
Generalizing the Algebraic Operators
The PACK and UNPACK operators provide the basis for greatly simplifying the formulation of certain kinds of queries that arise frequently in the temporal context, but there’s still room for further improvement. With such considerations in mind, this chapter shows how the familiar operators of the relational algebra can all be generalized appropriately, as U_ operators. To be specific, it discusses U_ versions of the familiar dyadic operators (UNION, INTERSECT, MINUS, D_UNION, I_MINUS, JOIN, MATCHING, NOT MATCHING); the n-adic operators (UNION, INTERSECT, D_UNION, JOIN); and the monadic operators (restrict, project, EXTEND, GROUP, UNGROUP). It also discusses U_ comparison operators. It concludes with an examination of the intuition underlying all of these new operators.
Keywords
“temporal” algebraic operators; “temporal” projection; “temporal” join (etc.)
To generalize is to be an idiot.
—William Blake:
Annotations to Sir Joshua Reynolds’s Discourses (c. 1798)
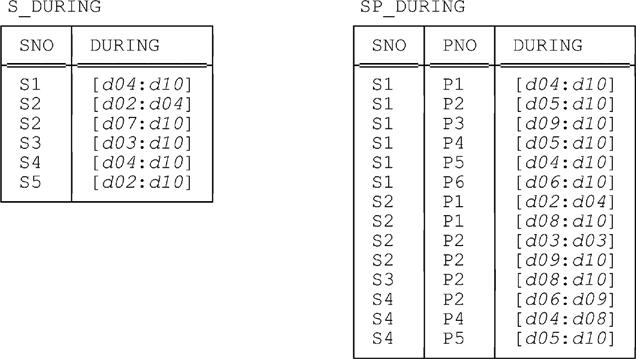
In Chapters 9 and 10, we saw how expressions that would have been quite complex and cumbersome to formulate in terms of the original relational algebra could be made much less so—indeed, much more user friendly and manageable—by means of the PACK and UNPACK shorthands. But PACK and UNPACK as such are still not the end of the story. To be specific, PACK and UNPACK can be used as a basis for defining still further shorthands at a still higher level of abstraction. Such further shorthands are the subject of the present chapter. Note: For convenience, we show our running example once again in Fig. 11.1. As usual, coding examples will be based on these sample values, barring explicit statements to the contrary.
A Motivating Example
Here’s Query B once again, repeated from Chapter 9:
■ Query B: Get SNO-DURING pairs such that DURING designates a maximal interval during which supplier SNO was unable to supply any parts at all.
And here again is the “temporal difference” formulation of this query, also repeated from Chapter 9:
PACK
( ( UNPACK S_DURING { SNO , DURING } ON ( DURING ) ) MINUS ( UNPACK SP_DURING { SNO , DURING } ON ( DURING ) ) )ON ( DURING )
As you can see, this expression overall is effectively asking for the following sequence of operations to be performed:
Now, it turns out that the general pattern illustrated by this example—unpack certain input relation(s), perform some relational operation on the resulting unpacked form(s), and then pack the result of that operation—occurs so frequently that the possibility of defining a shorthand seems worth investigation. What’s more (bonus!), such a shorthand offers the possibility of better performance. Consider in particular what happens with intervals of large cardinality (note that such intervals are likely to be commonplace if the contained points are of fine granularity, such as milliseconds or even microseconds). When such intervals are involved, the output from UNPACK can be very large in comparison to the input. Thus, if the system were actually to materialize such unpacked relations (and then perform the appropriate relational operation on the unpacked versions, and then pack the result), the query might “run forever” or run out of memory. By contrast, expressing the overall requirement as a single operation might let the optimizer choose a more efficient implementation, one that doesn’t require materialization of those intermediate unpacked results (see Appendix E). So let’s investigate.
Dyadic Operators
It should be clear that shorthands of the kind we have in mind can in principle be defined for all of the conventional relational operators. In this section, however, we limit our attention to the dyadic operators specifically—in other words, the operators UNION, INTERSECT, and MINUS; D_UNION and I_MINUS; JOIN; and MATCHING and NOT MATCHING. Note: Relational comparisons are dyadic operators too, of course, but we defer treatment of relational comparison operators to a section of their own.
UNION, INTERSECT, and MINUS
Since we began this chapter with a brief look at “temporal difference,” let’s complete our treatment of that operator first. Here’s a definition:
Definition: Let relations r1 and r2 be of the same type T, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is one of type T’s component attributes and (b) is of some interval type. Then the expression USING (ACL) : r1 MINUS r2 denotes the U_difference with respect to ACL between r1 and r2 (in that order), and it’s defined to be shorthand for the following:
PACK
( ( UNPACK rl ON ( ACL ) ) MINUS
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
■ The qualification “with respect to ACL” can be omitted if the commalist ACL is understood. Do note, however, that if IA is the set of all of type T’s component attributes that are interval valued, then in general there’s a distinct U_difference between r1 and r2 (in that order) for each distinct permutation of the attributes in each subset of IA. Note: Analogous remarks apply to all of the operators to be defined in this chapter, and we won’t bother to keep repeating them, instead letting this one paragraph do duty for all.
■ In our discussion of the motivating example in the previous section, we referred to the operator just defined as “temporal difference.” As noted in Chapter 9, however, we don’t much care for this terminology, because the operator doesn’t apply just to temporal intervals as such. Until further notice, therefore, we’ll call it U_difference—U for USING1—or simply U_MINUS for short.
■ In what follows, we’ll be defining several further U_ operators. In all cases, the syntax takes the following form:
USING ( ACL ) : exp
Please be aware, however, that this syntax is used in this book for expository purposes only. It hasn’t been checked for syntactic soundness.
Aside: For readers who might be familiar with “temporal statement modifiers” as described in, e.g., reference [8], we wish to stress that our USING specifications aren’t the same thing. Loosely speaking, temporal statement modifiers are supposed to apply to every operator involved in the expression or statement to which they’re attached. Our USING specifications, by contrast, apply only to the outermost operator of the expression to which they’re attached.2 For example, in the U_difference USING (ACL) : r1 MINUS r2, the USING specification applies to the MINUS operator as such, not to any operators that might be invoked during evaluation of the expressions denoting r1 and r2. See the revised formulation of Query B shown below for an illustration of this point.
These observations raise another point, however—namely, what in general is “the outermost operator” in an arbitrary Tutorial D expression? The answer to this question clearly depends on Tutorial D’s operator precedence rules, details of which (as noted in Chapter 2) we prefer not to provide in this book.3 In our examples, therefore, we’ll always use parentheses and/or WITH specifications, if and as necessary, in order to avoid any possibility of ambiguity. End of aside.
Here then is a shorthand formulation for Query B:
USING ( DURING ) :
S_DURING { SNO , DURING } MINUS SP_DURING { SNO , DURING }Explanation: First, the projections of S_DURING and SP_DURING on SNO and DURING are computed. (The first of these is an identity projection, of course.) Those projections are then unpacked on DURING; the difference between those unpacked results is computed; and that difference is then packed on DURING.4
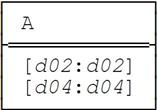
It’s interesting to note, by the way, that (unlike the regular MINUS operator) U_MINUS can produce a result whose cardinality is greater than that of its left operand. For example, let r1 and r2 be as follows:

Then USING (A) : r1 MINUS r2 gives:
Now we turn to U_UNION. Here’s the definition:
Definition: Let relations r1 and r2 be of the same type T, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is one of type T’s component attributes and (b) is of some interval type. Then the expression USING (ACL) : r1 UNION r2 denotes the U_union with respect to ACL of r1 and r2, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK rl ON ( ACL ) ) UNION
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
Actually there’s no need to do those preliminary UNPACKs in this particular case. That is, the U_UNION expansion can be simplified to just:
PACK ( rl UNION r2 ) ON ( ACL )
It’s not hard to see why this simplification is possible, but you can try working through an example if you need to convince yourself. Note: Similar simplifications are possible with several of the other U_ operators as well. We won’t bother to spell out the specifics in this chapter, however; instead, we refer you to Appendix E, where such matters are discussed in detail.
Unlike the regular UNION operator, U_UNION can produce a result whose cardinality is less than that of either of its operands. For example, let r1 and r2 be as follows:

Then USING (A) : r1 UNION r2 gives:

Finally we turn to U_INTERSECT:
Definition: Let relations r1 and r2 be of the same type T, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is one of type T’s component attributes and (b) is of some interval type. Then the expression USING (ACL) : r1 INTERSECT r2 denotes the U_intersection with respect to ACL of r1 and r2, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK rl ON ( ACL ) )
INTERSECT
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
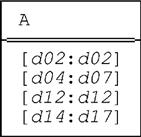
Unlike the regular INTERSECT operator, U_INTERSECT can produce a result whose cardinality is greater than that of either of its operands. For example, let r1 and r2 be as follows:

Then USING (A) : r1 INTERSECT r2 gives:
D_UNION and I_MINUS
U_ versions of D_UNION and I_MINUS certainly make sense, though the nomenclature gets a little clumsy. Once again let relations r1 and r2 be of the same type T, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is one of type T’s component attributes and (b) is of some interval type. Then:
Definition: The expression USING (ACL) : r1 D_UNION r2 denotes the disjoint U_union with respect to ACL of r1 and r2, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK rl ON ( ACL ) ) D_UNION
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
Definition: The expression USING (ACL) : r1 I_MINUS r2 denotes the included U_difference with respect to ACL between r1 and r2 (in that order), and it’s defined to be shorthand for the following:
PACK
( ( UNPACK r1 ON ( ACL ) ) I_MINUS
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
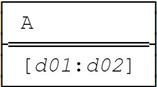
■ Let r1 and r2 be as follows:

Then USING (A) : r1 D_UNION r2 is undefined. But if the sole A value in r2 had been [d04:d04] instead of [d03:d04], the result would have been:

■ Again let r1 and r2 be as follows:

Then USING (A) : r1 I_MINUS r2 is undefined. But if the sole A value in r2 had been [d03:d03] instead of [d03:d04], the result would have been:
JOIN
Definition: Let relations r1 and r2 be joinable, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of both r1 and r2 and (b) is of some interval type. Then the expression USING (ACL) : r1 JOIN r2 denotes the U_join with respect to ACL of r1 and r2, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK r1 ON ( ACL ) ) JOIN
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
Note: If r1 and r2 are of the same type, then U_JOIN degenerates (as would surely be expected) to U_INTERSECT.
In order to illustrate the use of U_JOIN, suppose we have, in addition to our usual relvars S_DURING and SP_DURING, another relvar S_CITY_DURING—see Chapter 12—with attributes {SNO,CITY,DURING}, key {SNO,DURING}, and predicate as follows:
DURING denotes a maximal interval of days throughout which supplier SNO was located in city CITY.
Now consider the query “Get SNO-CITY-PNO-DURING tuples such that supplier SNO was both (a) located in city CITY, and (b) able to supply part PNO, throughout interval DURING, where DURING contains day 4.” Here’s a possible formulation of that query:
( USING ( DURING ) : S_CITY_DURING JOIN SP_DURING ) WHERE d04 ∈ DURING
Observe that this formulation involves a U_join followed by a regular restrict.
Aside: If we were to project attribute DURING away from the result of the foregoing query, the resulting projection would represent what’s sometimes called a snapshot of the database—or, more precisely, a snapshot of a certain portion of the database—as of a certain point in time (day 4, in the case at hand). Such snapshot queries are needed quite often in practice. (By the way, don’t confuse “a snapshot of the database” with “a snapshot database”! See footnote 1 in Chapter 4 for a brief explanation of this latter term.) End of aside.
One last point on U_join: Since TIMES is a special case of JOIN, we could obviously define a U_TIMES operator too if we wanted to, of the form USING (ACL) : r1 TIMES r2. However, ACL here would necessarily be empty, and U_TIMES would thus effectively be indistinguishable from the regular TIMES operator (see the section “The Regular Operators Revisited” at the end of the chapter). But we might still want to support such an operator, if only for completeness.
MATCHING and NOT MATCHING
Let relations r1 and r2 be joinable, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of both r1 and r2 and (b) is of some interval type. Then:
Definition: The expression USING (ACL) : r1 MATCHING r2 denotes the U_semijoin with respect to ACL of r1 and r2, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK rl ON ( ACL ) ) MATCHING
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
Definition: The expression USING (ACL) : r1 NOT MATCHING r2 denotes the U_semidiference with respect to ACL between r1 and r2 (in that order), and it’s defined to be shorthand for the following:
PACK
( ( UNPACK rl ON ( ACL ) ) NOT MATCHING
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
Let’s focus on MATCHING for a moment. Let A1, A2, …, An be all of the attributes of relation r1. As you’ll recall from Chapter 2, then, the expression r1 MATCHING r2 is shorthand for the following:
( ( rl JOIN r2 ) { A1 , A2 ,… , An } )(outer parentheses shown for reasons of clarity). However, the expression USING (ACL) : r1 MATCHING r2 is not shorthand for USING (ACL) : ((r1 JOIN r2) {A1,A2, …,An}). Instead, it’s shorthand for:
USING ( ACL ) : ( ( USING ( ACL ) : rl JOIN r2 ) { Al ,A2 ,… , An } )The outer USING here applies to the projection, the inner one to the join. In other words, where a regular semijoin is a regular projection of a regular join, a U_semijoin is a U_projection of a U_join. Note: U_join has already been discussed. As for U_projection, see the section “Monadic Operators,” later.
In similar fashion, the expression USING (ACL) : r1 NOT MATCHING r2 is shorthand for:
USING ( ACL ) : ( rl MINUS ( USING ( ACL ) : rl MATCHING r2 ) )
(a U_difference in which the second operand is a U_semijoin).
n-Adic Operators
Several of the operators discussed in the section “Dyadic Operators” above have n-adic analogs; to be specific, the operators UNION, INTERSECT, D_UNION, and JOIN all do. (So does TIMES, of course.) So we can define U_ versions of these operators that (a) involve unpacking all n of the relations involved, (b) applying the regular n-adic operator to those n unpacked forms, and then (c) packing the result. Here for example is a definition for n-adic U_JOIN (the definitions for the other operators follow the same general pattern, and we omit the specifics here):
Definition: Let relations r1, r2, …, rn be joinable, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of each of r1, r2, …, rn and (b) is of some interval type. Then the expression USING (ACL) : JOIN {r1,r2, …,rn} denotes the U_join with respect to ACL of r1, r2, …, rn, and it’s defined to be shorthand for the following:
PACK
( JOIN { UNPACK rl ON ( ACL ) , UNPACK r2 ON ( ACL ) , ………… , UNPACK rn ON ( ACL ) } )
ON ( ACL )
Monadic Operators
We turn now to U_ versions of the monadic operators RENAME, restrict, project, EXTEND, GROUP, and UNGROUP.
RENAME
Definition: Let r be a relation, let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of r and (b) is of some interval type, and let r have an attribute called A (not mentioned in ACL) and no attribute called B. Then the expression USING (ACL) : r RENAME {A AS B} denotes an (attribute) U_renaming of r, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK r ON ( ACL ) ) RENAME { A AS B } )
ON ( ACL )
Of course, this expression reduces to just:
PACK ( r RENAME { A AS B } ) ON ( ACL )Note: We include a definition of U_renaming here mainly for reasons of completeness, not because we expect such an operator to be very much used in practice.
Restrict
Definition: Let r be a relation, let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of r and (b) is of some interval type, and let bx be a restriction condition on r. Then the expression USING (ACL) : r WHERE bx denotes the U_restriction with respect to ACL of r according to bx, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK r ON ( ACL ) ) WHERE bx )
ON ( ACL )
Observe that the preliminary UNPACK here applies to r per se, not to the restriction r WHERE bx. Here’s an example:
USING ( DURING ) :
S_DURING WHERE DURING ⊆ INTERVAL_DATE ( [ d03 : d07 ] )
Note the difference between this U_restrict and the following regular restrict:
S_DURING WHERE DURING ⊆ INTERVAL_DATE ( [ d03 : d07 ] )
Suppose, for example, that relvar S_DURING currently contains just two tuples, as follows:
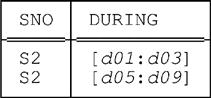
Then the regular restrict just shown will return an empty result, while the U_restrict will return a result of cardinality two, thus (regular restrict on the left, U_restrict on the right):

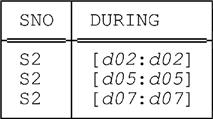
Unlike regular restrict, U_restrict can produce a result with cardinality greater than that of its input. For example, suppose again that relvar S_DURING contains just the two tuples for supplier S2 shown above, and consider the following U_restrict:
USING ( DURING ) :
S_DURING WHERE DURING = INTERVAL_DATE ( [ d02 : d02 ] )
OR DURING = INTERVAL_DATE ( [ d05 : d05 ] )
OR DURING = INTERVAL_DATE ( [ d07 : d07 ] )
Here’s the result:
Project
Definition: Let r be a relation, let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of r and (b) is of some interval type, and let BCL be a commalist of attribute names such that every attribute mentioned in ACL is also mentioned in BCL. Then the expression USING (ACL) : r {BCL} denotes the U_projection with respect to ACL of r on BCL, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK r ON ( ACL ) ) { BCL } )
ON ( ACL )
By way of an example, recall Query A from Chapter 9:
■ Query A: Get SNO-DURING pairs such that DURING designates a maximal interval during which supplier SNO was able to supply at least one part.
Here’s a formulation for this query using U_project (as noted in Chapter 10, it’s an example of what’s sometimes called “temporal projection”):
USING ( DURING ) : SP_DURING { SNO , DURING }EXTEND
By now the pattern should be familiar:
Definition: Let r be a relation, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of r and (b) is of some interval type. Then the expression USING (ACL) : EXTEND r : {A := exp} denotes a U_extension with respect to ACL of r, and it’s defined to be shorthand for the following:
PACK
( ( EXTEND ( UNPACK r ON ( ACL ) ) : { A := exp } )
ON ( ACL )
Unlike the regular EXTEND operator, U_EXTEND can return a result with cardinality either greater or less than that of its input.5 Suppose, for example, that relvar S_DURING currently contains just two tuples, as follows:
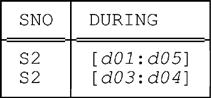
Then the first of the following U_EXTENDs will return a relation of cardinality five and the second will return a relation of cardinality one:
USING ( DURING ) : EXTEND S_DURING : { X := BEGIN ( DURING ) }USING ( DURING ) : EXTEND S_DURING : { Y := COUNT ( DURING ) }Here are the results:

Note: The expression BEGIN (DURING) in the first of the foregoing U_EXTENDs is equivalent to, and might more clearly have been replaced by, POINT FROM DURING.
Recall now the following example from the discussion of image relations in Chapter 2:
EXTEND S : { PNO_REL := !!SP }Suppose we replace those references to S and SP by references to S_DURING and SP_DURING, respectively, and prefix the whole thing with USING (DURING), like this:
USING ( DURING ) : EXTEND S_DURING : { PNO_REL := !!SP_DURING }What happens? Well, this is a U_EXTEND, and the initial UNPACK is thus done on the relation being extended—i.e., the relation that’s the current value of S_DURING. Next, a regular extension is done on that unpacked relation, and the result is then packed again. Here’s the result of the initial UNPACK (in outline):

Let’s call this unpacked relation u. Now, if you’ll take a look at Fig. 6.1 in Chapter 6 or Fig. 9.1 in Chapter 9, you’ll see that the only tuple in SP_DURING “matching”—i.e., with the same SNO and DURING values as—some tuple in u is this one:

In effect, therefore, every tuple in u is extended with a PNO_REL value that’s an empty relation, with the sole exception of the tuple with supplier number S2 and DURING value the interval [d03:d03], which gets a PNO_REL value that’s a relation with heading {PNO} and body containing just a tuple for part number P2. Thus, the final PACK yields a result containing:
■ For each tuple in S_DURING with SNO value not S2, a copy of that tuple extended with a PNO_REL value consisting of a relation with heading {PNO} and body empty
■ For the tuple in S_DURING with SNO value S2 and DURING value [d07:d70], a copy of that tuple extended with a PNO_REL value consisting of a relation with heading {PNO} and body empty
■ For the tuple in S_DURING with SNO value S2 and DURING value [d02:d04], three separate tuples that look like this:
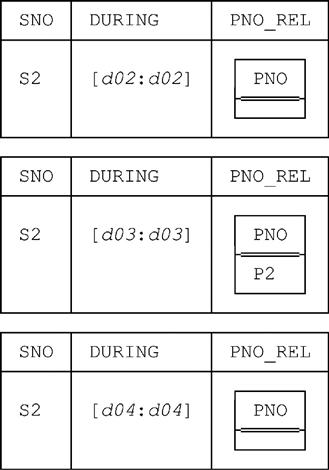
Now, this overall result is probably not what was wanted! Probably we’d have liked SP_DURING, as well as S_DURING, to be unpacked before the extension is done—but that’s not the way U_EXTEND works. (It’s not the way it works because the operator is monadic, and the implicit UNPACK therefore applies, as it does in the case of restrict, to the sole relation operand: namely, the relation being extended.) Thus, a more reasonable, or more useful (?), version of the query might look like this:
USING ( DURING ) : EXTEND S_DURING :
{ PNO_REL := !! ( UNPACK SP_DURING ON ( DURING ) ) }A pictorial (tabular) representation of the result of this expression—r, say—would be much too large to show here in its entirety, but you might like to confirm for yourself that the only tuples relation r contains, for supplier S1 in particular, are as follows:
■ A tuple with DURING value [d04:d04] and PNO_REL value consisting of a relation with heading {PNO} and body containing tuples for part numbers P1 and P5
■ A tuple with DURING value [d05:d05] and PNO_REL value consisting of a relation with heading {PNO} and body containing tuples for part numbers P1, P2, P4, and P5
■ A tuple with DURING value [d06:d08] and PNO_REL value consisting of a relation with heading {PNO} and body containing tuples for part numbers P1, P2, P4, P5, and P6
■ A tuple with DURING value [d09:d10] and PNO_REL value consisting of a relation with heading {PNO} and body containing tuples for part numbers P1, P2, P3, P4, P5, and P6
Let’s look at another example. Recall this query from Chapter 9:
■ At any given time, if there are any shipments at all at that time, then there’s some part number pmax such that, at that time, (a) at least one supplier is able to supply part pmax, but (b) no supplier is able to supply any part with a part number greater than pmax. So, for each part number that has ever been such a pmax value, get that part number together with the interval(s) during which it actually was that pmax value.
Just to remind you, here’s the formulation we gave in Chapter 9:
WITH ( t1 := UNPACK SP_DURING ON ( DURING ) ,
t2 := EXTEND t1 { DURING } : { PMAX := MAX ( !!t1 , PNO ) } ) :PACK t2 ON ( DURING )
Here by contrast is a formulation using U_EXTEND:
WITH ( t1 := UNPACK SP_DURING ON ( DURING ) ) :
USING ( DURING ) :
EXTEND SP_DURING { DURING } : { PMAX := MAX ( !!t1, PNO ) }As you’ll probably agree, this latter formulation isn’t much of an improvement on the Chapter 9 version (if it’s an improvement at all, that is). Indeed, what this example tends to suggest—and the same goes for the example immediately preceding this one—is that there might be scope here for defining a further shorthand of some kind.
Aside: Tutorial D currently supports an explicit SUMMARIZE operator that’s expressly intended for queries of the kind under discussion. Now, there were, and are, good reasons to prefer EXTEND and image relations over SUMMARIZE in general (see reference [40])—in fact, SUMMARIZE can actually be defined in terms of EXTEND and image relations. But one advantage SUMMARIZE clearly does have over EXTEND, at least in the present context, is that it’s a dyadic operator; in other words, it’s explicitly defined to take two relational operands. Thus, it would be reasonable to define a U_SUMMARIZE operator that would genuinely be useful for queries like the one under discussion.6 Here’s a putative U_SUMMARIZE version of that query:
USING ( DURING ) : SUMMARIZE SP_DURING PER ( SP_DURING { DURING } ) : { PMAX := MAX ( PNO ) }
The two relational operands here are (a) the current value of SP_DURING (“the SUMMARIZE relation”) and (b) the current value of the projection of SP_DURING on DURING (“the PER relation”). Thus, what the U_SUMMARIZE does is this: First, it unpacks both of these relations on DURING. Second, for each DURING value—a unit interval—in the unpacked form of the PER relation, it appends the corresponding PMAX value, which it computes by examining all tuples with that DURING value in the unpacked form of the SUMMARIZE relation (the result of this step is a relation with attributes DURING and PMAX). Finally, it packs the result on DURING again. End of aside.
Observe now that the foregoing discussion (i.e., of the pmax example) has to do specifically with aggregate operator invocations that appear within an attribute assignment within a U_EXTEND invocation. But exactly analogous considerations apply to aggregate operator invocations within a WHERE condition in a restriction. We omit detailed examination of this latter case here, however, since (as we saw in Chapter 2) it’s defined in terms of the former case anyway.
GROUP and UNGROUP
Definition: Let r be a relation; let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of r and (b) is of some interval type, let BCL be a commalist of attribute names in which every attribute mentioned is an attribute of r not mentioned in ACL; and let X be an attribute name that’s distinct from that of every attribute of r apart possibly from those attributes mentioned in BCL. Then the expression USING (ACL) : r GROUP {BCL} AS X denotes the U_grouping with respect to ACL of r on BCL, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK r ON ( ACL ) ) GROUP { BCL } AS X )
ON ( ACL )
Definition: Let r be a relation, let r have a relation valued attribute B, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is an attribute of r and (b) is of some interval type. Then the expression USING (ACL) : r UNGROUP B denotes the U_ungrouping with respect to ACL of r on B, and it’s defined to be shorthand for the following:
PACK
( ( UNPACK r ON ( ACL ) ) UNGROUP B )
ON ( ACL )
Here’s a U_GROUP example. Let the current value of relvar SP_DURING be as follows:
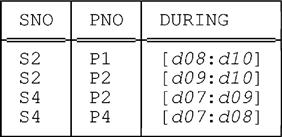
Then the expression
USING ( DURING ) : SP_DURING GROUP { PNO } AS PNO_RELyields the following result:
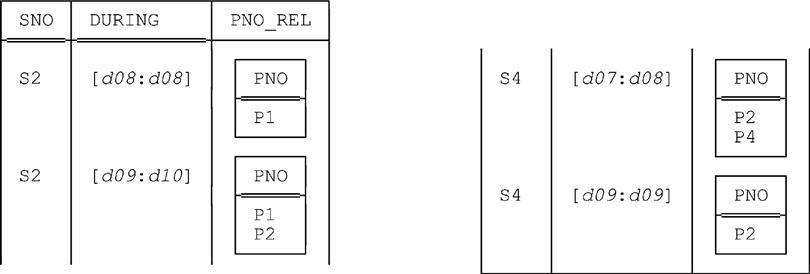
Exercise: Show that the foregoing U_GROUP expression is logically equivalent to the following (and hence, in effect, that U_GROUP can be defined in terms of U_EXTEND):
USING ( DURING ) : EXTEND SP_DURING { SNO , DURING } : { PNO_REL := !! ( UNPACK SP_DURING ON ( DURING ) ) }As for U_UNGROUP, we leave it as another exercise to show that if r is the result of the foregoing U_GROUP example, then the expression
USING ( DURING ) : r UNGROUP PNO_REL
returns the value of SP_DURING shown as the input relation for the U_GROUP example discussed above.
We remark without going into details that, like U_GROUP, U_ UNGROUP too can be defined in terms of U_EXTEND.
Relational Comparisons
The syntax of a regular relational comparison is basically as follows—
rl compop r2
—where r1 and r2 are relations of the same type T and compop is one of the following:
= ≠ ⊆ ⊂ ⊇ ⊃
Now, when relations r1 and r2 involve any interval attributes, what we often want to do is compare, not those relations per se, but certain unpacked versions of those relations. To that end, we introduce U_ versions of the regular comparison operators:
Definition: Let relations r1 and r2 be of the same type T, and let ACL be a commalist of attribute names in which every attribute mentioned (a) is one of type T’s component attributes and (b) is of some interval type. Then the expression USING (ACL) : r1 compop r2 (where compop is any of the regular relational comparison operators) denotes a U_comparison with respect to ACL between r1 and r2, and it’s defined to be shorthand for the following:
( UNPACK rl ON ( ACL ) ) compop ( UNPACK r2 ON ( ACL ) )
Note that there’s no question of performing a final PACK step here, because the result of a comparison is a truth value, not a relation. By way of example, let r1 and r2 be as follows:
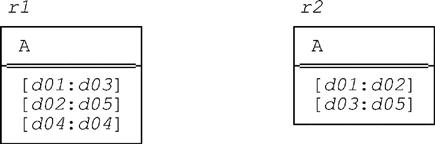
Then r1 = r2 is clearly false, but USING (A) : r1 = r2 is true. Note: When (as in this example) compop is “=”, the U_comparison is, of course, U_equality. And U_equality in turn is precisely the equivalence operator we defined for n-ary relations in Chapter 10.
The Underlying Intuition
In this section, we briefly discuss an alternative way of thinking about relations with interval attributes and the U_ operators on such relations as discussed in this chapter so far. Suppose the current value of relvar S_DURING is the relation shown here (let’s call it r):
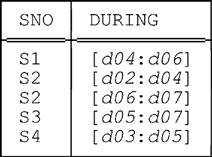
The intended interpretation for this relation, just to remind you, is that the indicated supplier was under contract throughout the indicated interval.
Observe now that the set of time points in DURING intervals in this relation r is exactly the following set:
{ d02 , d03 , d04 , d05 , d06 , d07 }The cardinality of this set is six. Thus, we can think of relation r as effectively specifying the overall state of affairs, regarding who was under contract, at each of those six separate points in time. In other words, we can think of r as a kind of shorthand for a sequence of six separate relations, one for each of the six time points in question (where the sequence in question is chronological, of course). Those six relations—let’s label them r02, r03, …, r07 in the obvious way—look like this:
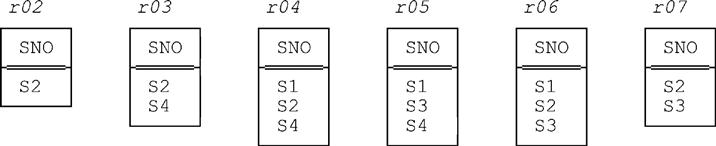
For example, relation r03 shows that suppliers S2 and S4 (only) were under contract on day 3. And, of course, that relation is obtained from relation r by (a) restricting r to just those tuples in which the DURING interval contains the value d03 and then (b) projecting the result of that restriction on attribute SNO.
It follows from the foregoing that we can imagine an operator that produces the sequence of relations r02, r03, …, r07 from relation r. Similarly, we can imagine an inverse operator that takes the sequence of relations r02, r03, …, r07 and gives us back relation r once again.7 For the sake of the present discussion, then, let’s refer to those two operators as REL_TO_SEQ and SEQ_TO_REL, respectively.
Now we can explain the intuition behind the various U_operators. For definiteness, let’s consider the operator U_JOIN specifically. Then the basic idea is that, first, for each individual point (each individual time point, in the foregoing example), the pertinent underlying operator—i.e., JOIN, in the case of U_JOIN—is applied to the pair of relations that correspond to that particular point value; second, the results of all of those individual operations are then put back together again appropriately. Thus, the operation of U_JOIN, for example, can be thought of, loosely, as doing a regular join on a point by point basis. (By way of another example, the U_equality comparison operator can be thought of, again loosely, as doing a regular equality comparison on a point by point basis.)
In order to see how the foregoing works out in more detail, let’s consider the case of U_JOIN a little more closely. Let the relations to be U_joined be r1 and r2. Conceptually, then, what happens is the following:
■ Let P1 be the set of all point values in intervals in r1. REL_TO_SEQ is applied to r1 to yield a sequence Q1 of relations, one for each point value in P1.
■ Let P2 be the set of all point values in intervals in r2 (note that P1 and P2 will be distinct sets, in general). REL_TO_SEQ is applied to r2 to yield a sequence Q2 of relations, one for each point value in P2.
■ Let P be the union of P1 and P2, and let the points in P, in sequence according to the ordering defined for the pertinent point type, be p1,p2, …, pn.
■ For all points pi in P (i = 1, 2, …, n), if pi appears in P1 and not P2, an empty relation of the same type as r2 and corresponding to pi is inserted into Q2; similarly, if pi appears in P2 and not in P1, an empty relation of the same type as r1 and corresponding to pi is inserted into Q1. Note: This step is necessary merely to ensure that the join operations in the next step are all well defined.
■ For all i (i = 1, 2, …, n), the relations in Q1 and Q2 corresponding to point pi are joined together. The net result is a sequence Q of n relations resulting from those joins.
■ SEQ_TO_REL is applied to Q to yield the desired overall result.
The Regular Operators Revisited
Consider once again the U_MINUS definition from the section “Dyadic Operators” earlier in this chapter. Just to remind you, we defined USING (ACL) : r1 MINUS r2 to be shorthand for:
PACK
( ( UNPACK r1 ON ( ACL ) )
MINUS
( UNPACK r2 ON ( ACL ) ) )
ON ( ACL )
Now suppose ACL is empty (i.e., specifies no attributes at all), so that the U_MINUS invocation becomes:
USING ( ) : r1 MINUS r2
Then the expansion becomes
PACK
( ( UNPACK r1 ON ( ) )
MINUS
( UNPACK r2 ON ( ) ) )
ON ( )
Recall now from Chapter 10 that UNPACK r ON ( ) and PACK r ON ( ) both reduce to just r. Thus, the entire expression reduces to just
r1 MINUS r2
In other words, the regular relational MINUS operator is essentially just a special case of U_MINUS! Thus, if we redefine the syntax of the regular MINUS operator as follows8—
[ USING ( ACL ) : ] r1 MINUS r2
—and if we allow the USING specification (and colon separator) to be omitted if and only if ACL is empty, then we no longer have any need to talk about a special U_MINUS operator at all: All MINUS invocations effectively become U_MINUS invocations, and we can generalize the semantics of the MINUS operator accordingly.
Analogous remarks apply to all of the other regular operators we’ve been talking about in this chapter (relational comparisons included): In all cases, the regular operator is basically just that special case of the corresponding U_ operator in which the USING specification mentions no attributes at all, and we can allow that specification and the colon separator to be omitted in such a case. To put it another way, the U_ operators are all just straightforward generalizations of their regular counterparts. Thus, we no longer need to talk explicitly about U_ operators, as such, at all (and we no longer will, except when we want to do so for reasons of clarity or emphasis). Instead, all we need do is recognize that the regular operators permit, but don’t require, an additional operand when they’re applied to relations with interval attributes. Please note carefully, therefore, that throughout the rest of the book, we’ll take all references to relational operators and relational comparisons to refer to the generalized versions as described in the present chapter (unless the context demands otherwise). For clarity and emphasis, however, we’ll occasionally use the explicit qualifiers regular (or classical) and generalized, as applicable, when referring to those operators and comparisons. As already noted, we’ll also sometimes use an explicit “U_” qualifier in such references for the same reason.
Exercises
11.1 In the body of the chapter we defined U_ versions of the regular relational operators, including operators like MATCHING that are fundamentally just shorthand. But what about the PACK and UNPACK shorthands? Would U_PACK and U_UNPACK operators make sense?
11.2 Does the following identity hold?
USING ( ACL ) : r1 INTERSECT r2 ≡
USING ( ACL ) : r1 MINUS ( USING ( ACL ) : r1 MINUS r2 )
11.3 Consider the operator U_JOIN. Assume for simplicity that the packing and unpacking are to be done on the basis of a single attribute A. Confirm that the following identity holds:
USING ( A ) : rl JOIN r2 ≡
WITH ( tl := r1 RENAME { A AS X },
t2 := r2 RENAME { A AS Y } ,
t3 := t1 JOIN t2 ,
t4 := t3 WHERE X OVERLAPS Y ,
t5 := EXTEND t4 : { A := X INTERSECT Y } ,
t6 := T5 { ALL BUT X , Y } ) :
PACK t6 ON ( A )
Confirm also that if r1 and r2 are initially packed on A, the final PACK step is unnecessary.
Answers
11.1 Such operators wouldn’t make a lot of sense (though that’s not necessarily a good reason for failing to support them, of course). Consider, e.g., a hypothetical U_PACK operator; more specifically, consider the following hypothetical expression:
USING ( DURING ) : PACK S_DURING ON ( DURING )
Presumably this expression would be defined to be shorthand for:
PACK
( UNPACK ( PACK S_DURING ON ( DURING ) ) ON ( DURING ) )
ON ( DURING )
And, of course, this expression reduces to simply PACK S_DURING ON (DURING). Note: In similar fashion, the expression USING (ACL) : !!r, if supported, would be equivalent to PACK !!r ON (ACL).
11.3 In essence, we need to show that the following identity holds:
( UNPACK r1 ON ( A ) ) JOIN ( UNPACK r2 ON ( A ) ) ≡ UNPACK t6 ON ( A )
Let B1 be all of the attributes of r1 apart from A, let B2 be all of the attributes of r2 apart from A, and let B be the set theory union of B1 and B2. Then:
■ Let B be empty. Then t6 has just one attribute, A, and the A values in its body consist of all possible intersections of an A value from r1 and an A value from r2. It follows that, loosely speaking, the unpacked form of t6 consists of every unit interval [p:p] such that p is contained in at least one of those intersections. And it’s clear that, speaking even more loosely, the join of the unpacked forms of r1 and r2 consists of exactly those same unit intervals. Thus, the identity does hold in this simple case.
■ Now let B be nonempty. If we partition r1 and r2 on the basis of B1 values and B2 values, respectively, we can apply an argument analogous to that given above to each pair of partitions, one each from r1 and r2. Hence the identity holds in all cases.
Proof that the final PACK step is unnecessary if r1 and r2 are initially packed: Note first that if the A value a appears in t6, then a is the intersection of some A value x appearing in r1 and some A value y appearing in r2; thus a ⊆ x. Now let B, B1, and B2 be as above. Further, let C be the set theory intersection of B1 and B2, let D be the set theory difference between B1 and B2 in that order, and let E be the set theory difference between B2 and B1 in that order. In other words, C is the other common attributes of r1 and r2 apart from A, D is the other attributes of r1, and E is the other attributes of r2.
Now let t = (a,c,d,e) and t’ = (a’,c,d,e) be tuples in t6, where a ≠ a’. (Here we use a shorthand notation for tuples that we take to be self-explanatory.) Then there must exist tuples (x,c,d) ∈ r1 and (x’,c,d) ∈ r1 such that a ⊆ x and a’ ⊆ x’. But r1 is packed on A, so these latter tuples neither meet nor overlap. Hence, since a ⊆ x and a’ ⊆ x’, tuples t and t’ neither meet nor overlap. Hence t6 is packed.
Points arising: First, we’ve now effectively discovered an algorithm for computing a U_join that involves no packing or unpacking at all; the algorithm works just so long as the input relations are initially packed. Second, the algorithm doesn’t in fact require both input relations to be packed—it’s sufficient that at least one of them be so. See Appendix E for further discussion.