
22
The Segmental/Suprasegmental Debate
BETH ZIELINSKI
Introduction
An important focus of ongoing research into L2 English pronunciation learning and teaching is the identification of features of pronunciation that impact on a speaker’s intelligibility and comprehensibility.1 Such features are generally identified and categorized by researchers as either segmental (individual sounds) or suprasegmental (extending over more than an individual sound, e.g., syllable structure, stress, rhythm, intonation). A long-standing debate in pronunciation teaching is whether segmentals or suprasegmentals are more important in promoting understandable speech. On one side of the debate, various authors have claimed that suprasegmental features should be given priority in pronunciation teaching because they are more important than segmental features to intelligibility and comprehensibility. For example, Fraser (2001: 33) listed six pronunciation features in the order in which they should be taught, based on their relative impact on listeners’ comprehension. At the top of the list was word and sentence stress and the features further down the list involved consonant and vowel production and distinctions. Fraser stated that this order implies that stress is the most important thing to teach, as learners with perfect consonant distinctions will still be very difficult to understand if they have not mastered word and sentence stress. She argued that “there is little point in helping students with, say consonant distinctions, if they have very poor control of word and sentence stress” (2001: 34). Chela-Flores (2001) expressed a similar view when describing what she saw as the priority in her approach to teaching pronunciation: “More emphasis has been given to suprasegmental aspects, since these have more impact on intelligibility and help students with their immediate pronunciation needs” (2001: 98). Similarly, Tanner and Landon (2009) proposed that “if intelligibility is prioritized above accuracy, a focus on key words, stress, rhythm, and intonation rather than the articulation of individual sounds, may be needed” (2009: 51).
On the other side of the debate, it has been argued that segmental features are more important to intelligibility and should therefore be given priority in pronunciation teaching. Collins and Mees (2003: 209), for example, supported this view and listed six pronunciation features they identified as having the greatest influence on intelligibility and therefore the highest priority in pronunciation teaching; five of these involved different consonants and vowels, and the sixth (and only suprasegmental feature) was word stress. Jenkins (2000) argued that segmental features are more important when non-native speakers of English are communicating with each other. She not only stressed the importance of segmental features to intelligibility in this context but asserted that some suprasegmental features actually “obstruct intelligibility” (2000: 135). She proposed a Lingua Franca Core, a set of pronunciation features considered to be crucial to intelligibility and thus a priority in pronunciation teaching. This set of pronunciation features was grouped into five categories referred to as “main core items” (see Jenkins 2002: 96–97 for a summary). Four of these categories involved segmental features, such as the production of various consonants, phonetic requirements related to voiced and voiceless consonants (aspiration and vowel length in specific contexts), production of consonant clusters, and production of specific vowels. Only one involved a suprasegmental feature, and this was the appropriate production and placement of nuclear stress, that is, stressing a particular word in an utterance to signal a particular meaning (variously referred to as tonic, primary, or contrastive stress). Other suprasegmental features, such as word stress, weak forms, stress-timed rhythm, and intonation, were considered to be non-core features, that is, not crucial to intelligibility.
Central to the segmental/suprasegmental debate is the notion that segmental and suprasegmental features are separate entities, and this is reflected in related research, where various studies have investigated the importance of one or the other to intelligibility and/or comprehensibility. Rogers and Dalby (2005), Bent, Bradlow, and Smith (2007), and Munro and Derwing (2006), for instance, focused on the relationship between intelligibility and/or comprehensibility and the production of various segments. Rogers and Dalby’s findings highlight the importance of accurate vowel production to intelligibility, while Bent, Bradlow, and Smith found that both vowel accuracy and the accurate production of consonants in the word-initial position were important. Munro and Derwing used the theoretical concept of functional load to determine the impact of different consonant substitutions on listener judgments of comprehensibility, and found that those with a high functional load had a greater impact on comprehensibility judgments than those with a low functional load. The concept of functional load is based on the premise that some segmental contrasts do a greater amount of work in English than others, and are therefore more important to intelligibility and/or comprehensibility (see, for example, Brown 1991; Catford 1987; Gilner and Morales 2010).
Other studies have focused on the importance of suprasegmental features. Benrabah (1997), for example, found that non-target-like word stress was detrimental to intelligibility and Hahn (2004) found that both misplaced and no primary stress (i.e., nuclear stress) in a lecture impacted negatively on listener judgments of the comprehensibility (ability to hear and understand) of the instructor. In contrast, Kang (2010) looked at the contribution of a range of different suprasegmental features (speech rate, pauses, stress, and pitch range) to listeners’ judgments of comprehensibility but found that these judgments were more closely related to speech rate than to the other features.
Various other studies have investigated the importance of both segmental and suprasegmental features to intelligibility and/or comprehensibility and again have viewed and measured these features as separate entities. Munro and Derwing (1995) and Derwing and Munro (1997), for example, focused on the impact of both segmental and suprasegmental features on measures of intelligibility and comprehensibility. Munro and Derwing (1995) identified and counted non-target-like segments, but rated intonation on a 9-point scale where 1 = native-like and 9 = not at all native-like. Similarly, Derwing and Munro (1997) identified and counted non-target-like segments, but evaluated nativeness of prosody using a 9-point scale for prosodic goodness, where 1 = perfectly native-like and 9 = extremely accented. Furthermore, the samples rated for prosodic goodness had been filtered so that most of the segmental information had been removed, leaving rhythm and intonation intact. Derwing and Munro argued that in this way prosody could be assessed without the influence of segmental factors, that is, as separate from segmental features. In another study, Isaacs and Trofimovich (2012) investigated the influence of (amongst other linguistic features) both segmental and suprasegmental features on listener judgments of comprehensibility, and listed them as separate entities and measured them in different ways. The segmental features investigated were consonant and vowel production, and the suprasegmental features included syllable structure, word stress, vowel reduction related to rhythm, pitch contour, and pitch range.
The notion that segmental and suprasegmental features are separate entities is also central to the small number of empirical teaching studies investigating the impact on intelligibility and/or comprehensibility of teaching that focuses on different pronunciation features. The outcome of a teaching focus on segmental features (Saito 2011) and suprasegmental features (Tanner and Landon 2009) has been investigated, as well as the relative impact of segmental versus suprasegmental features (Derwing, Munro, and Wiebe 1997, 1998).
Despite the discussion and debate in the literature about the relative importance of segmental and suprasegmental features for intelligibility and comprehensibility, and which should be given priority in pronunciation teaching, there is little empirical evidence to support one over the other (see Derwing and Munro, 2005; Derwing and Munro, 2009; Levis, 2005). In fact, the general consensus seems to be moving towards the idea that both are important, as discussed by Celce-Murcia et al. (2010):
Today we see signs that pronunciation instruction is moving away from the segmental/suprasegmental debate and towards a more balanced view …. Today’s pronunciation curriculum thus seeks to identify the most important aspects of both the suprasegmentals and segmentals and integrate them appropriately in courses that meet the needs of any given group of learners. (2010: 11)
However, although the view that both segmental and suprasegmental features are important moves away from the segmental/suprasegmental debate, it still supports the premise that segmental and suprasegmental features can be categorized as separate entities. As will be discussed in the next section, categorizing features as either segmental or suprasegmental is not always straightforward.
Categorizing features of pronunciation: segmental or suprasegmental?
Although previous studies have tended to view segmental and suprasegmental features as separate entities, categorizing non-target-like pronunciation features as either one or the other can be problematic. Research by Zielinski (2006a, 2006b, 2008) highlighted the two-way nature of intelligibility, that is, that both the speaker and the listener play a part at times when intelligibility is reduced. She had three native listeners (native speakers of Australian English) listen to utterances produced by three L2 speakers, each from a different L1 background (Vietnamese, Mandarin, and Korean), and write down the words they heard the speakers say. At sites of reduced intelligibility (i.e., the parts of the utterances where a listener was unable to, or had difficulty in, identifying the speaker’s intended words), links were made between the characteristics of the speakers’ pronunciation and the listeners’ difficulties identifying the words the speaker intended to say. As shown in the examples presented in Table 22.1,2 a non-target-like feature in a speaker’s pronunciation might be categorized differently depending on the perspective from which it is viewed. From the speaker’s perspective we might consider both how a particular word was pronounced and why it was pronounced that way, and from the listener’s perspective we might consider what the speaker was heard to say and therefore which non-target-like features were misleading.
Table 22.1 Categorizing non-target-like features of pronunciation that have an impact on intelligibility.
| The speaker | The listeners | |||
| Speaker’s L1 | What is the target word and how do they pronounce it? | Why? | What do they hear the speaker say? | What misleads them? |
| 1. Vietnamese | Target word: five Pronounced: /faɪ/ Description: final consonant /v/ is absent. | The syllable structure of Vietnamese does not allow a word-final consonant following a diphthong (Hansen 2004). | fie (non-word) | A consonant missing at the end of the word results in them hearing a non-word. |
| → Segmental? | → Suprasegmental? | →Segmental? | ||
| 2. Mandarin | Target word: just Pronounced: /ʤʌstǝ/ Description: vowel added to the end of the word. | Syllable structure of Mandarin does not allow for word-final consonant clusters. Adding a vowel is a common way Mandarin speakers modify them to create an open syllable structure at the end of the word (Hansen 2001). | just a just don’t | An added syllable results in them hearing an extra word. |
| → Segmental? | → Suprasegmental? | → Suprasegmental? | ||
Notes. The Vietnamese speaker is a male from North Vietnam. The Chinese speaker is a female from Northern China. The listeners are native speakers of Australian English. See endnote 2.
The first example in Table 22.1 highlights a common feature of Vietnamese speakers’ English pronunciation – the absence of word final consonants (see Hansen 2004). In this example, the word final consonant was absent in the speaker’s production of the word five and the listener was misled by the absence of this consonant and heard the speaker say a non-word, fie. We might therefore presume that this particular breakdown in intelligibility is related to a non-target-like segmental feature (i.e., the absence of a consonant). However, when we look at the reason why the speaker might have pronounced the word in this way, we see that it is related to Vietnamese syllable structure constraints, and thus suprasegmental in nature (i.e., Vietnamese syllable structure does not allow a word final consonant following a diphthong – see Hansen 2004). As a result, it is difficult to determine whether this error should be categorized as suprasegmental or segmental.
The second example presented in Table 22.1 involves a common feature in Mandarin speakers’ English pronunciation – the addition of a vowel to the end of a word (see Deterding 2006). In describing the speaker’s pronunciation of the word just in this way, the non-target-like feature (an extra vowel) would appear to be segmental in nature. However, the listeners in this example were misled by the resulting change in the syllable stress pattern (an extra vowel means an additional syllable) and both heard the speaker say two words rather than one (just a and just don’t). It seems, therefore, that from the listeners’ perspective, the misleading feature of this non-target-like production is suprasegmental in nature (there are more syllables than there should be). Similarly, the reason why the speaker might have produced the word this way seems to be related to the syllable structure constraints of Mandarin (see Hansen 2001), and is thus also suprasegmental in nature. Again, this raises the question of whether this feature should be categorized as suprasegmental or segmental?
As well as being difficult to do, categorization of different non-target-like pronunciation features as either segmental or suprasegmental ignores the possibility of a relationship between them, and fails to view them as part of an integrated system where one might interact with the other to influence intelligibility. The recognition of a possible interaction between the two has been raised in the speech disorder literature,3 where Weismer and Martin (1992) argued:
In running speech, segmental and suprasegmental events are executed simultaneously. Modifications of segmental elements … may influence not only the perception of those particular segments but also the perception of the rhythmic structure of the utterances as a whole. In this sense, the segmental event may contribute to a modification of the prosodic structure. (1992: 83)
Rather than debating whether segmental or suprasegmental features are more important, we need to rethink our approach and view the features of pronunciation as part of an integrated and interactive system where the production of one can influence the other. In this way we can further our understanding of reduced intelligibility in L2 speakers of English and gain insight into establishing not only what to teach but how to teach it in the classroom.
An integrated system of pronunciation features: the prosodic hierarchy
The prosodic hierarchy (e.g., Nespor and Vogel 1986; see Demuth 2009for an overview) provides a useful framework for the analysis of the way different pronunciation features might combine or interact to influence a speaker’s intelligibility. In this framework, the prosodic structure of spoken language is conceptualized as consisting of a hierarchy of increasingly smaller units. Within the context of the prosodic hierarchy, therefore, a particular word is seen to be composed of the units at levels below it (foot, syllable, mora) and also embedded in higher level units above (phonological phrase, intonational phrase, utterance). For example, if we use this framework to consider the word stress pattern in the word economics in the example presented in Table 22.2, we see that the word economics is composed of smaller units below and is embedded in larger units above. As described by Demuth (2009) in English, stress at the word level is influenced by units below the word level (the shaded area in Table 22.2); that is, the mora structure tends to determine which syllables are stressed and this influences the foot structure which in turn influences stress patterns in words. Word stress patterns in English are also influenced by morphology, with different suffixes affecting where primary stress is placed in a word. Thus, the word economics is produced with primary stress on the third syllable.
Table 22.2 The prosodic hierarchy: English.
| Hierarchy level | Example |
| Phonological utterance | Some students have to study agricultural economics |
| Intonational phrase | have to study agricultural economics |
| Phonological phrase | agricultural economics |
| Prosodic word | ecoNOmics |
| Foot | [NOmics] (s w) |
| Syllable | mics |
| Mora | mi |
Note. The utterance used as an example here was produced by a Vietnamese speaker. See endnote 2.
Different languages have different prosodic constraints and therefore differ in, for example, the types of rhythmic patterns, foot structures, and syllable structures permitted. It is therefore possible that prosodic constraints of a speaker’s L1 might play a role in the way they organize their pronunciation of English. Understanding what these constraints are gives us important insight into why speakers from particular L1 backgrounds might have the non-target-like English pronunciation features that they do, and thus provides important information about how we might need to go about teaching them.
The Vietnamese speaker featured in Table 22.2 actually produced the word economics with non-target-like stress, that is, with primary stress on the second syllable rather than the third. Consideration of the prosodic constraints of Vietnamese might therefore provide some insight into why he did so. Much of the information in the literature about why Vietnamese speakers might find English word stress challenging focuses on the transfer of different features of Vietnamese phonology. This includes observations that Vietnamese is a tonal language where most words have only one syllable (Hwa-Froelich, Hodson, and Edwards, 2002) and there seems to be no systematic difference between syllables in terms of duration or vowel quality (Nguyen and Ingram 2005) and no system of (lexical) word stress (Nguyen and Ingram 2007). It is, however, widely accepted that there is stress at the phrasal level for accentual prominence (Nguyen, Ingram, and Pensalfini 2008). If we consider these features of Vietnamese, it is no surprise that Vietnamese speakers find English word stress challenging. However, this information does not really help us understand what word stress errors Vietnamese speakers might make. We might, for example, expect that they would pronounce multisyllabic words with equal stress on each syllable, or that perhaps they might inadvertently use tones on particular syllables, which could be perceived as stressed when they were not intended to be.
Using the prosodic hierarchy as a framework, Schiering, Bickel, and Hildebrandt (2010) have provided some insight into how Vietnamese L1 prosodic constraints might influence English word stress. They argued that, in Vietnamese, the stress pattern of a string of syllables (i.e., words) is determined by the rhythmic pattern at the phonological phrase level and is not related to a particular word (as is the case in English). They describe the rhythmic pattern at the phrasal level as sequences of up to three syllables with ws or wws patterns.
Thus, if these prosodic constraints play a role in the way a Vietnamese speaker organizes English word stress, we might expect multisyllabic words to be treated as a series of syllables that are organized into phrases according to Vietnamese constraints, and would most likely start with a ws or wws pattern, as shown in Table 22.3.
Table 22.3 The prosodic hierarchy: Vietnamese.
| Hierarchy level | Example |
| Phonological utterance | Some students have to study agricultural economics |
| Intonational phrase | have to study agricultural economics |
| Phonological phrase | eCOnomics (w s) (w s) |
| Prosodic word | ecoNOmics |
| Foot | [NOmics] (s w) |
| Syllable | mics |
| Mora | mi |
Preliminary research by Zielinski et al. (2011) supports these expectations and found that there was in fact a tendency for the Vietnamese speaker featured here to produce word stress patterns that started with ws rather than sw patterns (e.g., foREIGN [ws]/ foreign; ofFIcer [wsw]/ officer; pathoGEN [wws]/pathogen). They also found an instance of inconsistency, where the word expect was produced with target-like word stress in one context and non-target-like word stress in another. This finding suggests that the stress placed on a particular syllable in an English multisyllabic word might depend on where that word occurs in a phrase. This means that there could be some inconsistency in word stress patterns, with a particular word having target-like word stress in one phrasal context but non-target-like word stress in another. This preliminary research involved the analysis of one sample of connected speech from one speaker, and so further research is needed before any firm conclusions can be drawn. However, these findings highlight the importance of viewing different features of pronunciation as part of an integrated system in understanding what a speaker is doing and why. They also raise questions about how we might best teach word stress patterns to learners of English from a Vietnamese L1 background, when phrasal level stress patterns might “undo” all the good work that has been done at the word level and result in a non-target-like word stress pattern being produced in a novel phrasal context. It is therefore crucial that once a particular stress pattern has been learned at the word level, the learner has the opportunity to practice this pattern in a range of different phrasal contexts, particularly those predicted to be difficult or likely to challenge the learned pattern.
By analyzing pronunciation features in the context of the hierarchical system in which they interact, we can also gain an understanding of the way in which non-target-like features at different levels might combine or interact to influence intelligibility. Zielinski (2006b, 2008), in relation to the examples presented in Table 22.1, analyzed non-target-like pronunciation features at sites of reduced intelligibility in terms of the interaction between segments (consonants and vowels), syllables (strong and weak), and words (prominent and nonprominent) within a pause group. Firstly, utterances were divided into smaller sections on the basis of the speaker’s placement of pauses (thus referred to as pause groups rather than phrases). Any pause group containing a section of speech where a listener was unable to, or had difficulty in, identifying what the speaker intended to say was considered to be a site of reduced intelligibility. At each of these sites, the relative strength of each syllable was judged as either the strongest in the pause group (S), strong but not the strongest (s), or weak (w), and the segments in each syllable were identified. This analysis captured both the patterns of strong and weak syllables in multisyllabic words and the patterns of strong and weak syllables across the words in the pause group. In order to establish a link between specific non-target-like features and the words the listeners heard the speakers say, the non-target-like features replicated in the listener responses were identified. An example taken from Zielinski’s study is presented in Figure 22.1 to illustrate this process.
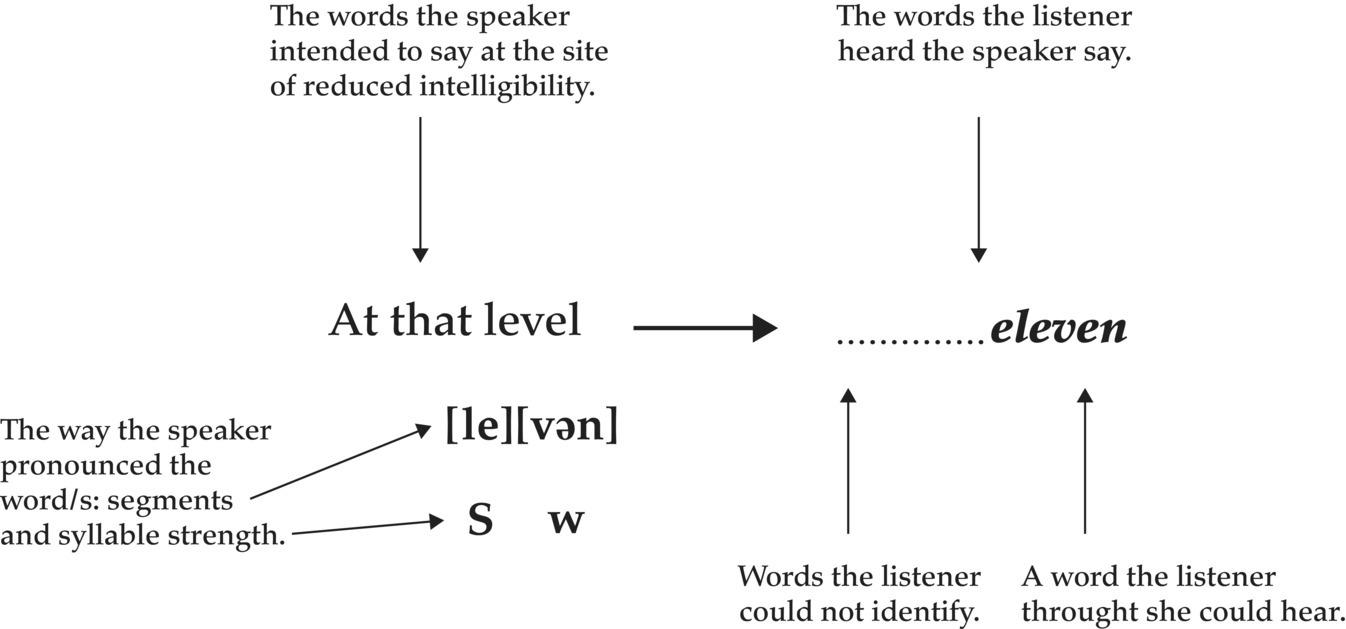
Figure 22.1 Analysis of speaker and listener contribution at sites of reduced intelligibility. Adapted from Zielinski 2006b.
The example shown in Figure 22.1 was a site of reduced intelligibility (underlined) in the following utterance produced by the Vietnamese speaker in Zielinski’s study:
At that level student have to study for five years.
At first, the listener was unable to identify any of the words at this site, but after listening to the utterance a number of times, she commented that she thought she heard the word eleven in there. Thus, the speaker’s syllable stress pattern and segments in the word level were replicated in the listener’s response. In identifying this word as eleven, she replicated the speaker’s S w stress pattern (in Australian English it is common for eleven to be pronounced with two syllables), but was misled by the nontarget production of the final consonant (n/l) substitution.
Such an analysis allows us to explore reduced intelligibility from the perspective of both the speaker and the listener, and investigate how non-target-like features at different levels might combine or interact to influence intelligibility. Zielinski found that, regardless of the speaker they were listening to, listeners found both the syllable stress pattern and segments produced by the speaker to be important; they all relied to some extent on both to identify the speaker’s intended words. They relied consistently on the speaker’s syllable stress pattern (both the number and pattern of strong and weak syllables) and more consistently on segments in strong syllables than those in weak ones. Thus, the non-target-like production of either, or both combined, had the potential to mislead the listeners and thus reduce intelligibility. Furthermore, segments in strong syllables were found to be particularly important to the listeners, especially the syllable initial consonant and the vowel. In fact, non-target-like segments in strong syllables had the greatest impact on intelligibility across all three speakers. These findings highlight the importance of moving on from the underlying assumptions inherent in the segmental/suprasegmental debate and changing our research focus to integrate segmentals and suprasegmentals.
Moving on from the segmental/suprasegmental debate
In order to move forward in our understanding of reduced intelligibility in L2 speakers of English, it is important that future research investigates how different features of pronunciation combine and interact to reduce intelligibility, and also explore the role played by both the speaker and the listener.
The interaction between different features of pronunciation
It is important that future studies analyze the speech signal in a way that allows the exploration of the way different pronunciation features might interact to influence a speaker’s intelligibility. Rather than categorizing different features as discrete items for attention, features of pronunciation need to be analyzed in the context of the integrated and interactive system of which they are part. For example, as mentioned earlier, Bent, Bradlow, and Smith (2007) investigated the relationship between intelligibility and the non-target-like production of various segments (both consonants and vowels) and found that vowel accuracy and syllable/word-initial consonant accuracy correlated with intelligibility scores. However, because syllable stress patterns were not included in the analysis, vowel changes related to the production of non-target-like syllable stress could not be distinguished from those related to non-target-like production of the vowels themselves. Similarly, Munro and Derwing (2006) investigated the impact of high and low functional load consonant errors on comprehensibility and found that high functional load errors had a greater effect than low functional load ones. Interestingly, they also noted that the high functional load errors occurred in content rather than function words. It is therefore likely that they were in strong syllables, and this may have affected the listeners’ reliance on them and therefore influenced their judgments of comprehensibility. However, because only consonants were analyzed, this possibility could not be investigated.
It is also important that rather than focusing on the relative importance of individual features to intelligibility, future studies investigate the cumulative effect of multiple non-target-like features. Zielinski (2006b) found that across all three speakers in her study, it was more likely than not that multiple non-target-like features contributed to reduced intelligibility, whether it be a combination of non-target-like syllable stress patterns and non-target-like consonants and/or vowels, or a combination of different non-target-like consonants and/or vowels. Munro and Derwing (2006) investigated the cumulative effect of high and low functional load consonant errors on comprehensibility and found that neither showed cumulative effects. They speculated that the nature of the errors might be more important to comprehensibility than the number. However, they only focused on consonants, and to be able to investigate the cumulative effect of different combinations of non-target-like features, we need to analyze the speech signal in a way that allows us to consider the combination and interaction features from different levels of the integrated system in which they operate.
The role of the speaker
To further our understanding of how to improve intelligibility and comprehensibility for speakers from different L1 backgrounds, it is important that future studies explore why they have the particular non-target-like pronunciation features they do. Further investigation of the role of L1 prosodic constraints on various English pronunciation features would give us important insight into why a speaker from one L1 background might find a particular pronunciation feature challenging, while a speaker from a different L1 background might not.
The role of the listener
When listening to speech, listeners rely on speech processing strategies that are “specifically tailored” to their native language phonology (Cutler 2001: 11) and they apply these strategies regardless of who they are listening to, and whether or not it results in limited success. The native English listeners in Zielinski’s studies (2006b, 2008) were misled by non-target-like features in the speakers’ pronunciation because they listened to the speech with their “English ears” and relied on the non-target-like features as if they were target-like English features. Cutler describes a similar listener response to foreign language input:
Listeners command a repertoire of procedures appropriate for their native language and not only cannot call at will upon new procedures appropriate to input in a new language but perforce apply the native procedures to the new input irrespective of whether these act to facilitate processing or to render it inefficient. (2001: 10)
As highlighted earlier in Table 22.1, because of the two-way nature of reduced intelligibility, it is important to investigate the role of the listener as well as the speaker. The listeners in Zielinski’s study operated in a way that might be expected, seeing they were native speakers of English. Relying heavily and consistently on a speaker’s syllable stress pattern (both the number and pattern of strong and weak syllables) is what native English listeners do, both to locate word boundaries (Cutler and Butterfield 1992; Liss et al. 1998) and for lexical access (Bond and Small 1983). The finding that they relied more consistently on segments in strong syllables than those in weak ones is also typical of native English listeners. Segments in strong syllables are important to them because they provide crucial information for lexical access (Bond and Small 1983; Bond 1999). In addition, the way segments are produced in strong syllables contributes to the perception of the syllable as strong (Cutler and Clifton 1999; Cutler 2009; Stevens 2002), and segments are less variable in strong syllables than they are in weak ones (Carroll 2004; Greenberg 2006).
An understanding of listeners’ speech processing strategies is crucial to our understanding of reduced intelligibility in different contexts. The way listeners identify individual words in a stream of continuous speech is language specific and based on the listener’s L1 speech processing strategies (Carroll 2004; Cutler 2001; Cutler, Dahan, and van Donselaar 1997). Listeners from different L1 backgrounds might therefore rely on different features in the speech signal to understand a speaker, and the intelligibility of the same speaker might be affected by different features for listeners from different L1 backgrounds. This poses a significant challenge to research related to the development of a Lingua Franca Core (Jenkins 2000, 2002) that would enable speakers from a wide range of L1 backgrounds to communicate effectively and intelligibly with each other. Considering the numerous combinations of speaker and listener L1 backgrounds in the mix, future research needs to not only consider what features the speaker might have in their pronunciation but also the speech processing strategies the listener might be using when listening to them.
Conclusion
The segmental/suprasegmental debate is based on a false dichotomy. Not only are both important to intelligibility and comprehensibility, but categorization of pronunciation features as either one or the other ignores the relationship between them and fails to view them as part of an integrated system where the production of one can influence the other. In order to further our understanding of reduced intelligibility and comprehensibility in L2 speakers of English, it is crucial that studies view features of pronunciation as part of an integrated and interactive system, and investigate how different features combine and interact to reduce intelligibility and comprehensibility, and why they do so for both the speaker and the listener.
REFERENCES
- Benrabah, M. 1997. Word-stress – A source of unintelligibility in English. IRAL 35(3): 157–165.
- Bent, T., Bradlow, A.R., and Smith, B. 2007. Phonemic errors in different word positions and their effects on intelligibility of non-native speech: All's well that begins well. In: Language Experience in Second Language Speech Learning. In Honor of James Emil Flege, O.S. Bohn and M.J. Munro (eds.), 331–347, Amsterdam: John Benjamins Publishing Company.
- Bond, Z.S. 1999. Slips of the Ear: Errors in the Perception of Casual Conversation, San Diego: Academic Press.
- Bond, Z.S. and Small, L.H. 1983. Voicing, vowel, and stress mispronunciations in continuous speech. Perception and Psychophysics 34(5): 470–474.
- Brown, A. 1991. Functional load and teaching pronunciation. In: Teaching English Pronunciation. A Book of Readings, A. Brown (ed.), London: Routledge.
- Carroll, S.E. 2004. Segmentation: learning how to “hear words” in the L2 speech stream. Transactions of the Philological Society 102(2): 227–254.
- Catford, W.W. 1987. Phonetics and the teaching of pronunciation: a systematic description of English phonology. In: Current Perspectives on Pronunciation: Practices Anchored in Theory, J. Morley (ed.), 87–100, Washington, DC: TESOL.
- Celce-Murcia, M., Brinton, D.M., Goodwin, J.M., and Griner, B. 2010. Teaching Pronunciation: A Course Book and Reference Guide, 2nd edition, New York: Cambridge University Press.
- Chela-Flores, B. 2001. Pronunciation and language learning: an integrative approach. International Review of Applied Linguistics 39: 85–101.
- Collins, B. and Mees, I.M. 2003. Practical Phonetics and Phonology. A Resource Book for Students, New York: Routledge.
- Cutler, A. 2001. Listening to a second language through the ears of a first. Interpreting 5(1): 1–23.
- Cutler, A. 2009. Greater sensitivity to prosodic goodness in non-native than in native listeners (L). Journal of the Acoustical Society of America 125(6): 3522–3525.
- Cutler, A. and Butterfield, S. 1992. Rhythmic cues to speech segmentation: evidence from juncture misperception. Journal of Memory and Language 31: 218–236.
- Cutler, A. and Clifton, C. 1999. Comprehending spoken language: a blueprint of the listener. In: The Neurocognition of Language, C.M. Brown and P. Hagoort (eds.), 123–166, Oxford: Oxford University Press.
- Cutler, A., Dahan, D., and van Donselaar, W. 1997. Prosody in the comprehension of spoken language: a literature review. Language and Speech 40(2): 141–201.
- Demuth, K. 2009. The prosody of syllables, words and morphemes. In: Cambridge Handbook on Child Language, E. Bavin (ed.), 183–198, Cambridge: Cambridge University Press.
- Derwing, T.M. and Munro, M.J. 1997. Accent, intelligibility, and comprehensibility. Evidence from four L1s. Studies in Second Language Acquisition 19: 1–16.
- Derwing, T.M. and Munro, M.J. 2005. Second language accent and pronunciation teaching: a research-based approach. TESOL Quarterly 39(3): 379–397.
- Derwing, T.M. and Munro, M.J. 2009. Putting accent in its place: rethinking obstacles to communication. Language Teaching 42(4): 476–490.
- Derwing, T.M., Munro, M.J., and Wiebe, G. 1997. Pronunciation instruction for “fossilized” learners. Can it help? Applied Language Learning 8(2): 217–235.
- Derwing, T.M., Munro, M.J., and Wiebe, G. 1998. Evidence in favor of a broad framework for pronunciation instruction. Language Learning 48(3): 393–410.
- Deterding, D. 2006. The pronunciation of English by speakers from China. English World Wide, 27(2): 175–198.
- Fraser, H. 2001. Teaching Pronunciation: A Handbook for Teachers and Trainers. Three frameworks for an integrated approach, NSW: Department of Education Training and Youth Affairs.
- Gilner, L. and Morales, F. 2010. Functional load: transcription and analysis of the 10,000 most frequent words in spoken English. The Buckingham Journal of Language and Linguistics 3: 135–162.
- Greenberg, S. 2006. A multi-tier theoretical framework for understanding spoken language. In: Listening to Speech: An Auditory Perspective, S. Greenberg and W.A. Ainsworth (eds.), 411–433, Mahwah, NJ: Lawrence Erlbaum Associates.
- Hahn, L.D. 2004. Primary stress and intelligibility: research to motivate the teaching of suprasegmentals. TESOL Quarterly 38(2): 201–223.
- Hansen, J.G. 2001. Linguistic constraints on the acquisition of English syllable codas by native speakers of Mandarin Chinese. Applied Linguistics 22(3): 338–365.
- Hansen, J.G. 2004. Developmental sequences in the acquisition of English L2 syllable codas. Studies in Second Language Acquisition 26: 85–124.
- Hwa-Froelich, D., Hodson, B.W., and Edwards, H.T. 2002. Characteristics of Vietnamese phonology. American Journal of Speech-Language Pathology 11(3): 264–273.
- Isaacs, T. and Trofimovich, P. 2012. Deconstructing comprehensibility. Studies in Second Language Acquisition 34: 520–531.
- Jenkins, J. 2000. The Phonology of English as an International Language: New Models, New Norms, New Goals, Oxford: Oxford University Press.
- Jenkins, J. 2002. A sociolinguistically based, empirically researched pronunciation syllabus for English as an International Language. Applied Linguistics 23(1): 83–103.
- Kang, O. 2010. Salience of suprasegmental features on judgments of L2 comprehensibility and accentedness. System 38(2): 301–315.
- Levis, J. 2005. Changing contexts and shifting paradigms in pronunciation. TESOL Quarterly 39(3): 369–377.
- Liss, J.M., Spitzer, S., Caviness, J.N., Adler, C., and Edwards, B. 1998. Syllable strength and lexical boundary decisions in the perception of hypokinetic dysarthric speech. Journal of the Acoustical Society of America 104(4): 2457–2466.
- Munro, M.J. and Derwing, T.M. (1995). Foreign accent, comprehensibility, and intelligibility in the speech of second language learners. Language Learning 45(1): 73–97.
- Munro, M.J. and Derwing, T.M. 2006. The functional load principle in ESL pronunciation instruction: an exploratory study. System 34: 520–531.
- Nespor, M. and Vogel, I. 1986. Prosodic Phonology, Dordrecht: Foris Publications.
- Nguyen, T.A.T. and Ingram, J. 2005. Vietnamese acquisition of English word stress. TESOL Quarterly 39(2): 309–319.
- Nguyen, T.A.T. and Ingram, J. 2007. Acoustic and perceptual cues for compound-phrasal contrasts in Vietnamese. Journal of the Acoustical Society of America 122(3): 1746–1757.
- Nguyen, T.A.T., Ingram, J. and Pensalfini, J.R. 2008. Prosodic transfer in Vietnamese acquisition of English contrastive stress patterns. Journal of Phonetics 36(1): 158–190.
- Rogers, C.L. and Dalby, J. 2005. Forced-choice analysis of segmental production by Chinese-accented English speakers. Journal of Speech, Language, and Hearing Research 48: 306–322.
- Saito, K. 2011. Examining the role of explicit phonetic instruction in native-like and comprehensible pronunciation development: an instructed SLA approach to L2 phonology. Language Awareness 20(1): 45–59.
- Schiering, R., Bickel, B., and Hildebrandt, K.A. 2010. The prosodic word is not universal, but emergent. Journal of Linguistics 46: 657–709.
- Stevens, K.N. 2002. Toward a model for lexical access based on acoustic landmarks and distinctive features. Journal of the Acoustical Society of America 111(4): 1872–1891.
- Tanner, M.W. and Landon, M.M. 2009. The effects of computer-assisted pronunciation readings on ESL learners' use of pausing, stress, intonation, and overall comprehensibility. Language Learning and Technology 13(3): 51–56.
- Weismer, G. and Martin, R.E. 1992 Acoustic and perceptual approaches to the study of intelligibility. In: Intelligibility in Speech Disorders, R.D. Kent (ed.), 67–118, Amsterdam: John Benjamins Publishing Company.
- Zielinski, B. 2006a. The intelligibility cocktail: an interaction between speaker and listener ingredients. Prospect: An Australian Journal of TESOL 21(1): 22–45.
- Zielinski, B.W. 2006b. Reduced intelligibility in L2 speakers of English. PhD, La Trobe University, Bundoora. Retrieved from:http://arrow.latrobe.edu.au:8080/vital/access/manager/Repository.
- Zielinski, B.W. 2008. The listener: no longer the silent partner in reduced intelligibility. System 36(1): 69–84.
- Zielinski, B., Yuen, I., Demuth, K., and Yates, L. 2011. Rethinking theory for practice in pronunciation teaching. Paper presented at the American Association of Applied Linguistics, Chicago.