
28
Technology and Learning Pronunciation
REBECCA HINCKS
Introduction
The use of technology for training pronunciation has been praised for being consistent and tireless from the time of the early phonograph to the present (e.g., Clarke 1918; Engwall et al. 2004; Levis 2007). Language educators have long been called early adaptors of new technologies (Last 1989; Roby 2004). Edison’s phonograph, first commercially marketed in the 1880s, was put to use for language learning purposes as early as 1893 (Léon 1962), and its successor, the gramophone, went on to be used for the provision of native-speaker pronunciation models throughout most of the twentieth century. The introduction of magnetic tape and tape-recording machines in the period following World War II allowed the development of language laboratories (Hocking 1954), where students sitting in isolated booths or carrels could listen to speaker models and record their own pronunciations. Digital technologies were used for language learning starting in the 1960s with the PLATO project, where by the end of the 1970s over 50 000 hours of language training in a dozen languages had been developed (Hart 1995). These early computer-assisted language-learning projects had limited capacity to provide oral and aural training, but when personal computers began to be equipped with audio input and output capacity in the 1990s, learners became able to record and listen to their own versions of modeled pronunciations. Though the first pronunciation software used the computer as little more than a record-and-playback device, steps had been taken toward creating systems to provide automatic feedback on pronunciation quality.
Good computer-assisted pronunciation training (CAPT) systems can allow training to be individualized and maximized. Specific exercises can be selected to meet a learner’s particular problems. The opportunity to practise is not limited to the time a teacher is available, and since a computer is infinitely patient, the time on task can be increased. However, it can be difficult to fit CAPT into a theoretical framework of how language learning best takes place. In general, computers lend themselves most naturally to the kind of training advocated by audiolingual theorists: drills, repetitions, and mimicry. The theories of the communicative approach to language learning are harder to put into practice. Further advances in artificial intelligence are necessary before computers can offer an environment that can be said to truly either “communicate” or “negotiate” with a learner, though research in creating spoken dialogue systems for language learning is underway. In future systems, mispronunciation could be part of the reason for a breakdown in communication, thus pushing students to focus on their pronunciation while providing an imitation of the “negotiation of meaning” that takes place between humans.
CAPT systems ideally use speech technology to give feedback on pronunciation. The three main components of speech technology are speech analysis, speech recognition, and speech synthesis. Speech analysis provides an acoustic analysis of the speech signal, usually in the form of a visualization of the speech waveform, spectrogram, and pitch contour. Freely available tools that provide speech analysis are, for example, Praat (Boersma and Weenink 2010) and WaveSurfer (Sjölander and Beskow 2000). An example of a WaveSurfer analysis is shown in Figure 28.1.
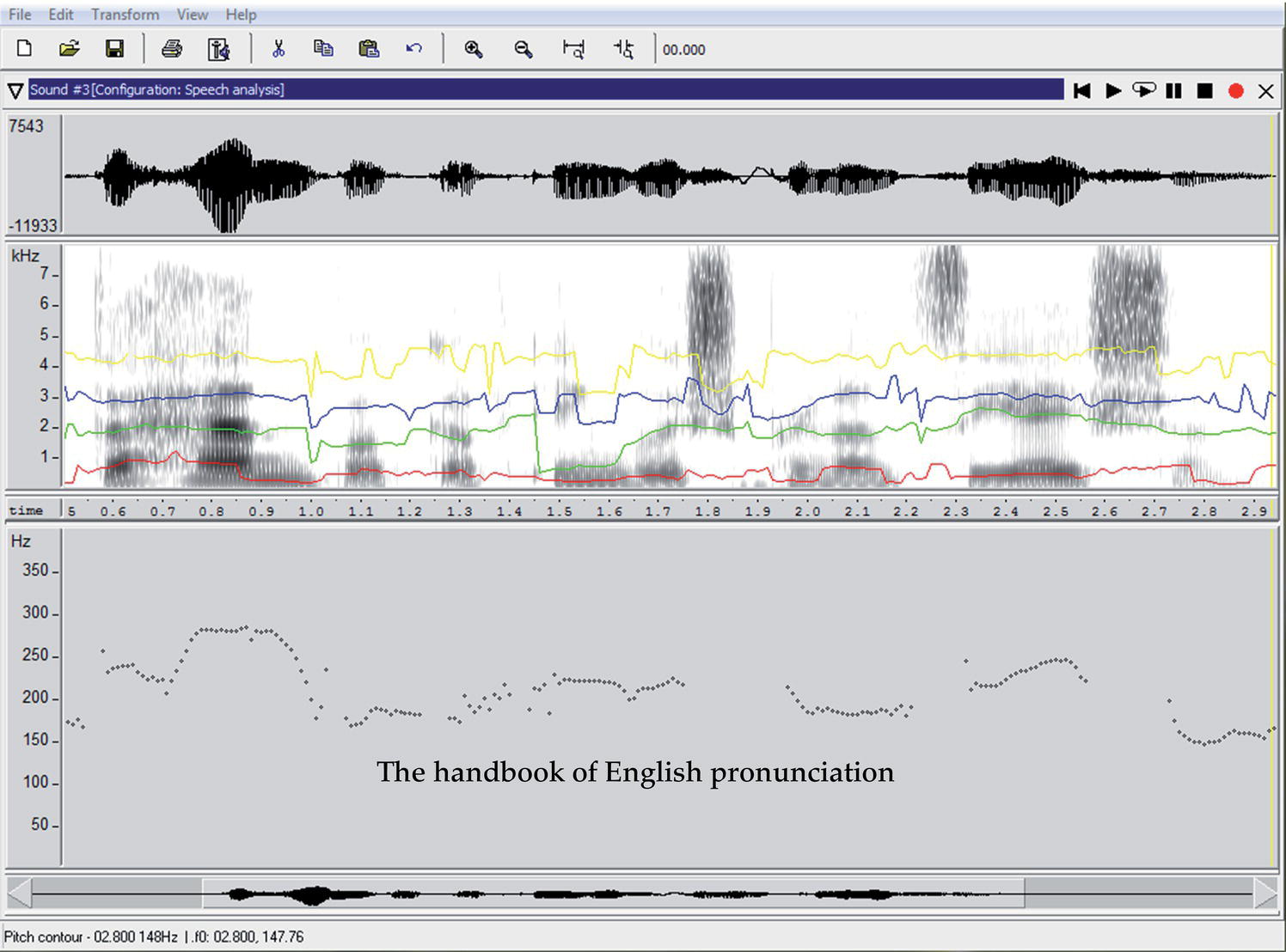
Figure 28.1 Speech analysis of the utterance “the handbook of English pronunciation”, showing the speech waveform (top), spectrogram with colored tracings of the first four formants (middle), and pitch contour (bottom).
Automatic speech recognition, also known as ASR, voice recognition, or speech-to-text (STT), turns the speech signal into words (for an introduction see Ainsworth 1997). Commercial ASR systems, such as Dragon Dictate, have taken longer than was originally hoped for to reach reliable word error rates, but are now reaching a wide mass market as software packages and apps.
Computer speech is generated by speech synthesis, or TTS (text-to-speech) (for an introduction see Carlson anad Granström 1997). There are freely available synthesis programs (e.g., http://espeak.sourceforge.net/index.html) that make use of the rule-based approach known as formant synthesis; however, the most natural-sounding synthesis is produced by splicing together tiny bits of sound taken from a large database of recordings of the speech of one individual. When combined with systems for natural language understanding and processing, ASR and TTS are used for dialogue systems, now being used in some speech training applications.
The remainder of this chapter is organized not by the technologies themselves but by the kind of feedback on learner production that they can provide. We will look first at technologies for capturing and modeling pronunciation. The next two sections discuss technologies for feedback on suprasegmental and segmental production respectively. We then look at how speech technologies can assess pronunciation, and finally at how technologies can provide conversational practice.
Technology for capturing and modeling pronunciation, with limited feedback
This section briefly considers how technologies for recording, playing back, and synthesizing speech have been used in ways that were innovative in their times.
Record and play back
The earliest language labs, using gramophones, were set up with the purpose of giving students opportunities to individually mimic recorded models, though from the outset questions were raised about the benefits of imitation without feedback (Roby 2004). The postwar language lab, using magnetic tape, offered students the ability to not only listen to models but also to record their own speech and listen to it. After their heyday in the 1960s, language labs fell rather abruptly out of fashion in the 1970s (Roby 2004). Research had been unable to show definitively that lab use had a positive effect on language proficiency, and the installations were described as expensive “electronic graveyards” (Turner 1969). The disillusionment with language labs was part of the transition from audio-lingual or behaviorist theories of language learning to constructivist models.
The successor to the language lab was the computer lab. CALL software by the 1990s was using “multimedia”, that is, audio, video, and graphics, to contribute to the learning process. When it came to pronunciation, however, most of the commercial software that claimed to teach pronunciation used the computer as no more than a recording device as late as the year 2000 (Hincks 2005a). With these programs, students were still expected to self-diagnose their pronunciation weaknesses by listening to recordings of their own speech collected by the software.
As “digital natives” have filled classrooms in the twenty-first century, we have seen innovative use of audio technology with the ultimate purpose of improving pronunciation. The English language, with its breadth of global, regional, and social pronunciation models, is especially well-suited to using technology to provide access to recordings of varieties that are remote from an individual setting. The Internet encompasses an enormous wealth of models of pronunciations for students in a lingua franca environment who would benefit from understanding many varieties of English. The web is also used to disseminate phonetic knowledge (e.g., by the University of Iowa’s phonetics department, http://www.uiowa.edu/~acadtech/phonetics/). Language students can also use the Internet to distribute oral texts – podcasts – and in that way improve pronunciation (e.g., Lord 2008). The web is also the distribution medium for low-cost apps for pronunciation training, with or without feedback.
Feedback on the perception of pronunciation can be given without the use of speech processing. While it is a difficult task for a computer to provide good feedback on a student’s production of pronunciation, it is a simple one to give feedback on a student’s perception of pronunciation. Computer programs can successfully be used to practise the perception of minimal pairs and lexical stress placement (Wik, Hincks, and Hirschberg 2009) or streams of rapid spontaneous speech (Cauldwell 1996). The program contributes feedback in the form of telling the student whether a response was correct or not; this is limited feedback, but is a first step to achieving good pronunciation.
Generating speech with synthesis
One as yet relatively unexplored means of providing pronunciation models is through the use of speech synthesis. The greatest research challenge at present is to improve the naturalness of synthesis, which can be done by finding better ways to choose what prosodic contour should best be applied to an utterance. Because synthesis can often sound quite artificial, developers have been wary of using it as a teaching model, preferring recordings of natural voices. Work has been done to develop a methodology for benchmarking synthesis so that it can be more reliably used in CALL applications (Handley 2009; Handley and Hamel 2005).
The advantage of using synthesis in any speech application is that it eliminates the reliance on the existence of pre-recorded utterances, which need to be planned in advance in order to maintain a consistent speaker voice. Any utterance can be generated at any time. Text-to-speech synthesis as a widely available learning tool would empower learners to generate the pronunciation of utterances in the absence of authoritative speakers of the language. Recent advances made in the naturalness of commercially available synthesis systems have inspired their use as reading models in situations where teachers may either not have satisfactory pronunciation or time to record large quantities of text. Students can thereby listen to a text as they read it, in that way doubling the channels of linguistic input. Speech synthesis could also potentially be used to disseminate new models of English. Jenkins (2000), for example, took the bold step of proposing a new standard for spoken International English. Since the Jenkins variety of English would be an artificial construction, it has no native speakers, and could be modeled and disseminated by the use of speech synthesis.
Speech synthesis can be manipulated with a level of control that cannot always be achieved with natural speech, and therefore it is often used to test the perception of speech sounds. The goal of this type of perception research has been an understanding of the relevant acoustic properties of speech sounds and how humans perceive them. For language learners, it is generally believed that perceiving second language sound contrasts is a prerequisite to being able to produce them, and it has been shown that they need to be exposed to a variety of voices in order to be able to generalize trained perception of L2 sound contrasts to new stimuli (Lively, Logan, and Pisoni 1994). Though these researchers achieved their results with recordings of natural speech, synthesis is an alternative for producing stimuli for the purpose of teaching the perception of L2 sounds. Wang and Munro (2004) successfully used synthetic stimuli to teach Mandarin and Cantonese learners distinctions in English vowel quality. With the goal of teaching students to focus less on vowel duration and more on vowel quality, they used formant synthesis to create stimuli with six different vowel durations. For example, the words heed and hid were each synthesized with different vowel durations ranging between 125 to 250 ms. The students thereby learned to listen to the differences in quality rather than length to distinguish between /i/ and /I/. Long-term improved perception of the contrasts in comparison with a control group was achieved.
One potential for speech synthesis in CAPT applications lies in its ability to be freely integrated with visual models of the face, mouth, and vocal tract (Engwall 2012). The visual component is an important part of spoken language understanding (Grant and Greenberg 2001) and is clearly essential when it comes to pronunciation instruction (Elliot 1995). Traditional CAPT systems use videos of human faces or animations to demonstrate correct articulation. Future systems will be able to reveal what the articulation should look like inside the oral cavity as well as on the outside of the mouth. This will provide important information about articulation, for example, for tongue placement.
Technology for suprasegmental feedback
Speech analysis software has been used to give visual feedback on intonation since the 1960s. The basic principle is that the pitch contour and sound waveform (see Figure 28.1) of a student utterance are displayed alongside those of a model utterance. Together with a teacher, or on his or her own, the student examines the differences in the visualizations of the two utterances, with the goal of achieving a better match in terms of pitch, duration, and intensity.
Pitch visualization lends itself most naturally to training short utterances that rely on pitch movement to distinguish meaning. For English, this could include, for example, polar-question intonation, pitch movement on key words, and minimal pairs distinguished by lexical stress placement. Longer discourse is harder to display and interpret at a fine-grained level, but can be useful to illustrate, for example, raised pitch with the introduction of a new topic, falling pitch across the length of an utterance, and tone choice (Levis and Pickering 2004). The speech waveform, when properly interpreted, reveals information about relative syllable length so that learners can observe durational differences between stressed and unstressed syllables.
Studies have shown that presenting visual displays of pitch contours improves both perception and production of target language intonation. Groundbreaking work was done in the Netherlands by de Bot and Mailfert (1982) who showed that even limited training with audiovisual feedback of prosody was more beneficial than audio feedback alone. A similar line of investigation was later carried out by Molholt (1988) on Chinese-speaking learners of English and by Oster (1998) on immigrants to Sweden. Hardison (2004) expanded this type of work to show that audiovisually trained learners of French not only improved their prosody but also their segmental accuracy.
These successful studies, however, were conducted largely in situations where there was a teacher available for guidance and interpretation. Because most language learners have little knowledge of acoustics, they need help to understand pitch displays. Pitch contours consist of not-always-intuitive broken lines, where the unvoiced segments of speech, which lack fundamental frequency, cause gaps that can be disconcerting to a learner. Furthermore, if a student and a model speaker have very different natural voice ranges, it can be hard to see the relationship between two pitch curves, and they may not be displayed with proper alignment with each other. Other problems can be caused by the algorithms for pitch extraction from the speech signal, which do not always work perfectly. Miscalculation of the fundamental frequency can lead to sudden discrepancies of an octave or more, so that the pitch contour suddenly seems to disappear. For best results, when signal analysis software is used to show intonation, it should be calibrated to respond to the vocal range of an individual speaker.
Speech analysis for visualizing intonation has not been widely used in language classrooms. Initially, teachers were put off by the high cost of signal analysis software such as VisiPitch (Chun 1998) or SpeechViewer (Oster 1998). The systems freely available, such as Praat (Boersma 2001) and WaveSurfer (Sjölander and Beskow 2000), were for some time well known in the speech research community but relatively unknown in the language-learning community. Some researchers/teachers have pointed out that the necessity of using utterances with many voiced (as opposed to unvoiced) segments presents an obstacle to its use (Anderson-Hsieh 1992; Chun 1998).
Automatically comparing two pitch contours for the purposes of supplying CAPT feedback is not a simple task. Research efforts are under way to apply pattern recognition and matching techniques to evaluate learner placement of lexical stress in English (Hönig et al. 2010), and there are commercial CAPT packages that incorporate a signal analysis element, though it is unclear in what way they use the intonation information in their feedback. It is unlikely that longer utterances could ever be meaningfully compared automatically. In an effort to find new ways of automatically using pitch information, Hincks (2005b) suggested that only the pitch data, rather than the visualized contours, be used as feedback. Pitch variation correlates with perceptions of speaker liveliness, which is important in public speaking and can be difficult to achieve when speaking in a second language. In a later study, Hincks and Edlund (2009) gave real-time feedback on pitch variation as Chinese learners of English practised oral presentations. The feedback was successful in teaching the students to speak with more liveliness.
One technique that is theoretically appealing is resynthesis of a student’s own production (Bannert and Hyltenstam 1981; De Meo et al. 2013; Sundström 1998). In resynthesis, the pitch and duration parameters of a native speaker are applied to an utterance made by a language learner. Providing the original utterance had acceptable segmental quality, the result is that the student is able to hear his or her own voice sounding much more like a native speaker. Listening to one’s own resynthesized utterance should lower some of the psychological barriers to adapting the intonation patterns of the target language. Felps, Bortfeld, and Gutierrez-Osuna (2009) applied the technique to a corpus of learner utterances, and evaluated the perception of the resynthesized versions. Their resynthesis was shown to reduce the perception of foreign accentedness while maintaining the voice quality properties of the foreign speaker. De Meo et al. (2013) found that self-imitation was more effective than imitation of a standard model in training Chinese speakers to achieve Italian prosodic patterns.
Technology for giving feedback at the segmental level
Since the mid-1990s, automatic speech recognition has been used in CAPT systems. ASR holds the tantalizing promise of enabling a communicative, feedback-providing framework for CALL, by letting learners “converse” with a computer in a spoken dialogue system. ASR technology has improved greatly in recent years, and reached a type of mass market with the growing use of voice applications such as Apple’s Siri in mobile devices. However, significant advances in natural language processing and computational power are necessary before even native speakers can converse with a computer about anything beyond the constraints of limited domains. These challenges are multiplied for the prospect of accented users using speech recognition, since their pronunciations cannot be represented in a general language database without diluting the precision of the recognition (Egan and LaRocca 2000). For the time being, ASR can be used in CAPT systems to give automatic feedback on the quality of phoneme production.
The basis of ASR technology is the probabilistic comparison between the signals received by the system and what is known about the phonemes of a language as represented in a database containing recordings of hundreds of native speakers of the language (Ainsworth 1997). Because of ASR’s mathematical basis, numerical scores can be derived representing the deviation between a signal and an acoustic model of the phoneme it is hypothesized to have initiated from. These scores have the potential to then be given to the learner as a type of feedback measuring a quantifiable distance from a target phoneme. However, it is not possible with current technology to say in what way the signal has deviated from the model, and this means that feedback is not corrective or constructive, but merely a sort of evaluation of the signal. Neri et al. (2002) raised the issue of whether the use of ASR in CAPT systems was driven by technology or by pedagogy, and proposed guidelines for the successful systems for teaching Dutch later developed by their research group at Radboud University in the Netherlands.
In a typical ASR-based CAPT system, a prompt will be given to a student, who can then choose a response from a limited set. One way to do this is to present a number of alternatives that the student basically can read up, and another is to design questions that can be answered only in very limited ways. Even if the student is heavily accented, the ASR system can still have a good chance of recognizing the answer if the choices are limited. Once the student response is recognized, it is aligned segment by segment with the model version in the system, and compared to find what sounds most deviate from the model sounds the ASR is based on. A well-designed CAPT system (Cucchiarini, Neri, and Strik 2009) has predetermined pedagogical priorities as to what sounds are most important to give feedback on, based on their functional load within the language. Another issue the system needs to take into consideration is what is known as the error threshold, which refers to the degree of certainty that a student has produced a correct or incorrect pronunciation. Systems can be tuned as to whether they should lean in favor of falsely accepting incorrect responses or falsely rejecting correct ones; it is probably better to do the former rather than the latter. Finally, it is wise to limit the amount of corrective feedback to avoid overwhelming the student.
Research has shown that carefully designed ASR-based training can produce positive results in teaching learners how to produce targeted sounds, such as the /x/ sound in Dutch (Cucchiarini, Neri, and Strik 2009). However, the kinds of studies that are possible to do in most real-world contexts, with many sometimes uncontrollable variables such as student engagement or the time on task, have been unable to show pronunciation development that has expanded from the improvement of a limited number of sounds to any kind of better pronunciation from a more holistic perspective (Cucchiarini, Neri, and Strik 2009; Hincks 2003). One reason for this could be the fact that speech recognition systems at present are poor at handling information contained in the speaker’s prosody. In order to recognize the words of an utterance, the recognizer must ignore the variations of pitch, tempo, and intensity that naturally appear in utterances by different speakers and even within an individual speaker’s various productions. This means that ASR can give feedback at the segmental level, but not on the suprasegmental level (with the exception of speaking rate, which will be handled below). Unfortunately for CALL developers who want to use ASR, these prosodic features are sometimes those that need the most practice from language learners (Anderson-Hsieh, Johnson, and Koehler 1992). Another possible reason for the relatively disappointing performance of ASR-based CAPT could be that critics of audiolingual language training were right: drilling and mimicry are not the best way to learn pronunciation.
ASR-based CAPT would be improved if the feedback could give precise instruction as to how a sound could be better articulated. One way to do that would be by working with specific L1-L2 pairs. It is known, for example, that German learners of English have a problem with devoicing in word-final position, so if the second consonant in the word “rise” produced in a CAPT system receives a low score, then the learner could be automatically prompted to voice the sound. Creating systems like this might be possible for pairs of the world’s major languages, but it is a very expensive process. The ASR speech database would need to consist of carefully annotated German-accented English, mixed with native-accented English. Since the global market for learning English is so valuable, this might be a worthwhile process for a commercial operation, but what about Somali-native learners of Swedish? Such specific systems will of course never exist, and without them the ASR will only be able to give scores on pronunciation without feedback on how to improve articulation.
In addition to the question of better feedback, there are a number of other issues regarding the ASR speech models used in CAPT systems. Many language learners are children, but their speech is not suitable for recognition in systems based on recordings of adult speech, and special databases and programs need to be created for them (Elenius and Blomberg 2005; Gerosa and Giuliani 2004). With the creation of such a system, Neri et al. (2008) were able to show that Italian children studying English learned the pronunciation of new vocabulary as well from a computer system as from a teacher. Ideally, users should model their utterances on those of speakers of the same sex. Work on allowing users to pick their own model speaker was done by Probst, Ke, and Eskenazi (2002); unfortunately, users were not very successful in choosing models that were appropriate for their voices. Another issue perhaps specific to English and a few other languages is the fact that there is more than one standard teaching model of English. It would be discouraging for a student who has been taught British English to receive negative feedback in a CAPT system that used underlying American English models.
The most widely known application for ASR is the spoken dialogue systems with which we can, for example, order tickets automatically, but an application available on the consumer market is for computer-based dictation. Dictation systems were previously speaker-dependent, that is, trained to recognize the speech of one individual. Recent breakthroughs in ASR technology have allowed the development of dictation systems that are speaker-independent. That is, they are able to recognize any speaker’s voice. A few researchers have been inspired to test dictation systems on language learners, as a way of assessing pronunciation. Coniam (1999) looked at the ability with which foreign-accented speakers of English could use a commercially available speaker-dependent dictation program. Predictably, the software was significantly worse at recognizing foreign-accented speech than native speech. Derwing, Munro, and Carbonaro (2000) compared ASR recognition scores with human intelligibility scores derived by transcribing recorded utterances. Like Coniam, they found that proficient non-native speech was recognized much less accurately than native speech; moreover, they found a discrepancy between errors perceived by humans and the misrecognitions of the dictation software. The problems the dictation systems encountered did not correspond to a human-like pattern as evidenced by human intelligibility scores. It is important to remember, however, that dictation software has not been designed with CAPT applications in mind. ASR for non-native speech needs to be adapted so that the underlying phonetic models encompass a wider variety of possible productions.
Because of the inherent limitations in the way standard ASR can be used for CAPT, researchers are testing other ways of using speech processing for feedback at the segmental level, though these methods are not as automated. Researchers have let students practise single words or phrases with visual feedback in the form of a spectrogram (provided by speech analysis software) and in the presence of a teacher for guidance and interpretation (Pearson, Pickering, and Da Silva 2011; Ruellot 2011). Cutting-edge work by Engwall and co-authors (Engwall 2012; Engwall and Balter 2007; Kjellström and Engwall 2009) has looked at what sorts of supplemental information can provide clues to the causes of deviant pronunciation. Their idea is to make use of features in the acoustic signal that indicate articulatory information, e.g., place or manner, and furthermore combine the acoustic information with visual information from a speaker’s mouth and face. This information can then be used to create feedback that gives instruction about better articulation, instead of the mere classification into acceptable or not-acceptable phonemes that can be given by traditional techniques.
Technology for evaluating pronunciation
An obstacle in testing pronunciation is determining a practical method for evaluation. Human judgment is not only time consuming and expensive, but it sometimes can be difficult for raters to be consistent and to agree with others. An appealing alternative would be to let ASR provide an objective measure for a pronunciation test. Since ASR is better at quantifying deviation from a norm than providing corrective feedback, pronunciation evaluation is in fact its most natural application in the language learning field. ASR can also be used to determine whether a student has given the correct answer to a simple question, such as “What is the opposite of ‘complex’?” Questions like this can be used to assess a student’s vocabulary and thereby language proficiency. Furthermore, ASR can be easily used to measure the speed at which a learner speaks, a type of fluency measure. Rate of speech has been shown to correlate with speaker proficiency (Cucchiarini, Strik, and Boves 2002; Hincks 2010; Kormos and Dénes 2004). Thus, the best prosodic application of ASR is in the assessment of temporal measures.
With the aim of creating an automatic pronunciation test for spoken Dutch, Cucchiarini, Strik, and Boves (2000) devised an extensive study that looked at the correlations between different aspects of human ratings of accented Dutch and machine scores provided by ASR. They found a high correlation between human ratings and machine-generated temporal measures such as rate of speech and total duration. In other words, speakers judged highly by the raters were also the faster speakers. However, the ASR in this system did a poor job of assessing segmental quality, which was the aspect of speech that the human raters found to be most important when rating accentedness. There was thus a mismatch between what humans associated with good speech and what computers rated as good speech. However, the ASR was still able to discern the better speakers; it just used another way of finding them than the humans did.
The commercially successful Versant (formerly PhonePass) test (Bernstein et al. 2000; Bernstein, Van Moere, and Cheng 2010) uses speech recognition to assess the correctness of student responses, and also gives scores in pronunciation and fluency. Comparisons of the results given by the test and those obtained by human-rated measures of oral proficiency show that there is as much correlation between its scores and averaged human ratings as there is between one human rater and another (Bernstein et al. 2001). An examination of the PhonePass scores of a group of students was published in Hincks (2001). That paper found a relationship between the speed at which students read test sentences and the scores they received, and discussed the risks inherent in assessing short, nonphonetically balanced samples of speech.
Technology for practising speaking skills
The market for CALL systems for English is enormous, especially in Asia. It is estimated, for example, that nearly 2% of the Korean GNP is spent on learning English (Pellom 2012). Companies that produce products for these markets are aware of the serious limitations in the ability of speech processing techniques to provide accurate formative feedback that can achieve measurable improvement in pronunciation. Some of them have therefore shifted the focus of their products from CAPT to the more general “practice in speaking”, with, for example, accompanying social and cultural training (Johnson 2012). Training delivered by the Internet provides an opportunity for human teachers to come in to give feedback on pronunciation after a student has practised a dialogue, a strategy adopted by a major American company (Pellom 2012) in its high-end systems.
One dream of CALL developers is the use of unconstrained dialogue systems for language speaking practice. A dialogue system combines speech recognition, natural language understanding, and speech synthesis to enable a person to communicate with a computer and complete a task. Developers are working on “embodied conversational agents” that can act as both language tutors and conversational partners. A number of projects include a gaming element, where, for example, a learner must bargain for a product in a flea-market environment (Wik and Hjalmarsson 2009), quickly provide a translation of a word (Seneff 2007) or exhibit culturally sensitive behavior (Johnson, Vilhjalmsson, and Marsella 2005). Games are believed to stimulate engagement and learning in a nonthreatening environment.
Conclusion
There is an enormous need for CAPT, a need expressed in a number of review articles in recent years (Eskenazi 2009; Levis 2007; O’Brien 2006). However, really effective automated feedback remains an elusive goal; in the words of one developer, it is a problem that is not too big to run away from (Johnson 2012). Until the research challenges for automation are solved, teachers are encouraged to work with students individually or in small groups, using proven methods to raise pronunciation awareness. The studies that have shown the most convincing benefits to learners (Hardison 2004; Pearson, Pickering, and Da Silva 2011) have used speech analysis software such as freely available Praat and WaveSurfer, and have not eliminated the presence of the teacher. The field of pronunciation training has a long tradition of embracing new technologies, and speech visualization is one of them.
REFERENCES
- Ainsworth, W.A. 1997. Some approaches to automatic speech recognition. In: The Handbook of Phonetic Sciences, W.J. Hardcastle and J. Laver (eds.), Oxford, Blackwell.
- Anderson-Hsieh, J. 1992. Using electronic visual feedback to teach suprasegmentals. System 20(1): 51–62. doi: 10.1016/0346-251X(92)90007-P.
- Anderson-Hsieh, J., Johnson, R., and Koehler, K. 1992. The relationship between native speaker judgments of nonnative pronunciation and deviance in segmentals, prosody and syllable structure. Language Learning 42(4): 529–555. doi: 10.1111/j.1467-1770.1992.tb01043.x.
- Bannert, R. and Hyltenstam, K. 1981. Swedish immigrants' communication: problems of understanding and being understood. Working Papers Lund University Department of Linguistics 21: 17–28.
- Bernstein, J., Van Moere, A., and Cheng, J. 2010. Validating automated speaking tests. Language Testing 27(3): 355–377.
- Bernstein, J., Jong, J.D., Pisoni, D., and Townshend, B. 2000. Two experiments on automatic scoring of spoken language proficiency. Paper presented at the Integration of Speech Technology in Language Learning, Dundee, Scotland.
- Boersma, P. 2001. PRAAT: a system for doing phonetics by computer. Glot International 5: 341–345.
- Boersma, P. and Weenink, D. 2010. Praat: doing phonetics by computer (Version 5.1.41) [computer program]. Retrieved July 22, 2010 from: http://www.fon.hum.uva.nl/praat/.
- Carlson, R. and Granström, B. 1997. Speech synthesis. In: The Handbook of Phonetic Sciences, W.J. Hardcastle and J. Laver (eds.), Oxford, Blackwell.
- Cauldwell, R.T. 1996. Direct encounters with fast speech on CD-audio to teach listening. System 24(4): 521–528. doi: 10.1016/s0346-251x(96)00046-2.
- Chun, D. 1998. Signal analysis software for teaching discourse intonation. Language Learning and Technology 2(1): 61–77.
- Clarke, C.C. 1918. The phonograph in modern language teaching. Modern Language Journal 3: 116–122.
- Coniam, D. 1999. Voice recognition software accuracy with second language speakers of English. System 27(1): 49–64. doi: 10.1016/S0346-251X(98)00049-9.
- Cucchiarini, C., Neri, A., and Strik, H. 2009. Oral proficiency training in Dutch L2: the contribution of ASR-based corrective feedback. Speech Communication 51(10): 853–863. doi: 10.1016/j.specom.2009.03.003.
- Cucchiarini, C., Strik, H., and Boves, L. 2000. Different aspects of expert pronunciation quality ratings and their relation to scores produced by speech recognition algorithms. Speech Communication 30: 109–119. doi: 10.1016/S0167-6393(99)00040-0.
- Cucchiarini, C., Strik, H., and Boves, L. 2002. Quantitative assessment of second language learners' fluency: comparison between read and spontaneous speech. Journal of the Acoustical Society of America 111(6): 2862–2873.
- De Bot, K., and Mailfert, K. 1982. The teaching of intonation: fundamental research and classroom applications. TESOL Quarterly 16(1): 71–77.
- De Meo, A., Vitale, M., Pettorino, M., Cutugno, F., and Origlia, A. 2013. Imitation/self-imitation in computer-assisted prosody training for Chinese learners of L2 Italian. Paper presented at the 4th Pronunciation in Second Language Learning and Teaching Conference, Ames, Iowa.
- Derwing, T., Munro, M., and Carbonaro, M. (2000). Does popular speech recognition software work with ESL speech? [Brief Report]. TESOL Quarterly 34(3): 592–602.
- Egan, K. and LaRocca, S. 2000. Speech recognition in language learning: a must. Paper presented at the Integration of Speech Technology in Language Learning, Dundee, Scotland.
- Elenius, D. and Blomberg, M. 2005. Adaptation and normalization experiments in speech recognition for 4- to 8-year old children. Paper presented at the Interspeech 2005, Lisbon.
- Elliot, R. 1995. Foreign language phonology: field independence, attitude, and the success of formal instruction in Spanish pronunciation. Modern Language Journal 79(IV): 530–542.
- Engwall, O. 2012. Analysis of and feedback on phonetic features in pronunciation training with a virtual teacher. Computer Assisted Language Learning 25(1): 37–64. doi: 10.1080/09588221.2011.582845.
- Engwall, O. and Balter, O. 2007. Pronunciation feedback from real and virtual language teachers. Computer Assisted Language Learning 20(3): 235–262. doi: 10.1080/09588220701489507.
- Engwall, O., Wik, P., Beskow, J., and Granström, B. 2004. Design strategies for a virtual language tutor. Paper presented at the International Conference on Spoken Language Processing, Jeju Island, Korea, October 4–8, 2004.
- Eskenazi, M. 2009. An overview of spoken language technology for education. Speech Communication 51(10): 832–844. doi: 10.1016/j.specom.2009.04.005.
- Felps, D., Bortfeld, H., and Gutierrez-Osuna, R. 2009. Foreign accent conversion in computer assisted pronunciation training. Speech Communication 51(10): 920–932. doi: 10.1016/j.specom.2008.11.004.
- Gerosa, M. and Giuliani, D. 2004. Preliminary investigations in automatic recognition of English sentences uttered by Italian children. Paper presented at the Integrating Speech Technology in Language Learning, Venice, Italy.
- Grant, K. and Greenberg, S. 2001. Speech intelligibility derived from asynchronous processing of auditory-visual information. Paper presented at the Audio-visual Speech Processing Workshop 2001.
- Handley, Z. 2009. Is text-to-speech synthesis ready for use in computer-assisted language learning? Speech Communication 51(10): 906–919. doi:10.1016/j.specom.2008.12.004.
- Handley, Z. and Hamel, M.-J. 2005. Establishing a methodology for benchmarking speech synthesis for computer-assisted language learning (CALL). Language Learning and Technology 9(3): 99–119.
- Hardison, D. 2004. Generalization of computer-assisted prosody training: quantitative and qualitative findings. Language Learning and Technology 8(1): 34–52.
- Hart, R.S. 1995. The Illinois PLATO foreign languages project. CALICO Journal 12(4): 15–37.
- Hincks, R. 2001. Using speech recognition to evaluate skills in spoken English. Proceedings of Fonetik 2001, 49: 58–61.
- Hincks, R. 2003. Speech technologies for pronunciation feedback and evaluation. ReCALL 15(1): 3–20.
- Hincks, R. 2005a. Computer support for learners of spoken English. Doctoral thesis, Royal Institute of Technology, Stockholm, Sweden.
- Hincks, R. 2005b. Measures and perceptions of liveliness in student oral presentation speech: a proposal for an automatic feedback mechanism. System 33(4): 575–591. doi: 10.1016/j.system.2005.04.002.
- Hincks, R. 2010. Speaking rate and information content in English lingua franca oral presentations. English for Specific Purposes 29(10): 4–18. doi: 10.1016/j.esp.2009.05.004.
- Hincks, R. and Edlund, J. 2009. Promoting increased pitch variation in oral presentations with transient visual feedback. Language Learning and Technology 13(3): 32–50.
- Hocking, E. 1954. Language Laboratory and Language Learning, Washington, DC: Division of Audiovisual Instruction, National Education Association.
- Hönig, F., Batliner, A., Weilhammer, K., and Noth, E. 2010. Automatic assessment of non-native prosody for English as L2. Paper presented at the Speech Prosody Chicago, Illinois.
- Jenkins, J. 2000. The Phonology of English as an International Language: New Models, New Norms, New Goals, Oxford: Oxford University Press.
- Johnson, L. 2012. Error detection for teaching communicative competence. Paper presented at The International Symposium on Automatic Detection of Errors in Pronunciation Training, Stockholm, Sweden.
- Johnson, L., Vilhjalmsson, H., and Marsella, S. 2005. Serious games for language learning: How much game, how much AI? In: Artificial Intelligence in Education, C.-K. Looietal (ed.), Amsterdam: IOS Press.
- Kjellström, H., and Engwall, O. 2009. Audiovisual-to-articulatory inversion. Speech Communication 51(3): 195–209. doi: 10.1016/j.specom.2008.07.005.
- Kormos, J. and Dénes, M. 2004. Exploring measures and perceptions of fluency in the speech of second language learners. System 32: 145–164. doi: 10.1016/j.system.2004.01.001.
- Last, R.W. 1989. Artificial Intelligence Techniques in Languge Learning, Chichester, England: Harwood.
- Léon, P.R. 1962. Laboratoire de Langues et Correction Phonétique, Paris: Didier.
- Levis, J. 2007. Computer technology in teaching and researching pronunciation. Annual Review of Applied Linguistics 27: 184–202.
- Levis, J. and Pickering, L. 2004. Teaching intonation in discourse using speech visualization technology. System 32: 505–524.
- Lively, S., Logan, J., and Pisoni, D. 1994. Training Japanese listeners to identify English /r/ and /l/. II: The role of phonetic environment and talker variability in learning new perceptual categories. Journal of the Acoustical Society of America 94(3): 1242–1255.
- Lord, G. 2008. Podcasting communities and second language pronunciation. Foreign Language Annals 41(2): 364–379.
- Molholt, G. 1988. Computer-assisted instruction in pronunciation for Chinese speakers of American English. TESOL Quarterly 22(1): 91–111.
- Neri, A., Cucchiarini, C., Strik, H., and Boves, L. 2002. The pedagogy–technology interface in computer assisted pronunciation training. Computer-Assisted Language Learning 15(5): 441–467. doi: 10.1076/call.15.5.441.13473.
- Neri, A., Mich, O., Gerosa, M., and Giuliani, D. 2008. The effectiveness of computer assisted pronunciation training for foreign language learning by children. Computer Assisted Language Learning 21(5): 393–408. doi: 10.1080/09588220802447651.
- O'Brien, M. 2006. Teaching pronunciation and intonation with computer technology. Calling on CALL: From Theory and Research to New Directions in Foreign Language Teaching, L. Ducate and N. Arnold (eds.), San Marcos, TX: Computer Assisted Language Instruction Consortium.
- Oster, A.-M. 1998. Spoken L2 teaching with contrastive visual and auditory feedback. Paper presented at the International Conference on Spoken Language Processing, Sydney, Australia.
- Pearson, P., Pickering, L., and Da Silva, R. 2011. The impact of computer assisted pronunciation training on the improvement of Vietnamese learner production of English syllable margins. Paper presented at the 2nd Pronunciation in Second Language Learning and Teaching Conference, Ames, Iowa.
- Pellom, B. 2012. Rosetta Stone ReFLEX: toward improving English conversational fluency in Asia. Paper presented at the International Symposium on Automatic Detection of Errors in Pronunciation Training, Stockholm, Sweden.
- Probst, K., Ke, Y., and Eskenazi, M. 2002. Enhancing foreign language tutors – In search of the golden speaker. Speech Communication 37: 161–173. doi: 10.1016/S0167-6393(01)00009-7.
- Roby, W.B. 2004. Technology in the service of foreign language teaching: the case of the language laboratory. In: Handbook of Research on Educational Communications and Technology, 2nd edition, D. Jonassen (ed.), 523–541, Mahwah, NJ: Lawrence Erlbaum.
- Ruellot, V. 2011. Computer-assisted pronunciation learning of French /u/ and /y/ at the intermediate level. Paper presented at the 2nd Pronunciation in Second Language Learning and Teaching, Ames, Iowa.
- Seneff, S. 2007. Web-based dialogue and translation games for spoken language learning. Paper presented at the Speech and Language Technology in Education (SLaTE) 2007, Pittsburgh, PA.
- Sjölander, K. and Beskow, J. 2000. WaveSurfer: an open source speech tool. Retrieved August 2013 from: http://www.speech.kth.se/wavesurfer/. Paper presented at the International Conference on Spoken Language Processing 2000, Beijing.
- Sundström, A. 1998. Automatic prosody modification as a means for foreign language pronunciation training. Paper presented at the ISCA Workshop on Speech Technology in Language Learning (STILL 98), Marholmen, Sweden.
- Turner, E.D. (1969). Correlation of language class and language laboratory. ERIC Focus Reports on the Teaching of Foreign Languages, vol. 13, New York.
- Wang, X. and Munro, M. 2004. Computer-based training for learning English vowel contrasts. System 32: 539–552.
- Wik, P., Hincks, R., and Hirschberg, J. (2009). Responses to Ville: A virtual language tutor for Swedish Paper presented at the Speech and Language Technology in Education Warwickshire, England
- Wik, P., & Hjalmarsson, A. (2009). Embodied conversational agents in computer assisted language learning. Speech Communication, 51(10), 1024–1037. doi: 10.1016/j.specom.2009.05.006