrated Pronunciation Course, New York: McGraw-Hill.
- Rost, M. 2006. Areas of research that influence L2 listening instruction. In: Current Trends in the Development and Teaching of the Four Language Skills, E. Usó Juan and A. Martínez Flor (eds.), 47–74, Berlin and New York: M. de Gruyter.
- Sardegna, V.G. 2011. Pronunciation learning strategies that improve ESL learners’ linking. In: Proceedings of the 2nd Pronunciation in Second Language Learning and Teaching Conference, J. Levis and K. LeVelle (eds.), 105–121, Ames, IA: Iowa State University.
- Scheibman, J. 2000. I dunno: a usage-based account of the phonological reduction of don’t in American English conversation. Journal of Pragmatics 32: 105–124.
- Shi, R., Gick, B., Kanwischer, D., and Wilson, I. 2005. Frequency and category factors in the reduction and assimilation of function words: EPG and acoustic measures. Journal of Psycholinguistic Research 34(4): 341–364.
- Shockey, L. 1974. Phonetic and phonological properties of connected speech. Ohio State Working Papers in Linguistics 17: 1–143.
- Shockey, L. 2003. Sound Patterns of Spoken English, Malden, MA: Blackwell Publishing.
- Sinor, M. 2006. Lexical and phonotactic cues to speech segmentation in a second language. Unpublished Doctoral dissertation, University of Alberta.
- Temperley, M.S. 1987. Linking and deletion in final consonant clusters. In: Current Perspectives on Pronunciation: Practices Anchored in Theory, J. Morley (ed.), Teachers of English to Speakers of Other Languages.
- Ting, W.-Y. and Kuo, F.-L. 2012. Messages behind the unheard sounds: crossing the word boundaries through songs. NCUE Journal of Humanities 5: 75–92.
- Vandergrift, L. 2004. Listening to learn or learning to listen? Annual Review of Applied Linguistics 24: 3–25.
- Walker, R. 2010. Teaching the Pronunciation of English as a Lingua Franca, Pap/Com edition, Oxford and New York: Oxford University Press.
- Wang, Y.T. 2005. An exploration of the effects of reduced forms instruction on EFL college students’ listening comprehension. Unpublished MA thesis, National Tsing Hua University, Hsinchu, Taiwan.
- Wright, S. 1986. The interaction of sociolinguistic and phonetically-conditioned CPSs in Cambridge English: auditory and electropalatographic evidence. Cambridge Papers in Phonetics and Experimental Linguistics 5.