
The SQL Standard
Temporal database support was added to the SQL standard in 2011. This lengthy chapter explains that support in detail and compares and contrasts it with the ideas introduced in previous chapters. It discusses “periods” (SQL’s analog of intervals, represented by explicit from/to pairs); an SQL base table can have at most one application time period (corresponding to valid time) and at most one system time period (corresponding to transaction time). SQL supports analogs of certain of the interval operators discussed in previous chapters; unfortunately, however, it has nothing analogous to PACK and UNPACK. The chapter discusses all of these operators, also database design considerations, queries, and updates in the SQL context. In particular, it explains how queries and updates work on “tables with system time” (especially system-versioned tables) and on “bitemporal tables” (tables with both application time and system time). The chapter concludes with a detailed analysis and assessment of the SQL temporal features.
Keywords
SQL temporal features; time period; application time; system time; bitemporal table; system versioning
Standards are always out of date.
That’s what makes them standards.
—Alan Bennett:
Forty Years On (1969)
Temporal database support was added to the SQL standard in the 2011 edition of that standard (“SQL:2011”—see reference [61]). In this chapter, we examine that support in some detail, and we analyze and assess it from the point of view of our own approach to temporal data as described in Parts II and III of this book. But we might as well give the game away right up front: While SQL’s temporal features might reasonably be described as a step—possibly, in some respects, even a fairly large step—in the right direction, they nevertheless fail in all too many ways to solve (or, in some cases, even attempt to solve) all of the problems we identified in Parts II and III of this book.
We use the structure of earlier parts of this book as a loose organizing principle for the discussions that follow. In other words, we’ll cover SQL’s temporal features in a sequence that parallels, more or less, the sequence in which we described their counterparts in the chapters in earlier parts of the book. Recall, however, that Chapters 1-3 were basically just a refresher course on the relational model, and Chapters 4 and 5 were concerned merely with setting the scene, as it were; we didn’t really start to get into our preferred approach to the problem until we reached Chapter 6, on intervals, and so that’s where we’ll start now.
Periods
SQL doesn’t support intervals. In their place, it supports what it calls periods—but those periods aren’t values in their own right (i.e., there are no period types); instead, they consist of explicit FROM-TO value pairs (typically pairs of column values, if we’re talking about periods that happen to be represented within SQL tables specifically).1 Note, moreover, that those periods are quite specifically temporal in nature; SQL has nothing corresponding to the general purpose interval abstraction as described in earlier chapters. So an SQL version of the suppliers-and-shipments database—the first, simplest (?), but still fully temporal form—from Part II of this book might look as shown in Fig. 19.1.
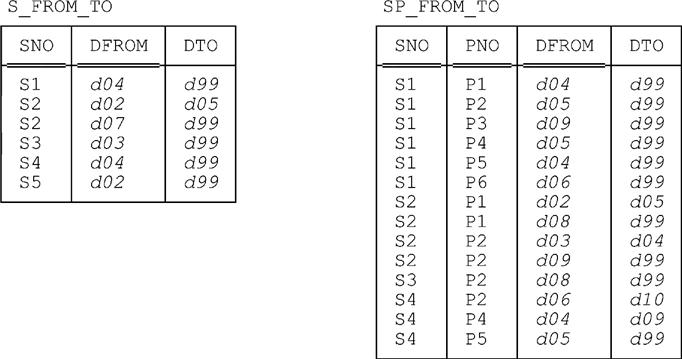
Fig. 19.1 is basically a repeat of Fig. 5.3 from Chapter 5, except that:
■ We’ve renamed the “from” and “to” columns DFROM and DTO, respectively (D for during). Note: FROM and TO as such are reserved words in SQL and so can’t be used as column names without being enclosed in what the standard calls double quotes (in other words, quotation marks). As for the tables themselves, we’ve named them S_FROM_TO and SP_FROM_TO as in Chapter 5, in order to stress the point that they do indeed have explicit “from” and “to” columns instead of a single “during” column.
■ We’ve replaced all of those d10 “end of time” markers by the slightly more reasonable value d99. Note: As far as SQL is concerned, the actual end of time is DATE ‘9999–12–31’ and the beginning of time is DATE ‘0001–01–01’ (both values given here in the form of DATE literals, which by definition are accurate to the day—though SQL does also support finer granularities, of course, as we’ll see later). Throughout this chapter, therefore, references to d99 should be taken as denoting “the last day” as understood by SQL (i.e., December 31st, 9999).
■ As we’ve said, an SQL period is denoted by an explicit pair of “from” and “to” values, not by a single interval value. As a consequence, SQL has to specify the intended interpretation for such value pairs, and it plumps for the closed:open interpretation; that is, the “from” value denotes the first point contained in the period, and the “to” value denotes the point immediately following the last point contained in the period. For this reason, we’ve increased all of the “to” values in the figure (other than those “end of time” markers) by one day.
■ Following on from the previous point, however, there’s a serious oddity here. Precisely because periods in SQL do use the closed:open interpretation, there’s no way “the end of time” can actually be contained in such a period! If, as in Fig. 19.1, we specify a “to” value of d99, then the last day that’s actually contained in the period in question is d98, which of course isn’t “the end of time.” On the other hand, we can’t specify a “to” value of d100, because d100 isn’t legal as a DATE value in SQL.2 To put the point another way, no “from” value can ever be equal to d99, and SQL has no way of representing the fact that some state of affairs holds on day d99.
Perhaps we should take a moment to consider SQL’s rationale for not supporting period types as such. The following quote is taken from reference [65]:
Many treatments of temporal databases introduce a period data type,3 defined as an ordered pair of two datetime values … SQL:2011 has not taken this route. Adding a new data type to the SQL standard (or to an SQL product) is a costly venture because of the need to support the new data type in the tools and other software packages that form the ecosystem surrounding SQL. For example, if a period type were added to SQL, then it would have to also be added to the stored procedure language, to all database APIs such as JDBC, ODBC, and .NET, as well as to the surrounding technology such as ETL products, replication solutions, and others. There must also be some means of communicating period values to host languages that do not support period as a native data type, such as C or Java. These factors can potentially slow down the adoption of a new type for a long time.
But note the consequences of adopting this position. Among other things, it appears to mean that “the ecosystem surrounding SQL” simply has no knowledge or understanding of the temporal aspects of SQL databases. What are the implications of this state of affairs? For example, does it mean a natural language front end won’t be able to handle temporal queries? And in any case, don’t essentially the same arguments apply to user defined types, too—in fact, to all possible user defined types? Are we to conclude that the set of system defined types in SQL is cast in concrete and can never change?4
Anyway, here’s the SQL definition—i.e., the CREATE TABLE statement—for table S_FROM_TO:
CREATE TABLE S_FROM_TO
( SNO SNO NOT NULL , DFROM DATE NOT NULL, DTO DATE NOT NULL , PERIOD FOR DPERIOD ( DFROM , DTO ) ,
UNIQUE ( SNO, DPERIOD WITHOUT OVERLAPS ) ) ;
■ Table S_FROM_TO is, of course, a base table, in SQL terms. For simplicity, we’ll adopt the convention throughout this chapter that the term table, unqualified, means a base table specifically, unless the context demands otherwise.
■ The PERIOD FOR specification defines columns DFROM and DTO to be the boundary columns for a period called DPERIOD. Note very carefully that DPERIOD itself is not a column. However, period names are allowed to appear in just one context where column references are permitted: They can be used as period references within certain boolean expressions, typically within a WHERE clause (see the discussion of Allen’s operators, later in this section).5
■ The columns that are paired in a PERIOD FOR specification must both be of the same data type—either DATE, as in the example, or some SQL timestamp type such as TIMESTAMP(6).6 As already indicated, therefore, SQL’s periods are specifically temporal in nature; there’s no support for intervals (or periods, rather) involving integers, or heights, or money values, or indeed anything else at all.
■ It follows from the previous point that the only point types supported in SQL are dates and SQL-style timestamps. For simplicity, throughout what follows we’ll concentrate on type DATE only and ignore the other possibilities (i.e., we’ll assume from this point forward that periods are always measured in days specifically), until further notice. Now, we saw in Chapter 6 that a point type requires niladic first and last operators and monadic next and prior operators. For type DATE, invocations of the first and last operators can be represented by literals denoting “the first day” and “the last day,” respectively, as we’ve already seen. As for next (the successor function), the operator for adding one day suffices. Here’s a simple example (note the syntax):7
DFROM + INTERVAL '1' DAY
Prior is analogous, of course.
■ As already noted, SQL’s periods implicitly use the closed:open interpretation, as in, e.g., [d02,d05). The PERIOD FOR specification in the definition of table S_FROM_TO effectively reflects this state of affairs by guaranteeing that, within any row of that table, the value of DFROM will always be less than that of DTO. More generally, in fact, SQL will enforce the constraint for any period, no matter how or where it’s specified (in a table definition or elsewhere), that the “from” value is strictly less than the “to” value.8 Note: The expression [d02,d05) isn’t meant to be actual SQL syntax (we’ll explain that actual syntax when we get to “period selectors,” later in this section). However, it’s at least true, as the example suggests, that SQL uses a comma, not a colon, as a separator.
■ Period DPERIOD in the example represents what SQL calls application time, which is the SQL term for valid time. (Recall from Chapter 17 that our own preferred term for this concept is stated time. In this chapter, however, we’ll stay with the SQL term.)
■ No SQL table can ever have more than one application time period. Now, this rule is perhaps not too unreasonable, given that—as we effectively saw in Chapter 12, in the section “During Relvars Only”—it usually wouldn’t make sense for a table to have more than one, anyway (though it might).9 Observe, however, that the table in question had probably better be in 6NF—for otherwise the application time period will probably be “timestamping too much,” as we put it in that discussion in Chapter 12. Note, therefore, that converting a nontemporal design into a satisfactory temporal analog will typically involve rather more than just adding an application time period to each nontemporal table (as indeed we also saw in Chapter 12).
■ We defer detailed explanation of the UNIQUE specification to the next section (“Database Design”).10 However, we remark that—regardless of whether WITHOUT OVERLAPS is specified—UNIQUE (SNO,DPERIOD…) effectively defines, not a key as such, but rather a proper superkey (see the answer to Exercise 13.2a in Chapter 13).
For completeness, we also show an SQL definition for table SP_FROM_TO:
CREATE TABLE SP_FROM_TO
( SNO SNO NOT NULL , PNO PNO NOT NULL , DFROM DATE NOT NULL , DTO DATE NOT NULL , PERIOD FOR DPERIOD ( DFROM , DTO ) ,
UNIQUE ( SNO , PNO , DPERIOD WITHOUT OVERLAPS ) ,
FOREIGN KEY ( SNO , PERIOD DPERIOD )
REFERENCES S_FROM_TO ( SNO , PERIOD DPERIOD ) ) ;
The only new feature here is the FOREIGN KEY specification, an explanation of which we also defer to the next section (“Database Design”).
“Period Selectors”
Since SQL has no period types, it also has no period variables. A fortiori, therefore, it has no period variable references, nor more generally does it have period expressions—i.e., expressions that return a period value—of any kind. It does, however, have a construct that might be thought of as a kind of “period selector” operator, and, as a special case of that construct, it does support a kind of “period literal.” However, these constructs can appear in just two contexts—they can appear in a FOR PORTION OF specification, which we’ll be discussing in the section “Updates” later, and they can also appear in a “period predicate” (which is a special kind of boolean expression), where they can be used to denote an operand, or both operands, to one of Allen’s operators. The syntax is PERIOD (f,t), where f and t are expressions both of the same type, either DATE or some timestamp type.
Aside: Don’t be confused by this syntax: As already stated, SQL implicitly uses the closed:open interpretation, so the syntax PERIOD (f,t) denotes what would more conventionally be represented as [f,t), or in closed:closed notation[f,t-1]. In this chapter, for reasons of explicitness and (we hope) clarity, we’ll occasionally make use of [f,t) as an abbreviation for PERIOD (f,t). End of aside.
Here then is a simple SQL query against table S_FROM_TO:
SELECT DISTINCT SNO
FROM S_FROM_TO
WHERE PERIOD ( DFROM , DTO ) OVERLAPS
PERIOD ( DATE '2012-12-01' , DATE '2013-01-01' )
Observe that the OVERLAPS operands in this example are denoted by constructs—SQL calls them period predicands—that do look something like hypothetical “period selector” invocations, and the second in particular does look something like a hypothetical “period literal.”
Note: In the common special case where a period predicand denotes a period that’s explicitly defined to be part of some SQL table, the corresponding period name can be used in place of the corresponding “period selector.” Thus, the foregoing SQL query might be simplified slightly to:
SELECT DISTINCT SNO
FROM S_FROM_TO
WHERE DPERIOD OVERLAPS
PERIOD ( DATE '2012-12-01' , DATE '2013-01-01' )
Period Operators
In Chapter 7, we discussed the following operators on intervals: BEGIN and END; PRE and POST; POINT FROM; and “∈” and “∋”. So let p be an SQL period predicand, and let the FROM-TO pair denoted by p be [f,t). Then the following table shows how analogs of those operators, applied to p, can be expressed in SQL:

For POINT FROM, of course, we can write simply f (or t − ‘1’ DAY), but it’s our responsibility to ensure the period in question does indeed contain just one day (no exception will be raised if it doesn’t). As for “∈”, the hypothetical expression “x ∈ p” can always be recast as p CONTAINS x (where x is any SQL expression that evaluates to a value of the applicable point type). Note carefully, however, that the point t is explicitly not contained in the period [f,t).
Allen’s Operators
As the sample query shown earlier suggests, the SQL syntax for invoking one of Allen’s operators (Op, say) takes the usual infix form:
p1 Op p2
Let [f1,t1) and [f2,t2) be the FROM-TO pairs corresponding to the period predicands p1 and p2, respectively. Then the following table shows how Allen’s operators can be expressed in SQL:
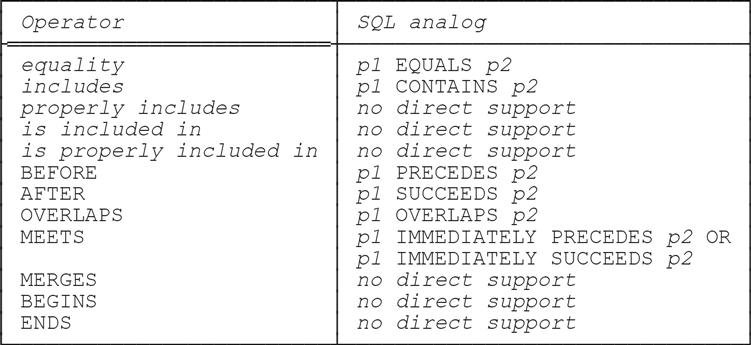
■ Note that SQL uses the same keyword, CONTAINS, to denote both “∋” and “⊇” (in other words, CONTAINS is overloaded).
■ It’s a little odd that certain of the SQL expressions shown are actually longer (sometimes quite a bit longer) than the expressions they’re explicitly defined to be “shorthand” for. For example, p1 PRECEDES p2 simply means t1 ≤ f2, and p1 IMMEDIATELY PRECEDES p2 simply means t1 = f2. It’s also odd that PERIOD (f1,t1) = PERIOD (f2,t2) is illegal, and yet (f1,t1) = (f2,t2) is not only legal but means exactly the same as PERIOD (f1,t1) EQUALS PERIOD (f2,t2).
■ Of course, the cases where SQL has no direct support can always be worked around—but it’s a pity that MERGES in particular has to be treated in this fashion. Here for the record is an SQL analog (not the only one possible, but perhaps the most obvious) of p1 MERGES p2:
p1 OVERLAPS p2 OR
p1 IMMEDIATELY PRECEDES p2 OR
p1 IMMEDIATELY SUCCEEDS p2
Finally, in Chapter 7 we also defined an interval COUNT operator and interval UNION, INTERSECT, and MINUS operators. SQL has no counterparts to the last three. As for COUNT, it can be simulated by simply subtracting the applicable from value from the corresponding to value. For example, given the period [4,11), the corresponding count is 11 − 4 = 7. Note: We’re pretending here for simplicity that SQL supports periods whose contained values are integers. In practice, of course, those contained points will be SQL datetime values; thus, the expression to – from will return an SQL-style interval (i.e., a duration), which will then have to be cast to the desired integer value, thus: CAST ((to – from) AS INTEGER).
PACK, UNPACK, and U_ Operators
SQL has no support for the PACK and UNPACK operators—unfortunately a rather serious omission! A fortiori, therefore, it also has no support for the generalized relational operators (U_join and the rest, also the U_ comparisons) described in Chapter 11. It also has no support for the U_update operators (U_INSERT and the rest) described in Chapter 16.
Database Design
Our discussions in the previous section tacitly assumed a “fully temporal” design. And the reason for that assumption was that, frankly, there’s not much to be said—at least, not much of real interest, and certainly not much from a purely SQL perspective—about an SQL design that’s merely semitemporal. Just for the record, however, SQL can of course use its existing DATE and TIMESTAMP data types as a basis for defining semitemporal tables. Here’s a simple example. It’s an SQL version of the design consisting of relvars S_SINCE and SP_SINCE from Chapter 14 (see Figs. 14.1 and 14.3 in that chapter). Note the SQL versions of Constraints SR6 and SR9 in particular.
CREATE TABLE S_FROM
( SNO SNO NOT NULL ,
SNO_FROM DATE NOT NULL ,
STATUS INTEGER NOT NULL ,
STATUS_FROM DATE NOT NULL ,
UNIQUE ( SNO ) ) ;
CREATE TABLE SP_FROM
( SNO SNO NOT NULL ,
PNO PNO NOT NULL ,
SP_FROM DATE NOT NULL ,
UNIQUE ( SNO, PNO ) ,
FOREIGN KEY ( SNO ) REFERENCES S_FROM ( SNO ) ) ;
CREATE ASSERTION SR6 CHECK ( NOT EXISTS
( SELECT * FROM S_FROM
WHERE STATUS_FROM < SNO_FROM ) ) ;
CREATE ASSERTION SR9 CHECK ( NOT EXISTS
( SELECT * FROM SP_FROM NATURAL JOIN S_FROM
WHERE SP_FROM < SNO_FROM ) ) ;
Now let’s consider a fully temporal SQL design—a “historical tables only” design, in effect—for suppliers and shipments. Of course, we’ve already seen SQL definitions for tables S_FROM_TO and SP_FROM_TO, but now let’s bring supplier status history back into the picture, so that the complete database definition looks as shown in Fig. 19.2. Sample values are shown in Fig. 19.3, an edited version of Fig. 14.5 from Chapter 14.
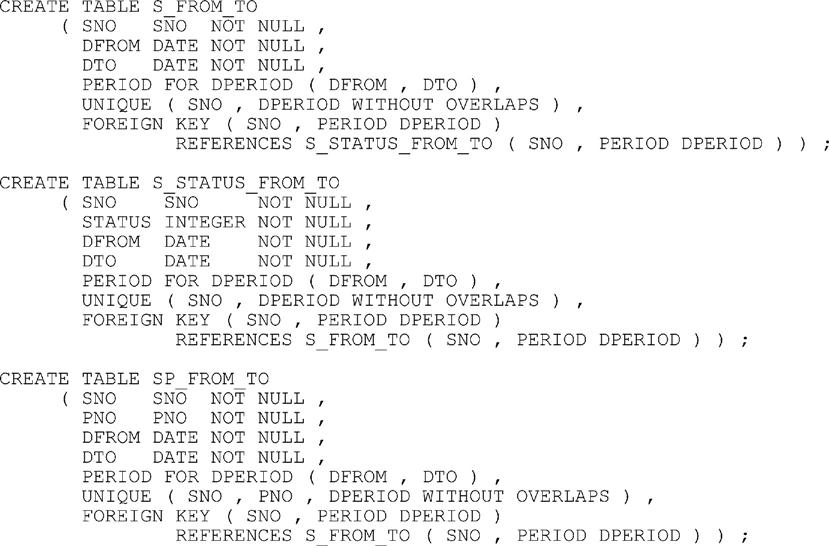
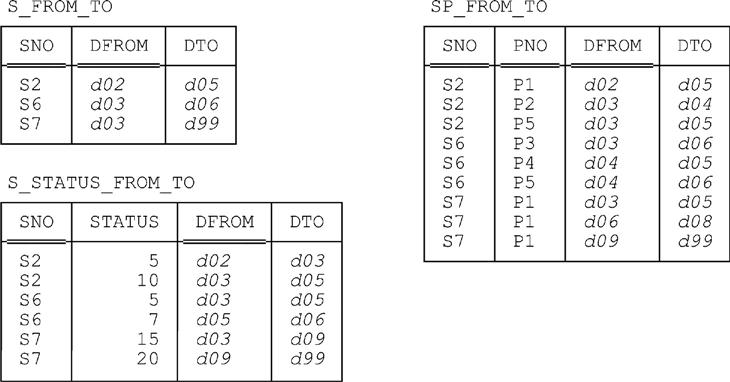
Note: The sample values shown in Fig. 19.3 aren’t meant to correspond in any particular way to the ones shown in Fig. 19.1.
Now let’s concentrate for the moment on table S_STATUS_FROM_TO. Here again is the UNIQUE specification for that table:
UNIQUE ( SNO, DPERIOD WITHOUT OVERLAPS )
In a nutshell, what this specification does is prevent the table from suffering from the redundancy and contradiction problems described in Chapters 13 and 14. (Note, however, that it doesn’t prevent it from suffering from the circumlocution problem.) More precisely, what it says is this:
(Expansion)11 Let row r in table S_STATUS_FROM_TO have SNO, STATUS, DFROM, and DTO values sno, st, df, and dt, respectively. Derive from that row n distinct rows, one for each DATE value d such that df ≤ d < dt; each such derived row contains the SNO value sno, the STATUS value st, and one of those n DATE values, d. Let T be a table containing all such derived rows for all such rows r (and nothing else besides), and let D be the column of T that contains those DATE values d. Then no two rows of that table T have the same (SNO,D) value.
The UNIQUE specifications for S_FROM_TO and SP_FROM_TO are analogous, except that for those two tables the contradiction problem doesn’t—in fact, can’t—arise.
Now, you might be thinking from the foregoing that WITHOUT OVERLAPS is equivalent to our PACKED ON constraint, but it isn’t, not quite (precisely because it doesn’t address the circumlocution problem), and the tables are thus not necessarily kept in packed form.12 Alternatively, you might be thinking it’s equivalent to our WHEN / THEN constraint, but again it isn’t. To see why not, consider what happens if S_STATUS_FROM_TO contains two rows for supplier S1 and status 20, one with period [d04,d08) and the other with period [d06,d10). Then the UNPACK implied by WHEN / THEN wouldn’t give rise to a uniqueness constraint violation but would simply eliminate the duplicates (for days 6 and 7) implied by these two rows (i.e., WHEN / THEN addresses the contradiction problem, not the redundancy problem). By contrast, the same thing does not happen—i.e., a uniqueness constraint violation would occur—with WITHOUT OVERLAPS (check the “expansion” algorithm above).
We turn now to the FOREIGN KEY specifications. Here again is the specification for the foreign key from S_STATUS_FROM_TO to S_FROM_TO:
FOREIGN KEY ( SNO , PERIOD DPERIOD )
REFERENCES S_FROM_TO ( SNO , PERIOD DPERIOD )
Incidentally, note the tiny syntactic inconsistency here: The FOREIGN KEY specification uses the explicit keyword PERIOD, twice, but the “target” UNIQUE specification doesn’t use it at all—indeed, it would fail on a syntax error if it did. Note also that referential actions such as cascade delete aren’t allowed in connection with foreign key specifications like the one shown.
Anyway, what the foregoing foreign key specification says is this: If we perform (a) the expansion process described above on S_STATUS_FROM_TO and (b) the analogous process on S_FROM_TO, then (c) the combination of SNO and the column D containing the DATE values produced in that expansion, in the expanded form of S_STATUS_FROM_TO, will be a regular foreign key referencing the corresponding columns in the expanded form of S_FROM_TO. In other words, if some row in S_STATUS_FROM_TO contains the period [f,t), then there must be one or more rows in S_FROM_TO with the same supplier number and with periods that when merged—when packed together, in fact—include that same period [f,t).13
The foreign key specifications for S_FROM_TO and SP_FROM_TO are analogous, of course.
The net of the foregoing discussions is this: While SQL doesn’t exactly support U_keys or foreign U_keys as such, it does support constructs of a somewhat similar nature. As a consequence, it manages to take care of six of “the nine requirements” from Chapter 14 in a fairly economical way, syntactically speaking. (The three it doesn’t take care of are R2, R5, and R8, or in other words the ones that have to do with circumlocution.) So that’s a definite plus. But there are some negatives as well:
■ First, each of S_FROM_TO and S_STATUS_FROM_TO has a foreign key that references the other. As a consequence, the tables must be kept “in synch,” as it were. Now, the operator we used for such purposes in Chapter 16 was multiple assignment (multiple relvar assignment, to be specific). Unfortunately, however, SQL has no direct support for such an operator, and the task of keeping those SQL tables in synch is thus not entirely straightforward. See the discussion of Updates U12, U13, and U14 in the section “Updates,” later, for further explanation.
■ Second, SQL doesn’t support PACK and UNPACK, and so the user’s job of making sure the various KEY and FOREIGN KEY constraints aren’t violated is rather more difficult than it might otherwise be. In other words, keeping the tables in packed form, assuming that’s what’s wanted, is at least partly the user’s problem—a problem that isn’t made any easier by the fact that, as noted previously, SQL also fails to support the U_update operators (U_INSERT in particular).
Queries
Let’s consider some of the sample queries from Chapter 15 and see how they might look in SQL, using the design of Fig. 19.2 and (where applicable) the sample values of Fig. 19.3. To be specific, we’ll consider Queries Q1-Q3, Q5, Q6-Q7, and Q9.
Query Q1: Get the status of supplier S1 on day dn, together with the associated period (this is a slightly modified version of Query Q1 from Chapter 15).
SELECT STATUS , DFROM , DTO
FROM S_STATUS_FROM_TO
WHERE SNO = SNO ( 'S1' )
AND DPERIOD CONTAINS dn
This one is straightforward, in part because the WITHOUT OVERLAPS specification for table S_STATUS_FROM_TO is sufficient to guarantee that there’ll be at most one row in that table that satisfies the condition in the WHERE clause. Note, however, that that WHERE clause makes it look as if that table has a column called DPERIOD, which of course it doesn’t. More to the point, the result table doesn’t either; in fact, the whole notion that columns DFROM and DTO together define an SQL-style period doesn’t apply to that result table. (It’s relevant to point out that the SELECT clause doesn’t mention DPERIOD, as such, at all; instead, it mentions—it has to mention—the boundary columns DFROM and DTO.) Thus, while table S_STATUS_FROM_TO does have an associated “application time,” the result table doesn’t. Application time periods don’t “carry through” operational expressions.
Now, this kind of situation is exactly what’s to be expected of a language in which certain constructs are treated as special cases (instead of as what some writers like to call “first class objects”) and well established language design principles such as orthogonality [35] are ignored. Be that as it may, the full consequences of such a situation aren’t immediately clear, but here’s one obvious one. Consider the following expression:
SELECT STATUS , DFROM , DTO
FROM ( SELECT *
FROM S_STATUS_FROM_TO ) AS POINTLESS
WHERE SNO = SNO ( 'S1' )
AND DPERIOD CONTAINS dn
This expression certainly looks as if it ought to be logically equivalent to the one shown previously, and indeed it would be, if DPERIOD were just a column name. In fact, however, it fails on a syntax error—the table denoted by the subquery in the FROM clause doesn’t have a column, or indeed anything at all, called DPERIOD.14 You might like to meditate on some of the implications of this state of affairs. For example, what happens if we use the expression SELECT * FROM S_STATUS_FROM_TO to define a view? Does that view inherit the period DPERIOD? Answer: No, it doesn’t (because if it did, it could only be thanks to still more special casing—special casing on top of special casing, in fact).
By the way, the fact that periods don’t carry through operational expressions is actually a logical consequence of what we earlier called the “not too unreasonable” rule that no SQL table can have more than one application time period, together with the rather less reasonable way that SQL has chosen to denote such periods—essentially, by representing what ought to be a general purpose construct in a special case way. For if periods did carry through such expressions, then the result of, e.g., a join might have two such periods (or, more generally, n such periods for some arbitrary n > 1), thereby violating that “not too unreasonable” rule.
Query Q2: Get pairs of supplier numbers such that the indicated suppliers were assigned their current status on the same day.
WITH t1 AS ( SELECT SNO , DFROM
FROM S_STATUS_FROM_TO
WHERE DPERIOD CONTAINS CURRENT_DATE ) ,
t2 AS ( SELECT SNO AS XNO , DFROM
FROM t1 ) ,
t3 AS ( SELECT SNO AS YNO , DFROM
FROM t1 ) ,
t4 AS ( SELECT XNO , YNO
FROM t2 NATURAL JOIN t3 )
SELECT XNO , YNO FROM t4 WHERE XNO < YNO
For an explanation of the logic underlying the foregoing formulation, see Chapter 15. By the way, note the use here of (and syntax for) SQL’s WITH construct. Note also the reference to the SQL “system variable”—also known as a datetime value function—CURRENT_DATE.
Query Q3: Get supplier numbers for suppliers who were able to supply both part P1 and part P2 at the same time.
SELECT DISTINCT t1 .SNO
FROM SP_FROM_TO AS t1 , SP_FROM_TO AS t2
WHERE t1.SNO = t2.SNO
AND t1.PNO = PNO ( 'P1' )
AND t2.PNO = PNO ( 'P2' )
AND t1.DPERIOD OVERLAPS t2.DPERIOD
Observe that we have to express this query, in part, in terms of an explicit invocation of one of Allen’s operators (OVERLAPS, in the case at hand), because SQL doesn’t support the higher level “U_” abstractions such as U_join.
Query Q5: Get supplier numbers for suppliers who, while they were under some specific contract, changed their status since they most recently became able to supply some part under that contract.
WITH t1 AS ( SELECT SNO, DFROM AS FX, DTO AS TX
FROM S_STATUS_FROM_TO ) ,
t2 AS ( SELECT SNO , FX , TX , DFROM , DTO
FROM t1 NATURAL JOIN S_FROM_TO ) ,
t3 AS ( SELECT SNO , FX , TX , DFROM , DTO
FROM t2
WHERE PERIOD ( DFROM , DTO ) CONTAINS PERIOD ( FX , TX ) ) ,
t4 AS ( SELECT SNO , DFROM AS FY , DTO AS TY
FROM SP_FROM_TO ) ,
t5 AS ( SELECT SNO , FX , TX , DFROM , DTO , FY , TY
FROM t4 NATURAL JOIN t3 ) ,
t6 AS ( SELECT SNO , FX , TX , DFROM , DTO , FY , TY
FROM t5
WHERE PERIOD ( DFROM , DTO ) CONTAINS PERIOD ( FY , TY ) ) ,
t7 AS ( SELECT SNO , ( SELECT MAX ( FX )
FROM t6 AS tt6
WHERE tt6.SNO = t6.SNO
AND tt6.DFROM = t6.DFROM
AND tt6.DTO = t6.DTO ) AS BXMAX ,
( SELECT MAX ( FY )
FROM t6 AS tt6
WHERE tt6.SNO = t6.SNO
AND tt6.DFROM = t6.DFROM
AND tt6.DTO = t6.DTO ) AS BYMAX
FROM t6 )
SELECT SNO FROM t7 WHERE BXMAX > BYMAX
Exercise: Does the formulation shown above assume that tables SP_FROM_TO and S_STATUS_FROM_TO are kept packed on DPERIOD? And should any of those SELECT clauses specify DISTINCT?
Query Q6: Get periods during which at least one supplier was under contract.
SELECT DISTINCT DFROM , DTO
FROM S_FROM_TO
Of course, the result here won’t be properly packed, in general, even if table S_FROM_TO is kept packed on DPERIOD. Now, we saw in Chapter 8 that PACK (at least in its simple “COLLAPSE” form) can be defined in terms of FORALL, EXISTS, “∈”, FIRST, LAST, PRE, and POST—and since all of these constructs can at least be simulated in SQL, it follows that it must be possible to write an SQL expression that, given an SQL table, returns a packed version of that table. Like us, however, you probably wouldn’t like to have to write such an expression, and we’re not even going to try.
Note: Remarks somewhat analogous to the foregoing would apply to an SQL version of Query A, the query we used in Chapter 5 and elsewhere to demonstrate the desirability of supporting a “temporal projection” operator.
Query Q7: Suppose the result of Query Q6 is kept as a table BUSY. Use BUSY to get periods during which no supplier was under contract at all.
Let ETERNITY be the result of the following expression:
SELECT TEMP.*
FROM ( VALUES ( DATE '01-01-01' , DATE '9999-12-31' ) )
AS TEMP ( DFROM , DTO )
Conceptually, then (and speaking rather loosely), what we need to do is unpack ETERNITY, unpack BUSY, form the difference between the two unpacked results in that order, and then pack that difference. The details are left as an exercise.15
Note: Remarks somewhat analogous to the foregoing would apply to an SQL version of Query B, the query we used in Chapter 5 and elsewhere to demonstrate the desirability of supporting a “temporal difference” operator.
Query Q9: Get (SNO,pf,pt,df,dt) quintuples such that supplier SNO was able to supply all parts with part numbers in the range [pt,pf) throughout the time period [df,dt).
SQL provides essentially no features at all to help with queries like this one. Note in particular that (a) the query involves nontemporal “periods” (or intervals)—namely, ranges of part numbers—and (b) the result ought by rights to involve two distinct “periods” (or intervals).
Updates
Now we consider some of the update examples from Chapter 16 (though we deliberately treat them here in a somewhat different order). Our first example (Update U12) involves just tables S_FROM_TO and S_STATUS_FROM_TO, not SP_FROM_TO.
Update U12: Add proposition(s) to show that supplier S9 has just been placed under contract, starting today, with status 15.
Tentative formulation:
INSERT INTO S_FROM_TO ( SNO , DFROM , DTO )
VALUES ( SNO ( 'S9' ) , CURRENT_DATE , DATE '9999-12-31' ) ;
INSERT INTO S_STATUS_FROM_TO ( SNO , STATUS , DFROM , DTO )
VALUES ( SNO ( 'S9' ) , 15 , CURRENT_DATE , DATE '9999-12-31' ) ;
Well, there are two problems here. The first is that each of the tables has a foreign key that references the other, and so they really need to be updated “simultaneously.” But SQL doesn’t support multiple assignment on tables. Somewhat unfortunately, therefore, what we have to do is wrap the two updates up into a transaction and defer the constraint checking to some later time (COMMIT time at the latest). Note: Actually, SQL has no explicit support for single table assignment, let alone support for the multiple version that we’d like here. Of course, it does support the INSERT, DELETE (etc.), shorthands, but again only in “single assignment” form.
The second problem is those two CURRENT_DATE references. In order to guarantee that both of the inserted rows wind up containing the exact same DFROM value, we ought really to “code defensively” by (a) assigning the value of CURRENT_DATE to some local variable (X, say) before doing either of the INSERTs, and then (b) replacing those separate references to CURRENT_DATE in those two INSERT statements by references to X instead.
Update U13: Remove all proposition(s) showing supplier S7 as being under contract.
Again several updates are needed, and they need to be wrapped up into a transaction (though again we won’t bother to show the transaction details):
DELETE FROM SP_FROM_TO WHERE SNO = SNO ( 'S7' ) ;
DELETE FROM S_STATUS_FROM_TO WHERE SNO = SNO ( 'S7' ) ;
DELETE FROM S_FROM_TO WHERE SNO = SNO ( 'S7' ) ;
Note that (with reference to the sample values shown in Fig. 19.3), some of the rows we’re deleting here represent current beliefs about past states of affairs.
Update U14: Supplier S7’s current contract has just been terminated. Update the database accordingly.
SET X = CURRENT_DATE ;
SET Y = X + INTERVAL '1' DAY ;
UPDATE S_FROM_TO
SET DTO = Y
WHERE SNO = SNO ( 'S7' )
AND DPERIOD CONTAINS X ;
UPDATE S_STATUS_FROM_TO
SET DTO = Y
WHERE SNO = SNO ( 'S7' )
AND DPERIOD CONTAINS X ;
UPDATE SP_FROM_TO
SET DTO = Y
WHERE SNO = SNO ( 'S7' )
AND DPERIOD CONTAINS X ;
Note the slight trickiness arising here in connection with the new DTO values.16 Once again these statements ought really all to be wrapped up into a transaction, of course.
Update U4: Add the proposition “Supplier S2 was able to supply part P4 on day 2.”
INSERT INTO SP_FROM_TO ( SNO, PNO, DFROM, DTO )
VALUES ( SNO ( 'S2' ), PNO ( 'P4' ), d02, d03 ) ;
But suppose the proposition had specified part P5 instead of P4. Then if we were to insert just the corresponding row into SP_FROM_TO, that table would contain the following two rows—

—and thus would no longer be properly packed, even if it was so before. Now, when we were faced with this problem in Chapter 16, we fixed it by defining a new operator, called U_INSERT. But SQL has no support for “U_” operators of any kind, and so the problem is simply passed back to the user.
Update U5: Remove the proposition “Supplier S6 was able to supply part P3 from day 3 to day 5, inclusive” (in other words, after the specified removal has been performed, the database shouldn’t show supplier S6 as supplying part P3 on any of days 3, 4, or 5).
DELETE
FROM SP_FROM_TO
WHERE SNO = SNO ( 'S6' )
AND PNO = PNO ( 'P3' )
AND DPERIOD EQUALS PERIOD ( d03, d06 ) ;
Now, this formulation does happen to work, because SP_FROM_TO does happen to contain a row satisfying exactly the specified conditions. But consider the following modified version of the example. Suppose the proposition to be removed had been “Supplier S7 was able to supply part P1 from day 4 to day 11.” Then the corresponding DELETE—
DELETE
FROM SP_FROM_TO
WHERE SNO = SNO ( 'S7' )
AND PNO = PNO ( 'P1' )
AND DPERIOD EQUALS PERIOD ( d04, d12 ) ;
—will have no effect. However, SQL does support a FOR PORTION OF clause on DELETE (referencing, specifically, the application time period), such that the desired removal in the example can be effected thus:
DELETE
FROM SP_FROM_TO FOR PORTION OF DPERIOD FROM d04 TO d12
WHERE SNO = SNO ( 'S7' )
AND PNO = PNO ( 'P1' ) ;
The FOR PORTION OF clause applies, in effect, to the table identified by the table reference in the immediately preceding FROM clause.17 It provides a limited version of the functionality provided by PORTION as described in Chapter 16. The general syntax is:
FOR PORTION OF p FROM t1 TO t2
Here p is the name of the application time period and t1 and t2 are expressions denoting values of the applicable SQL datetime type. Thus, what happens in the example—conceptually, at any rate18—is this:
1. Let table t1 contain just those rows of SP_FROM_TO that satisfy the boolean expression in the WHERE clause (i.e., the rows for supplier S7 and part P1).
2. Let table t2 contain just those rows of t1 that satisfy the boolean expression DPERIOD OVERLAPS [d04,d12).
3. Let table t3 contain just one row: namely, some row from t2.
4. Let table t4 be the result of unpacking t3 on DPERIOD.
5. Let table t5 be the result of removing from t4 all rows whose DPERIOD values (which are all “unit periods,” of course) are included in [d04,d12).
6. Let table t6 be the result of packing t5 on DPERIOD.
7. Let table t7 be the result of replacing t3, in SP_FROM_TO, by t6.
Let’s see how this procedure works out in detail for the case at hand:
■ t1 consists of the following three rows (we’ve labeled them for future reference):
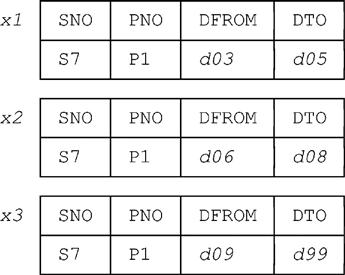
■ Let t3 be the table containing just row x1. Then unpacking t3 produces a table t4 containing just two rows, for [d03,d04) and [d04,d05), and removing the rows whose DPERIOD values are included in [d04,d12) produces a table t5 containing just one row, for [d03,d04). Packing t5 then produces t6, which is identical to t5 in this case. Thus, the effect of this step is to replace x1 in SP_FROM_TO by a row for [d03,d04).
■ Next, let t3 be the table containing just row x2. Then unpacking t3 produces a table t4 containing just two rows, for [d06,d07) and [d07,d08), and removing the rows whose DPERIOD values are included in [d04,d12) produces an empty table t5. Packing t5 produces t6, which is also empty. Thus, the effect of this step is simply to remove x2 from SP_FROM_TO.
■ Next, let t3 be the table containing just row x3. Then unpacking t3 produces a table t4 containing 90 rows, for [d09,d10), [d10,d11), …, and [d98,d99). Removing the rows whose DPERIOD values are included in [d04,d12) produces a table t5 containing all except the first three of these 90 rows. Packing t5 produces t6, which contains just one row, for [d12,d99]. Thus, the effect of this step is to replace x3 in SP_FROM_TO by a row for [d12,d99).
So the final value of SP_FROM_TO is as follows (the only change is, of course, in the highlighted rows, i.e., the ones for supplier S7 and part P1):
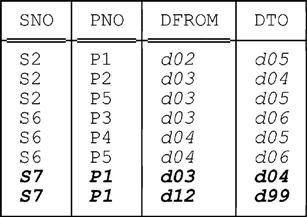
By the way, suppose we now execute the following INSERT (which can be regarded, a trifle loosely, as the inverse of the foregoing DELETE):
INSERT INTO SP_FROM_TO ( SNO , PNO , DFROM , DTO )
VALUES ( SNO ( 'S7' ), PNO ( 'P1' ), d04, d12 ) ;
Here’s the result (showing the rows for S7 and P1 only, for simplicity):
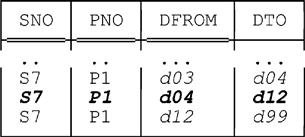
The point about this example, of course, is that the three rows for S7 and P1 in the result are not automatically packed together into one.
Note finally that FOR PORTION OF can be used with UPDATE as well as DELETE. The specifics are essentially as for the DELETE case, and we omit the details here, except to note that—in contrast to PORTION UPDATE as discussed in Chapter 16—the SET clause in such an UPDATE isn’t allowed to assign to either the “from” or the “to” column of the application time period.
System Time
In addition to application time, SQL also supports system time, which is the SQL term for transaction time. (Our own preferred term for this concept is logged time, as you’ll probably recall; in this chapter, however, we’ll stay with the SQL term.) Now, you’ll probably also recall that the approach we proposed to this issue in Chapter 17 involved having separate logged time relvars, automatically maintained by the DBMS as—in effect—views of the system log. But SQL doesn’t do anything like that. Instead, it allows tables to have an explicit system time period (at most one such per table), instead of or as well as an explicit application time period. Note, therefore, that any table—any base table, that is—can have a system time period, regardless of whether or not it’s a historical table in the sense in which we’ve been using this latter term in this chapter so far.19 For simplicity, therefore, let’s begin by looking at an example of a “nonhistorical” table with a system time period. To be specific, let’s suppose for the sake of the example that we want to keep system time information, but not application time information, for suppliers and their status values. Then instead of S_STATUS_FROM_TO, we might define a table XS_STATUS_FROM_TO that looks like this:
CREATE TABLE XS_STATUS_FROM_TO
( SNO SNO NOT NULL ,
STATUS INTEGER NOT NULL ,
XFROM TIMESTAMP(12) GENERATED ALWAYS AS ROW START NOT NULL ,
XTO TIMESTAMP(12) GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME ( XFROM , XTO ) ,
UNIQUE ( SNO ) ,
FOREIGN KEY ( SNO ) REFERENCES XS_FROM_TO ( SNO ) )
WITH SYSTEM VERSIONING ;
■ Observe first that table XS_STATUS_FROM_TO has j ust two “regular” columns, SNO and STATUS. These are the only columns users can update directly (see the subsection “Updates on System-Versioned Tables” below).
■ The system time period—which, as usual in SQL, uses the closed:open interpretation—has the required name SYSTEM_TIME. The PERIOD FOR SYSTEM_TIME specification defines columns XFROM and XTO—which for the sake of the example we’ve defined to be of type TIMESTAMP(12), meaning times that are accurate to the picosecond—to be the boundary columns for that period.
■ The specifications GENERATED ALWAYS AS ROW START (on XFROM) and GENERATED ALWAYS AS ROW END (on XTO) are required. That’s because values of those columns aren’t assigned by explicit user updates in the usual way but are instead assigned automatically by the system (again, see the subsection “Updates on System-Versioned Tables” below).
■ The specification WITH SYSTEM VERSIONING is actually optional, but we’ll treat it as required until further notice. Note, however, that if it appears, then PERIOD FOR SYSTEM_TIME must be specified as well.
■ The remaining specifications are discussed in the next subsection but one, “UNIQUE and FOREIGN KEY Specifications for System-Versioned Tables.”
Updates on System-Versioned Tables
Regardless of whether or not it has an application time period, a table for which WITH SYSTEM VERSIONING is specified is called a system-versioned table. Consider the system-versioned table XS_STATUS_FROM_TO. When it’s first defined, that table is empty, of course. Suppose we now execute the following INSERT statement:
INSERT INTO XS_STATUS_FROM_TO ( SNO, STATUS )
VALUES ( SNO ( 'S1' ) , 20 ) ;
Further, suppose this INSERT statement is executed at time t02 by the system clock.20 Then the row that’s actually inserted looks like this:

Observe, therefore, that the user does not—in fact, must not—specify explicit values to be inserted into columns XFROM and XTO; instead, the system automatically inserts the timestamp t02 in the XFROM position and “the end of time” timestamp t99 in the XTO position. Note: Here and elsewhere in this chapter we use t99 to denote the maximum value of type TIMESTAMP(12). For the record, the actual SQL value would be:
TIMESTAMP '9999-12-31 23:59:59.999999999999'
Now suppose we execute the following UPDATE statement:
UPDATE XS_STATUS_FROM_TO
SET STATUS = 25
WHERE SNO = SNO ( 'S1' ) ;
Further, suppose this UPDATE statement is executed at time t06 by the system clock. After the UPDATE, then, the table looks like this:
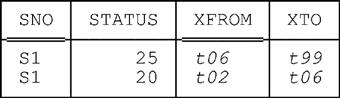
In other words, the UPDATE in this example does two things:
■ It inserts a new row for supplier S1 with STATUS value 25, XFROM value t06, and XTO value t99.
■ It also replaces the old row for supplier S1 by a new row that’s identical to that old row except that the XTO value is t06 instead of t99.
Aside: Suppose the “new” STATUS value happens to be the same as the “old” one (i.e., suppose the SET clause in the UPDATE specified STATUS = 20 instead of STATUS = 25). Then a new row will still be inserted, with the result that the table overall will no longer be packed on SYSTEM_TIME, even if it was so before. End of aside.
Finally, suppose we subsequently execute the following DELETE statement:
DELETE
FROM XS_STATUS_FROM_TO
WHERE SNO = SNO ( 'S1' ) ;
Further, suppose this DELETE statement is executed at time t45 by the system clock. After the DELETE, then, the table looks like this:
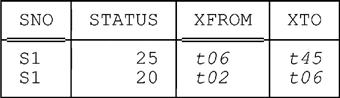
In other words, the DELETE doesn’t actually delete anything; instead, it simply replaces the XTO value in the “current row” for supplier S1 by t45. Note: The current row for supplier S1 is, of course, the row for supplier S1 in which the XTO value is t99 (see the next subsection for further discussion). After the DELETE, there’s no current row for supplier S1 at all.
Observe now that current rows are the only ones that can be updated21—once a “historical” row gets into the table (see the subsection immediately following), it’s there forever, and it never changes (though of course it can be queried, as we’ll see).
To sum up: The system time columns in a system-versioned table are effectively invisible as far as update operations are concerned—they’re maintained entirely, and of course desirably, by the system, not the user, and there’s no way the user can assign values to those columns directly. Note the following also:
■ Let C be a contract for some supplier Sx.
■ Let xcf and xct be the minimum XFROM value in table XS_STATUS_FROM_TO for contract C and the maximum XTO value in table XS_STATUS_FROM_TO for contract C, respectively.
■ Let t be an arbitrary time such that xcf ≤ t < xct.
■ Then table XS_STATUS_FROM_TO contains exactly one row for supplier Sx in which the system time period contains that value t.
In other words, XS_STATUS_FROM_TO contains the total status history for contract C, without any redundancy or gaps (though not necessarily without circumlocution).
UNIQUE and FOREIGN KEY Specifications for System-Versioned Tables
Every row in a system-versioned table is either a current row or a historical row. If as in our example the system time end column is called XTO, then a current row is, as already indicated, a row in which the XTO value is “the end of time.” A historical row is a row that’s not current.
Observe now that the UNIQUE and FOREIGN KEY specifications in the table definition for a system-versioned table apply to the current rows only. In other words, in the case of table XS_STATUS_FROM_TO:
■ The specification UNIQUE (SNO) says there’s at most one current row in that table at any given time for a given supplier number.
■ The specification FOREIGN KEY (SNO) REFERENCES XS_FROM_TO (SNO) says that for every current row in the table at any given time, there’s exactly one current row in table XS_FROM_TO with the same supplier number.22 In fact, of course, there’ll be a foreign key specification on XS_FROM_TO that “goes the other way” as well, thanks to our usual denseness requirements: For every current row in XS_FROM_TO at any given time, there’ll be exactly one current row in XS_STATUS_FROM_TO with the same supplier number.
Now, the foregoing rules are perhaps reasonable, given that historical rows are never updated and can therefore never violate any constraints.23 At the same time, however, they do seem a little questionable … What’s really going on here is this: A system-versioned table like XS_STATUS_FROM_TO is really a kind of shorthand for a combination of two separate tables, one current and one historical. And it might be clearer to make this fact explicit, somewhat along the lines suggested in Chapters 12-15 in connection with our own “preferred approach” to design (though there we were talking about application time, not system time). Then there’d be no need to play the foregoing kinds of games with SQL’s existing UNIQUE and FOREIGN KEY syntax. On the other hand, making the separation explicit might make certain queries more complex, unless the system provides some appropriate shorthands.
Aside: IBM’s DB2 product, which does make the separation explicit, shows what such shorthands might look like in practice. By the way, it’s worth noting that there could be certain administrative advantages to making the separation explicit. For example, it might be desirable to have two different indexes, one on the current table and one on the historical table; or it might be desirable to be able to carry out recovery operations on the two tables separately. But these are pragmatic issues, of course, having to do with the way the implementation in question happens to be designed. Ideally, therefore, they should have no bearing on what the user interface looks like. End of aside.
Queries on System-Versioned Tables
By default, queries on a system-versioned table apply only to the current rows (i.e., they behave as if the historical rows simply weren’t there). Thus, if table XS_STATUS_FROM_TO contains just two rows right now, as follows—
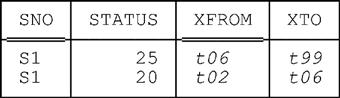
—then the query
SELECT STATUS
FROM XS_STATUS_FROM_TO
WHERE SNO = SNO ( 'S1' )
returns the following result:24

To query historical rows, or more generally to query both current and historical rows, we can qualify the pertinent table reference (in the FROM clause) by a “FOR SYSTEM_TIME …” specification, as in this example:
SELECT STATUS, XFROM, XTO
FROM XS_STATUS_FROM_TO FOR SYSTEM_TIME AS OF t04
WHERE SNO = SNO ( 'S1' )
Result (see further explanation below):
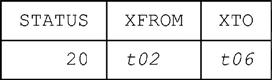
Note that this result does have XFROM and XTO columns (of course), but it doesn’t have a system time period as such—like application time periods, system time periods don’t “carry through” operational expressions.
The following FOR SYSTEM_TIME options are supported (t, t1, and t2 are expressions denoting timestamps):
■ FOR SYSTEM_TIME AS OF t
Selects rows whose system time period contains t.
■ FOR SYSTEM_TIME FROM t1 TO t2
Selects rows whose system time period overlaps the closed:open period [t1 :t2).
■ FOR SYSTEM_TIME BETWEEN t1 AND t2
Selects rows whose system time period overlaps the closed:closed period [t1:t2].
The semantics are as indicated.25 Observe that FOR SYSTEM_TIME can be thought of as providing a kind of FOR PORTION OF functionality, albeit for queries instead of updates. (On the other hand, FOR SYSTEM_TIME is used to qualify a specific reference to a specific table—typically within a FROM clause within a SELECT expression—whereas FOR PORTION OF is used, in effect, to qualify a DELETE or UPDATE statement as such.) Omitting the FOR SYSTEM_TIME specification entirely is equivalent to specifying FOR SYSTEM_TIME AS OF CURRENT_TIMESTAMP.
Tables with System Time but without WITH SYSTEM VERSIONING
Finally, recall that WITH SYSTEM VERSIONING is in fact optional. However, a table with system time for which WITH SYSTEM VERSIONING isn’t specified doesn’t really support much by way of “transaction time history” at all (at least, not as that term is usually understood), even though it does have a system time period. Certainly the rows in such a table are all current ones—there aren’t any historical rows. Thus, INSERT on such a table behaves just as it does for a system-versioned table; UPDATE does change the system start time in affected rows but doesn’t insert any “history” rows; and DELETE simply removes affected rows, again without inserting any “history” rows. In consequence, every row in such a table contains (a) a system start time indicating when that row was last updated (or inserted) and (b) a system end time that’s always equal to “the end of time.”
Bitemporal Tables
An SQL table can have both an application time period and a system time period. Everything we’ve said in previous sections regarding tables with just one of the two applies equally to such “bitemporal tables,” mutatis mutandis (note, however, that bitemporal table isn’t an official SQL term). Here by way of example are definitions for bitemporal versions (with system versioning) of tables S_FROM_TO and S_STATUS_FROM_TO:
CREATE TABLE BS_FROM_TO
( SNO SNO NOT NULL ,
DFROM DATE NOT NULL ,
DTO DATE NOT NULL ,
PERIOD FOR DPERIOD ( DFROM , DTO ) ,
UNIQUE ( SNO , DPERIOD WITHOUT OVERLAPS ) ,
FOREIGN KEY ( SNO , PERIOD DPERIOD )
REFERENCES BS_STATUS_FROM_TO ( SNO , PERIOD DPERIOD ) ,
XFROM TIMESTAMP(12) GENERATED ALWAYS AS ROW START NOT NULL ,
XTO TIMESTAMP(12) GENERATED ALWAYS AS ROW END NOT NULL ,
PERIOD FOR SYSTEM_TIME ( XFROM , XTO ) )
WITH SYSTEM VERSIONING ;
CREATE TABLE BS_STATUS_FROM_TO
( SNO SNO NOT NULL ,
STATUS INTEGER NOT NULL ,
DFROM DATE NOT NULL ,
DTO DATE NOT NULL ,
PERIOD FOR DPERIOD ( DFROM , DTO ) ,
UNIQUE ( SNO , DPERIOD WITHOUT OVERLAPS ) ,
FOREIGN KEY ( SNO , PERIOD DPERIOD )
REFERENCES BS_FROM_TO ( SNO , PERIOD DPERIOD )
XFROM TIMESTAMP(12) GENERATED ALWAYS AS ROW START NOT NULL ,
XTO TIMESTAMP(12) GENERATED ALWAYS AS ROW END NOT NULL ,
PERIOD FOR SYSTEM_TIME ( XFROM , XTO ) )
WITH SYSTEM VERSIONING ;
Now let’s focus on just BS_STATUS_FROM_TO, for definiteness. When it’s first defined, that table is empty, of course. Suppose we now execute the following INSERT statement:
INSERT INTO BS_STATUS_FROM_TO ( SNO, STATUS, DFROM, DTO )
VALUES ( SNO ( 'S2' ) , 5 , d02 , d05 ) ;
Further, suppose this INSERT statement is executed at time t11. Then the row that’s actually inserted looks like this:

Now suppose we execute the following UPDATE statement at time t22 (note the FOR PORTION OF specification):
UPDATE BS_STATUS_FROM_TO
FOR PORTION OF DPERIOD FROM d03 TO d04
SET STATUS = 10
WHERE SNO = SNO ( 'S2' ) ;
After this UPDATE, the table looks like this:
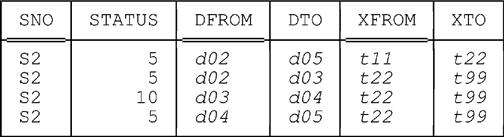
Now suppose we execute the following DELETE statement at time t33 (again note the FOR PORTION OF specification):26
DELETE
FROM BS_STATUS_FROM_TO
FOR PORTION OF DPERIOD FROM d03 TO d05
WHERE SNO = SNO ( 'S2' ) ;
Now the table looks like this:
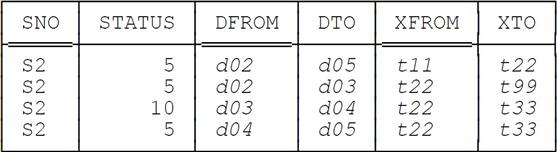
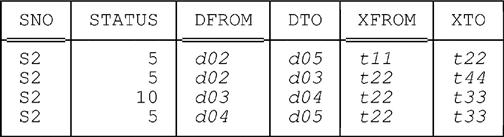
Finally, we execute the following DELETE statement at time t44:
DELETE
FROM BS_STATUS_FROM_TO
WHERE SNO = SNO ( 'S2' ) ;
Then the final version of the table looks like this:
Summary and Assessment
In this final section, we briefly summarize the features of our own approach to temporal data as described in Parts II and III of this book and show in each case whether SQL supports the feature in question (and if so, how). We also offer some occasional comments regarding that SQL support.
Database Design
In Chapter 12, we described three broad approaches to design: since relvars only, during relvars only, or a mixture, with the mixture being our preference. SQL effectively assumes the second approach—at least, it provides no direct support for the third, though there’s nothing to stop us from adopting such a scheme if we want to. Of course, as explained in Chapter 12, that second approach inevitably entails dealing with “the moving point now” in some ad hoc kind of way, and we’ve seen that SQL agrees with us in using explicit “end of time” markers for that purpose.
We also recommended strongly in Chapter 12 that during relvars be in 6NF. Of course, designing relvars (or tables) to be in some particular normal form is indeed a design matter, not a matter of legislation, so SQL quite rightly has nothing to say on the issue. But it’s hard to escape the impression that SQL’s temporal features were expressly designed on the basis of an assumption that converting a nontemporal database into a temporal analog could and should be done by simply adding timestamp columns to existing tables (in which case it’s quite likely that those resulting temporal tables won’t be in 6NF). For example, consider this extract from reference [65]:
The choice of returning current … rows as the default [i.e., from a query on a system-versioned table] … helps with … database migration in that applications running on non system-versioned tables would continue to work and produce the same results when those tables are converted to system-versioned tables.
And this from the same source:
One of the advantages of the SQL:2011 approach over an approach based on the period data type is that it allows existing databases … to take advantage of the SQL:2011 extensions more easily. Ever since DBMSs have been on the scene, users have been building their own solutions for handling temporal data as part of their application logic … It would be very expensive for users invested in such solutions to replace them with a solution that uses a single column of [some] period type.
Well, we’ve given our reasons elsewhere (see, e.g., reference [29]) for being somewhat skeptical regarding the kinds of scenarios being envisaged here; indeed, we explained in some detail in Chapter 12 why doing temporal database design by simply adding a timestamp attribute to a relvar without one wasn’t, in general, a very good idea.
In Chapter 13, we proposed the PACKED ON, WHEN /THEN, U_key, and foreign U_key constraints for temporal relvars. SQL has features that provide some but not all of the functionality of these constraints. To be specific:
a. WITHOUT OVERLAPS on an SQL UNIQUE specification can be used to prevent redundancy and contradiction, though not circumlocution.
b. The UNIQUE and FOREIGN KEY specifications, if used in connection with tables with an application time period (and if used appropriately, of course), are almost equivalent to analogous U_key and foreign U_key specifications.
But keeping tables in fully packed form, assuming that’s what’s desired, is the user’s responsibility. (Well, so it is in our proposals too—but then we provide various features, such as U_INSERT, that are explicitly intended to help the user in this regard. SQL doesn’t, not really.)
We also proposed some syntactic shorthands in Chapter 14—basically the SINCE_FOR and HISTORY_IN specifications—to simplify the process of defining the relvars in our preferred approach. SQL has nothing analogous. Of course, it doesn’t need anything corresponding to HISTORY_IN, because it doesn’t do horizontal decomposition anyway. But something analogous to SINCE_FOR could be useful.
We also mentioned the possibility of another syntactic shorthand in Chapters 15 and 16—basically some kind of a COMBINED_IN specification—to simplify the process of querying and updating the relvars by undoing the decompositions involved in our preferred approach. Again SQL has nothing analogous. Of course, it doesn’t really need anything for undoing horizontal decomposition, because, to say it again, it doesn’t really do horizontal decomposition in the first place. But undoing vertical decomposition is another matter.
Feature List
We now present a list of the various features of our overall approach and their SQL counterparts (where such exist), together with some brief commentary where appropriate. Please note, however, that we most definitely do not want this list to be used as a basis for any kind of “checklist” evaluation (not of SQL per se, and not of anything else, either). We do think it can serve as a convenient framework for structuring discussion, but it’s not meant to serve as a basis for any kind of scoring scheme. We’re not interested in scoring schemes.
Note: Of course, many of the features we show below as “missing” in SQL do have various workarounds; thus, a no in the SQL column should usually—though not always!—be taken to mean only “no direct support.”
| Feature | SQL:2011 analog |
| intervals (values) | periods (but value pairs, not values) |
| interval type generator and interval types | no — periods aren’t “first class objects” and can’t be used orthogonally |
| no particular interval style forced by the system | periods always closed:open |
| “automatic” enforcement of “from” < “to” (in closed:open terms) | yes |
| nontemporal intervals | temporal periods only |
| any ordinal type usable as a point type | DATE and TIMESTAMP types only |
| successor function (NEXT_T) | yes — e.g., d + INTERVAL ‘1’ DAY |
| PRIOR_T | yes — e.g., d − INTERVAL ‘1’ DAY |
| FIRST_T | yes27 — e.g., DATE ‘0001–01–01’ |
| LAST_T | yes28 — e.g., DATE ‘9999–12–31’ |
| interval attribute reference | period name (but only in certain boolean expressions and FOR PORTION OF clauses) |
| interval selector invocation (including interval literals) | period predicand (but only in certain boolean expressions and FOR PORTION OF clauses) |
| BEGIN | yes — “from” (column reference) |
| END | yes — e.g.,“to” – INTERVAL ‘1’ DAY |
| PRE | yes — e.g., “from” – INTERVAL ‘1’ DAY |
| POST | yes — “to” (column reference) |
| POINT FROM | no |
| “∈” | no |
| “∋” | CONTAINS (but care needed over “to”) |
| “=” (Allen) | EQUALS |
| “⊆” | no |
| “⊂” | no |
| “⊇” | CONTAINS (note the overloading) |
| “⊃” | no |
| BEFORE | PRECEDES |
| AFTER | SUCCEEDS |
| OVERLAPS | OVERLAPS |
| MEETS | no29 |
| MERGES | no |
| BEGINS | no |
| ENDS | no |
| COUNT | “to” – “from” (but result must be cast to type INTEGER) |
| UNION | no |
| INTERSECT | no |
| MINUS | no |
| relvars with two or more interval attributes | no — except for the special case of a bitemporal table |
| derived relations with intervals | no |
| EXPAND and COLLAPSE | no |
| PACK and UNPACK on one attribute | no |
| PACK and UNPACK on any number of attributes | no |
| “automatic” packing of query results | no |
| updating beliefs about the past | yes |
| U_ operators (U_join, etc.) | no |
| U_ comparisons | no |
| interval-only relations | yes |
| “Queries A and B” (see, e.g., Chapter 11) | intolerably clumsy |
| “nine requirements” (see Chapter 14) | prevent redundancy and contradiction: yes prevent circumlocution: no denseness: yes (but needs deferred checking) |
| multiple relvar assignment | no |
| U_update operators | no |
| PORTION (single interval) | yes |
| PORTION (two or more intervals) | no |
| stated time | application time (base tables only) |
| logged time | system time30 (base tables only; explicitly part of the table in question) |
| LOGGED_TIMES_IN (see Chapter 17) | no |
| “automatic” packing of logged time query results | no |
| more than one successor function (as in, e.g., DDATE vs. MDATE) | yes — e.g., d + INTERVAL ‘1’ DAY vs. d + INTERVAL ‘1’ MONTH (but one point type, not two) |
| numeric point types (as in, e.g., NUMERIC(p,q)) | no |
| cyclic point types (see Appendix A) | no |
To all of the above, we’d like to add the following.
■ Our own approach is truly general purpose. It’s based on a widely applicable abstraction, the interval. What’s more, it conforms 100 percent to relational principles. The only places where time as such shows up in our approach are in connection with (a) design specifics—but then, as previously noted, design considerations are largely orthogonal to relational model considerations anyway—and (b) logged times, as described in Chapter 17.
■ SQL’s approach, by contrast, is quite definitely specific to temporal data as such (as indeed the very term period strongly suggests). The concept of time is all pervasive. Partly as a consequence of this state of affairs, SQL also violates certain rather important principles: The Assignment Principle, certainly (see Chapter 3); The Information Principle, at least arguably31 (see Chapter 4); and The Principle of Interchangeability (of views and base relvars—see reference [44]). It also suffers from a variety of ad hoc limitations: e.g., the limitation of at most two (rather special) periods per table, and the limitation of periods to base tables specifically (this latter is the source of the violation of The Principle of Interchangeability, of course).
Exercises
19.1 Given table XS_STATUS_FROM_TO as defined in the body of the chapter, what does the expression SELECT * FROM XS_STATUS_FROM_TO evaluate to?
19.2 What are the predicates for S_STATUS_FROM_TO and XS_STATUS_FROM_TO?
19.3 Here repeated from Exercise 2.2 in Chapter 2 are Tutorial D definitions for the three relvars in the original version of the courses-and-students database:
VAR COURSE BASE RELATION
{ COURSENO COURSENO , CNAME NAME , AVAILABLE DATE }
KEY { COURSENO } ;
VAR STUDENT BASE RELATION
{ STUDENTNO STUDENTNO , SNAME NAME , REGISTERED DATE }
KEY { STUDENTNO } ;
VAR ENROLLMENT BASE RELATION
{ COURSENO COURSENO , STUDENTNO STUDENTNO , ENROLLED DATE }
KEY { COURSENO , STUDENTNO }
FOREIGN KEY { COURSENO } REFERENCES COURSE
FOREIGN KEY { STUDENTNO } REFERENCES STUDENT ;
Observe now that although we didn’t say as much in Chapter 2, this database is actually semitemporal. Give CREATE TABLE statements for a fully temporal SQL analog.
19.4 (Based on Exercises 15.2-15.5 in Chapter 15) Given your answer to Exercise 19.3, write SQL queries for the following:
a. Get student numbers for students currently enrolled on both course C1 and course C2.
b. Get student numbers for students not currently enrolled on both course C1 and course C2.
c. Get intervals during which at least one course was being offered.
d. Get intervals during which no course was being offered at all.
19.5 (Based on the answer to Exercise 16.2 in Chapter 16.) Given your answer to Exercise 19.3, write SQL updates for the following:
a. New courses C542 (“Tutorial D”) and C543 (“Temporal Databases”) became available on June 1st, 2013.
b. Currently available courses C193 (“SQL”) and C203 (“Object Oriented Databases”) were discontinued at the end of May this year (2013).
c. Student ST21, Hugh Manatee, not currently registered with the university, was registered from October 1st, 2011, to June 30th, 2012, but the database doesn’t show that fact.
d. Student ST19 changed her name to Anna Marino on November 18th, 2012.
19.6 Let BSP_FROM_TO be a system-versioned bitemporal analog of table SP_FROM_TO from the body of the chapter. Give a suitable CREATE TABLE statement.
19.7 Using the bitemporal table BS_FROM_TO as defined in the body of the chapter, write SQL queries for the following:
a. When if ever did the database say that supplier S2 was under contract on day 4?
b. On day 8, what did the database say was supplier S2’s term of contract?
19.8 In the body of the chapter, we saw that current rows in tables with system time have a system time period in which the “to” value is represented by “the end of time” (t99 in examples). But system time is just SQL’s term for transaction time or—our preferred term—logged time, and we saw in Chapter 17 that, by definition, transaction times can never refer to the future. How do you reconcile this state of affairs?
19.9 Our explanation of system time (also known as transaction time or—our preferred term—logged time) in the body of the chapter referred to the system clock. However, we did also say, in a footnote, that the standard doesn’t actually mention this concept—it merely says there’s something called the transaction timestamp, which is required to remain constant throughout the life of the transaction in question and is used for the purpose of timestamping rows in tables with system time. How do you think transaction timestamps might be implemented in a real system?
Answers
19.1 It evaluates to that restriction of the table that contains current rows only. Note, therefore, that the usual definition, to the effect that SELECT * FROM T returns table T in its entirety, is no longer applicable. Perhaps even more counterintuitively, the expression TABLE T can no longer be said to denote table T(!). Note: In case you’re unfamiliar with this latter SQL construct—i.e., an expression of the form TABLE T—we should explain that it’s defined to be shorthand for SELECT * FROM T. (At least, that’s what the standard says; however, it would probably be more correct to say it’s shorthand for a parenthesized version of this latter expression, thus: (SELECT * FROM T).)
19.2 We don’t have a good answer to this exercise. In fact, we seriously doubt whether a good answer even exists. The essence of the problem is this: Although the tables in question are guaranteed to be free of redundancy (and of course contradiction), they’re not guaranteed to be free of circumlocution. To illustrate the point, let’s focus on table S_STATUS_FROM_TO, for definiteness. Here then is the obvious first attempt at a predicate—let’s call it P—for that table:
Supplier SNO had status STATUS throughout the period (“period p”) from day DFROM to the day that’s the immediate predecessor of day DTO, inclusive.
Note that we can’t extend this predicate by adding and not throughout any period that properly includes period p, precisely because the table isn’t guaranteed to be kept packed on DPERIOD.
Now, Fig. 19.3 shows S_STATUS_FROM_TO as containing a row—let’s call it row r—indicating that supplier S7 had status 15 throughout the period [d03,d09). However, there are numerous ways of splitting up that period [d03,d09) into smaller, nonoverlapping periods. Here are just a few of them:
■ [d03,d04) [d04,d05) [d05,d06) [d06,d07) [d07,d08) [d08,d09)
■ [d03,d05) [d05,d06) [d06,d07) [d07,d08) [d08,d09)
■ [d03,d04) [d04,d06) [d06,d07) [d07,d08) [d08,d09)
■ [d03,d06) [d06,d08) [d08,d09)
And so on. It follows that it would be possible, without violating the WITHOUT OVERLAPS constraint on S_STATUS_FROM_TO, to replace row r by several distinct rows, and to do so, moreover, in several different ways. And every such replacement row—call it r’—would represent a true instantiation of predicate P! So predicate P can’t possibly be right. Why not? Well, recall The Closed World Assumption from Chapter 3. That assumption, translated into SQL terms, says that row r appears in table T at time t if and only if r satisfies the predicate for T at time t (emphasis added). In the case at hand, however, table S_STATUS_FROM_TO clearly isn’t going to contain all of those possible rows r’at the same time, and so predicate P clearly isn’t sufficient, in and of itself, to pin down just which rows do or don’t appear in that table at any given time.
Here’s another predicate we might consider (let’s call it P'):
Supplier SNO had status STATUS throughout the period (“period p”) from day DFROM to the day that’s the immediate predecessor of day DTO, inclusive, and hence—but only implicitly—throughout every period properly included in period p.
But predicate P' doesn’t do the job either. To be specific, it’s true—as it was with the previous attempt, predicate P—that if row r appears in the table, then row r necessarily satisfies this predicate; conversely, however, it isn’t true that if row r satisfies this predicate, then row r necessarily appears in the table.
To sum up: It seems to be the case that certain real world situations can be represented by the same SQL table—table S_STATUS_FROM_TO, in the case at hand—in more than one way. This state of affairs begins to look like a rather serious violation of relational principles. To put it another way, avoiding circumlocution seems to be even more important than we originally thought, and SQL tables, precisely because they don’t avoid it, seem to be less than fully respectable, relationally speaking.32
19.3 In contrast to earlier exercises and answers having to do with this database (see, e.g., Exercise 12.8c in Chapter 12), we choose to go for a pure 6NF design here.
CREATE TABLE COURSE_FROM_TO
( COURSENO COURSENO NOT NULL ,
DFROM DATE NOT NULL ,
DTO DATE NOT NULL ,
PERIOD FOR AVAILABLE ( DFROM , DTO ) ,
UNIQUE ( COURSENO, AVAILABLE WITHOUT OVERLAPS ) ,
FOREIGN KEY ( COURSENO, PERIOD AVAILABLE )
REFERENCES COURSE_NAME_FROM_TO ( COURSENO , PERIOD NAMED ) ) ;
CREATE TABLE COURSE_NAME_FROM_TO
( COURSENO COURSENO NOT NULL ,
CNAME NAME NOT NULL ,
DFROM DATE NOT NULL ,
DTO DATE NOT NULL ,
PERIOD FOR NAMED ( DFROM , DTO ) ,
UNIQUE ( COURSENO , NAMED WITHOUT OVERLAPS ) ,
FOREIGN KEY ( COURSENO , PERIOD NAMED )
REFERENCES COURSE_FROM_TO ( COURSENO , PERIOD AVAILABLE ) ) ;
CREATE TABLE STUDENT_FROM_TO
( STUDENTNO STUDENTNO NOT NULL ,
DFROM DATE NOT NULL ,
DTO DATE NOT NULL ,
PERIOD FOR REGISTERED ( DFROM , DTO ) ,
UNIQUE ( STUDENTNO , REGISTERED WITHOUT OVERLAPS ) ,
FOREIGN KEY ( STUDENTNO , PERIOD REGISTERED )
REFERENCES STUDENT_NAME_FROM_TO ( STUDENTNO , PERIOD NAMED ) ) ;
CREATE TABLE STUDENT_NAME_FROM_TO
( STUDENTNO STUDENTNO NOT NULL ,
SNAME NAME NOT NULL ,
DFROM DATE NOT NULL ,
DTO DATE NOT NULL ,
PERIOD FOR NAMED ( DFROM , DTO ) ,
UNIQUE ( STUDENTNO , NAMED WITHOUT OVERLAPS ) ,
FOREIGN KEY ( STUDENTNO , PERIOD NAMED )
REFERENCES STUDENT_FROM_TO ( STUDENTNO , PERIOD REGISTERED ) ) ;
CREATE TABLE ENROLLMENT_FROM_TO
( COURSENO COURSENO NOT NULL ,
STUDENTNO STUDENTNO NOT NULL ,
DFROM DATE NOT NULL ,
DTO DATE NOT NULL ,
PERIOD FOR ENROLLMENT ( DFROM , DTO ) ,
UNIQUE ( COURSENO , STUDENTNO , ENROLLMENT WITHOUT OVERLAPS ) ,
FOREIGN KEY ( COURSENO , PERIOD ENROLLMENT )
REFERENCES COURSE_FROM_TO ( COURSENO , PERIOD AVAILABLE ) ,
FOREIGN KEY ( STUDENTNO , PERIOD ENROLLMENT )
REFERENCES STUDENT_FROM_TO ( STUDENTNO , PERIOD REGISTERED ) ) ;
a. WITH t1 AS ( SELECT STUDENTNO FROM ENROLLMENT_FROM_TO WHERE COURSENO = COURSENO ( 'C1' ) AND DTO = d99 ),
t2 AS ( SELECT STUDENTNO FROM ENROLLMENT_FROM_TO WHERE COURSENO = COURSENO ( 'C2' ) AND DTO = d99 )
SELECT STUDENTNO FROM t1 NATURAL JOIN t2
Note: The expression DTO = d99 in the definitions of t1 and t2 here could be replaced by ENROLLMENT CONTAINS CURRENT_DATE if desired.
b. The problem statement is ambiguous! We interpret the requirement to be “Get student numbers for students currently enrolled on at least one course, but not currently enrolled on both course C1 and course C2.” Let the result of evaluating the expression given as the answer to part a. above be assigned to table Ta. Then the following will suffice:
SELECT STUDENTNO FROM ENROLLMENT_FROM_TO WHERE DTO = d99
EXCEPT
SELECT STUDENTNO FROM Ta
Note that there won’t be any duplicate student numbers in the result here (why not?).
c. SELECT DISTINCT DFROM , DTO
FROM COURSE_FROM_TO
But the result here almost certainly won’t be in packed form. Do you have a good way to fix this problem? If so, we’d like to hear about it. You can contact us via the publisher.
d. This one is even worse, and would remain so even if we could figure out a way to get the result in part c. into packed form. No solution provided.
a. INSERT INTO COURSE_FROM_TO ( COURSENO , DFROM , DTO )
VALUES ( COURSENO ( 'C542' ) , DATE '2013-06-01' , DATE '9999-12-31' )
( COURSENO ( 'C543' ) , DATE '2013-06-01' , DATE '9999-12-31' )
INSERT INTO COURSE_NAME_FROM_TO ( COURSENO , CNAME , DFROM , DTO )
VALUES ( COURSENO ( 'C542' ), NAME ( 'Tutorial D' ), DATE '2013-06-01' , DATE '9999-12-31' ) ,
( COURSENO ( 'C543' ) , NAME ( 'Temporal Databases' ), DATE '2013-06-01' , DATE '9999-12-31' ) ;
Of course, these two INSERTs really need to be done as part of the same transaction. An analogous remark applies to the answers to parts b.-d. also.
b. UPDATE COURSE_FROM_TO
SET DTO = DATE '2013-05-31'
WHERE DTO = DATE '9999-12-31'
AND COURSENO IN ( COURSENO ( 'C193' ), COURSENO ( 'C203' ) ) ;
UPDATE COURSE_NAME_FROM_TO
SET DTO = DATE '2013-05-31'
WHERE DTO = DATE '9999-12-31'
AND COURSENO IN ( COURSENO ( 'C193' ), COURSENO ( 'C203' ) ) ;
We assume for simplicity here that table ENROLLMENT_FROM_TO doesn’t show any students as currently enrolled on either of these courses.
c. INSERT INTO STUDENT_FROM_TO ( STUDENTNO , DFROM , DTO )
VALUES ( STUDENTNO ( 'ST21' ) , DATE '2011-10-01' , DATE '2012-06-30' ) ;
INSERT INTO STUDENT_NAME_FROM_TO ( STUDENTNO , SNAME , DFROM , DTO )
VALUES ( STUDENTNO ( 'ST21' ) , NAME ( 'Hugh Manatee' ) , DATE '2011-10-01' , DATE '2012-06-30' ) ;
d. UPDATE STUDENT_NAME_FROM_TO
SET DTO = DATE '2012-11-18'
WHERE STUDENTNO = STUDENTNO ( 'ST19' )
AND NAMED CONTAINS DATE '2012-11-18' ;
INSERT STUDENT_NAME_FROM_TO ( STUDENTNO , SNAME , DFROM , DTO )
VALUES ( STUDENTNO ( 'ST19' ) , NAME ( 'Anna Marino' ) , DATE '2012-11-18' ,
( SELECT MIN ( DTO ) FROM STUDENT_NAME_FROM_TO WHERE STUDENTNO = STUDENTNO ( 'ST19' ) AND NAMED CONTAINS DATE '2012-11-18' ) ;
Note: This solution assumes the database currently shows student ST19 as having some name on November 18th, 2012.
19.6 CREATE TABLE BSP_FROM_TO
( SNO SNO NOT NULL ,
PNO PNO NOT NULL ,
DFROM DATE NOT NULL ,
DTO DATE NOT NULL ,
PERIOD FOR DPERIOD ( DFROM , DTO ) ,
UNIQUE ( SNO , PNO , DPERIOD WITHOUT OVERLAPS ) ,
FOREIGN KEY ( SNO , PERIOD DPERIOD ) REFERENCES BS_FROM_TO ( SNO , PERIOD DPERIOD ) ,
XFROM TIMESTAMP(12) GENERATED ALWAYS AS ROW START NOT NULL ,
XTO TIMESTAMP(12) GENERATED ALWAYS AS ROW END NOT NULL ,
PERIOD FOR SYSTEM_TIME ( XFROM , XTO ) ,
UNIQUE ( SNO , PNO ) )
WITH SYSTEM VERSIONING ;
a. SELECT XFROM, XTO
FROM BS_FROM_TO
FOR SYSTEM_TIME BETWEEN t01 AND t99
WHERE SNO = SNO ( 'S2' )
AND DPERIOD CONTAINS d04
For simplicity we use t01 and t99 here to denote the first and last value, respectively, of type TIMESTAMP(12). The result is guaranteed to be free of redundancy but not necessarily free of circumlocution.
b. SELECT DFROM , DTO
FROM BS_FROM_TO
FOR SYSTEM_TIME BETWEEN t01 AND t99
WHERE SNO = SNO ( 'S2' )
AND SYSTEM_TIME CONTAINS d08
19.8 The situation here is analogous to that described in Chapter 12 in connection with during relvars only and “the moving point now.” The point is, those appearances of t99 in current rows don’t really mean the end of time as such—rather, they stand for until further notice. However, SQL has no direct way of saying something is true “until further notice”; thus, it has to resort to that “end of time” trick,33 much as we had to do for “valid” or stated time in a design consisting of during relvars only. As noted in Chapter 12, however, such tricks effectively mean we’re recording in the database something we know is false—a practice that’s logically incorrect, and hence somewhat hard to condone.
19.9 There are several interconnected issues involved here, and a good way to explain them, or at least air them, is by means of a series of questions and answers—a kind of dialog between a hypothetical student and teacher, as follows.
Student: First of all, why do we need this transaction timestamp notion at all? Why can’t we just timestamp updates with the system clock reading, as suggested in the body of the chapter? Surely that would be the obvious approach. Is there something wrong with it?
Teacher: Well, imagine the following scenario. You start a transaction on Monday. Your transaction updates some row r on Wednesday,34 so—assuming we do use the system clock—the pertinent timestamp is Wednesday. On Friday, your transaction successfully completes (i.e., commits). Meanwhile, I submit a query on row r on Thursday, and I see the version of r that was current before your transaction ran. (I can’t see your updated version, because your transaction hasn’t committed yet.) Then I submit the same query on Saturday—and now I do see your updated version of r. What’s more, I see now that your updated version of r came into being on Wednesday, before I ran my query on Thursday! So why didn’t I see that version on Thursday?
Student: But wait a minute. Surely, when my transaction updates r on Wednesday, I get an exclusive lock on r. So when you try to access r on Thursday, you’re trying to get at least a shared lock on r, and so you’ll have to wait. And when my transaction commits, you’ll come out of the wait state, but then you’ll see my updated version of r. Isn’t that right?
Teacher: Yes, it’s right in principle, so long as the DBMS we’re talking about is one that uses locking for concurrency control and abides by all of the protocols normally associated with locking. But it might not be! The SQL standard nowhere mentions locking as such, and indeed there are concurrency control schemes that don’t use it. For example, there’s a scheme called multiversion read (MVR). Under MVR, if I ask to see a row r that you already have update access to, then I’m given access to a previously committed version of that row (in our example, that would be the version of r as it was last Sunday). In other words, the system makes it look as if my transaction actually ran before yours.
Student: But isn’t that approach a little suspect? It looks to me as if there’s something inconsistent going on. On Thursday, you’re going to make some business decision on the basis of incorrect information—to be specific, on the basis of row r having the value on Thursday that you saw on Thursday. What are you going to do on Saturday when you discover that row r actually had a different value on Thursday? I mean, the ATM machine might have dispensed hard cash on Thursday … and you can’t call it back on Saturday, can you?
Teacher: I can’t answer that.
Student: All right, let’s go back to locking. It seems to me there are other problems too, even with locking. Suppose we don’t use the system clock; suppose instead that, since updates don’t “really” happen until they’re committed, we use commit time as the transaction timestamp. One obvious difficulty springs to mind immediately: namely, at the time when an update is requested inside the transaction, we don’t know what the commit time is going to be. So what’s the transaction timestamp, within a given transaction, for a row that has been updated in that transaction and not yet committed, because the transaction hasn’t yet finished?35
Teacher: Good point! Perhaps we might use the transaction start time, instead of commit time, for the transaction timestamp?
Student: All right … So suppose I update the same row twice in the same transaction. If we use the same timestamp for both updates, how can I see, within that same transaction, the update history for that row? I mean an update history that does reflect both of those updates?
Teacher: I give up.