
27
Using Orthography to Teach Pronunciation
WAYNE B. DICKERSON
Introduction
It is hard to find a more stinging indictment of English spelling than that which opens Professor Mont Follick’s Case for Spelling Reform (1965: 1), “Our present spelling system is just a chaotic concoction of oddities without order and cohesion.” This is not a reformer’s hyperbole; the sentiment is as widespread, deeply rooted, and profoundly felt across the English speaking community today as it was 50 years ago. Word pairs like to and go, few and sew, gauze and gauge, illustrating problematic symbol–sound associations, only reinforce the skepticism among laymen and teachers alike that anything good can come of our present spelling system.
In the face of such withering criticism and public disdain for how we spell words, it might seem like a fool’s errand to suggest that English spelling can actually be a useful ally in our job of helping ESL/EFL learners improve their oral English skills. Even so, that is the intent of this chapter. It asks those who would discredit our whole writing system because of apparently anomalous spellings to suspend judgment and take a dispassionate look at how our orthography actually goes about representing English sounds. They would likely be amazed at how much valuable information can be gleaned about spoken English from its “defective” spellings.
While Morley (1994), citing Dickerson (1989, now 2004), called attending to sound–spelling relationships a “major shift in the instructional focus of ESL programs” (1994: 65), this shift has been very slow to materialize. Hahn and Dickerson (1999) show advanced learners how to use spelling to predict the major stress of words of any length. Gilbert (2001), drawing on patterns from vowel phonics that apply to one-syllable words, offers low-level learners some “… simple and efficient spelling rules to guess how a word is pronounced” (2001: x).
Much more than this can be done with spelling, as this chapter will illustrate. We begin by attempting to dispel a myth about English spelling, namely, that it represents how we pronounce words. Then we explore the areas in which ESL/EFL learners and their teachers can benefit from spelling guidance.
Representing English sounds
Conventional wisdom says that an ideal orthography should match each vowel and consonant sound (each phoneme) in the language uniquely to one letter. Russian, Spanish, Finnish, Serbian, and other languages approach this ideal. The belief that English should do the same underlies the endless roasting of English spelling for its seemingly “chaotic concoction of oddities without order and cohesion”.
If English spelling were built on the one-sound-to-one-symbol principle, our way of spelling words would deserve every criticism leveled at it. However, connecting sounds and letters one-to-one is not its dominant principle. Instead of representing sound directly, English spelling attempts to represent meaning directly. Without pronouncing these words, how do readers recognize the past-tense ending in it appealed, she recited, he politicked? The uniform -ed spelling tells us immediately. It makes no difference to readers that the -ed is pronounced /d/, /əd/, and /t/ respectively. By putting meaning first and by spelling related words and word parts similarly, the spelling system helps readers grasp by sight the semantic connection between, for example, appeal and appellation, recite and recitation, politick and politician. The fact that the ap- prefix of appeal and appellation is pronounced /ə/ and /æ/ respectively does not bother readers. We are not disturbed that the -cit- root is /ay/ in recite but /ə/ in recitation. Nor do readers hesitate over the /k/ and /ʃ/ pronunciations of the c of politick and politician respectively. In their attention to meaning, native readers are largely oblivious to the fact that the same letters are used for different sounds.
While English represents meaning directly, by-passing sound, it represents sound indirectly. The principle in play is this: whatever is predictable by rule is unwritten. To extract sound from spelling, one has to know the rule linking letters to sounds. For example, the variant sounds of -ed are unwritten because readers know that after a t or d the -ed will be pronounced as /əd/; after a vowel or voiced consonant other than d, -ed will be pronounced as /d/; and after a voiceless consonant other than t, -ed will be pronounced as /t/. The regular alternation of full vowels and the reduced vowel /ə/ in the first two syllables of these “flawed” words appeal – appellation, recite – recitation, and politick – politician also goes unwritten because the vowel alternation exactly matches the predictable alternation of stress: ˘ ˊ versus ˋ ˘ in these words. The divergent pronunciations of c are not coded in spelling because readers know that c before i and another vowel letter (e.g., -ian) is predictably pronounced as /ʃ/ but as /k/ when the c comes before another consonant letter and before the letters a, o, u (e.g., crack, cat, cot, cut) (Dickerson 1994; Kreidler 1972; O’Neil 1980).
By representing meaning directly and sound indirectly, our spellings make it inherently easier to extract meaning from written words than to extract sound. To discover sounds in spelled words, learners must use rules like those above. There is no alternative to rules; they are part of the essential nature of our spelling system. Native decoders know some of these rules by virtue of being native speakers. They have learned other rules just like non-native decoders must learn them. Unaware of the rule-mediated connection between spelling and sound and the absolute necessity of rules, textbook writers and teachers often hesitate to offer learners the rules needed to derive pronunciations from spelling. Wishing for a direct spelling–sound link, textbook writers and teachers tend to reject rules, even in a learnable form, as too complex for students. As a result, denied access to rules, their students are effectively denied access to sound via spelling, which could be a life-long resource for them.
While challenging, rule learning is not beyond the ESL/EFL student’s capability when they use learner rules, specially designed formulae (illustrated below) that take into account the learner’s limitations (Dickerson 2012). Fixated on anomalies, detractors of spelling often fail to appreciate that English spelling does an amazingly good job preserving all the structural information necessary for learner rules to work well – prefix, stem, and suffix identities, syllable count and syllable structure, and even cues to guide the selection of symbols for consonant and vowel segments. Even “sight words”, which defy decoding strategies in some respects (Otto and Chester 1972) and are parceled out to elementary school children to memorize, are not chaotic. Except for words like one, once, those with silent letters like talk, could and those with anomalous gh spellings, even sight words have consonant letters where consonant sounds are and vowel letters where vowel sounds are.
An assessment of how well-formed English spelling is depends on the yardstick used. Clearly direct symbol-sound connections will not do. Instead, the assessment tool must gauge English spelling according to principles at work in the system: (a) How well does spelling preserve visual evidence of the semantic connections among related words (meaning-first principle)? (b) Is the information in spelling rich enough that learner rules can apply to generate conventional pronunciations (sound-second principle)? This is precisely the metric that Chomsky and Halle used when concluding that standard orthography is remarkably close to an ideal representation of English words (1968: 48–49, 96, 184n).
With that endorsement of our spelling system, we turn now to the role that English spelling can play in the learner’s developing sound system and to examples of learner rules that can make available valuable pronunciation clues.
Orthography for prediction
Attention to spelling can be of use in pronunciation teaching and learning to the extent that it helps teachers and learners realize goals they value. We understand of course that good production skills underlie good communication. Equally important is an ability to hear what is said to us so that we can interpret the messages sent. Good perception skills are likewise essential. Less widely appreciated, but no less fundamental to communication, is the ability to make good judgments before speaking about what to say in each area of production. Good prediction skills make possible good production and perception. These three skills – prediction, production, perception – are what we call the 3Ps (Dickerson 2004: Unit 1, 8). Since we value these skills as fundamental to communication, and since our basic objective in teaching pronunciation is to help learners develop intelligible oral communication, we take the 3Ps as our pronunciation-teaching goals.
Of these three goals, the use of orthography serves prediction most directly and, through prediction, it serves production and perception. The use of orthography for prediction has its place principally in a strategy chain we call covert rehearsal, in which learners privately inspect their oral utterances, evaluate them against rules they know and models they have learned, correct them, and then practise their corrections until they can say them fluently and accurately (Dickerson 2000). To use orthography in this way, learners need to know useful patterns they can apply to spelled words. They also need to learn how to use this strategy chain effectively. The effort to equip learners with internal resources – providing rules, models, and practice with the strategy chain – is important because long-term pronunciation improvements can result from using these resources (Sardegna 2009).
Predicting consonant choice
If there is one area of phonology that is iconically identified with pronunciation teaching it is the area of segmentals – the vowels and consonants that make up each word. Their claim to fame is that they do the work of distinguishing one word from another. They keep useful from sounding like youthful and mislaid from sounding like misled. Segmentals that do this kind of work are called phonemes. That is why phonemes are so central to pronunciation teaching.
Predicting consonant phonemes via orthography is different from predicting vowel phonemes. That is because consonant choice is not so tightly bound to the stress of a word as vowel choice is. Even so, decoding consonant letters and letter combinations is not straightforward.
Learners who anticipate being able to judge consonant sounds directly from consonant spellings will be disappointed. Only half of the consonant letters in the alphabet point unambiguously to a single consonant phoneme: b, f, j, k, m, p, q, r, v, and z. The other half have no such immediate connection to a consonant phoneme. To these we can add letter combinations such as ch, sch, gh, sh, th, ng, ps, and pt. Only ph, wr, mb, mn, pn, and kn reliably point to only one phoneme each.
While there are some direct symbol-to-sound connections among consonants, the great majority of letter-to-sound connections are indirect, requiring the use of rules to determine the phonemic value of a letter or letter combination. That is, most letters are busy implementing the meaning-first principle, identifying for the eye of the reader the semantic relatedness of words such as political and politician. For readers to extract a pronunciation from such spellings, the visual shape of the words must preserve enough information that the rules of the sound-second principle can generate a pronunciation successfully.
Clues to the sound value of a graphic unit (letter and letter combinations) are to be found in the environment surrounding the letter – its neighboring letters, nearby endings, its position in a word, degrees of stress on adjacent vowels, or a combination of these clues. An analysis of the c in words like politician, political; electrician, electricity, electric reveals these regularities, with the most specific rule given first and the most general given last. The rules form an ordered set:
| Sound | Environment | Examples |
| /ʃ/ | c+iV-ending | iV-endings are strings like -ia, -ion, -ial, -ious, -ient. |
| e.g., acacia, suspicion, official, gracious, efficient | ||
| /s/ | ce/i/y | The / means “replace the letter on the left with the letter on the right”, which gives us ce, ci, cy, |
| e.g., ceiling, peace, city, deficit, cypress, mercy | ||
| /k/ | celsewhere | “Elsewhere” means “not in the above environments”, |
| e.g., call, stack, active, traffic |
The sound-second principle says that a graphic unit in a word context predicts its sound value. Since this is the way our orthography works, we have designed prediction rules for learners around this principle. Based on the analysis above, learner rules for the consonant letter c are the following, to be used in this order:
| A graphic unit in context | predicts | its sound value |
| c+iV | = | /ʃ/ |
| ce/i/y | = | /s/ |
| cew | = | /k/ |
Consonant prediction patterns such as these are also written to conform to the characteristics of a good learner rule (Dickerson 2012). One feature of a good learner rule is that it is stated succinctly enough that it can be practised easily in written exercises, ideally in coordination with articulatory work on one of the key segmental targets. For example, the above patterns can be presented when working on palatal consonants, thereby joining prediction to production and perception work.
To illustrate learner rules for a consonant letter combination, we can look at the interpretation of the th spelling, troublesome for learners of English trying to articulate the difference, and even for native speakers of English trying to tell the difference between /θ/ and /ð/:
| A graphic unit in context | predicts | its sound value |
| thVf | = | /ð/ |
| thern/∙ | = | /ð/ |
| V/rth+E | = | /ð/ |
| thew | = | /θ/ |
The consonant eth (/ð/) occurs almost exclusively among native Anglo-Saxon words; words borrowed from Greek and elsewhere entered the language with /θ/. Despite the borrowings, the environments are sufficiently distinct that only a dozen out of about 800 th words cannot be predicted by the rules above. The first rule says that when th is followed by a vowel letter in a function word (f), the phoneme value of th is /ð/, as in the, this, them, although. The second rule says that when we see a thern string or a ther∙ string, the th should be pronounced as /ð/, as in northern, farther, bothered. (The ∙ symbol stands for end of word or before an ending like -e, -ed, -ing.) The third rule applies to Vth or rth followed by an ending (E) such as -e, -ed, -ing. Again, the predicted phoneme value of th is /ð/, as in farthing, bathe, seethed. The last rule tells us that every other instance of th should be pronounced as /θ/. These patterns can be practised in written exercises when teaching /θ/ and /ð/ (Dickerson 2006).
Predicting major word stress
Without accent marks in standard written English, or a uniform stress-placement rule, an English text tells us nothing directly about where the stressed and unstressed vowels are. For example, nothing in the words colony and colonial indicates that the first two o letters in colony are stressed and unstressed and that the first two o letters of colonial are unstressed and stressed. Consistent with the nature of English orthography, the stress of a word can be ascertained only indirectly by rule.
An indirect approach to word stress should not deter us; word stress is too important to be ignored. It is a subsystem that supports the entire structure of phonology. Fortunately, it is also a part of phonology that can be predicted using learner rules that apply to standard orthography.
Wherever the major stress of a word falls on a polysyllabic word, it creates one of three possible word-rhythm patterns in English relative to the peak: peak-valley (e.g., cómplicated), valley-peak-valley (e.g., persecútion), or valley-peak (e.g., represént). Major stress on the right syllable, creating the right rhythm, makes a spoken word intelligible. On the wrong syllable, creating an unexpected rhythm, it may obscure its meaning entirely (Field 2005).
Most importantly for interpersonal communication, major word stress has the potential to contribute a meaningful peak to the discourse, thereby adding substantially to the listener’s understanding of the message. A peak has the power to signal, however, largely because it contrasts with surrounding valley syllables. That is, for maximal effect, it is not enough for teachers and learners to focus on peaks and ignore nearby valleys. Both are equally important, which is why contrast is such a fundamental feature of oral communication.
Understanding the importance of word stress, generations of ESL/EFL teachers and textbook writers have tried to help. With no simple way to determine the location of a word’s major stress, they have offered a variety of partial solutions: citing statistical guidance (Prator and Robinett 1972), suggesting that the practice of words with particular patterns will help the pattern “rub off” (Trager and Henderson 1957), offering endings where stress can be predicted reliably, e.g., -ion, etc. (Woods 1979). While helpful, none of these approaches adds up to a systematic or comprehensive way to stress all, or even a useful majority of, the words in English.
The only fully developed word-stress prediction system yet available to ESL/EFL learners is that found in Dickerson (2004), which was strongly influenced by the research of Chomsky and Halle (1968). Others have also worked profitably in this arena (Guierre 1984; Teschner and Whitley 2004). The broad outlines of the prediction system in Dickerson (2004) are presented to illustrate what can be done.
To understand the rule system, we need to recognize that, regardless of the length of a polysyllabic word, it will carry its major stress on only one of two syllables, either on the Key Syllable or on the Left Syllable. These two syllables can be identified unambiguously in spelling terms for every polysyllabic word. For example, the Key Syllable (as underlined) is immediately to the left of particular endings, e.g., punit(ive, regul(atory, compass(ionately. Sometimes, if there is no ending, the Key Syllable is the last syllable, e.g., underdevelop, disregard, or the next-to-the-last syllable, e.g., maverick, astronaut, depending on the part-of-speech. The Left Syllable is always immediately to the left of the Key Syllable. The fact that there are only two candidates for major stress – the Key and Left Syllables – and that both are easy to locate in any word hugely reduces the chances of putting the stress on the wrong syllable. The role of the four word-stress rules in Dickerson (2004) is to reduce those chances to almost zero.
The four word-stress rules start at the Key Syllable; two rules focus on the Left Syllable and two focus on the Key Syllable. Of the two rules focusing on the Left Syllable, one places stress directly on that syllable (Left Stress Rule). The other examines the composition of the Left Syllable (whether or not any part of a prefix is present) to determine whether the stress should go on the Key Syllable or on the Left Syllable (Prefix Stress Rule). Of the two rules focusing on the Key Syllable, one is designed to place stress directly on that syllable (Key Stress Rule). The other examines the composition of the Key Syllable (its syllable structure) to determine whether the stress should go on the Key Syllable or on the Left Syllable (V/VC Stress Rule). The focus of each rule and its way of assigning stress are depicted in the following summary where SR stands for “stress rule”. Among the four stress rules, the major stress of every English word is accounted for with few exceptions.

Within this structure, the learner’s prediction task involves answering three questions:
- Which rule applies to a word?
- Where is the Key Syllable?
- Where does the rule place major stress, on the Key or Left Syllable?
Years of empirical research have answered the first question. The Key Syllable is defined by each rule. As indicated, the position of the Left Syllable is derived from the position of the Key Syllable. The rule then applies to place the major stress on the Key or Left Syllable.
To provide a sense of how the rules actually work, and to show that the rules are not difficult to use, we will illustrate the Left Stress Rule and the V/VC Stress Rule as each applies to a narrowly defined word group. One rule focuses on the Left Syllable and the other on the Key Syllable. One rule places stress directly and the other places stress by evaluating the composition of a syllable.
The Left Stress Rule applies to words that end in -ate and derivatives (-ates, -ated, -ating, -ator). These words have two or more syllables left of the ending (Q1). The Key Syllable (underlined in the examples) is immediately to the left of the ending (Q2). The Left Syllable is left of the Key Syllable. The Left Stress Rule places stress on the Left Syllable (Q3):
Examples of Stress Left: cónfisc(ated, indiscrímin(ate, démonstr(ator, commúnic(ating
The V/VC Stress Rule applies to words that end in -ous (Q1). The Key Syllable (underlined in the examples) is immediately to the left of the ending (Q2). The Left Syllable is left of the Key Syllable. The V/VC Stress Rule places stress by evaluating the Key Syllable: Is it spelled with a single vowel letter (V) or a single vowel letter followed by a single consonant letter (VC)? If so, stress the Left Syllable. If not, stress the Key Syllable (Q3):
Examples of Stress Left: impétu(ous, ambígu(ous, húmor(ous, anónym(ous
Examples of Stress Key: treménd(ous, momént(ous, polymórph(ous, disástr(ous
This word-stress system empowers learners with the internal resources to stress tens of thousands of words with great accuracy. Stress exceptions in each word group are usually under 1%. Even so, the rules must be used selectively because time allotted for attention to pronunciation is always limited. For all learners, including those who cannot take full advantage of this resource, what are the most important take-aways about English word stress? These stand out.
- The major stress of a word is predictable.
- The major stress will fall on the Key or Left Syllable.
- The major stress creates one of three rhythms in every polysyllabic word. (Practice identifying the rhythm pattern of polysyllabic words is worthwhile.)
- The location of the Key Syllable is predictable, usually just to the left of an ending. (Time spent finding the Key Syllable in different word groups is time well spent.)
- The Left Syllable is always immediately to the left of the Key Syllable.
- Finding the Key and Left Syllables can limit stress guessing. (Hearing stressed words and saying words with the stressed vowel marked can improve guessing.)
- Stress rules are so straightforward that post-puberty learners can learn to use them even on their own if they wish. (Well-structured materials can help, e.g., Hahn and Dickerson 1999.)
Predicting major-stressed vowels
Efforts to predict vowel sounds from spelling have been part of pronunciation instruction for many decades (Prator 1951; Vernick and Nesgoda, 1980; Guierre 1984; Gilbert 2001). That in itself is a testament to the fact that there are useful regularities in how spellings point to sounds.
Vowel prediction, like consonant and word-stress prediction, follows the sound-second principle: A graphic unit in context predicts its sound value. A graphic unit is a single vowel letter or a letter combination. Its context in a word must include those factors that are relevant to the language. To do a good job, a vowel prediction pattern must take into account word stress, neighboring letters, and position in a word.
A learner rule incorporates all three conditions. On the left of the pattern, left of the = mark, is a vowel letter or a general stand-in for a vowel letter, V, in its relevant context, and on the right is the predicted vowel phoneme or a vowel quality. Two vowel patterns illustrate the presence of the three essential ingredients of context (Dickerson 1980):
| A graphic unit in contex | predicts | its sound value |
| úC← | = | tense |
| V´C← | = | lax |
For both, the syllable in question carries major stress, as determined beforehand by a stress rule. This syllable consists of a single vowel letter followed by a single consonant letter. The first pattern applies exclusively to the letter u; the second case is not specific to particular vowel letters. The left-pointing arrow designates the syllable in each case as the Left Syllable. On the right, the first pattern predicts a tense vowel, namely, /uw/. The second pattern reliably predicts a lax vowel. These are ordered rules. That is, the first and most specific rule filters out u cases; the second, more general, rule applies to all other vowel letters. The first rule tells us that the uC Left Syllables in púnitive, commúnicating, and húmorous (all mentioned above) should be pronounced as /uw/. The second rule tells us why the vowel letter in the stressed VC Left Syllables of cólony, démonstrator, and ambíguous (all mentioned above) have lax vowels. A full presentation of vowel rules such as these, designed for ESL/EFL learners, is given in Dickerson (2004), including the tool needed to translate “tense” or “lax” into a specific vowel prediction (see also Dickerson 2012).
After assigning the major stress to one syllable of a word, predicting vowels left of the major stress is a much easier task. Left of the major stress, we can predict the stress and vowel quality simultaneously. The complete system is presented in Dickerson (2004).
Predicting compression
Good rhythm when speaking English promotes intelligibility. Rhythm, however, is not a single phenomenon but a collection of phenomena that can be grouped into two meaning-based categories – contrast and compression. Contrast is the difference between peaks – longer, louder, and higher-pitched vowels – and valleys – shorter, quieter, and lower-pitched vowels – in a phrase. Compression refers to the many ways we abbreviate valley syllables across a phrase – those in function words and content words alike. In focus here is the feature of compression.
We use peaks to highlight words that carry more significant meaning (typically content words and certain function words) and valleys for words of less significance. In a typical phrase of one or two peaks, the majority of syllables are in valleys (Bolinger 1986: 47–48). English speakers not only highlight the peaks by contrasting them with surrounding quieter, briefer, and lower-pitched valleys but they also hurry the less significant valley words along. They use a variety of devices to minimize the vowels and consonants of these syllables. The effect is to draw the peaks closer together, as listeners expect. By meeting this expectation, speakers enhance their intelligibility. We can capture the compression devices we use, in the order we use them in speech, in this convenient acronym: NATRL – native assimilation, trimming, reduction, and linking.
NATRL devices are accessible to learners in part because English orthography faithfully represents the structure of spoken syllables, using consonant letters for consonant sounds and vowel letters where vowel sounds belong. Compression devices are also accessible because learners can easily understand the rules that apply to these spellings. The combination of a rich orthography, learner-oriented rules, and the high-value feature of good compression make NATRL devices an ideal starting point for using ordinary spelling to improve the clarity of learners’ spoken language. The most important native-English compression devices are the following (Hahn and Dickerson 1999):
-
In American English, palatal assimilation compresses two segments, an alveolar nonsonorant (/t/, /d/, /s/, /z/) and a palatal glide /y/ (at the start of you, your, yourself) into a single palatal segment /ʧ/, /ʤ/, /ʃ/, and /ʒ/ respectively.
-
/ʧ/ Do it ͜ yourself! He guessed ͜ your secret. /ʤ/ You included ͜ yourself. Would ͜ you help me? /ʃ/ Can you dress ͜ yourself? Try to trace ͜ your roots. /ʒ/ It taxes ͜ your brain. Whatever pleases ͜ you!
-
-
Trimming is the complete loss of a vowel or consonant segment. Five types of trimming save valley time. In describing trimming, we use an apostrophe to mark the position of the loss.
Loss of /t/ and /d/ from Ct and Cd clusters. This loss happens when a consonant (but not w, h, y, or r) follows the cluster. All Ct and Cd clusters are affected by trimming except lt, nt, rt, rd, and r-ed. Most examples occur at word boundaries, e.g., mos’ people, kep’ singing, mov’(ed) quickly. However, /t/ and /d/ will also be lost between word parts, e.g., han’some, cos’ly, enac’ment.
Loss of consonants and vowels from contractions. Contractions commonly trim some portion of eleven function words (am, is, has, are, did, had, would, have, will, us, not): I’m, she’s here, she’s gone, you’re, he’d go, he’d gone, where’d he go? we’ve, they’ll, let’s, can’t. The apostrophe indicates that a loss has occurred. It does not identify what has been lost – a vowel sound, a consonant sound, or both. Nor does it suggest how to pronounce the remainder. Depending on the word it is attached to, a contraction may have two or three different pronunciations.
H-loss from he, him, his, her, have, has, had. When not at the start of a phrase nor under primary stress, the /h/ of these seven function words will drop away. An eighth instance of h-loss happened to the ancient form of them, hem, and continues to the present as ’em (Pyles 1964: 334), e.g., Tell ’im about it. I should ’ave warned you. Go get ’em!
Vowel loss with a syllabic consonant. In a string of two syllables where the first is stressed and the second is unstressed, the vowel of the second syllable will drop away most commonly when the first syllable ends with /t/ or /d/ and the first consonant after the next vowel is /l/ or /n/. The /l/ or /n/ that remains carries the beat; it becomes the center of the syllable (“syllabic”) like the vowel that has been lost, e.g., met’l, id’l, sent’nce, gard’n.
Vowel loss without a syllabic consonant. In a string of three syllables where the first is stressed and the next two are unstressed, the middle vowel will drop away most often before a single /n/, /l/, or /r/ consonant, e.g., comp’ny, fam’ly, ev’ry.
-
Reduction preserves the segment but shrinks its size. The most important reduction is vowel reduction. While all valley vowels are reduced in size, the most common reduced vowel is the schwa [ə]. Reduced valley vowels are so important that they are required; all the other NATRL devices are optional. They are important because they alone serve two functions. They contrast with peaks to make peaks stand out. For example, in the following sentence, -vent- and min- stand out in part because they are surrounded by valley vowels. Reduced vowels also do more to speed up valley syllables than any of the other devices because there is a reduced vowel in almost every valley syllable. In this example, there are eight valley vowels to two peak vowels.

In its work on behalf of compression, vowel reduction gets help from consonant reduction in American English. Oral and nasal flaps reduce the size of /t/, /d/, /n/, and /nt/ to a fraction of their nonflapped duration. This happens mostly when these segments come between stressed and unstressed vowels or between two unstressed vowels, as we hear in these parts of the sentence above: -vented, -ed a, -ini, -atte-.
-
While all adjacent segments in a phrase are close together, only a few interact with each other to shorten their overall articulation time. We refer to four cases that interact this way as linking.
-
C ͜ Csame Linking between identical continuants simply continues the first consonant a little longer, e.g., yes ͜ sir!, a rough ͜ few days, the same ͜ moment. Linking identical stops involves holding the stoppage a little longer, e.g., rob ͜ banks, not ͜ talking, a big ͜ group. Cst ͜ Cst/af/nas When a stop is adjacent to a different stop, an affricate, or a nasal, the air of the first stop is not released until the tongue shifts to the new position. This happens between words, as in back ͜ pain, good ͜ morning. It also happens within words, as in elec͜tive, ab͜normal, mag͜nificent. C ͜ V/w y r/ The consonant at the end of a word seems to attach itself to the vowel, /w/, /y/, or /r/ at the start of the next word, e.g., ask ͜ about, closed ͜ it, the best ͜ way, some ͜ years ago, a pack͜rat. 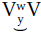
Except for word-final schwa, all other word-final vowels use their off-glides (/-w/, /-y/) as a bridge to a vowel-initial word, e.g., go ͜ on, fly ͜ over. The glide moves to the next syllable. This process is also seen inside words where two vowel sounds juxtapose, e.g., the͜ology, mighti͜er, co-͜author, tu͜ition.
A concentration on linking is particularly important for students who insert a glottal stop (a “throat stop”) [ʔ] before every vowel-initial word and for those who insert a schwa [ə] between the consonant end of one word and the consonant start of another. Without the help of linking, their speech stream sounds choppy and is distracting to the listener. Fortunately for such students, ordinary spelling represents the relevant segments accurately enough that they are able to identify types of linking with a high level of accuracy.
-
Learners have the advantage that most of these devices are presented in modern pronunciation textbooks (Weinstein 2001). Good discussions are also available in teachers’ guides (e.g., Celce-Murcia, Brinton, and Goodwin 2010: 163–184). While their use is encouraged in order to sound more natural and friendly, they are worth teaching, especially because they meet listeners’ expectations.
Predicting suffix forms
In our prefix-stem-suffix language, endings abound. How we say them makes a difference, particularly if they carry significant grammatical information. As we have come to appreciate, our spelling system preserves each ending in a uniform graphic shape regardless of how it is pronounced. Fortunately, the rules needed to give them a pronunciation are not complex.
The most important endings for learners are -ed and -s because of the information load they carry. The -ed marks the past tense and past participle verb, and derivative nouns and adjectives: They dedicated the park, She has dedicated her life to service, These are the dedicated, They are so dedicated.
The -s endings, -’s genitive, and -’s contractions are used to make nouns plural and possessive, verbs third-person present tense, and to shorten is, has, and us, e.g., my sisters, my brother’s wife, she works, she’s working, she’s been living, let’s go.
Most of the -ed, -s, and -’s meaning units have potentially three forms each, /t/, /d/, /əd/ and /s/, /z/, /əz/. We know, however, that the exact voicing of the single-sound variant is not crucial for intelligibility as long as the voiced or voiceless variant is present. By removing the voicing decision (/t/ versus /d/ and /s/ versus /z/), we can simplify the three-way decision to a two-way decision and improve the learner’s accuracy (Dickerson 1990).
The decision procedure uses orthography in place of sound as the basis for prediction. The rules are straightforward and highly reliable:
- Pronounce -ed as /əd/ after a stem ending in t or d. Pronounce all other cases of -ed as /t/ or /d/, e.g., patented, decided, preached, sneezed.
- Pronounce -s and -’s as /əz/ after a stem ending in a clue letter (e.g., ce, ge, s/se, z/ze, ch/che, sh/she, x/xe). Pronounce all other cases of -s and -’s as /s/ or /z/, e.g., changes, Chase’s, grips, Pat’s, homes, Nora’s.
It is good to remember that these patterns do not exist in isolation. As illustrated in the preceding section on predicting compression, the -ed, -s, and -’s patterns predict segments that are subject to palatal assimilation (You included ͜ yourself, It taxes ͜ your brain) and linking (closed ͜ it, years ͜ ago). Furthermore, -ed has forms that can undergo cluster trimming (mov’(ed) quickly).
Predicting variability
With no single standard for educated pronunciation, English speakers are not uniform in the phonemes they use for some words. Depending on their dialect, we hear educated speakers say class with /ɑ/ and /æ/, garage with /ʤ/ and /ʒ/, roof with /uw/ and /ʊ/, and where with /hw/ and /w/. The unspoken protocol among educated speakers is the Golden Rule: give others the same latitude to use their own variants as we expect others to give us. We find it entirely justified to extend the same accommodation to learners of English. That is, we do not insist that learners settle on a single pronunciation for class, garage, roof, or where. We allow, even encourage, them to select the educated variant that they find easiest to pronounce, even if it is different from the teacher’s usage.
To implement this policy toward variability, ESL/EFL teachers need to know where educated speakers use different pronunciations for the same word. This is not hugely challenging for teachers because variability is largely regular, being governed by environment. The same spelling-based patterns that describe consonants, word stress, vowels, and compression also describe the variability in each area.
For example, among consonants, by knowing that wh = /hw/ or /w/, we can tell that words like when, where, and why will be pronounced acceptably as /hw/ or /w/. Speakers of British English prefer major stress on the second syllable of two-syllable -ate verbs, whereas speakers of American English prefer it on the first syllable, e.g. rotáte versus rótate. The majority of phonological variability is found among vowels. Vowel prediction patterns reflect that variation. For instance, aˊu = /ɑ/ or /ɔ/ tells us that educated speakers may pronounce daughter and cause in two different ways. We regularly hear phonological variability among NATRL devices because all compression devices except vowel reduction are inherently variable. Educated speakers are not obliged, for example, to use palatal assimilation when saying I miss you, nor must they drop the middle vowel of company to make it comp’ny. The presence of phonological variability is identified in all the prediction patterns presented in Dickerson (2004).
The practical ramifications of having access to phonological variability are that we can implement a policy of tolerance toward educated variability in our pedagogical materials, our teaching, and our correction. In NATRL areas where variability is the norm, we inform learners about their range of options, when each option is appropriate to use, and encourage learners to use them when they can. In other areas where there are variable and nonvariable words, the approach is to teach the target segment or stress pattern using nonvariable words and to leave variable words to be treated as a separate group in which we monitor learners’ pronunciation to see that it is within the range of acceptable variation. By being able to identify exercise items in which variability exists, we can also more easily inform our students about where different variants are available to them. Finally, when we monitor and correct our students’ production, we know where to offer leeway for alternate pronunciations among variable words and where to insist on a particular target among nonvariable words (Dickerson 1977).
Conclusion
The value to learners of knowing how to use standard orthography to predict the sounds of spoken English is enormous. That is why the loss to learners is equally great when we do not take the time to show them how to use this valuable resource for their benefit (Hill and Beebe 1980; Kreidler 1972).
One source of reticence on the part of teachers may be their deep-seated distrust of our spelling system, perpetuated by a drumbeat of largely misplaced criticism about how poorly it represents spoken words. To help teachers get beyond this barrier and come to appreciate the wealth of guidance that spelling can provide, this chapter opened with a direct challenge to conventional thinking about how English orthography actually works despite its admitted infelicities.
The message is simple: English spelling does not work the way people think it should, namely, based on straightforward spelling-to-sound correlations. Instead, first and foremost, words are spelled to communicate meaning to the eye of the reader. It does this directly by using similar spellings for related words, e.g., write, writ, writing, written, wrote, and different spellings for unrelated words, e.g., write, right, wright, rite. This is the operation of the meaning-first principle. Only secondarily and indirectly does spelling signal a pronunciation to the mouth of the reader. The sound-second principle works only by means of rules that readers bring to the task, e.g., wr = /r/; igh = /ay/.
With the inner workings of English orthography exposed, this chapter proceeded to show that English spelling is much more consistent than expected and much more valuable to learners who want to improve their spoken English than has been supposed. The learner rules we have presented are evidence of these claims.
We close with two cautions to the teacher. Firstly, rule-based prediction of sound from spelling is not an approach about which the teacher must decide: Do I buy in or opt out? It is not a monolithic system but a collection of many useful subsystems. Each subsystem can stand largely on its own and be integrated into pronunciation instruction without the teacher having to commit to any other parts of the system.
Secondly, it is important that teachers be realistic in what can be achieved. Since learners must access sound information indirectly through rules, prediction skills cannot be developed quickly. This means that teachers must be strategic in selecting the prediction subsystems they teach so that learners will have time to accumulate prediction skills in areas of their greatest need.
The richness of our orthography and the clarity of learner rules should be sources of encouragement to teachers and learners alike. Any part of the prediction system that we can offer our students makes their prospects brighter because that part will become an internal resource for self-monitoring, self-correction, and self-practice as they continue to improve their oral accuracy and fluency after formal instruction ends.
REFERENCES
- Bolinger, D. 1986. Intonation and Its Parts, Stanford, CA: Stanford University Press.
- Celce-Murcia, M., Brinton, D., and Goodwin, J. 2010. Teaching Pronunciation: A Course Book and Reference Guide, 2nd edition, Cambridge: Cambridge University Press.
- Chomsky, N. and Halle, M. 1968. The Sound Pattern of English, New York: Harper & Row.
- Dickerson, W. 1977. The problem of dialects in teaching pronunciation. English Teaching Forum 15(2): 18–21.
- Dickerson, W. 1980. Bisyllabic laxing rule: vowel prediction in linguistics and language learning. Language Learning I: 317–329. (Erratum, Language Learning 31: 283, 1981.)
- Dickerson, W. 1990. Morphology via orthography: a visual approach to oral decisions. Applied Linguistics 11: 238–252.
- Dickerson, W. 1994. How English orthography really works. In: Current Trends: New Approaches to EFL Teaching, C. Dirksen (ed.), 89–95, English Language Institute/China.
- Dickerson, W. 2000. Covert rehearsal as a bridge to accurate fluency. Paper read at the 34th Annual TESOL Convention and Exposition, March 18, 2000, Vancouver, BC, Canada.
- Dickerson, W. 2004. Stress in the Speech Stream: The Rhythm of Spoken English, Urbana, IL: University of Illinois Press [CD-ROM]. Available from: [email protected] (Original work published 1989).
- Dickerson, W. 2006. A is for Alphabet … Roman letters and their use in written English. Educators and Education Journal 21: 1–21.
- Dickerson, W. 2012. Prediction in teaching pronunciation. In: The Encyclopedia of Applied Linguistics, C.A. Chapelle (ed.), Hoboken, NJ: Blackwell Publishing Ltd. http://onlinelibrary.wiley.com/doi/10.1002/9781405198431.wbeal0950/full.
- Field, J. 2005. Intelligibility and the listener: the role of lexical stress. TESOL Quarterly 39: 399–423.
- Follick, M. 1965. The Case for Spelling Reform: With a Foreword by Sir William Mansfield Cooper, Manchester University Press.
- Gilbert, J. 2001. Clear Speech from the Start, Cambridge: Cambridge University Press.
- Guierre, L. 1984. Drills in English Stress-Patterns, 4th edition, Paris: Armand Colin-Longman.
- Hahn, L. and Dickerson, W. 1999. Speechcraft: Discourse Pronunciation for Advanced Learners, Ann Arbor, MI: University of Michigan Press.
- Hill, C. and Beebe, L. 1980. Contraction and blending: the use of orthographic clues in teaching pronunciation. TESOL Quarterly 14: 299–323.
- Kreidler, C. 1972. Teaching English spelling and pronunciation. TESOL Quarterly 6: 3–12.
- Morley, J. 1994. A multidimensional curriculum design for speech-pronunciation instruction. In: Pronunciation Pedagogy and Theory, J. Morley (ed.), 64–91, Alexandria, VA: TESOL.
- O’Neil, W. 1980. English orthography. In: Standards and Dialects in English, T. Shopen and J.M. Williams (ed.), 63–83, Cambridge, MA: Winthrop Publishers, Inc.
- Otto, W. and Chester, R. 1972. Sight words for beginning readers. The Journal of Educational Research 65: 435–443.
- Vernick, J. and Nesgoda, J. 1980. American English Sounds and Spellings for Beginning ESL Students, Pittsburgh, PA: University Center for International Studies.
- Prator, C. (1951). Manual of American English Pronunciation for adult foreign students, New York: Rinehart & Company, Inc.
- Prator, C. and Robinett, B. 1972. Manual of American English Pronunciation, New York: Holt, Rinehart and Winston.
- Pyles, T. 1964. The Origins and Development of the English Language. New York: Harcourt, Brace & World, Inc.
- Sardegna, V. 2009. Improving English stress through pronunciation learning strategies. PhD dissertation, University of Illinois at Urbana-Champaign (UMI No. 3363085).
- Teschner, R. and Whitley, M.S. 2004. Pronouncing English: A Stress-Based Approach, Washington, DC: Georgetown University Press.
- Trager, E. and Henderson, S. 1957. Pronunciation Drills for Learners of English, Washington, DC: American University Language Center.
- Weinstein, N. 2001. Whaddaya Say? 2nd edition, New York: Addison Wesley Longman.
- Woods, H. 1979. Syllable Stress and Unstress, Hull, Quebec: Canadian Government Publishing Centre.